مزودو الترجمة
يدعم AI Localization Automator خمسة مزودين مختلفين للذكاء الاصطناعي، لكل منهم نقاط قوة وخيارات تكوين فريدة. اختر المزود الذي يناسب احتياجات مشروعك وميزانيته ومتطلبات الجودة بشكل أفضل.
Ollama (الذكاء الاصطناعي المحلي)
الأفضل لـ: المشاريع الحساسة للخصوصية، الترجمة دون اتصال، استخدام غير محدود
يعمل Ollama على تشغيل نماذج الذكاء الاصطناعي محليًا على جهازك، مما يوفر خصوصية وسيطرة كاملة دون تكاليف API أو متطلبات اتصال بالإنترنت.
النماذج الشائعة
- translategemma:12b (نموذج ترجمة متخصص يعتمد على Gemma 3)
- llama3.2 (موصى به للأغراض العامة)
- mistral (بديل فعال)
- codellama (ترجمات واعية بالكود)
- والعديد من النماذج المجتمعية الأخرى
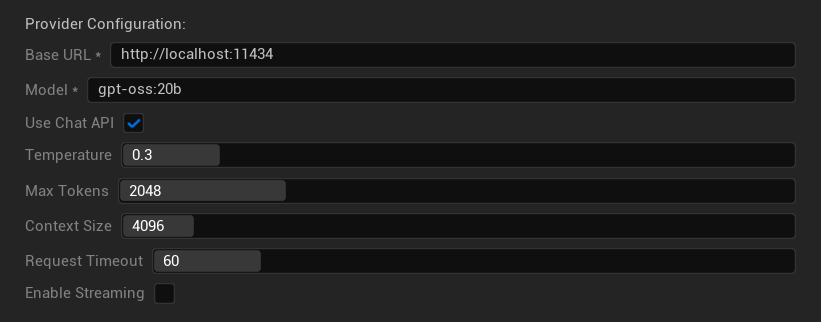
خيارات التكوين
- عنوان URL الأساسي: خادم Ollama المحلي (الافتراضي:
http://localhost:11434) - النموذج: اسم النموذج المثبت محليًا (مطلوب)
- استخدام Chat API: تمكين لمعالجة محادثة أفضل
- Temperature: 0.0-2.0 (يوصى بـ 0.3)
- الحد الأقصى للرموز (Tokens): 1-8,192 رمز
- حجم السياق: 512-32,768 رمز
- مهلة الطلب: 10-300 ثانية (النماذج المحلية قد تكون أبطأ)
- تمكين البث (Streaming): لمعالجة الاستجابة في الوقت الفعلي
نقاط القوة
- ✅ خصوصية كاملة (لا تترك البيانات جهازك)
- ✅ لا تكاليف API أو حدود استخدام
- ✅ يعمل دون اتصال بالإنترنت
- ✅ تحكم كامل في معلمات النموذج
- ✅ مجموعة واسعة من النماذج المجتمعية
- ✅ لا قيود من المزود
الاعتبارات
- 💻 يتطلب إعدادًا محليًا وأجهزة قادرة
- ⚡ أبطأ بشكل عام من مزودي السحابة
- 🔧 إعداد تقني أكثر مطلوب
- 📊 تختلف جودة الترجمة بشكل كبير حسب النموذج (يمكن لبعضها تجاوز مزودي السحابة)
- 💾 متطلبات تخزين كبيرة للنماذج
إعداد Ollama
- تثبيت Ollama: قم بالتنزيل من ollama.ai وقم بالتثبيت على نظامك
- تنزيل النماذج: استخدم
ollama pull translategemma:12bلتنزيل النموذج الذي اخترته - بدء الخادم: يعمل Ollama تلقائيًا، أو ابدأه بـ
ollama serve - تكوين الإضافة: قم بتعيين عنوان URL الأساسي واسم النموذج في إعدادات الإضافة
- اختبار الاتصال: ستتحقق الإضافة من الاتصال عند تطبيق التكوين
OpenAI
الأفضل لـ: أعلى جودة ترجمة بشكل عام، اختيار واسع للنماذج
يوفر OpenAI نماذج لغة رائدة في الصناعة من خلال واجهة برمجة التطبيقات Chat Completions الخاصة بهم، بما في ذلك أحدث نماذج GPT، ونماذج التفكير، والنماذج المدعومة بالبحث على الويب.
