Demoprojekte
Um Ihnen den schnellen Einstieg in Runtime MetaHuman Lip Sync zu erleichtern, stehen zwei gebrauchsfertige Demoprojekte zur Verfügung. Beide wurden mit Unreal Engine 5.6+ erstellt, sind Blueprint-only und laufen plattformübergreifend auf Windows, Mac, Linux, iOS, Android sowie Android-basierten Plattformen (einschließlich Meta Quest).
Verfügbare Demo-Projekte
- KI-Konversations-NPC / Interaktiver Avatar
- Grundlegende Lippensynchronisations-Demo
Ein vollständiger KI-gestützter Konversations-Avatar-Workflow, der Spracherkennung, einen KI-Chatbot (LLM), Text-to-Speech und Audiowiedergabe mit Echtzeit-Lippensynchronisation kombiniert – alles läuft gemeinsam in einem einzigen Projekt. Geeignet für eine Vielzahl von Anwendungsfällen – darunter Spiele, interaktive Kioske, virtuelle Produktion, Museumsinstallationen, digitale Assistenten und Trainingssimulationen.
Pipeline-Übersicht
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Videos
Kurze Vorschau (~30 Sek.)
Eine kurze Vorführung der Demo in Aktion.
Komplette Durchführung
Eine detaillierte Anleitung, die Einrichtung, Konfiguration und die gesamte Konversationspipeline abdeckt.
Downloads
Erforderliche & optionale Plugins
Das Demoprojekt ist modular aufgebaut – Sie benötigen nur die Plugins für die Anbieter, die Sie verwenden möchten.
| Plugin | Zweck | Erforderlich? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Lippensynchronisations-Animation | ✅ Immer |
| Runtime Audio Importer | Audioaufnahme & -verarbeitung | ✅ Immer |
| Runtime Speech Recognizer | Offline-Spracherkennung (whisper.cpp) | ✅ Immer |
| Runtime AI Chatbot Integrator | Externe LLMs (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) und/oder externes TTS (OpenAI, ElevenLabs) | 🔶 Optional |
| Runtime Local LLM | Lokale LLM-Inferenz via llama.cpp (Llama, Mistral, Gemma, usw., GGUF-Modelle) | 🔶 Optional |
| Runtime Text To Speech | Lokales TTS via Piper und Kokoro | 🔶 Optional |
Während jedes der oben genannten Plugins einzeln optional ist, benötigst du mindestens einen LLM-Anbieter und mindestens einen TTS-Anbieter, damit die Demo funktioniert. Mische und kombiniere frei (z. B. lokales LLM + ElevenLabs TTS oder OpenAI LLM + lokales TTS).
Modulare Architektur
Im Content-Ordner finden Sie einen Modules-Ordner, der drei Unterordner enthält:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Falls Sie eines (oder mehrere) der optionalen Plugins nicht erworben haben, löschen Sie einfach den/die entsprechenden Ordner. Die Basis-Assets des Demoprojekts (Spielinstanz, Widgets usw.) verweisen nicht direkt auf diese Module, sodass das Löschen keine Asset-Referenzfehler verursacht. Die Konfigurationsoberfläche blendet automatisch jeden Anbieter aus, dessen Ordner fehlt.
Diese Modularität gilt nur für LLM- und TTS-Anbieter. Spracherkennung (Runtime Speech Recognizer) und Lippensynchronisation (Runtime MetaHuman Lip Sync) sind Teil des Basis-Demoprojekts und immer erforderlich.
Beim ersten Start fragt Unreal möglicherweise, ob fehlende optionale Plugins deaktiviert werden sollen – klicken Sie auf Ja. Stellen Sie sicher, dass Sie auch den entsprechenden Ordner Content/Modules/ gelöscht haben (siehe oben).
