Audio-Verarbeitungsleitfaden
Diese Anleitung beschreibt, wie Sie verschiedene Audioeingabemethoden einrichten, um Audiodaten an Ihre Lippen-Synchronisations-Generatoren zu übermitteln. Stellen Sie sicher, dass Sie die Einrichtungsanleitung abgeschlossen haben, bevor Sie fortfahren.
Audio-Eingabeverarbeitung
Sie müssen eine Methode zur Verarbeitung von Audioeingaben einrichten. Es gibt mehrere Möglichkeiten, dies zu tun, abhängig von Ihrer Audioquelle.
- Mikrofon (Echtzeit)
- Mikrofon (Wiedergabe)
- Text-to-Speech (Lokal)
- Text-to-Speech (externe APIs)
- Aus Audiodatei/Puffer
- Streaming-Audio-Puffer
Dieser Ansatz führt die Lippensynchronisation in Echtzeit durch, während Sie ins Mikrofon sprechen:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Erstellen Sie eine aufnehmbare Schallwelle mit dem Runtime Audio Importer.
- Für Linux mit Pixel Streaming verwenden Sie stattdessen Pixel Streaming Capturable Sound Wave.
- Bevor Sie mit der Audioaufnahme beginnen, binden Sie sich an den
OnPopulateAudioData-Delegaten - Rufen Sie in der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator auf - Starten Sie die Audioaufnahme über das Mikrofon
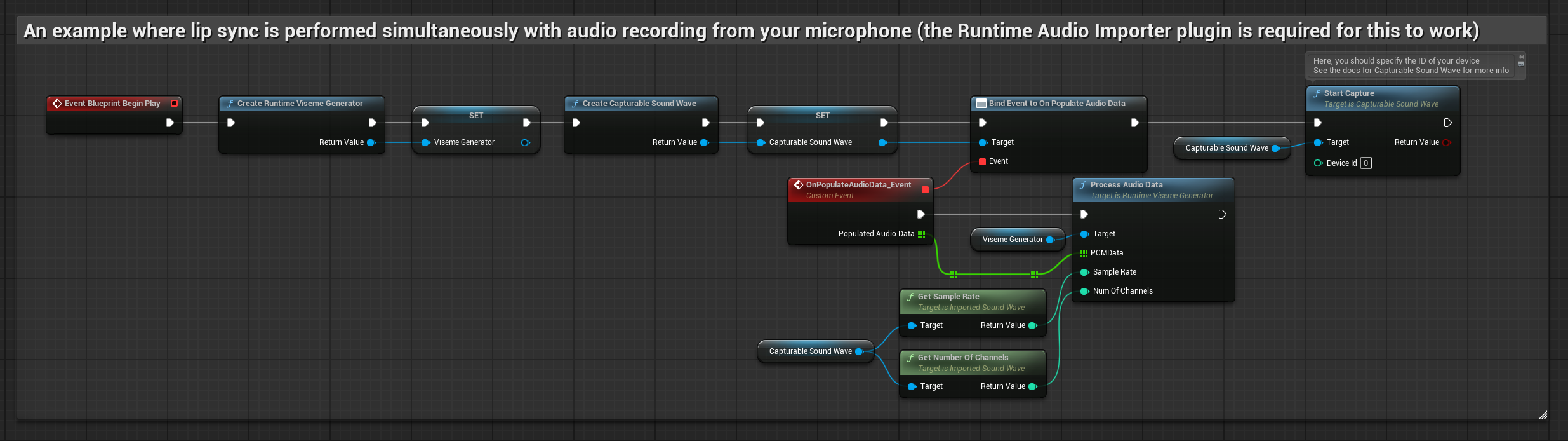
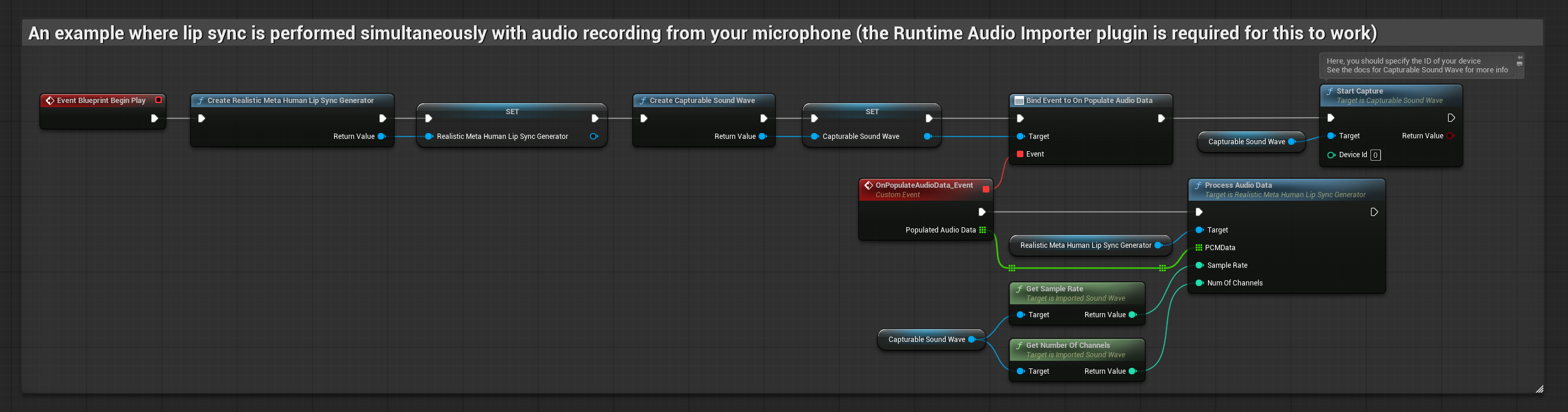
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für die Stimmung.

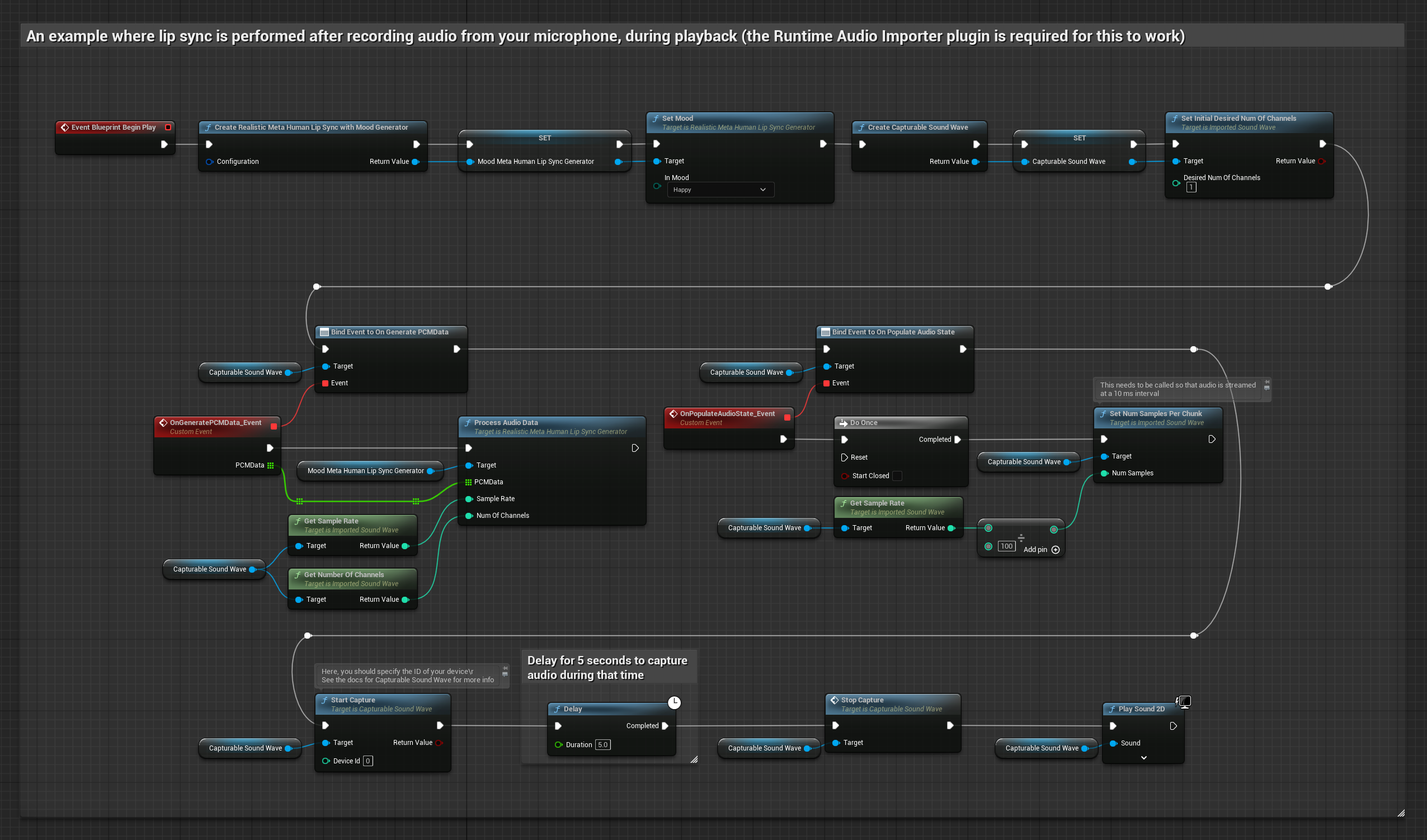
Dieser Ansatz erfasst Audio von einem Mikrofon und gibt es dann mit Lippen-Synchronisation wieder:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Erstellen Sie eine aufnehmbare Schallwelle mit dem Runtime Audio Importer.
- Für Linux mit Pixel Streaming verwenden Sie stattdessen Pixel Streaming Capturable Sound Wave.