النماذج المتاحة
عائلة GPT-5 (نماذج الرائدة)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
عائلة GPT-4.1 (عالية الأداء)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
عائلة GPT-4o (متعددة الوسائط)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
سلسلة O (نماذج التفكير — لا تدعم temperature/top_p)
- o1, o1-pro, o3, o3-mini, o4-mini
نماذج البحث على الويب (لا تدعم temperature/top_p)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
قديمة / معاينة
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
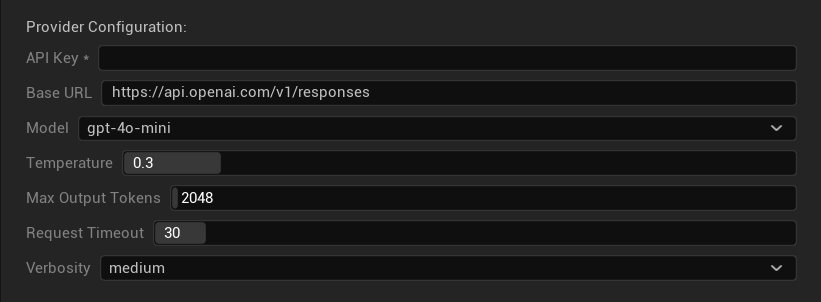
خيارات التكوين
- مفتاح API: مفتاح OpenAI API الخاص بك (مطلوب)
- عنوان URL الأساسي: نقطة نهاية API (الافتراضي:
https://api.openai.com/v1/chat/completions) - النموذج: اختر من النماذج المتاحة المذكورة أعلاه
- استخدام Temperature: تبديل معلمة temperature تشغيل/إيقاف (يتم تجاهلها تلقائيًا لنماذج التفكير من سلسلة o ونماذج البحث على الويب)
- Temperature: 0.0–2.0 (يوصى بـ 0.3 لاتساق الترجمة)
- Top P: معلمة أخذ العينات النووية من 0.0–1.0 (يتم تجاهلها لنماذج التفكير من سلسلة o ونماذج البحث على الويب)
- الحد الأقصى لرموز الإكمال: 1–128,000 رمز (يشمل رموز الإخراج والتفكير)
- مهلة الطلب: 5–300 ثانية
نقاط القوة
- ✅ جودة ترجمة عالية باستمرار
- ✅ فهم ممتاز للسياق
- ✅ الحفاظ القوي على التنسيق
- ✅ دعم لغوي واسع
- ✅ وقت تشغيل API موثوق
الاعتبارات
- 💰 تكلفة أعلى لكل طلب
- 🌐 يتطلب اتصالاً بالإنترنت
- ⏱️ حدود استخدام تعتمد على المستوى
Anthropic Claude
الأفضل لـ: الترجمات الدقيقة، المحتوى الإبداعي، التطبيقات التي تركز على السلامة
تتفوق نماذج Claude في فهم السياق والفروق الدقيقة، مما يجعلها مثالية للألعاب الغنية بالسرد وسيناريوهات الترجمة المحلية المعقدة.
