Übersetzungsanbieter
Der AI Localization Automator unterstützt fünf verschiedene KI-Anbieter, jeder mit einzigartigen Stärken und Konfigurationsoptionen. Wählen Sie den Anbieter, der am besten zu den Anforderungen, dem Budget und den Qualitätsanforderungen Ihres Projekts passt.
Ollama (Lokale KI)
Am besten geeignet für: Datenschutzsensible Projekte, Offline-Übersetzung, unbegrenzte Nutzung
Ollama führt KI-Modelle lokal auf Ihrem Rechner aus und bietet vollständige Privatsphäre und Kontrolle ohne API-Kosten oder Internetanforderungen.
Beliebte Modelle
- translategemma:12b (Spezialisiertes Übersetzungsmodell basierend auf Gemma 3)
- llama3.2 (Empfohlen für allgemeine Zwecke)
- mistral (Effiziente Alternative)
- codellama (Code-bewusste Übersetzungen)
- Und viele weitere Community-Modelle
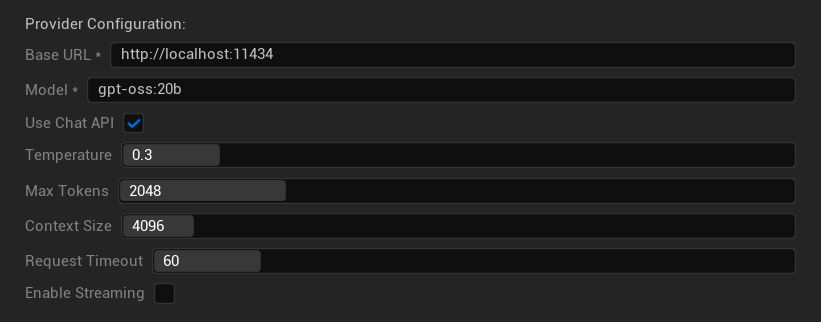
Konfigurationsoptionen
- Basis-URL: Lokaler Ollama-Server (Standard:
http://localhost:11434) - Modell: Name des lokal installierten Modells (erforderlich)
- Chat-API verwenden: Für bessere Konversationsverarbeitung aktivieren
- Temperatur: 0,0-2,0 (0,3 empfohlen)
- Maximale Tokens: 1-8.192 Tokens
- Kontextgröße: 512-32.768 Tokens
- Anfrage-Timeout: 10-300 Sekunden (lokale Modelle können langsamer sein)
- Streaming aktivieren: Für Echtzeit-Antwortverarbeitung
Stärken
- ✅ Vollständige Privatsphäre (keine Daten verlassen Ihren Rechner)
- ✅ Keine API-Kosten oder Nutzungslimits
- ✅ Funktioniert offline
- ✅ Vollständige Kontrolle über Modellparameter
- ✅ Große Auswahl an Community-Modellen
- ✅ Kein Vendor-Lock-in
Überlegungen
- 💻 Erfordert lokale Einrichtung und leistungsfähige Hardware
- ⚡ Allgemein langsamer als Cloud-Anbieter
- 🔧 Technischere Einrichtung erforderlich
- 📊 Übersetzungsqualität variiert stark je nach Modell (einige können Cloud-Anbieter übertreffen)
- 💾 Großer Speicherbedarf für Modelle
Ollama einrichten
- Ollama installieren: Laden Sie es von ollama.ai herunter und installieren Sie es auf Ihrem System
- Modelle herunterladen: Verwenden Sie
ollama pull translategemma:12b, um Ihr gewähltes Modell herunterzuladen - Server starten: Ollama läuft automatisch oder starten Sie mit
ollama serve - Plugin konfigurieren: Legen Sie Basis-URL und Modellname in den Plugin-Einstellungen fest
- Verbindung testen: Das Plugin überprüft die Konnektivität, wenn Sie die Konfiguration anwenden
OpenAI
Am besten geeignet für: Höchste allgemeine Übersetzungsqualität, umfangreiche Modellauswahl
OpenAI bietet branchenführende Sprachmodelle über ihre Chat Completions API, einschließlich der neuesten GPT-Modelle, Reasoning-Modelle und websearch-fähigen Modelle.
