كيفية استخدام الإضافة
تم تصميم إضافة Runtime Speech Recognizer للتعرف على الكلمات من بيانات الصوت الواردة. تستخدم نسخة معدلة قليلاً من whisper.cpp للعمل مع المحرك. لاستخدام الإضافة، اتبع الخطوات التالية:
جانب المحرر
- اخطر نماذج اللغة المناسبة لمشروعك كما هو موضح هنا.
جانب وقت التشغيل
- أنشئ معرّف كلام وحدد المعاملات الضرورية (CreateSpeechRecognizer، للمعاملات انظر هنا).
- اربط بالمفوضين المطلوبين (OnRecognitionFinished, OnRecognizedTextSegment و OnRecognitionError).
- ابدأ التعرف على الكلام (StartSpeechRecognition).
- معالجة بيانات الصوت وانتظر النتائج من المفوضين (ProcessAudioData).
- أوقف معرّف الكلام عند الحاجة (مثلاً، بعد بث OnRecognitionFinished).
تدعم الإضافة بيانات الصوت الواردة بصيغة PCM المتشابك 32 بت ذات النقطة العائمة. بينما تعمل بشكل جيد مع Runtime Audio Importer، فهي لا تعتمد عليه مباشرة.
معاملات التعرف
تدعم الإضافة التعرف على بيانات الصوت المتدفقة وغير المتدفقة. لضبط معاملات التعرف لحالة الاستخدام الخاصة بك، استدعِ SetStreamingDefaults أو SetNonStreamingDefaults. بالإضافة إلى ذلك، لديك المرونة لتعيين المعاملات الفردية يدوياً مثل عدد الخيوط، حجم الخطوة، ما إذا كان سيتم ترجمة اللغة الواردة إلى الإنجليزية، وما إذا كان سيتم استخدام النص السابق. راجع قائمة معاملات التعرف للحصول على قائمة كاملة بالمعاملات المتاحة.
تحسين الأداء
يرجى الرجوع إلى قسم كيفية تحسين الأداء للحصول على نصائح حول كيفية تحسين أداء الإضافة.
كشف النشاط الصوتي (VAD)
عند معالجة مدخلات الصوت، خاصة في سيناريوهات البث المباشر، يُوصى باستخدام كشف النشاط الصوتي (VAD) لتصفية مقاطع الصوت الفارغة أو التي تحتوي على ضوضاء فقط قبل وصولها إلى المعرّف. يمكن تمكين هذا التصفية على جانب موجة الصوت القابلة للالتقاط باستخدام إضافة Runtime Audio Importer، مما يساعد على منع نماذج اللغة من الهلوسة - محاولة العثور على أنماط في الضوضاء وإنشاء نصوص غير صحيحة.
للحصول على أفضل نتائج للتعرف على الكلام، نوصي باستخدام مزود Silero VAD الذي يوفر تحملاً متفوقاً للضوضاء وكشفاً أكثر دقة للكلام. Silero VAD متاح كامتداد لإضافة Runtime Audio Importer. للحصول على تعليمات مفصلة حول تكوين VAD، راجع توثيق كشف النشاط الصوتي.
العقد القابلة للنسخ في الأمثلة أدناه تستخدم مزود VAD الافتراضي لأسباب التوافقية. لتحسين دقة التعرف، يمكنك بسهولة التبديل إلى Silero VAD عن طريق:
- تثبيت امتداد Silero VAD كما هو موضح في قسم امتداد Silero VAD
- بعد تمكين VAD باستخدام عقدة Toggle VAD، أضف عقدة Set VAD Provider واختر "Silero" من القائمة المنسدلة
في مشروع التجربة المضمن مع الإضافة، VAD مفعل افتراضيًا. يمكنك العثور على مزيد من المعلومات حول تنفيذ التجربة في مشروع التجربة.
أمثلة
يوجد مشروع تجربة جيد مضمن في مجلد Content -> Demo الخاص بالإضافة، والذي يمكنك استخدامه كمثال للتنفيذ.
هذه الأمثلة توضح كيفية استخدام إضافة Runtime Speech Recognizer مع إدخال الصوت المتدفق وغير المتدفق، باستخدام Runtime Audio Importer للحصول على بيانات الصوت كمثال. يرجى ملاحظة أن تنزيل RuntimeAudioImporter بشكل منفصل مطلوب للوصول إلى نفس مجموعة ميزات استيراد الصور المعروضة في الأمثلة (مثل موجة الصوت القابلة للالتقاط و ImportAudioFromFile). هذه الأمثلة مخصصة فقط لتوضيح المفهوم الأساسي ولا تتضمن معالجة الأخطاء.
