Configuración del Plugin
Configuración del modelo
Para un funcionamiento confiable con los modelos Realista y Realista con Control de Estado de Ánimo, recrea el generador antes de cada nueva reproducción de audio en lugar de reutilizarlo durante silencios prolongados. Consulta Recreación del Generador en Solución de Problemas para más detalles.
Configuración del Modelo Estándar
El nodo Create Runtime Viseme Generator utiliza configuraciones predeterminadas que funcionan bien para la mayoría de los escenarios. La configuración se maneja a través de las propiedades del nodo de mezcla del Animation Blueprint.
Para las opciones de configuración del Animation Blueprint, consulta la sección Configuración de Lip Sync a continuación.
Configuración de Modelo Realista
El nodo Create Realistic MetaHuman Lip Sync Generator acepta un parámetro opcional de Configuración que te permite personalizar el comportamiento del generador:
Tipo de modelo
La configuración de Tipo de Modelo determina qué versión del modelo realista utilizar:
| Tipo de modelo | Rendimiento | Calidad Visual | Manejo de Ruido | Casos de uso recomendados |
|---|---|---|---|---|
| Altamente optimizado (Predeterminado) | Máximo rendimiento, menor uso de CPU | Buena calidad | Puede mostrar movimientos notables de la boca con ruido de fondo o sonidos no vocales. | Entornos de audio limpios, escenarios críticos de rendimiento |
| Semi-Optimizado | Buen rendimiento, uso moderado de CPU | Alta calidad | Mayor estabilidad con audio ruidoso | Rendimiento y calidad equilibrados, condiciones de audio mixtas |
| Original | Adecuado para uso en tiempo real en CPUs modernas | La más alta calidad | Más estable con ruido de fondo y sonidos no vocales. | Producciones de alta calidad, entornos de audio ruidosos, cuando se necesita la máxima precisión |
Configuraciones de rendimiento
Intra Op Threads: Controla el número de hilos utilizados para las operaciones internas de procesamiento del modelo.
- 0 (Predeterminado/Automático): Usa detección automática (normalmente 1/4 de los núcleos de CPU disponibles, máximo 4)
- 1-16: Especifica manualmente el número de hilos. Valores más altos pueden mejorar el rendimiento en sistemas multinúcleo, pero usan más CPU.
Inter Op Threads: Controla el número de hilos utilizados para la ejecución en paralelo de diferentes operaciones del modelo.
- 0 (Predeterminado/Automático): Usa detección automática (normalmente 1/8 de los núcleos de CPU disponibles, máximo 2)
- 1-8: Especifica manualmente el número de hilos. Generalmente se mantiene bajo para procesamiento en tiempo real
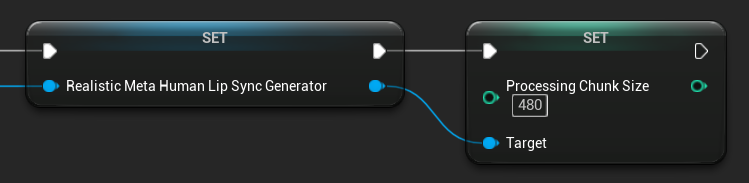
Tamaño del Fragmento de Procesamiento
El Tamaño del Fragmento de Procesamiento determina cuántas muestras se procesan en cada paso de inferencia. El valor predeterminado es 160 muestras (10 ms de audio a 16 kHz):
- Los valores más pequeños proporcionan actualizaciones más frecuentes pero aumentan el uso de la CPU
- Los valores más grandes reducen la carga de la CPU pero pueden disminuir la capacidad de respuesta de la sincronización de labios
- Se recomienda usar múltiplos de 160 para una alineación óptima
Configuración del modelo habilitado para estados de ánimo
El nodo Create Realistic MetaHuman Lip Sync With Mood Generator proporciona opciones de configuración adicionales más allá del modelo realista básico:
Configuración básica
Lookahead Ms: Tiempo de anticipación en milisegundos para mejorar la precisión de la sincronización de labios.
- Predeterminado: 80 ms
- Rango: 20 ms a 200 ms (debe ser divisible por 20)
- Los valores más altos proporcionan una mejor sincronización, pero aumentan la latencia.
Tipo de salida: Controla qué controles faciales se generan.
