Plugin-Konfiguration
Modellkonfiguration
Für einen zuverlässigen Betrieb mit den realistischen und stimmungsgesteuerten realistischen Modellen erstellen Sie den Generator vor jeder neuen Audiowiedergabe neu, anstatt ihn über längere Stille hinweg wiederzuverwenden. Siehe Generator-Neuerstellung im Abschnitt zur Fehlerbehebung für Details.
Standardmodell-Konfiguration
Der Knoten Create Runtime Viseme Generator verwendet Standardeinstellungen, die für die meisten Szenarien gut funktionieren. Die Konfiguration erfolgt über die Eigenschaften des Animations-Blueprint-Blending-Knotens.
Informationen zu den Konfigurationsoptionen des Animation Blueprints finden Sie im Abschnitt Lip Sync Konfiguration unten.
Konfiguration des realistischen Modells
Der Knoten Create Realistic MetaHuman Lip Sync Generator akzeptiert einen optionalen Konfigurations-Parameter, mit dem Sie das Verhalten des Generators anpassen können:
Modelltyp
Die Einstellung Modelltyp bestimmt, welche Version des realistischen Modells verwendet werden soll:
| Modelltyp | Leistung | Visuelle Qualität | Rauschunterdrückung | Empfohlene Anwendungsfälle |
|---|---|---|---|---|
| Hochoptimiert (Standard) | Höchste Leistung, geringste CPU-Auslastung | Gute Qualität | Kann bei Hintergrundgeräuschen oder Nicht-Sprachgeräuschen auffällige Mundbewegungen zeigen. | Saubere Audio-Umgebungen, leistungskritische Szenarien |
| Semi-optimiert | Gute Leistung, moderate CPU-Auslastung | Hochwertig | Bessere Stabilität bei verrauschtem Audio | Ausgewogene Leistung und Qualität, gemischte Audiobedingungen |
| Original | Geeignet für den Echtzeiteinsatz auf modernen CPUs | Höchste Qualität | Am stabilsten bei Hintergrundgeräuschen und Nicht-Sprachgeräuschen | Hochwertige Produktionen, laute Audio-Umgebungen, wenn maximale Genauigkeit erforderlich ist |
Leistungseinstellungen
Intra Op Threads: Steuert die Anzahl der Threads, die für interne Modellverarbeitungsvorgänge verwendet werden.
- 0 (Standard/Automatisch): Verwendet automatische Erkennung (normalerweise 1/4 der verfügbaren CPU-Kerne, maximal 4)
- 1-16: Manuelle Angabe der Thread-Anzahl. Höhere Werte können die Leistung auf Mehrkernsystemen verbessern, beanspruchen jedoch mehr CPU.
Inter Op Threads: Steuert die Anzahl der Threads, die für die parallele Ausführung verschiedener Modelloperationen verwendet werden.
- 0 (Standard/Automatisch): Verwendet automatische Erkennung (normalerweise 1/8 der verfügbaren CPU-Kerne, maximal 2)
- 1-8: Manuelle Angabe der Thread-Anzahl. Für Echtzeitverarbeitung wird sie normalerweise niedrig gehalten.
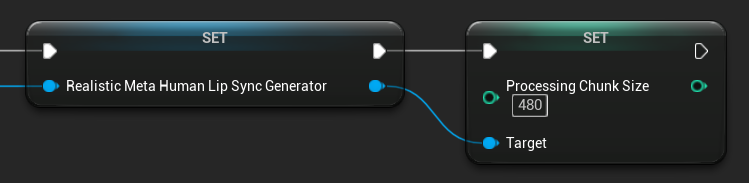
Verarbeitungs-Chunk-Größe
Die Verarbeitungs-Chunk-Größe bestimmt, wie viele Samples in jedem Inferenzschritt verarbeitet werden. Der Standardwert beträgt 160 Samples (10 ms Audio bei 16 kHz):
- Kleinere Werte sorgen für häufigere Aktualisierungen, erhöhen jedoch die CPU-Auslastung
- Größere Werte verringern die CPU-Last, können aber die Reaktionsfähigkeit der Lippenbewegungssynchronisation beeinträchtigen
- Es wird empfohlen, Vielfache von 160 zu verwenden, um eine optimale Ausrichtung zu erzielen
Konfiguration des stimmungsfähigen Modells
Der Knoten Create Realistic MetaHuman Lip Sync With Mood Generator bietet über das grundlegende realistische Modell hinaus zusätzliche Konfigurationsoptionen:
Grundlegende Konfiguration
Lookahead Ms: Lookahead-Zeit in Millisekunden für eine verbesserte Lippensynchronisationsgenauigkeit.