Demo-Projekt-Layout
Die unten gezeigte Benutzeroberfläche ist vollständig mit UMG (Unreal Motion Graphics) erstellt und dient ausschließlich dazu, die Pipeline zu demonstrieren – Spracherkennung → LLM → TTS → Lippen-Synchronisation. Sie können sie nach Belieben umgestalten oder ersetzen, um sie an das visuelle Design, das Steuerungsschema oder die Plattform Ihres Projekts (VR/AR, Mobilgeräte, Konsole, Kiosk usw.) anzupassen. Falls bestimmte Widgets in Ihrem Anwendungsfall nicht benötigt werden, können Sie sie auch einfach ausblenden (z. B. ihre Sichtbarkeit auf Eingeklappt oder Versteckt setzen).

| Area | Was gibt es? |
|---|---|
| Zentrieren | Der MetaHuman-Charakter. |
| Linke Seite | Vier Konfigurationsschaltflächen (Spracherkennung, KI-Chatbot, Text-zu-Sprache, Animationen), die unten im Detail beschrieben werden. |
| Mitte unten | Ein Aufnahme starten-Button. Klicken Sie darauf, um ein Sprachgespräch zu beginnen: Ihr Mikrofon wird erfasst, transkribiert, an das LLM gesendet, die Antwort wird per TTS synthetisiert und mit Lippen-Synchronisation abgespielt – völlig freihändig. |
| Rechte Mitte | Ein Widget für den Gesprächsverlauf, das den vollständigen Austausch zwischen Ihnen und der KI anzeigt (sowohl Benutzer- als auch Assistentennachrichten). Es enthält außerdem ein Texteingabefeld, mit dem Sie Nachrichten direkt eingeben können, ohne Spracherkennung zu verwenden – nützlich zum Testen, für Barrierefreiheit oder wenn kein Mikrofon verfügbar ist. |