أمثلة إدخال الصوت المتدفق
ملاحظة: في UE 5.3 والإصدارات الأخرى، قد تواجه عقدًا مفقودة بعد نسخ Blueprints. يمكن أن يحدث هذا بسبب الاختلافات في تسلسل العقد بين إصدارات المحرك. تحقق دائمًا من أن جميع العقد متصلة بشكل صحيح في تنفيذك.
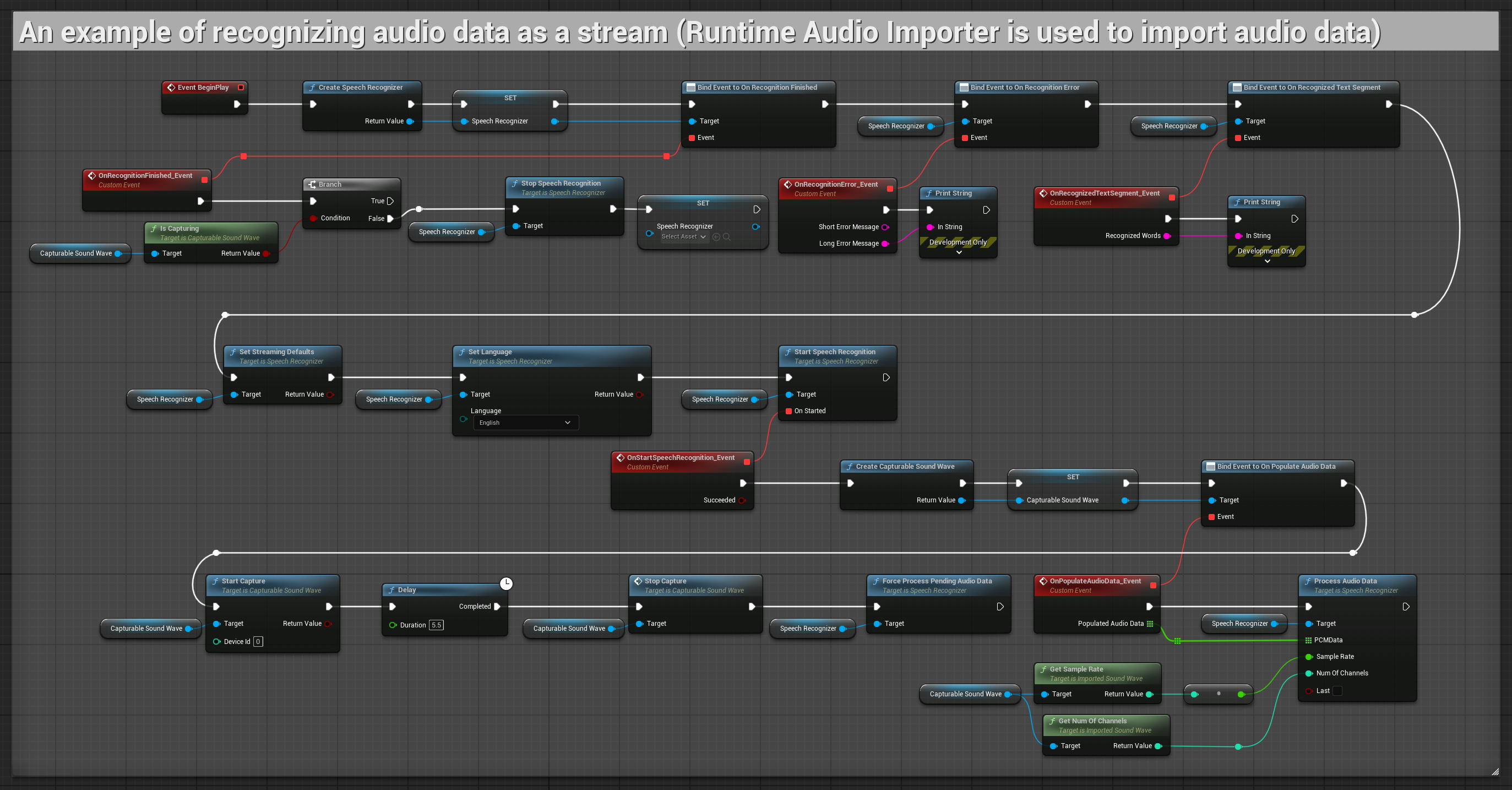
1. التعرف الأساسي المتدفق
يوضح هذا المثال الإعداد الأساسي لالتقاط بيانات الصوت من الميكروفون كتدفق باستخدام موجة الصوت القابلة للالتقاط وتمريرها إلى مُعرّف الكلام. يقوم بتسجيل الكلام لمدة 5 ثوانٍ تقريبًا ثم يعالج التعرف، مما يجعله مناسبًا للاختبارات السريعة والتنفيذات البسيطة. عقد قابلة للنسخ.