- Standard: 80 ms
- Bereich: 20 ms bis 200 ms (muss durch 20 teilbar sein)
- Höhere Werte bieten eine bessere Synchronisation, erhöhen jedoch die Latenz.
Ausgabetyp: Steuert, welche Gesichtssteuerungen generiert werden.
- Gesamtes Gesicht: Alle 81 Gesichtssteuerungen (Augenbrauen, Augen, Nase, Mund, Kiefer, Zunge)
- Nur Mund: Nur Steuerungen für Mund, Kiefer und Zunge
Leistungseinstellungen: Verwendet dieselben Intra-OP-Threads- und Inter-OP-Threads-Einstellungen wie das reguläre realistische Modell.
Stimmungseinstellungen
Verfügbare Stimmungen:
- Neutral, Happy, Sad, Disgust, Anger, Surprise, Fear
- Selbstbewusst, Aufgeregt, Gelangweilt, Verspielt, Verwirrt
Stimmungsintensität: Steuert, wie stark die Stimmung die Animation beeinflusst (0,0 bis 1,0)
Laufzeit-Stimmungskontrolle
Sie können die Stimmungseinstellungen während der Laufzeit mit den folgenden Funktionen anpassen:
- Stimmung festlegen: Ändert den aktuellen Stimmungstyp
- Stimmungsintensität festlegen: Passt an, wie stark die Stimmung die Animation beeinflusst (0,0 bis 1,0)
- Lookahead in ms festlegen: Ändert den Vorausschau-Zeitpunkt für die Synchronisation
- Ausgabetyp festlegen: Wechselt zwischen den Steuerungen „Gesamtes Gesicht“ und „Nur Mund“

Stimmungsauswahl-Leitfaden
Wählen Sie passende Stimmungen basierend auf Ihrem Inhalt aus:
| Mood | Am besten geeignet für | Typischer Intensitätsbereich |
|---|---|---|
| Neutral | Allgemeine Konversation, Erzählung, Standardzustand | 0,5 - 1,0 |
| Glücklich | Positive Inhalte, fröhliche Dialoge, Feierlichkeiten | 0.6 - 1.0 |
| Traurig | Melancholischer Inhalt, emotionale Szenen, düstere Momente | 0,5 - 0,9 |
| Ekel | Negative Reaktionen, anstößige Inhalte, Ablehnung | 0.4 - 0.8 |
| Wut | Aggressiver Dialog, konfrontative Szenen, Frustration | 0.6 - 1.0 |
| Überraschung | Unerwartete Ereignisse, Enthüllungen, Schockreaktionen | 0.7 - 1.0 |
| Angst | Bedrohliche Situationen, Angst, nervöser Dialog | 0,5 - 0,9 |
| Selbstbewusst | Professionelle Präsentationen, Führungsdialog, durchsetzungsfähige Rede | 0.7 - 1.0 |
| Aufgeregt | Energetischer Inhalt, Ankündigungen, enthusiastischer Dialog | 0,8 - 1,0 |
| Gelangweilt | Monotoner Inhalt, desinteressierter Dialog, müde Sprache | 0.3 - 0.7 |
| Verspielt | Locker Smalltalk, Humor, unbeschwerte Interaktionen | 0.6 - 0.9 |
| Verwirrt | Frage-lastiger Dialog, Unsicherheit, Verwirrung | 0.4 - 0.8 |
Animation Blueprint-Konfiguration
Lippensynchronisations-Konfiguration
- Standardmodell
- Realistische Modelle
Der Knoten Blend Runtime MetaHuman Lip Sync verfügt über Konfigurationsoptionen in seinem Eigenschaftenfenster:
| Eigenschaft | Standard | Beschreibung |
|---|---|---|
| Interpolationsgeschwindigkeit | 25 | Steuert, wie schnell die Lippenbewegungen zwischen Visemen übergehen. Höhere Werte führen zu schnelleren, abrupteren Übergängen. |
| Zeit zurücksetzen | 0.2 | Die Dauer in Sekunden, nach der die Lippensynchronisation zurückgesetzt wird. Dies ist nützlich, um zu verhindern, dass die Lippensynchronisation fortgesetzt wird, nachdem das Audio gestoppt wurde. |
Lach-Animation
Sie können auch Lachanimationen hinzufügen, die dynamisch auf im Audio erkanntes Lachen reagieren.