Sie können beide Eingabemodi in derselben Sitzung frei kombinieren – einige Nachrichten sprechen, andere tippen.
Konfigurationsschaltflächen
Die vier Konfigurationsschaltflächen auf der linken Seite öffnen dedizierte Bedienfelder für jeden Teil der Pipeline:
1. Spracherkennung konfigurieren
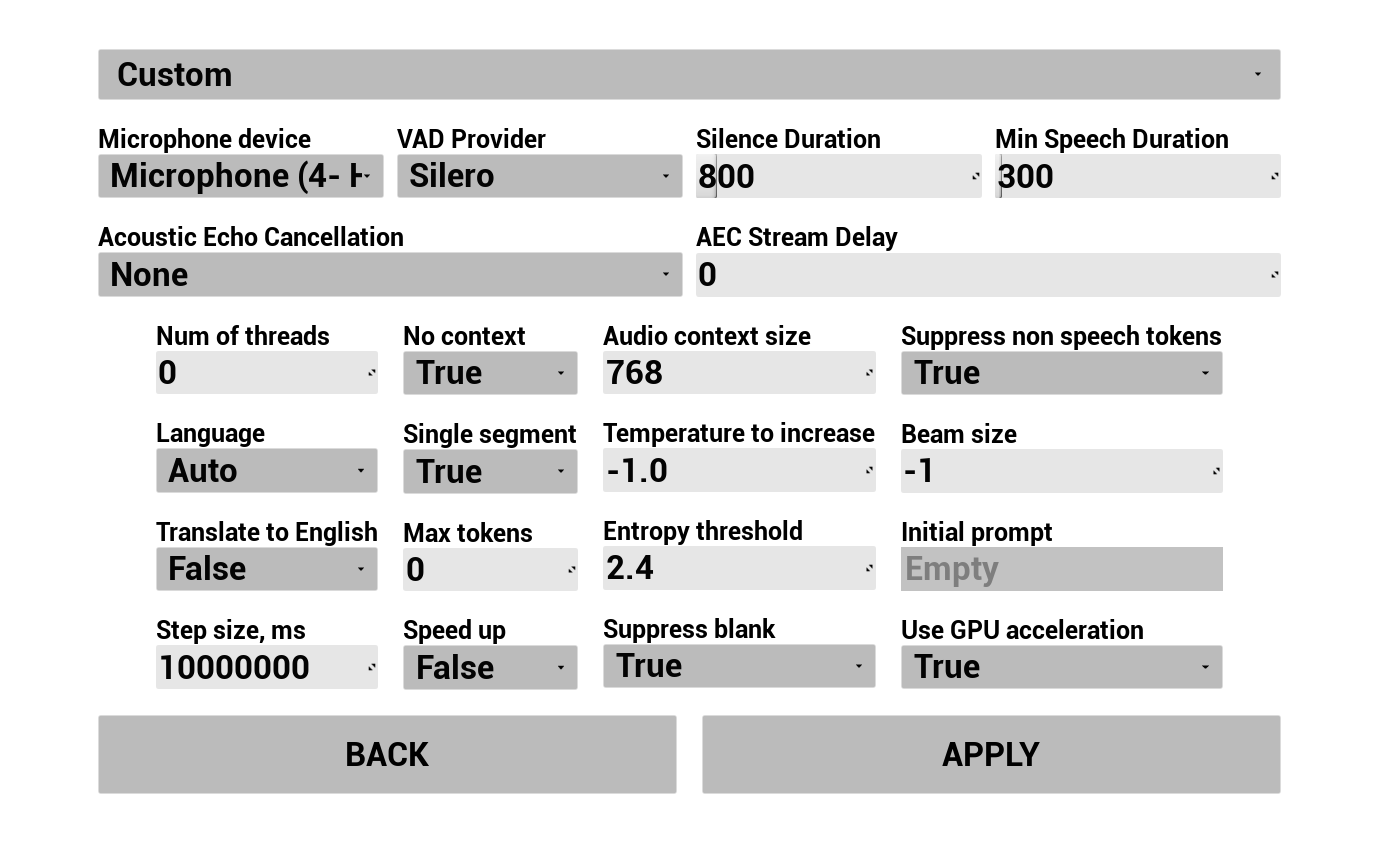
Konfigurieren Sie, wie die Stimme des Benutzers erfasst und transkribiert wird:
- Sprache auswählen
- Parameter der Spracherkennung anpassen (Whisper-Modell-Einstellungen)
- AEC (akustische Echounterdrückung) konfigurieren
- VAD (Sprachaktivitätserkennung) konfigurieren
