Liste der Erkennungsparameter
Diese Parameter können nur gesetzt werden, während der Erkennungsprozess nicht läuft.
Dies ist keine vollständige Liste aller in Whisper verfügbaren Parameter. Nur die wichtigsten werden hier verfügbar gemacht. Bei Bedarf wird diese Liste aktualisiert.
Set Recognition Parameters
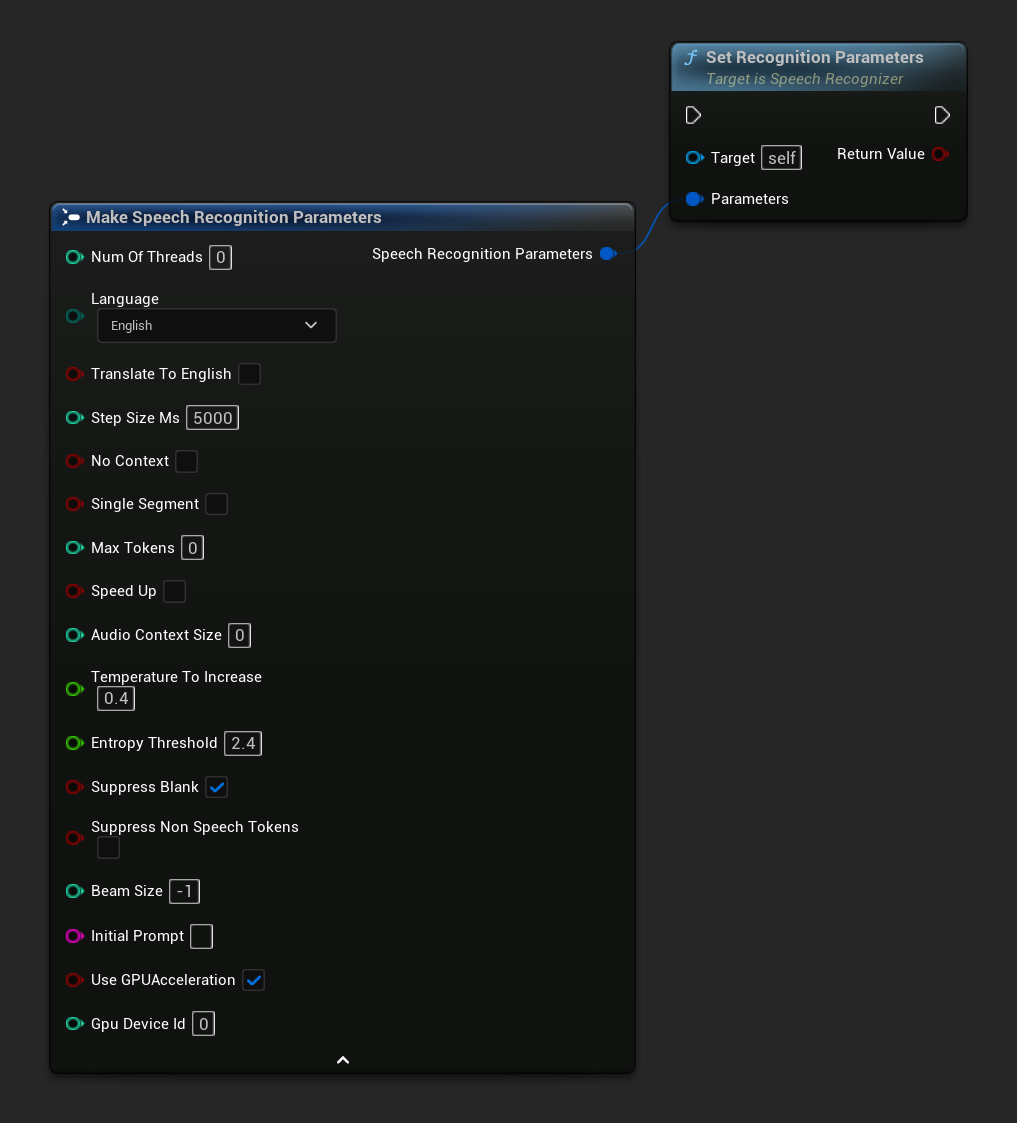
Legt die Parameter für die Spracherkennung fest. Wenn Sie nur bestimmte Parameter ändern möchten, sollten Sie die einzelnen Setter-Funktionen in Betracht ziehen.
Set Streaming Defaults
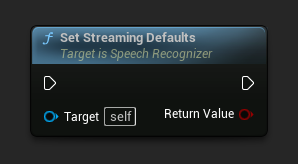
Legt die Standardparameter fest, die für die Streaming-Spracherkennung geeignet sind.
Diese Funktion überschreibt alle zuvor angewendeten Parameter. Stellen Sie sicher, dass Sie diese Funktion aufrufen, bevor Sie Ihre benutzerdefinierten Parameter setzen, wenn Sie die Streaming-Standards als Basis-Konfiguration verwenden müssen.
Set Non Streaming Defaults
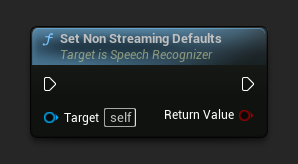
Legt die Standardparameter fest, die für die nicht-streamende Spracherkennung geeignet sind.