الميزات الرئيسية لهذا الإعداد:
- مدة تسجيل ثابتة لمدة 5 ثوانٍ
- تعرف لمرة واحدة بسيط
- متطلبات إعداد دنيا
- مثالي للاختبار وإنشاء النماذج الأولية
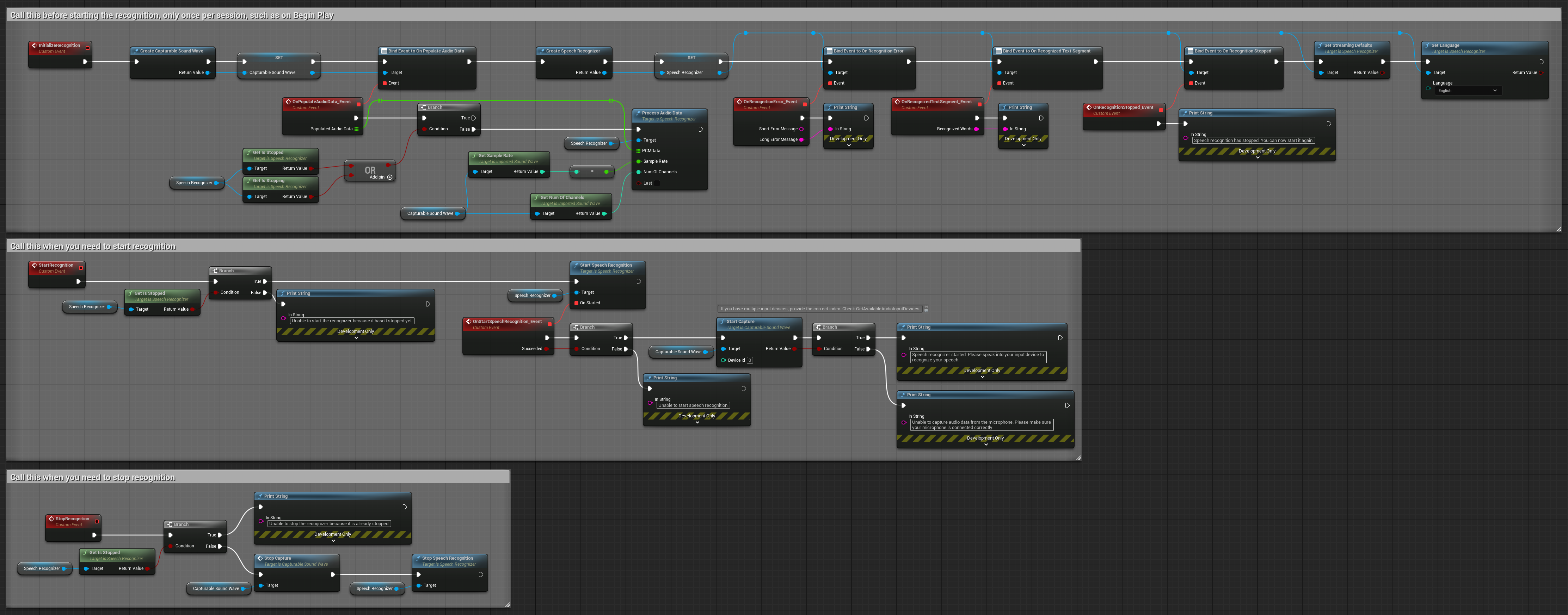
2. التعرف المتدفق المتحكم به
يمتد هذا المثال لإعداد البث الأساسي عن طريق إضافة تحكم يدوي في عملية التعرف. يسمح لك ببدء وإيقاف التعرف حسب الرغبة، مما يجعله مناسبًا للسيناريوهات التي تحتاج فيها إلى تحكم دقيق في وقت حدوث التعرف. عقد قابلة للنسخ.
