مشاريع العرض التوضيحي
لمساعدتك في البدء بسرعة مع Runtime MetaHuman Lip Sync، يتوفر مشروعان تجريبيان جاهزان للاستخدام. كلاهما مبنيان باستخدام Unreal Engine 5.6+، ويعتمدان على Blueprint-only، ويعملان عبر المنصات على Windows, Mac, Linux, iOS, Android، والمنصات المبنية على Android (بما في ذلك Meta Quest).
مشاريع العرض التوضيحي المتاحة
- شخصية محادثة بالذكاء الاصطناعي / صورة رمزية تفاعلية
- Basic Lip Sync Demo
سير عمل كامل للصورة الرمزية التفاعلية القائمة على الذكاء الاصطناعي يجمع بين التعرف على الكلام، وبوت محادثة ذكي (LLM)، وتحويل النص إلى كلام، وتشغيل الصوت مع مزامنة الشفاه في الوقت الفعلي - كل ذلك يعمل معًا في مشروع واحد. مناسب لمجموعة واسعة من حالات الاستخدام — بما في ذلك الألعاب، والأكشاك التفاعلية، والإنتاج الافتراضي، وتركيبات المتاحف، والمساعدين الرقميين، ومحاكاة التدريب.
نظرة عامة على خط الأنابيب
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
مقاطع فيديو
معاينة سريعة (~30 ثانية)
عرض سريع للعرض التوضيحي أثناء عمله.
شرح كامل
شرح تفصيلي يغطي الإعداد والتهيئة وخط أنابيب المحادثة بالكامل.
تحميلات
المكونات الإضافية المطلوبة والاختيارية
المشروع التجريبي هو وحداتي - لا تحتاج سوى المكونات الإضافية للمزودين الذين ترغب في استخدامهم.
| المكون الإضافي | الغرض | مطلوب؟ |
|---|---|---|
| Runtime MetaHuman Lip Sync | تحريك تزامن الشفاه | ✅ دائماً |
| Runtime Audio Importer | التقاط الصوت ومعالجته | ✅ دائماً |
| Runtime Speech Recognizer | التعرف على الكلام دون اتصال (whisper.cpp) | ✅ دائماً |
| Runtime AI Chatbot Integrator | نماذج لغوية خارجية (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) و/أو تحويل نص إلى كلام خارجي (OpenAI, ElevenLabs) | 🔶 اختياري |
| Runtime Local LLM | استدلال نموذج لغة محلي عبر llama.cpp (نماذج GGUF مثل Llama, Mistral, Gemma, إلخ) | 🔶 اختياري |
| Runtime Text To Speech | تحويل نص إلى كلام محلي عبر Piper و Kokoro | 🔶 اختياري |
مع أن كل مكون إضافي في الجدول اختياري بذاته، إلا أنك تحتاج إلى مزود LLM واحد على الأقل و مزود TTS واحد على الأقل لكي يعمل العرض التوضيحي. يمكنك المزج والمطابقة بحرية (مثلاً LLM محلي + ElevenLabs TTS، أو OpenAI LLM + TTS محلي).
