دليل معالجة الصوت
يغطي هذا الدليل كيفية إعداد طرق إدخال صوتية مختلفة لتغذية بيانات الصوت إلى مولدات مزامنة الشفاه. تأكد من إكمال دليل الإعداد قبل المتابعة.
معالجة إدخال الصوت
تحتاج إلى إعداد طريقة لمعالجة إدخال الصوت. هناك عدة طرق للقيام بذلك اعتمادًا على مصدر الصوت الخاص بك.
- الميكروفون (في الوقت الحقيقي)
- الميكروفون (إعادة التشغيل)
- تحويل النص إلى كلام (محلي)
- تحويل النص إلى كلام (واجهات برمجة تطبيقات خارجية)
- من ملف/مخزن مؤقت للصوت
- مخزن مؤقت للصوت مع البث
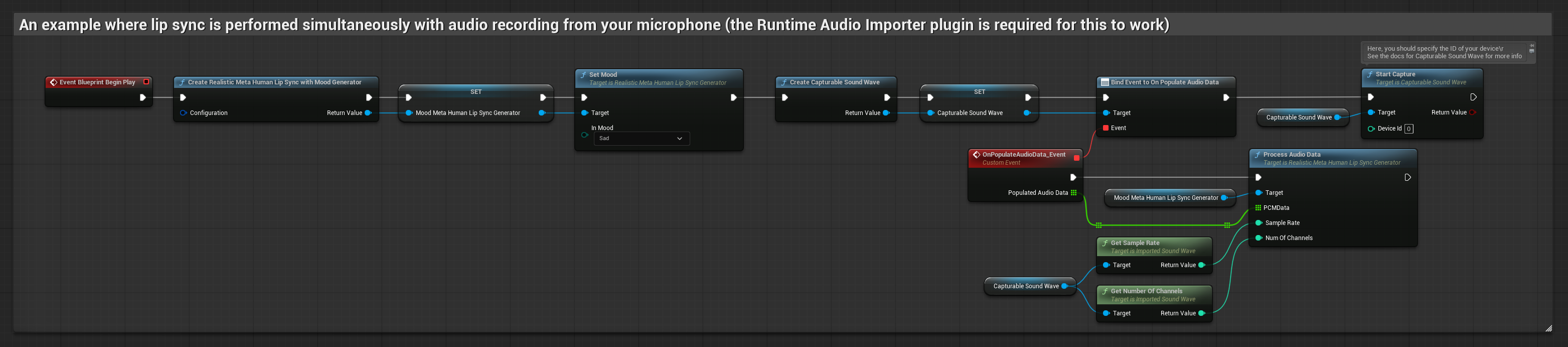
يقوم هذا النهج بمزامنة الشفاه في الوقت الحقيقي أثناء التحدث في الميكروفون:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- أنشئ Capturable Sound Wave باستخدام Runtime Audio Importer
- بالنسبة لنظام Linux مع Pixel Streaming، استخدم Pixel Streaming Capturable Sound Wave بدلاً من ذلك
- قبل البدء في التقاط الصوت، قم بربط مندوب
