Cómo usar el plugin
Esta guía cubre la API completa en tiempo de ejecución: crear una instancia de LLM, cargar modelos, enviar mensajes, descargar modelos en tiempo de ejecución, gestionar el estado y funciones de utilidad.
Crea una instancia de LLM
Comience creando un objeto Runtime Local LLM. Mantenga una referencia al mismo (por ejemplo, como una variable en Blueprints o una UPROPERTY en C++) para evitar una recolección de basura prematura.
- Blueprint
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
Cargar un modelo
Debes cargar un modelo antes de enviar mensajes. El plugin proporciona varios métodos de carga según tu flujo de trabajo.
Cargar por Nombre
Si gestionas modelos a través del panel de configuración del editor, usa Load Model (By Name).
- Blueprint
- C++
- UE 5.3 y anteriores
- UE 5.4+
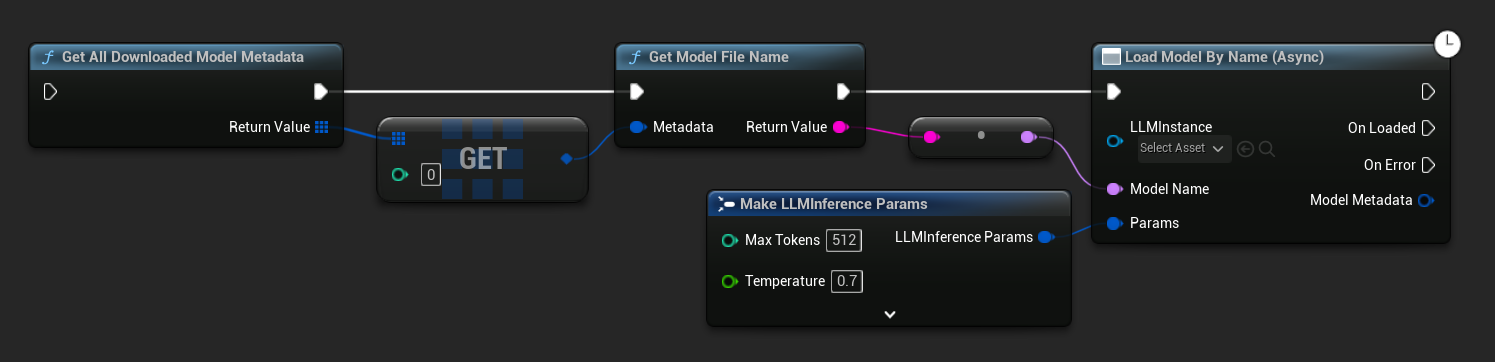
En UE 5.3 y versiones anteriores, el menú desplegable no aparece, por lo que debes recuperar los modelos disponibles manualmente. Usa Get All Downloaded Model Metadata, obtén el elemento en el índice 0 (o el modelo que necesites), pásalo a Get Model File Name para recuperar la cadena de nombre, y luego pásalo a Load Model (By Name).
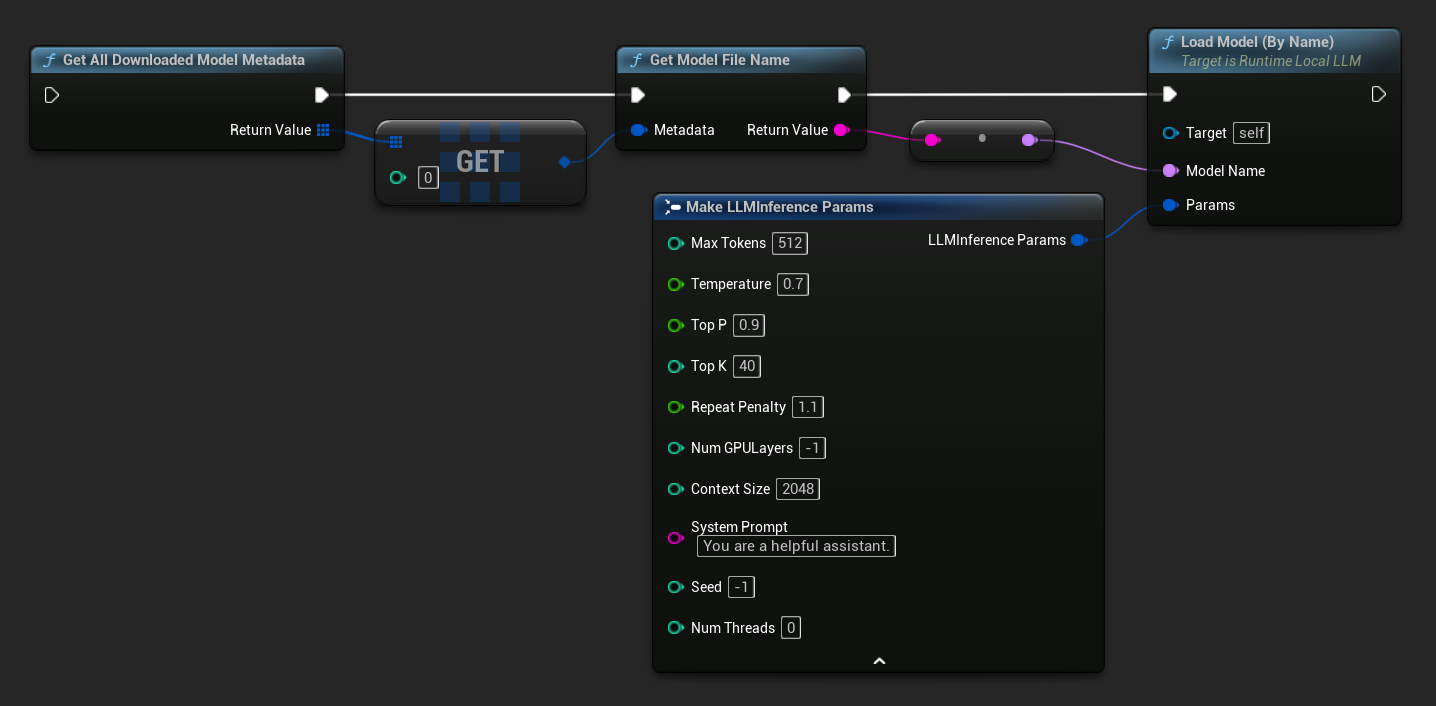
En UE 5.4 y posteriores, Load Model (By Name) presenta un menú desplegable con todos los modelos en disco: simplemente selecciona el modelo que deseas cargar.