Verfügbare Modelle
GPT-5 Familie (Flaggschiff-Modelle)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
GPT-4.1 Familie (Hochleistung)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
GPT-4o Familie (Multimodal)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O-Serie (Reasoning-Modelle — Temperatur/top_p nicht unterstützt)
- o1, o1-pro, o3, o3-mini, o4-mini
Web Search Modelle (Temperatur/top_p nicht unterstützt)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
Legacy / Vorschau
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
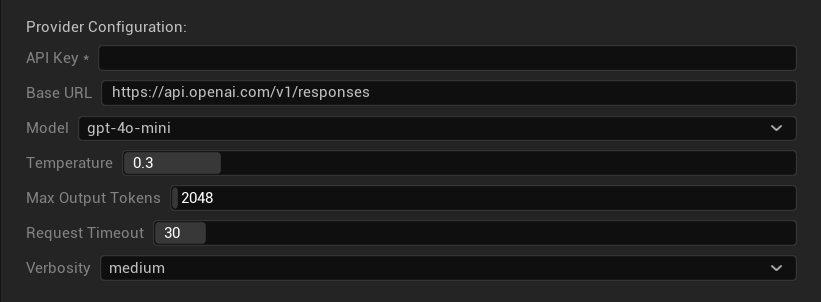
Konfigurationsoptionen
- API-Schlüssel: Ihr OpenAI API-Schlüssel (erforderlich)
- Basis-URL: API-Endpunkt (Standard:
https://api.openai.com/v1/chat/completions) - Modell: Wählen Sie aus den oben aufgeführten verfügbaren Modellen
- Temperatur verwenden: Temperaturparameter ein-/ausschalten (wird automatisch für O-Serie Reasoning- und Web Search-Modelle ignoriert)
- Temperatur: 0,0–2,0 (0,3 empfohlen für Übersetzungskonsistenz)
- Top P: 0,0–1,0 Nucleus-Sampling-Parameter (wird für O-Serie Reasoning- und Web Search-Modelle ignoriert)
- Maximale Completion-Tokens: 1–128.000 Tokens (enthält sowohl Ausgabe- als auch Reasoning-Tokens)
- Anfrage-Timeout: 5–300 Sekunden
Stärken
- ✅ Konsistent hochwertige Übersetzungen
- ✅ Hervorragendes Kontextverständnis
- ✅ Starke Formatierungserhaltung
- ✅ Breite Sprachunterstützung
- ✅ Zuverlässige API-Verfügbarkeit
Überlegungen
- 💰 Höhere Kosten pro Anfrage
- 🌐 Erfordert Internetverbindung
- ⏱️ Nutzungslimits basierend auf Tier
Anthropic Claude
Am besten geeignet für: Nuancierte Übersetzungen, kreative Inhalte, sicherheitsfokussierte Anwendungen
Claude-Modelle zeichnen sich durch das Verständnis von Kontext und Nuancen aus, was sie ideal für erzähllastige Spiele und komplexe Lokalisierungsszenarien macht.
Verfügbare Modelle
Claude 4.6 Familie (Neueste)
- claude-opus-4-6, claude-sonnet-4-6
Claude 4.5 Familie
- claude-haiku-4-5 (Schnell und effizient)
- claude-sonnet-4-5, claude-opus-4-5
Claude 4.x Familie
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Claude 3.x Familie (Legacy)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
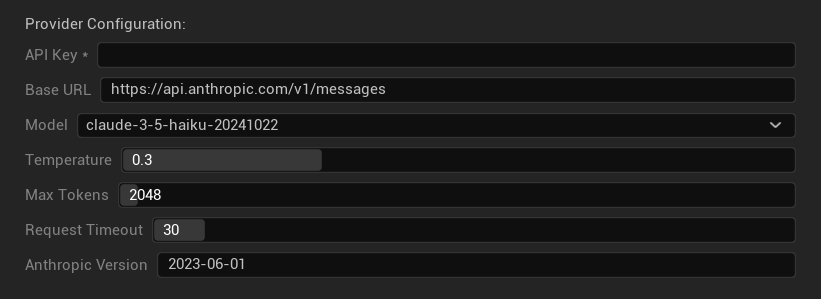
Konfigurationsoptionen
- API-Schlüssel: Ihr Anthropic API-Schlüssel (erforderlich)
- Basis-URL: Claude API-Endpunkt
- Modell: Aus der Claude-Modellfamilie auswählen
- Temperatur: 0,0–1,0 (0,3 empfohlen)
- Top K: Top-K-Sampling-Parameter (0 = nicht gesetzt)
- Maximale Tokens: 1–64.000 Tokens
- Anfrage-Timeout: 5–300 Sekunden
- Anthropic Version: API-Versions-Header
Stärken
- ✅ Außergewöhnliches Kontextbewusstsein
- ✅ Großartig für kreative/erzählerische Inhalte
- ✅ Starke Sicherheitsfunktionen
- ✅ Detaillierte Reasoning-Fähigkeiten (erweitertes Denken bei 3.7+ Modellen)
- ✅ Hervorragende Befolgung von Anweisungen
Überlegungen
- 💰 Premium-Preismodell
- 🌐 Internetverbindung erforderlich
- 📏 Token-Limits variieren je nach Modell
DeepSeek
Am besten geeignet für: Kosteneffektive Übersetzung, hohen Durchsatz, budgetbewusste Projekte
DeepSeek bietet wettbewerbsfähige Übersetzungsqualität zu einem Bruchteil der Kosten anderer Anbieter, was es ideal für groß angelegte Lokalisierungsprojekte macht.