النماذج المتاحة
عائلة Claude 4.6 (الأحدث)
- claude-opus-4-6, claude-sonnet-4-6
عائلة Claude 4.5
- claude-haiku-4-5 (سريع وفعال)
- claude-sonnet-4-5, claude-opus-4-5
عائلة Claude 4.x
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
عائلة Claude 3.x (قديمة)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
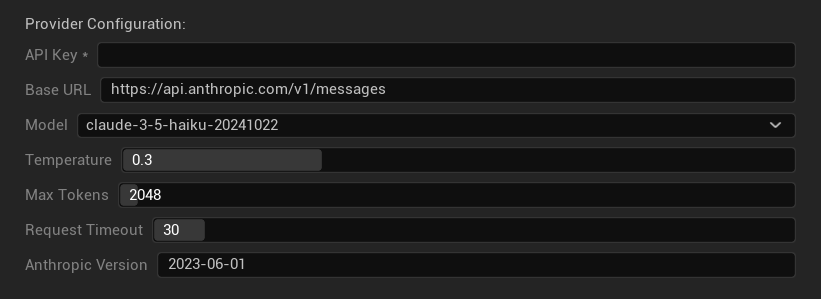
خيارات التكوين
- مفتاح API: مفتاح Anthropic API الخاص بك (مطلوب)
- عنوان URL الأساسي: نقطة نهاية Claude API
- النموذج: اختر من عائلة نماذج Claude
- Temperature: 0.0–1.0 (يوصى بـ 0.3)
- Top K: معلمة أخذ العينات Top-K (0 = غير مضبوط)
- الحد الأقصى للرموز (Tokens): 1–64,000 رمز
- مهلة الطلب: 5–300 ثانية
- إصدار Anthropic: رأس إصدار API
نقاط القوة
- ✅ وعي استثنائي بالسياق
- ✅ رائع للمحتوى الإبداعي/السردي
- ✅ ميزات أمان قوية
- ✅ قدرات تفصيلية على التفكير (تفكير موسع على نماذج 3.7+)
- ✅ اتباع ممتاز للتعليمات
الاعتبارات
- 💰 نموذج تسعير متميز
- 🌐 يتطلب اتصالاً بالإنترنت
- 📏 تختلف حدود الرموز حسب النموذج
DeepSeek
الأفضل لـ: الترجمة فعالة التكلفة، الإنتاجية العالية، المشاريع التي تراعي الميزانية
يقدم DeepSeek جودة ترجمة تنافسية بجزء بسيط من تكلفة المزودين الآخرين، مما يجعله مثاليًا لمشاريع الترجمة المحلية واسعة النطاق.
النماذج المتاحة
- deepseek-chat (للأغراض العامة، موصى به)
- deepseek-reasoner (قدرات تفكير محسنة)
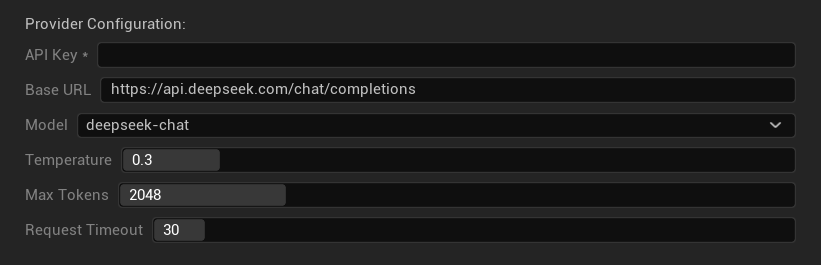
خيارات التكوين
- مفتاح API: مفتاح DeepSeek API الخاص بك (مطلوب)
- عنوان URL الأساسي: نقطة نهاية DeepSeek API
- النموذج: اختر بين نماذج الدردشة ونماذج التفكير
- Temperature: 0.0-2.0 (يوصى بـ 0.3)
- الحد الأقصى للرموز (Tokens): 1-8,192 رمز
- مهلة الطلب: 5-300 ثانية
نقاط القوة
- ✅ فعال التكلفة جدًا
- ✅ جودة ترجمة جيدة
- ✅ أوقات استجابة سريعة
- ✅ تكوين بسيط
- ✅ حدود معدل عالية
الاعتبارات
- 📏 حدود رموز أقل
- 🆕 مزود أحدث (سجل أقل)
- 🌐 يتطلب اتصالاً بالإنترنت
Google Gemini
الأفضل لـ: المشاريع متعددة اللغات، الترجمة فعالة التكلفة، تكامل مع نظام Google البيئي
تقدم نماذج Gemini قدرات قوية متعددة اللغات مع تسعير تنافسي وميزات فريدة مثل وضع التفكير لتعزيز المنطق.