المعمارية الوحداتية
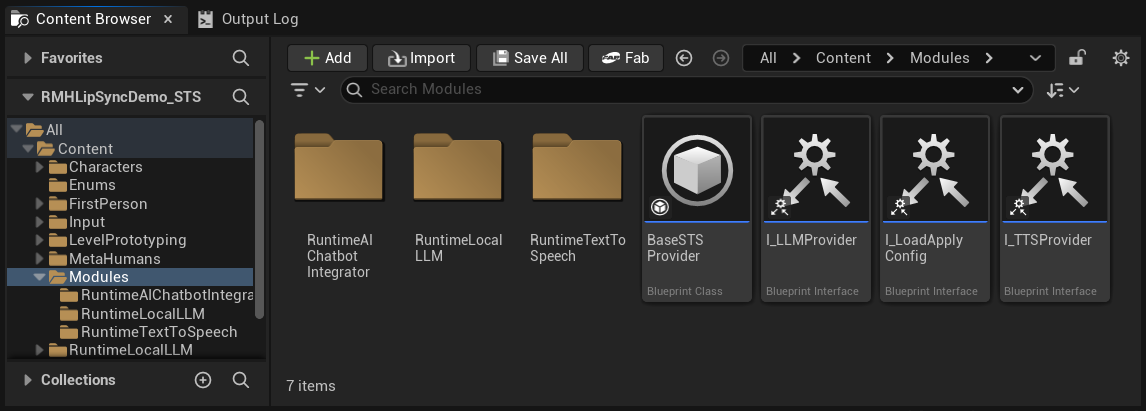
في مجلد Content ستجد مجلد Modules يحتوي على ثلاثة مجلدات فرعية:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
إذا لم تحصل على واحد (أو أكثر) من الإضافات الاختيارية، فما عليك سوى حذف المجلد (المجلدات) المقابلة. أصول المشروع التجريبي الأساسية (مثيل اللعبة، وعناصر واجهة المستخدم، وما إلى ذلك) لا تشير إلى هذه الوحدات مباشرة، لذا لن يتسبب حذفها في أخطاء مرجعية. ستخفي واجهة التكوين تلقائيًا أي مزود يكون مجلده مفقودًا.
تنطبق هذه الوحدات النمطية على مزودي LLM و TTS فقط. التعرف على الكلام (Runtime Speech Recognizer) و مزامنة الشفاه (Runtime MetaHuman Lip Sync) هما جزء من المشروع التجريبي الأساسي ومطلوبان دائمًا.
عند التشغيل لأول مرة، قد يسأل Unreal عما إذا كان سيتم تعطيل أي إضافات اختيارية مفقودة - انقر فوق نعم. تأكد أيضًا من حذف مجلد Content/Modules/ المقابل (انظر أعلاه).
تخطيط المشروع التجريبي
واجهة المستخدم الموضحة أدناه مبنية بالكامل باستخدام UMG (رسوميات Unreal المتحركة) وهي مخصصة فقط لتوضيح خط الأنابيب - التعرف على الكلام ← LLM ← TTS ← مزامنة الشفاه. أنت حر في إعادة تصميمها أو استبدالها لتتناسب مع التصميم المرئي لمشروعك، أو نظام التحكم، أو المنصة (VR/AR، الهاتف المحمول، وحدة التحكم، الكشك، إلخ). إذا لم تكن هناك حاجة لبعض عناصر واجهة المستخدم في حالة استخدامك، يمكنك أيضًا إخفاؤها (مثل تعيين رؤيتها إلى Collapsed أو Hidden).

| المنطقة | ما يوجد هناك |
|---|---|
| الوسط | شخصية MetaHuman. |
| الجانب الأيسر | أربعة أزرار تكوين (التعرف على الكلام، روبوت الدردشة بالذكاء الاصطناعي، تحويل النص إلى كلام، الرسوم المتحركة)، موصوفة بالتفصيل أدناه. |
| أسفل المنتصف | زر بدء التسجيل. انقر عليه لبدء محادثة صوتية: يتم التقاط الميكروفون الخاص بك، ونسخه، وإرساله إلى LLM، ويتم تركيب الاستجابة عبر TTS، وتشغيلها مع مزامنة الشفاه، بدون استخدام اليدين بالكامل. |
| المنتصف الأيمن | عنصر واجهة سجل المحادثة يعرض التبادل الكامل بينك وبين الذكاء الاصطناعي (رسائل المستخدم والمساعد). يتضمن أيضًا حقل إدخال نصي، بحيث يمكنك كتابة الرسائل مباشرة دون استخدام التعرف على الكلام، وهو مفيد للاختبار، أو لإمكانية الوصول، أو عندما لا يتوفر الميكروفون. |
يمكنك المزج بين وضعي الإدخال بحرية في الجلسة نفسها - تحدث ببعض الرسائل، واكتب بعضها الآخر.