- Fügen Sie den Knoten
Blend Runtime MetaHuman Laughterhinzu - Verbinden Sie Ihre
RuntimeVisemeGenerator-Variable mit dem PinViseme Generator - Wenn Sie bereits Lippen-Synchronisation verwenden:
- Verbinden Sie die Ausgabe des Knotens
Blend Runtime MetaHuman Lip Syncmit derSource Posedes KnotensBlend Runtime MetaHuman Laughter. - Verbinden Sie die Ausgabe des Knotens
Blend Runtime MetaHuman Laughtermit demResult-Pin desOutput Pose.
- Verbinden Sie die Ausgabe des Knotens
- Wenn nur Lachen ohne Lippen-Synchronisation verwendet wird:
- Verbinden Sie Ihre Quellpose direkt mit dem
Source Pose-Pin desBlend Runtime MetaHuman Laughter-Knotens - Verbinden Sie die Ausgabe mit dem
Result-Pin
- Verbinden Sie Ihre Quellpose direkt mit dem
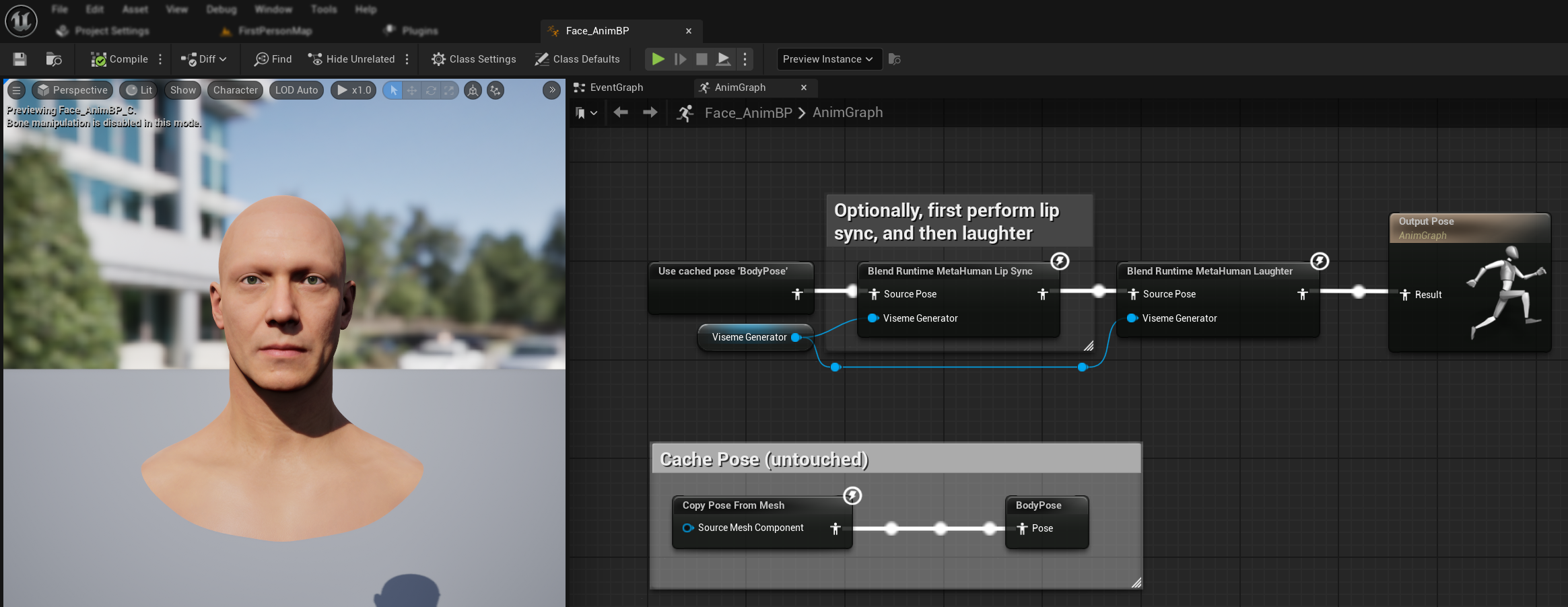
Wenn im Audio Gelächter erkannt wird, animiert sich dein Charakter dynamisch entsprechend:
Lach-Konfiguration
Der Knoten Blend Runtime MetaHuman Laughter verfügt über eigene Konfigurationsoptionen:
| Eigenschaft | Standard | Beschreibung |
|---|---|---|
| Interpolationsgeschwindigkeit | 25 | Steuert, wie schnell die Lippenbewegungen zwischen Lachanimationen übergehen. Höhere Werte führen zu schnelleren, abrupteren Übergängen. |
| Zeit zurücksetzen | 0.2 | Die Dauer in Sekunden, nach der das Lachen zurückgesetzt wird. Dies ist nützlich, um zu verhindern, dass das Lachen fortgesetzt wird, nachdem das Audio gestoppt wurde. |
| Max Laughter Weight | 0.7 | Skaliert die maximale Intensität der Lachanimation (0,0 - 1,0). |
Hinweis: Die Lach-Erkennung ist derzeit nur mit dem Standard-Modell verfügbar.
