Guía de Procesamiento de Audio
Esta guía cubre cómo configurar diferentes métodos de entrada de audio para alimentar datos de audio a tus generadores de sincronización de labios. Asegúrate de haber completado la Guía de Configuración antes de continuar.
Procesamiento de Entrada de Audio
Debes configurar un método para procesar la entrada de audio. Hay varias formas de hacerlo según tu fuente de audio.
- Micrófono (Tiempo real)
- Micrófono (Reproducción)
- Texto a Voz (Local)
- Texto a Voz (APIs Externas)
- Desde archivo/almacenamiento de audio
- Búfer de Audio en Streaming
Este enfoque realiza la sincronización de labios en tiempo real mientras se habla al micrófono:
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Crea una Onda de Sonido Capturable usando Runtime Audio Importer
- Para Linux con Pixel Streaming, usa Pixel Streaming Capturable Sound Wave en su lugar.
- Antes de comenzar a capturar audio, vincúlate al delegado
OnPopulateAudioData - En la función vinculada, llama a
ProcessAudioDatadesde tu Generador de Visemas en Tiempo de Ejecución - Comienza a capturar audio desde el micrófono
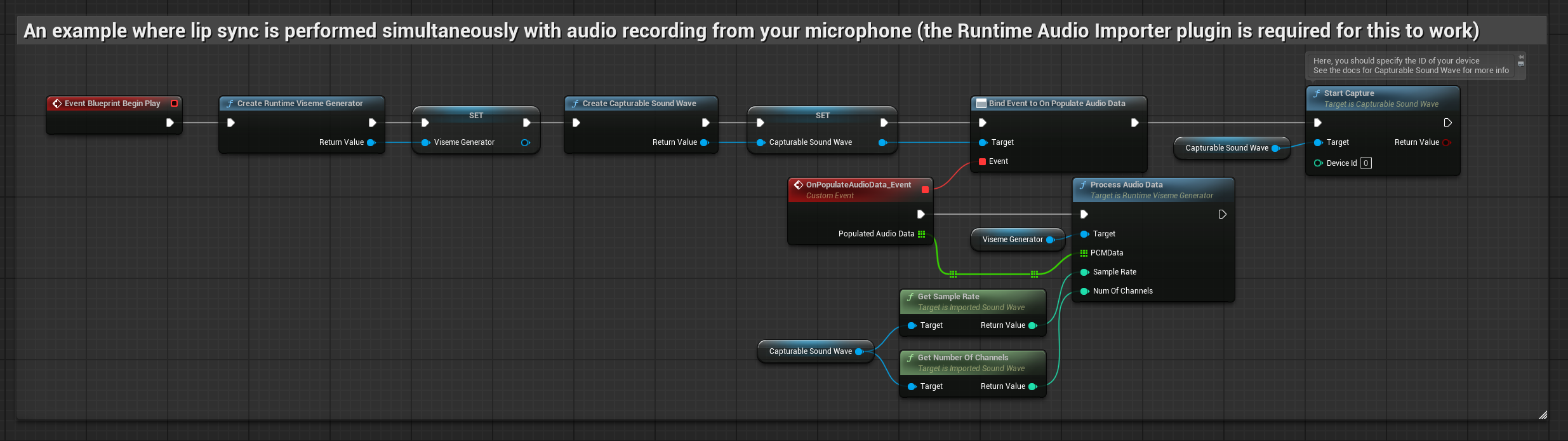
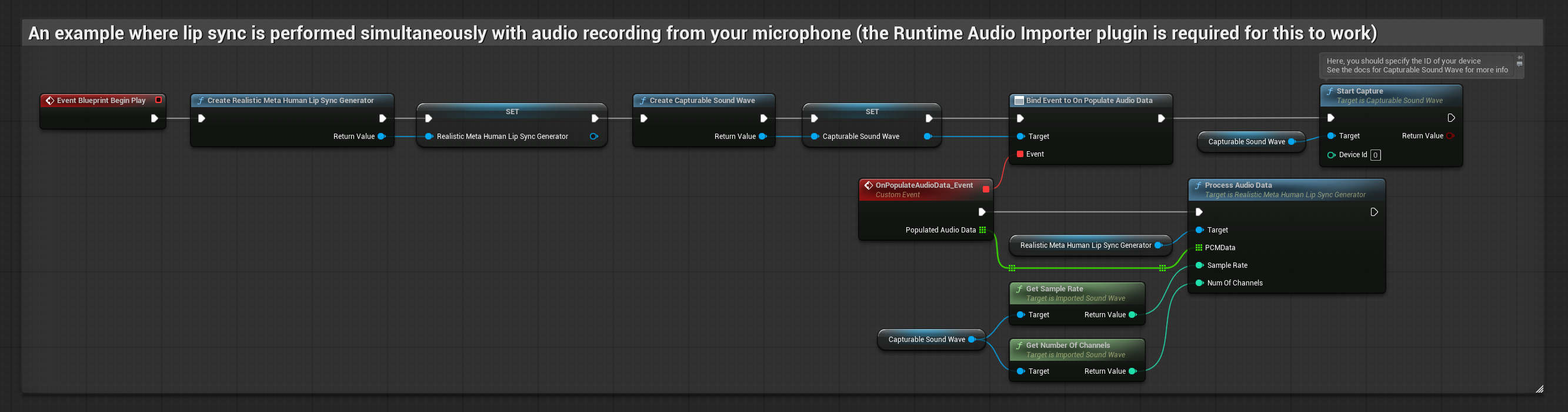
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
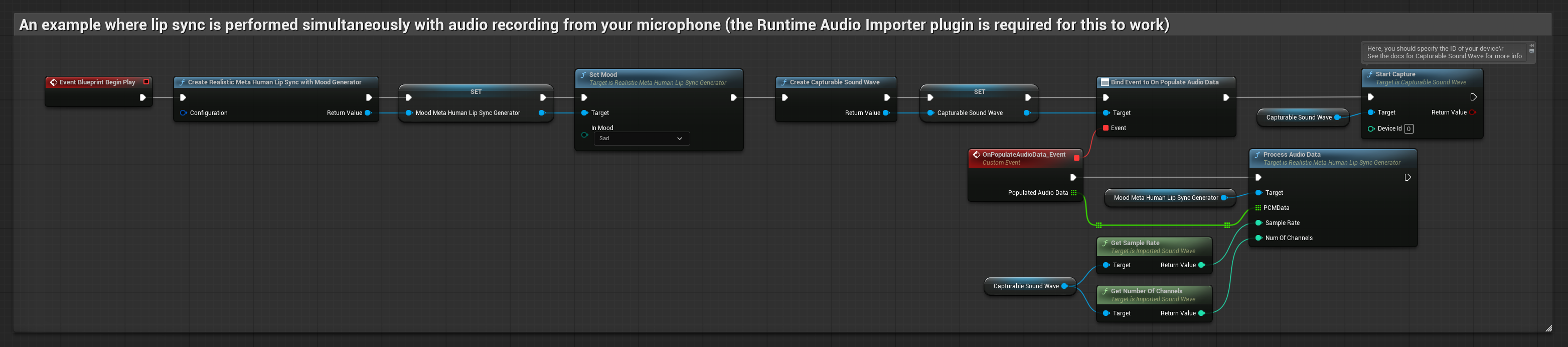
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
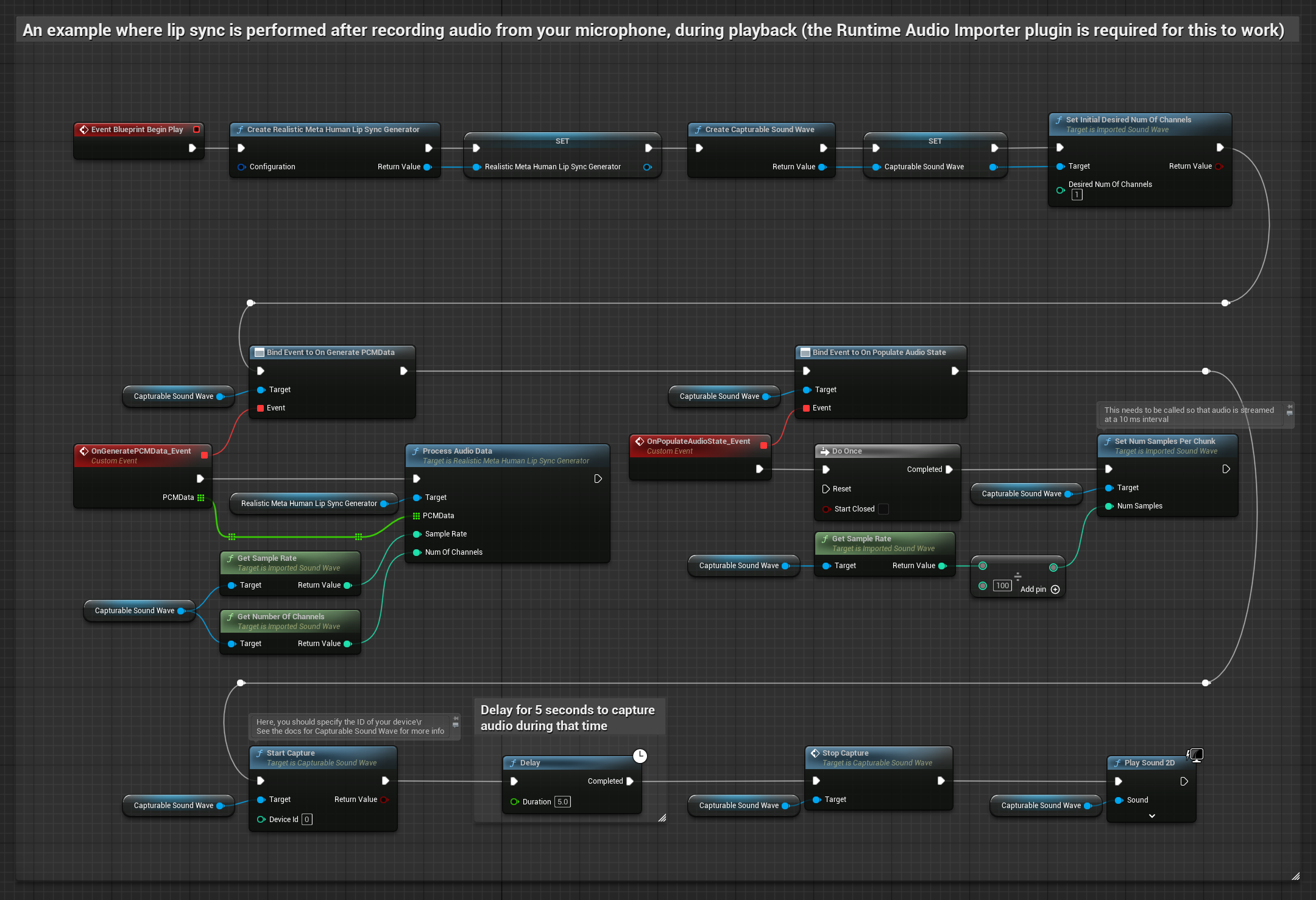
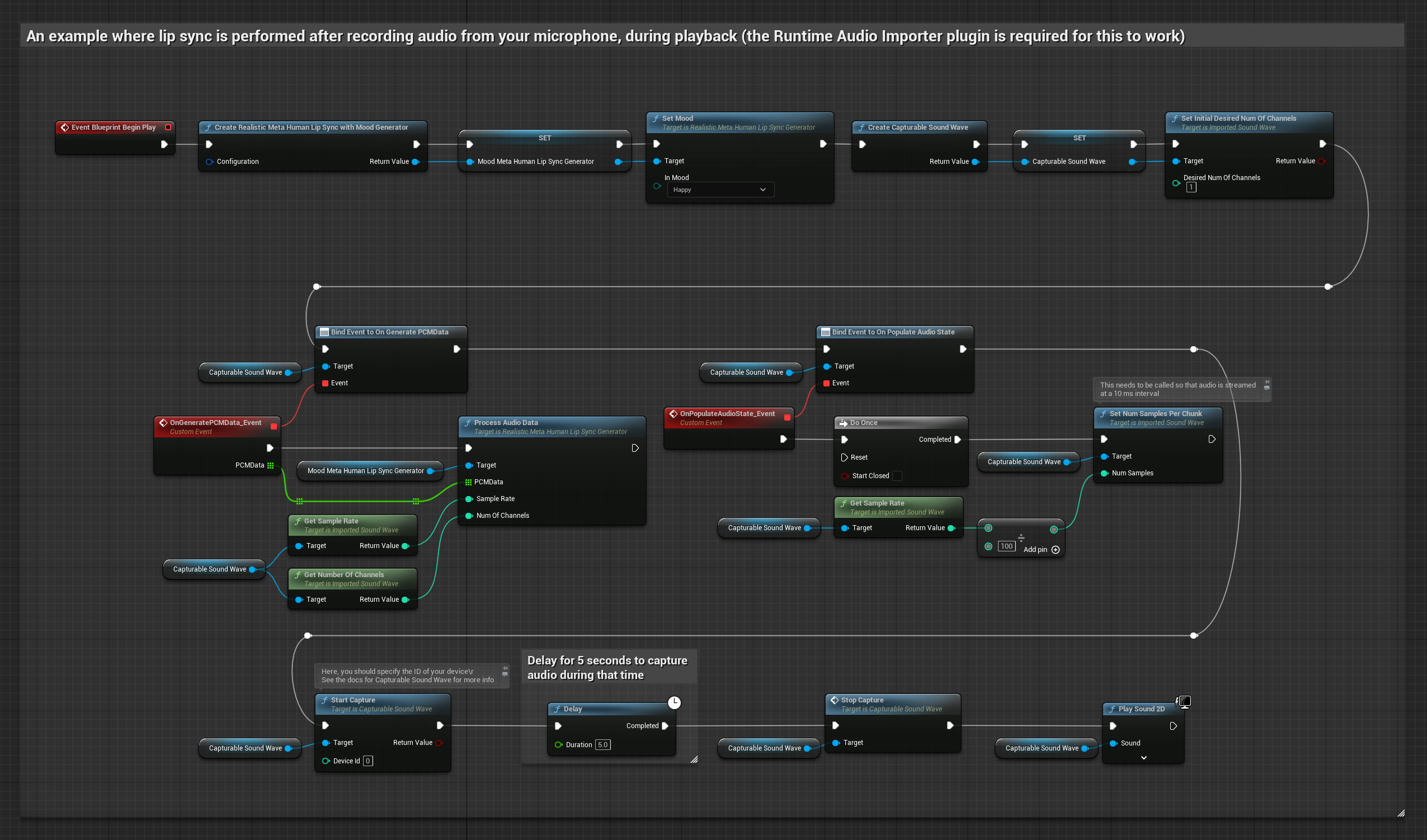
Este enfoque captura el audio desde un micrófono y luego lo reproduce con sincronización de labios:
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Crea una Onda de Sonido Capturable usando Runtime Audio Importer
- Para Linux con Pixel Streaming, usa Pixel Streaming Capturable Sound Wave en su lugar.
- Iniciar la captura de audio desde el micrófono
- Antes de reproducir la onda de sonido capturable, vincúlate a su delegado
OnGeneratePCMData - En la función vinculada, llama a
ProcessAudioDatadesde tu Generador de Visemas en Tiempo de Ejecución
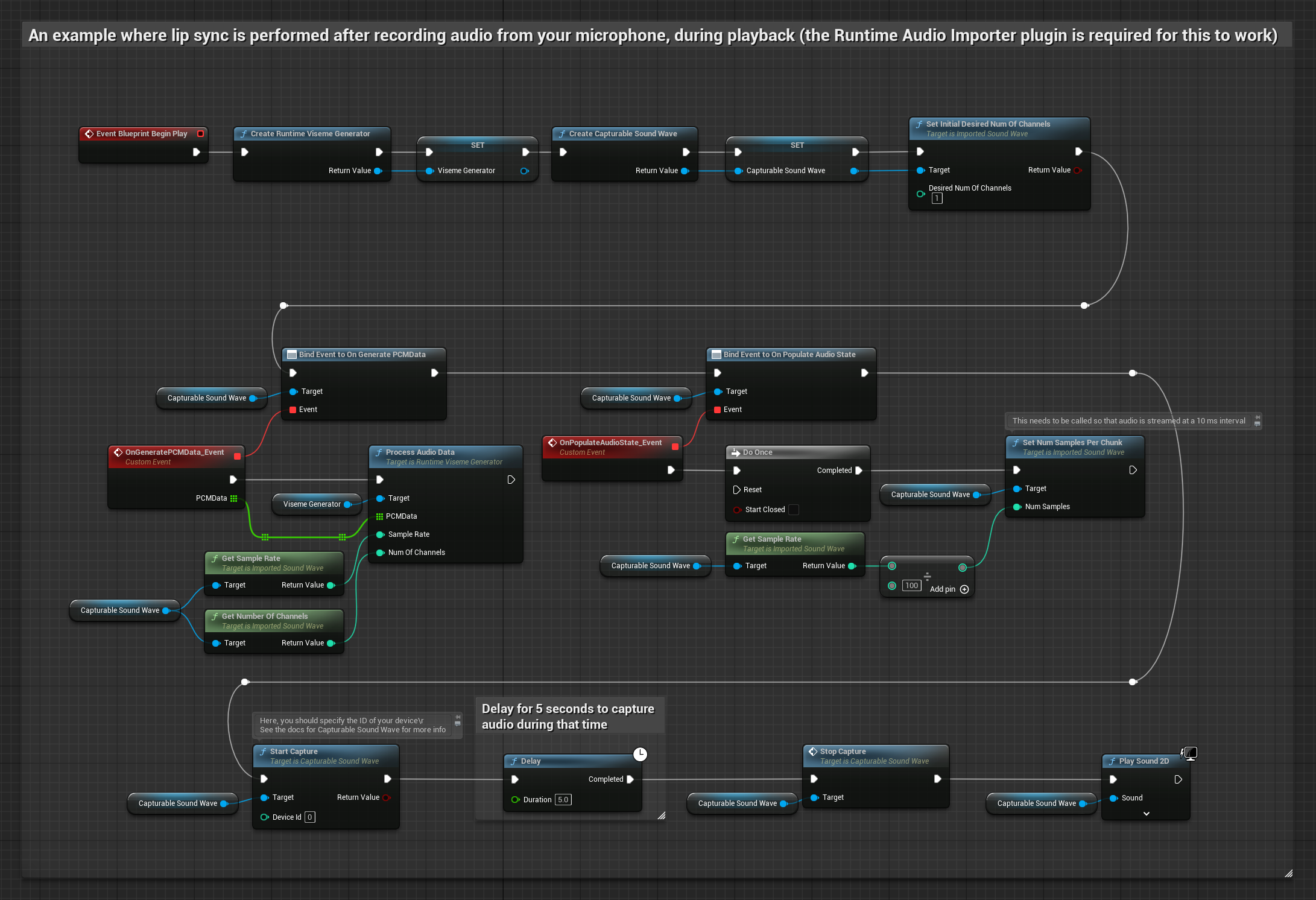
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
- Regular
- Transmisión en vivo
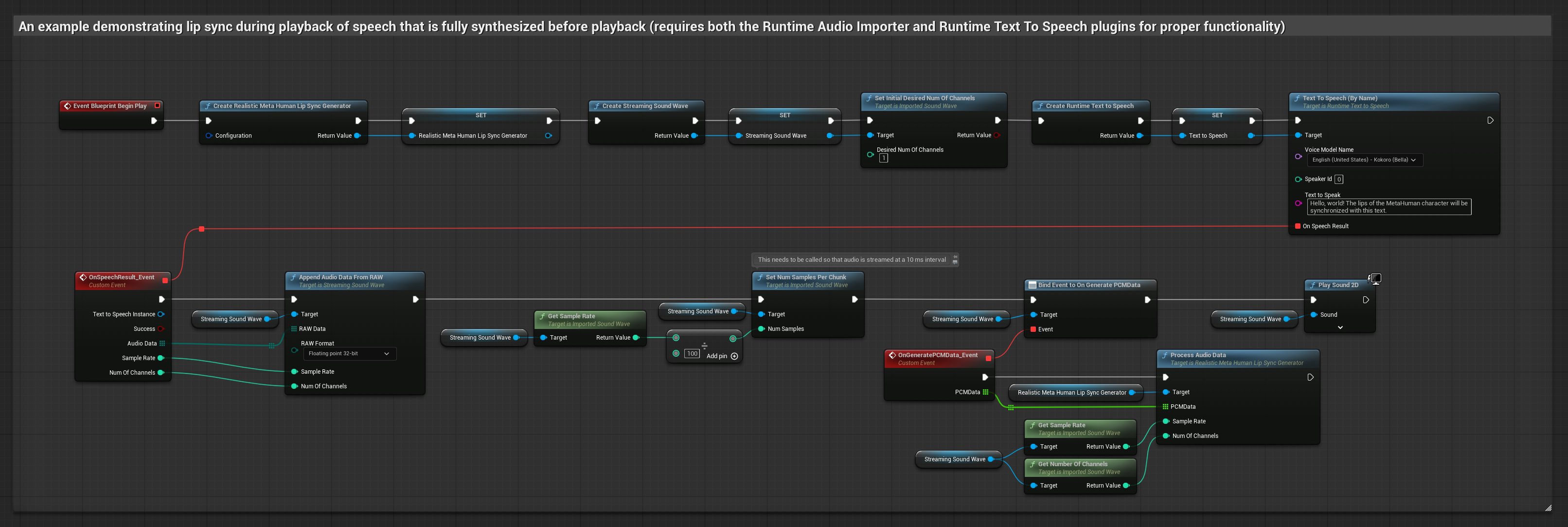
Este enfoque sintetiza el habla a partir de texto utilizando TTS local y realiza sincronización de labios.
