معاملات الاستدلال
تتحكم بنية معاملات الاستدلال LLM في كيفية تحميل النموذج وتوليده للنص. تقوم بتمرير هذه المعاملات عند تحميل النموذج. تصف هذه الصفحة كل معامل وتأثيره.
مرجع المعاملات
| المعامل | النوع | الافتراضي | النطاق | الوصف |
|---|---|---|---|---|
| الرموز القصوى | int32 | 512 | 1–8192 | الحد الأقصى لعدد الرموز التي يتم توليدها في استجابة واحدة |
| درجة الحرارة | float | 0.7 | 0.0–2.0 | يتحكم في العشوائية. 0.0 = حتمي. القيم الأعلى = إخراج أكثر إبداعًا |
| أعلى P | float | 0.9 | 0.0–1.0 | أخذ عينات بالنواة. يتم النظر فقط في الرموز التي تتجاوز احتماليتها التراكمية هذه القيمة |
| أعلى K | int32 | 40 | 0–200 | يقتصر التحديد على الرموز الأكثر احتمالاً من فئة K العليا. 0 = معطل |
| عقوبة التكرار | float | 1.1 | 0.0–3.0 | يعاقب الرموز التي ظهرت بالفعل في المخرجات. 1.0 = لا عقوبة |
| عدد طبقات GPU | int32 | -1 | -1–200 | طبقات النموذج التي سيتم تفريغها إلى GPU. -1 = تلقائي. 0 = وحدة المعالجة المركزية فقط |
| حجم السياق | int32 | 2048 | 128–131072 | النافذة القصوى للسياق بالرموز. القيم الأكبر تستخدم ذاكرة أكثر |
| الموجه النظامي | FString | "You are a helpful assistant." | — | تعليمة النظام التي تشكل سلوك النموذج |
| البذرة | int32 | -1 | -1+ | بذرة عشوائية لإخراج قابل للتكرار. -1 = عشوائي |
| عدد الخيوط | int32 | 0 | 0–128 | خيوط وحدة المعالجة المركزية للتوليد. 0 = تلقائي |
الاستخدام
- Blueprint
- C++
تظهر معاملات الاستدلال كدبوس بنية على عقد التحميل والعقد غير المتزامنة. قم بتفكيك البنية لتعيين القيم الفردية:
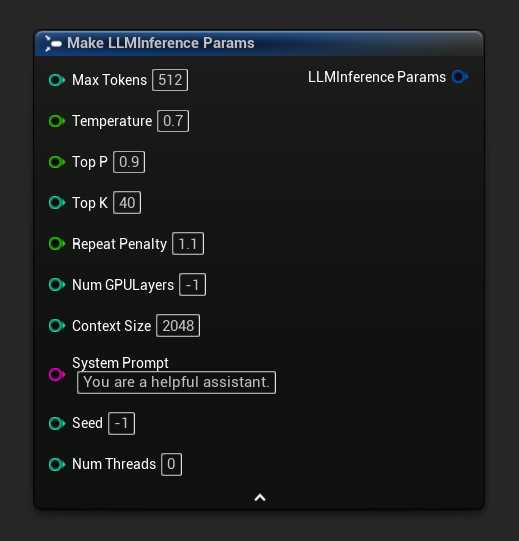
للحصول على مجموعة افتراضية من المعاملات كنقطة بداية، استخدم Get Default Inference Params:
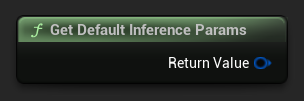
...
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
توصيات المنصة
الجوال / الواقع الافتراضي (Android, iOS, Meta Quest)
- حجم السياق: 1024–2048
- Num GPU Layers: 0 (CPU فقط) ما لم يدعم الجهاز حوسبة GPU بشكل مؤكد
- Max Tokens: أقل من 256 لتفاعلات سريعة الاستجابة
- Num Threads: 2–4 حسب الجهاز
سطح المكتب (Windows, Mac, Linux)
- حجم السياق: 2048–8192 لمعظم المحادثات
- Num GPU Layers: -1 (تلقائي) للاستفادة من تسريع GPU عند توفره
- Num Threads: 0 (تلقائي)
- Max Tokens: 512–2048 للردود الأطول