OnPopulateAudioData - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك - ابدأ في التقاط الصوت من الميكروفون
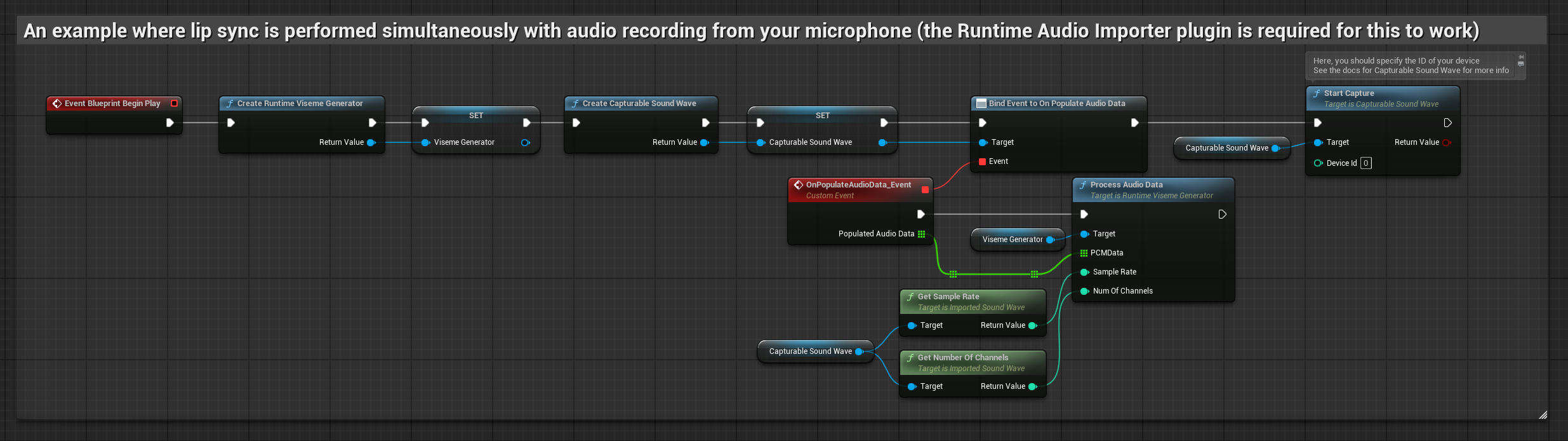
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
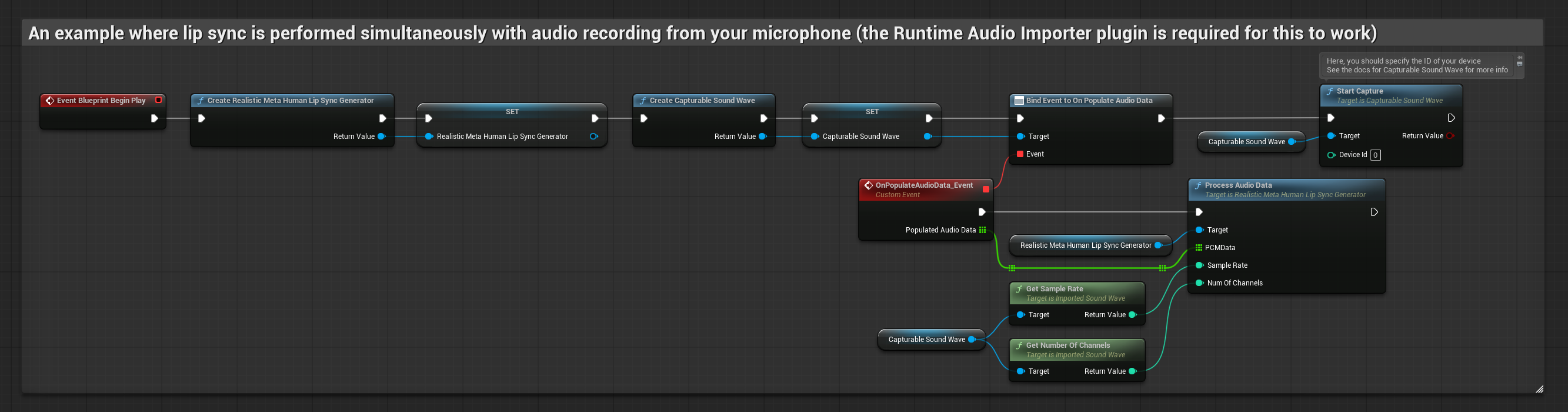
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
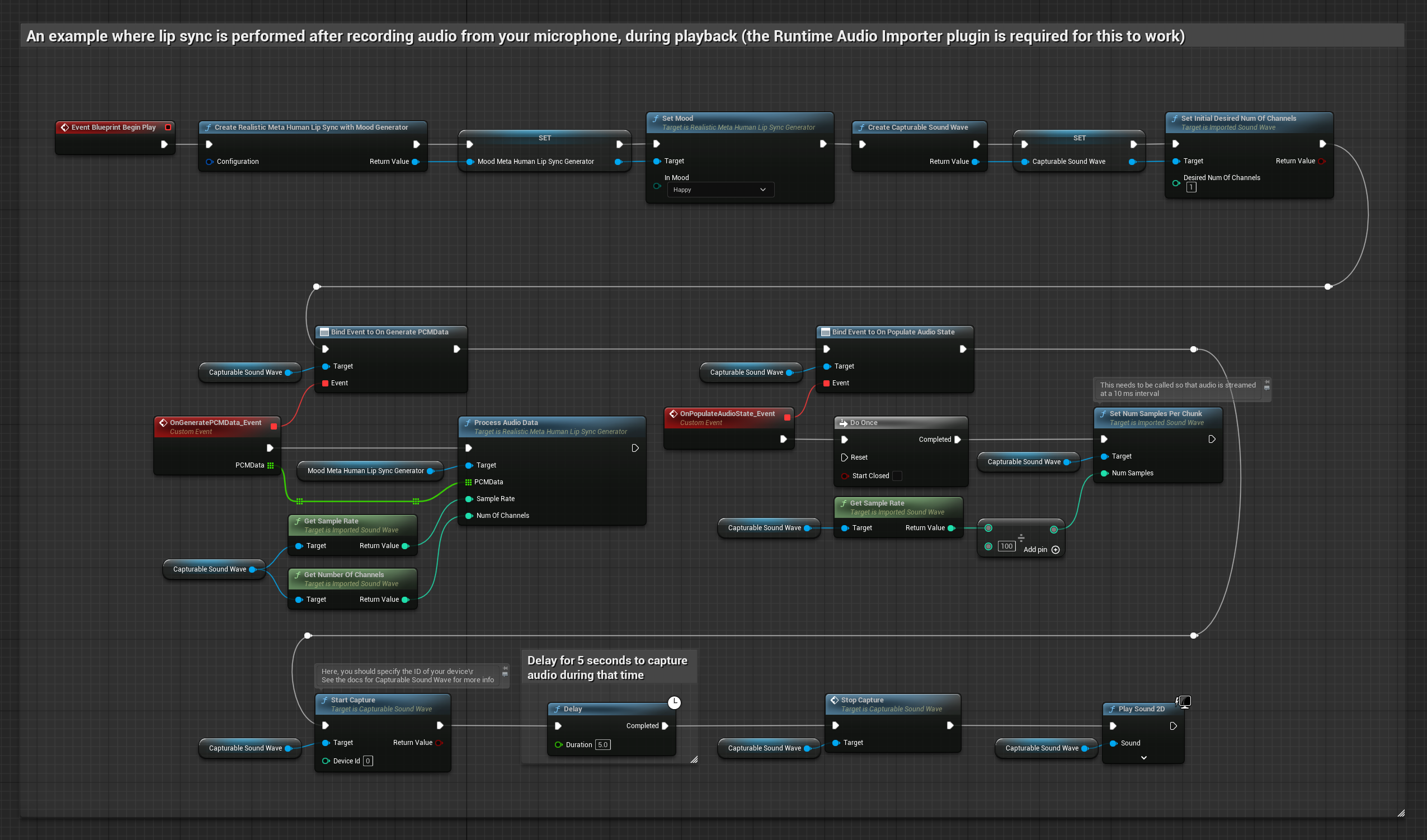
يقوم هذا النهج بالتقاط الصوت من ميكروفون، ثم يعيد تشغيله مع مزامنة الشفاه:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- أنشئ Capturable Sound Wave باستخدام Runtime Audio Importer
- بالنسبة لنظام Linux مع Pixel Streaming، استخدم Pixel Streaming Capturable Sound Wave بدلاً من ذلك
- ابدأ في التقاط الصوت من الميكروفون
- قبل إعادة تشغيل Capturable Sound Wave، قم بربط مندوب
OnGeneratePCMDataالخاص به - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك
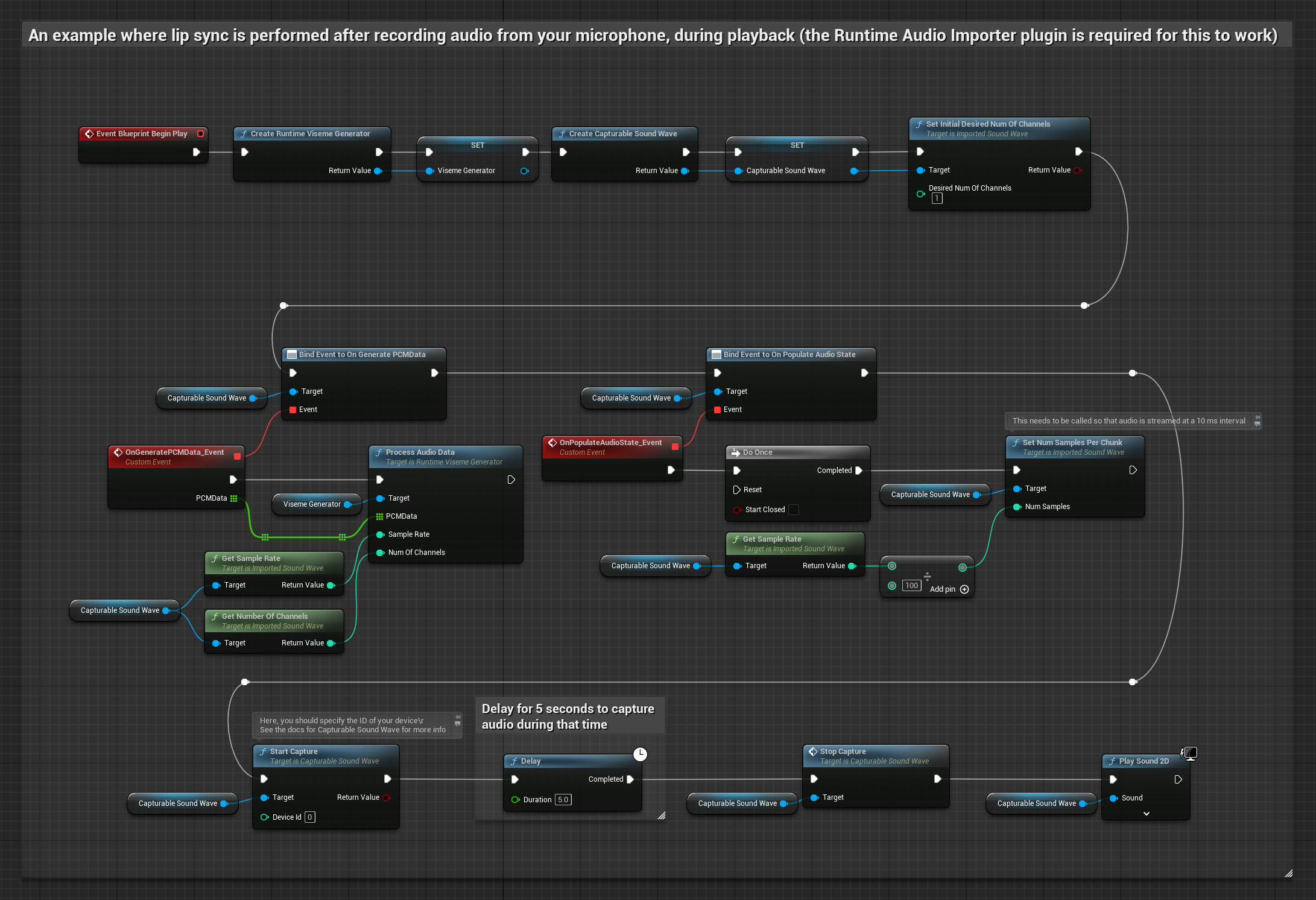