أزرار التكوين
تفتح أزرار التكوين الأربعة على اليسار لوحات مخصصة لكل جزء من خط الأنابيب:
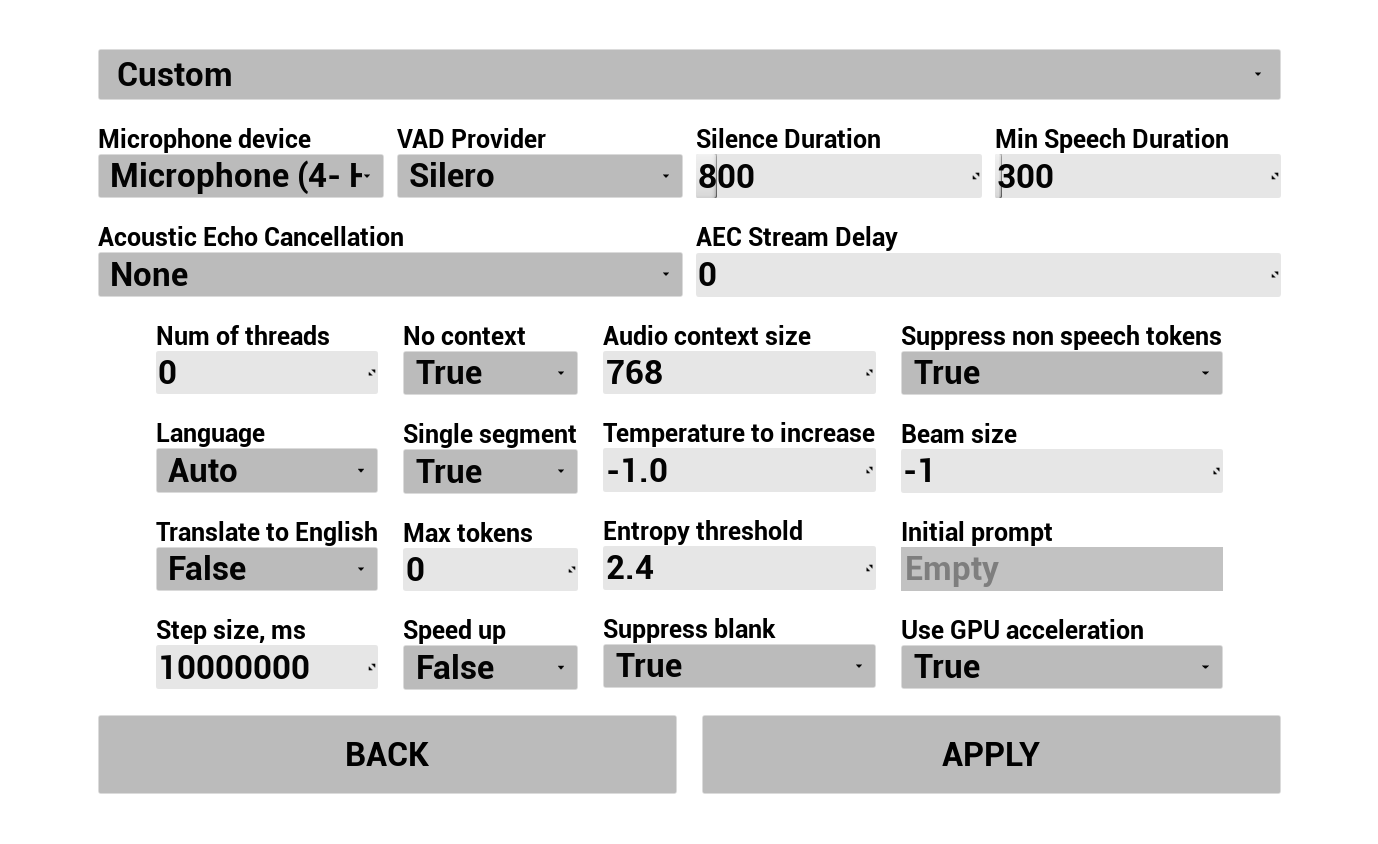
1. تكوين التعرف على الكلام
تكوين كيفية التقاط صوت المستخدم ونسخه:
- اختر اللغة
- اضبط معلمات التعرف على الكلام (إعدادات نموذج Whisper)
- تكوين AEC (إلغاء الصدى الصوتي)
- تكوين VAD (اكتشاف النشاط الصوتي)
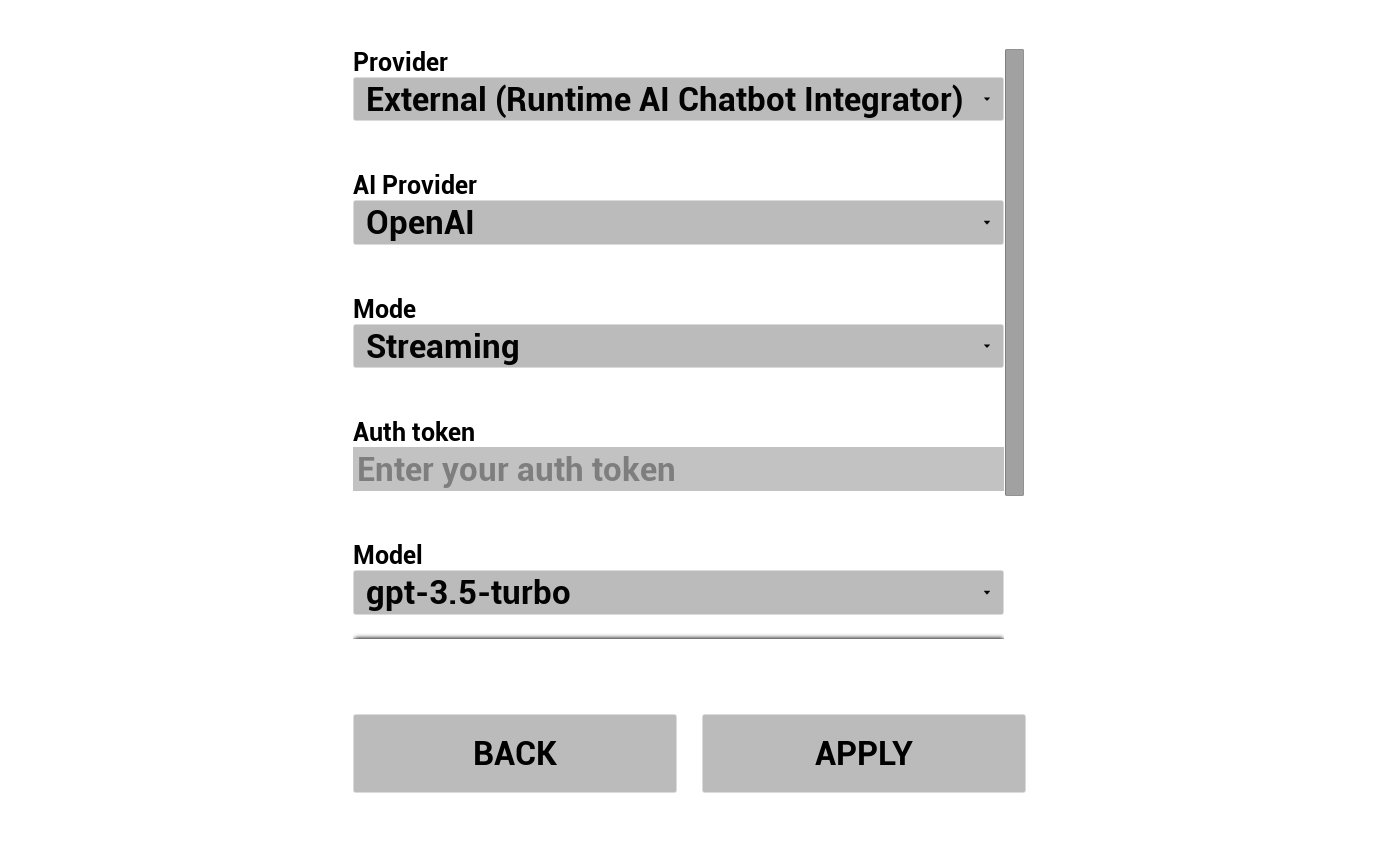
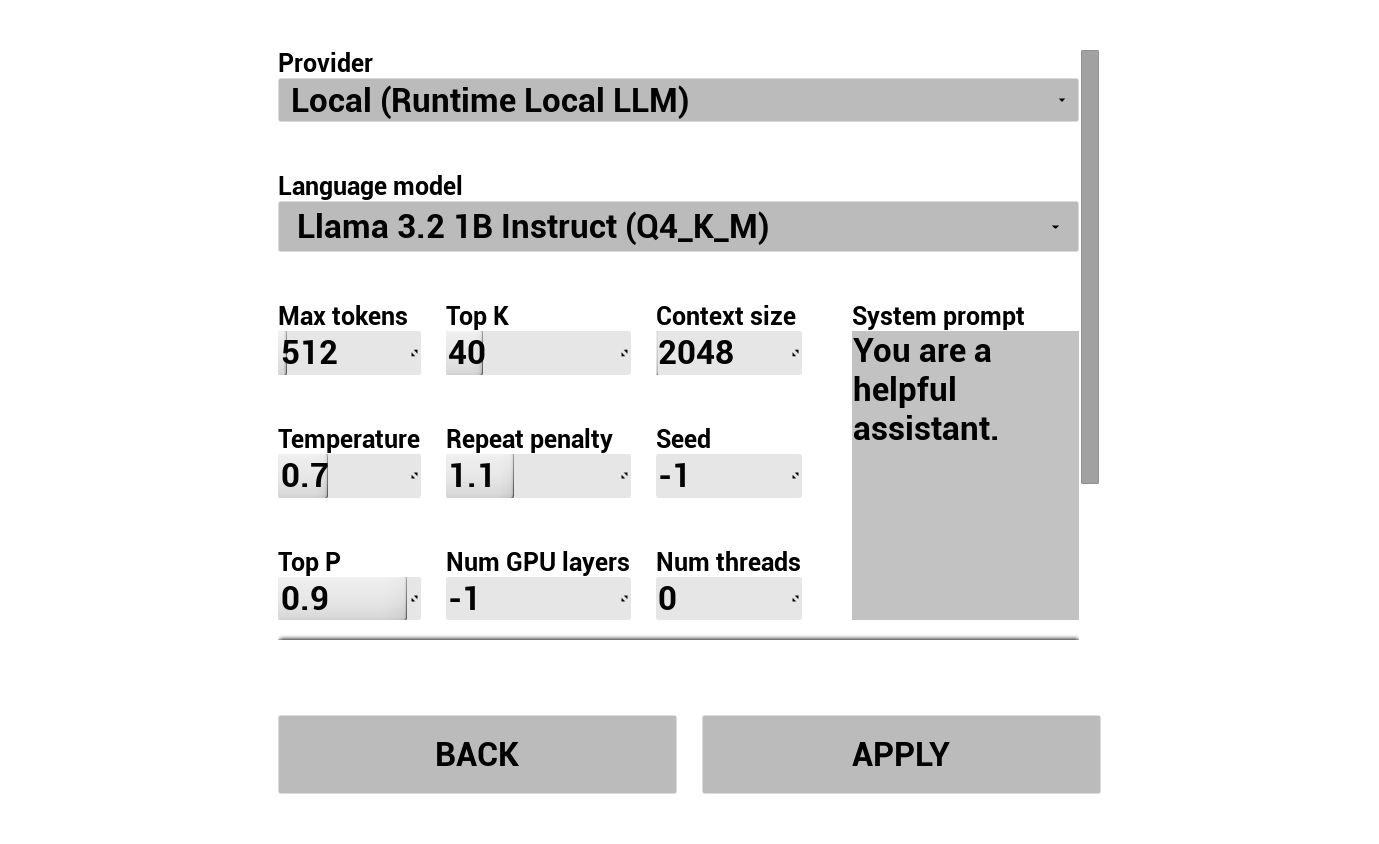
2. تكوين روبوت الدردشة بالذكاء الاصطناعي
اختر مزود LLM وقم بتكوينه:
- اختر المزود (Runtime AI Chatbot Integrator أو Runtime Local LLM)
- للمزودين الخارجيين: رمز المصادقة، اسم النموذج، إلخ.