- Rostro Completo: Los 81 controles faciales (cejas, ojos, nariz, boca, mandíbula, lengua)
- Solo Boca: Únicamente los controles relacionados con la boca, mandíbula y lengua
Configuración de rendimiento: Utiliza los mismos ajustes de Hilos Intra Op e Hilos Inter Op que el modelo realista estándar.
Configuración de estado de ánimo
Estados de ánimo disponibles:
- Neutral, Happy, Sad, Disgust, Anger, Surprise, Fear
- Confident, Excited, Bored, Playful, Confused
Intensidad del estado de ánimo: Controla cuán fuertemente el estado de ánimo afecta la animación (0.0 a 1.0)
Control de Estado de Ánimo en Tiempo de Ejecución
Puede ajustar la configuración de estado de ánimo durante el tiempo de ejecución utilizando las siguientes funciones:
- Establecer Estado de Ánimo: Cambiar el tipo de estado de ánimo actual
- Establecer Intensidad del Estado de Ánimo: Ajustar cuán fuertemente el estado de ánimo afecta la animación (0.0 a 1.0)
- Establecer Lookahead Ms: Modificar el tiempo de anticipación para la sincronización
- Establecer Tipo de Salida: Cambiar entre controles de Rostro Completo y Solo Boca

Guía de Selección de Estado de Ánimo
Elige los estados de ánimo adecuados según tu contenido.
| Mood | Lo mejor para | Rango de Intensidad Típico |
|---|---|---|
| Neutral | Conversación general, narración, estado predeterminado | 0.5 - 1.0 |
| Feliz | Contenido positivo, diálogo alegre, celebraciones | 0.6 - 1.0 |
| Triste | Contenido melancólico, escenas emotivas, momentos sombríos | 0.5 - 0.9 |
| Asco | Reacciones negativas, contenido desagradable, rechazo | 0.4 - 0.8 |
| Enojo | Diálogo agresivo, escenas de confrontación, frustración | 0.6 - 1.0 |
| Sorpresa | Eventos inesperados, revelaciones, reacciones de shock | 0.7 - 1.0 |
| Miedo | Situaciones amenazantes, ansiedad, diálogo nervioso | 0.5 - 0.9 |
| Seguro | Presentaciones profesionales, diálogo de liderazgo, discurso asertivo | 0.7 - 1.0 |
| Emocionado | Contenido enérgico, anuncios, diálogo entusiasta | 0.8 - 1.0 |
| Aburrido | Contenido monótono, diálogo desinteresado, discurso cansado. | 0.3 - 0.7 |
| Juguetón | Conversación casual, humor, interacciones ligeras | 0.6 - 0.9 |
| Confundido | Diálogo cargado de preguntas, incertidumbre, desconcierto | 0.4 - 0.8 |
Configuración de Animation Blueprint
Configuración de sincronización de labios
- Modelo Estándar
- Modelos realistas
El nodo Blend Runtime MetaHuman Lip Sync tiene opciones de configuración en su panel de propiedades:
| Propiedad | Predeterminado | Descripción |
|---|---|---|
| Velocidad de Interpolación | 25 | Controla la rapidez con la que los movimientos labiales transicionan entre visemas. Los valores más altos generan transiciones más rápidas y abruptas. |
| Restablecer tiempo | 0.2 | La duración en segundos después de la cual se restablece la sincronización de labios. Esto es útil para evitar que la sincronización de labios continúe después de que el audio se haya detenido. |
Animación de Risa
También puedes agregar animaciones de risa que responderán dinámicamente a la risa detectada en el audio.