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
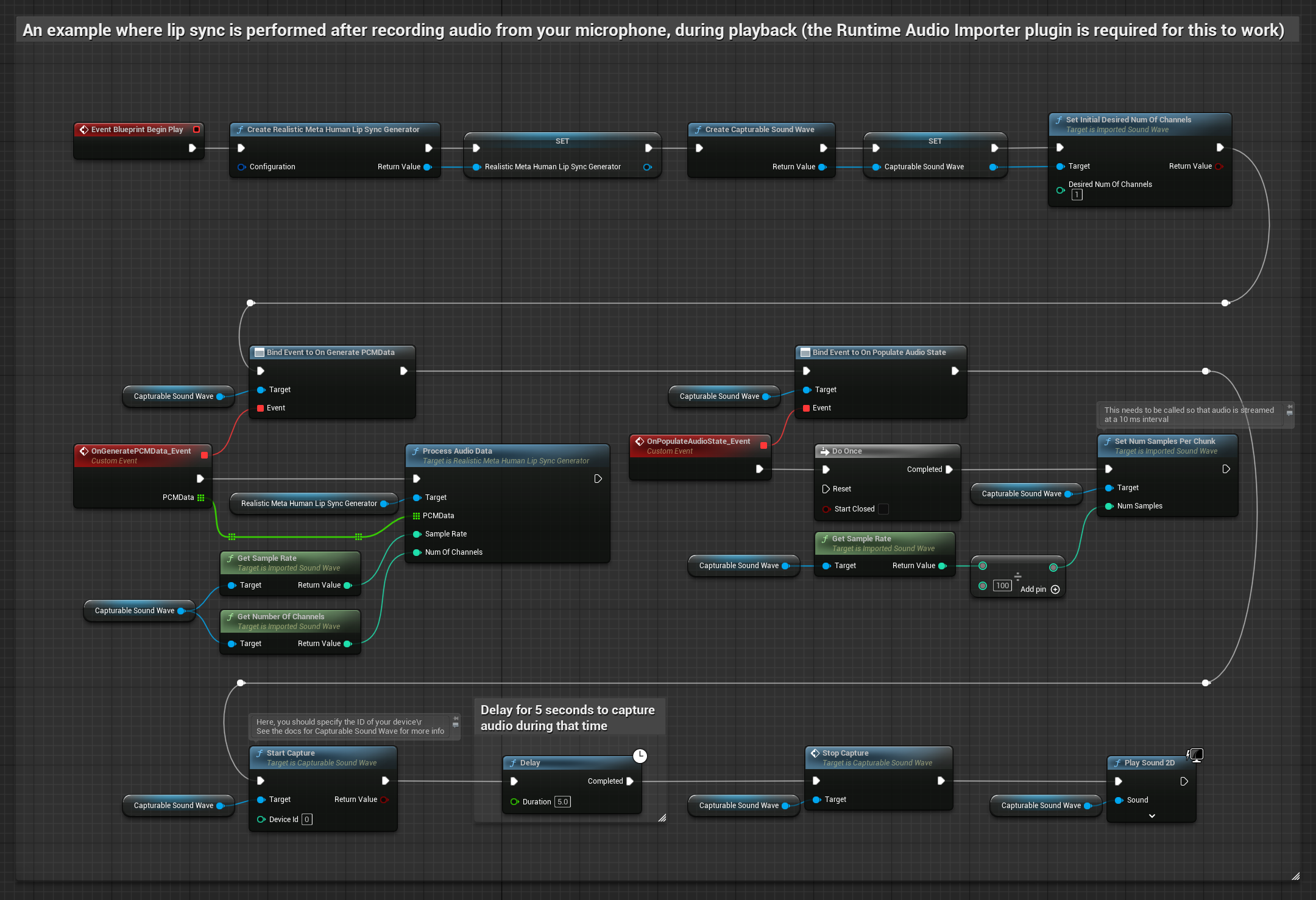
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
- عادي
- البث
يقوم هذا النهج بتوليف الكلام من النص باستخدام TTS محلي ويقوم بمزامنة الشفاه:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- استخدم Runtime Text To Speech لتوليف الكلام من النص
- استخدم Runtime Audio Importer لاستيراد الصوت المُولَّف
- قبل إعادة تشغيل Sound Wave المستورد، قم بربط مندوب
OnGeneratePCMDataالخاص به - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
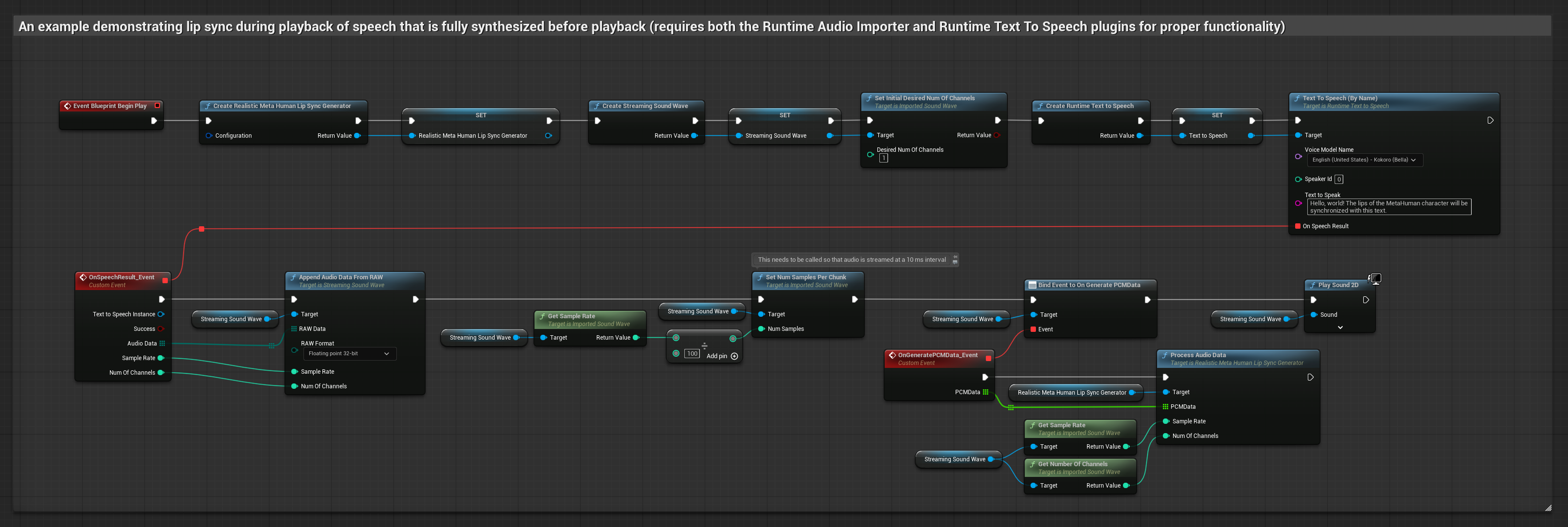
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
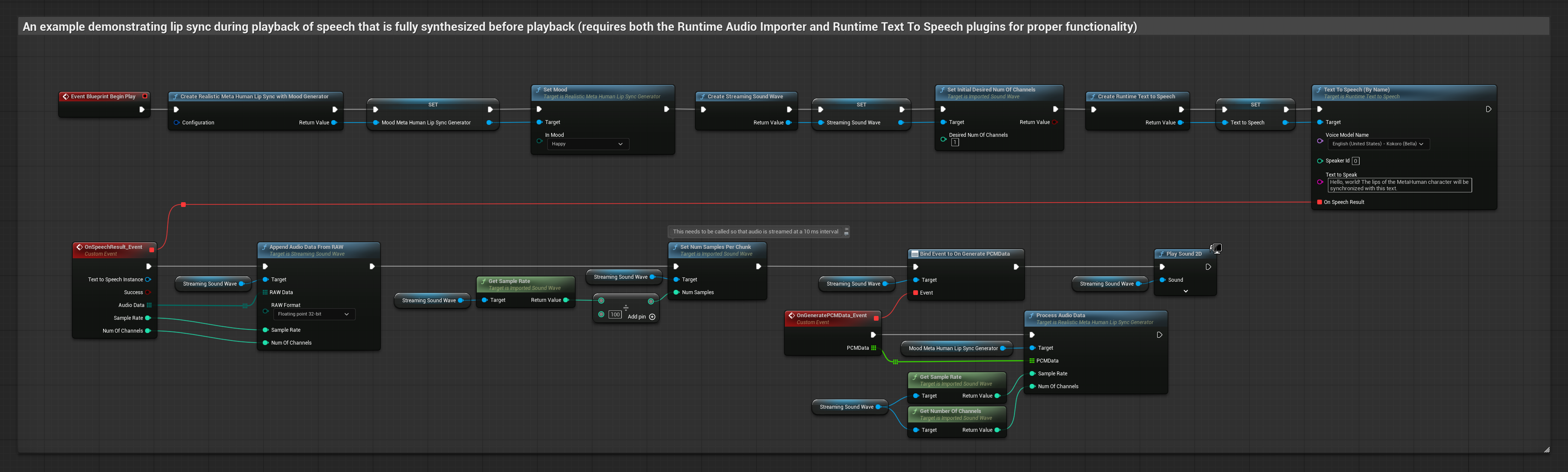
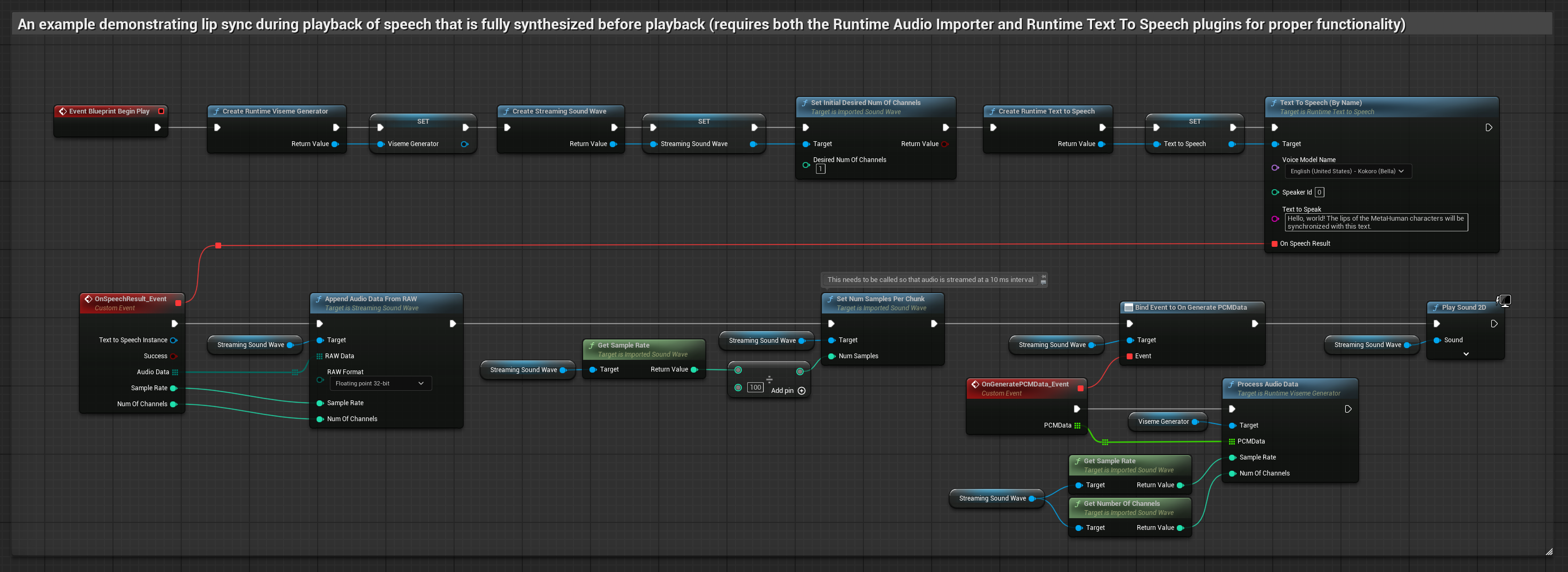
يقوم هذا النهج باستخدام توليف تحويل النص إلى كلام مع البث ومزامنة الشفاه في الوقت الحقيقي:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- استخدم Runtime Text To Speech لتوليف كلام مع البث من النص