Der Knoten Blend Realistic MetaHuman Lip Sync verfügt über Konfigurationsoptionen in seinem Eigenschaftenfenster:
| Eigenschaft | Standard | Beschreibung |
|---|---|---|
| Interpolationsgeschwindigkeit | 30 | Steuert, wie schnell Gesichtsausdrücke während aktiver Sprache übergehen. Höhere Werte führen zu schnelleren, abrupteren Übergängen. |
| Leerlauf-Interpolationsgeschwindigkeit | 15 | Steuert, wie schnell Gesichtsausdrücke in den Ruhe-/Neutralzustand zurückkehren. Niedrigere Werte erzeugen sanftere, allmählichere Übergänge zur Ruheposition. |
| Zeit zurücksetzen | 0.2 | Dauer in Sekunden, nach der die Lippensynchronisation in den Ruhezustand zurückgesetzt wird. Nützlich, um zu verhindern, dass Ausdrücke nach dem Stoppen des Audios fortgesetzt werden. |
| Bewahren Sie den Ruhezustand | false | Wenn aktiviert, bleibt der letzte emotionale Zustand während Leerlaufphasen erhalten, anstatt auf neutral zurückgesetzt zu werden. |
| Augenausdrücke beibehalten | true | Steuert, ob augenbezogene Gesichtssteuerungen im Leerlaufzustand beibehalten werden. Nur wirksam, wenn „Leerlaufzustand beibehalten“ aktiviert ist. |
| Brow-Ausdrücke beibehalten | true | Steuert, ob augenbrauenbezogene Gesichtssteuerungen während des Ruhezustands beibehalten werden. Nur wirksam, wenn „Ruhezustand beibehalten“ aktiviert ist. |
| Mundform beibehalten | false | Steuert, ob Mundformsteuerungen (mit Ausnahme von sprachspezifischen Bewegungen wie Zunge und Kiefer) während des Ruhezustands beibehalten werden. Nur wirksam, wenn „Ruhezustand beibehalten“ aktiviert ist. |
Leerlaufzustandserhaltung
Die Funktion Ruhezustand beibehalten befasst sich damit, wie das Realistische Modell mit Stilleperioden umgeht. Im Gegensatz zum Standardmodell, das diskrete Viseme verwendet und während der Stille konsequent auf Nullwerte zurückfällt, kann das neuronale Netzwerk des Realistischen Modells subtile Gesichtspositionierungen beibehalten, die von der Standard-Ruhepose des MetaHuman abweichen.
Wann aktivieren:
- Aufrechterhaltung emotionaler Ausdrücke zwischen Sprachsegmenten
- Bewahrung von Charakterpersönlichkeitsmerkmalen
- Sicherstellung visueller Kontinuität in filmischen Sequenzen
Optionen für regionale Steuerung:
- Augenausdrücke: Behält das Zusammenkneifen, Weiten und die Positionierung der Augenlider bei
- Brauenausdrücke: Behält die Positionierung der Augenbrauen und der Stirn bei
- Mundform: Behält die allgemeine Mundkrümmung bei, während Sprachbewegungen (Zunge, Kiefer) zurückgesetzt werden können
Kombinieren mit vorhandenen Animationen
Um Lippen-Synchronisation und Lachen zusammen mit vorhandenen Körperanimationen und benutzerdefinierten Gesichtsanimationen anzuwenden, ohne diese zu überschreiben:
Diese Einrichtung gilt für das Gesichts-Animation-Blueprint, da die Lippenanimation nicht Teil des Körper-Animation-Blueprints ist. Für benutzerdefinierte Körperanimationen (z. B. Rumpf, Arme und andere Körperbewegungen) verbinden Sie einfach Ihre Animationssequenz (über einen Sequence Player) direkt mit der Ausgabepose im Körper-Animation-Blueprint. Dort ist keine zusätzliche Einrichtung erforderlich.