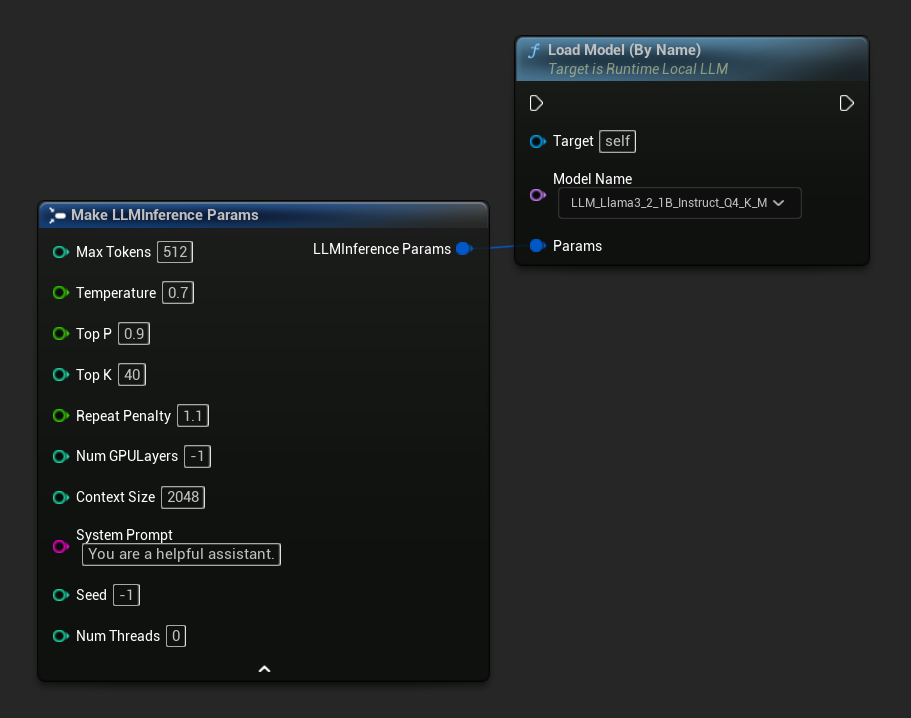
En C++, usa GetAllDownloadedModelMetadata para recuperar los modelos disponibles y GetModelFileName para obtener el nombre que se pasará a LoadModelByName.
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
Cargar desde la ruta del archivo
Cargar un modelo directamente desde una ruta de archivo absoluta a un archivo .gguf:
- Blueprint
- C++
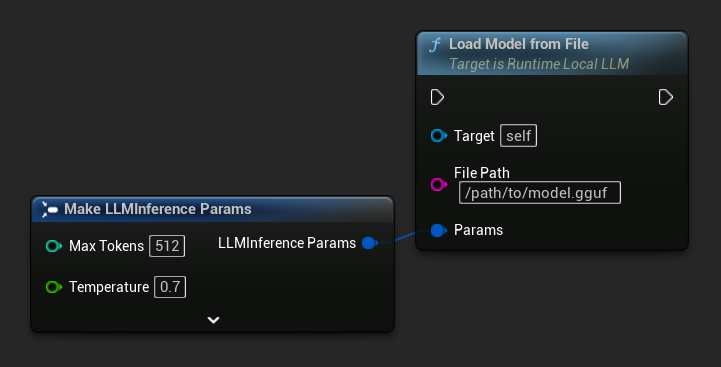
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
Cargar desde URL (Descargar y Cargar)
Descarga un modelo desde una URL (si aún no está en el disco) y cárgalo automáticamente. Si el archivo ya existe localmente, se omite la descarga.
- Blueprint
- C++
La variante más simple solo requiere una URL; los metadatos se derivan del nombre del archivo.
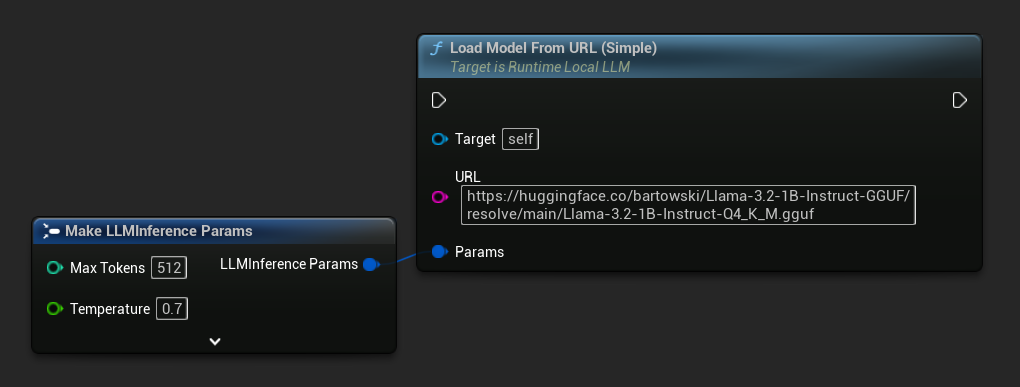
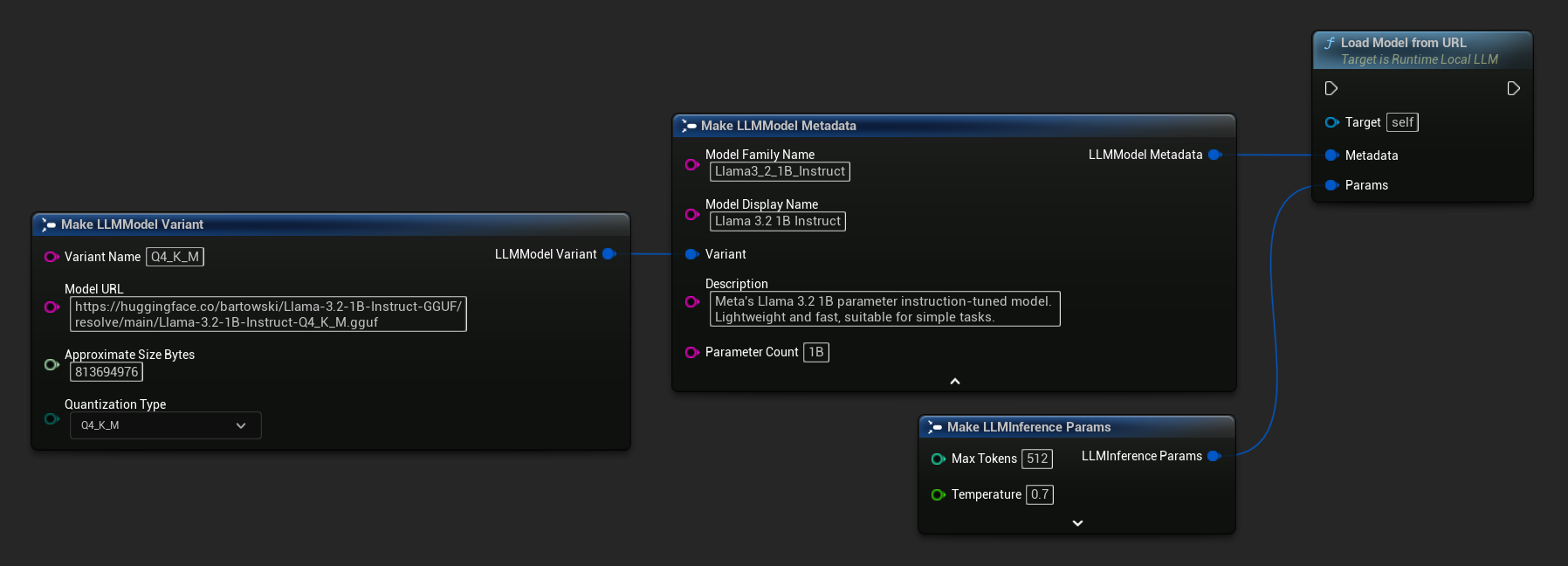
También puedes usar Load Model From URL con metadatos completos del modelo para obtener información más detallada del mismo.