Diese Funktion überschreibt alle zuvor angewendeten Parameter. Stellen Sie sicher, dass Sie diese Funktion aufrufen, bevor Sie Ihre benutzerdefinierten Parameter setzen, wenn Sie die Nicht-Streaming-Standards als Basis-Konfiguration verwenden müssen.
Set Num Of Threads
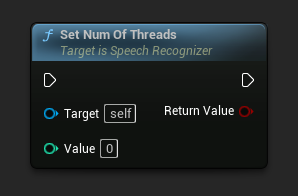
Legt die Anzahl der Threads fest, die für die Spracherkennung verwendet werden sollen. Setzen Sie diesen Wert auf 0, um die Anzahl der Kerne zu verwenden.
Set Language
Legt die Sprache fest, die für die Spracherkennung verwendet werden soll. Muss vom ausgewählten Sprachmodell in den Editor-Einstellungen unterstützt werden.
Das Setzen der Sprache auf Auto verringert die Erkennungsgenauigkeit und Leistung.
Get Detected Language
Ruft die erkannte Sprache aus der letzten Erkennung ab. Gibt die Sprache als Enumerationswert zurück.
Hinweis: Diese Funktion funktioniert nur, nachdem eine Erkennung durchgeführt wurde. Sie gibt Auto zurück, wenn die Spracherkennung fehlgeschlagen ist oder nicht durchgeführt wurde. Dies ist besonders nützlich, wenn die automatische Spracherkennung verwendet wird, um zu identifizieren, welche Sprache tatsächlich erkannt wurde.
Get Language Code
Konvertiert einen Sprach-Enumerationswert in seinen Sprachcode-String (z.B. En -> "en", Fr -> "fr", De -> "de").
Get Language Full Name
Konvertiert einen Sprach-Enumerationswert in seinen vollständigen Sprachnamen (z.B. En -> "English", Fr -> "French", De -> "German").
Set Translate To English
![]()
Legt fest, ob die erkannten Wörter ins Englische übersetzt werden sollen. Wenn true, muss das Sprachmodell mehrsprachig sein.
Set Step Size
Legt die Schrittgröße in Millisekunden fest. Bestimmt, wie oft Audiodaten zur Erkennung gesendet werden. Der Standardwert ist 5000 ms (5 Sekunden).
Set No Context
Legt fest, ob die vorherige Transkription (falls vorhanden) als initiale Eingabeaufforderung für den Decoder verwendet werden soll.
Set Single Segment
Legt fest, ob eine Einzelsegment-Ausgabe erzwungen werden soll (nützlich für Streaming).
Set Max Tokens
Legt die maximale Anzahl von Tokens pro Textsegment fest. Verwenden Sie 0 für kein Limit.
Set Speed Up
Legt fest, ob die Erkennung mit Phase Vocoder um das 2-fache beschleunigt werden soll. Setzen Sie es auf false, um die Qualität der Ausgabe zu verbessern.
Set Audio Context Size
Legt die Größe des Audio-Kontexts fest. Setzen Sie es auf 0, um die Qualität der Ausgabe zu verbessern.
Set Temperature To Increase
Legt die Temperatur fest, die erhöht werden soll, wenn ein Fallback erfolgt, weil das Decodieren eine der untenstehenden Schwellenwerte nicht erfüllt.
Set Entropy Threshold
Legt den Entropie-Schwellenwert fest. Wenn das Kompressionsverhältnis höher als dieser Wert ist, wird die Decodierung als fehlgeschlagen behandelt. Ähnlich wie OpenAIs "compression_ratio_threshold"
Set Suppress Blank
![]()
Legt fest, ob Leerzeichen, die in den Ausgaben auftauchen, unterdrückt werden sollen.
Set Suppress Non Speech Tokens
Legt fest, ob Nicht-Sprach-Tokens, die in den Ausgaben auftauchen, unterdrückt werden sollen.
Set Beam Size
Legt die Anzahl der Strahlen (Beams) bei der Beam-Suche fest. Nur anwendbar, wenn die Temperatur null ist.
Set Initial Prompt
Legt die initiale Eingabeaufforderung für das erste Fenster fest. Dies kann verwendet werden, um der Erkennung Kontext zu geben, damit sie Wörter mit höherer Wahrscheinlichkeit korrekt vorhersagt, z.B. benutzerdefinierte Vokabulare oder Eigennamen.
Weitere Details zu effektiven Prompting-Strategien finden Sie im Whisper Prompting Guide.
Set GPU Acceleration
Legt fest, ob GPU-Beschleunigung für die Spracherkennung verwendet werden soll (derzeit nur unter Windows anwendbar).
Set GPU Device ID
Legt die GPU-Geräte-ID fest, die für die Spracherkennung verwendet werden soll. Der Standardwert ist 0. Dies ist nützlich für Systeme mit mehreren GPUs, um anzugeben, welche GPU für den Erkennungsprozess verwendet werden soll. Wenn die angegebene GPU-Geräte-ID ungültig ist, wird stattdessen der erste verfügbare GPU-Geräteindex verwendet.