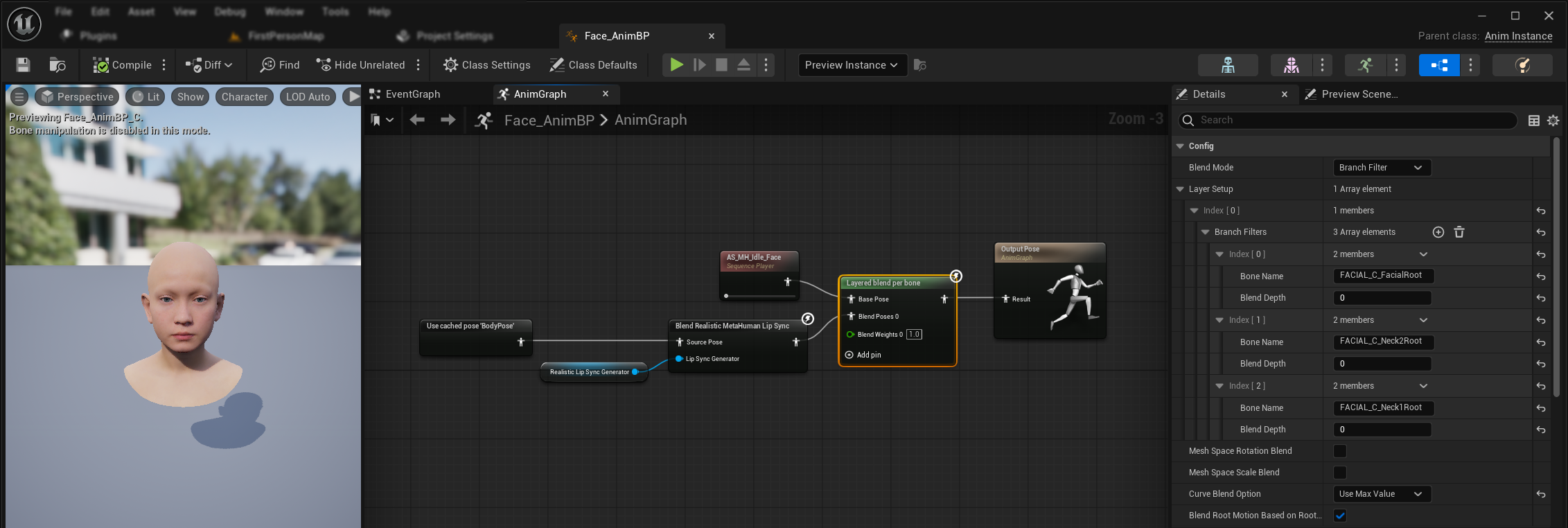
- Fügen Sie einen
Layered blend per bone-Knoten zwischen Ihren Körperanimationen und der endgültigen Ausgabe ein. Stellen Sie sicher, dassUse Attached Parentauf "true" gesetzt ist. - Konfigurieren Sie das Layer-Setup:
- Fügen Sie 1 Element zum
Layer Setup-Array hinzu - Fügen Sie 3 Elemente zu den
Branch Filtersfür die Ebene hinzu, mit den folgendenBone Names:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Fügen Sie 1 Element zum
- Wichtig für benutzerdefinierte Gesichtsanimationen: Wählen Sie in der
Curve Blend Optiondie Option "Maximalwert verwenden". Dadurch können benutzerdefinierte Gesichtsanimationen (Ausdrücke, Emotionen usw.) ordnungsgemäß über die Lippenbewegungssynchronisation geschichtet werden. - Stellen Sie die Verbindungen her:
- Ihre benutzerdefinierte Animation (normalerweise ein
Sequence Playermit dem gewünschten Animationssequenz-Asset) →Base Pose-Eingabe - Gesichtsanimationsausgabe (von Lippen-Synchronisations- und/oder Lachknoten) →
Blend Poses 0-Eingabe - Überlagerter Mischknoten → Endgültige
Result-Pose
- Ihre benutzerdefinierte Animation (normalerweise ein
Morph-Zielset-Auswahl
- Standardmodell
- Realistische Modelle
Das Standardmodell verwendet Pose-Assets, die durch die Einrichtung benutzerdefinierter Pose-Assets grundsätzlich jede Morph-Target-Benennungskonvention unterstützen. Es ist keine zusätzliche Konfiguration erforderlich.