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Usa Runtime Text To Speech para generar voz a partir de texto
- Usa Runtime Audio Importer para importar el audio sintetizado
- Antes de reproducir la onda de sonido importada, vincúlate a su delegado
OnGeneratePCMData - En la función vinculada, llama a
ProcessAudioDatadesde tu Runtime Viseme Generator
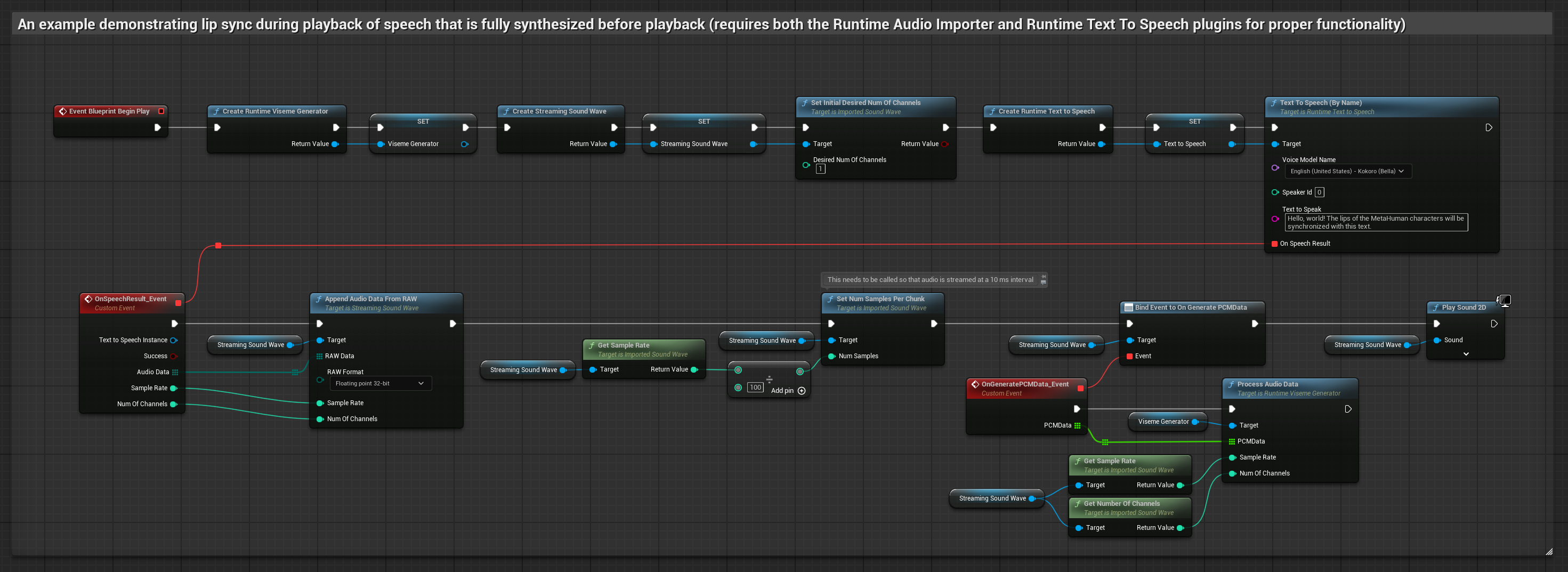
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
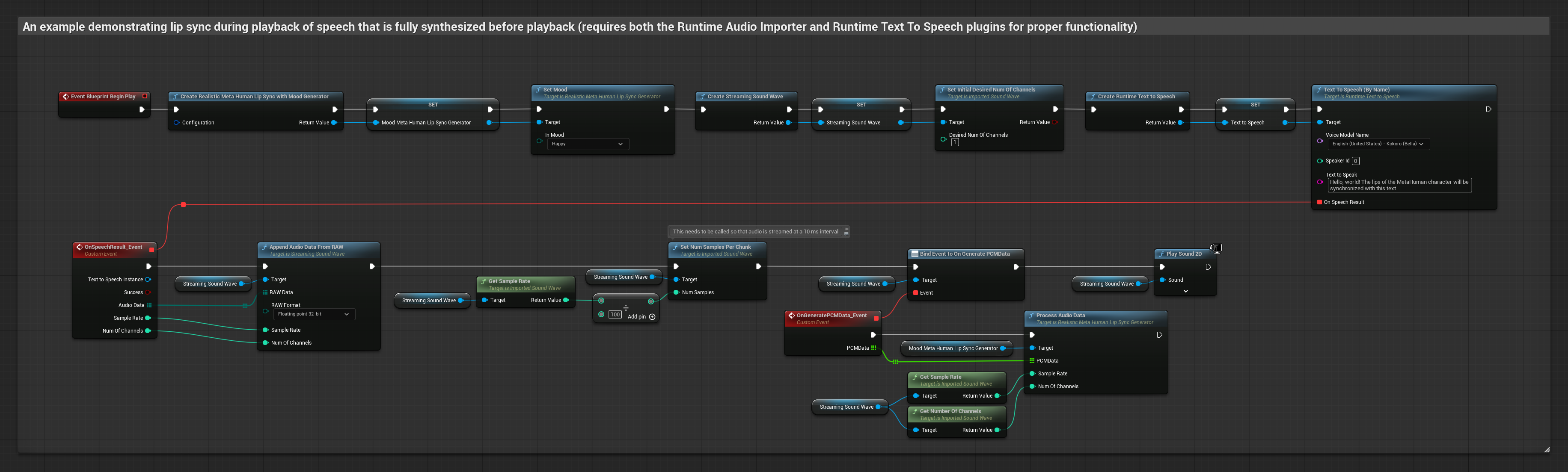
Este enfoque utiliza síntesis de texto a voz en streaming con sincronización de labios en tiempo real.
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Usa Runtime Text To Speech para generar voz en streaming a partir de texto
- Usa Runtime Audio Importer para importar el audio sintetizado
- Antes de reproducir la onda de sonido en streaming, vincúlate a su delegado
OnGeneratePCMData - En la función vinculada, llama a
ProcessAudioDatadesde tu Runtime Viseme Generator
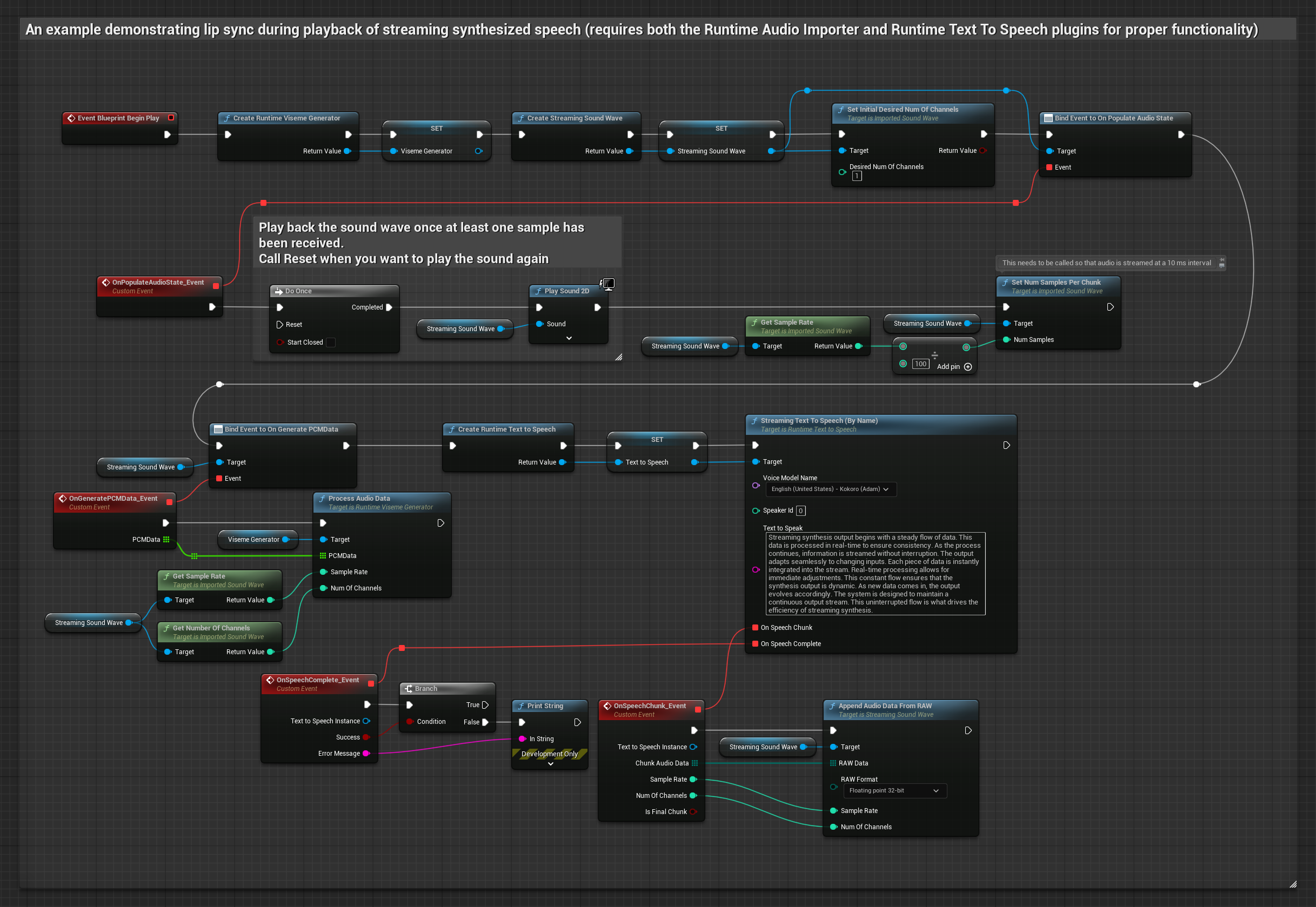
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
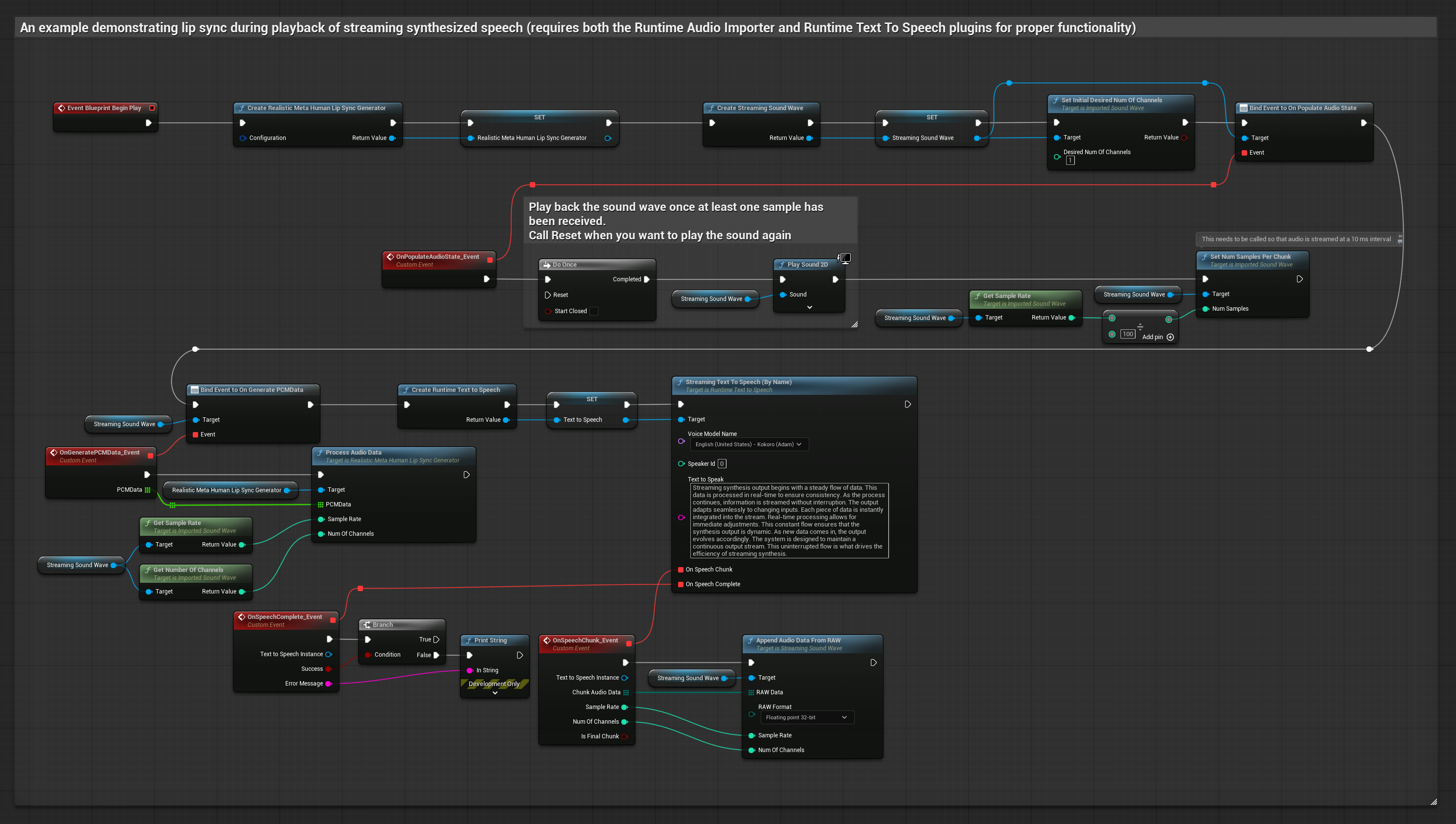
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración del estado de ánimo.
