Sprachaktivitätserkennung
Streaming Sound Wave, zusammen mit seinen abgeleiteten Typen wie Capturable Sound Wave, unterstützt die Sprachaktivitätserkennung (VAD). VAD filtert eingehende Audiodaten und füllt den internen Puffer nur, wenn Sprache erkannt wird.
Das Plugin bietet zwei VAD-Implementierungen:
- Standard VAD
- Silero VAD
Die Standardimplementierung verwendet libfvad, eine leichtgewichtige Stimmaktivitätserkennungsbibliothek, die effizient auf allen Plattformen und Engine-Versionen funktioniert, die vom Runtime Audio Importer unterstützt werden.
Erhältlich als Erweiterungs-Plugin, ist Silero VAD ein auf neuronalen Netzen basierender Sprachaktivitätsdetektor, der eine höhere Genauigkeit bietet, insbesondere in lauten Umgebungen. Es verwendet maschinelles Lernen, um Sprache zuverlässiger von Hintergrundgeräuschen zu unterscheiden.
Grundlegende Nutzung
Um VAD nach dem Erstellen einer Sound Wave zu aktivieren, verwenden Sie die ToggleVAD-Funktion:
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
StreamingSoundWave->ToggleVAD(true);
Nachdem Sie VAD aktiviert haben, können Sie es jederzeit zurücksetzen:
- Blueprint
- C++
// Reset the VAD
StreamingSoundWave->ResetVAD();
Standard-VAD-Einstellungen
Wenn Sie den Standard-VAD-Provider verwenden, können Sie seine Aggressivität einstellen, indem Sie den VAD-Modus ändern:
- Blueprint
- C++
// Set the VAD mode (only works with the default VAD provider)
StreamingSoundWave->SetVADMode(ERuntimeVADMode::VeryAggressive);
Der mode-Parameter steuert, wie aggressiv die VAD das Audio filtert. Höhere Werte sind restriktiver, was bedeutet, dass sie weniger wahrscheinlich falsche Positive melden, dafür aber möglicherweise manche Sprachpassagen verpassen.
VAD-Anbieter
Nachdem Sie VAD mit der Funktion ToggleVAD aktiviert haben, können Sie zwischen verschiedenen Anbietern für Sprachaktivitätserkennung wählen, um Ihren Anforderungen gerecht zu werden. Der Standardanbieter ist integriert, während zusätzliche Anbieter wie Silero VAD über Erweiterungs-Plugins verfügbar sind.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Make sure to call ToggleVAD(true) before setting the provider
// Set the VAD provider to Silero VAD
StreamingSoundWave->SetVADProvider(URuntimeSileroVADProvider::StaticClass());
Den aktuellen VAD-Anbieter abrufen
Sie können den derzeit einer Streaming-Sound-Wave zugewiesenen VAD-Anbieter mithilfe der GetVADProvider-Funktion abrufen. Dies ist nützlich, wenn Sie auf anbieterspezifische Funktionen zugreifen müssen, wie beispielsweise die Sprachschwellwert-Einstellungen des Silero VAD, ohne eine separate Referenz vorhalten zu müssen.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Get the currently assigned VAD provider
URuntimeVADProviderBase* VADProvider = StreamingSoundWave->GetVADProvider();
Um auf anbieterspezifische Funktionen zuzugreifen, casten Sie den zurückgegebenen Anbieter in den gewünschten Typ. Beispielsweise, um auf Silero VAD-spezifische Funktionalität zuzugreifen:
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Get the currently assigned VAD provider and cast it to the Silero VAD provider
if (URuntimeSileroVADProvider* SileroVADProvider = Cast<URuntimeSileroVADProvider>(StreamingSoundWave->GetVADProvider()))
{
// Use Silero VAD-specific functionality, such as SetSpeechThreshold
}
Silero VAD Erweiterung
Silero VAD bietet eine genauere Spracherkennung mithilfe neuronaler Netze. So verwenden Sie es:
-
Stellen Sie sicher, dass das Runtime Audio Importer-Plugin bereits in Ihrem Projekt installiert ist.
-
Für UE 5.5 und früher: Bevor Sie das Silero VAD-Erweiterungs-Plugin herunterladen, stellen Sie sicher, dass NNERuntimeORT in Ihrem Projekt deaktiviert ist. Wenn NNERuntimeORT aktiviert ist, kann es bei der Verwendung von Silero VAD auf diesen Engine-Versionen aufgrund von Konflikten zu Abstürzen kommen.
-
Laden Sie das Silero VAD-Erweiterungsplugin von hier herunter.