- Audioaufnahme vom Mikrofon starten
- Bevor die aufnehmbare Schallwelle abgespielt wird, an deren
OnGeneratePCMData-Delegate binden - In der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator aufrufen
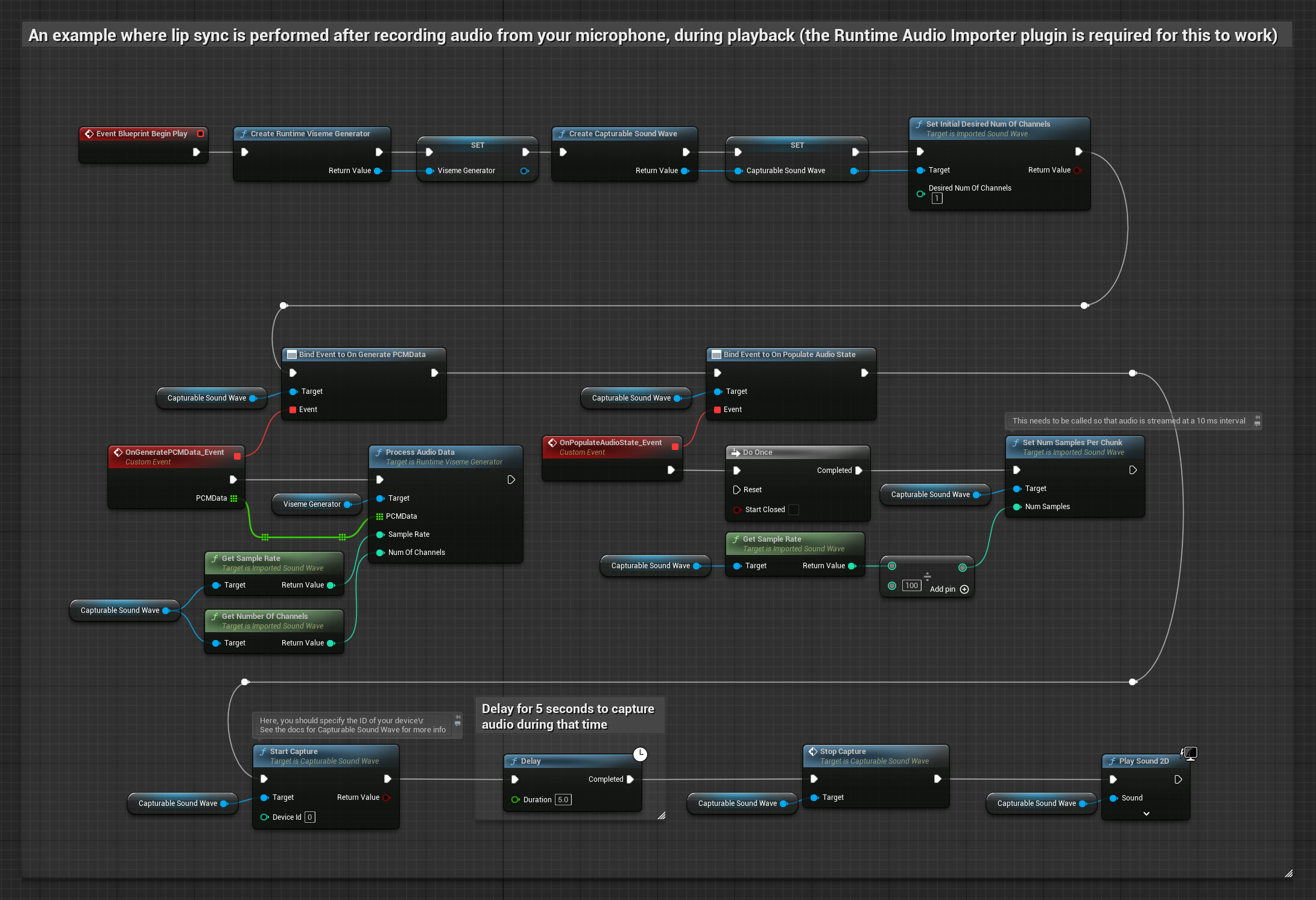
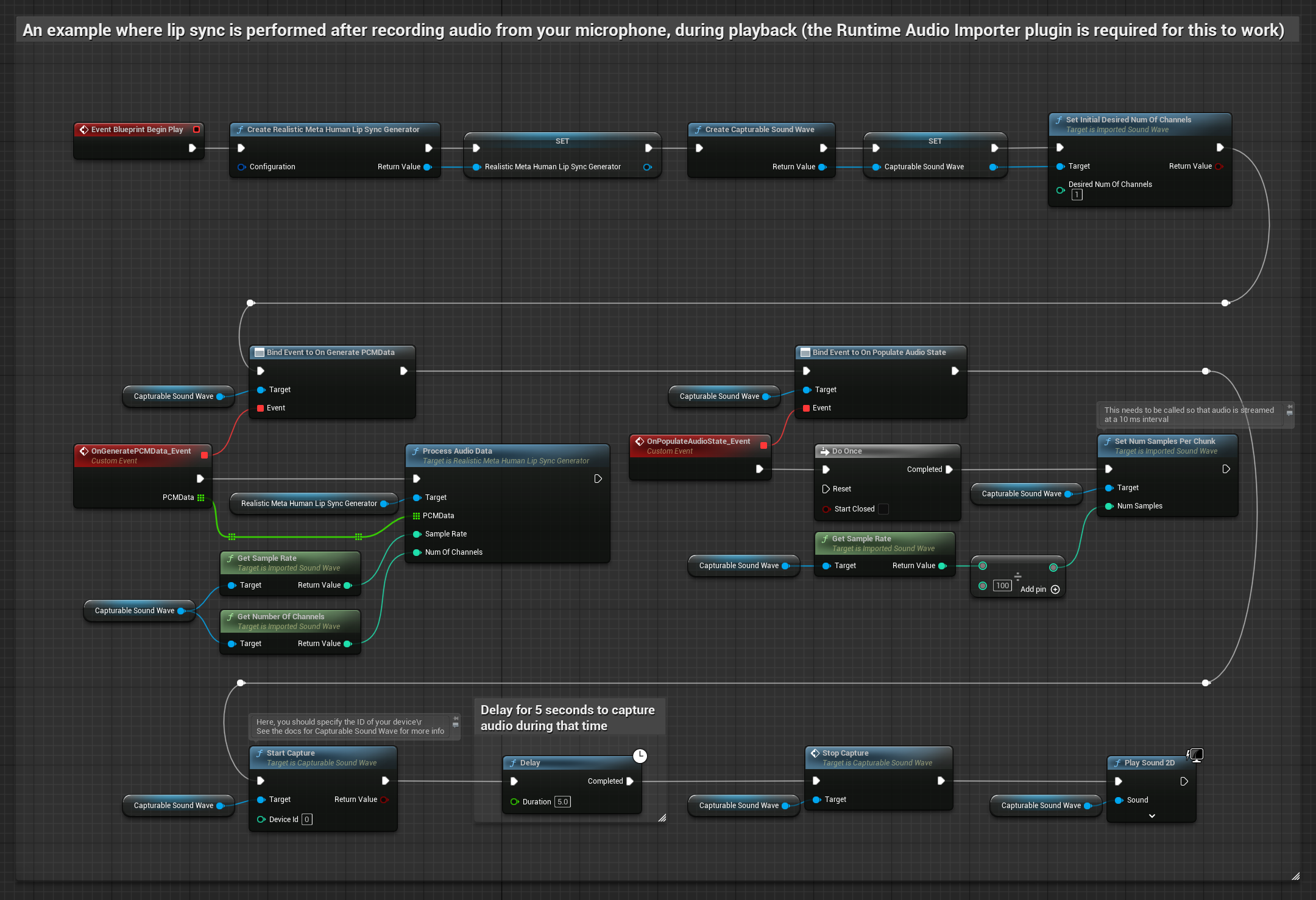
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.
- Regulär
- Streaming
Dieser Ansatz synthetisiert Sprache aus Text mittels lokaler TTS und führt Lippensynchronisation durch:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Verwenden Sie Runtime Text To Speech, um Sprache aus Text zu generieren
- Verwenden Sie Runtime Audio Importer, um die synthetisierte Audio-Datei zu importieren
- Bevor Sie die importierte Schallwelle abspielen, binden Sie sich an deren
OnGeneratePCMData-Delegaten - Rufen Sie in der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator auf
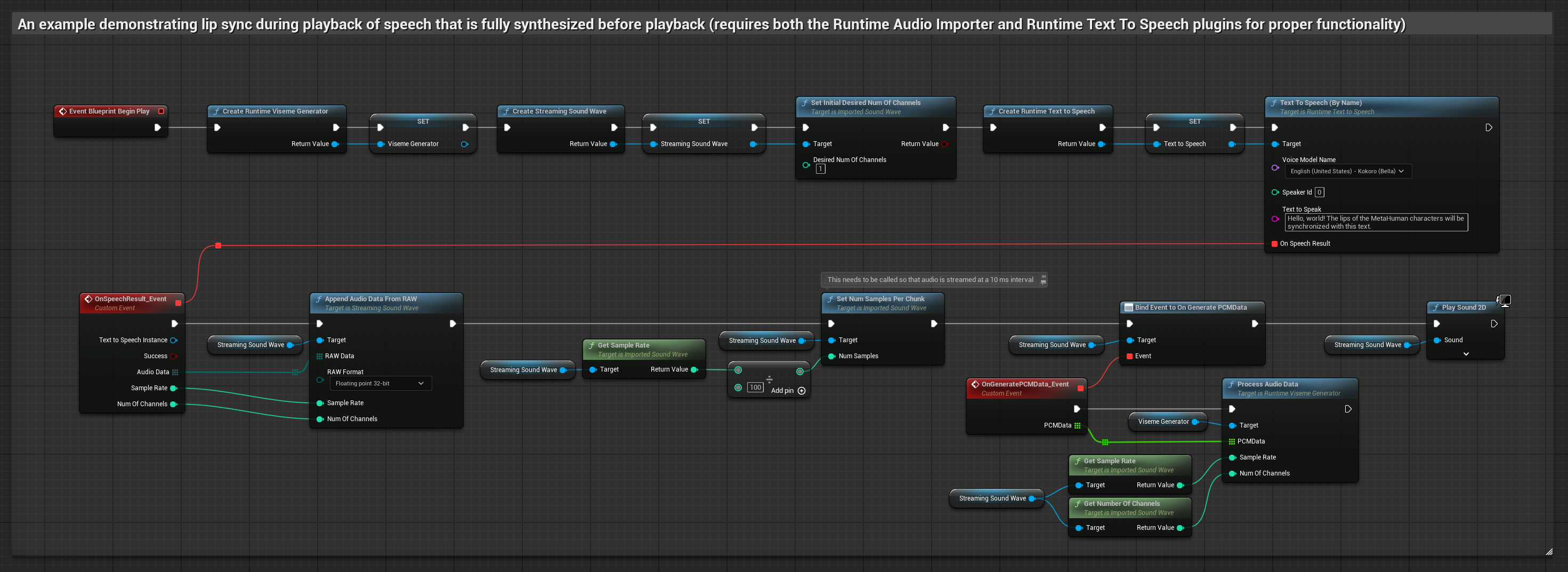
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
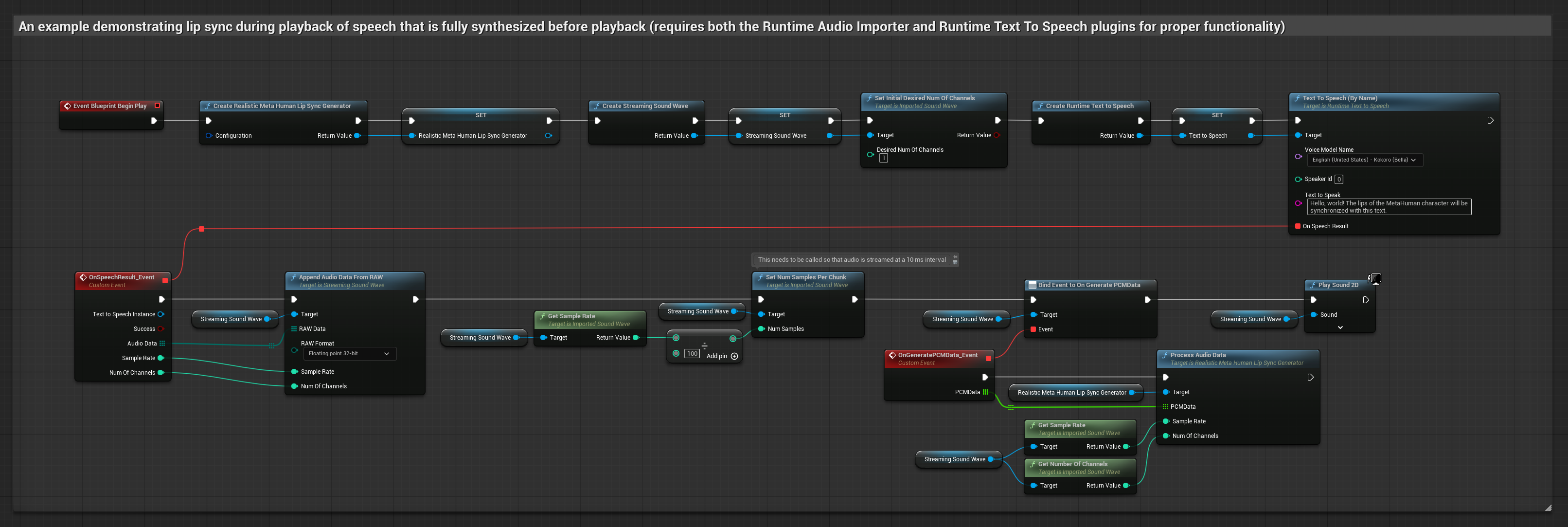
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.