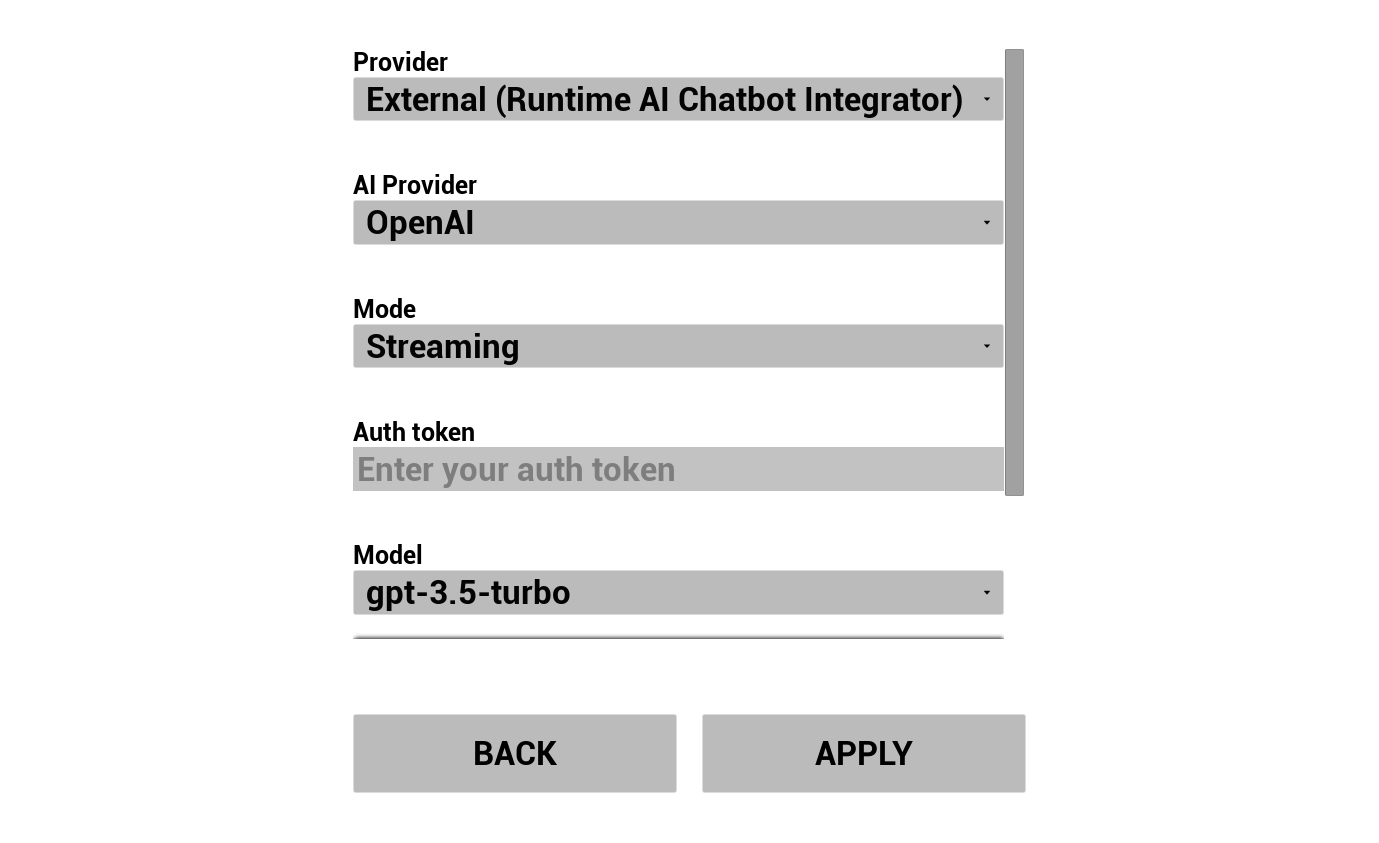
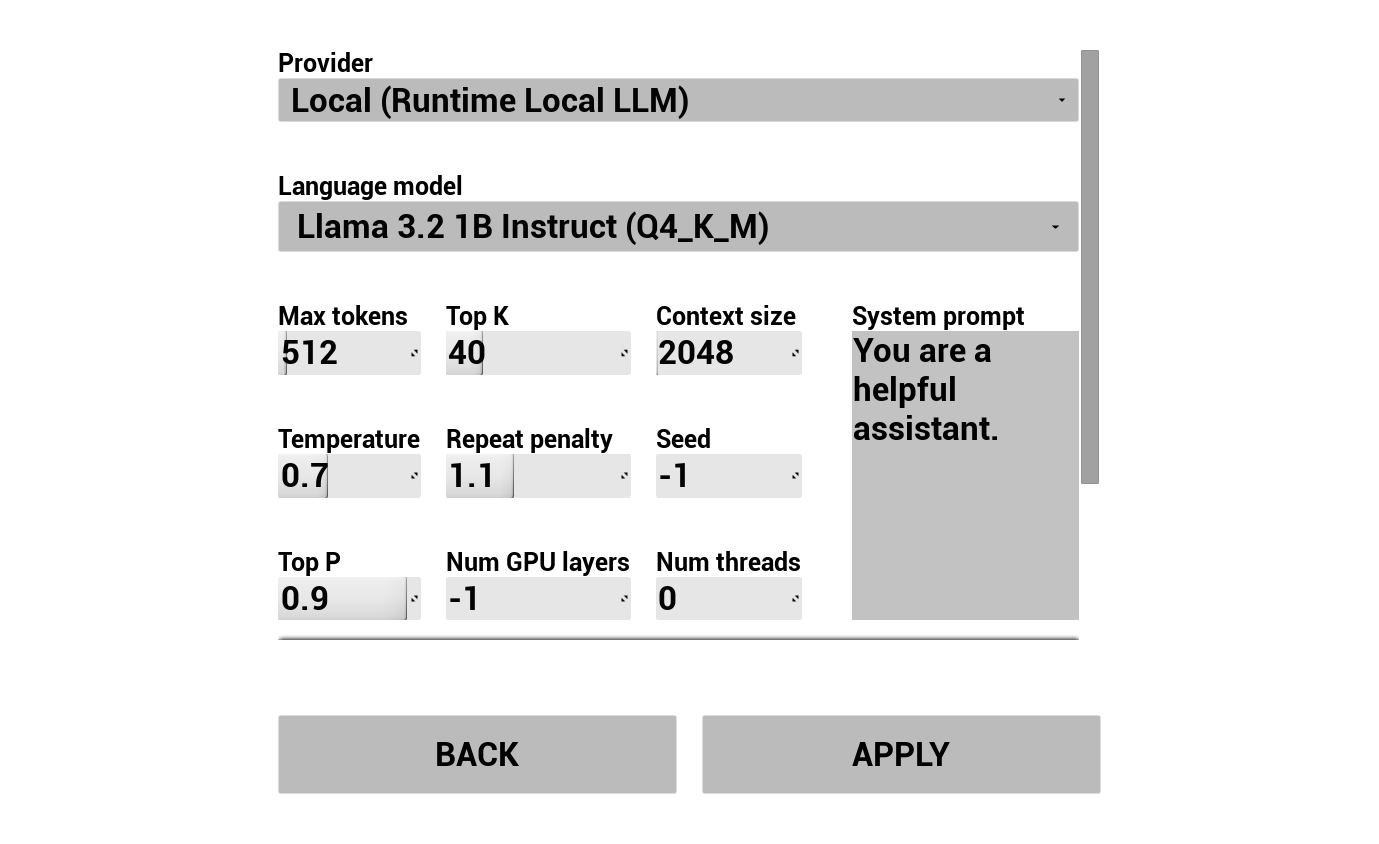
2. KI-Chatbot konfigurieren
Wählen Sie Ihren LLM-Anbieter aus und konfigurieren Sie ihn:
- Wählen Sie Anbieter (Runtime AI Chatbot Integrator oder Runtime Local LLM)
- Für externe Anbieter: Authentifizierungstoken, Modellname usw.
- Für lokales LLM: Wählen Sie ein GGUF-Modell aus, legen Sie die Kontextgröße und andere Inferenzparameter fest. Sie können auch Ihr eigenes GGUF-Modell zur Laufzeit herunterladen – direkt aus der Demo (z. B. per URL) – und sofort verwenden, ohne das Projekt neu erstellen zu müssen.
Das Provider-Kombinationsfeld zeigt nur Anbieter an, deren Plugin-Modulordner in Content/Modules/ vorhanden ist.