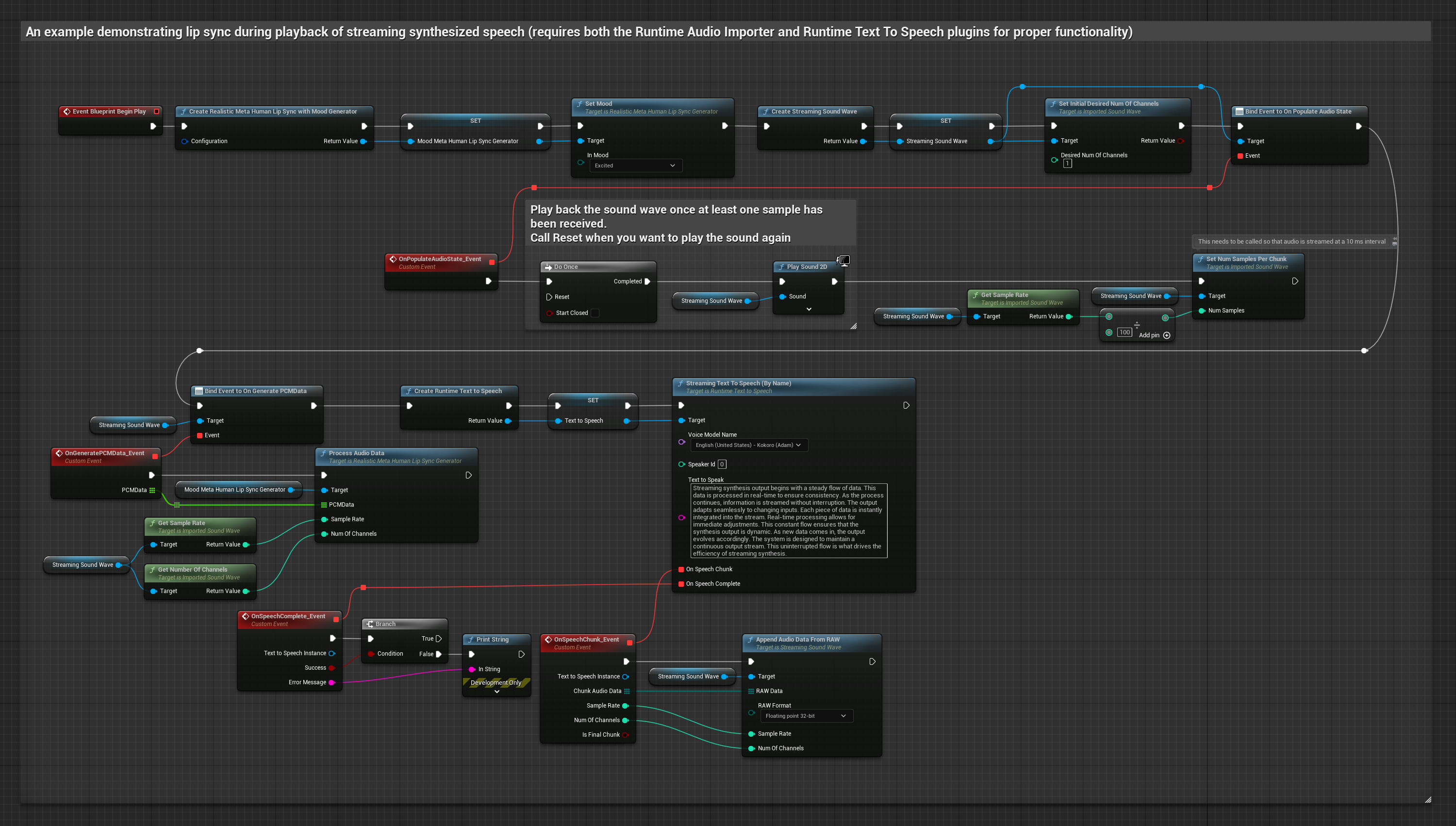
- Regular
- Transmisión en vivo
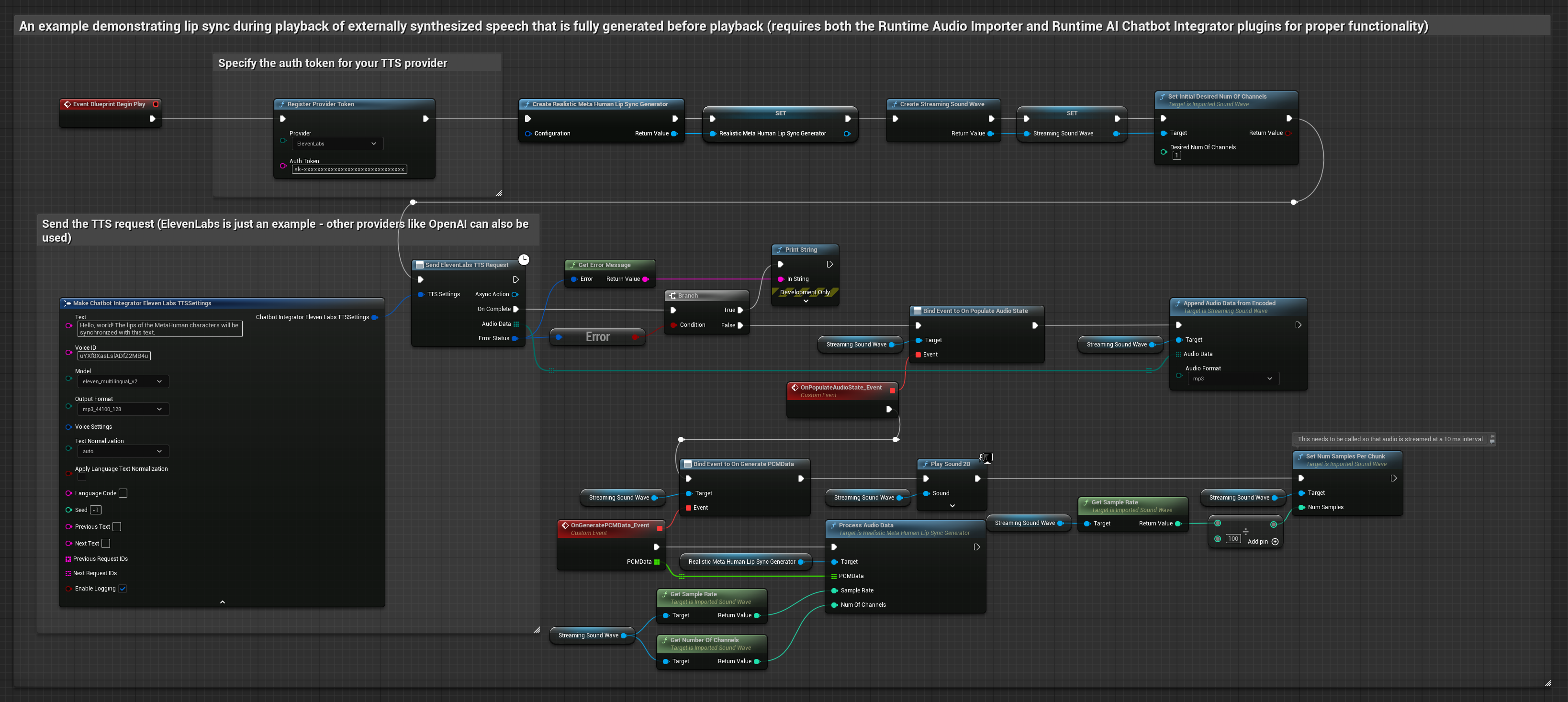
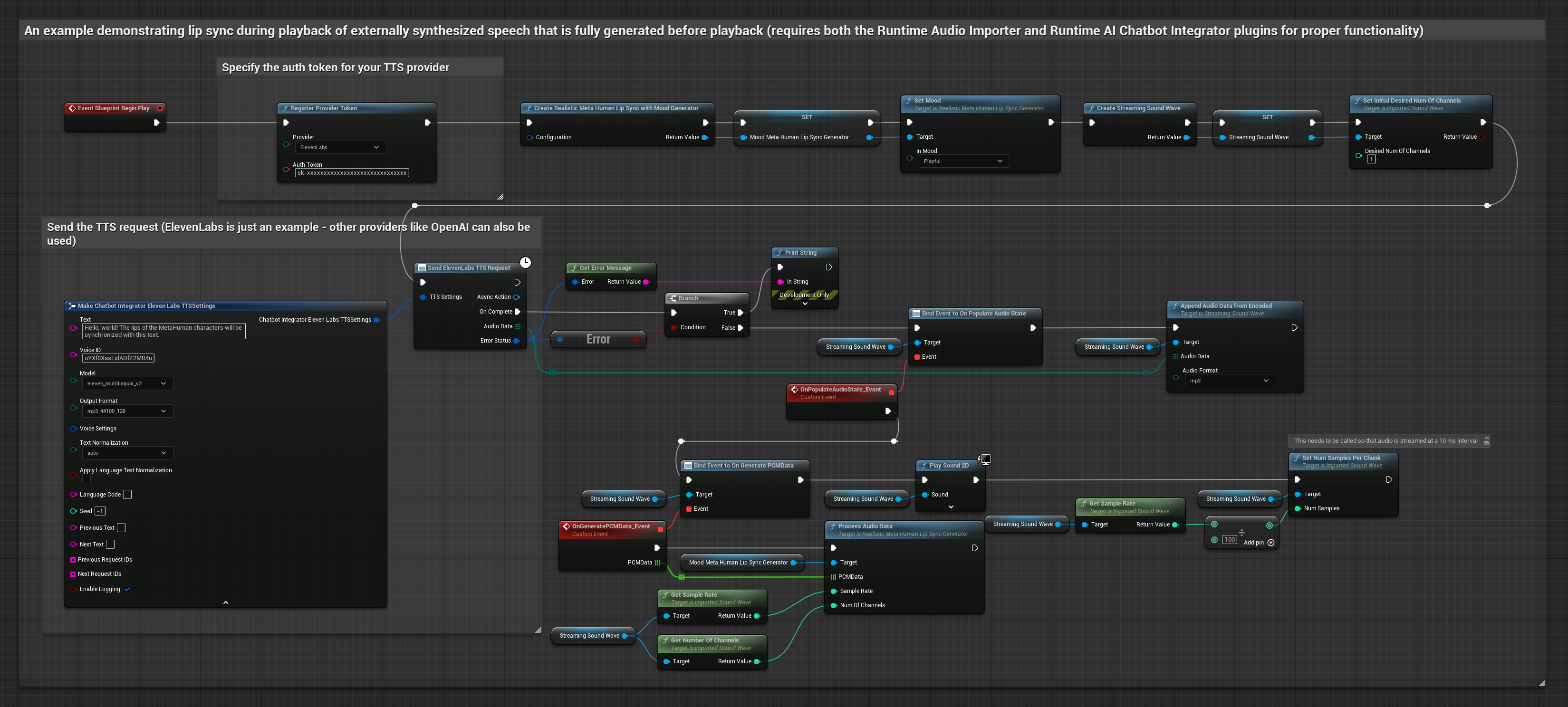
Este enfoque utiliza el plugin Runtime AI Chatbot Integrator para generar voz sintetizada a partir de servicios de IA (OpenAI o ElevenLabs) y realizar sincronización de labios:
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Usa Runtime AI Chatbot Integrator para generar voz a partir de texto usando APIs externas (OpenAI, ElevenLabs, etc.)