Der Knoten Blend Realistic MetaHuman Lip Sync enthält eine Eigenschaft Morph Target Set, die festlegt, welche Benennungskonvention für Morph-Targets bei der Gesichtsanimation verwendet werden soll:
| Morph-Ziel-Set | Beschreibung | Anwendungsfälle |
|---|---|---|
| MetaHuman (Standard) | Standard-MetaHuman-Morph-Target-Namen (z. B. CTRL_expressions_jawOpen) | MetaHuman-Charaktere |
| ARKit | Apple ARKit-kompatible Namen (z. B. JawOpen, MouthSmileLeft) | ARKit-basierte Charaktere |
Feinabstimmung des Lippen-Synchronisationsverhaltens
Skalierung spezifischer Lippen-Synchronisationskurven
Sie können einzelne Gesichtsbewegungen, die durch Lippen-Synchronisation erzeugt werden, mit einem Modify Curve-Knoten abschwächen (oder verstärken). Dies ist nützlich, wenn eine bestimmte Kurve für Ihren Audioinhalt oder Charakter zu ausgeprägt wirkt.
Einrichtung:
- Fügen Sie nach Ihrem Lippen-Synchronisations-Blend-Knoten einen
Modify Curve-Knoten hinzu - Klicken Sie mit der rechten Maustaste auf den Knoten und wählen Sie Add Curve Pin aus, geben Sie dann den Kurvennamen ein, den Sie skalieren möchten
- Setzen Sie die Eigenschaft Apply Mode des Knotens auf Scale
- Legen Sie den Parameter Value fest: Werte unter 1,0 dämpfen die Bewegung, Werte über 1,0 verstärken sie (z. B. 0,8 = 20 % Reduzierung)
Häufig skalierte Kurven:
| Kurvenname | Zweck | Gilt für | Typische Anpassung |
|---|---|---|---|
CTRL_expressions_tongueOut | Vorwärtsgerichtetes Herausstrecken der Zunge bei bestimmten Phonemen | Standardmodell | 0,8, um das Hervortreten zu reduzieren |
CTRL_expressions_jawOpen | Kieferöffnungsbereich | Realistische Modelle | 0,9 zur Reduzierung der Kieferbewegung |
Sie können mehrere Kurven-Pins zum selben Modify Curve-Knoten hinzufügen, um mehrere Kurven gleichzeitig zu skalieren.
Stimmungsspezifisches Feintuning
Für stimmungsfähige Modelle können Sie bestimmte emotionale Ausdrücke verfeinern:
Augenbrauensteuerung:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- Inneres AugenbrauenhebenCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- Äußeres AugenbrauenhebenCTRL_expressions_browDownL/CTRL_expressions_browDownR- Augenbrauensenken
Augenausdruckssteuerung:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Augen zusammenkneifenCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Wangen heben
Modellvergleich und -auswahl
Auswahl zwischen Modellen
Berücksichtigen Sie bei der Entscheidung, welches Lippen-Synchronisationsmodell Sie für Ihr Projekt verwenden möchten, die folgenden Faktoren:
| Berücksichtigung | Standardmodell | Realistisches Modell | Stimmungsgesteuertes realistisches Modell |
|---|---|---|---|
| Charakter-Kompatibilität | MetaHumans und alle benutzerdefinierten Charaktertypen | MetaHumans (und ARKit)-Charaktere | MetaHumans (und ARKit)-Charaktere |
| Visuelle Qualität | Gute Lippensynchronisation mit effizienter Leistung | Verbesserte Realistik durch natürlichere Mundbewegungen | Verbesserte Realität durch emotionale Ausdrücke |
| Leistung | Optimiert für alle Plattformen, einschließlich Mobilgeräte/VR. | Höhere Ressourcenanforderungen | Höhere Ressourcenanforderungen |
| Funktionen | 14 Viseme, Lachdetektion | 81 Gesichtssteuerungen, 3 Optimierungsstufen | 81 Gesichtssteuerungen, 12 Stimmungen, konfigurierbare Ausgabe |
| Plattformunterstützung | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Anwendungsfälle | Allgemeine Anwendungen, Spiele, VR/AR, Mobilgeräte | Filmische Erlebnisse, Nahaufnahme-Interaktionen | Emotionales Storytelling, erweiterte Charakterinteraktion |
Engine-Version-Kompatibilität
Wenn Sie Unreal Engine 5.2 verwenden, funktionieren die realistischen Modelle aufgrund eines Fehlers in der Resampling-Bibliothek von UE möglicherweise nicht korrekt. Für UE 5.2-Benutzer, die eine zuverlässige Lippen-Synchronisation benötigen, verwenden Sie bitte stattdessen das Standardmodell.