3. Text-to-Speech konfigurieren
Wählen Sie Ihren TTS-Anbieter aus und konfigurieren Sie Stimmen/Modelle:
- Wählen Sie Anbieter (Runtime AI Chatbot Integrator für OpenAI/ElevenLabs oder Runtime Text To Speech für lokales Piper/Kokoro)
- Wählen Sie Stimme/Modell
- Passen Sie anbieterspezifische Parameter an

4. Animationen konfigurieren
Steuere die visuelle Darstellung deines KI-Avatars:
- Wählen Sie zwischen 3 vorab heruntergeladenen MetaHuman-Charakteren (Aera, Ada, Orlando)
- Wählen Sie das Lip-Sync-Modell (Standard oder Realistisch)
- Wählen Sie den Lip-Sync-Modelltyp – Hochoptimiert, Semi-optimiert oder Original (siehe Modelltyp)
- Passen Sie die Verarbeitungs-Chunk-Größe an – steuert, wie oft die Lip-Sync-Inferenz ausgeführt wird (siehe Verarbeitungs-Chunk-Größe)
- Wählen Sie eine Idle-Animation aus, die auf dem MetaHuman während des Gesprächs abgespielt wird

Vorkonfiguration der Demo im Editor
Wenn Sie mit der Quellversion arbeiten, können Sie Standardwerte direkt im Editor vorausfüllen, sodass Werte nicht bei jedem Durchlauf erneut eingegeben werden müssen:
| What | Wo |
|---|---|
| Allgemeine Einstellungen (Lippensynchronisationsmodell, Leerlaufanimation, Charakterklasse, Spracherkennung usw.) | Content/LipSyncSTSGameInstance |
| Externes LLM / Externes TTS – Einstellungen (Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Lokale LLM-Einstellungen (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Lokale TTS-Einstellungen (Runtime Text To Speech) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Plattformübergreifende Hinweise
Alle vom Demo verwendeten Plugins unterstützen Windows, Mac, Linux, iOS, Android sowie Android-basierte Plattformen (einschließlich Meta Quest), daher funktioniert das Demoprojekt auch auf all diesen Systemen. Dies macht es für den Einsatz in einer Vielzahl von Umgebungen geeignet – von Spielen und Desktop-Kiosksystemen über mobile Apps und eigenständige VR-Headsets bis hin zu virtuellen Produktionssetups am Set.
Für schwächere Geräte (Mobilgeräte, eigenständige VR) können Sie Folgendes tun:
- Verwenden Sie das Standard-Lippensynchronisationsmodell anstelle von Realistisch – siehe den Modellvergleich
- Wechseln Sie zum hochoptimierten Modelltyp
- Erhöhen Sie die Verarbeitungs-Chunk-Größe, um die CPU-Last zu reduzieren
- Wählen Sie kleinere LLM-/TTS-Modelle
Siehe Plattformspezifische Konfiguration für zusätzliche Einrichtungsschritte unter Android, iOS, Mac und Linux.
Unterstützung für Pixel Streaming
Bereitstellen der Demo auf Pixel Streaming (zum Erweitern klicken)
Das KI-Konversations-Demoprojekt funktioniert auch in einer Pixel Streaming-Umgebung, sodass Sie den MetaHuman-Avatar an einen entfernten Client (z. B. einen Webbrowser) streamen können, während das Mikrofon-Audio des Benutzers clientseitig erfasst wird. Es ist nur eine einzige Änderung am Demo erforderlich.
1. Installieren Sie die Pixel-Streaming-Erweiterung für den Runtime Audio Importer
Das Runtime Audio Importer Plugin bietet ein kostenloses Erweiterungs-Plugin, das die Aufnahme von Audio von einem Pixel Streaming-Client ermöglicht. Abhängig davon, welche Version der Pixel Streaming-Infrastruktur Sie verwenden, installieren Sie eine der folgenden Optionen:
- Pixel Streaming-Erweiterung (für das ursprüngliche Pixel Streaming-Plugin), oder
- Pixel Streaming 2-Erweiterung (für das neuere Pixel Streaming 2-Plugin)
Download-Links und Installationsschritte sind hier verfügbar: Pixel Streaming Audio Capture - Erweiterungs-Plugin-Installation.
2. Tauschen Sie den erfassbaren Schallwellen-Knoten in LipSyncSTSGameInstance aus.
Nachdem das Erweiterungs-Plugin installiert ist:
- Navigieren Sie im Content Browser zu
/All/Gameund öffnen Sie das AssetLipSyncSTSGameInstance. - Wechseln Sie zum Event Graph.
