Proyectos de demostración
Para ayudarte a comenzar rápidamente con Runtime MetaHuman Lip Sync, hay dos proyectos demo listos para usar. Ambos están creados con Unreal Engine 5.6+, son Blueprint-only y funcionan multiplataforma en Windows, Mac, Linux, iOS, Android y plataformas basadas en Android (incluyendo Meta Quest).
Proyectos de demostración disponibles
- NPC Conversacional de IA / Avatar Interactivo
- Demostración básica de sincronización de labios
Un flujo de trabajo completo de avatar conversacional con IA que combina reconocimiento de voz, un chatbot de IA (LLM), texto a voz y reproducción de audio con sincronización de labios en tiempo real, todo funcionando junto en un solo proyecto. Adecuado para una amplia gama de casos de uso, incluidos juegos, quioscos interactivos, producción virtual, instalaciones en museos, asistentes digitales y simulaciones de entrenamiento.
Resumen del Pipeline
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Cuando el LLM está configurado en modo Streaming, su salida se divide oración por oración y se envía a TTS a medida que cada oración se completa, en lugar de esperar la respuesta completa, para minimizar la latencia.
Videos
Vista previa rápida (~30 seg)
Una breve demostración del demo en acción.
Guía completa
Un recorrido detallado que cubre la configuración, el ajuste y el pipeline conversacional completo.
Descargas
Complementos Requeridos y Opcionales
El proyecto de demostración es modular; solo necesitas los complementos para los proveedores que quieras usar.
| Complemento | Propósito | ¿Requerido? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animación de sincronización de labios | Siempre |
| Runtime Audio Importer | Captura y procesamiento de audio | Siempre |
| Runtime Speech Recognizer | Reconocimiento de voz sin conexión (whisper.cpp) | Siempre |
| Runtime AI Chatbot Integrator | LLMs externos (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) y/o TTS externo (OpenAI, ElevenLabs) | 🔶 Opcional |
| Runtime Local LLM | Inferencia de LLM local mediante llama.cpp (modelos Llama, Mistral, Gemma, etc., GGUF) | 🔶 Opcional |
| Runtime Text To Speech | TTS local mediante Piper y Kokoro | 🔶 Opcional |
Si bien cada complemento anterior es opcional de forma individual, necesitas al menos un proveedor de LLM y al menos un proveedor de TTS para que la demostración funcione. Combínalos libremente (por ejemplo, LLM local + TTS de ElevenLabs, o LLM de OpenAI + TTS local).
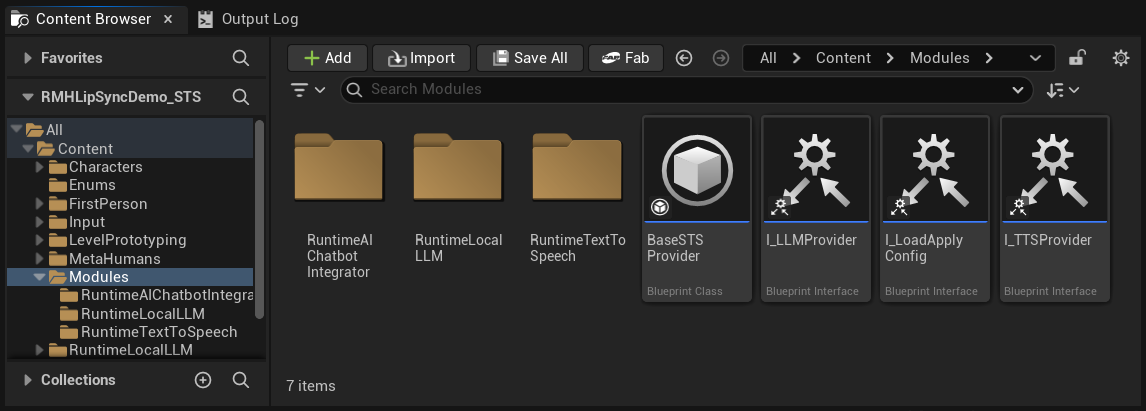
Arquitectura Modular
En la carpeta Content encontrarás una carpeta Modules que contiene tres subcarpetas:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Si no adquiriste uno (o más) de los complementos opcionales, simplemente elimina la(s) carpeta(s) correspondiente(s). Los activos base del proyecto de demostración (instancia de juego, widgets, etc.) no hacen referencia directa a estos módulos, por lo que eliminarlos no causará errores de referencia de activos. La interfaz de configuración ocultará automáticamente cualquier proveedor cuya carpeta falte.