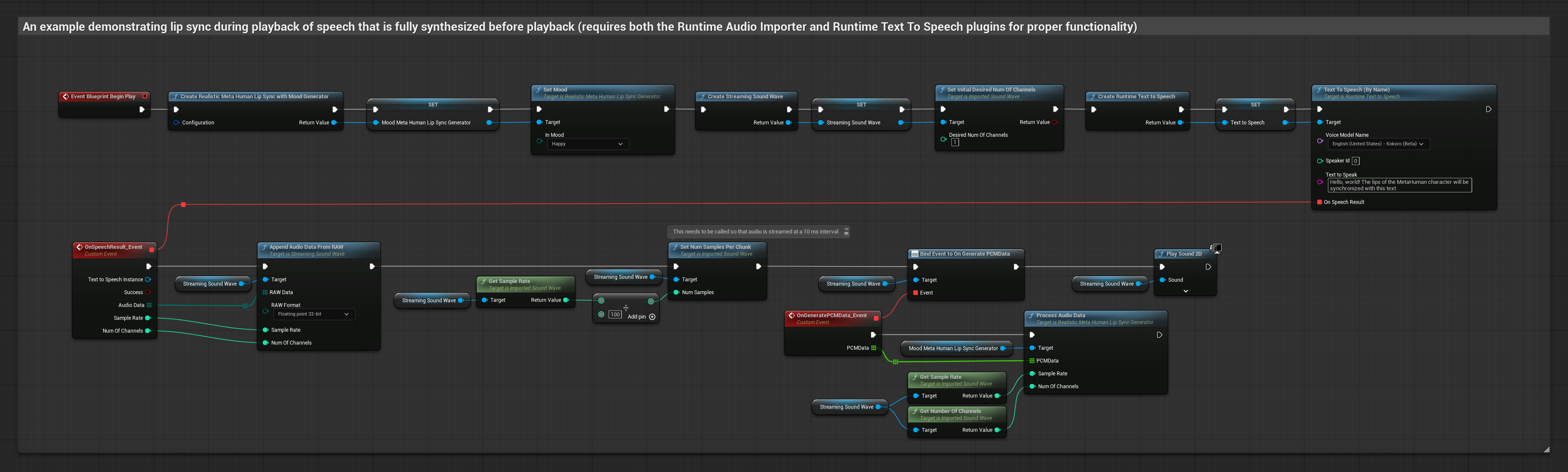
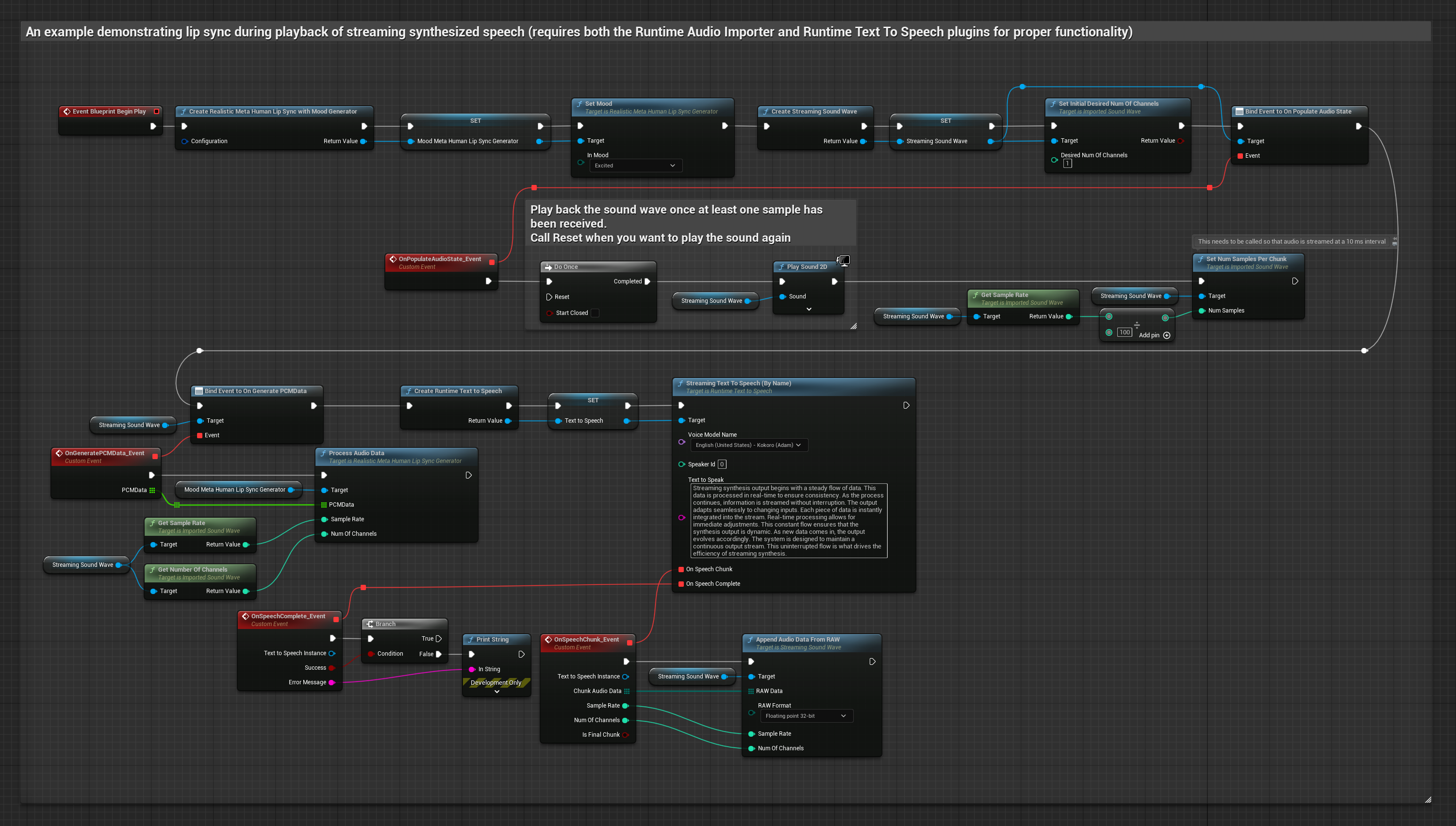
Dieser Ansatz verwendet eine Streaming-Text-zu-Sprache-Synthese mit Echtzeit-Lippensynchronisation:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Verwenden Sie Runtime Text To Speech, um Streaming-Sprache aus Text zu generieren
- Verwenden Sie Runtime Audio Importer, um die synthetisierte Audio-Datei zu importieren
- Bevor Sie die Streaming-Sound-Wave abspielen, binden Sie an deren
OnGeneratePCMData-Delegate - Rufen Sie in der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator auf
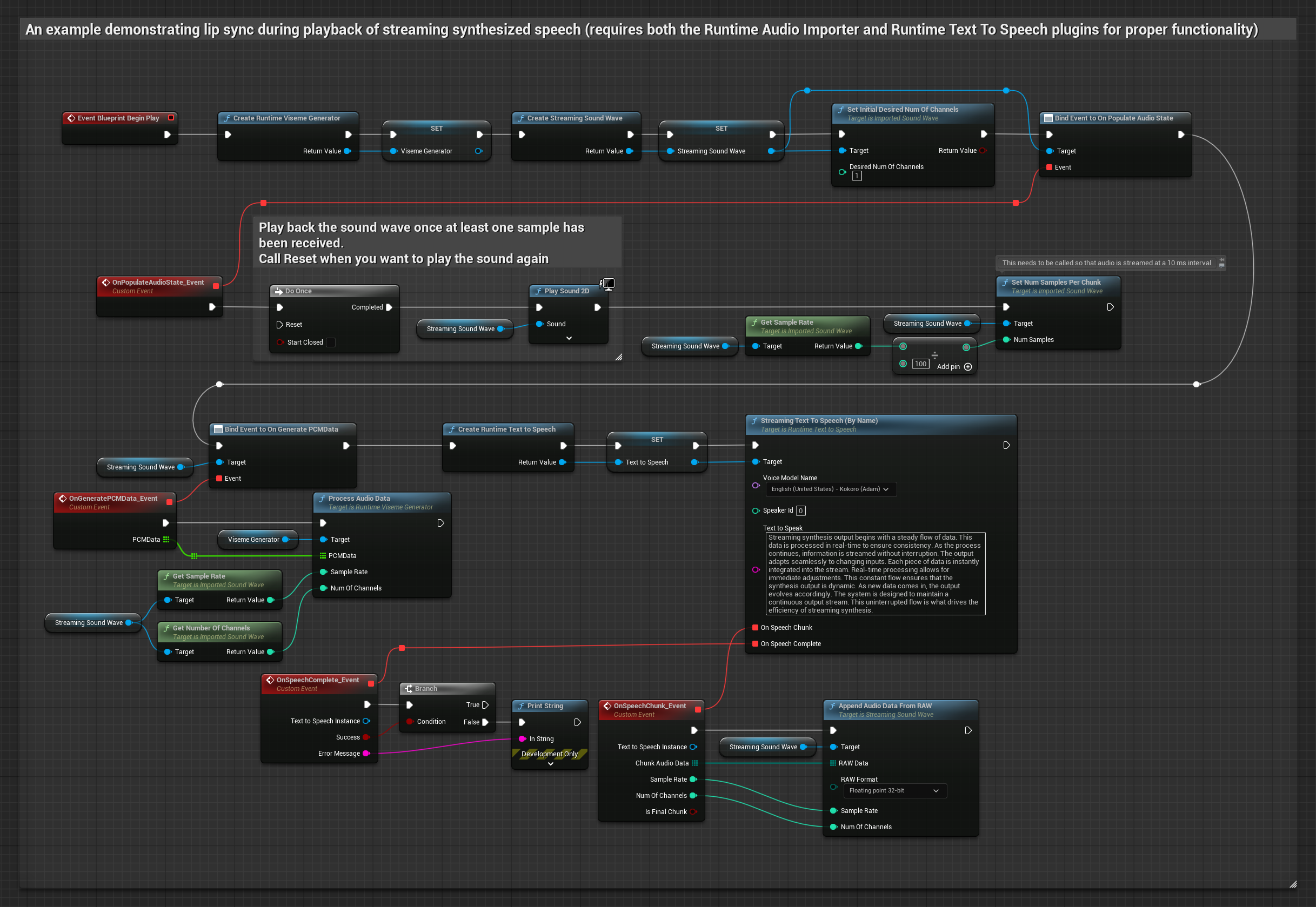