-
Extrahieren Sie den Ordner aus dem heruntergeladenen Archiv in den
Plugins-Ordner Ihres Projekts (erstellen Sie diesen Ordner, falls er nicht existiert). -
Für UE 5.6 und höher: Bearbeiten Sie die Datei
RuntimeAudioImporterSileroVAD.uplugin, um die NNERuntimeORT-Abhängigkeit hinzuzufügen. Fügen Sie im "Plugins"-Feld nach der RuntimeAudioImporter-Einbindung Folgendes hinzu:,{"Name": "NNERuntimeORT","Enabled": true} -
Erstellen Sie Ihr Projekt neu (diese Erweiterung benötigt ein C++-Projekt)
-
Die standardmäßige VAD funktioniert mit allen von Runtime Audio Importer unterstützten Engine-Versionen (UE 4.24, 4.25, 4.26, 4.27, 5.0, 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7 und 5.8)
-
Silero VAD unterstützt Unreal Engine 4.27 und alle UE5-Versionen (4.27, 5.0, 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7 und 5.8)
-
UE 5.5 und früher: NNERuntimeORT muss deaktiviert werden, bevor man Silero VAD verwendet, um Abstürze aufgrund von Plugin-Konflikten zu vermeiden. In UE 5.3 speziell müssen NNERuntimeORTCpu und NNERuntimeORTGpu ebenfalls deaktiviert werden.
-
UE 5.6+ Anforderung: Ab Unreal Engine 5.6 erfordert die Silero VAD-Erweiterung, dass die NNERuntimeORT-Plugin-Abhängigkeit manuell zur
.uplugin-Datei hinzugefügt wird. -
Silero VAD ist verfügbar für Windows, Linux, Mac, Android (einschließlich Meta Quest) und iOS.
-
Diese Erweiterung wird als Quellcode bereitgestellt und erfordert ein C++-Projekt zur Nutzung.
-
Für weitere Informationen zum manuellen Erstellen von Plugins siehe das Tutorial zum Erstellen von Plugins
Sobald es installiert ist, können Sie es als Ihren VAD-Anbieter auswählen, indem Sie die Funktion SetVADProvider mit dem Silero-Klassenanbieter verwenden.
Sprachschwelle
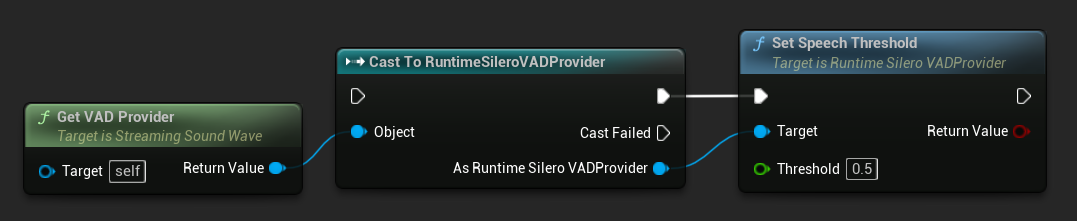
Der Silero VAD Provider bietet einen Speech Threshold-Parameter, der den minimalen Konfidenzwert (aus der Sprachwahrscheinlichkeitsausgabe des neuronalen Netzwerks) bestimmt, ab dem ein Audiosegment als Sprache betrachtet wird. Sie können ihn mit der Funktion SetSpeechThreshold setzen, die verfügbar ist, nachdem Sie den Provider mit GetVADProvider abgerufen und in den Typ des Silero VAD Providers gecastet haben.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Make sure the VAD provider has already been set to Silero VAD via SetVADProvider
// Get the VAD provider and cast it to the Silero VAD provider
if (URuntimeSileroVADProvider* SileroVADProvider = Cast<URuntimeSileroVADProvider>(StreamingSoundWave->GetVADProvider()))
{
// Set the speech threshold
bool bSuccess = SileroVADProvider->SetSpeechThreshold(0.5f);
}
SetSpeechThreshold gibt true zurück, wenn der Schwellenwert erfolgreich angewendet wurde, und andernfalls false (zum Beispiel, wenn der Wert außerhalb des gültigen Bereichs liegt).
Eine höhere Schwelle macht die Erkennung konservativer: Sie reduziert Falsch-Positive durch Hintergrundgeräusche, kann aber auch leisere oder weniger deutliche Sprache verpassen. Eine niedrigere Schwelle macht die Erkennung empfindlicher: Sie erfasst mehr Sprache, aber das Risiko von Falsch-Positiven steigt. Der Standardwert ist 0,5.
Erkennung von Sprachbeginn und -ende
Sprachaktivitätserkennung erkennt nicht nur das Vorhandensein von Sprache, sondern ermöglicht auch die Erkennung des Beginns und Endes der Sprachaktivität. Dies ist nützlich, um Ereignisse auszulösen, wenn während der Wiedergabe oder Aufnahme Sprache beginnt oder endet.
