Proveedores de Traducción
El AI Localization Automator admite cinco proveedores de IA diferentes, cada uno con fortalezas únicas y opciones de configuración. Elija el proveedor que mejor se adapte a las necesidades, el presupuesto y los requisitos de calidad de su proyecto.
Ollama (IA Local)
Ideal para: Proyectos sensibles a la privacidad, traducción sin conexión, uso ilimitado
Ollama ejecuta modelos de IA localmente en su máquina, proporcionando privacidad y control completos sin costos de API ni requisitos de internet.
Modelos Populares
- translategemma:12b (Modelo de traducción especializado basado en Gemma 3)
- llama3.2 (Propósito general recomendado)
- mistral (Alternativa eficiente)
- codellama (Traducciones conscientes del código)
- Y muchos más modelos de la comunidad
Opciones de Configuración
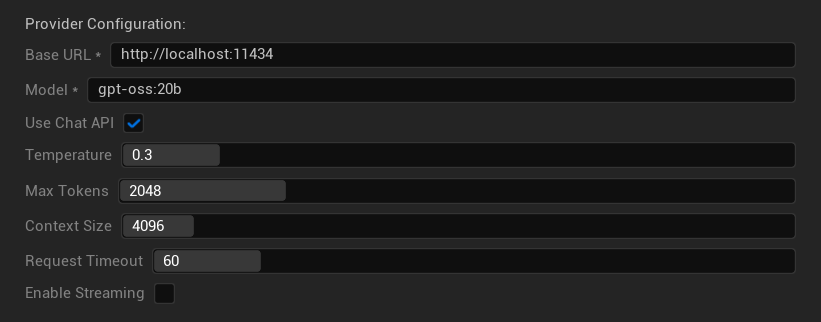
- URL Base: Servidor local de Ollama (predeterminado:
http://localhost:11434) - Modelo: Nombre del modelo instalado localmente (requerido)
- Usar API de Chat: Habilitar para un mejor manejo de conversaciones
- Temperatura: 0.0-2.0 (0.3 recomendado)
- Tokens Máximos: 1-8,192 tokens
- Tamaño de Contexto: 512-32,768 tokens
- Tiempo de Espera de Solicitud: 10-300 segundos (los modelos locales pueden ser más lentos)
- Habilitar Streaming: Para procesamiento de respuestas en tiempo real
Fortalezas
- ✅ Privacidad completa (los datos no salen de su máquina)
- ✅ Sin costos de API ni límites de uso
- ✅ Funciona sin conexión
- ✅ Control total sobre los parámetros del modelo
- ✅ Amplia variedad de modelos comunitarios
- ✅ Sin dependencia de proveedor
Consideraciones
- 💻 Requiere configuración local y hardware capaz
- ⚡ Generalmente más lento que los proveedores en la nube
- 🔧 Se requiere una configuración más técnica
- 📊 La calidad de la traducción varía significativamente según el modelo (algunos pueden superar a los proveedores en la nube)
- 💾 Grandes requisitos de almacenamiento para los modelos
Configuración de Ollama
- Instalar Ollama: Descargue desde ollama.ai e instálelo en su sistema
- Descargar Modelos: Use
ollama pull translategemma:12bpara descargar el modelo elegido - Iniciar Servidor: Ollama se ejecuta automáticamente, o inícielo con
ollama serve - Configurar Plugin: Establezca la URL base y el nombre del modelo en la configuración del plugin
- Probar Conexión: El plugin verificará la conectividad cuando aplique la configuración
OpenAI
Ideal para: La más alta calidad general de traducción, amplia selección de modelos
OpenAI proporciona modelos de lenguaje líderes en la industria a través de su API de Chat Completions, incluidos los últimos modelos GPT, modelos de razonamiento y modelos habilitados para búsqueda web.