الميزات الرئيسية لهذا الإعداد:
- التحكم اليدوي في البدء/التوقف
- قدرة التعرف المستمر
- مدة تسجيل مرنة
- مناسبة للتطبيقات التفاعلية
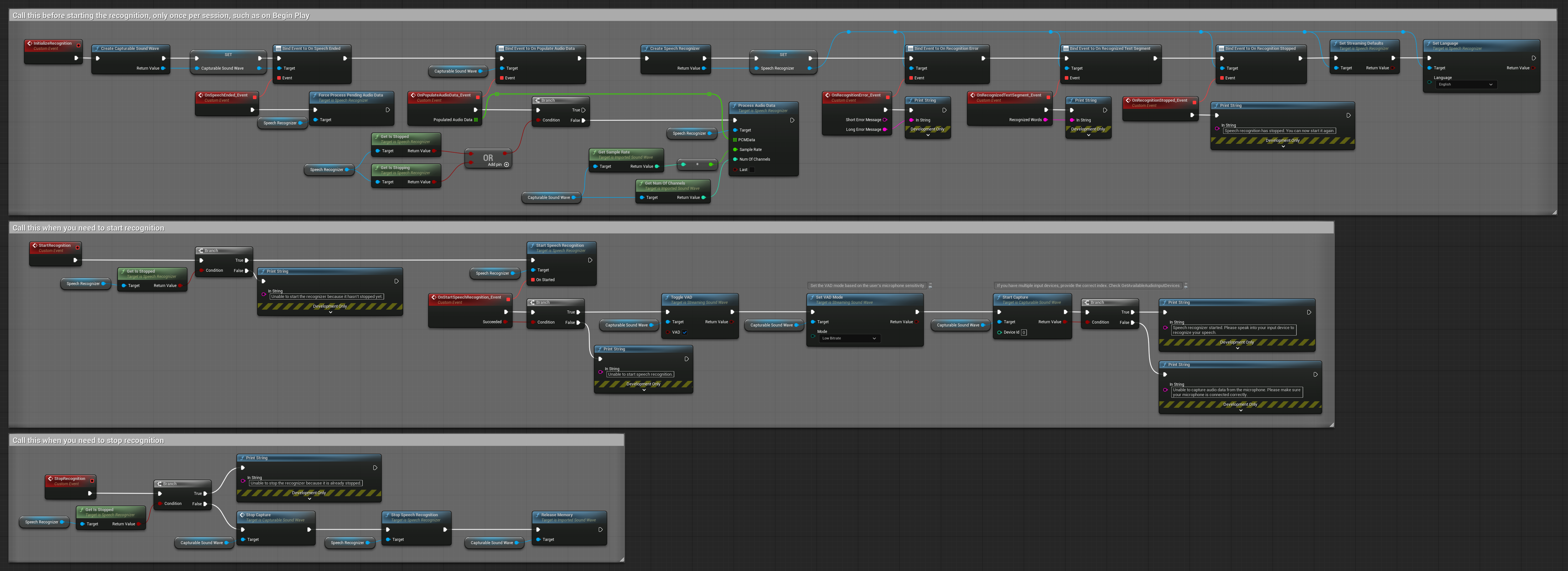
3. التعرف على الأوامر الصوتية
هذا المثال مُحسّن لسيناريوهات التعرف على الأوامر. فهو يجمع بين التعرف المتدفق وكشف النشاط الصوتي Voice Activity Detection (VAD) لمعالجة الكلام تلقائيًا عندما يتوقف المستخدم عن الكلام. يبدأ المُعرّف بمعالجة الكلام المتراكم فقط عند اكتشاف الصمت، مما يجعله مثاليًا للواجهات القائمة على الأوامر. عُقَد قابلة للنسخ.