Sie können die Empfindlichkeit der Sprachstart- und Sprachendenerkennung anpassen, indem Sie Parameter wie die minimale Sprachdauer und die Stilledauer einstellen. Diese Parameter helfen, die Erkennung fein abzustimmen, um Fehlalarme zu vermeiden, wie das Aufnehmen von kurzen Geräuschen oder zu kurzen Pausen zwischen Sprachäußerungen.
Minimale Sprachdauer
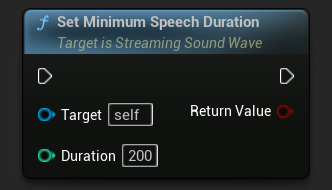
Der Parameter Minimale Sprachdauer legt die minimale Dauer kontinuierlicher Sprachaktivität fest, die erforderlich ist, um ein Sprachstart-Ereignis auszulösen. Dies hilft, kurze Geräusche herauszufiltern, die nicht als Sprache betrachtet werden sollten, um sicherzustellen, dass nur anhaltende Sprachaktivität erkannt wird. Der Standardwert für Minimale Sprachdauer beträgt 300 Millisekunden.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Set the minimum speech duration
StreamingSoundWave->SetMinimumSpeechDuration(200);
Stilledauer
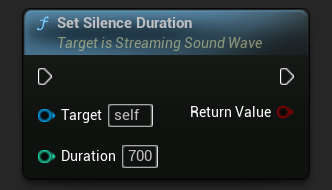
Der Parameter Stilledauer legt die Stilledauer fest, die erforderlich ist, um ein Sprachende-Ereignis auszulösen. Dies verhindert, dass die Spracherkennung bei natürlichen Pausen zwischen Wörtern oder Sätzen vorzeitig endet. Der Standardwert für Stilledauer beträgt 500 Millisekunden.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Set the silence duration
StreamingSoundWave->SetSilenceDuration(700);
Binden an Sprachdelegaten
Sie können sich an bestimmte Delegaten binden, wenn die Sprache beginnt oder endet. Dies ist nützlich, um benutzerdefiniertes Verhalten basierend auf Sprachaktivität auszulösen, wie das Starten oder Stoppen der Texterkennung oder das Anpassen der Lautstärke anderer Audioquellen.
- Blueprint
- C++
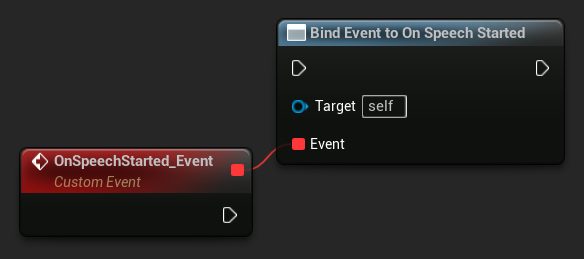
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Bind to the OnSpeechStartedNative delegate
StreamingSoundWave->OnSpeechStartedNative.AddWeakLambda(this, [this]()
{
// Handle the result when speech starts
});
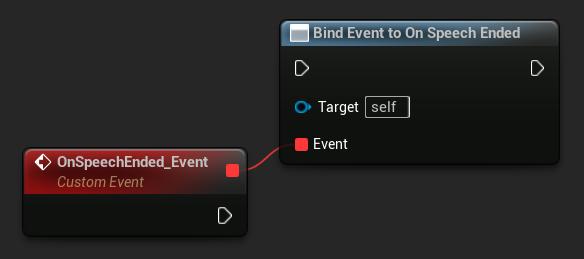
// Bind to the OnSpeechEndedNative delegate
StreamingSoundWave->OnSpeechEndedNative.AddWeakLambda(this, [this]()
{
// Handle the result when speech ends
});
Vergleich von VAD-Anbietern
- Standard VAD
- Silero VAD
Standard-VAD (libfvad)
Vorteile:
- Leichtgewichtig und effizient
- Funktioniert auf allen Plattformen
- Minimale Ressourcennutzung
- Geeignet für mobile und stromsparende Geräte
Am besten für:
- Einfache Spracherkennung in ruhigen Umgebungen
- Mobile Anwendungen
- Projekte, bei denen Leistung eine Priorität ist
- Wenn universelle Plattformunterstützung erforderlich ist
Silero VAD
Vorteile:
- Höhere Genauigkeit bei der Stimmerkennung
- Überlegene Geräuschtoleranz in schwierigen Umgebungen
- Konsistentere Ergebnisse bei verschiedenen Sprechern
- Erweiterte Konfigurationsoptionen für präzise Steuerung
Ideal für:
- Anwendungen, die eine präzise Stimmerkennung erfordern
- Umgebungen mit Hintergrundgeräuschen
- Spracherkennungssysteme
- Professionelle Audioanwendungen
Silero VAD erfordert möglicherweise mehr Rechenressourcen als das Standard-VAD.