Esta modularidad aplica solo a los proveedores de LLM y TTS. Speech Recognition (Runtime Speech Recognizer) y Lip Sync (Runtime MetaHuman Lip Sync) son parte del proyecto de demostración base y siempre son necesarios.
En el primer inicio, Unreal puede preguntar si desea deshabilitar los complementos opcionales faltantes; haga clic en Sí. Asegúrese también de haber eliminado la carpeta Content/Modules/ correspondiente (consulte arriba).
Diseño del Proyecto de Demostración
La interfaz de usuario que se muestra a continuación está construida completamente con UMG (Unreal Motion Graphics) y está destinada puramente a demostrar el flujo de trabajo: reconocimiento de voz → LLM → TTS → sincronización de labios. Eres libre de rediseñarla o reemplazarla para que coincida con el diseño visual, el esquema de control o la plataforma de tu proyecto (VR/AR, móvil, consola, quiosco, etc.). Si ciertos widgets no son necesarios en tu caso de uso, también puedes simplemente ocultarlos (por ejemplo, estableciendo su visibilidad en Collapsed o Hidden).

| Area | ¿Qué hay? |
|---|---|
| Centro | El personaje MetaHuman. |
| Lado izquierdo | Cuatro botones de configuración (Reconocimiento de Voz, Chatbot de IA, Texto a Voz, Animaciones), descritos en detalle a continuación. |
| Centro inferior | Un botón Iniciar grabación. Haz clic en él para comenzar una conversación por voz: se captura tu micrófono, se transcribe, se envía al LLM, la respuesta se sintetiza mediante TTS y se reproduce con sincronización de labios, completamente manos libres. |
| Centro derecho | Un widget de historial de conversación que muestra el intercambio completo entre usted y la IA (mensajes tanto del usuario como del asistente). También incluye un campo de entrada de texto, para que pueda escribir mensajes directamente sin usar reconocimiento de voz, útil para pruebas, accesibilidad o cuando no hay un micrófono disponible. |
Puedes mezclar ambos modos de entrada libremente en la misma sesión: di algunos mensajes, escribe otros.
Si el sincronismo de labios sigue desfasándose cada vez más del audio cuanto más tiempo pruebas (no solo un retraso fijo), consulta Tamaño del fragmento de procesamiento en Configurar animaciones a continuación.