- Usa Runtime Audio Importer para importar los datos de audio sintetizados
- Antes de reproducir la onda de sonido importada, vincúlate a su delegado
OnGeneratePCMData - En la función vinculada, llama a
ProcessAudioDatadesde tu Generador de Visemas en Tiempo de Ejecución
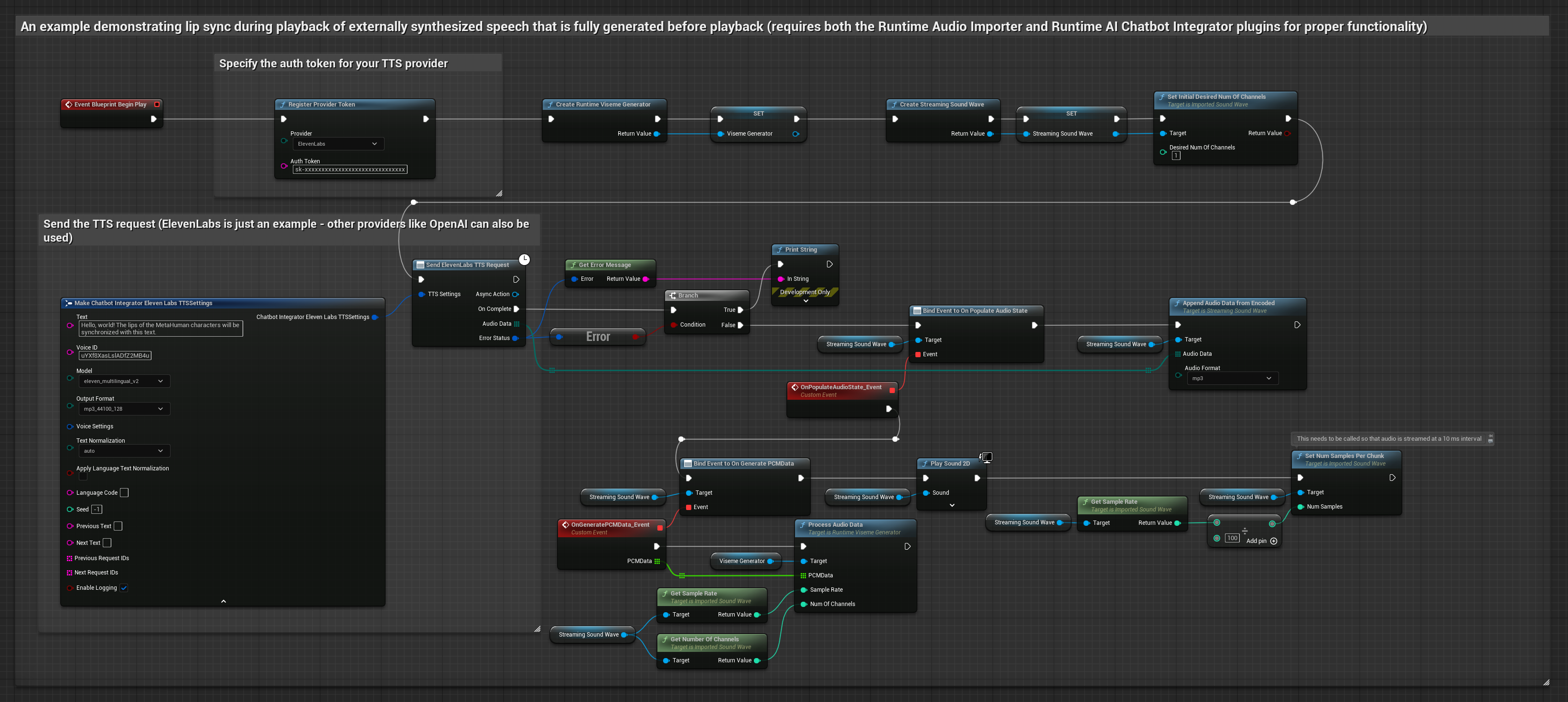
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
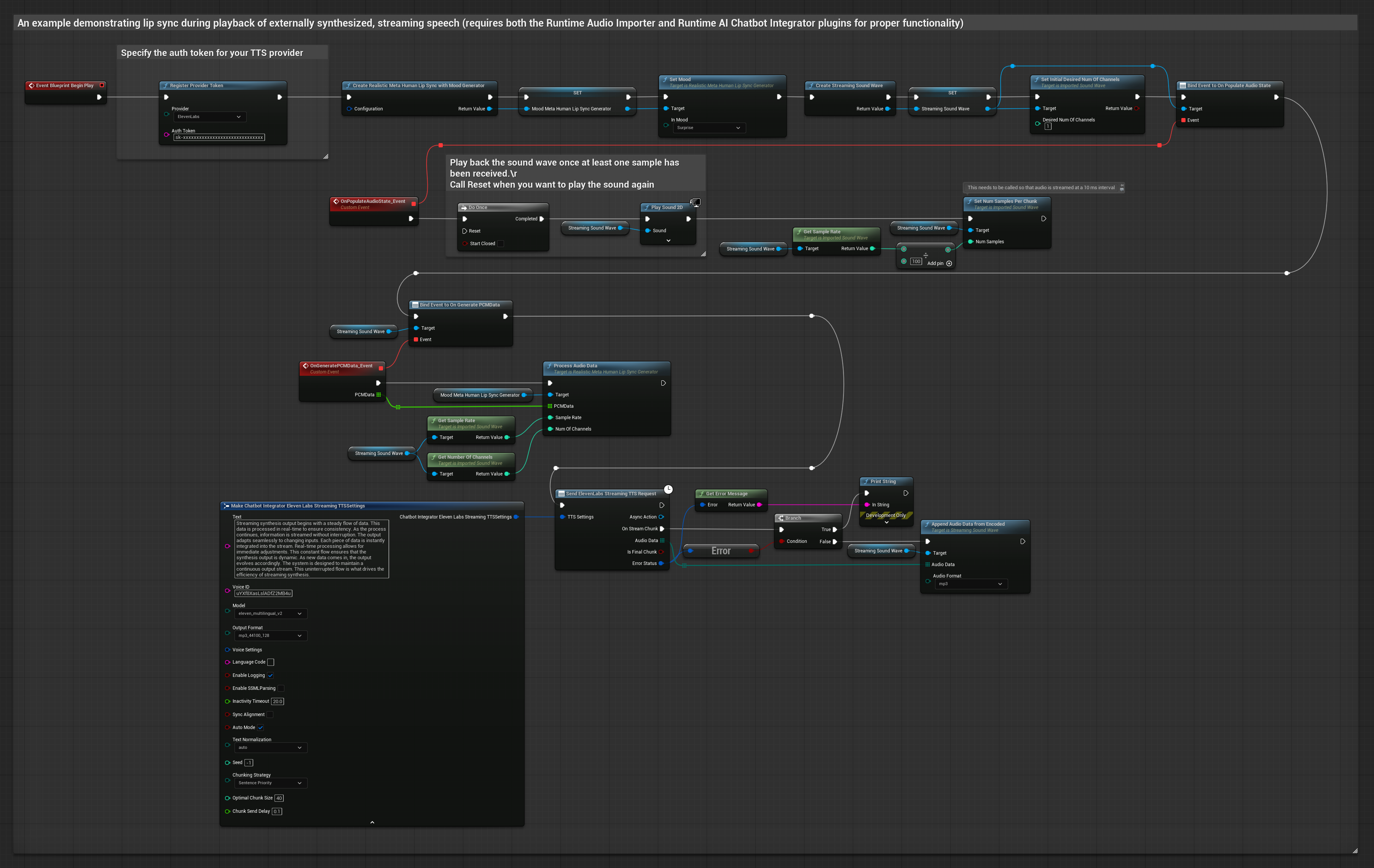
Este enfoque utiliza el plugin Runtime AI Chatbot Integrator para generar voz sintetizada en streaming desde servicios de IA (OpenAI o ElevenLabs) y realizar sincronización de labios:
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Usa Runtime AI Chatbot Integrator para conectarte a APIs de TTS en streaming (como la API de streaming de ElevenLabs)
- Usa Runtime Audio Importer para importar los datos de audio sintetizados
- Antes de reproducir la onda de sonido en streaming, vincúlate a su delegado