- استخدم Runtime Audio Importer لاستيراد الصوت المُولَّف
- قبل إعادة تشغيل Streaming Sound Wave، قم بربط مندوب
OnGeneratePCMDataالخاص به - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك
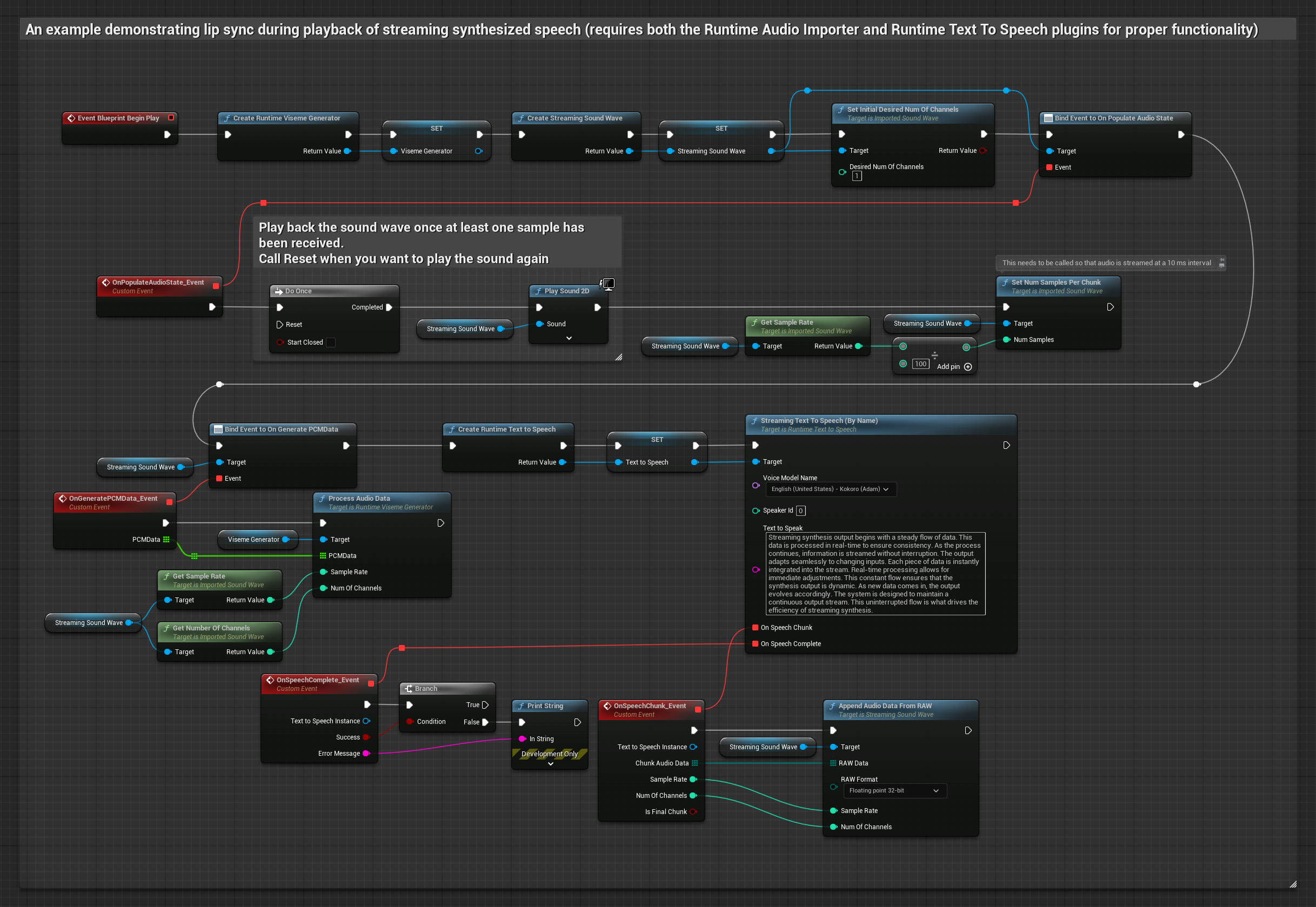
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
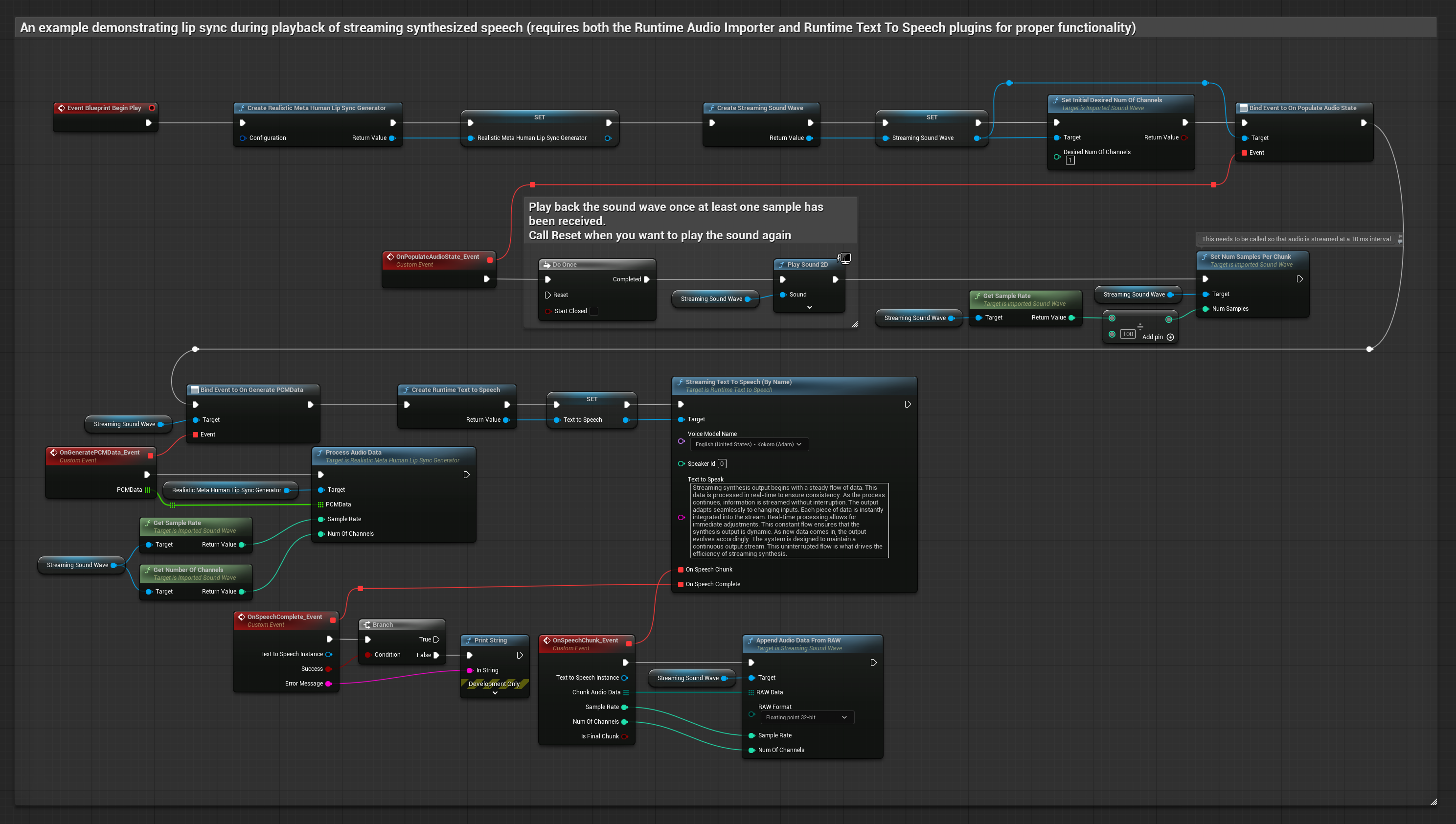
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
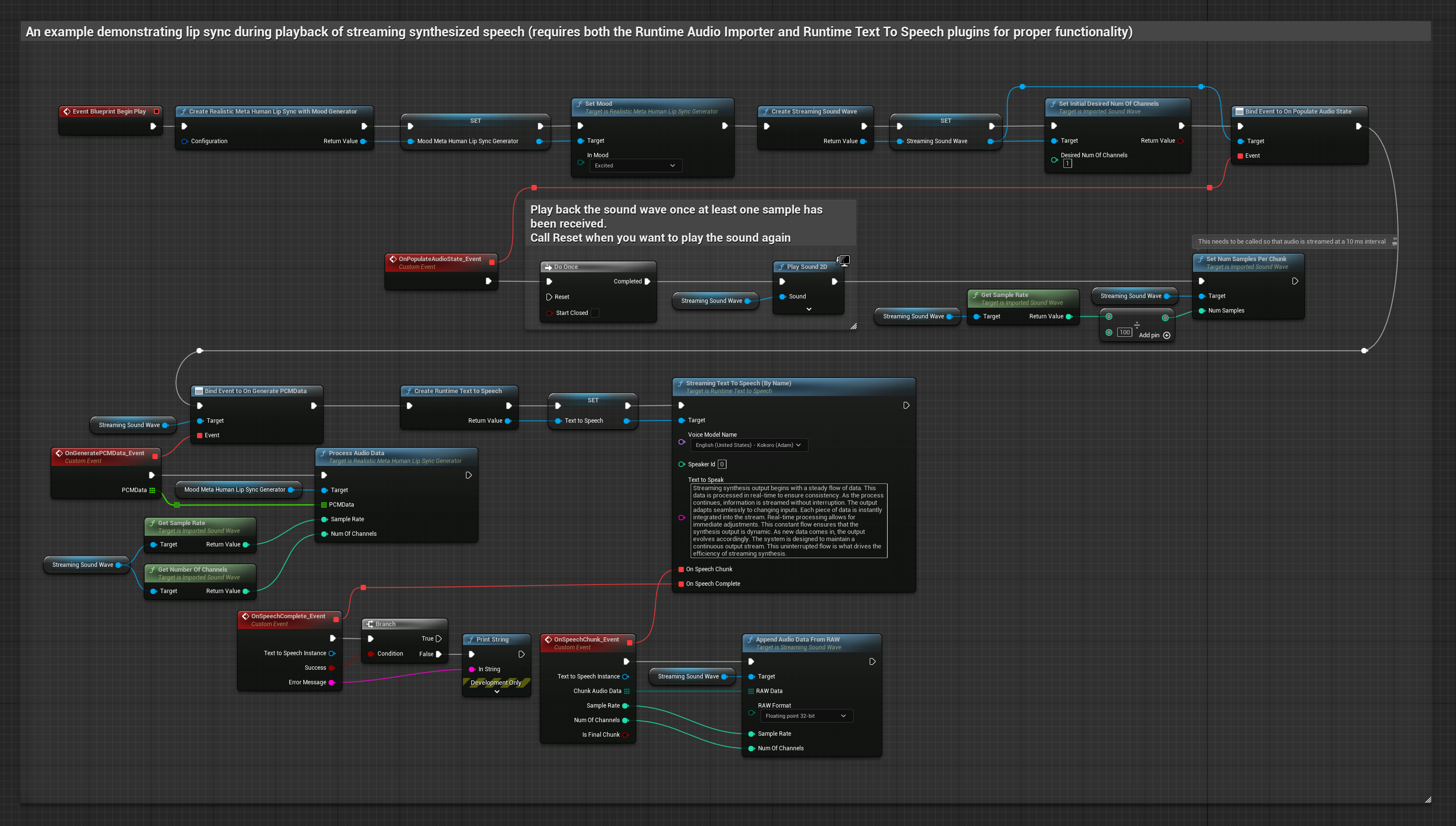
- عادي
- البث
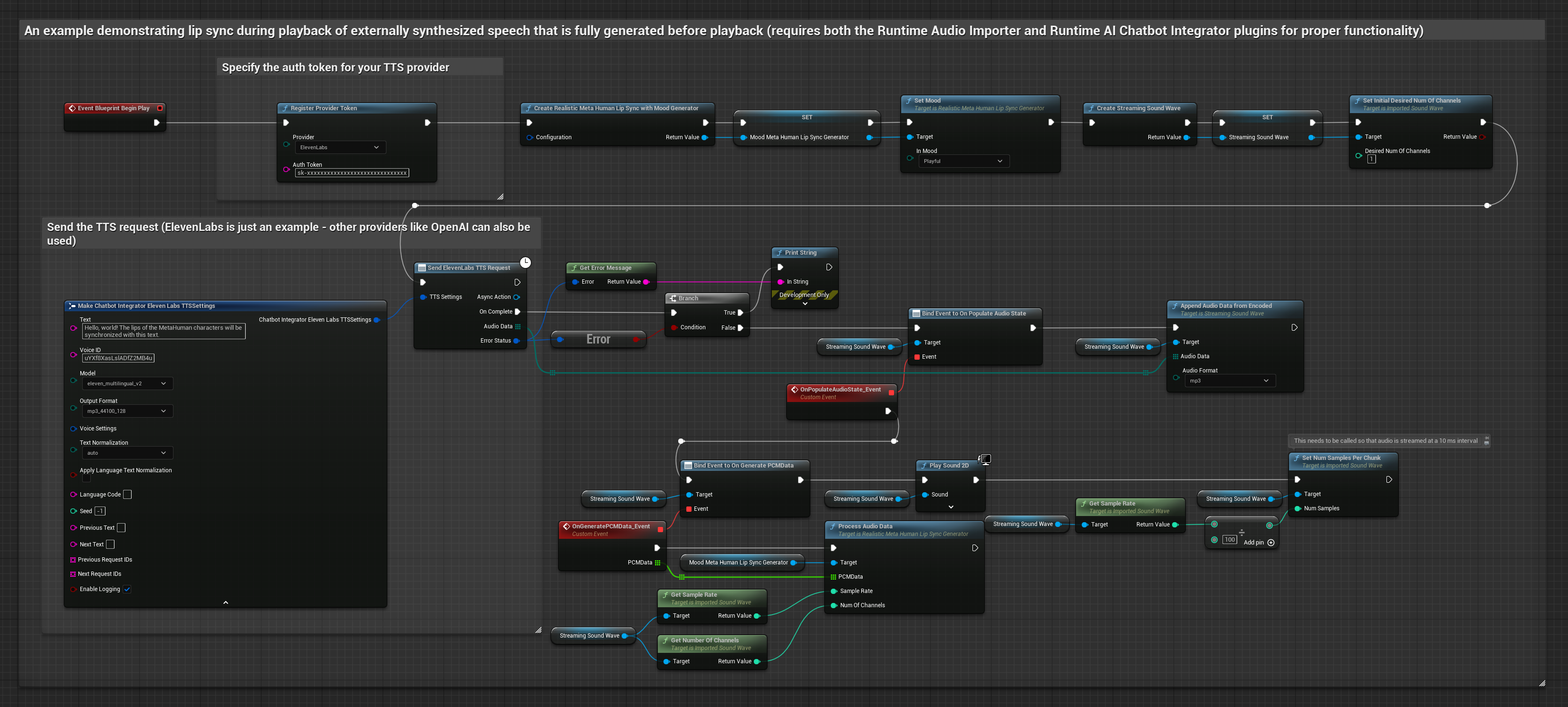
يقوم هذا النهج باستخدام مكون Runtime AI Chatbot Integrator الإضافي لتوليف الكلام من خدمات الذكاء الاصطناعي (OpenAI أو ElevenLabs) وإجراء مزامنة الشفاه:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- استخدم Runtime AI Chatbot Integrator لتوليف الكلام من النص باستخدام واجهات برمجة تطبيقات خارجية (OpenAI، ElevenLabs، إلخ.)