Botones de Configuración
Los cuatro botones de configuración a la izquierda abren paneles dedicados para cada parte del proceso:
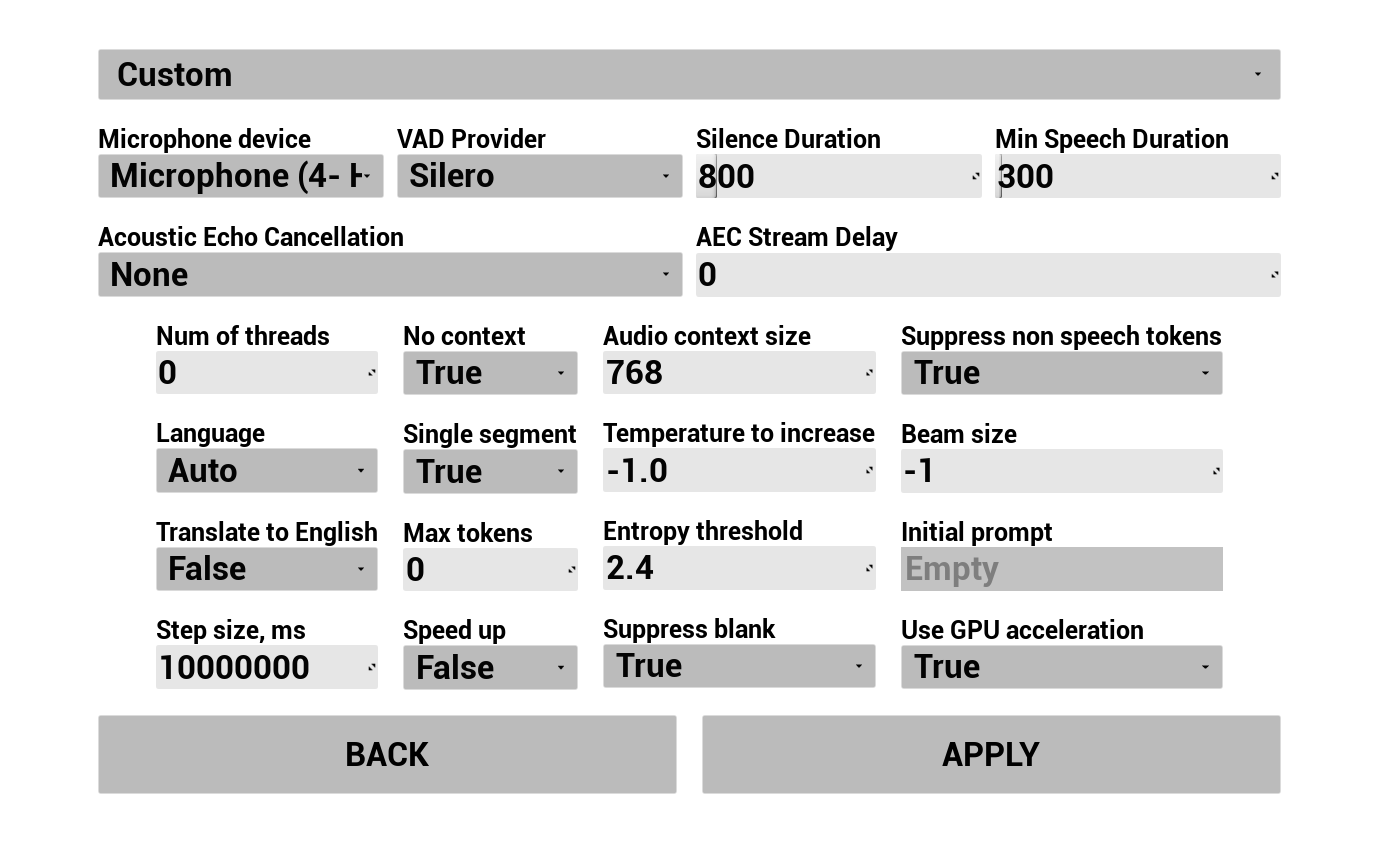
1. Configurar el Reconocimiento de Voz
Configura cómo se captura y transcribe la voz del usuario:
- Seleccionar idioma