Dieses Problem tritt spezifisch in UE 5.2 auf und betrifft keine anderen Engine-Versionen.
Leistungsempfehlungen
- Für die meisten Projekte bietet das Standardmodell eine hervorragende Balance zwischen Qualität und Leistung
- Verwenden Sie das realistische Modell, wenn Sie die höchste visuelle Wiedergabetreue für MetaHuman-Charaktere benötigen
- Verwenden Sie das stimmungsgesteuerte realistische Modell, wenn die Kontrolle des emotionalen Ausdrucks für Ihre Anwendung wichtig ist
- Berücksichtigen Sie die Leistungsfähigkeit Ihrer Zielplattform bei der Wahl zwischen den Modellen
- Testen Sie verschiedene Optimierungsstufen, um die beste Balance für Ihren spezifischen Anwendungsfall zu finden
Fehlerbehebung
Häufige Probleme
Neuerstellung des Generators für realistische Modelle: Für einen zuverlässigen und konsistenten Betrieb mit den realistischen Modellen wird empfohlen, den Generator jedes Mal neu zu erstellen, wenn Sie nach einer Phase der Inaktivität neue Audiodaten einspeisen möchten. Dies liegt am Verhalten der ONNX-Laufzeitumgebung, das dazu führen kann, dass die Lippensynchronisation nicht mehr funktioniert, wenn Generatoren nach Phasen der Stille wiederverwendet werden.
Zum Beispiel könnten Sie den Lippensynchronisationsgenerator bei jedem Start der Wiedergabe neu erstellen, etwa wenn Sie Play Sound 2D aufrufen oder eine andere Methode verwenden, um die Wiedergabe von Schallwellen und die Lippensynchronisation zu starten:
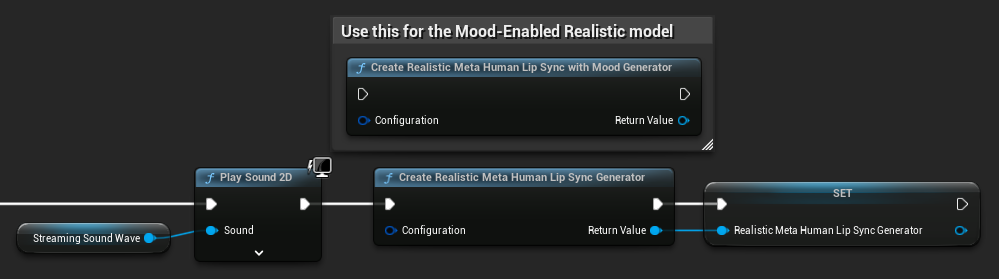
Plugin-Speicherort für die Integration von Runtime Text To Speech: Wenn Sie Runtime MetaHuman Lip Sync zusammen mit Runtime Text To Speech verwenden (beide Plugins nutzen ONNX Runtime), können in paketierten Builds Probleme auftreten, falls die Plugins im Marketplace-Ordner der Engine installiert sind. So beheben Sie dies:
- Finden Sie beide Plugins in Ihrem UE-Installationsordner unter
\Engine\Plugins\Marketplace(z. B.C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Verschieben Sie sowohl den Ordner
RuntimeMetaHumanLipSyncals auchRuntimeTextToSpeechin denPlugins-Ordner Ihres Projekts - Falls Ihr Projekt keinen
Plugins-Ordner hat, erstellen Sie einen im selben Verzeichnis wie Ihre.uproject-Datei - Starten Sie den Unreal Editor neu
Dies behebt Kompatibilitätsprobleme, die auftreten können, wenn mehrere ONNX Runtime-basierte Plugins aus dem Marketplace-Verzeichnis der Engine geladen werden.