Modelos Disponibles
Familia GPT-5 (Modelos insignia)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
Familia GPT-4.1 (Alto rendimiento)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
Familia GPT-4o (Multimodal)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
Serie O (Modelos de razonamiento — no admiten temperatura/top_p)
- o1, o1-pro, o3, o3-mini, o4-mini
Modelos de Búsqueda Web (No admiten temperatura/top_p)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
Legado / Vista Previa
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
Opciones de Configuración
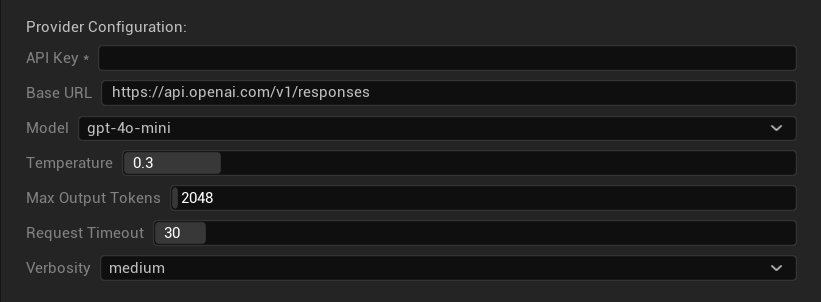
- Clave API: Su clave API de OpenAI (requerida)
- URL Base: Punto final de la API (predeterminado:
https://api.openai.com/v1/chat/completions) - Modelo: Elija entre los modelos disponibles listados arriba
- Usar Temperatura: Alternar el parámetro de temperatura activado/desactivado (ignorado automáticamente para modelos de razonamiento de la serie o y modelos de búsqueda web)
- Temperatura: 0.0–2.0 (0.3 recomendado para consistencia en traducción)
- Top P: Parámetro de muestreo de núcleo 0.0–1.0 (ignorado para modelos de razonamiento de la serie o y modelos de búsqueda web)
- Tokens de Finalización Máximos: 1–128,000 tokens (incluye tokens de salida y de razonamiento)
- Tiempo de Espera de Solicitud: 5–300 segundos
Fortalezas
- ✅ Calidad de traducción consistentemente alta
- ✅ Excelente comprensión del contexto
- ✅ Fuerte preservación del formato
- ✅ Amplio soporte de idiomas
- ✅ Tiempo de actividad de API confiable
Consideraciones
- 💰 Costo más alto por solicitud
- 🌐 Requiere conexión a internet
- ⏱️ Límites de uso basados en el nivel
Anthropic Claude
Ideal para: Traducciones matizadas, contenido creativo, aplicaciones centradas en la seguridad
Los modelos Claude sobresalen en la comprensión del contexto y los matices, lo que los hace ideales para juegos con mucha narrativa y escenarios de localización complejos.
Modelos Disponibles
Familia Claude 4.6 (Última)
- claude-opus-4-6, claude-sonnet-4-6
Familia Claude 4.5
- claude-haiku-4-5 (Rápido y eficiente)
- claude-sonnet-4-5, claude-opus-4-5
Familia Claude 4.x
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Familia Claude 3.x (Legado)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
Opciones de Configuración
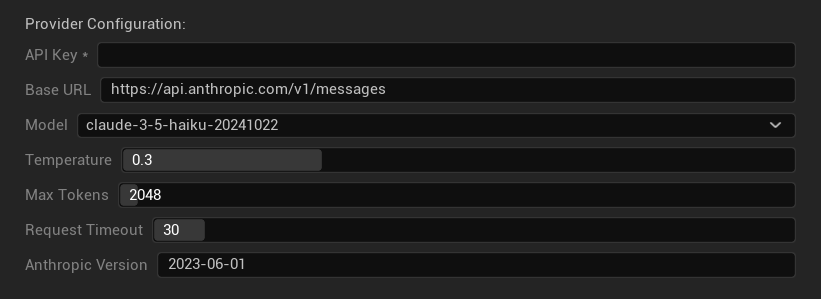
- Clave API: Su clave API de Anthropic (requerida)
- URL Base: Punto final de la API de Claude
- Modelo: Seleccione de la familia de modelos Claude
- Temperatura: 0.0–1.0 (0.3 recomendado)
- Top K: Parámetro de muestreo Top-K (0 = no establecido)
- Tokens Máximos: 1–64,000 tokens
- Tiempo de Espera de Solicitud: 5–300 segundos
- Versión de Anthropic: Encabezado de versión de API
Fortalezas
- ✅ Conciencia contextual excepcional
- ✅ Excelente para contenido creativo/narrativo
- ✅ Fuertes características de seguridad
- ✅ Capacidades de razonamiento detalladas (pensamiento extendido en modelos 3.7+)
- ✅ Seguimiento excelente de instrucciones
Consideraciones
- 💰 Modelo de precios premium
- 🌐 Se requiere conexión a internet
- 📏 Los límites de tokens varían según el modelo
DeepSeek
Ideal para: Traducción rentable, alto rendimiento, proyectos conscientes del presupuesto
DeepSeek ofrece calidad de traducción competitiva a una fracción del costo de otros proveedores, lo que lo hace ideal para proyectos de localización a gran escala.