- Agrega el nodo
Blend Runtime MetaHuman Laughter - Conecta tu variable
RuntimeVisemeGeneratoral pinViseme Generator - Si ya estás usando lip sync:
- Conecta la salida del nodo
Blend Runtime MetaHuman Lip Synca laSource Posedel nodoBlend Runtime MetaHuman Laughter - Conecta la salida del nodo
Blend Runtime MetaHuman Laughteral pinResultde laOutput Pose
- Conecta la salida del nodo
- Si solo se usa risa sin sincronización de labios:
- Conecta tu pose de origen directamente a la
Pose de origendel nodoMezclar risa de MetaHuman en tiempo de ejecución - Conecta la salida al pin
Resultado
- Conecta tu pose de origen directamente a la
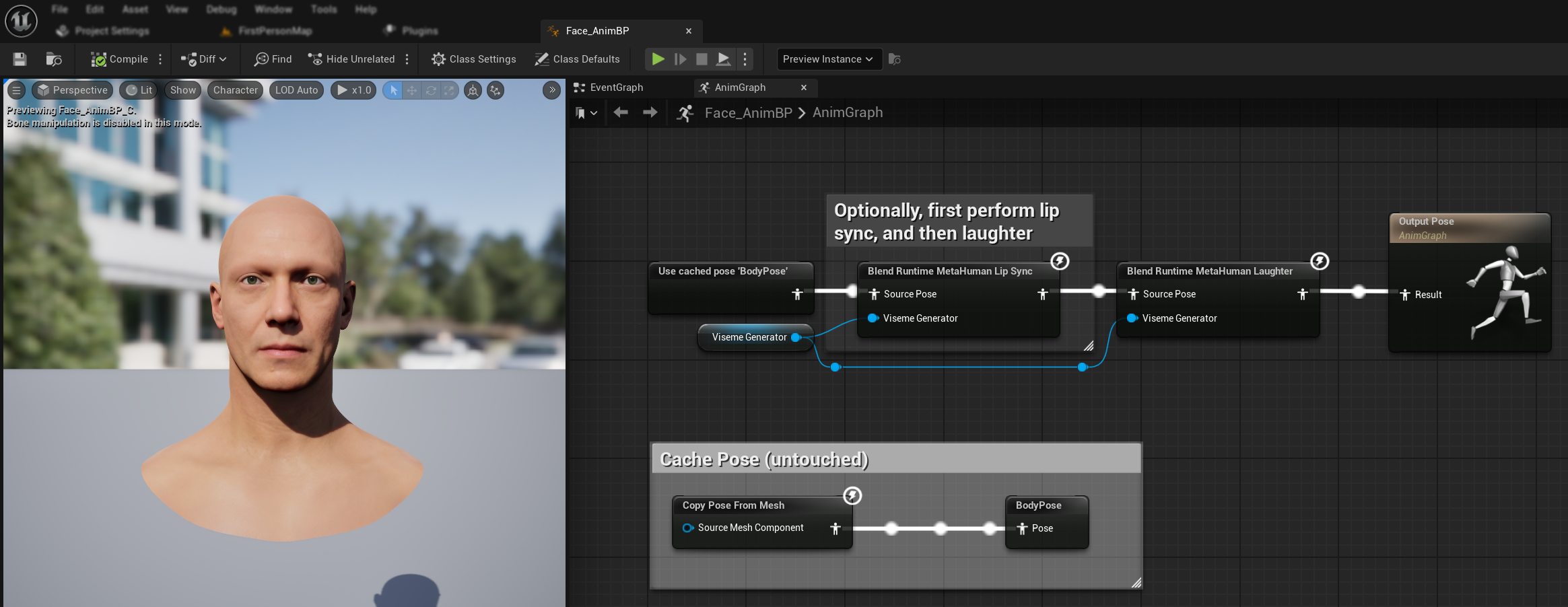
Cuando se detecte risa en el audio, tu personaje se animará dinámicamente en consecuencia:
Configuración de la risa
El nodo Blend Runtime MetaHuman Laughter tiene sus propias opciones de configuración:
| Propiedad | Predeterminado | Descripción |
|---|---|---|
| Velocidad de Interpolación | 25 | Controla la rapidez con la que los movimientos labiales realizan la transición entre animaciones de risa. Los valores más altos generan transiciones más rápidas y abruptas. |
| Restablecer tiempo | 0.2 | La duración en segundos después de la cual se reinicia la risa. Esto es útil para evitar que la risa continúe después de que el audio se haya detenido. |
| Peso máximo de la risa | 0.7 | Escala la intensidad máxima de la animación de risa (0.0 - 1.0). |
Nota: La detección de risas está disponible actualmente solo con el Modelo Estándar.