- لـ LLM المحلي: اختر نموذج GGUF، وحدد حجم السياق، ومعلمات الاستدلال الأخرى. يمكنك أيضًا تنزيل نموذج GGUF الخاص بك في وقت التشغيل مباشرة من العرض التوضيحي (على سبيل المثال عن طريق URL)، واستخدامه فوراً دون إعادة بناء المشروع.
يعرض مربع التحرير والسرد للمزود فقط المزودين الذين يوجد مجلد وحدة الإضافة الخاص بهم في Content/Modules/.
3. تكوين تحويل النص إلى كلام
اختر مزود TTS وقم بتكوين الأصوات/النماذج:
- اختر المزود (Runtime AI Chatbot Integrator لـ OpenAI/ElevenLabs، أو Runtime Text To Speech لـ Piper/Kokoro المحليين)
- اختر الصوت/النموذج
- اضبط المعلمات الخاصة بالمزود

4. تكوين الرسوم المتحركة
التحكم في مرئيات شخصية الذكاء الاصطناعي الخاص بك:
- اختر بين 3 شخصيات MetaHuman مُعدة مسبقًا (Aera, Ada, Orlando)
- اختر نموذج مزامنة الشفاه (قياسي أو واقعي)
- اختر نوع نموذج مزامنة الشفاه - محسن للغاية، شبه محسن، أو أصلي (انظر نوع النموذج)
- اضبط حجم جزء المعالجة - يتحكم في عدد مرات تشغيل استدلال مزامنة الشفاه (انظر حجم جزء المعالجة)
- اختر رسوم متحركة خاملة لتشغيلها على MetaHuman أثناء المحادثة

التكوين المسبق للعرض التوضيحي في المحرر
عند العمل مع إصدار المصدر، يمكنك ملء القيم الافتراضية مسبقًا مباشرة في المحرر بحيث لا تحتاج إلى إعادة إدخالها في كل مرة تشغيل:
| ماذا | أين |
|---|---|
| الإعدادات العامة (نموذج مزامنة الشفاه، الرسوم المتحركة الخاملة، فئة الشخصية، التعرف على الكلام، إلخ) | Content/LipSyncSTSGameInstance |
| إعدادات LLM الخارجي / TTS الخارجي (Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| إعدادات LLM المحلي (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| إعدادات TTS المحلي (Runtime Text To Speech) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
ملاحظات عبر الأنظمة الأساسية
جميع الإضافات المستخدمة في العرض التوضيحي تدعم Windows, Mac, Linux, iOS, Android، والمنصات المبنية على Android (بما في ذلك Meta Quest)، لذا فإن المشروع التجريبي يعمل على كل هذه الأنظمة أيضًا. وهذا يجعله مناسبًا للنشر عبر مجموعة واسعة من البيئات — من أكشاك سطح المكتب والتجارب القائمة على المتصفح إلى تطبيقات الهاتف المحمول، وسماعات الواقع الافتراضي المستقلة، وإعدادات الإنتاج الافتراضي في موقع التصوير.