- استخدم Runtime Audio Importer لاستيراد بيانات الصوت المُولَّفة
- قبل إعادة تشغيل Sound Wave المستورد، قم بربط مندوب
OnGeneratePCMDataالخاص به - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك
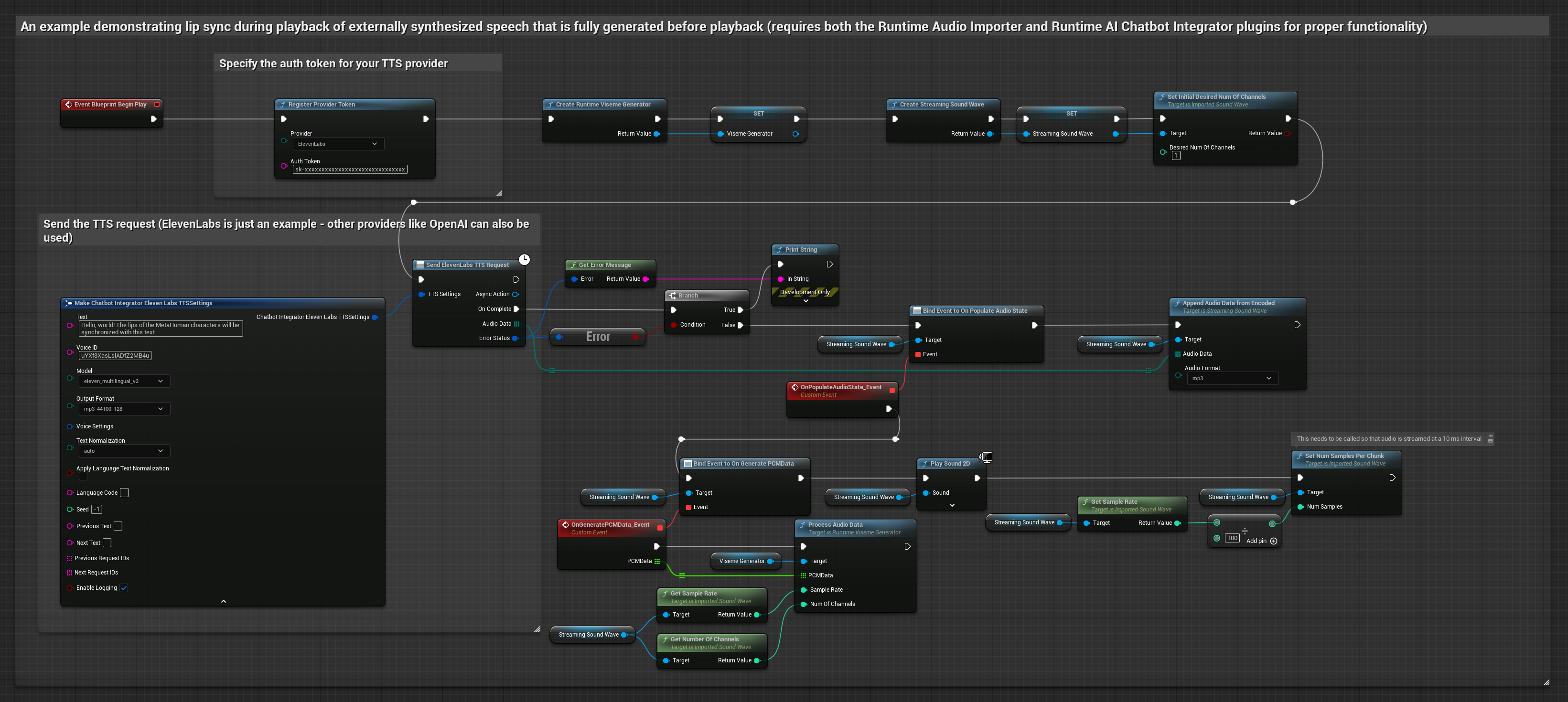
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
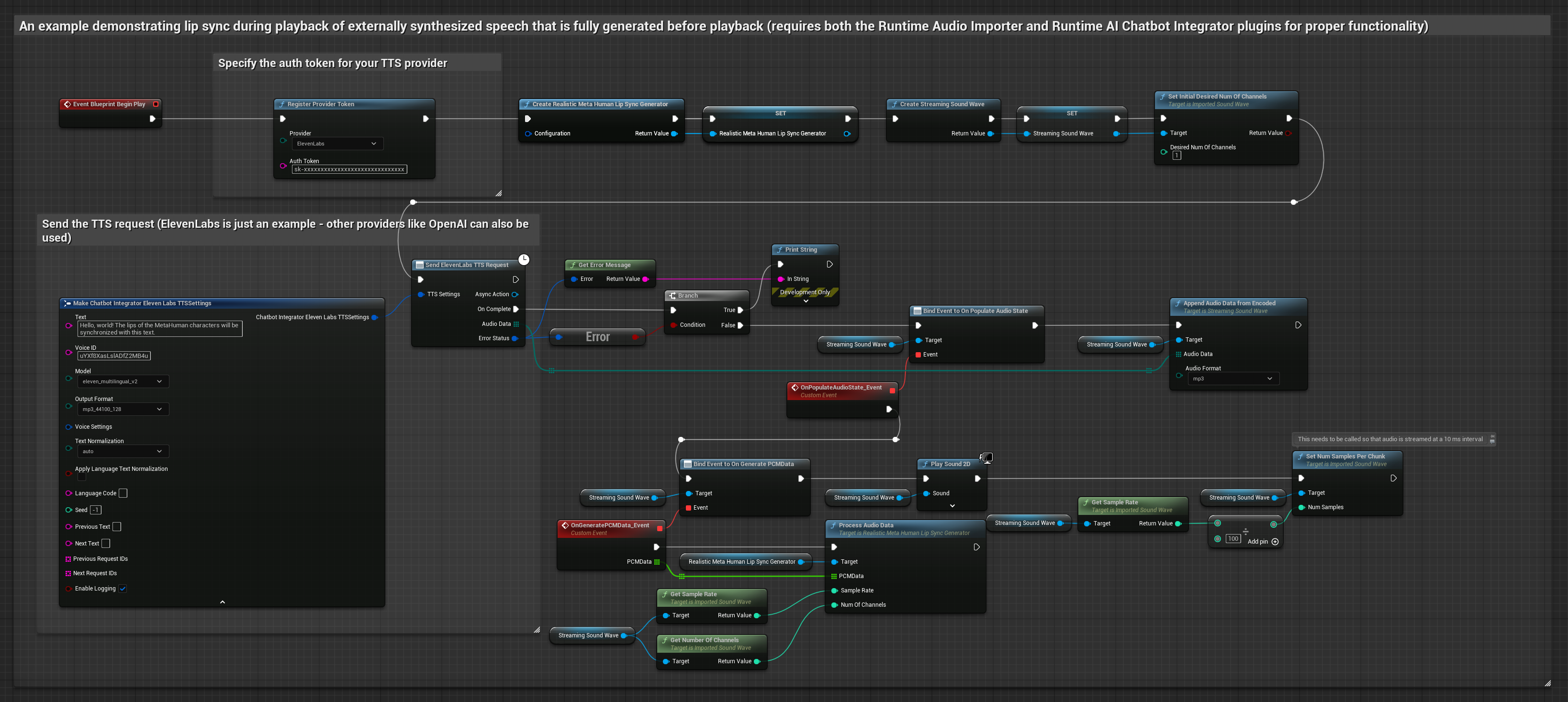
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
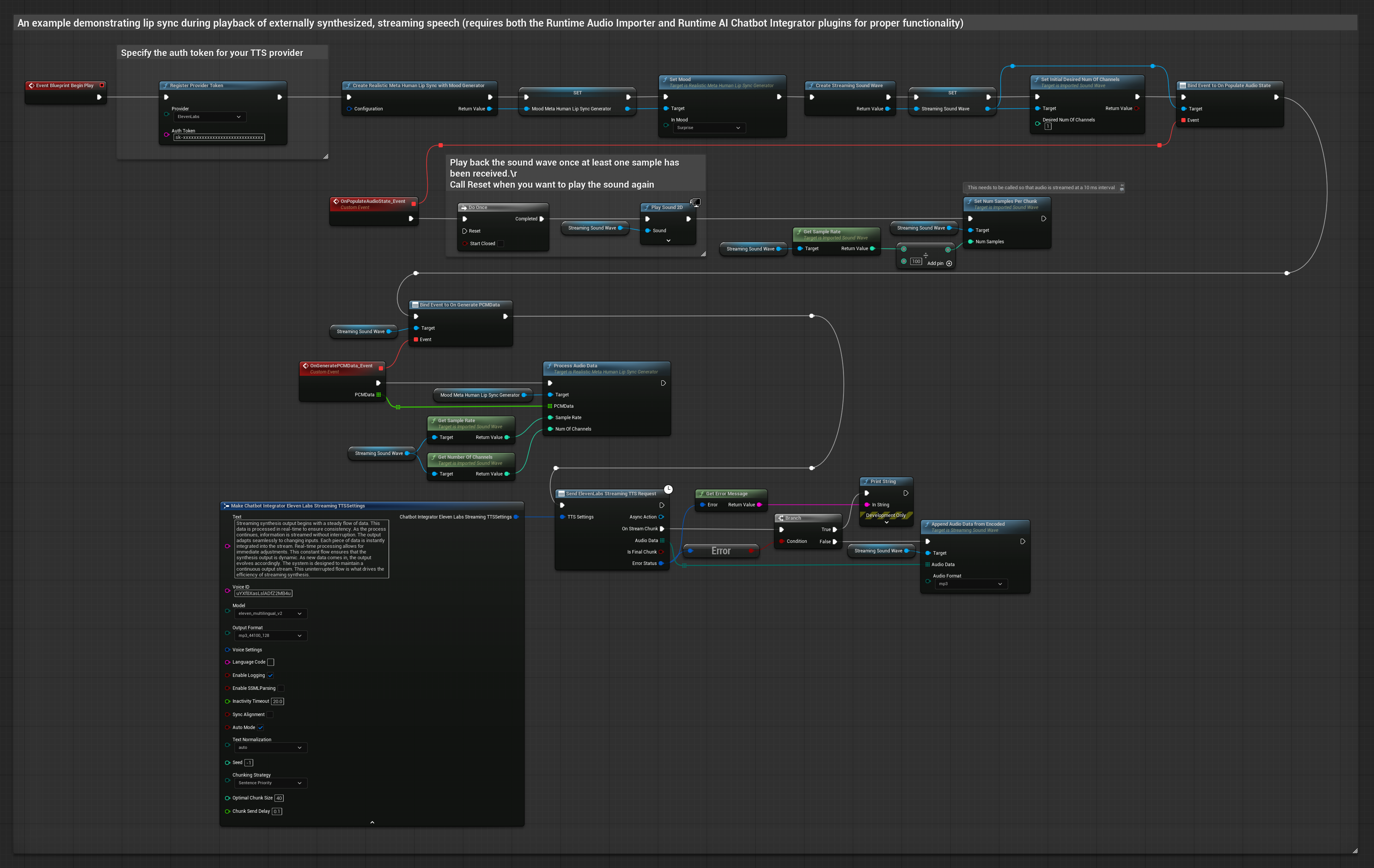
يقوم هذا النهج باستخدام مكون Runtime AI Chatbot Integrator الإضافي لتوليف كلام مع البث من خدمات الذكاء الاصطناعي (OpenAI أو ElevenLabs) وإجراء مزامنة الشفاه:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- استخدم Runtime AI Chatbot Integrator للاتصال بواجهات برمجة تطبيقات TTS مع البث (مثل ElevenLabs Streaming API)