الميزات الرئيسية لهذا الإعداد:
- التحكم اليدوي في البدء/التوقف
- تمكين كشف النشاط الصوتي Voice Activity Detection (VAD) لاكتشاف مقاطع الكلام
- تشغيل التعرف تلقائيًا عند اكتشاف الصمت
- الأمثل للتعرف على الأوامر القصيرة
- تقليل الحمل المعالَجي من خلال التعرف على الكلام الفعلي فقط
4. تهيئة التعرف الصوتي التلقائي مع معالجة المخزن المؤقت النهائي
هذا المثال هو اختلاف آخر لنهج التعرف المُفعّل صوتيًا مع معالجة مختلفة لدورة الحياة. فهو يبدأ المُعرّف تلقائيًا أثناء التهيئة ويوقفه أثناء إلغاء التهيئة. الميزة الرئيسية هي أنه يعالج آخر مخزن مؤقت للصوت المتراكم قبل إيقاف المُعرّف، مما يضمن عدم فقدان أي بيانات كلام عندما يرغب المستخدم في إنهاء عملية التعرف. هذا الإعداد مفيد بشكل خاص للتطبيقات التي تحتاج إلى التقاط نطق المستخدم الكامل حتى عند التوقف في منتصف الكلام. عُقَد قابلة للنسخ.
الميزات الرئيسية لهذا الإعداد:
- بدء المُعرّف تلقائيًا عند التهيئة
- إيقاف المُعرّف تلقائيًا عند إلغاء التهيئة
- معالجة المخزن المؤقت الصوتي النهائي قبل التوقف تمامًا
- يستخدم كشف النشاط الصوتي Voice Activity Detection (VAD) للتعرف الفعال
- يضمن عدم فقدان بيانات الكلام عند التوقف
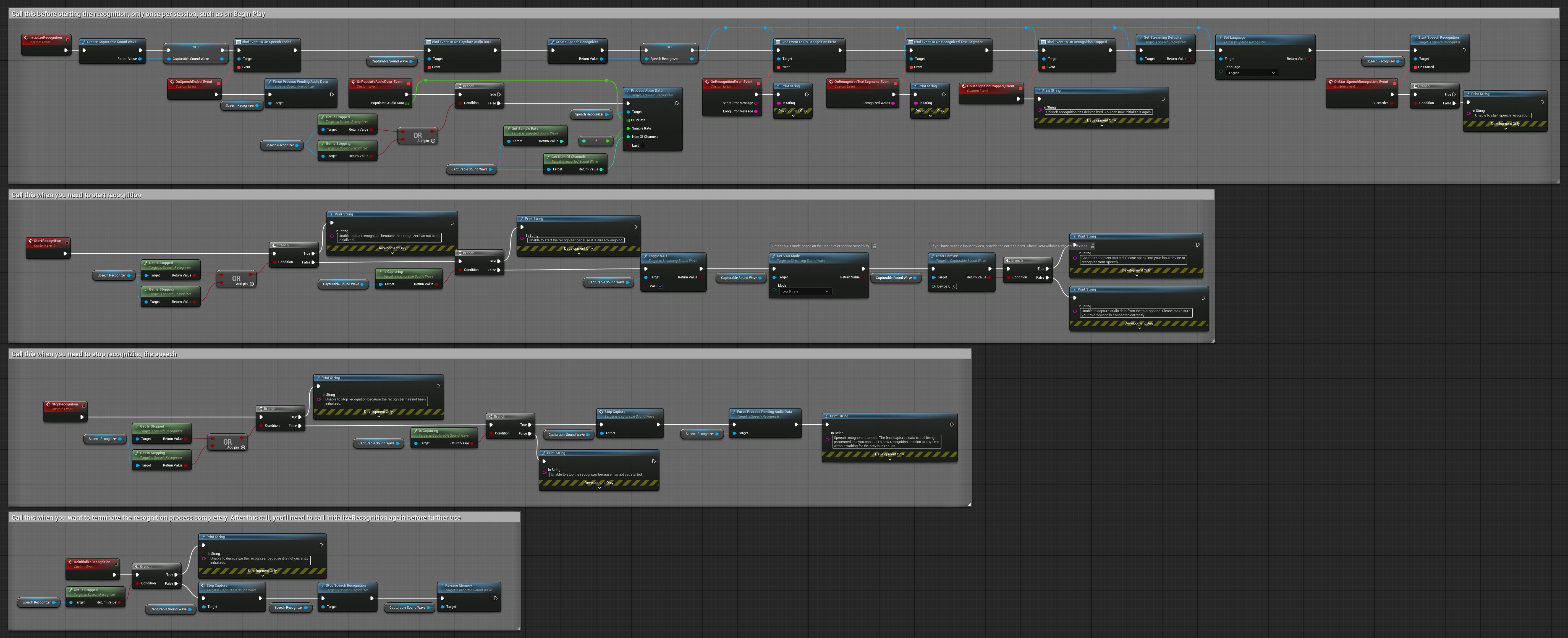
إدخال الصوت غير المتدفق
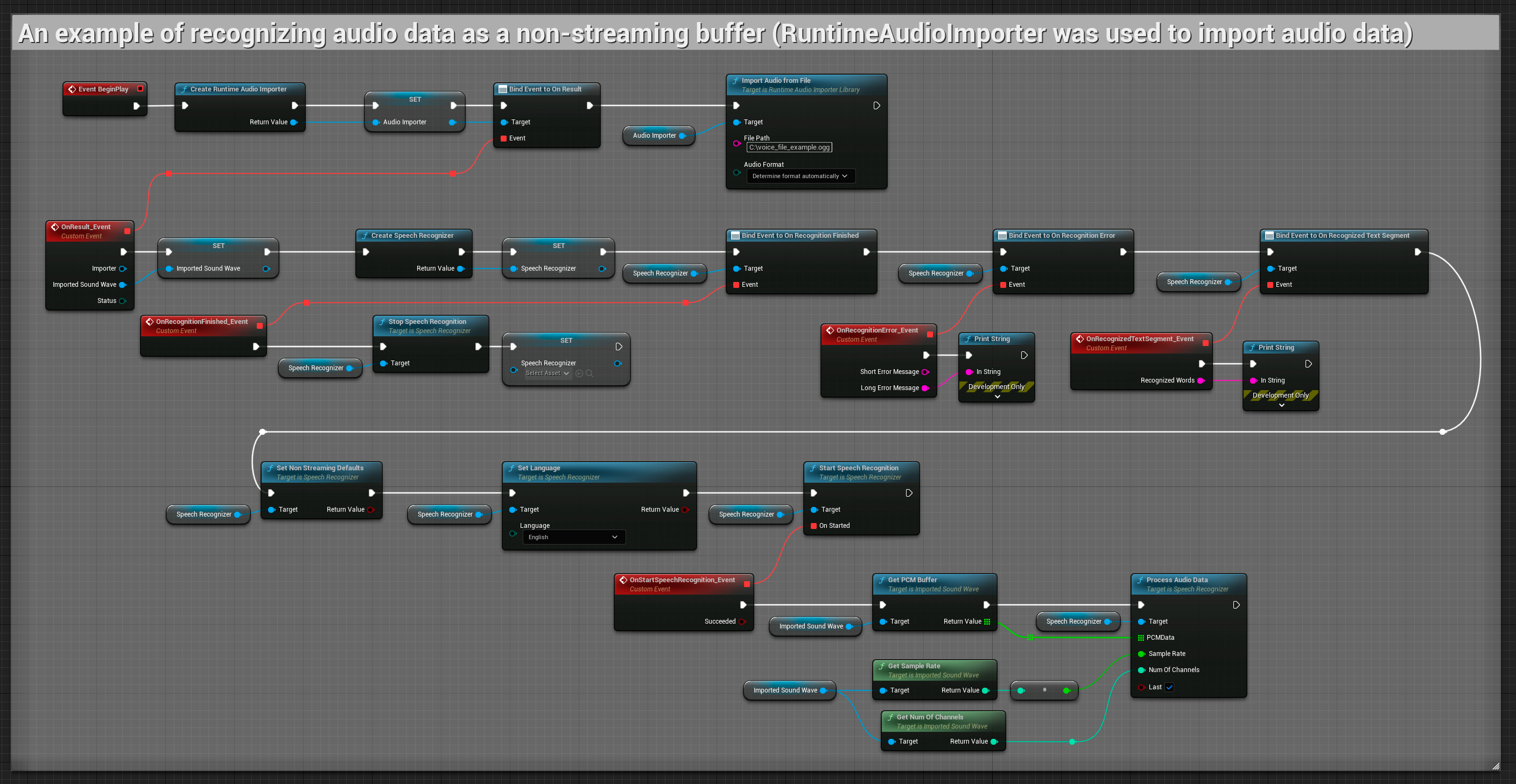
يقوم هذا المثال باستيراد بيانات الصوت إلى "Imported sound wave" ويتعرف على بيانات الصوت الكاملة بمجرد استيرادها. عُقَد قابلة للنسخ.