للأجهزة الأضعف (الهاتف المحمول، الواقع الافتراضي المستقل)، قد ترغب في:
- استخدام نموذج مزامنة الشفاه القياسي بدلاً من الواقعي - انظر مقارنة النماذج
- التبديل إلى نوع النموذج المحسن للغاية
- زيادة حجم جزء المعالجة لتقليل حمل وحدة المعالجة المركزية
- اختيار نماذج LLM / TTS أصغر
انظر التكوين الخاص بالمنصة لخطوات الإعداد الإضافية على Android, iOS, Mac, و Linux.
إحضار شخصيتك الخاصة
يأتي المشروع التجريبي مع ثلاث شخصيات MetaHuman نموذجية (Aera, Ada, Orlando)، ولكن يمكنك استيراد MetaHuman الخاص بك واستخدامه في العرض التوضيحي.
📺 فيديو تعليمي: إضافة شخصية MetaHuman مخصصة إلى المشروع التجريبي
إضافة Runtime MetaHuman Lip Sync نفسها تدعم العديد من أنظمة الشخصيات الأخرى بخلاف MetaHumans (الشخصيات المبنية على ARKit، Daz Genesis 8/9، Reallusion CC3/CC4، Mixamo، ReadyPlayerMe، إلخ - انظر دليل إعداد الشخصية المخصصة). سواء كنت تبني شخصية غير قابلة للعب في لعبة، أو مقدمًا افتراضيًا، أو مرافق كشك، أو إنسانًا رقميًا للإنتاج الافتراضي، فإن الإضافة تتكيف مع خط أنابيب شخصيتك.
مشروع تجريبي أبسط يركز على ميزة مزامنة الشفاه نفسها فقط، بدون سير عمل المحادثة الكامل بالذكاء الاصطناعي. مناسب إذا كنت ترغب فقط في رؤية مزامنة الشفاه أثناء العمل مع مصادر صوتية متنوعة.
فيديو مميز
التحميلات
ما هو متضمن
يعرض هذا العرض التوضيحي سير عمل مزامنة الشفاه الأساسي:
- إدخال الميكروفون - مزامنة شفاه في الوقت الفعلي من الصوت المباشر
- تشغيل ملف صوتي - مزامنة شفاه من ملفات صوتية مستوردة
- تحويل النص إلى كلام - مزامنة شفاه مدفوعة بالكلام المُركَّب
الإضافات المطلوبة والاختيارية
| الإضافة | الغرض | مطلوبة؟ |
|---|---|---|
| Runtime MetaHuman Lip Sync | رسوم متحركة لمزامنة الشفاه | ✅ مطلوبة |
| Runtime Audio Importer | استيراد الصوت والتقاطه | ✅ مطلوبة |
| Runtime Text To Speech | TTS محلي لمشهد عرض TTS | 🔶 اختيارية |
| Runtime AI Chatbot Integrator | مزودو TTS الخارجيون (OpenAI, ElevenLabs) | 🔶 اختيارية |
ملاحظات حول نموذج مزامنة الشفاه القياسي
إذا كنت تخطط لاستخدام النموذج القياسي (بدلاً من الواقعي) في أي من المشروعين التجريبيين، فستحتاج إلى تثبيت إضافة Standard Lip Sync Extension. انظر امتداد النموذج القياسي للحصول على تعليمات التثبيت.
هل تحتاج مساعدة؟
إذا واجهت أي مشاكل في إعداد المشاريع التجريبية أو تشغيلها، فلا تتردد في التواصل:
بالنسبة لطلبات التطوير المخصصة (على سبيل المثال، توسيع العرض التوضيحي بمنطقك الخاص، أو تكييفه لمنصة محددة أو خط أنابيب الشخصيات)، اتصل بـ [email protected].