OnGeneratePCMData - En la función vinculada, llama a
ProcessAudioDatadesde tu Generador de Visemas en Tiempo de Ejecución
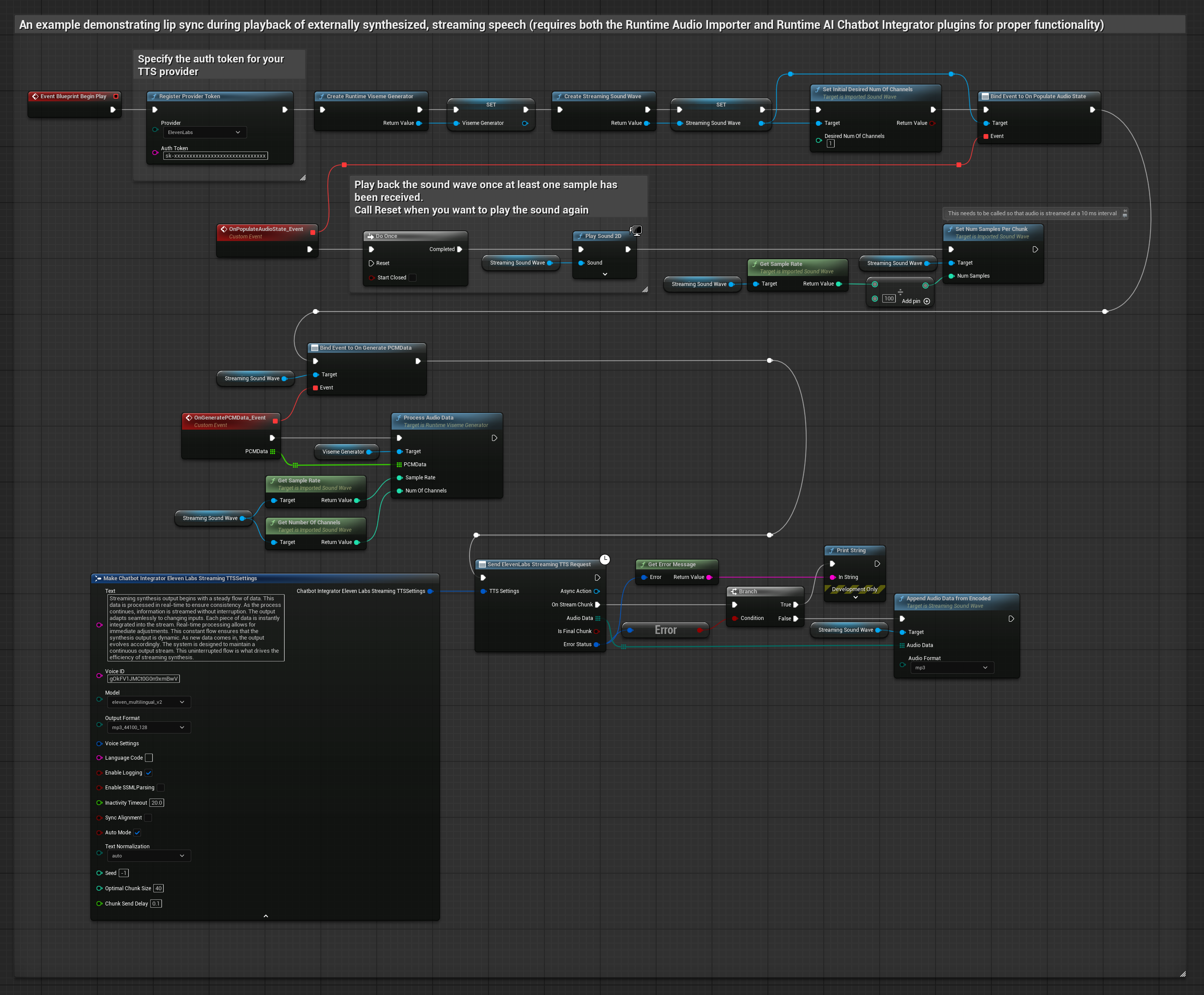
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
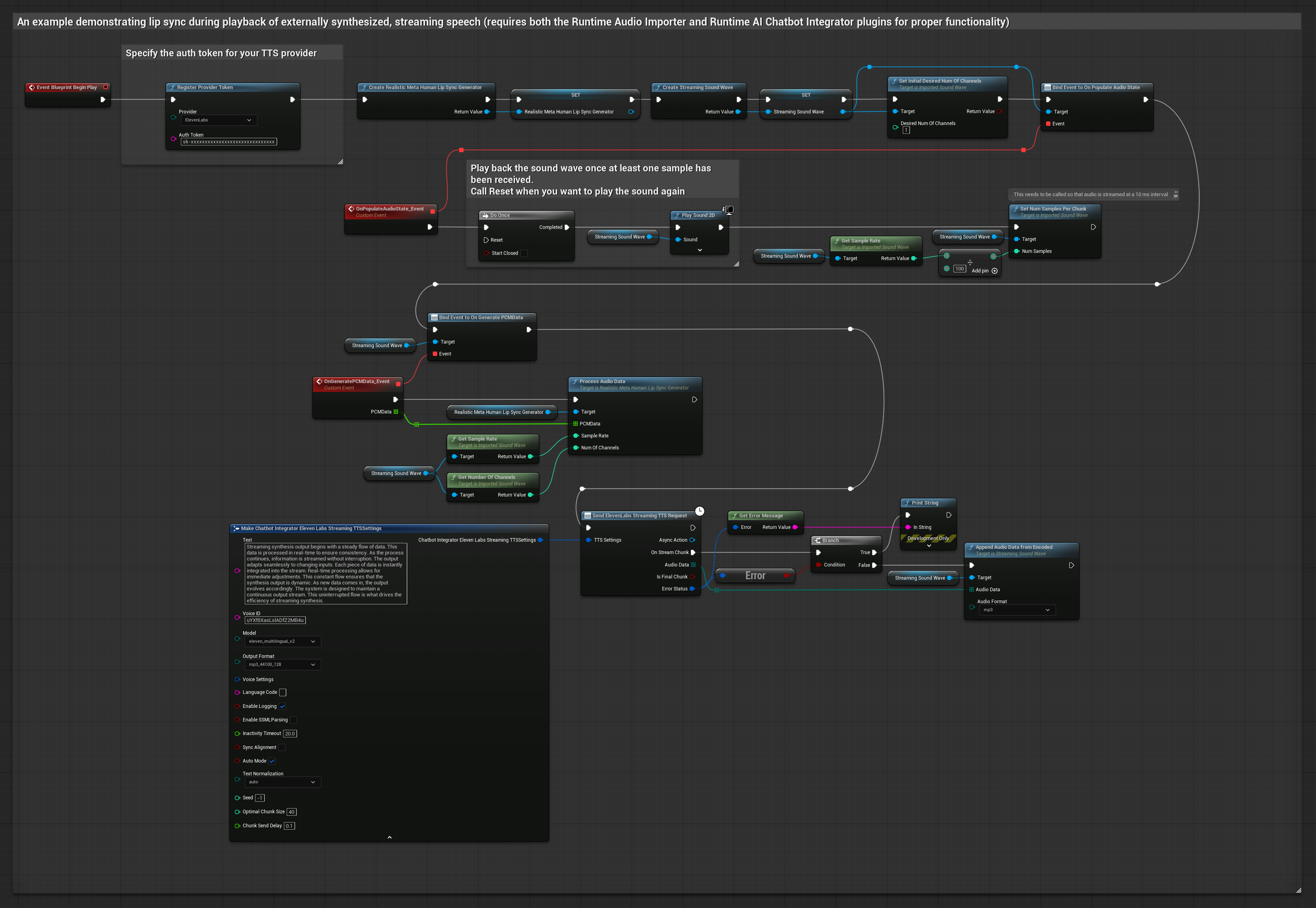
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
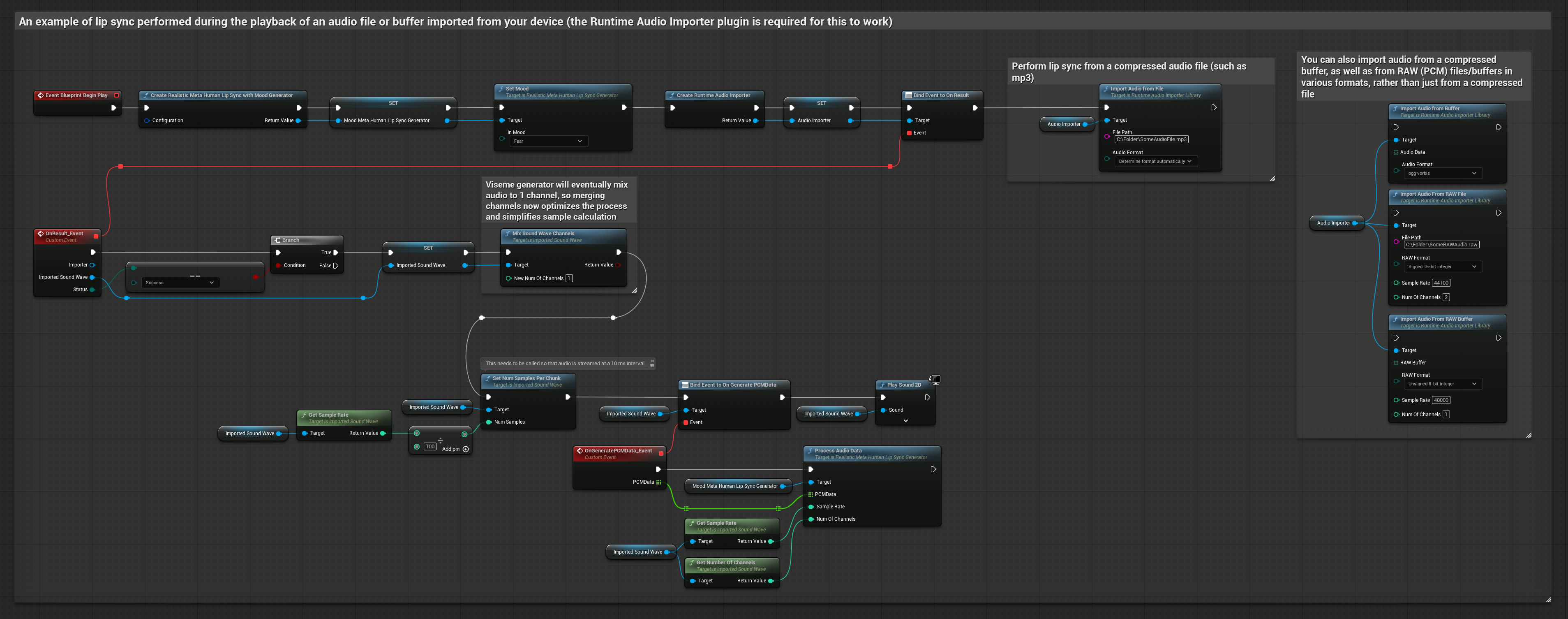
Este enfoque utiliza archivos de audio pregrabados o búferes de audio para la sincronización de labios:
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Usa Runtime Audio Importer para importar un archivo de audio desde el disco o la memoria
- Antes de reproducir la onda de sonido importada, vincúlate a su delegado
OnGeneratePCMData - En la función vinculada, llama a
ProcessAudioDatadesde tu Generador de Visemas en Tiempo de Ejecución - Reproduce la onda de sonido importada y observa la animación de sincronización de labios