Modelos Disponibles
- deepseek-chat (Propósito general, recomendado)
- deepseek-reasoner (Capacidades de razonamiento mejoradas)
Opciones de Configuración
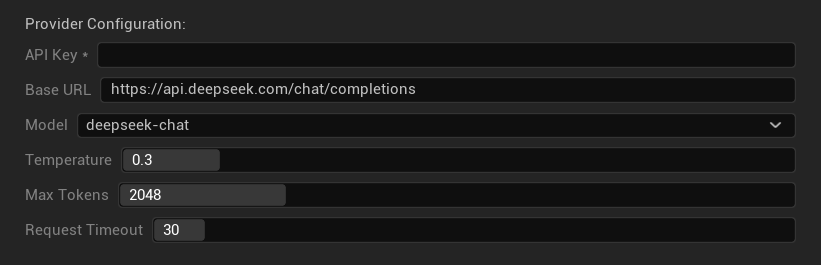
- Clave API: Su clave API de DeepSeek (requerida)
- URL Base: Punto final de la API de DeepSeek
- Modelo: Elija entre modelos de chat y de razonamiento
- Temperatura: 0.0-2.0 (0.3 recomendado)
- Tokens Máximos: 1-8,192 tokens
- Tiempo de Espera de Solicitud: 5-300 segundos
Fortalezas
- ✅ Muy rentable
- ✅ Buena calidad de traducción
- ✅ Tiempos de respuesta rápidos
- ✅ Configuración simple
- ✅ Límites de tasa altos
Consideraciones
- 📏 Límites de tokens más bajos
- 🆕 Proveedor más nuevo (menos historial)
- 🌐 Requiere conexión a internet
Google Gemini
Ideal para: Proyectos multilingües, traducción rentable, integración con el ecosistema de Google
Los modelos Gemini ofrecen sólidas capacidades multilingües con precios competitivos y características únicas como el modo de pensamiento para un razonamiento mejorado.
Modelos Disponibles
Familia Gemini 3.x (Vista previa)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Familia Gemini 2.5 (Con soporte de pensamiento)
- gemini-2.5-pro (Insignia con pensamiento)
- gemini-2.5-flash (Rápido, con soporte de pensamiento)
- gemini-2.5-flash-lite (Variante ligera)
Familia Gemini 2.0
- gemini-2.0-flash, gemini-2.0-flash-lite
Alias Más Recientes
- gemini-flash-latest, gemini-flash-lite-latest
Opciones de Configuración
- Clave API: Su clave API de Google AI (requerida)
- URL Base: Punto final de la API de Gemini
- Modelo: Seleccione de la familia de modelos Gemini
- Temperatura: 0.0–2.0 (0.3 recomendado)
- Tokens de Salida Máximos: 1–8,192 tokens
- Tiempo de Espera de Solicitud: 5–300 segundos
- Habilitar Pensamiento: Activar razonamiento mejorado para modelos 2.5+
- Presupuesto de Pensamiento: Controlar la asignación de tokens de pensamiento (0 = sin pensamiento)
Fortalezas
- ✅ Fuerte soporte multilingüe
- ✅ Precios competitivos
- ✅ Razonamiento avanzado (modo de pensamiento)
- ✅ Integración con el ecosistema de Google
- ✅ Actualizaciones regulares de modelos con acceso de vista previa a los modelos más nuevos
Consideraciones
- 🧠 El modo de pensamiento aumenta el uso de tokens
- 📏 Límites de tokens variables según el modelo
- 🌐 Se requiere conexión a internet
Elegir el Proveedor Correcto
| Proveedor | Ideal Para | Calidad | Costo | Configuración | Privacidad |
|---|---|---|---|---|---|
| Ollama | Privacidad/sin conexión | Variable* | Gratis | Avanzada | Local |
| OpenAI | Máxima calidad | ⭐⭐⭐⭐⭐ | 💰💰💰 | Fácil | Nube |
| Claude | Contenido creativo | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Fácil | Nube |
| DeepSeek | Proyectos con presupuesto | ⭐⭐⭐⭐ | 💰 | Fácil | Nube |
| Gemini | Multilingüe | ⭐⭐⭐⭐ | 💰 | Fácil | Nube |
*La calidad para Ollama varía significativamente según el modelo local utilizado; algunos modelos locales modernos pueden igualar o superar a los proveedores en la nube.
Consejos de Configuración del Proveedor
Para Todos los Proveedores en la Nube:
- Almacene las claves API de forma segura y no las incluya en el control de versiones
- Comience con configuraciones de temperatura conservadoras (0.3) para traducciones consistentes
- Supervise su uso de API y costos
- Pruebe con lotes pequeños antes de ejecuciones de traducción grandes
Para Ollama:
- Asegúrese de tener RAM adecuada (se recomiendan 8GB+ para modelos más grandes)
- Use almacenamiento SSD para un mejor rendimiento de carga de modelos
- Considere la aceleración por GPU para una inferencia más rápida
- Pruebe localmente antes de confiar en él para traducciones de producción