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
Carga Asíncrona (Blueprint)
Para manejar la finalización de la carga y los errores a través de pines de salida en lugar de enlazar delegados manualmente, hay dos nodos asíncronos disponibles.
Load Model By Name (Async) es un espejo de Load Model (By Name): en UE 5.4+ presenta un menú desplegable de todos los modelos en el disco.
- UE 5.4+
- UE 5.3 y anteriores
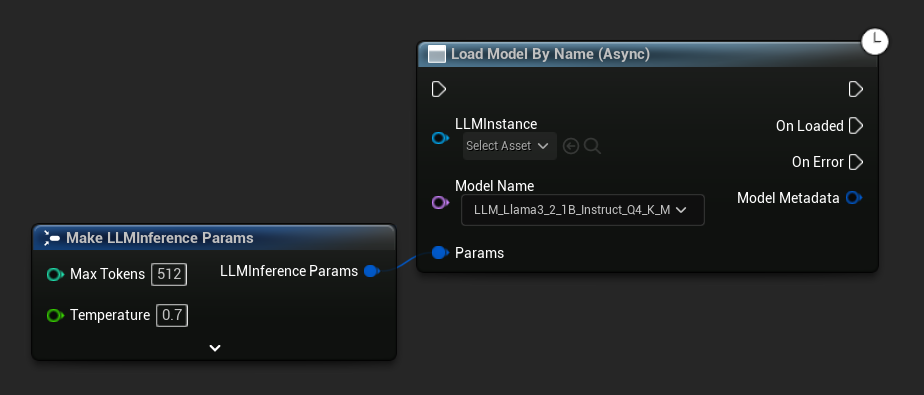
En UE 5.3 y versiones anteriores, el menú desplegable no aparece. Use Get All Downloaded Model Metadata, obtenga el elemento en el índice 0 (o el modelo que necesite), páselo a Get Model File Name, luego páselo a Load Model By Name (Async).
Load Model From File (Async) toma una ruta de archivo absoluta en su lugar:
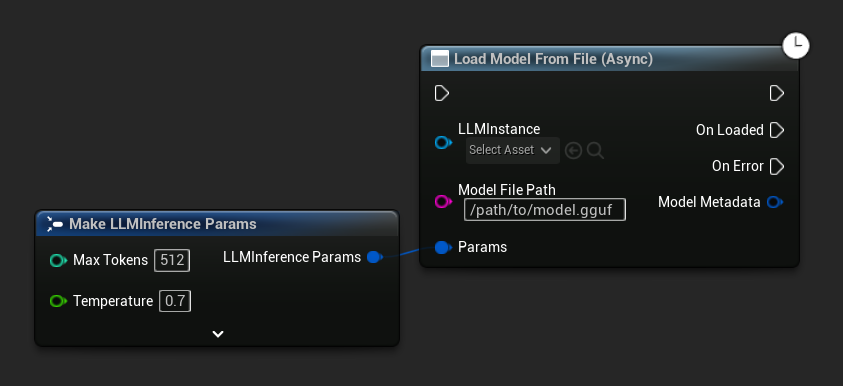
Vincular eventos
Vincularse a los delegados de la instancia del LLM para recibir callbacks. Todos los callbacks se activan en el hilo del juego.
- Blueprint
- C++
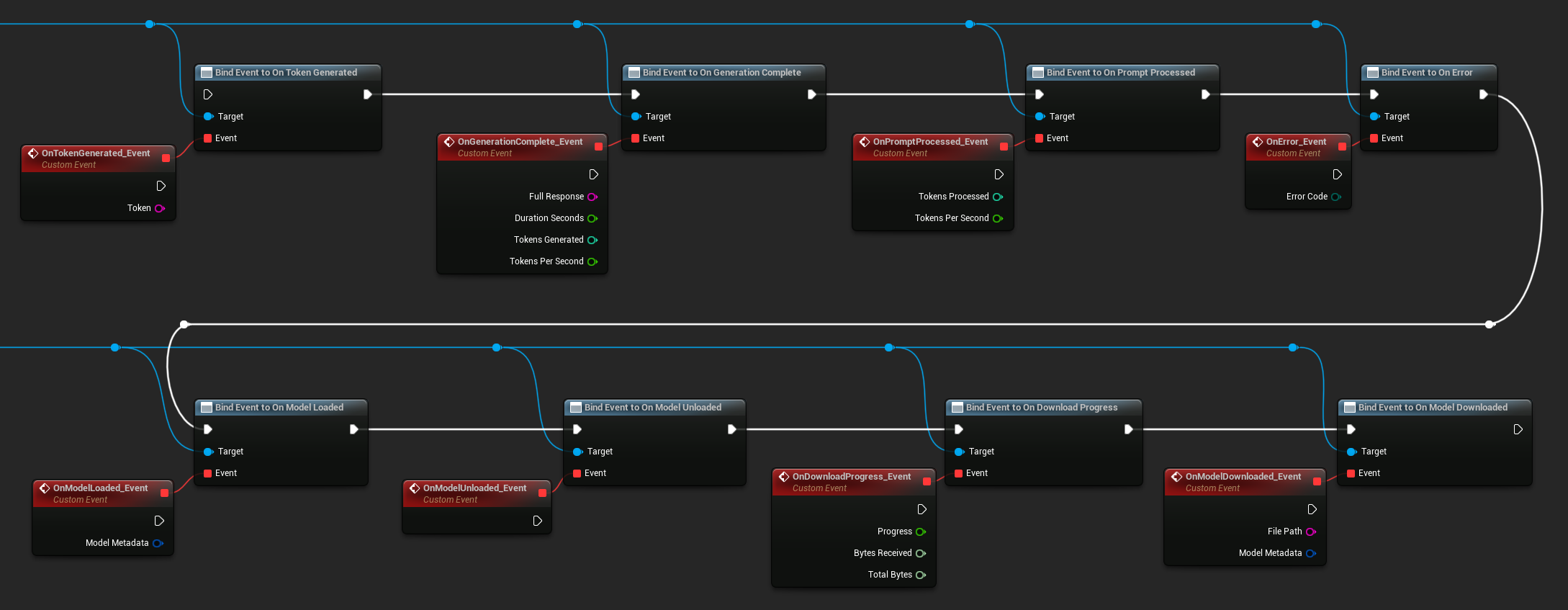
Delegados disponibles:
- Al generar token: Se activa por cada token de salida
- Al completar la generación: Se activa cuando la respuesta completa está lista, con duración, cantidad de tokens y tokens por segundo
- Al procesar el prompt: Se activa después de que se procesa el prompt de entrada, antes de que comience la generación
- Al ocurrir un error: Se activa si ocurre un error durante cualquier operación
- Al cargar el modelo: Se activa cuando un modelo termina de cargarse
- Al descargar el modelo: Se activa cuando el modelo se descarga
- Al progresar la descarga: Se activa periódicamente durante la descarga de un modelo (fracción de progreso, bytes recibidos, bytes totales)
- Al descargar el modelo: Se activa cuando una operación de solo descarga se completa
- Al guardar la conversación: Se activa cuando una conversación se ha escrito en un archivo JSON
- Al cargar la conversación: Se activa cuando una conversación se ha cargado desde un archivo o una instantánea de memoria
- Al resumir el historial: Se activa cuando la auto-resumir comprime mensajes antiguos (informa la cantidad de mensajes, tokens ahorrados y el resumen)
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda(