- استخدم Runtime Audio Importer لاستيراد بيانات الصوت المُولَّفة
- قبل إعادة تشغيل Streaming Sound Wave، قم بربط مندوب
OnGeneratePCMDataالخاص به - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك
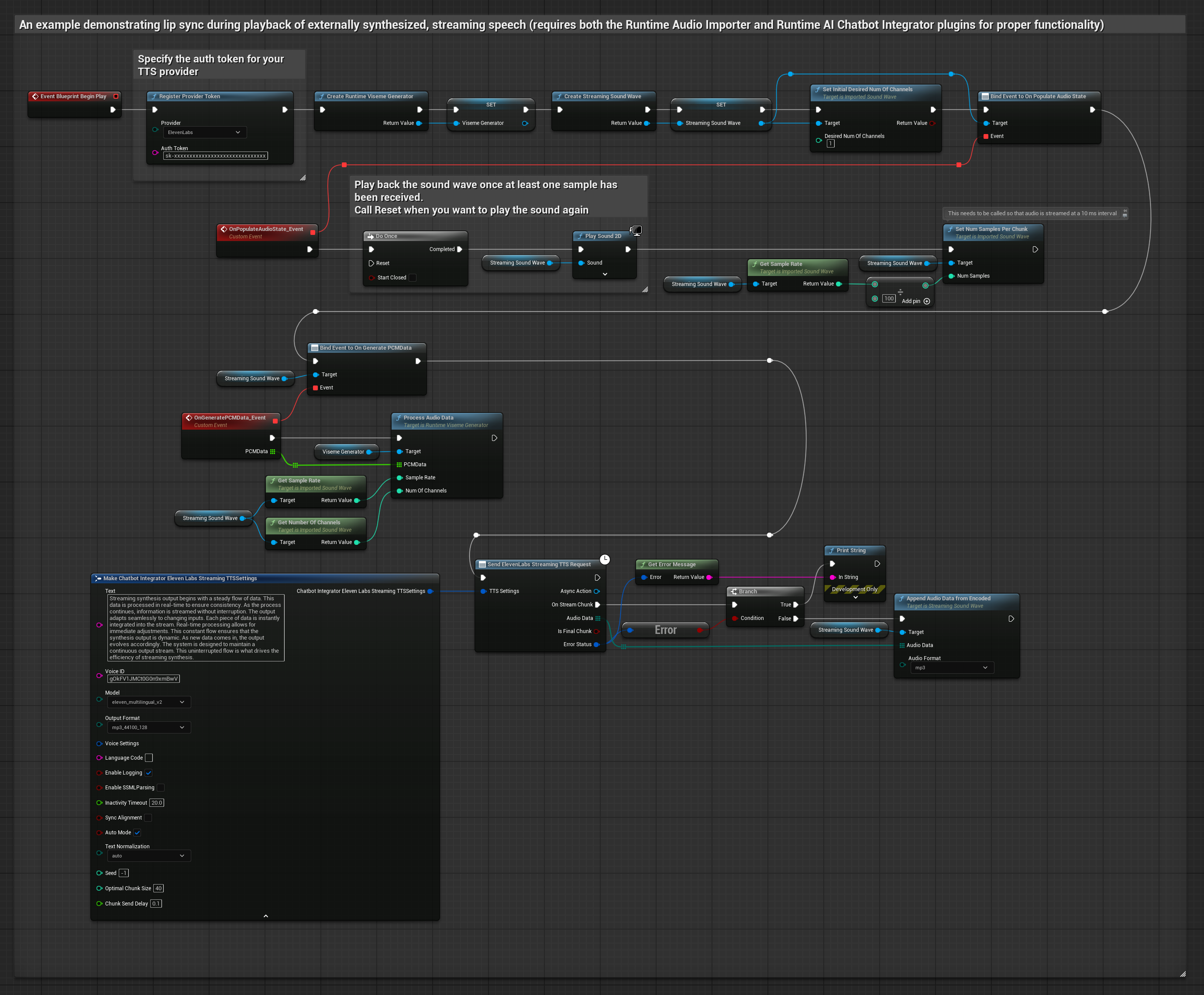
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
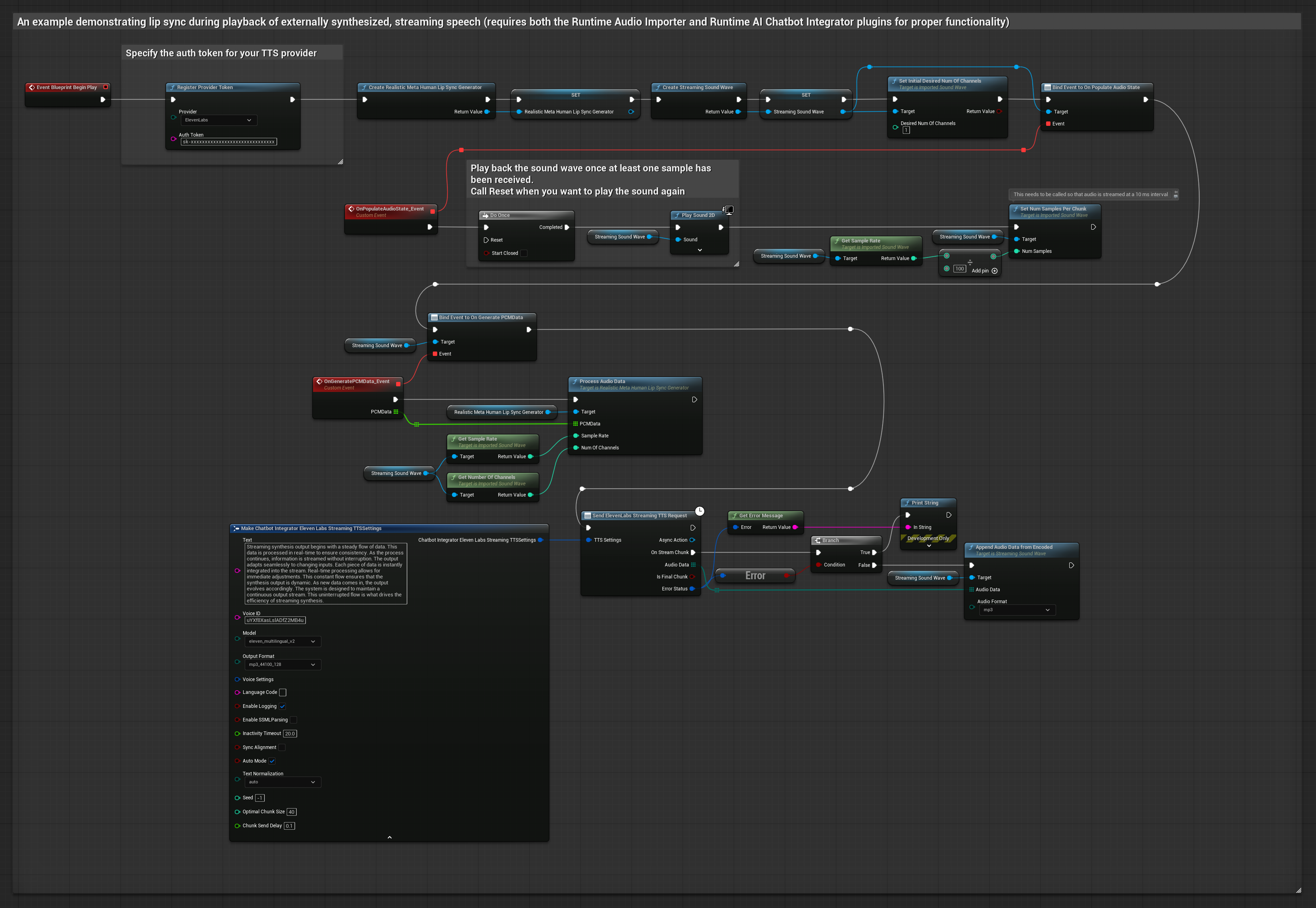
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
يستخدم هذا النهز ملفات صوت مسجلة مسبقًا أو مخازن مؤقتة للصوت لمزامنة الشفاه:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- استخدم Runtime Audio Importer لـاستيراد ملف صوت من القرص أو الذاكرة
- قبل إعادة تشغيل Sound Wave المستورد، قم بربط مندوب
OnGeneratePCMDataالخاص به - في الوظيفة المقيدة، استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك - شغل Sound Wave المستورد ولاحظ حركة مزامنة الشفاه