- Ajustar parámetros de reconocimiento de voz (configuración del modelo Whisper)
- Configurar AEC (Cancelación de Eco Acústico)
- Configurar VAD (Detección de Actividad de Voz)
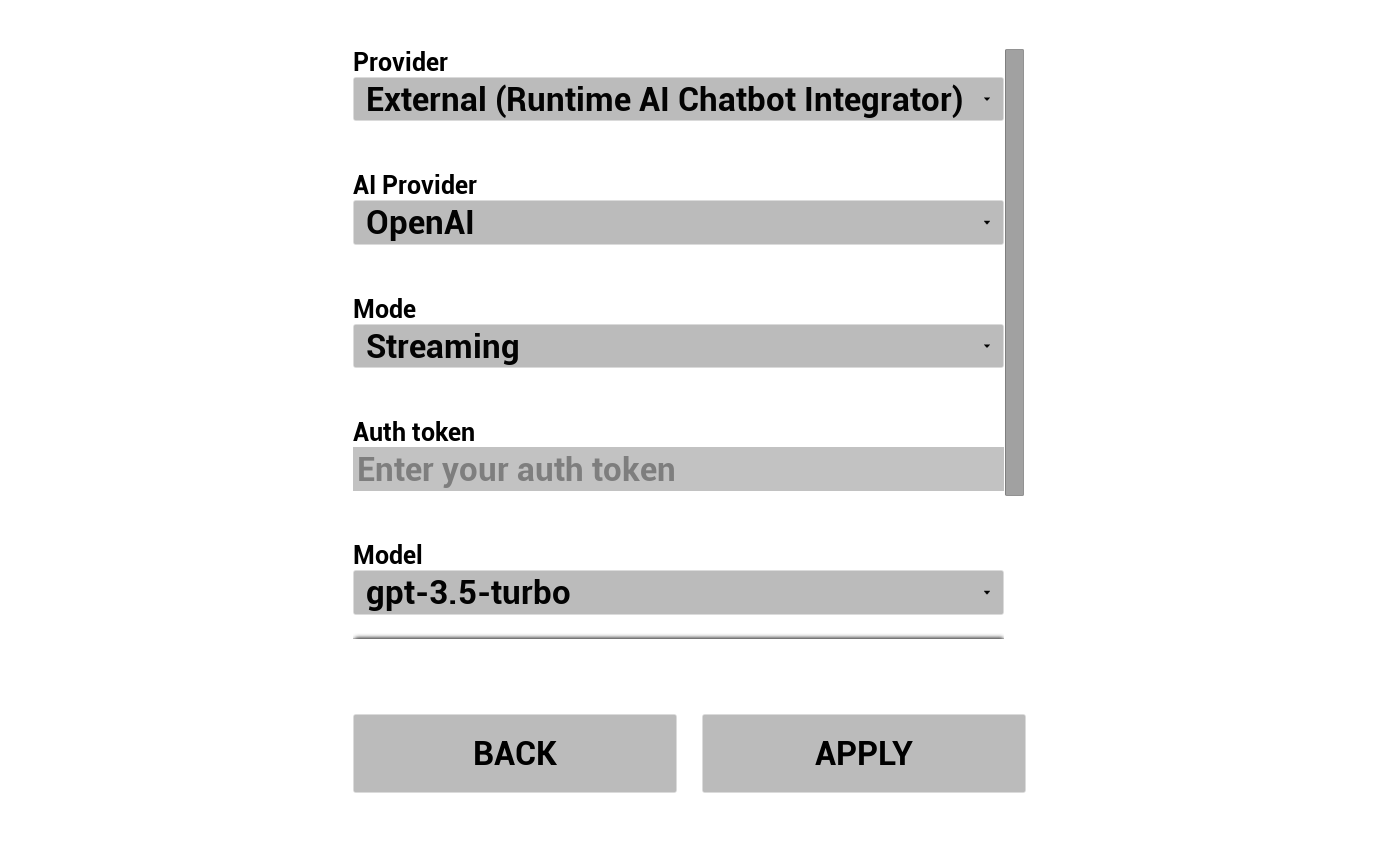
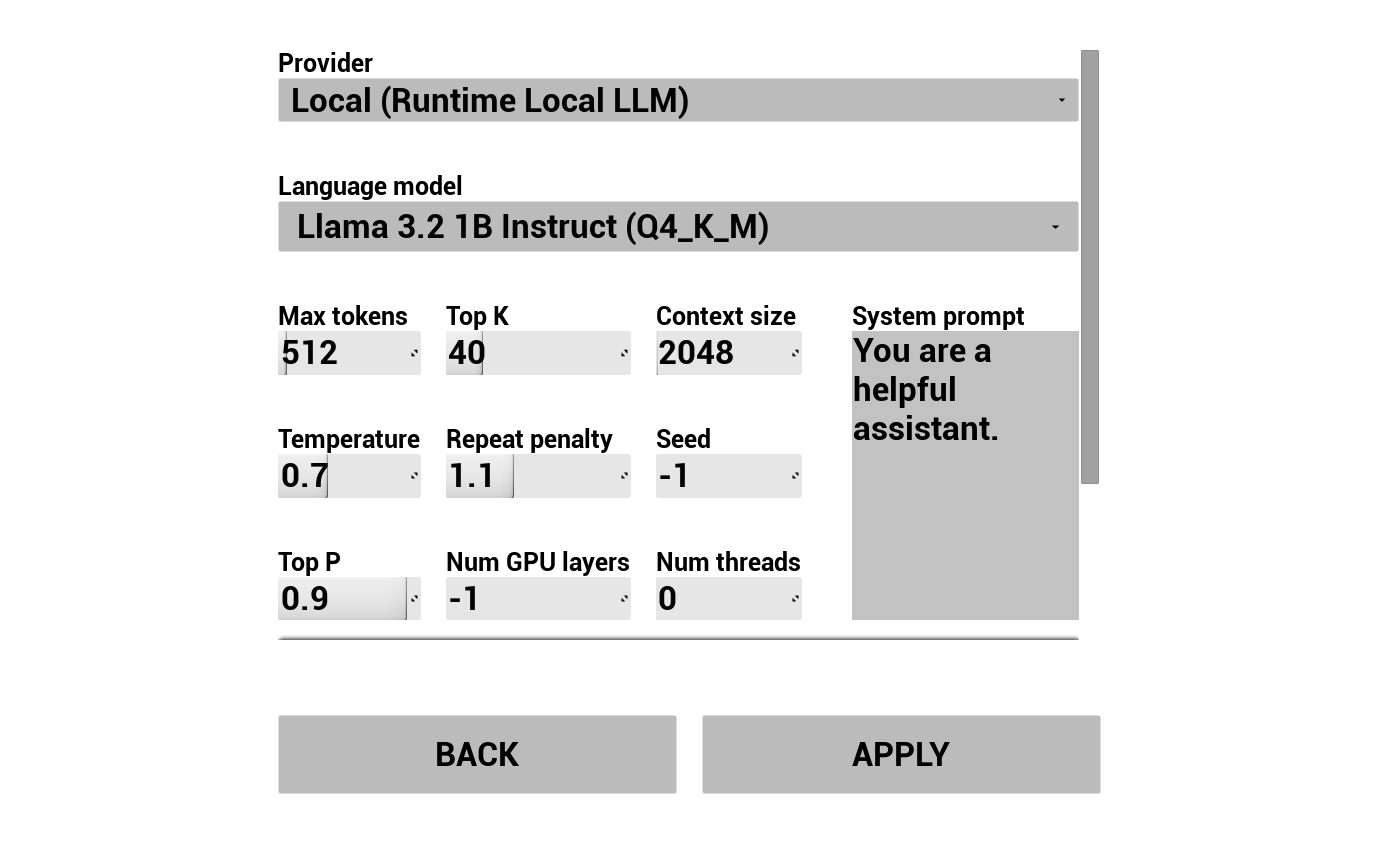
2. Configurar Chatbot de IA
Elige tu proveedor de LLM y configúralo:
- Selecciona proveedor (Runtime AI Chatbot Integrator o Runtime Local LLM)
- Selecciona modo: Regular o Streaming (depende del proveedor, Streaming permite la transferencia de TTS frase por frase, consulta Resumen del Pipeline)
- Para proveedores externos: token de autenticación, nombre del modelo, etc.