Paketierungskonfiguration (Windows): Wenn die Lippensynchronisation in Ihrem paketierten Projekt unter Windows nicht korrekt funktioniert, stellen Sie sicher, dass Sie die Shipping-Build-Konfiguration anstelle von Development verwenden. Die Development-Konfiguration kann in paketierten Builds Probleme mit der ONNX-Laufzeit der realistischen Modelle verursachen.
Um dies zu beheben:
- Gehen Sie in Ihren Projekteinstellungen → Verpackung und setzen Sie die Build-Konfiguration auf Shipping
- Verpacken Sie Ihr Projekt neu
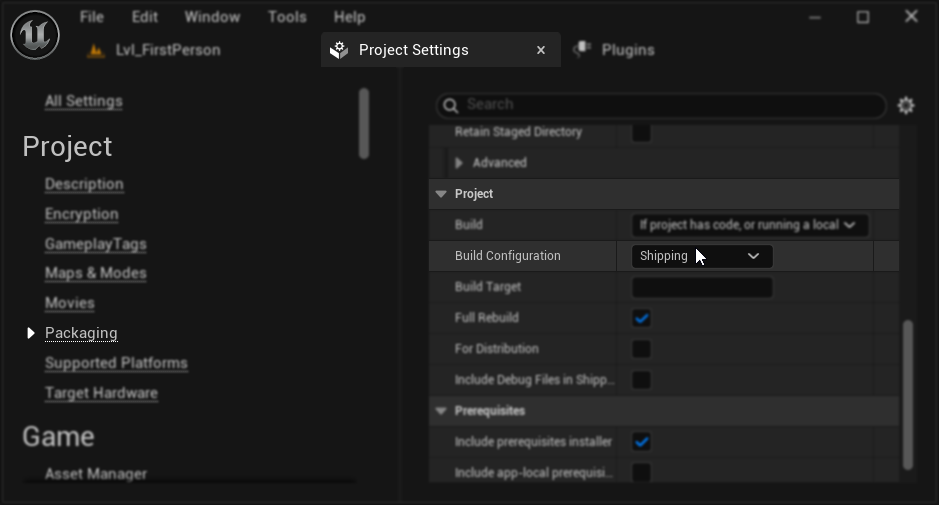
In manchen Blueprint-only-Projekten erstellt Unreal Engine möglicherweise trotzdem in der Development-Konfiguration, selbst wenn Shipping ausgewählt ist. Falls dies passiert, konvertieren Sie Ihr Projekt in ein C++-Projekt, indem Sie mindestens eine C++-Klasse hinzufügen (diese kann leer sein). Gehen Sie dazu im UE-Editor-Menü zu Tools → Neue C++-Klasse und erstellen Sie eine leere Klasse. Dadurch wird das Projekt gezwungen, korrekt in der Shipping-Konfiguration zu erstellen. Ihr Projekt kann funktional weiterhin ein reines Blueprint-Projekt bleiben; die C++-Klasse wird nur für die korrekte Build-Konfiguration benötigt.
Verminderte Lippensynchronisations-Reaktionsfähigkeit: Wenn Sie feststellen, dass die Lippensynchronisation im Laufe der Zeit bei Verwendung von Streaming Sound Wave oder Capturable Sound Wave weniger reaktionsschnell wird, kann dies durch Speicheransammlungen verursacht werden. Standardmäßig wird der Speicher jedes Mal neu zugewiesen, wenn neue Audiodaten angehängt werden. Um dieses Problem zu vermeiden, rufen Sie die Funktion ReleaseMemory regelmäßig auf, um angesammelten Speicher freizugeben, z. B. alle 30 Sekunden.
Leistungsoptimierung:
- Passen Sie die Verarbeitungs-Chunk-Größe für realistische Modelle basierend auf Ihren Leistungsanforderungen an
- Verwenden Sie geeignete Thread-Anzahlen für Ihre Zielhardware
- Erwägen Sie die Verwendung des Ausgabetyps „Nur Mund“ für stimmungsfähige Modelle, wenn keine vollständige Gesichtsanimation erforderlich ist