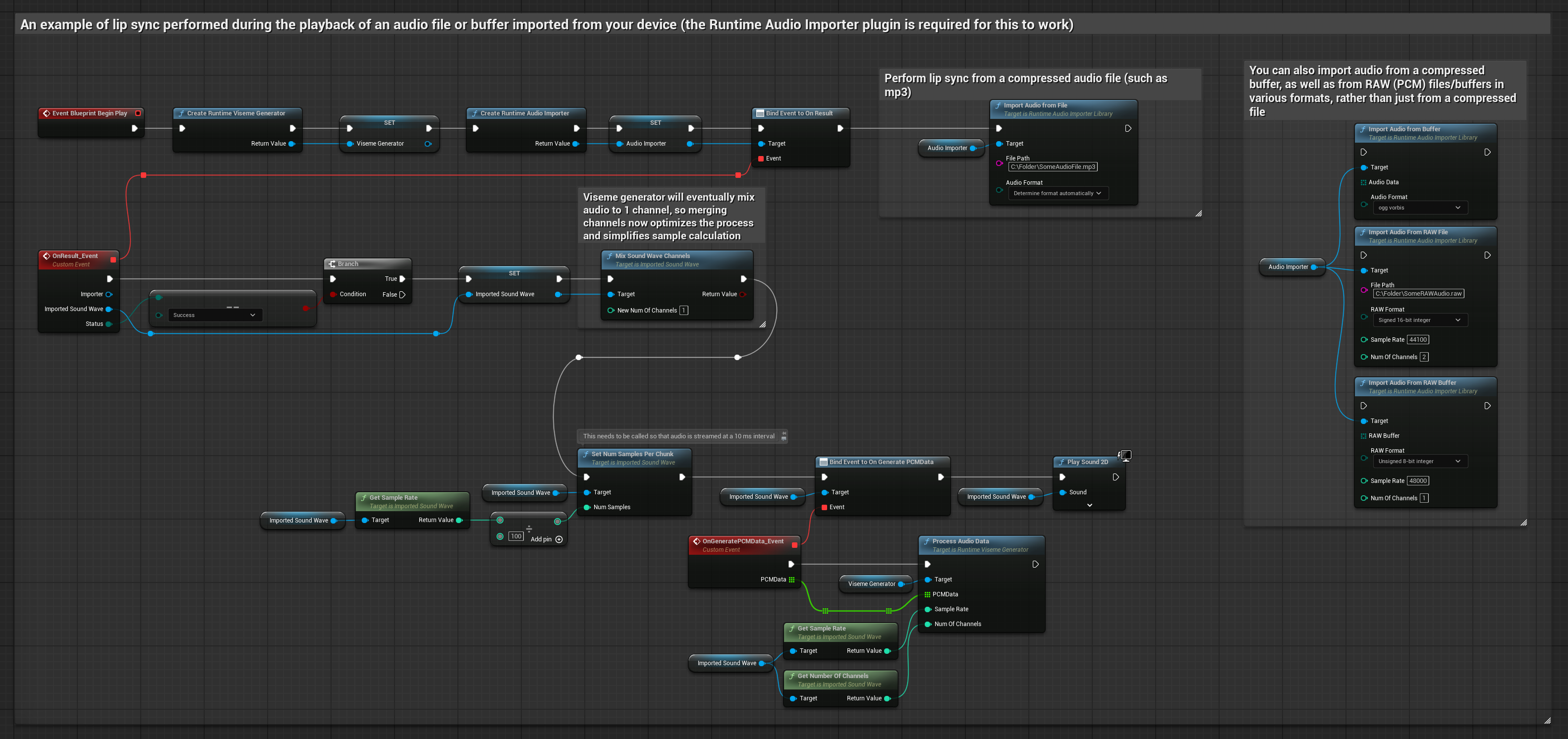
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
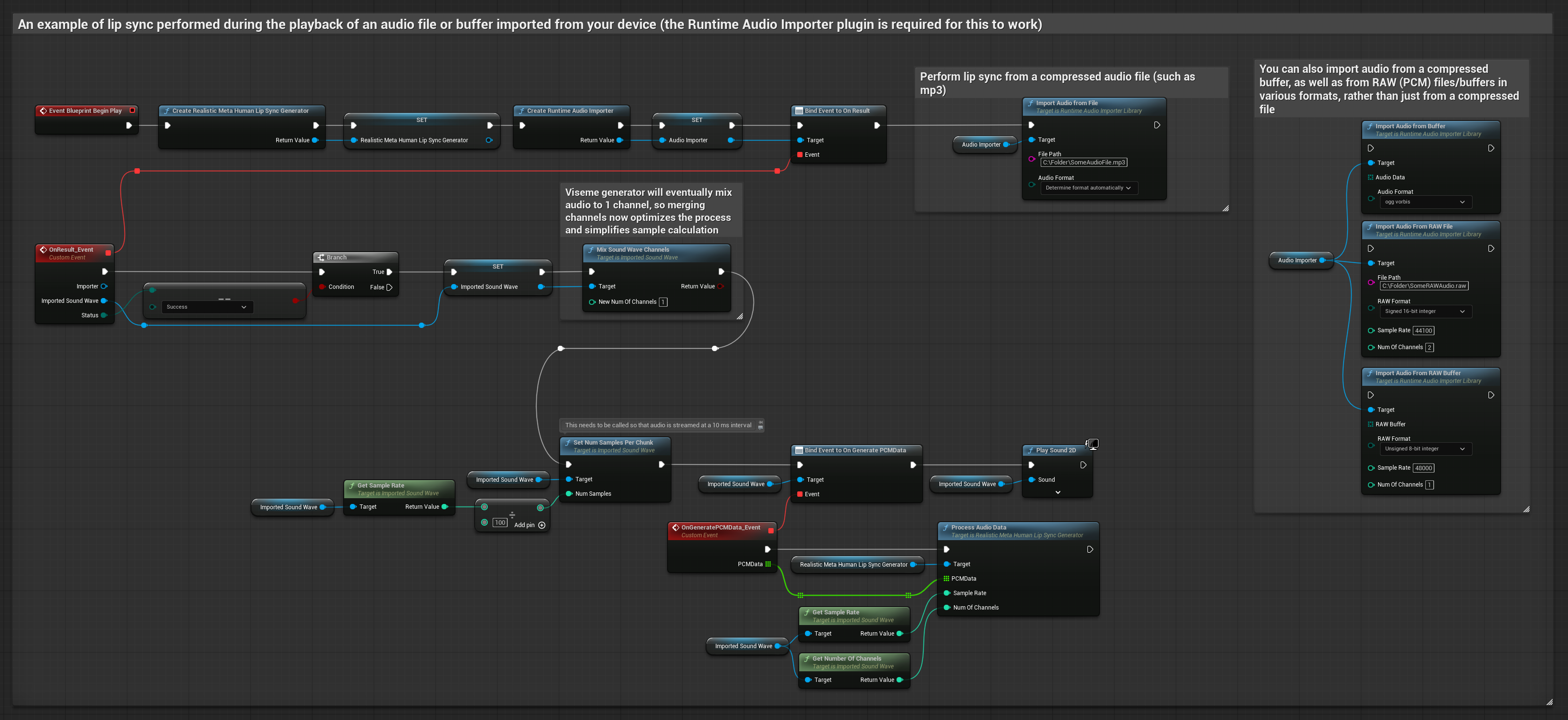
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
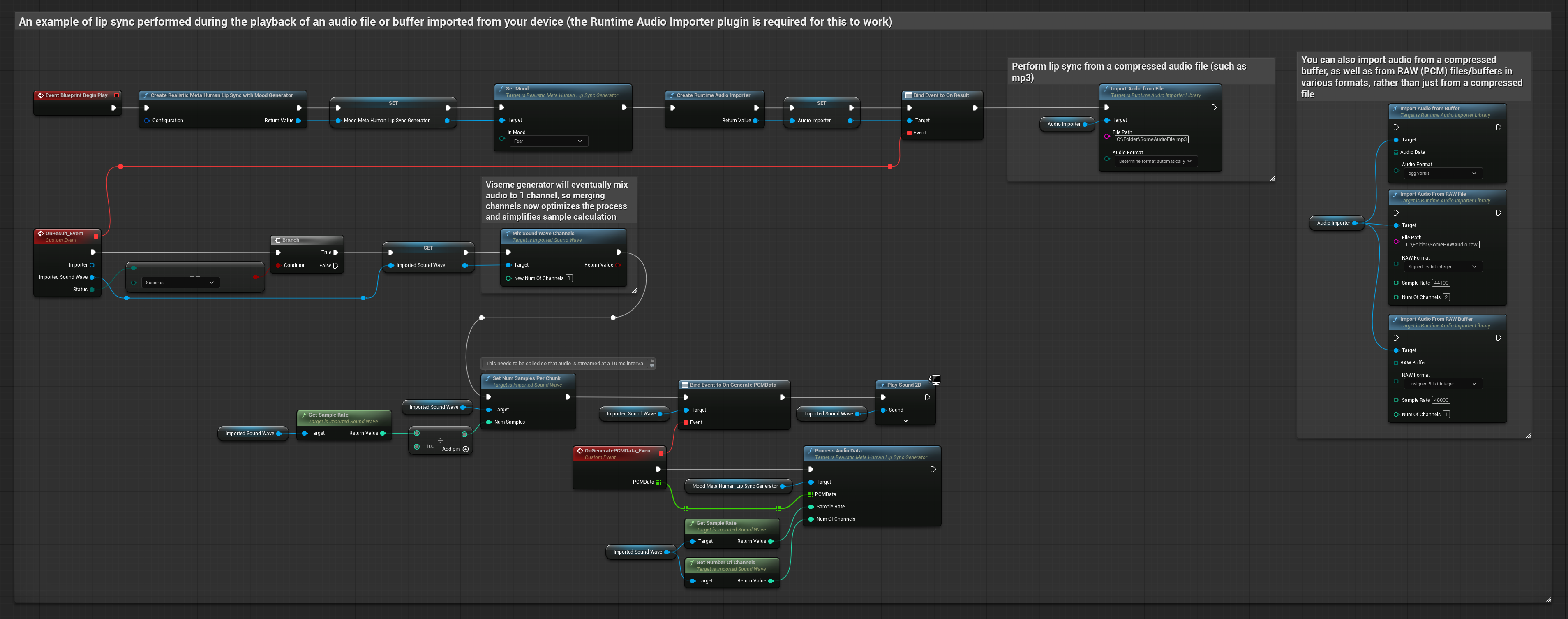
لبيانات الصوت مع البث من مخزن مؤقت، تحتاج إلى:
- النموذج القياسي
- النموذج الواقعي
- النموذج الواقعي المدعوم بالمزاج
- بيانات صوت بتنسيق PCM عائم (مصفوفة من عينات النقطة العائمة) متاحة من مصدر البث الخاص بك (أو استخدم Runtime Audio Importer لدعم المزيد من التنسيقات)
- معدل العينات وعدد القنوات
- استدعِ
ProcessAudioDataمن Runtime Viseme Generator الخاص بك مع هذه المعلمات عند توفر مقاطع الصوت
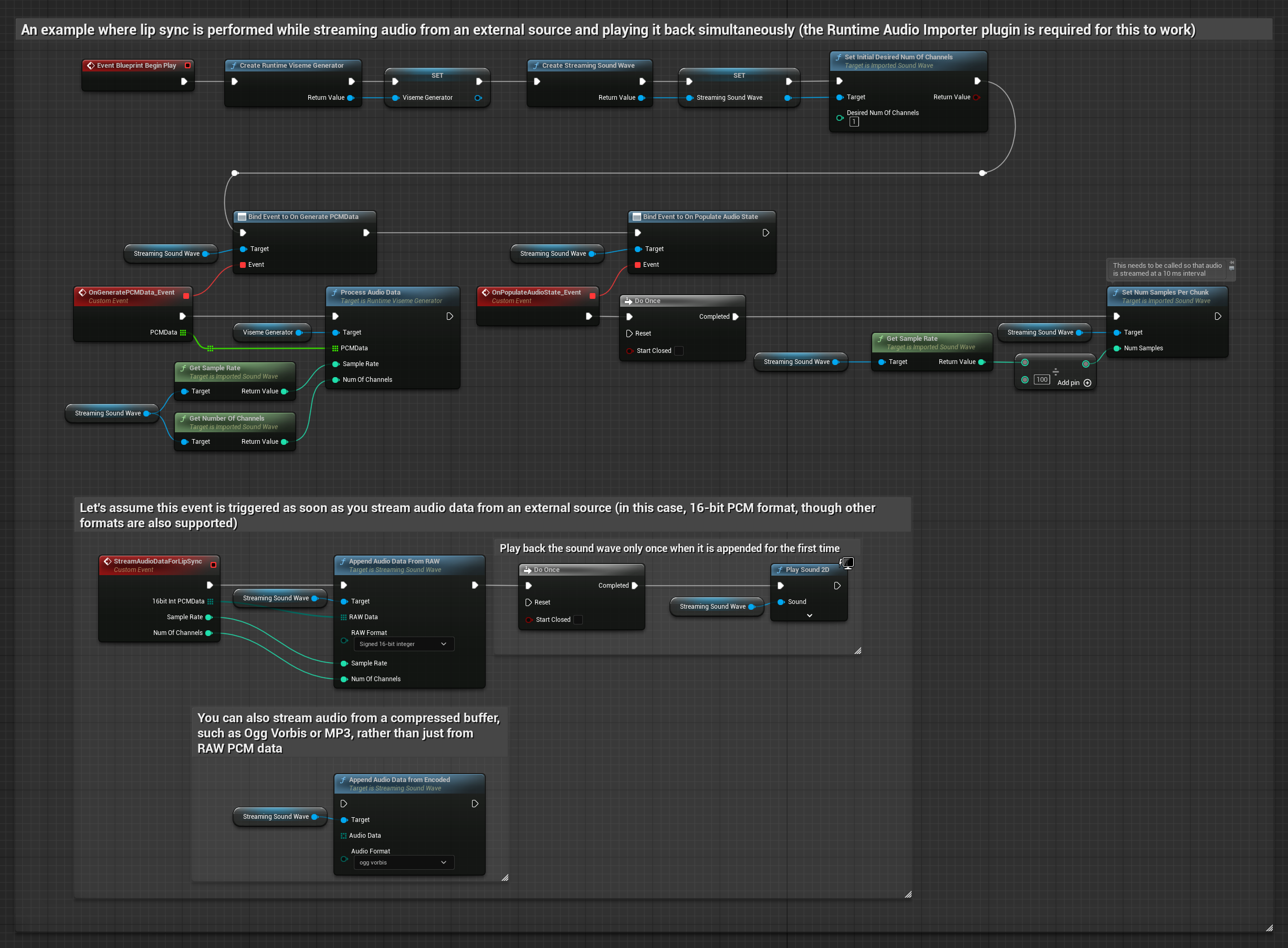
يستخدم النموذج الواقعي نفس سير عمل معالجة الصوت مثل النموذج القياسي، ولكن مع متغير RealisticLipSyncGenerator بدلاً من VisemeGenerator.