[](const FString& FullResponse, float DurationSeconds, int32 TokensGenerated, float TokensPerSecond)
{
});
LLM->OnPromptProcessedNative.AddLambda([](int32 TokensProcessed, float TokensPerSecond)
{
});
LLM->OnErrorNative.AddLambda([](ELLMErrorCode ErrorCode)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnModelUnloadedNative.AddLambda([]()
{
});
LLM->OnDownloadProgressNative.AddLambda([](float Progress, int64 BytesReceived, int64 TotalBytes)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& FilePath, const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnConversationSavedNative.AddLambda([](const FString& FilePath)
{
});
LLM->OnConversationLoadedNative.AddLambda([](const FLLMConversationSnapshot& Snapshot)
{
});
LLM->OnHistorySummarizedNative.AddLambda([](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
});
Enviar mensajes
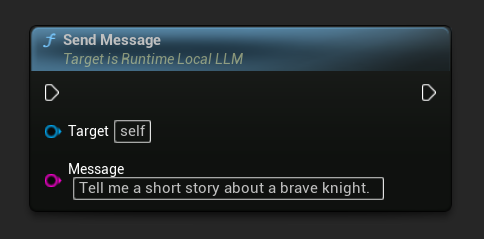
Una vez que se carga un modelo, envía un mensaje de usuario para generar una respuesta:
- Blueprint
- C++
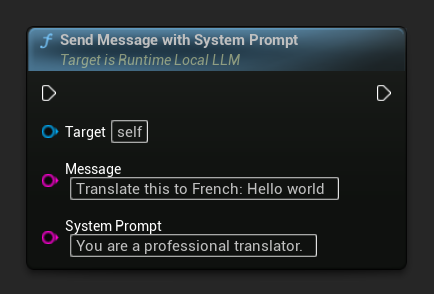
Para sobrescribir el prompt del sistema para un mensaje específico, usa Send Message With System Prompt:
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
Los tokens fluyen a través de OnTokenGenerated a medida que se generan. Cuando la generación finaliza, OnGenerationComplete se activa con la respuesta completa, la duración, el recuento de tokens y los tokens por segundo.
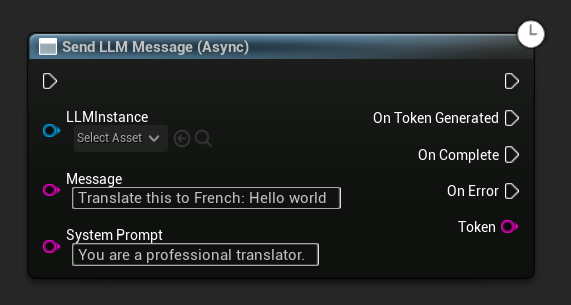
Enviar mensaje asíncrono (Blueprint)
El nodo Send LLM Message (Async) proporciona pines de salida dedicados para tokens, finalización y errores:
Descargar modelos en tiempo de ejecución
Además del flujo de descarga y carga descrito anteriormente, puedes descargar un modelo al disco sin cargarlo. Esto es útil para precargar modelos en una pantalla de carga o menú de configuración.
- Blueprint
- C++
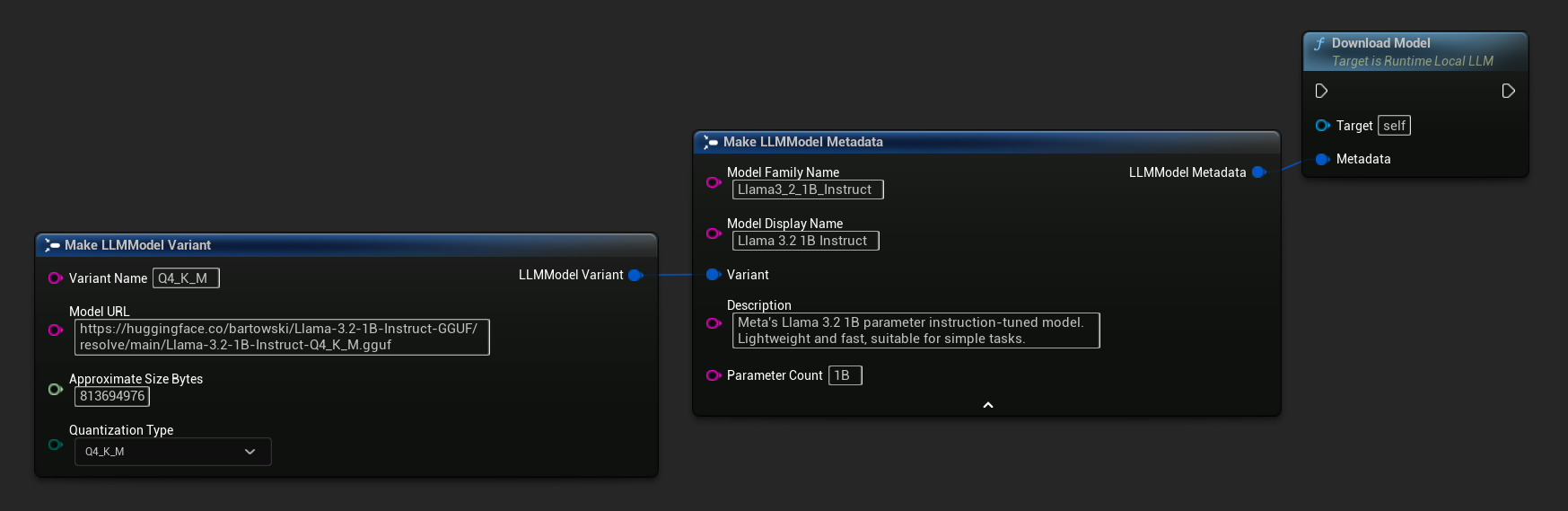
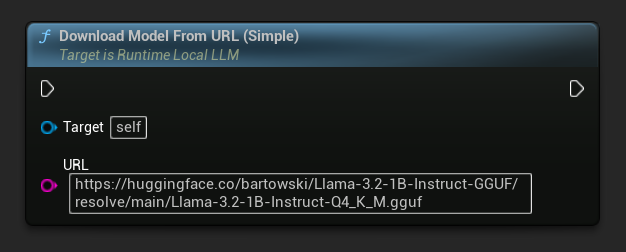
También está disponible una variante solo con URL:
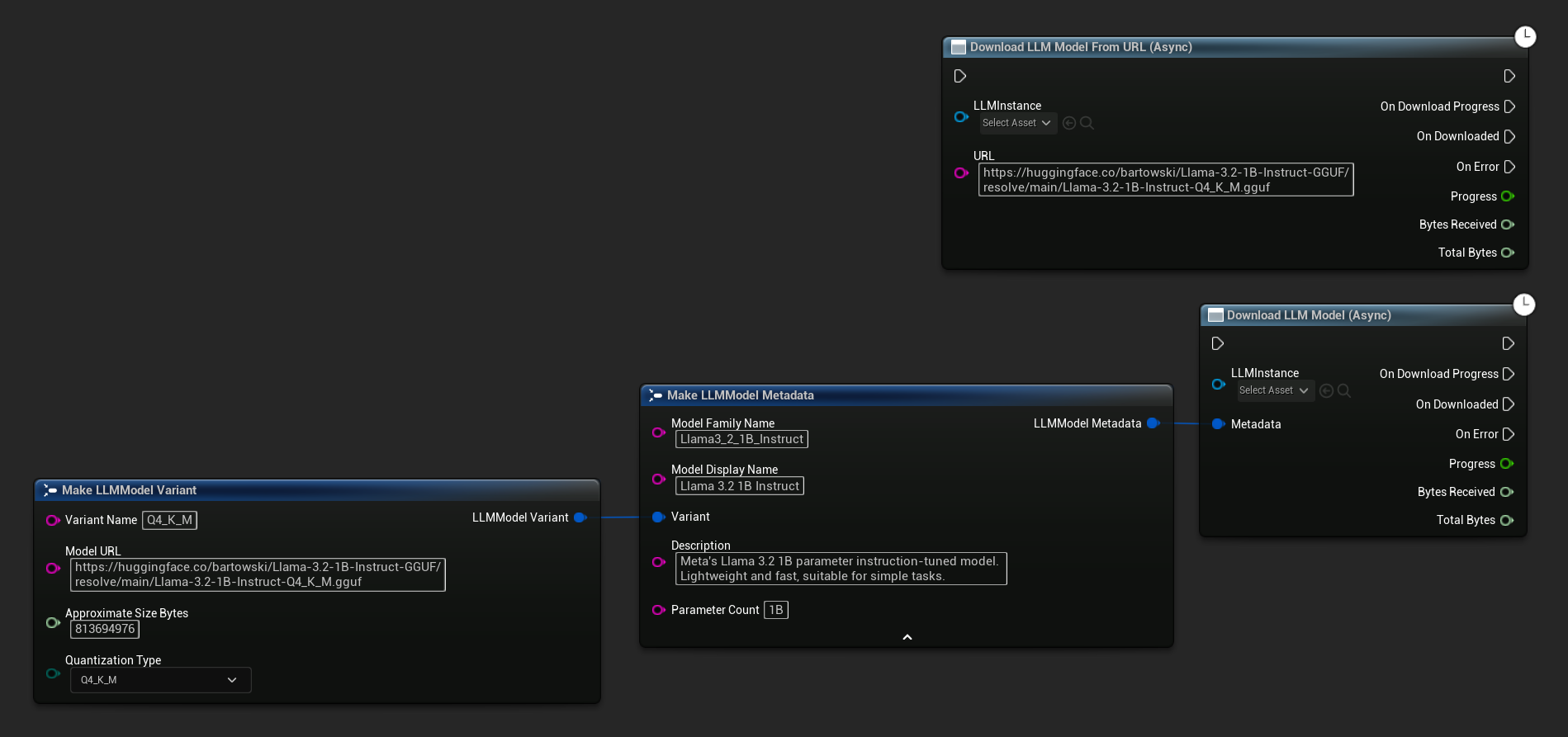
El nodo Download LLM Model (Async) y Download LLM Model From URL (Async) proporciona pines de salida para el progreso, la finalización y los errores:
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
El delegado OnDownloadProgress informa el progreso durante la descarga. OnModelDownloaded se activa cuando el archivo se guarda en el disco.
Para cancelar una descarga en curso:
- Blueprint
- C++
LLM->CancelDownload();
El plugin evita automáticamente las descargas duplicadas: si ya hay una descarga en curso para el mismo modelo, las llamadas posteriores se ignoran.
Detener Generación
Para interrumpir una generación en curso:
- Blueprint
- C++
LLM->StopGeneration();
Restablecer el contexto de la conversación
Borra el historial de la conversación para iniciar una nueva conversación:
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
Guardar y Cargar Conversaciones
El plugin puede persistir el historial de conversación en disco como JSON o mantenerlo en memoria como una instantánea. De forma predeterminada, el mensaje del sistema se excluye de los guardados, por lo que el mismo historial de conversación se puede cargar en diferentes instancias de LLM con distintas reglas del sistema. Esto es útil para escenarios con múltiples NPC, donde cada personaje tiene su propia memoria pero puede compartir o diferir en sus instrucciones del sistema.
Guardar en archivo
Guarda la conversación actual en un archivo JSON en el disco.
- Blueprint
- C++
El parámetro Include System Prompt controla si el mensaje del sistema (si está presente) se escribe en el archivo. El valor predeterminado es false para portabilidad entre NPCs.
On Conversation Saved se activa cuando se escribe el archivo.
// Excludes system prompt by default
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"));
// Include the system prompt in the file
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"), /*bIncludeSystemPrompt=*/ true);
Cargar desde archivo
Cargar una conversación desde un archivo JSON:
- Blueprint
- C++
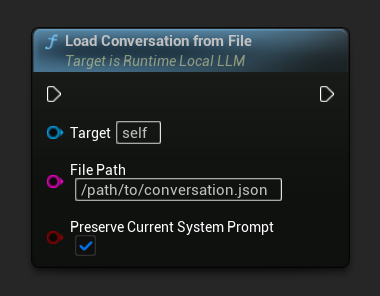
El parámetro Preserve Current System Prompt (por defecto true) mantiene intacto el mensaje del sistema actualmente cargado mientras intercambia el historial de conversación guardado. Esta es la configuración recomendada para el intercambio de memoria de NPC.
Al cargar la conversación se activa con la instantánea cargada.