- Para LLM local: selecciona un modelo GGUF, establece el tamaño de contexto y otros parámetros de inferencia. También puedes descargar tu propio modelo GGUF en tiempo de ejecución directamente desde el demo (por ejemplo, mediante URL) y usarlo de inmediato sin necesidad de reconstruir el proyecto.
El cuadro combinado de proveedores solo muestra aquellos proveedores cuya carpeta de módulo del plugin está presente en Content/Modules/.
3. Configurar Texto a Voz
Elige tu proveedor de TTS y configura las voces/modelos:
- Selecciona el proveedor (Runtime AI Chatbot Integrator para OpenAI/ElevenLabs, o Runtime Text To Speech para Piper/Kokoro local)
- Selecciona el modo: Normal o Streaming (controla si el audio se devuelve de una vez o mientras se sintetiza)
- Selecciona la voz/modelo
- Ajusta los parámetros específicos del proveedor

4. Configurar Animaciones
Controla los aspectos visuales de tu avatar de IA:
- Elige entre 3 personajes MetaHuman pre-descargados (Aera, Ada, Orlando)
- Selecciona el modelo de sincronización labial (Estándar o Realista)
- Selecciona el tipo de modelo de sincronización labial - Altamente optimizado, Semi-optimizado u Original (consulta Tipo de modelo)
- Ajusta el Tamaño del fragmento de procesamiento - controla la frecuencia con la que se ejecuta la inferencia de sincronización labial (consulta Tamaño del fragmento de procesamiento)
- Si el sincronismo de labios se retrasa más con respecto al audio con el tiempo bajo carga de la CPU, aumenta esto a 480 o 640.
- Selecciona una animación de reposo para reproducir en el MetaHuman durante la conversación.

Preconfiguración de la demostración en el Editor
Al trabajar con la versión fuente, puedes predefinir valores predeterminados directamente en el editor para que no sea necesario volver a ingresarlos en cada ejecución:
| What | Dónde |
|---|---|
| Configuración general (modelo de sincronización labial, animación en reposo, clase de personaje, reconocimiento de voz, etc.) | Content/LipSyncSTSGameInstance |
| Configuración de LLM externo / TTS externo (Integrador de chatbot de IA en tiempo real) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Configuración de LLM local (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Configuración de TTS Local (Texto a Voz en Tiempo de Ejecución) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Notas multiplataforma
Todos los complementos utilizados por la demo son compatibles con Windows, Mac, Linux, iOS, Android y plataformas basadas en Android (incluyendo Meta Quest), por lo que el proyecto de demostración también funciona en todas ellas. Esto lo hace adecuado para su implementación en una amplia variedad de entornos, desde juegos y quioscos de escritorio hasta aplicaciones móviles, cascos de realidad virtual independientes y configuraciones de producción virtual en el set.
Para dispositivos más débiles (móviles, VR independiente), es posible que desees:
- Usa el modelo de sincronización labial estándar en lugar de Realista; consulta la Comparación de modelos
- Cambia al tipo de modelo Altamente optimizado
- Aumenta el Tamaño del fragmento de procesamiento para reducir la carga de la CPU
- Elige modelos LLM / TTS más pequeños
Consulte la Configuración específica de la plataforma para conocer los pasos de configuración adicionales en Android, iOS, Mac y Linux.
Soporte para Pixel Streaming
Implementación de la demo en Pixel Streaming (clic para expandir)
El proyecto de demostración de IA conversacional también funciona en un entorno de Pixel Streaming, lo que permite transmitir el avatar de MetaHuman a un cliente remoto (por ejemplo, un navegador web) mientras se captura el audio del micrófono del usuario desde el lado del cliente. Solo se requiere un único cambio en la demostración.