El nodo Blend Realistic MetaHuman Lip Sync tiene opciones de configuración en su panel de propiedades:
| Propiedad | Predeterminado | Descripción |
|---|---|---|
| Velocidad de Interpolación | 30 | Controla la rapidez con la que las expresiones faciales realizan la transición durante el habla activa. Los valores más altos generan transiciones más rápidas y abruptas. |
| Velocidad de Interpolación en Reposo | 15 | Controla la rapidez con la que las expresiones faciales vuelven al estado neutro/inactivo. Los valores más bajos generan transiciones más suaves y graduales hacia la pose de reposo. |
| Restablecer tiempo | 0.2 | Duración en segundos tras la cual la sincronización de labios se restablece al estado inactivo. Útil para evitar que las expresiones continúen después de que el audio se detenga. |
| Conservar el estado inactivo | falso | Cuando está habilitado, conserva el último estado emocional durante los períodos de inactividad en lugar de restablecerlo a neutral. |
| Conservar las Expresiones Oculares | true | Controla si los controles faciales relacionados con los ojos se conservan durante el estado inactivo. Solo es efectivo cuando Conservar Estado Inactivo está habilitado. |
| Conservar las expresiones de las cejas | true | Controla si los controles faciales relacionados con las cejas se conservan durante el estado inactivo. Solo es efectivo cuando la opción Conservar estado inactivo está habilitada. |
| Conservar la forma de la boca | falso | Controla si los controles de la forma de la boca (excluyendo movimientos específicos del habla como la lengua y la mandíbula) se conservan durante el estado inactivo. Solo es efectivo cuando la opción Conservar estado inactivo está habilitada. |
Preservación del Estado Inactivo
La función Preservar estado inactivo aborda cómo el modelo Realista maneja los períodos de silencio. A diferencia del modelo Estándar, que utiliza visemas discretos y regresa consistentemente a valores cero durante el silencio, la red neuronal del modelo Realista puede mantener una sutil posición facial que difiere de la pose de reposo predeterminada del MetaHuman.
Cuándo habilitar:
- Mantener las expresiones emocionales entre segmentos de habla
- Preservar los rasgos de personalidad del personaje
- Asegurar la continuidad visual en secuencias cinematográficas
Opciones de Control Regional:
- Expresiones Oculares: Conserva el entrecerrado de ojos, la apertura y la posición de los párpados
- Expresiones de Cejas: Mantiene la posición de las cejas y la frente
- Forma de la Boca: Mantiene la curvatura general de la boca mientras permite que los movimientos del habla (lengua, mandíbula) se reinicien
Combinando con Animaciones Existentes
Para aplicar sincronización de labios y risa junto con animaciones corporales existentes y animaciones faciales personalizadas sin sobrescribirlas:
Esta configuración se aplica al Animation Blueprint de la cara, ya que la sincronización de labios no forma parte del Animation Blueprint del cuerpo. Para animaciones corporales personalizadas (p. ej., torso, brazos y otros movimientos del cuerpo), simplemente conecta tu secuencia de animación (a través de un Sequence Player) directamente a la pose de salida en el Animation Blueprint del cuerpo. Allí no se necesita configuración adicional.
