قائمة معلمات التعرف
يمكن تعيين هذه المعلمات فقط عندما لا يكون المُعرِّف قيد التشغيل.
هذه ليست قائمة شاملة لجميع المعلمات المتاحة في Whisper. فقط أهمها معروضة هنا. إذا لزم الأمر، سيتم تحديث هذه القائمة.
تعيين معلمات التعرف
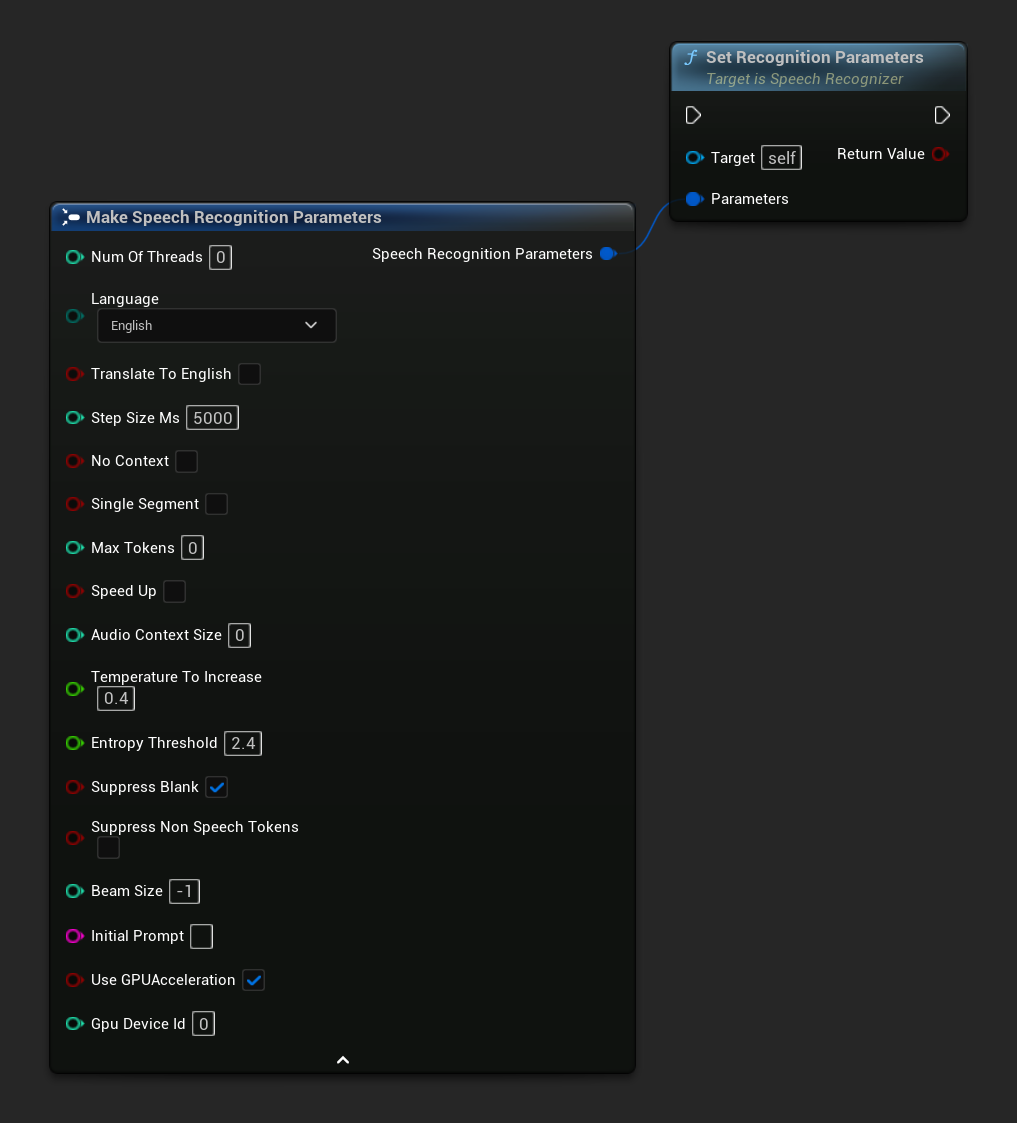
يحدد معلمات التعرف الصوتي. إذا كنت تريد تغيير معلمات محددة فقط، ففكر في استخدام دوال التعيين الفردية.
تعيين الإعدادات الافتراضية للبث
يحدد المعلمات الافتراضية المناسبة للتعرف الصوتي بالبث.
تستبدل هذه الدالة جميع المعلمات المطبقة سابقًا. تأكد من استدعاء هذه الدالة قبل تعيين معلماتك المخصصة إذا كنت بحاجة إلى استخدام الإعدادات الافتراضية للبث كتكوين أساسي.
تعيين الإعدادات الافتراضية لغير البث
يحدد المعلمات الافتراضية المناسبة للتعرف الصوتي غير البثي.
تستبدل هذه الدالة جميع المعلمات المطبقة سابقًا. تأكد من استدعاء هذه الدالة قبل تعيين معلماتك المخصصة إذا كنت بحاجة إلى استخدام الإعدادات الافتراضية لغير البث كتكوين أساسي.