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
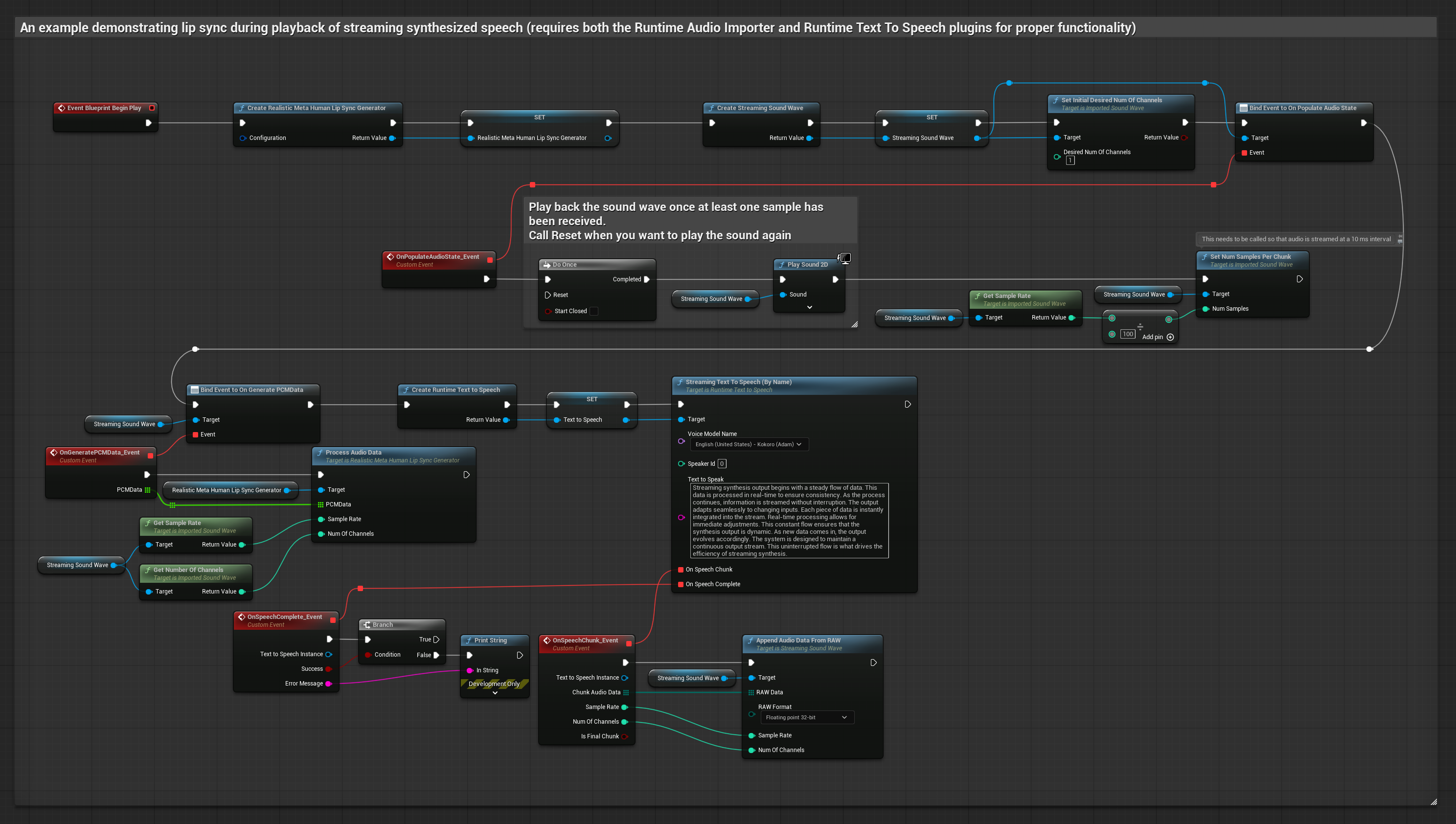
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.
- Regulär
- Streaming
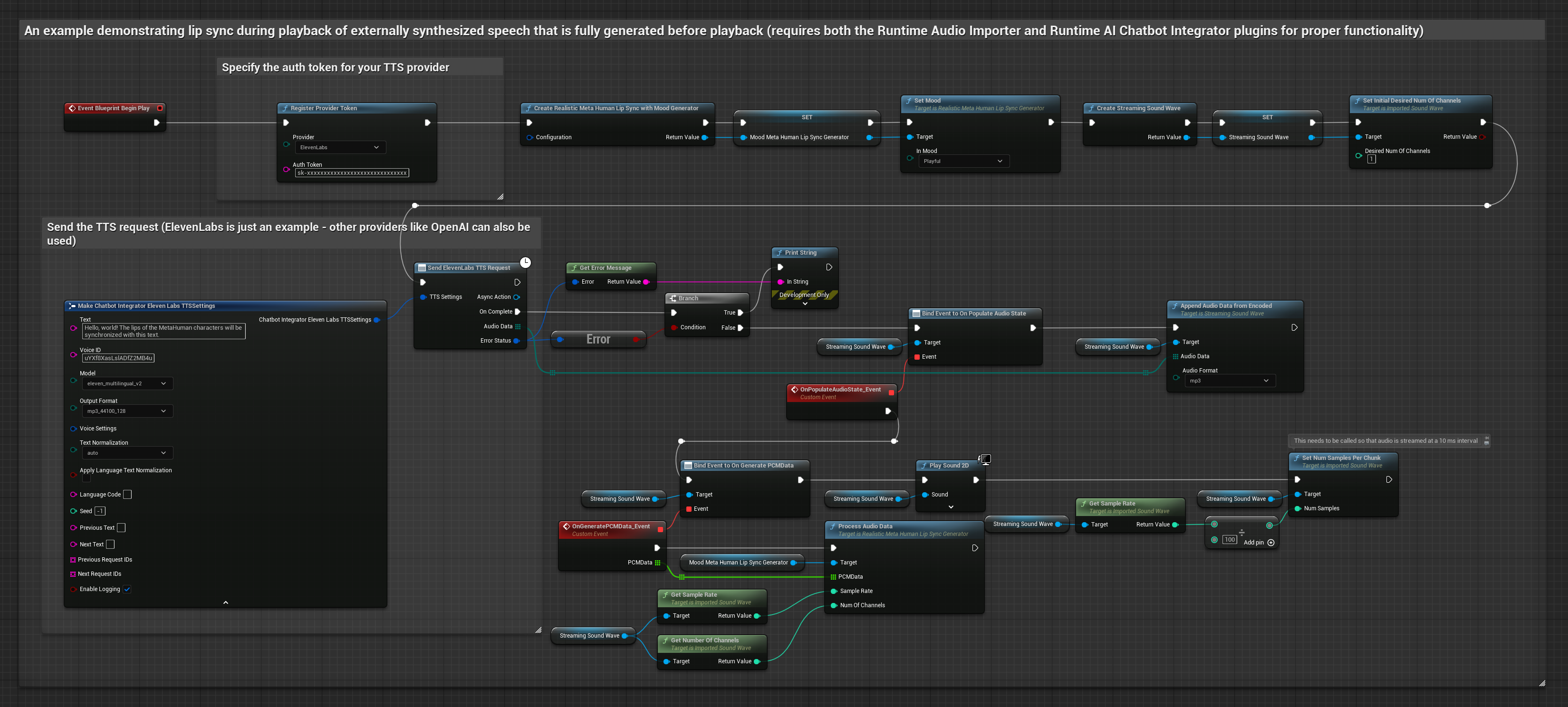
Dieser Ansatz verwendet das Plugin „Runtime AI Chatbot Integrator“, um synthetisierte Sprache von KI-Diensten (OpenAI oder ElevenLabs) zu generieren und eine Lippensynchronisation durchzuführen:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Verwenden Sie den Runtime AI Chatbot Integrator, um Sprache aus Text mithilfe externer APIs (OpenAI, ElevenLabs usw.) zu generieren.