- Agrega un nodo
Layered blend per boneentre tus animaciones del cuerpo y la salida final. Asegúrate de queUse Attached Parentesté activado. - Configura la disposición de capas:
- Agrega 1 elemento al array
Layer Setup - Agrega 3 elementos a los
Branch Filterspara la capa, con los siguientesBone Names:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Agrega 1 elemento al array
- Importante para animaciones faciales personalizadas: En la
Opción de Mezcla de Curvas, selecciona "Usar Valor Máximo". Esto permite que las animaciones faciales personalizadas (expresiones, emociones, etc.) se superpongan correctamente sobre la sincronización de labios. - Realiza las conexiones:
- Tu animación personalizada (normalmente un
Sequence Playercon el activo de secuencia de animación deseado) → entradaBase Pose - Salida de animación facial (desde nodos de sincronización de labios y/o risa) → entrada
Blend Poses 0 - Nodo de mezcla por capas → pose
Resultfinal
- Tu animación personalizada (normalmente un
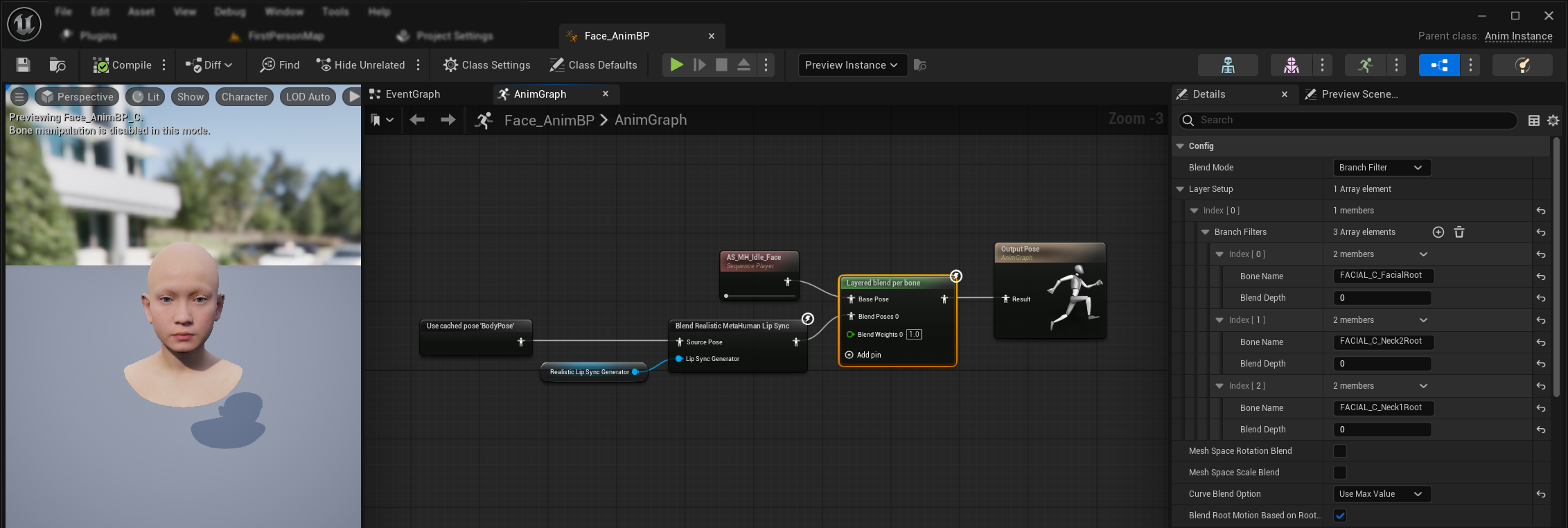
Selección de Conjunto de Morph Targets
- Modelo Estándar
- Modelos realistas
El Modelo Estándar utiliza activos de pose que admiten inherentemente cualquier convención de nomenclatura de morph target a través de la configuración personalizada de activos de pose. No se necesita configuración adicional.
El nodo Blend Realistic MetaHuman Lip Sync incluye una propiedad de Conjunto de Objetivos de Morfología que determina qué convención de nomenclatura de objetivos de morfología utilizar para la animación facial:
| Conjunto de Objetivos de Morfología | Descripción | Casos de Uso |
|---|---|---|
| MetaHuman (Predeterminado) | Nombres estándar de morph targets de MetaHuman (ej., CTRL_expressions_jawOpen) | Personajes MetaHuman |
| ARKit | Nombres compatibles con Apple ARKit (por ejemplo, JawOpen, MouthSmileLeft) | Personajes basados en ARKit |
Ajuste Fino del Comportamiento de Sincronización Labial
Escalando Curvas Específicas de Sincronización Labial
Puede atenuar (o amplificar) movimientos faciales individuales producidos por la sincronización de labios usando un nodo Modify Curve. Esto es útil cuando una curva en particular se ve demasiado pronunciada para su contenido de audio o personaje.
Configuración:
- Después de tu nodo de mezcla de sincronización labial, agrega un nodo
Modify Curve - Haz clic derecho en el nodo y selecciona Add Curve Pin, luego ingresa el nombre de la curva que deseas escalar
- Establece la propiedad Apply Mode del nodo en Scale
- Establece el parámetro Value: los valores por debajo de 1.0 atenúan el movimiento, los valores por encima de 1.0 lo amplifican (por ejemplo, 0.8 = reducción del 20%)
Curvas comúnmente escaladas:
| Nombre de la curva | Propósito | Se aplica a | Ajuste Típico |
|---|---|---|---|
CTRL_expressions_tongueOut | Protrusión hacia adelante de la lengua durante ciertos fonemas | Modelo estándar | 0.8 para reducir la protrusión |
CTRL_expressions_jawOpen | Rango de apertura de la mandíbula | Modelos realistas | 0.9 para reducir el movimiento de la mandíbula |
Puedes agregar múltiples pines de curva al mismo nodo Modify Curve para escalar varias curvas a la vez.