- Suchen Sie Event Init und folgen Sie dem Ausführungsfluss, bis Sie das Knotenpaar finden:
Create Capturable Sound Wave→Set Capturable Sound Wave. - Ersetzen Sie den Aufruf von
Create Capturable Sound Waveentweder durchCreate Pixel Streaming Capturable Sound WaveoderCreate Pixel Streaming 2 Capturable Sound Wave, je nachdem, welche Version der Pixel-Streaming-Infrastruktur Sie anvisieren. - Verbinden Sie dessen Ausgabe mit demselben
Set Capturable Sound Wave-Knoten.
Danach ist das Projekt bereit, auf Pixel Streaming bereitgestellt zu werden – Spracherkennung, LLM, TTS und Lippen-Synchronisation funktionieren wie zuvor, jedoch mit Audio, das vom entfernten Client anstelle eines lokalen Mikrofons erfasst wird.
Eigenen Charakter einbringen
Das Demoprojekt enthält drei Beispiel-MetaHuman-Charaktere (Aera, Ada, Orlando), aber Sie können Ihren eigenen MetaHuman importieren und im Demo verwenden.
📺 Video-Tutorial: Hinzufügen eines benutzerdefinierten MetaHuman-Charakters zum Demoprojekt
Das Runtime MetaHuman Lip Sync Plugin selbst unterstützt viele andere Charaktersysteme über MetaHumans hinaus (ARKit-basierte Charaktere, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe usw. – siehe die Anleitung zur Einrichtung benutzerdefinierter Charaktere). Egal, ob Sie einen Spiel-NPC, einen virtuellen Präsentator, einen Kiosk-Assistenten oder einen digitalen Menschen für die virtuelle Produktion erstellen, das Plugin passt sich Ihrer Charakter-Pipeline an.
Ein einfacheres Demoprojekt, das sich ausschließlich auf die Lippensynchronisation selbst konzentriert, ohne den vollständigen KI-Konversationsworkflow. Geeignet, wenn Sie die Lippensynchronisation einfach mit verschiedenen Audioquellen in Aktion sehen möchten.
Empfohlenes Video
Downloads
Was ist enthalten
Diese Demo zeigt die grundlegenden Lippen-Synchronisations-Workflows:
- Mikrofoneingabe – Lippen-Synchronisation in Echtzeit aus Live-Audio
- Audiodatei-Wiedergabe – Lippen-Synchronisation aus importierten Audiodateien
- Text-zu-Sprache – Lippen-Synchronisation gesteuert durch synthetisierte Sprache
Erforderliche & optionale Plugins
| Plugin | Zweck | Erforderlich? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Lippensynchronisations-Animation | ✅ Erforderlich |
| Runtime Audio Importer | Audio-Import und -Aufnahme | ✅ Erforderlich |
| Runtime Text To Speech | Lokales TTS für die TTS-Demoszene | 🔶 Optional |
| Runtime AI Chatbot Integrator | Externe TTS-Anbieter (OpenAI, ElevenLabs) | 🔶 Optional |
Hinweise zum Standard-Lippensynchronisationsmodell
Wenn Sie vorhaben, das Standardmodell (anstelle des realistischen) in einem der Demoprojekte zu verwenden, müssen Sie das Standard Lip Sync Extension Plugin installieren. Siehe Standardmodell-Erweiterung für Installationsanweisungen.
Hilfe nötig?
Sollten Sie bei der Einrichtung oder Ausführung der Demoprojekte auf Probleme stoßen, können Sie sich gerne melden:
Für individuelle Entwicklungsanfragen (z. B. Erweiterung der Demo mit eigener Logik, Anpassung an eine bestimmte Plattform oder Zeichen-Pipeline) kontaktieren Sie [email protected].