- Verwenden Sie den Runtime Audio Importer, um die synthetisierten Audiodaten zu importieren.
- Bevor Sie die importierte Schallwelle abspielen, binden Sie sich an deren
OnGeneratePCMData-Delegaten. - Rufen Sie in der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator auf.
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
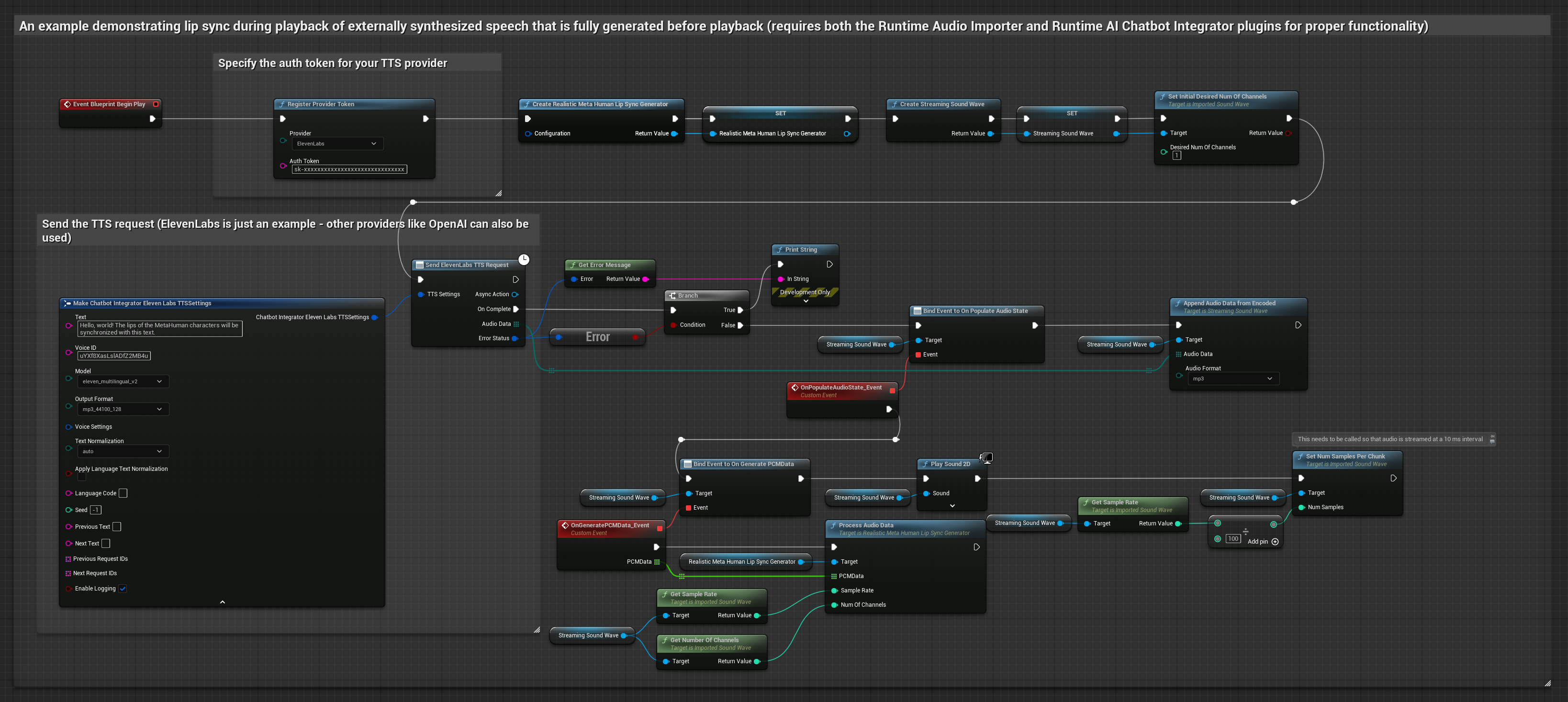
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.
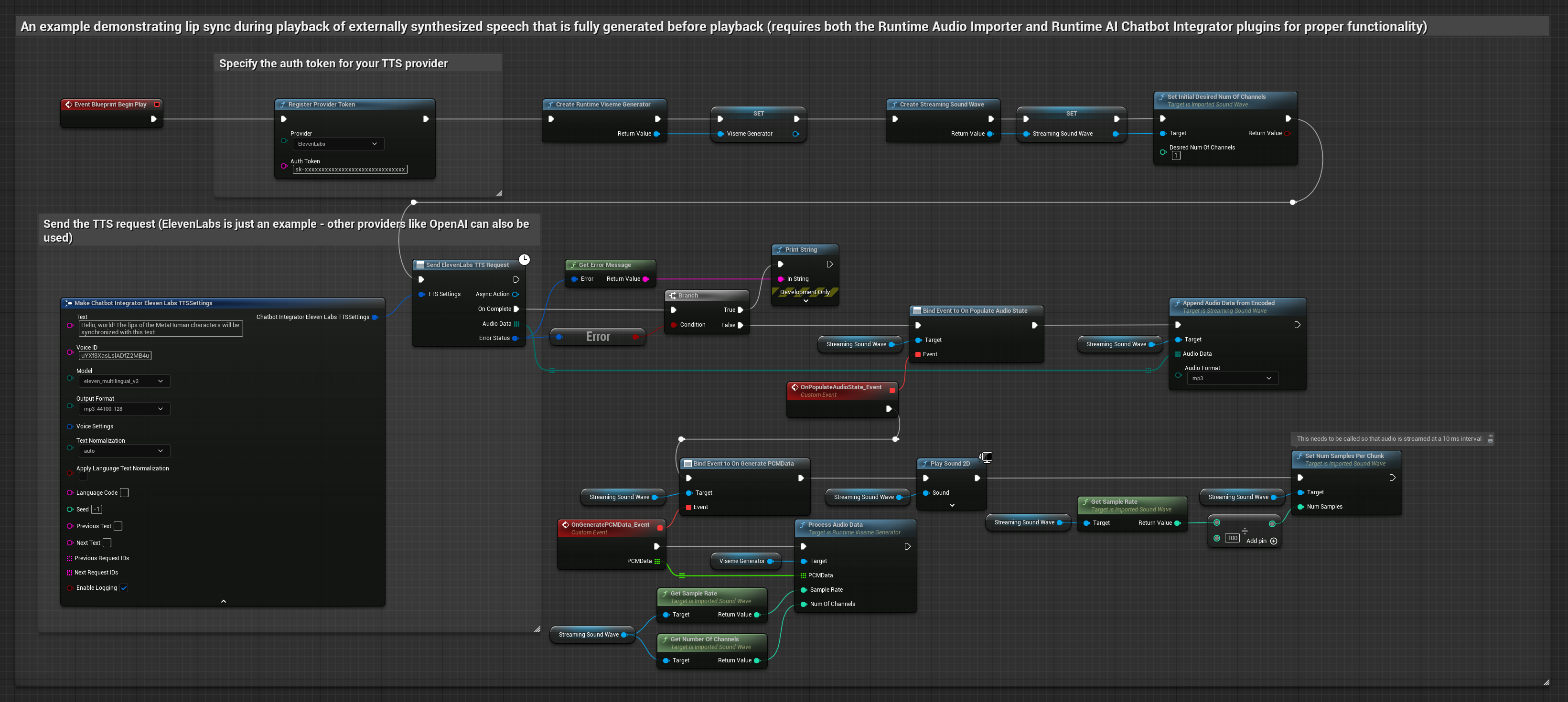
Dieser Ansatz verwendet das Plugin „Runtime AI Chatbot Integrator“, um synthetisierte Streaming-Sprache aus KI-Diensten (OpenAI oder ElevenLabs) zu generieren und Lippen-Synchronisation durchzuführen:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Verwenden Sie Runtime AI Chatbot Integrator, um eine Verbindung zu Streaming-TTS-APIs (wie der ElevenLabs Streaming API) herzustellen
- Verwenden Sie Runtime Audio Importer, um die synthetisierten Audiodaten zu importieren
- Binden Sie vor der Wiedergabe der Streaming-Soundwelle an dessen
OnGeneratePCMData-Delegate - Rufen Sie in der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator auf
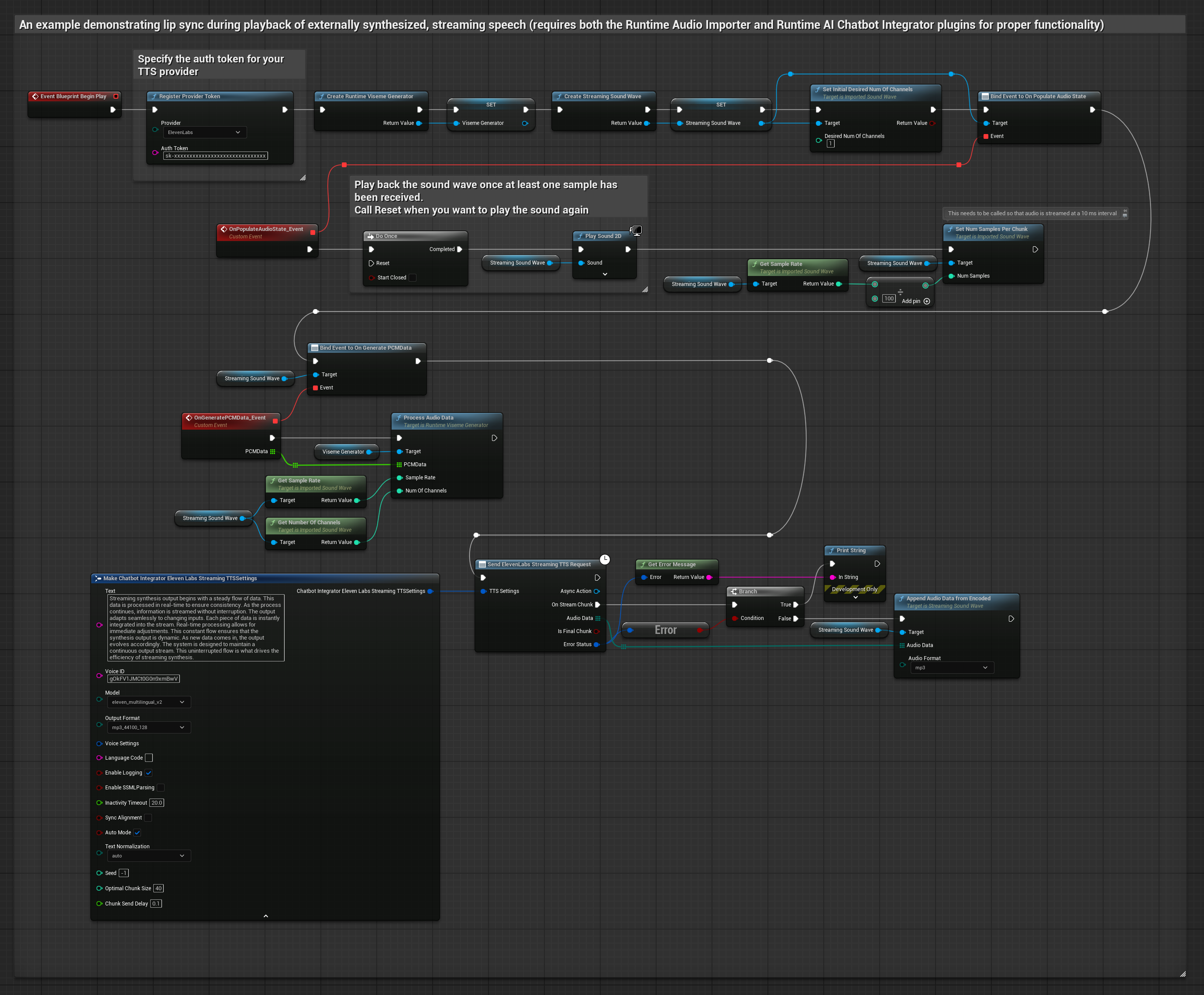
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
