Inferenzparameter
Die Struktur der LLM-Inferenzparameter steuert, wie das Modell geladen wird und Text generiert. Sie übergeben diese Parameter beim Laden eines Modells. Diese Seite beschreibt jeden Parameter und seine Wirkung.
Parameterreferenz
| Parameter | Type | Standard | Bereich | Beschreibung |
|---|---|---|---|---|
| Max Tokens | int32 | 512 | 1–8192 | Maximale Anzahl von Tokens, die in einer einzelnen Antwort generiert werden sollen |
| Temperatur | float | 0.7 | 0.0–2.0 | Steuert die Zufälligkeit. 0,0 = deterministisch. Höhere Werte = kreativere Ausgabe. |
| Top P | float | 0.9 | 0,0–1,0 | Nucleus-Sampling. Es werden nur Tokens berücksichtigt, deren kumulative Wahrscheinlichkeit diesen Wert überschreitet. |
| Top K | int32 | 40 | 0–200 | Begrenzt die Auswahl auf die K wahrscheinlichsten Tokens. 0 = deaktiviert |
| Wiederholungsstrafe | float | 1.1 | 0.0–3.0 | Bestraft Tokens, die bereits in der Ausgabe vorkommen. 1.0 = keine Bestrafung |
| Anzahl der GPU-Layer | int32 | -1 | -1–200 | Model-Ebenen, die auf die GPU ausgelagert werden sollen. -1 = automatisch. 0 = nur CPU. |
| Kontextgröße | int32 | 2048 | 128–131072 | Maximale Kontextfenster in Tokens. Größere Werte verbrauchen mehr Speicher. |
| System-Prompt | FString | „Du bist ein hilfreicher Assistent.“ | — | Systemanweisung, die das Verhalten des Modells prägt |
| Seed | int32 | -1 | -1+ | Zufälliger Startwert für reproduzierbare Ausgabe. -1 = zufällig |
| Anzahl der Threads | int32 | 0 | 0–128 | CPU-Threads für die Generierung. 0 = automatisch |
Nutzung
- Blueprint
- C++
Inferenzparameter erscheinen als Struct-Pin auf Load- und Async-Nodes. Brechen Sie das Struct auf, um einzelne Werte festzulegen:
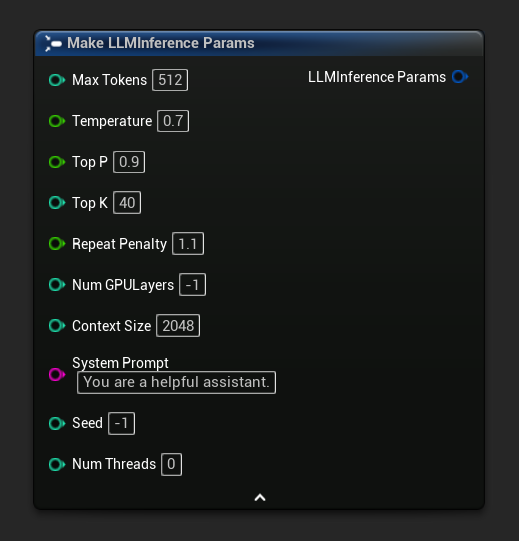
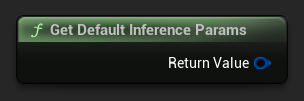
Um einen Standardsatz von Parametern als Ausgangspunkt zu erhalten, verwenden Sie Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Plattform-Empfehlungen
Mobil / VR (Android, iOS, Meta Quest)
- Kontextgröße: 1024–2048
- Anzahl GPU-Schichten: 0 (nur CPU), sofern das Gerät nicht über bestätigte GPU-Compute-Unterstützung verfügt
- Maximale Token-Anzahl: Unter 256 für reaktionsschnelle Interaktionen
- Anzahl Threads: 2–4, abhängig vom Gerät
Desktop (Windows, Mac, Linux)
- Kontextgröße: 2048–8192 für die meisten Gespräche
- Anzahl GPU-Schichten: -1 (automatisch) zur Nutzung der GPU-Beschleunigung, falls verfügbar
- Anzahl Threads: 0 (automatisch)
- Maximale Token: 512–2048 für längere Antworten
Lang andauernde Gespräche
Wenn Ihre Anwendung Gespräche über lange Sitzungen hinweg aufrechterhält (NPC-Dialoge, dauerhafte Assistenten, Rollenspiele), sollten Sie Ihre Kontextgröße eher mit automatischer Zusammenfassung kombinieren, anstatt einfach die Context Size zu erhöhen. Eine moderate Context Size von 2048–4096 mit aktivierter automatischer Zusammenfassung hält Latenz und Speichernutzung stabil, während größere Kontextfenster jede Generierung zunehmend verlangsamen. Siehe Automatische Kontextzusammenfassung.