تعيين عدد الخيوط
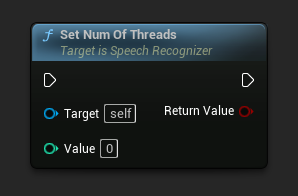
يحدد عدد الخيوط (threads) لاستخدامها في التعرف الصوتي. عيّن هذه القيمة على 0 لاستخدام عدد النوى.
تعيين اللغة
يحدد اللغة لاستخدامها في التعرف الصوتي. يجب أن تكون مدعومة من قبل نموذج اللغة المحدد في إعدادات المحرر.
سيؤدي تعيين اللغة على "تلقائي" إلى تقليل دقة التعرف والأداء.
الحصول على اللغة المكتشفة
يحصل على اللغة المكتشفة من آخر عملية تعرف. تُرجع اللغة كقيمة تعداد (enum).
ملاحظة: تعمل هذه الدالة فقط بعد إجراء التعرف. تُرجع "تلقائي" إذا فشل اكتشاف اللغة أو لم يتم إجراؤه. يكون هذا مفيدًا بشكل خاص عند استخدام اكتشاف اللغة التلقائي لتحديد اللغة التي تم التعرف عليها بالفعل.
الحصول على رمز اللغة
يحول قيمة تعداد اللغة إلى سلسلة رمز اللغة الخاصة بها (على سبيل المثال، En -> "en"، Fr -> "fr"، De -> "de").
الحصول على الاسم الكامل للغة
يحول قيمة تعداد اللغة إلى اسمها الكامل (على سبيل المثال، En -> "English"، Fr -> "French"، De -> "German").
تعيين الترجمة إلى الإنجليزية
![]()
يحدد ما إذا كان سيتم ترجمة الكلمات المعترف بها إلى الإنجليزية. إذا كانت القيمة صحيحة، فيجب أن يكون نموذج اللغة متعدد اللغات.
تعيين حجم الخطوة
يحدد حجم الخطوة بالمللي ثانية. يحدد عدد مرات إرسال بيانات الصوت للتعرف. القيمة الافتراضية هي 5000 مللي ثانية (5 ثوانٍ).
تعيين عدم وجود سياق
يحدد ما إذا كان سيتم استخدام النسخ السابق (إن وجد) كموجه أولي لفك التشفير (decoder).
تعيين المقطع الواحد
يحدد ما إذا كان سيتم فرض إخراج مقطع واحد (مفيد للبث).
تعيين الحد الأقصى للرموز
يحدد الحد الأقصى لعدد الرموز (tokens) لكل مقطع نصي. استخدم 0 لعدم وجود حد.
تعيين التسريع
يحدد ما إذا كان سيتم تسريع التعرف بمقدار 2x باستخدام Phase Vocoder. عيّنه على false لتحسين جودة الإخراج.
تعيين حجم سياق الصوت
يحدد حجم سياق الصوت. عيّنه على 0 لتحسين جودة الإخراج.
تعيين درجة الحرارة للزيادة
يحدد درجة الحرارة للزيادة عند التراجع عندما يفشل فك التشفير في تلبية أي من العتبات أدناه.
تعيين عتبة الإنتروبيا
يحدد عتبة الإنتروبيا. إذا كانت نسبة الضغط أعلى من هذه القيمة، فاعتبر فك التشفير فاشلًا. مشابه لـ "compression_ratio_threshold" الخاص بـ OpenAI
تعيين كتم الفراغات
![]()
يحدد ما إذا كان سيتم كتم ظهور الفراغات في المخرجات.
تعيين كتم الرموز غير الصوتية
يحدد ما إذا كان سيتم كتم ظهور الرموز غير الصوتية في المخرجات.
تعيين حجم الحزمة
يحدد عدد الحزم (beams) في بحث الحزمة (beam search). ينطبق فقط عندما تكون درجة الحرارة صفرًا.
تعيين الموجه الأولي
يحدد الموجه الأولي للنافذة الأولى. يمكن استخدام هذا لتوفير سياق للتعرف لجعله أكثر احتمالية للتنبؤ بالكلمات بشكل صحيح، على سبيل المثال، المفردات المخصصة أو الأسماء الصحيحة.
لمزيد من التفاصيل حول استراتيجيات التوجيه الفعالة، راجع دليل توجيه Whisper.
تعيين تسريع GPU
يحدد ما إذا كان سيتم استخدام تسريع GPU للتعرف الصوتي (ينطبق فقط على Windows في الوقت الحالي).
تعيين معرف جهاز GPU
يحدد معرف جهاز GPU لاستخدامه في التعرف الصوتي. القيمة الافتراضية هي 0. يكون هذا مفيدًا للأنظمة التي تحتوي على وحدات معالجة رسومات متعددة لتحديد وحدة معالجة الرسومات التي يجب استخدامها لعملية التعرف. إذا كان معرف جهاز GPU المحدد غير صالح، فسيتم استخدام أول فهرس جهاز GPU متاح بدلاً من ذلك.