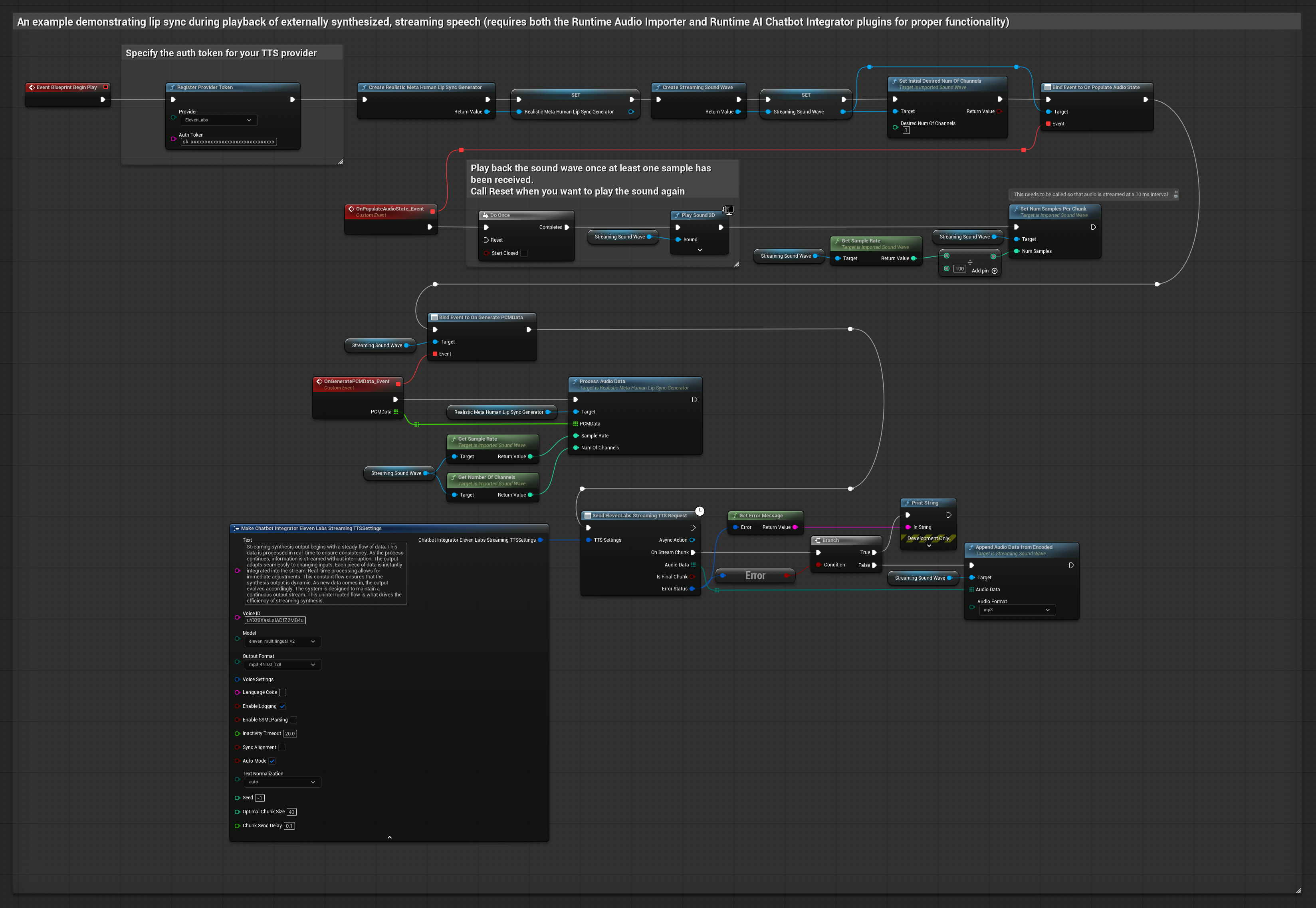
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.

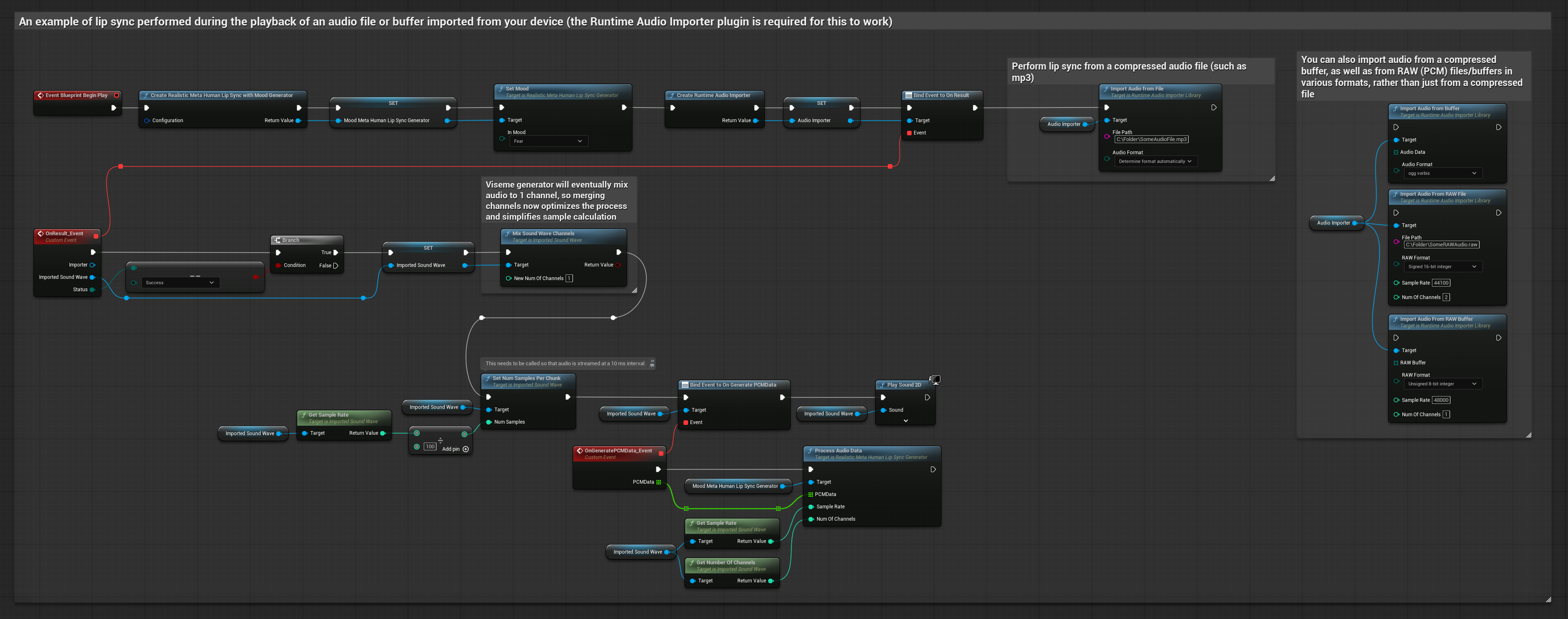
Dieser Ansatz verwendet vorab aufgezeichnete Audiodateien oder Audiopuffer für die Lippensynchronisation:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Verwenden Sie Runtime Audio Importer, um eine Audiodatei von der Festplatte oder aus dem Speicher zu importieren
- Bevor Sie die importierte Schallwelle abspielen, binden Sie sich an deren
OnGeneratePCMData-Delegaten - Rufen Sie in der gebundenen Funktion
ProcessAudioDatavon Ihrem Runtime Viseme Generator auf - Spielen Sie die importierte Schallwelle ab und beobachten Sie die Lippen-Synchronisationsanimation
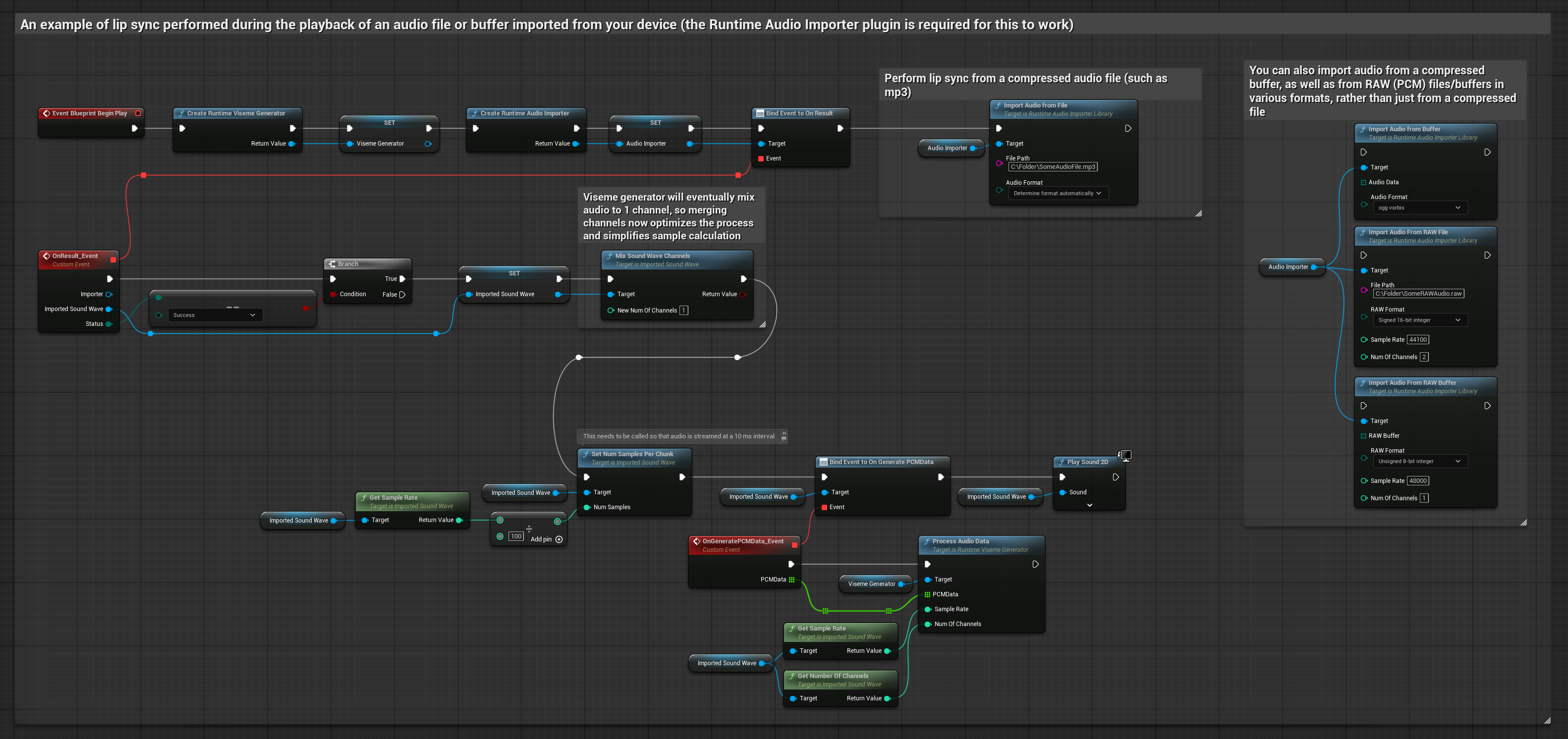
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
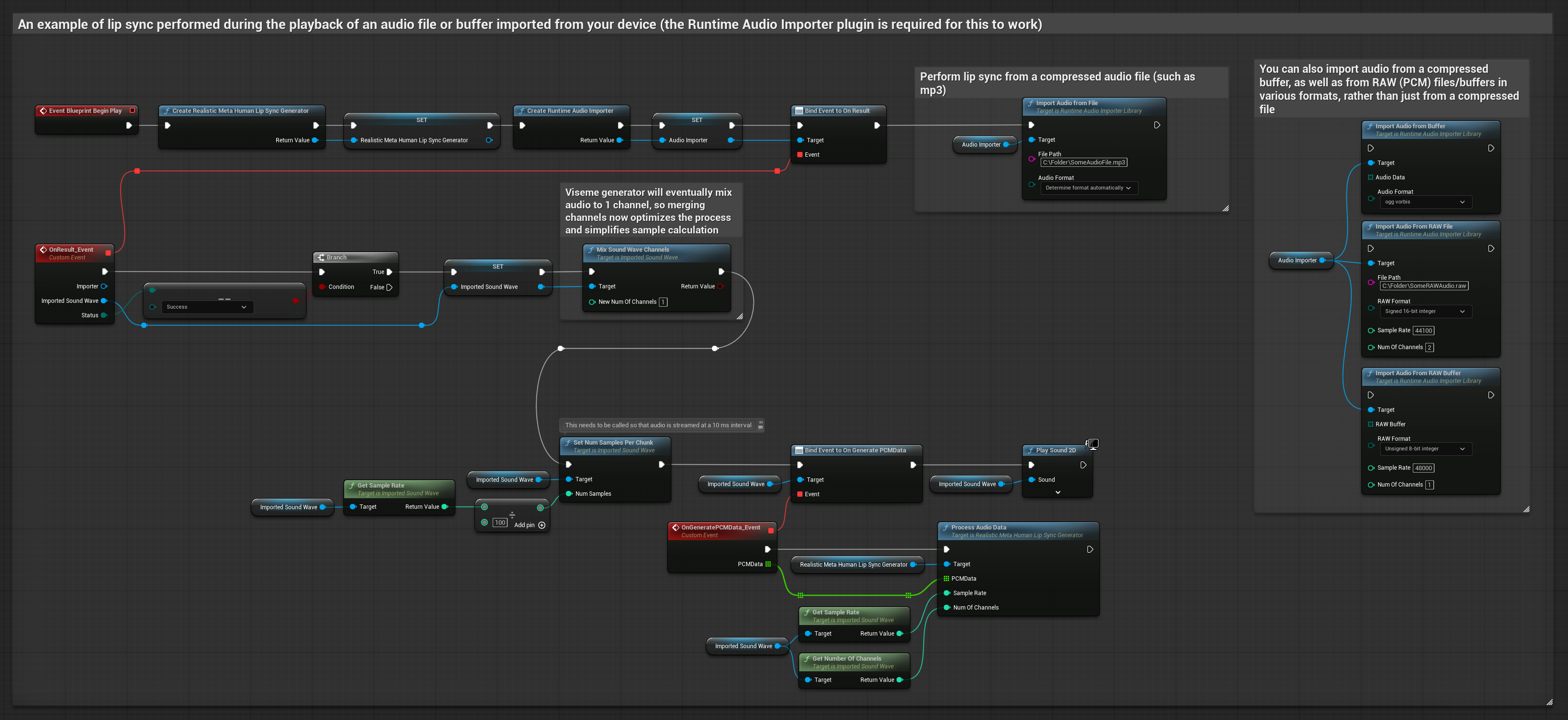
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.
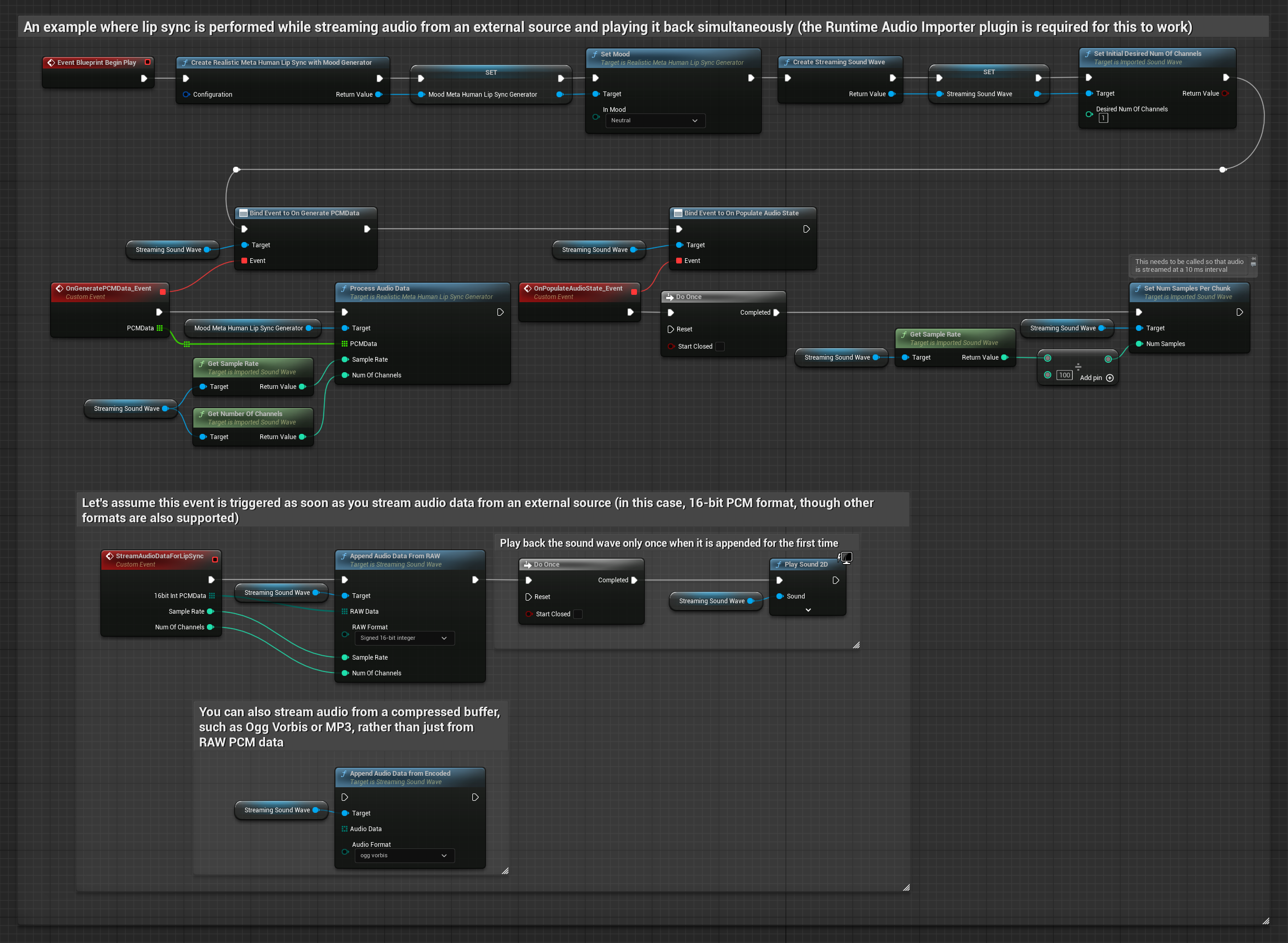
Für das Streamen von Audiodaten aus einem Puffer benötigen Sie:
- Standardmodell
- Realistisches Modell
- Stimmungsgesteuertes realistisches Modell
- Audiodaten im Float-PCM-Format (ein Array von Gleitkomma-Samples), die von Ihrer Streaming-Quelle verfügbar sind (oder verwenden Sie Runtime Audio Importer, um weitere Formate zu unterstützen)