// Keep current system prompt, swap in the saved history
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"));
// Replace the system prompt with whatever's in the file
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"), /*bPreserveCurrentSystemPrompt=*/ false);
Instantáneas en Memoria (Flujo de Trabajo Multi-NPC)
Para un intercambio rápido de NPC durante el juego, guarda la conversación actual en la memoria en lugar de escribirla en el disco. Este patrón es la forma recomendada de gestionar muchos NPC que comparten un único modelo cargado:
- Blueprint
- C++
El patrón típico de múltiples NPC utiliza un Mapa de Nombre → Instantánea de Conversación LLM en tu administrador de NPC o estado del juego:
- Al cambiar de un NPC: llama a
Save Conversation To Memory, luego enOn Conversation Loaded(que también se activa para la entrega de instantáneas), almacena la instantánea en tu mapa con la clave del nombre del NPC. - Al cambiar a otro NPC: lee la instantánea de tu mapa y llama a
Load Conversation From MemoryconPreserve Current System Prompthabilitado.

Dado que el mensaje del sistema permanece cargado entre intercambios, la "personalidad" de cada NPC puede codificarse en un mensaje del sistema por NPC (llama a Send Message With System Prompt una vez después de un intercambio para actualizarlo) o compartirse entre todos los NPC.
// Maintain per-NPC snapshots
UPROPERTY()
TMap<FName, FLLMConversationSnapshot> NPCMemories;
// Save the currently active NPC's memory before switching
LLM->OnConversationLoadedNative.AddLambda([this](const FLLMConversationSnapshot& Snapshot)
{
NPCMemories.Add(CurrentNPC, Snapshot);
});
LLM->SaveConversationToMemory();
// Activate another NPC's memory
if (const FLLMConversationSnapshot* Found = NPCMemories.Find(NextNPC))
{
LLM->LoadConversationFromMemory(*Found, /*bPreserveCurrentSystemPrompt=*/ true);
CurrentNPC = NextNPC;
}
Las instantáneas son independientes del modelo: almacenan mensajes, no el estado de la caché KV. La misma instantánea se puede cargar en un modelo diferente (aunque el estilo conversacional puede cambiar). El campo OriginModelFamilyName en la instantánea te permite verificar qué modelo la produjo, si deseas imponer compatibilidad.
Resumen Automático de Contexto
Las conversaciones largas eventualmente superan la ventana de contexto del modelo, lo que normalmente truncaría el historial o causaría errores. La función de resumen automático del plugin monitorea el uso del contexto y, cuando se supera un umbral configurado, resume los mensajes más antiguos en un único mensaje de "memoria" antes de generar la siguiente respuesta. Esto mantiene estables los costos de tokens y la latencia en conversaciones de duración indefinida.
La síntesis la realiza el mismo modelo cargado, por lo que no se necesita un segundo modelo ni una llamada a la API.
Habilitar la auto-resumir
- Blueprint
- C++
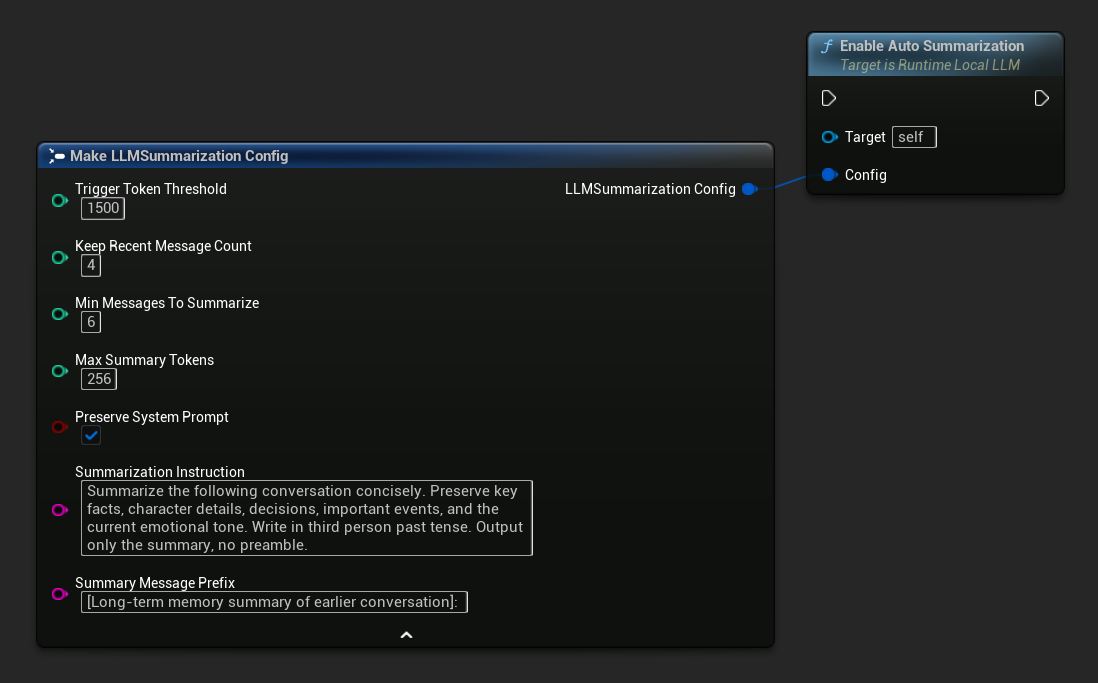
Usa Get Default Summarization Config para obtener valores predeterminados sensatos y luego ajústalos según sea necesario.
FLLMSummarizationConfig Config = URuntimeLocalLLM::GetDefaultSummarizationConfig();
Config.TriggerTokenThreshold = 1500;
Config.KeepRecentMessageCount = 4;
Config.MinMessagesToSummarize = 6;
LLM->EnableAutoSummarization(Config);
Una vez habilitado, el resumen se ejecuta automáticamente antes de cada llamada a SendMessage cuando sea necesario, sin requerir ninguna acción adicional.
Por defecto, el auto-resumen se ejecuta antes de procesar un nuevo mensaje, ya que necesita reconstruir el contexto, lo que no puede ocurrir de forma segura junto con la generación de una respuesta. Si prefieres que se ejecute después de la respuesta, mientras el jugador lee y escribe, desactiva el auto-resumen y actívalo manualmente: vincula a On Generation Complete, verifica Get Used Context Length con respecto a tu umbral, y llama a Summarize Now si se supera. Dado que Summarize Now se encola en la misma cola de tareas en segundo plano, se ejecutará justo después de que finalice la respuesta y antes de que se procese el siguiente mensaje.