Ajuste Fino Específico del Estado de Ánimo
Para los modelos con capacidad de estado de ánimo, puedes ajustar expresiones emocionales específicas:
Control de Cejas:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- Elevación interna de cejasCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- Elevación externa de cejasCTRL_expressions_browDownL/CTRL_expressions_browDownR- Descenso de cejas
Control de Expresión Ocular:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Entrecerrar los ojosCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Elevación de mejillas
Comparación y Selección de Modelos
Elección entre modelos
Al decidir qué modelo de sincronización labial usar para tu proyecto, considera estos factores:
| Consideración | Modelo Estándar | Modelo Realista | Modelo Realista con Estado de Ánimo |
|---|---|---|---|
| Compatibilidad de personajes | MetaHumans y todos los tipos de personajes personalizados | MetaHumans (y personajes de ARKit) | MetaHumans (y personajes ARKit) |
| Calidad Visual | Buen sincronismo labial con rendimiento eficiente. | Realismo mejorado con movimientos de boca más naturales | Realismo mejorado con expresiones emocionales |
| Rendimiento | Optimizado para todas las plataformas, incluyendo móvil/VR. | Mayores requisitos de recursos | Mayores requisitos de recursos |
| Funcionalidades | 14 visemas, detección de risa | 81 controles faciales, 3 niveles de optimización | 81 controles faciales, 12 estados de ánimo, salida configurable |
| Soporte de Plataforma | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Casos de uso | Aplicaciones generales, juegos, VR/AR, móvil | Experiencias cinematográficas, interacciones en primer plano | Narración emocional, interacción avanzada de personajes |
Compatibilidad de Versiones del Motor
Si estás usando Unreal Engine 5.2, los Modelos Realistas pueden no funcionar correctamente debido a un error en la biblioteca de remuestreo de UE. Para los usuarios de UE 5.2 que necesiten una funcionalidad de sincronización labial confiable, usa el Modelo Estándar en su lugar.
Este problema es específico de UE 5.2 y no afecta a otras versiones del motor.
Recomendaciones de rendimiento
- Para la mayoría de los proyectos, el Modelo Estándar ofrece un excelente equilibrio entre calidad y rendimiento
- Utiliza el Modelo Realista cuando necesites la máxima fidelidad visual para personajes MetaHuman
- Utiliza el Modelo Realista con Control de Estado de Ánimo cuando el control de la expresión emocional sea importante para tu aplicación
- Considera las capacidades de rendimiento de tu plataforma objetivo al elegir entre modelos
- Prueba diferentes niveles de optimización para encontrar el mejor equilibrio para tu caso de uso específico
Solución de problemas
Problemas Comunes
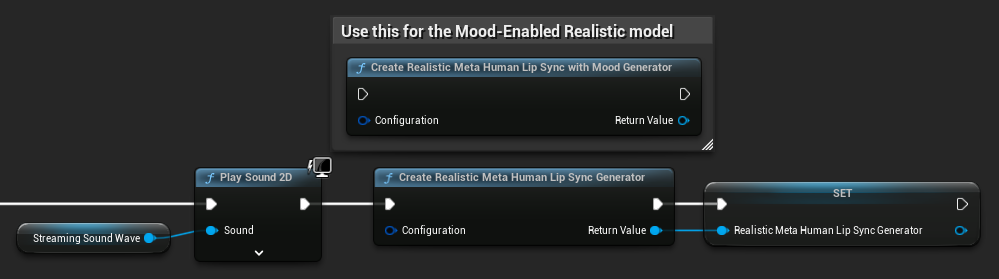
Recreación del generador para modelos realistas: Para un funcionamiento fiable y consistente con los modelos realistas, se recomienda recrear el generador cada vez que se desee introducir nuevos datos de audio tras un período de inactividad. Esto se debe al comportamiento del tiempo de ejecución de ONNX, que puede provocar que la sincronización de labios deje de funcionar al reutilizar generadores después de períodos de silencio.