- Die Abtastrate und die Anzahl der Kanäle
- Rufen Sie
ProcessAudioDatavon Ihrem Runtime Viseme Generator mit diesen Parametern auf, sobald Audio-Chunks verfügbar werden
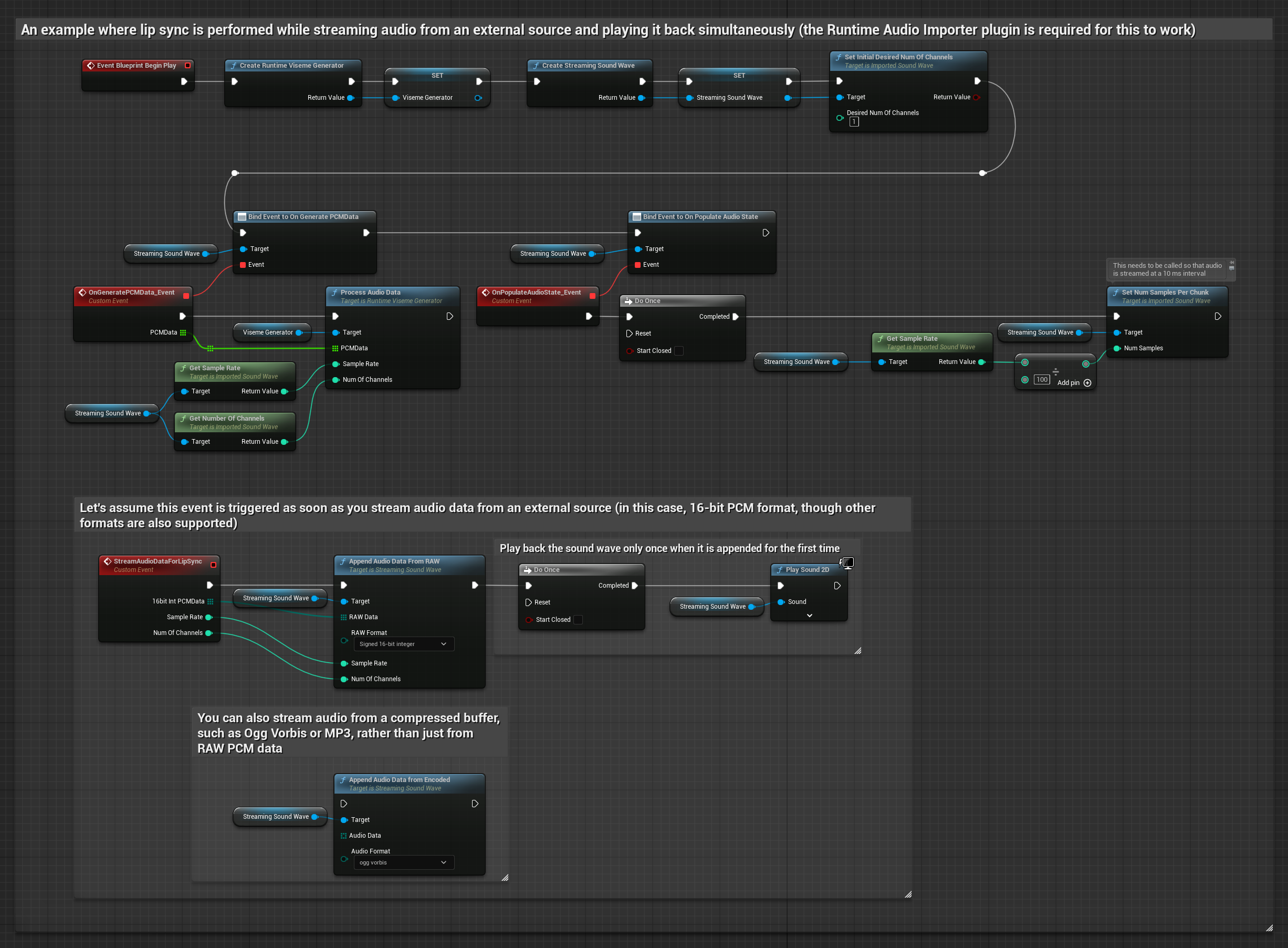
Das realistische Modell verwendet denselben Audioverarbeitungs-Workflow wie das Standardmodell, jedoch mit der Variable RealisticLipSyncGenerator anstelle von VisemeGenerator.
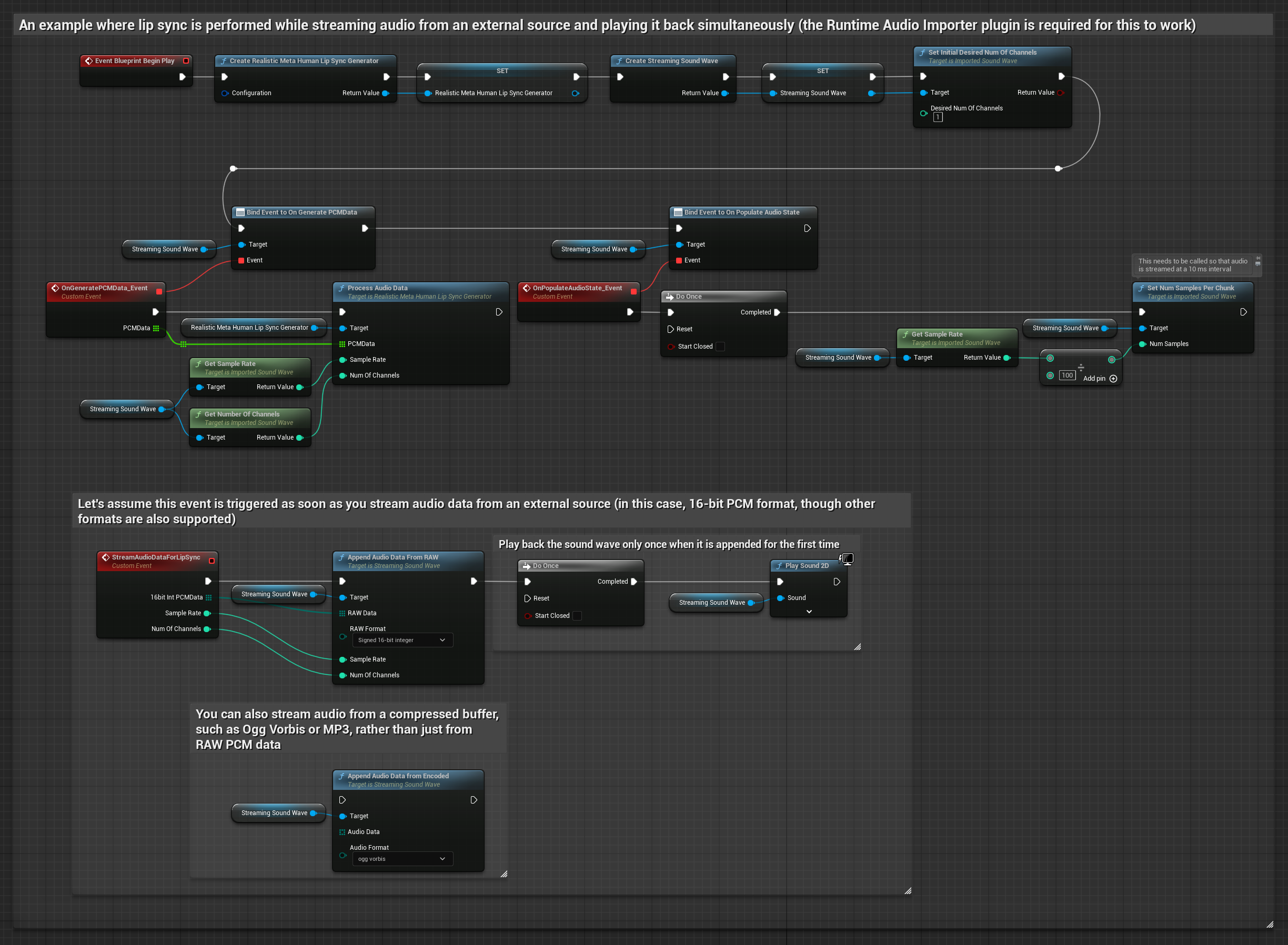
Das stimmungsfähige Modell verwendet denselben Audioverarbeitungs-Workflow, jedoch mit der Variable MoodMetaHumanLipSyncGenerator und zusätzlichen Konfigurationsmöglichkeiten für Stimmungen.
Hinweis: Bei der Verwendung von Streaming-Audioquellen stellen Sie sicher, dass die Audiowiedergabe zeitlich angemessen gesteuert wird, um verzerrte Wiedergabe zu vermeiden. Weitere Informationen finden Sie in der Dokumentation zu Streaming Sound Wave.
Leistungstipps zur Verarbeitung
-
Chunk-Größe: Eine Erhöhung der
ProcessingChunkSizeKonfigurationsoption (z. B. auf 320, 480 oder 640 Samples) kann die Latenz spürbar verbessern, bei minimalen Auswirkungen auf Qualität oder Reaktionsfähigkeit. -