Referencia de Configuración
| Parámetro | Type | Predeterminado | Descripción |
|---|---|---|---|
| Umbral del Token de Activación | int32 | 1500 | La summarización se ejecuta cuando los tokens de contexto utilizados superan este valor. Ajústelo en relación con su Context Size; alrededor del 60-75 % es una buena regla general. |
| Mantener el Recuento de Mensajes Recientes | int32 | 4 | Los mensajes más recientes N nunca se resumen, preservando la coherencia conversacional inmediata. |
| Mensajes Mínimos para Resumir | int32 | 6 | Omitir la síntesis si hay menos de esta cantidad de mensajes antiguos elegibles (evita resúmenes pequeños sin sentido) |
| Tokens de Resumen Máximos | int32 | 256 | Longitud máxima del resumen generado en tokens |
| Preservar el Prompt del Sistema | bool | true | Siempre mantén intacto el mensaje del sistema (índice 0) |
| Instrucción de resumen | FString | (see default) | La instrucción enviada al modelo para producir el resumen |
| Prefijo del Mensaje de Resumen | FString | "[Resumen de memoria a largo plazo de la conversación anterior]: " | Se antepone al resumen generado cuando se inserta en la conversación como un mensaje de memoria con rol de asistente. |
Disparador Manual y Escucha para Resúmenes
Puede activar la síntesis manualmente en cualquier momento, independientemente del umbral.
- Blueprint
- C++
Vincula a On History Summarized para recibir una notificación cuando se complete un pase de resumen. El evento informa cuántos mensajes se eliminaron, cuántos tokens se ahorraron y el texto del resumen generado, útil para mostrar un indicador sutil en la interfaz de chat:
LLM->SummarizeNow();
LLM->OnHistorySummarizedNative.AddLambda(
[](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
UE_LOG(LogTemp, Log, TEXT("Summarized %d messages, saved %d tokens"), MessagesRemoved, TokensSaved);
});
Consultando la longitud de contexto utilizada
Usa Get Used Context Length para verificar cuántos tokens están ocupados actualmente en la ventana de contexto del modelo. Este es el mismo valor que el disparador de auto-resumen integrado compara con Trigger Token Threshold.
- Blueprint
- C++
LLM->GetUsedContextLengthNative([](int32 UsedTokens)
{
UE_LOG(LogTemp, Log, TEXT("Used context: %d tokens"), UsedTokens);
});
Desactivar la auto-resumización
- Blueprint
- C++
LLM->DisableAutoSummarization();
Deshabilitar no deshace los resúmenes ya aplicados a la conversación.
La generación del resumen toma un momento en ejecutarse en el hilo de fondo (el modelo está generando el resumen). Las devoluciones de llamada del flujo de tokens se suprimen durante esta generación interna para que no aparezcan en tu interfaz de chat. On History Summarized se activa una vez que la inserción está completa.
Descargar un modelo
Recursos gratuitos cuando un modelo ya no es necesario:
- Blueprint
- C++
LLM->UnloadModel();
Estado de la consulta
Verifica el estado actual de la instancia del LLM:
- Blueprint
- C++
- Modelo Cargado: Verdadero si un modelo está listo para inferencia
- Generando: Verdadero si la generación está en progreso
- Ocupado: Verdadero si alguna operación (carga, generación, descarga) está activa
- Descargando: Verdadero si una descarga de modelo está en progreso
- Obtener Metadatos del Modelo Cargado: Devuelve los metadatos del modelo actual
- Obtener Parámetros de Inferencia Aplicados: Devuelve los parámetros aplicados al cargar
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
Funciones de la Biblioteca de Modelos