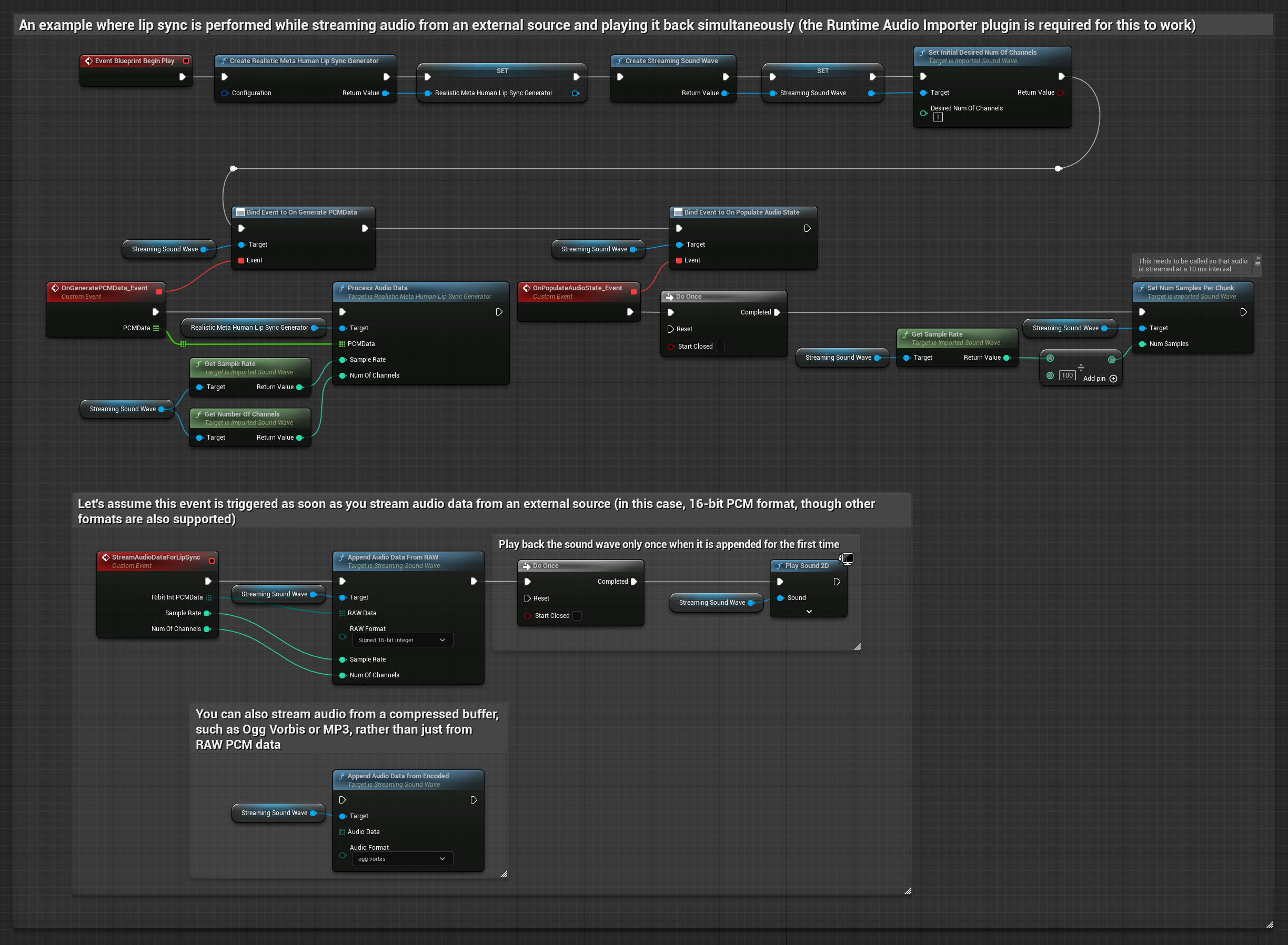
يستخدم النموذج المدعوم بالمزاج نفس سير عمل معالجة الصوت، ولكن مع متغير MoodMetaHumanLipSyncGenerator وقدرات تكوين مزاج إضافية.
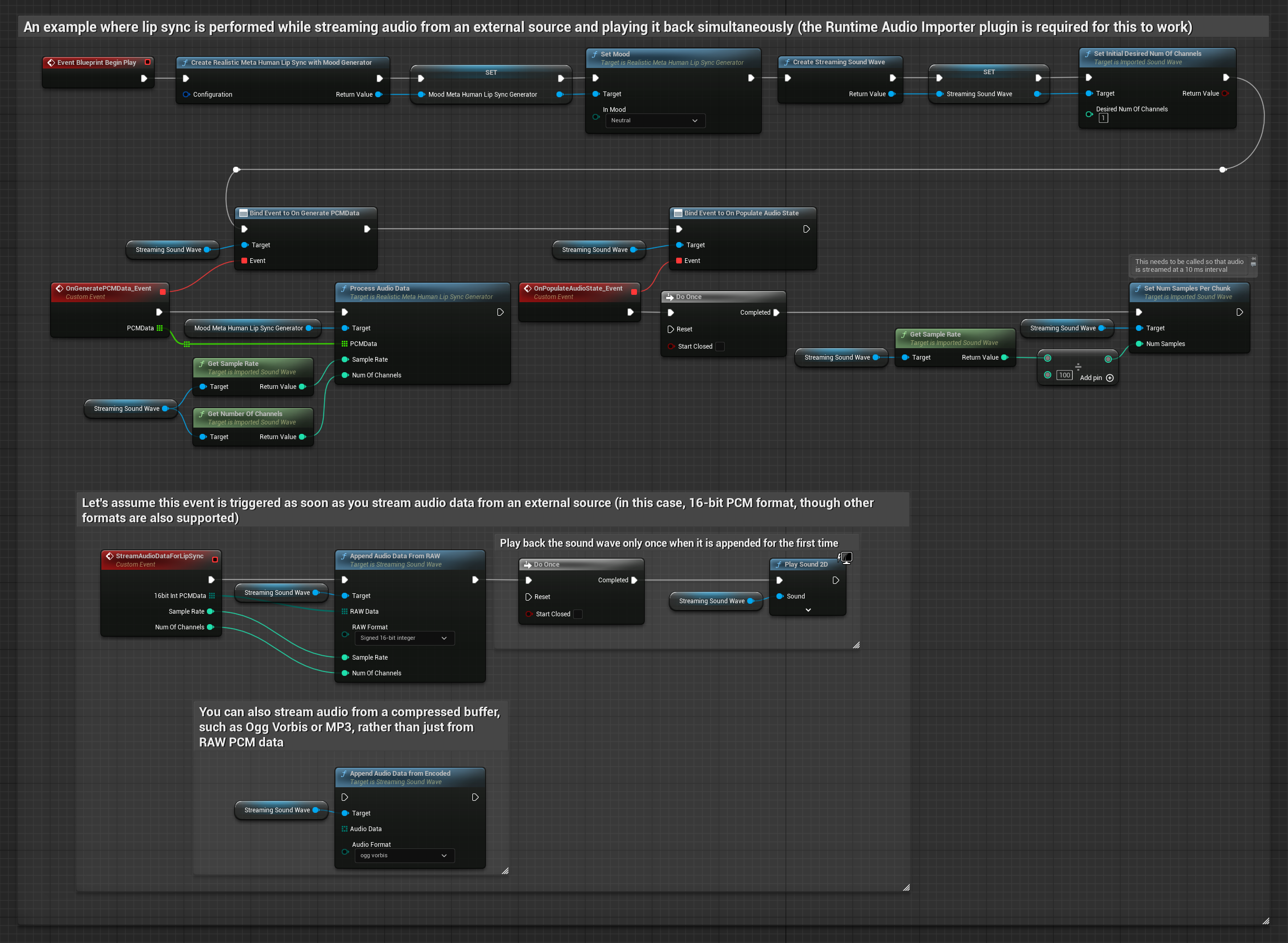
ملاحظة: عند استخدام مصادر صوت مع البث، تأكد من إدارة توقيت تشغيل الصوت بشكل مناسب لتجنب تشويه التشغيل. راجع توثيق Streaming Sound Wave لمزيد من المعلومات.
نصائح أداء المعالجة
-
حجم المقطع: يمكن أن يؤدي زيادة خيار التكوين
ProcessingChunkSize(على سبيل المثال إلى 320 أو 480 أو 640 عينة) إلى تحسين زمن الوصول بشكل ملحوظ مع تأثير ضئيل على الجودة أو الاستجابة. -
نوع النموذج: عند استخدام النماذج الواقعية، يمكن أن يؤدي التبديل إلى نوع النموذج المُحسَّن للغاية (المحدد افتراضيًا) إلى تحسين الأداء. لاحظ أن النموذج الأصلي قد ينتج جودة أفضل قليلاً، خاصة مع الصوت المشوش.
-
إدارة المخزن المؤقت: يعالج النموذج المدعوم بالمزاج الصوت في إطارات من 320 عينة (20 مللي ثانية عند 16 كيلو هرتز). تأكد من محاذاة توقيت إدخال الصوت الخاص بك مع هذا للحصول على أداء مثالي.
-
إعادة إنشاء المولد: للتشغيل الموثوق مع النماذج الواقعية، أعد إنشاء المولد في كل مرة تريد فيها تغذية بيانات صوت جديدة بعد فترة من الخمول.
الخطوات التالية
بمجرد إعداد معالجة الصوت، قد ترغب في:
- التعرف على خيارات التكوين لضبط سلوك مزامنة الشفاه الخاص بك
- إضافة حركة الضحك لتحسين التعبير
- دمج مزامنة الشفاه مع حركات الوجه الحالية باستخدام تقنيات الطبقة الموضحة في دليل التكوين