Modelltyp: Bei Verwendung realistischer Modelle kann der Wechsel zum hochoptimierten Modelltyp (standardmäßig ausgewählt) die Leistung verbessern. Beachten Sie, dass das ursprüngliche Modell möglicherweise eine etwas bessere Qualität liefert, insbesondere bei verrauschten Audiodaten.
-
Puffer-Verwaltung: Das stimmungsfähige Modell verarbeitet Audio in 320-Sample-Frames (20 ms bei 16 kHz). Stellen Sie sicher, dass Ihr Audio-Eingabe-Timing für eine optimale Leistung darauf abgestimmt ist.
-
Generator-Neuerstellung: Für einen zuverlässigen Betrieb mit realistischen Modellen erstellen Sie den Generator jedes Mal neu, wenn Sie nach einer Phase der Inaktivität neue Audiodaten zuführen möchten. Siehe Generator-Neuerstellung im Abschnitt zur Fehlerbehebung für die Erklärung.
Nächste Schritte
Sobald Sie die Audioverarbeitung eingerichtet haben, möchten Sie vielleicht:
- Erfahren Sie mehr über Konfigurationsoptionen, um Ihr Lippensynchronisationsverhalten fein abzustimmen
- Fügen Sie Lachanimationen für eine verbesserte Ausdruckskraft hinzu
- Kombinieren Sie die Lippensynchronisation mit vorhandenen Gesichtsanimationen mithilfe der im Konfigurationsleitfaden beschriebenen Schichtungstechniken