Se proporciona un conjunto de funciones de utilidad estáticas para gestionar archivos de modelo en el disco. Estas son útiles para crear una interfaz de usuario de selección de modelos o para verificar la disponibilidad de modelos en tiempo de ejecución.
Obtener Nombres de Modelos Descargados / Metadatos
- Blueprint
- C++
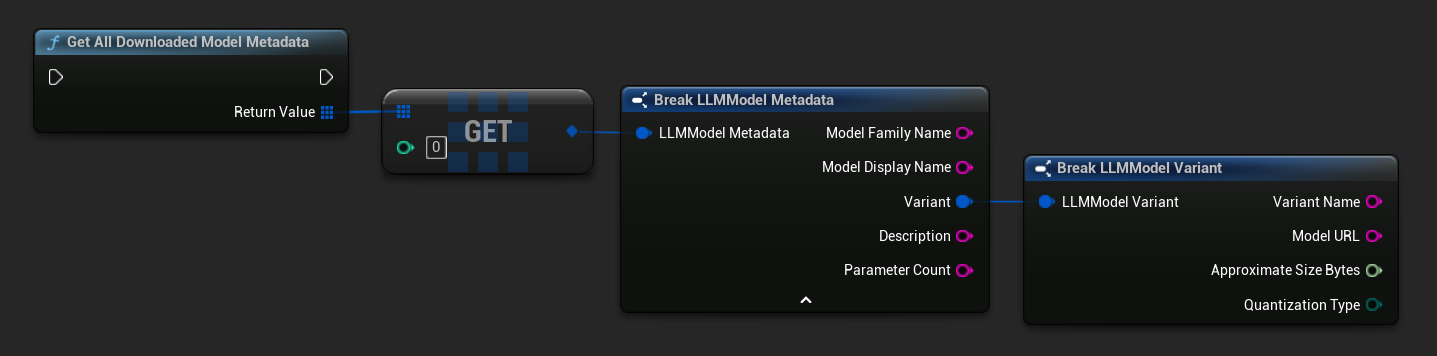
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
Verificar si un modelo está en el disco
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
Obtener la ruta del archivo del modelo
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
Eliminar archivos del modelo
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
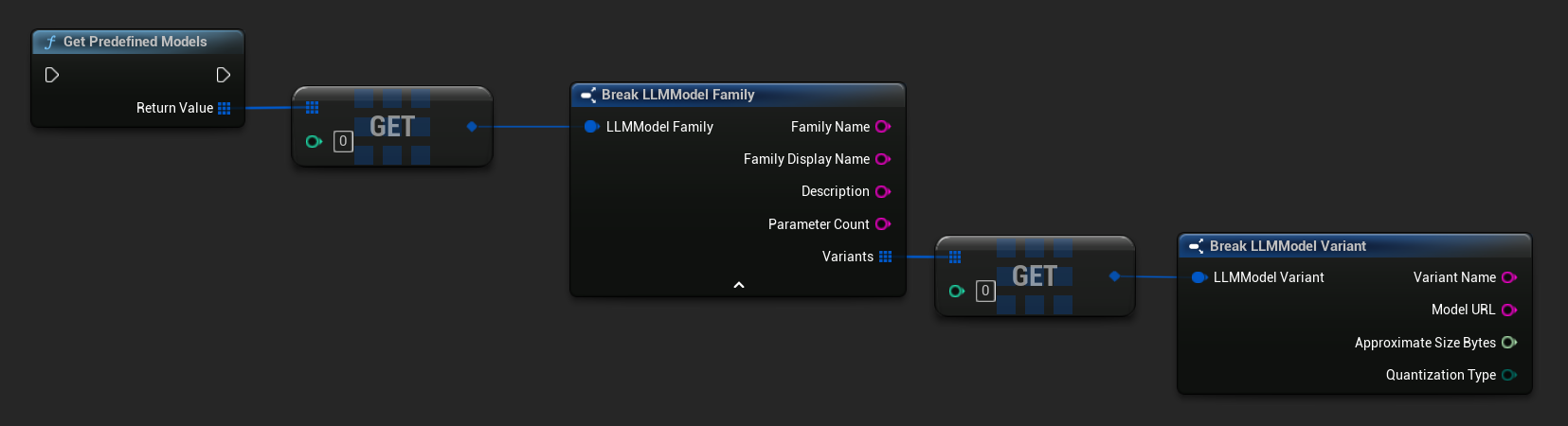
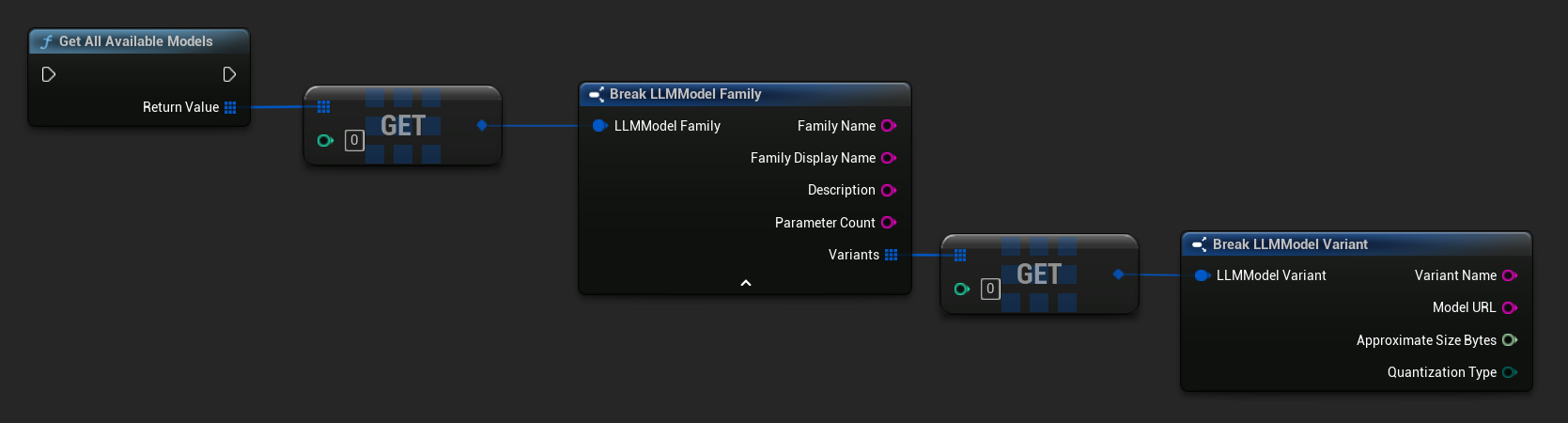
Obtén modelos predefinidos y disponibles
- Blueprint
- C++
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
Generar metadatos a partir de una URL
Construir metadatos de modelo a partir de una URL sin procesar (los campos se derivan del nombre del archivo):
- Blueprint
- C++
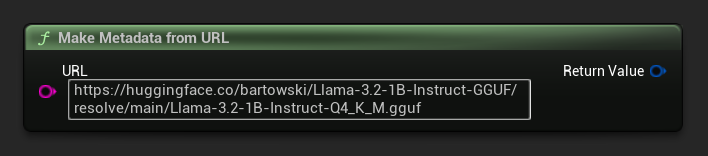
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
Funciones de Utilidad
Se proporciona un conjunto de funciones auxiliares para el formato y la visualización de errores.
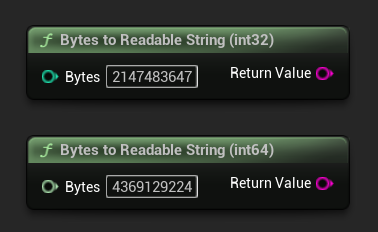
Bytes a Cadena Legible
Convierte un recuento de bytes a una cadena legible para humanos (ej. "4.07 GB"). Útil para mostrar tamaños de modelos en la interfaz de usuario.
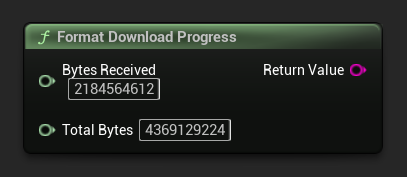
Formato de Progreso de Descarga
Formatea una cadena de progreso de descarga como "1.23 GB / 4.07 GB (30.2%)". Si se desconoce el tamaño total, devuelve solo la cantidad recibida.
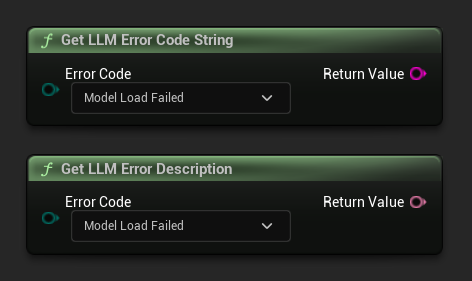
Obtener Descripción del Error / Cadena del Código de Error
Get LLM Error Description devuelve una descripción de texto legible para un código de error. Get LLM Error Code String devuelve el nombre del valor de enumeración como una cadena (útil para el registro).
Referencia de Códigos de Error
| Code | Valor | Descripción |
|---|---|---|
| Desconocido | 0 | Un error no especificado |
| ModelLoadFailed | 10 | El archivo GGUF no se pudo cargar (archivo corrupto, formato incompatible, etc.) |
| ContextCreateFailed | 11 | No se pudo crear el contexto de inferencia. |
| ModeloNoCargado | 20 | Se intentó realizar la inferencia sin que hubiera un modelo cargado. |
| ChatTemplateFalló | 21 | La plantilla de chat del modelo no se pudo aplicar. |
| TokenizationFailed | 22 | El texto de entrada no pudo ser tokenizado. |
| ContextOverflow | 23 | La indicación + el contexto supera el tamaño de contexto configurado. |
| PromptDecodeFailed | 24 | Los tokens de prompt no pudieron decodificarse. |
| ContextTooFullToGenerate | 25 | No hay suficiente espacio de contexto restante para generar la salida. |
| GenerationDecodeFailed | 30 | Se produjo un error al decodificar un token durante la generación. |
| GenerationTruncated | 31 | La generación se detuvo porque se alcanzó el límite máximo de tokens. |
| LLMInstanceNull | 40 | La instancia de LLM es nula o no válida. |
| ModelNotFoundOnDisk | 41 | El archivo del modelo no existe en la ruta esperada. |
| ModelURLEmpty | 42 | Se solicitó una descarga con una URL vacía. |
| ModeloDescargaCancelada | 43 | La descarga fue cancelada. |
| ModelDownloadEmptyData | 44 | La descarga se completó, pero el cuerpo de la respuesta estaba vacío. |
| Error al guardar la descarga del modelo | 45 | La descarga se completó, pero el archivo no pudo guardarse en el disco. |