النماذج المتاحة
عائلة Gemini 3.x (معاينة)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
عائلة Gemini 2.5 (مع دعم التفكير)
- gemini-2.5-pro (الرائد مع التفكير)
- gemini-2.5-flash (سريع، مع دعم التفكير)
- gemini-2.5-flash-lite (نسخة خفيفة الوزن)
عائلة Gemini 2.0
- gemini-2.0-flash, gemini-2.0-flash-lite
الأسماء المستعارة الأحدث
- gemini-flash-latest, gemini-flash-lite-latest
خيارات التكوين
- مفتاح API: مفتاح Google AI API الخاص بك (مطلوب)
- عنوان URL الأساسي: نقطة نهاية Gemini API
- النموذج: اختر من عائلة نماذج Gemini
- Temperature: 0.0–2.0 (يوصى بـ 0.3)
- الحد الأقصى لرموز الإخراج: 1–8,192 رمز
- مهلة الطلب: 5–300 ثانية
- تمكين التفكير: تفعيل التفكير المحسن لنماذج 2.5+
- ميزانية التفكير: التحكم في تخصيص رموز التفكير (0 = لا تفكير)
نقاط القوة
- ✅ دعم قوي متعدد اللغات
- ✅ تسعير تنافسي
- ✅ تفكير متقدم (وضع التفكير)
- ✅ تكامل مع نظام Google البيئي
- ✅ تحديثات منتظمة للنماذج مع وصول معاينة لأحدث النماذج
الاعتبارات
- 🧠 يزيد وضع التفكير من استخدام الرموز
- 📏 حدود رموز متغيرة حسب النموذج
- 🌐 يتطلب اتصالاً بالإنترنت
اختيار المزود المناسب
| المزود | الأفضل لـ | الجودة | التكلفة | الإعداد | الخصوصية |
|---|---|---|---|---|---|
| Ollama | الخصوصية/دون اتصال | متغيرة* | مجاني | متقدم | محلي |
| OpenAI | أعلى جودة | ⭐⭐⭐⭐⭐ | 💰💰💰 | سهل | سحابة |
| Claude | المحتوى الإبداعي | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | سهل | سحابة |
| DeepSeek | المشاريع ذات الميزانية | ⭐⭐⭐⭐ | 💰 | سهل | سحابة |
| Gemini | متعدد اللغات | ⭐⭐⭐⭐ | 💰 | سهل | سحابة |
*تختلف جودة Ollama بشكل كبير بناءً على النموذج المحلي المستخدم - يمكن لبعض النماذج المحلية الحديثة أن تطابق أو تتجاوز مزودي السحابة.
نصائح لتكوين المزود
لجميع مزودي السحابة:
- قم بتخزين مفاتيح API بأمان ولا تضعها في نظام التحكم بالإصدار
- ابدأ بإعدادات temperature محافظة (0.3) لترجمات متسقة
- راقب استخدام API وتكاليفك
- اختبر مع دفعات صغيرة قبل عمليات الترجمة الكبيرة
لـ Ollama:
- تأكد من وجود ذاكرة وصول عشوائي كافية (يوصى بـ 8 جيجابايت+ للنماذج الأكبر)
- استخدم تخزين SSD لأداء تحميل نموذج أفضل
- فكر في تسريع GPU لاستدلال أسرع
- اختبر محليًا قبل الاعتماد عليه للترجمات الإنتاجية