Verfügbare Modelle
- deepseek-chat (Allgemeiner Zweck, empfohlen)
- deepseek-reasoner (Erweiterte Reasoning-Fähigkeiten)
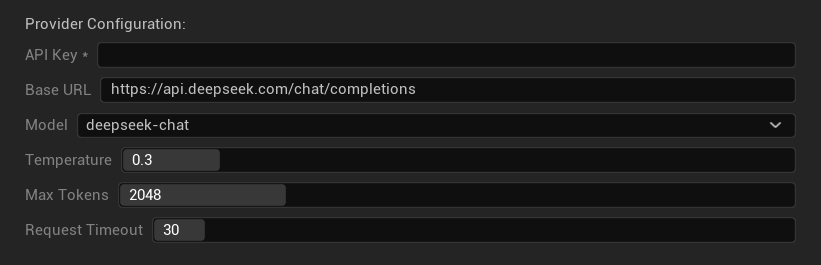
Konfigurationsoptionen
- API-Schlüssel: Ihr DeepSeek API-Schlüssel (erforderlich)
- Basis-URL: DeepSeek API-Endpunkt
- Modell: Wählen Sie zwischen Chat- und Reasoner-Modellen
- Temperatur: 0,0-2,0 (0,3 empfohlen)
- Maximale Tokens: 1-8.192 Tokens
- Anfrage-Timeout: 5-300 Sekunden
Stärken
- ✅ Sehr kosteneffektiv
- ✅ Gute Übersetzungsqualität
- ✅ Schnelle Antwortzeiten
- ✅ Einfache Konfiguration
- ✅ Hohe Rate-Limits
Überlegungen
- 📏 Niedrigere Token-Limits
- 🆕 Neuerer Anbieter (weniger Erfahrungswerte)
- 🌐 Erfordert Internetverbindung
Google Gemini
Am besten geeignet für: Mehrsprachige Projekte, kosteneffektive Übersetzung, Google-Ökosystem-Integration
Gemini-Modelle bieten starke mehrsprachige Fähigkeiten mit wettbewerbsfähigen Preisen und einzigartigen Funktionen wie den Denkmodus für erweitertes Reasoning.
Verfügbare Modelle
Gemini 3.x Familie (Vorschau)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Gemini 2.5 Familie (Mit Denkunterstützung)
- gemini-2.5-pro (Flaggschiff mit Denken)
- gemini-2.5-flash (Schnell, mit Denkunterstützung)
- gemini-2.5-flash-lite (Leichtgewichtige Variante)
Gemini 2.0 Familie
- gemini-2.0-flash, gemini-2.0-flash-lite
Neueste Aliase
- gemini-flash-latest, gemini-flash-lite-latest
Konfigurationsoptionen
- API-Schlüssel: Ihr Google AI API-Schlüssel (erforderlich)
- Basis-URL: Gemini API-Endpunkt
- Modell: Aus der Gemini-Modellfamilie auswählen
- Temperatur: 0,0–2,0 (0,3 empfohlen)
- Maximale Ausgabe-Tokens: 1–8.192 Tokens
- Anfrage-Timeout: 5–300 Sekunden
- Denken aktivieren: Erweitertes Reasoning für 2.5+ Modelle aktivieren
- Denk-Budget: Denk-Token-Zuweisung steuern (0 = kein Denken)
Stärken
- ✅ Starke mehrsprachige Unterstützung
- ✅ Wettbewerbsfähige Preise
- ✅ Fortgeschrittenes Reasoning (Denkmodus)
- ✅ Google-Ökosystem-Integration
- ✅ Regelmäßige Modell-Updates mit Vorschauzugang zu neuesten Modellen
Überlegungen
- 🧠 Denkmodus erhöht den Token-Verbrauch
- 📏 Variable Token-Limits je nach Modell
- 🌐 Internetverbindung erforderlich
Den richtigen Anbieter wählen
| Anbieter | Am besten geeignet für | Qualität | Kosten | Einrichtung | Privatsphäre |
|---|---|---|---|---|---|
| Ollama | Privatsphäre/Offline | Variabel* | Kostenlos | Fortgeschritten | Lokal |
| OpenAI | Höchste Qualität | ⭐⭐⭐⭐⭐ | 💰💰💰 | Einfach | Cloud |
| Claude | Kreative Inhalte | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Einfach | Cloud |
| DeepSeek | Budget-Projekte | ⭐⭐⭐⭐ | 💰 | Einfach | Cloud |
| Gemini | Mehrsprachig | ⭐⭐⭐⭐ | 💰 | Einfach | Cloud |
*Die Qualität bei Ollama variiert stark basierend auf dem verwendeten lokalen Modell - einige moderne lokale Modelle können Cloud-Anbieter erreichen oder übertreffen.
Anbieter-Konfigurationstipps
Für alle Cloud-Anbieter:
- Speichern Sie API-Schlüssel sicher und committen Sie sie nicht in die Versionskontrolle
- Beginnen Sie mit konservativen Temperatureinstellungen (0,3) für konsistente Übersetzungen
- Überwachen Sie Ihre API-Nutzung und Kosten
- Testen Sie mit kleinen Stapeln vor großen Übersetzungsläufen
Für Ollama:
- Stellen Sie ausreichend RAM sicher (8GB+ empfohlen für größere Modelle)
- Verwenden Sie SSD-Speicher für bessere Modellladeleistung
- Erwägen Sie GPU-Beschleunigung für schnellere Inferenz
- Testen Sie lokal, bevor Sie sich für Produktionsübersetzungen darauf verlassen