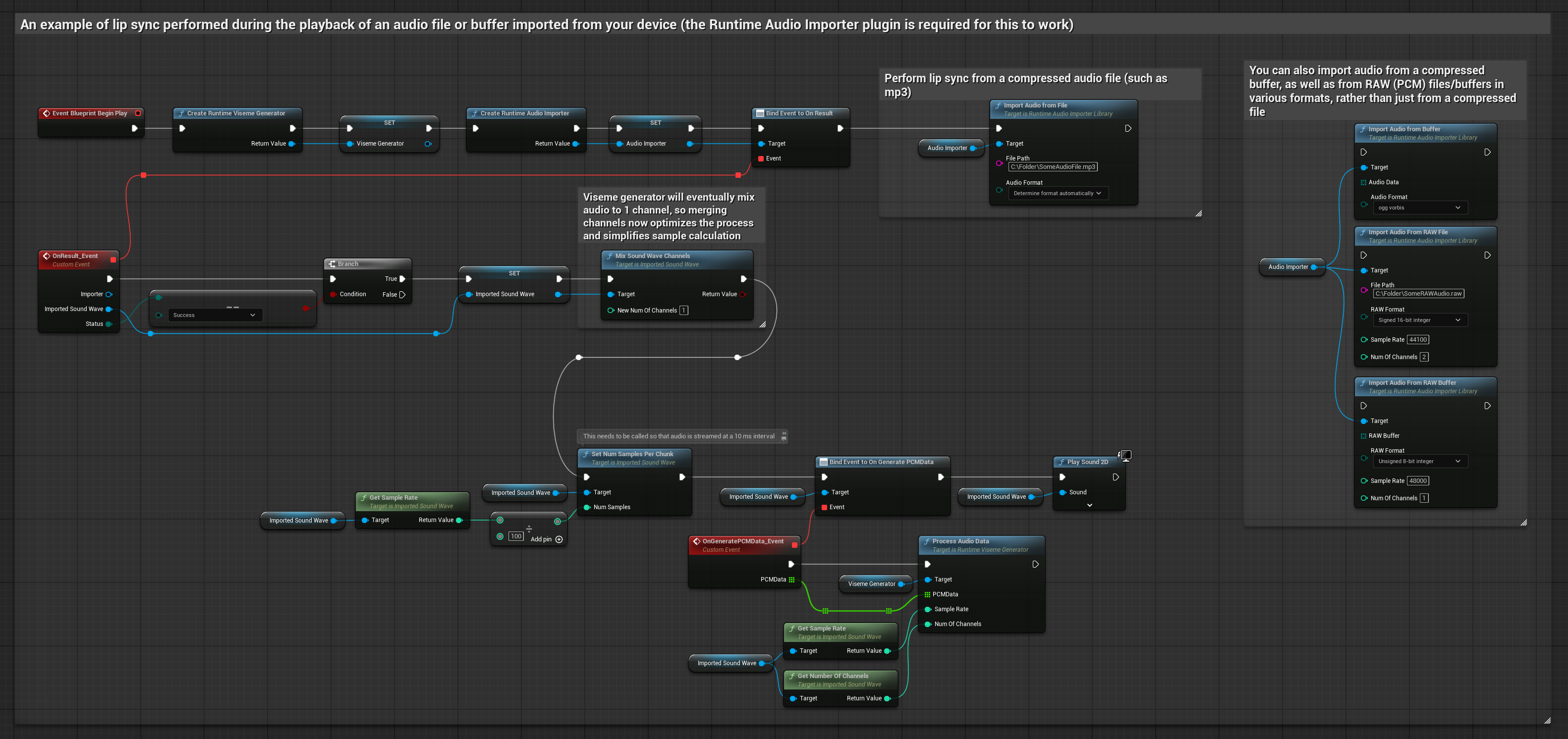
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
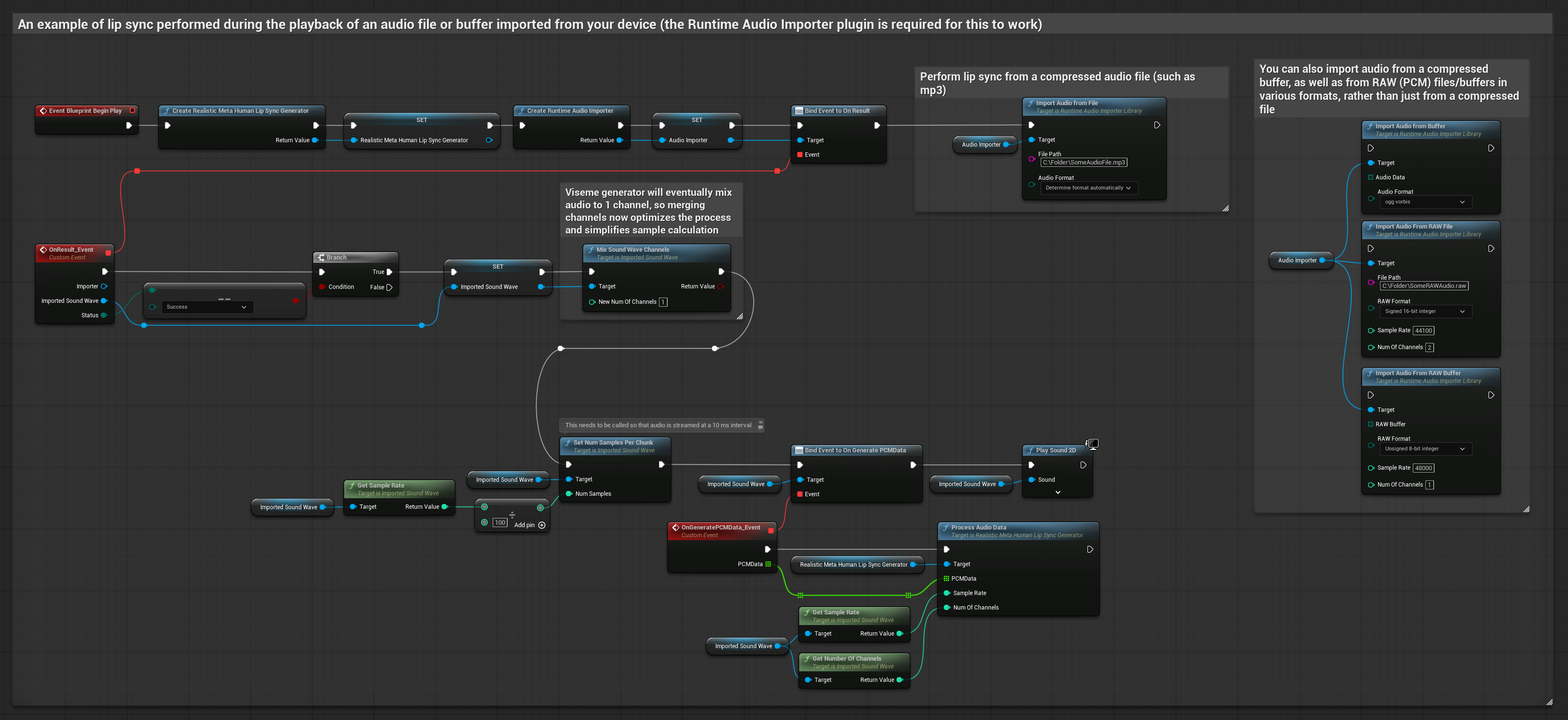
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
Para transmitir datos de audio desde un búfer, necesitas:
- Modelo Estándar
- Modelo Realista
- Modelo Realista con Estado de Ánimo
- Datos de audio en formato PCM flotante (un arreglo de muestras de punto flotante) disponibles desde tu fuente de transmisión (o usa Runtime Audio Importer para admitir más formatos)
- La frecuencia de muestreo y el número de canales
- Llama a
ProcessAudioDatadesde tu Runtime Viseme Generator con estos parámetros a medida que los fragmentos de audio estén disponibles
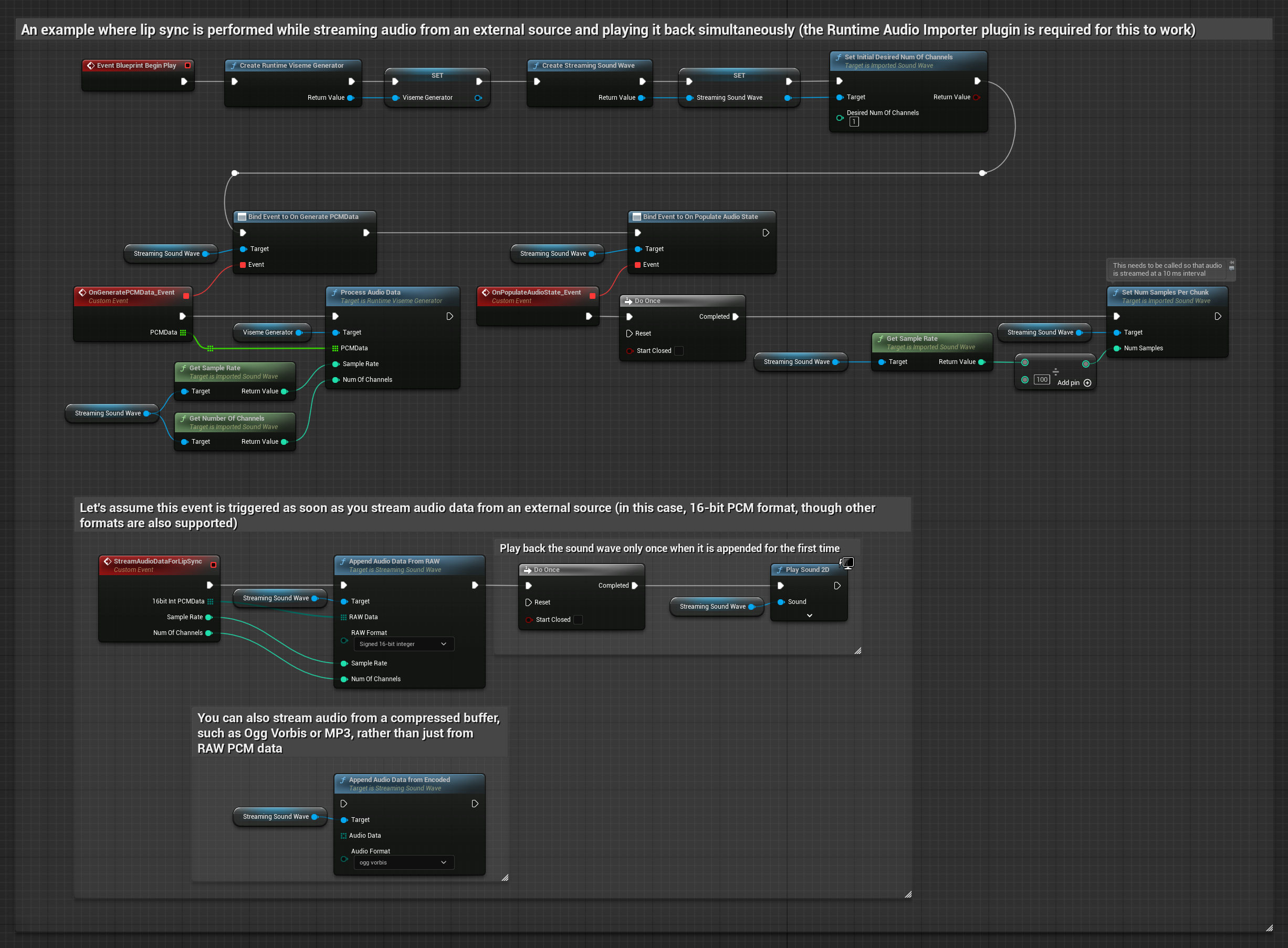
El Modelo Realista utiliza el mismo flujo de trabajo de procesamiento de audio que el Modelo Estándar, pero con la variable RealisticLipSyncGenerator en lugar de VisemeGenerator.