Por ejemplo, podrías recrear el generador de sincronización labial al inicio de cada reproducción, como cada vez que llames a Play Sound 2D o uses cualquier otro método para iniciar la reproducción de ondas de sonido y la sincronización labial:
Ubicación del Plugin para la Integración de Runtime Text To Speech: Al usar Runtime MetaHuman Lip Sync junto con Runtime Text To Speech (ambos plugins usan ONNX Runtime), es posible que experimentes problemas en compilaciones empaquetadas si los plugins están instalados en la carpeta Marketplace del motor. Para solucionarlo:
- Localiza ambos plugins en tu carpeta de instalación de UE dentro de
\Engine\Plugins\Marketplace(por ejemplo,C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Mueve las carpetas
RuntimeMetaHumanLipSyncyRuntimeTextToSpeecha la carpetaPluginsde tu proyecto - Si tu proyecto no tiene una carpeta
Plugins, crea una en el mismo directorio que tu archivo.uproject - Reinicia el Unreal Editor
Esto soluciona problemas de compatibilidad que pueden ocurrir cuando múltiples plugins basados en ONNX Runtime se cargan desde el directorio de Marketplace del motor.
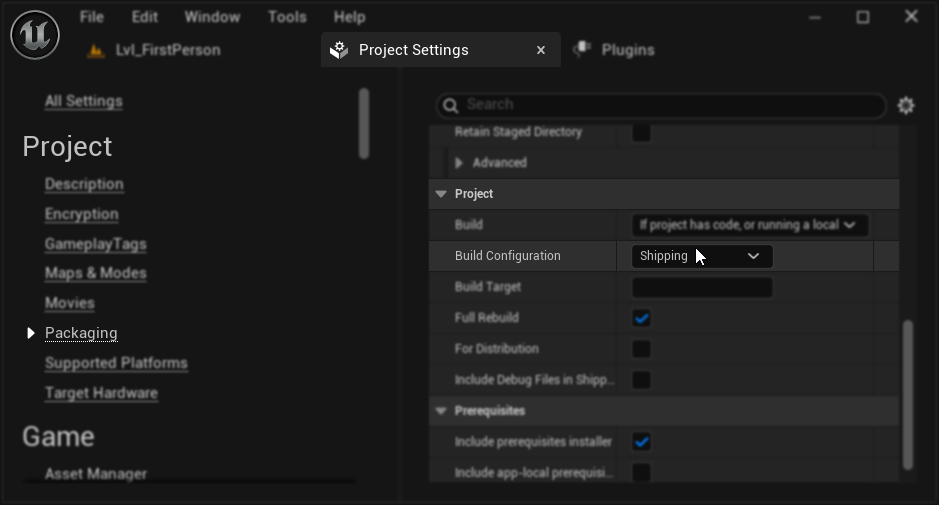
Configuración de empaquetado (Windows): Si la sincronización de labios no funciona correctamente en tu proyecto empaquetado en Windows, asegúrate de usar la configuración de compilación Shipping en lugar de Development. La configuración Development puede causar problemas con el tiempo de ejecución ONNX de los modelos realistas en compilaciones empaquetadas.
Para solucionar esto:
- En tu Configuración del Proyecto → Empaquetado, establece la Configuración de Compilación en Shipping
- Vuelve a empaquetar tu proyecto
En algunos proyectos que solo usan Blueprints, Unreal Engine puede seguir compilando en configuración Development incluso cuando se selecciona Shipping. Si esto ocurre, convierte tu proyecto a un proyecto C++ agregando al menos una clase C++ (puede estar vacía). Para hacerlo, ve a Tools → New C++ Class en el menú del editor de UE y crea una clase vacía. Esto forzará al proyecto a compilar correctamente en configuración Shipping. Tu proyecto puede seguir siendo solo de Blueprints en funcionalidad; la clase C++ solo es necesaria para la configuración de compilación adecuada.
Respuesta de sincronización labial degradada: Si experimenta que la sincronización labial se vuelve menos receptiva con el tiempo al usar Streaming Sound Wave o Capturable Sound Wave, esto puede deberse a la acumulación de memoria. De forma predeterminada, la memoria se reasigna cada vez que se agrega nuevo audio. Para evitar este problema, llame periódicamente a la función ReleaseMemory para liberar la memoria acumulada, por ejemplo, cada 30 segundos aproximadamente.
Optimización del Rendimiento:
- Ajusta el tamaño del fragmento de procesamiento para modelos realistas según tus requisitos de rendimiento
- Usa recuentos de hilos adecuados para tu hardware objetivo
- Considera usar el tipo de salida Solo Boca para modelos con estado de ánimo habilitado cuando no se necesite animación facial completa