1. Instala la extensión Pixel Streaming para Runtime Audio Importer
El plugin Runtime Audio Importer proporciona un plugin de extensión gratuito que permite capturar audio desde un cliente de Pixel Streaming. Dependiendo de la versión de la infraestructura de Pixel Streaming que estés utilizando, instala uno de los siguientes:
- Extensión de Pixel Streaming (para el plugin original de Pixel Streaming), o
- Extensión de Pixel Streaming 2 (para el plugin más reciente de Pixel Streaming 2)
Los enlaces de descarga y los pasos de instalación están disponibles aquí: Instalación del Plugin de Extensión de Captura de Audio para Pixel Streaming.
2. Intercambia el nodo de onda de sonido capturable en LipSyncSTSGameInstance
Después de que el plugin de extensión esté instalado:
- En el Navegador de Contenido, navega a
/All/Gamey abre el activoLipSyncSTSGameInstance. - Cambia al Gráfico de Eventos.
- Localiza Event Init y sigue el flujo de ejecución hasta que encuentres el par de nodos:
Create Capturable Sound Wave→Set Capturable Sound Wave. - Reemplaza la llamada a
Create Capturable Sound WaveporCreate Pixel Streaming Capturable Sound WaveoCreate Pixel Streaming 2 Capturable Sound Wave, dependiendo de la versión de la infraestructura de Pixel Streaming a la que te estés dirigiendo. - Conecta su salida al mismo nodo
Set Capturable Sound Wave.
Después de esto, el proyecto está listo para ser implementado en Pixel Streaming: el reconocimiento de voz, el LLM, el TTS y la sincronización de labios funcionarán igual que antes, pero con el audio capturado desde el cliente remoto en lugar de un micrófono local.
Trayendo tu propio personaje
El proyecto de demostración incluye tres personajes MetaHuman de muestra (Aera, Ada, Orlando), pero puedes importar tu propio MetaHuman y usarlo en la demostración.
📺 Tutorial en video: Agregar un personaje MetaHuman personalizado al proyecto de demostración
El plugin Runtime MetaHuman Lip Sync en sí mismo admite muchos otros sistemas de personajes más allá de MetaHumans (personajes basados en ARKit, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe, etc. - consulte la Guía de configuración de personajes personalizados). Ya sea que estés creando un NPC de juego, un presentador virtual, un asistente de quiosco o un humano digital para producción virtual, el plugin se adapta a tu flujo de trabajo de personajes.
Un proyecto de demostración más simple que se centra puramente en la función de sincronización de labios en sí misma, sin el flujo de trabajo completo de conversación con IA. Adecuado si solo quieres ver la sincronización de labios en acción con varias fuentes de audio.
Vídeo destacado
Descargas
Qué está incluido
Esta demostración muestra los flujos de trabajo básicos de sincronización de labios:
- Entrada de micrófono - sincronización de labios en tiempo real desde audio en vivo
- Reproducción de archivos de audio - sincronización de labios desde archivos de audio importados
- Texto a Voz - sincronización de labios impulsada por voz sintetizada
Complementos Requeridos y Opcionales
| Complemento | Propósito | ¿Requerido? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animación de sincronización de labios | ✅ Requerido |
| Runtime Audio Importer | Importación y captura de audio | ✅ Requerido |
| Runtime Text To Speech | TTS local para la escena de demostración de TTS | 🔶 Opcional |
| Runtime AI Chatbot Integrator | Proveedores de TTS externos (OpenAI, ElevenLabs) | 🔶 Opcional |
Notas para el modelo estándar de sincronización de labios
Si planeas usar el Modelo Estándar (en lugar del Realista) en cualquiera de los proyectos de demostración, deberás instalar el plugin de Extensión de Sincronización Labial Estándar. Consulta Extensión del Modelo Estándar para obtener instrucciones de instalación.
¿Necesitas ayuda?
Si tienes algún problema al configurar o ejecutar los proyectos de demostración, no dudes en contactarnos:
Para solicitudes de desarrollo personalizado (por ejemplo, ampliar la demo con tu propia lógica, adaptarla para una plataforma o flujo de personajes específico), contacta a [email protected].