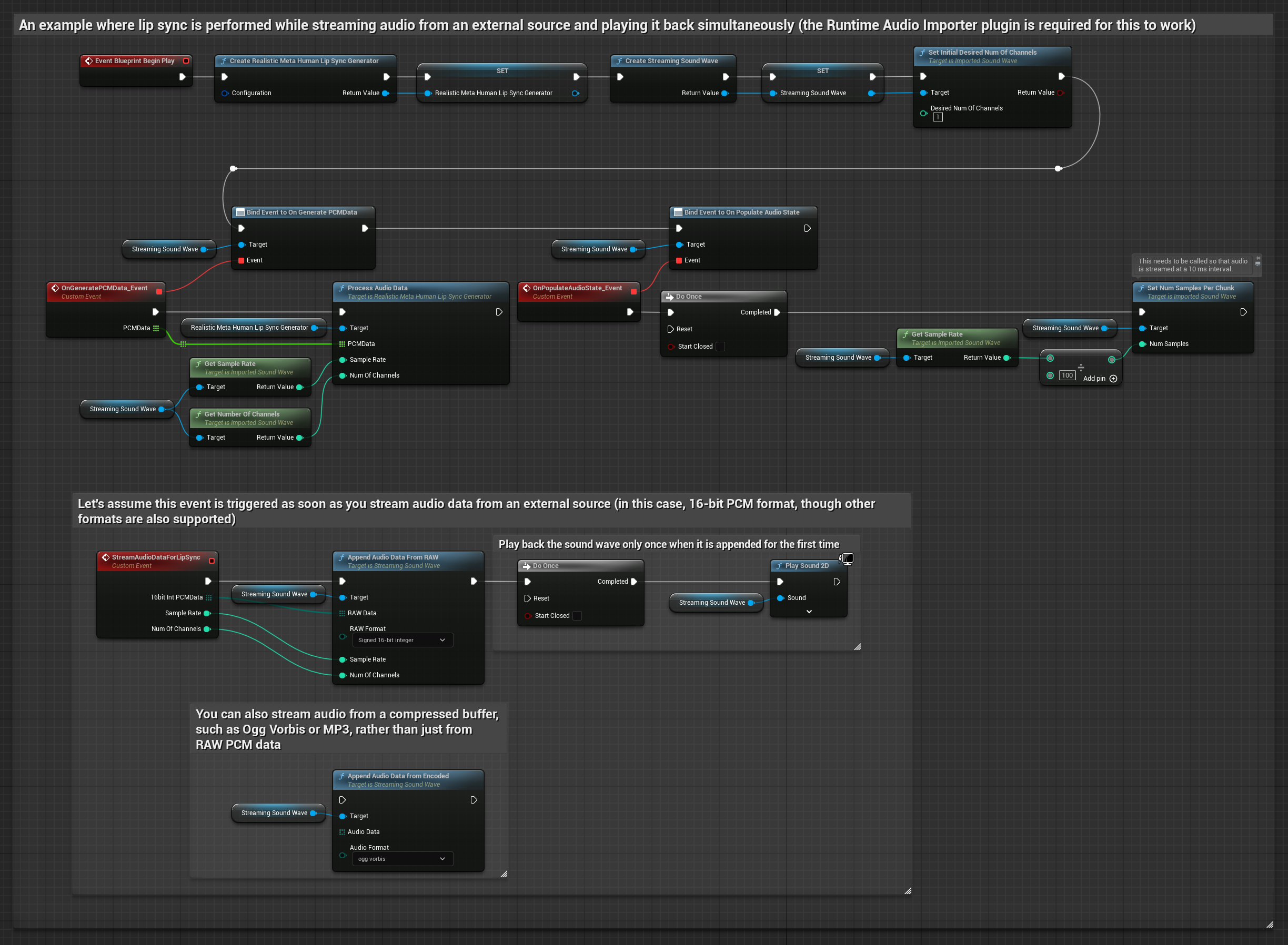
El modelo habilitado para estados de ánimo utiliza el mismo flujo de trabajo de procesamiento de audio, pero con la variable MoodMetaHumanLipSyncGenerator y capacidades adicionales de configuración de estados de ánimo.
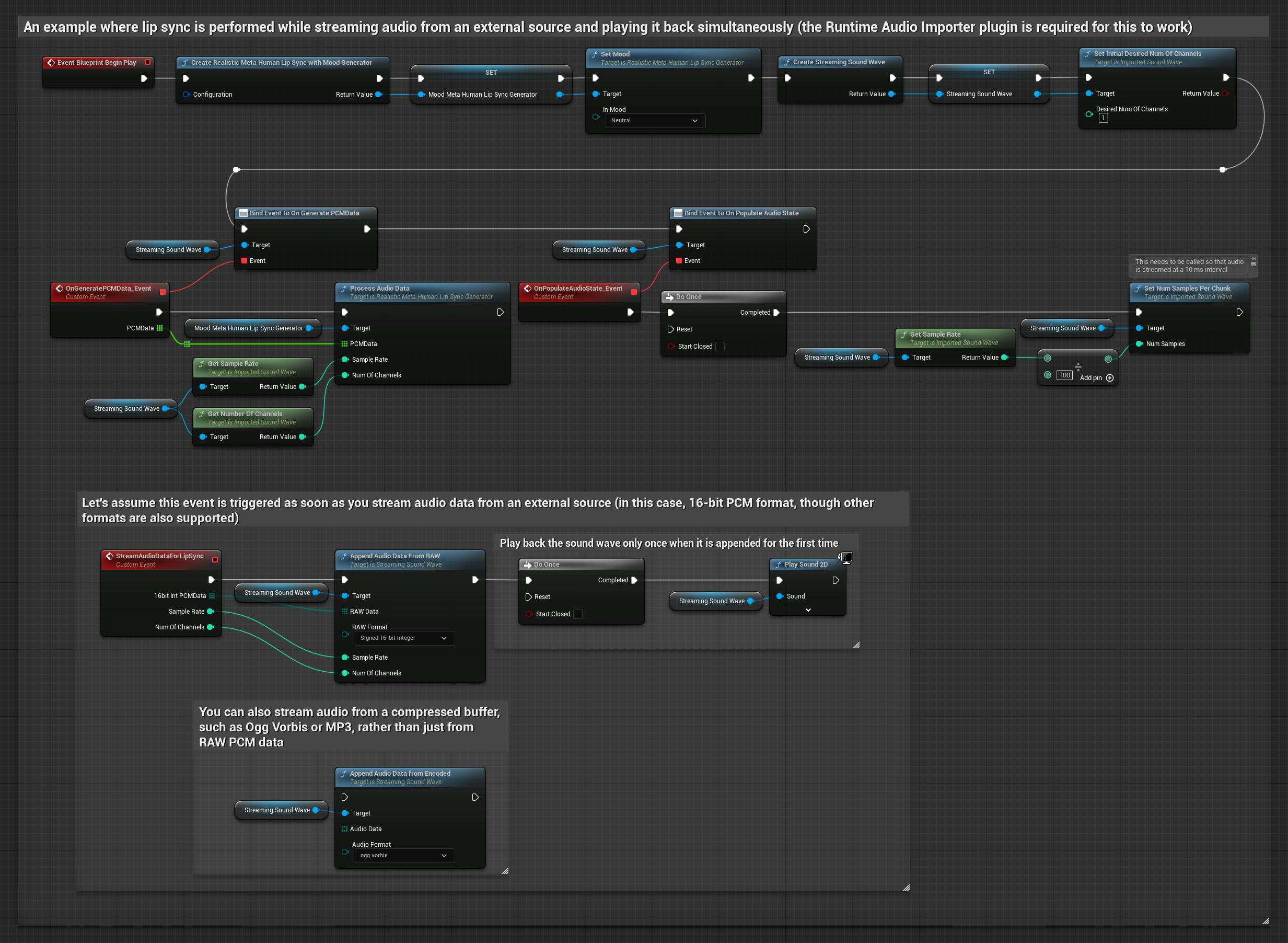
Nota: Al usar fuentes de audio en streaming, asegúrate de gestionar adecuadamente la sincronización de la reproducción de audio para evitar una reproducción distorsionada. Consulta la documentación de Streaming Sound Wave para obtener más información.
Consejos de rendimiento de procesamiento
-
Tamaño de Fragmento: Aumentar la opción de configuración
ProcessingChunkSize(https://docs.georgy.dev/runtime-metahuman-lip-sync/plugin-configuration#processing-chunk-size) (por ejemplo, a 320, 480 o 640 muestras) puede mejorar notablemente la latencia con un impacto mínimo en la calidad o la capacidad de respuesta. -
Tipo de modelo: Al usar modelos realistas, cambiar al tipo de modelo altamente optimizado (seleccionado por defecto) puede mejorar el rendimiento. Tenga en cuenta que el modelo original puede producir una calidad ligeramente mejor, especialmente con audio ruidoso.
-
Gestión de Búfer: El modelo habilitado para estados de ánimo procesa el audio en tramas de 320 muestras (20 ms a 16 kHz). Asegúrese de que la sincronización de su entrada de audio se alinee con esto para un rendimiento óptimo.
-
Recreación del generador: Para un funcionamiento fiable con modelos realistas, recrea el generador cada vez que quieras introducir nuevos datos de audio tras un período de inactividad. Consulta Recreación del generador en la sección de Solución de problemas para obtener una explicación.
Próximos pasos
Una vez que tengas configurado el procesamiento de audio, es posible que desees:
- Aprende sobre las opciones de configuración para ajustar el comportamiento de sincronización de labios
- Agrega animación de risa para una mayor expresividad
- Combina la sincronización de labios con animaciones faciales existentes utilizando las técnicas de capas descritas en la guía de configuración