Cómo usar el plugin
El plugin Runtime Speech Recognizer está diseñado para reconocer palabras a partir de datos de audio entrantes. Utiliza una versión ligeramente modificada de whisper.cpp para funcionar con el motor. Para usar el plugin, sigue estos pasos:
Lado del editor
- Selecciona los modelos de lenguaje apropiados para tu proyecto como se describe aquí.
Lado del runtime
- Crea un Speech Recognizer y establece los parámetros necesarios (CreateSpeechRecognizer, para los parámetros ver aquí).
- Enlaza a los delegados necesarios (OnRecognitionFinished, OnRecognizedTextSegment y OnRecognitionError).
- Inicia el reconocimiento de voz (StartSpeechRecognition).
- Procesa los datos de audio y espera los resultados de los delegados (ProcessAudioData).
- Detén el reconocedor de voz cuando sea necesario (por ejemplo, después de la emisión de OnRecognitionFinished).
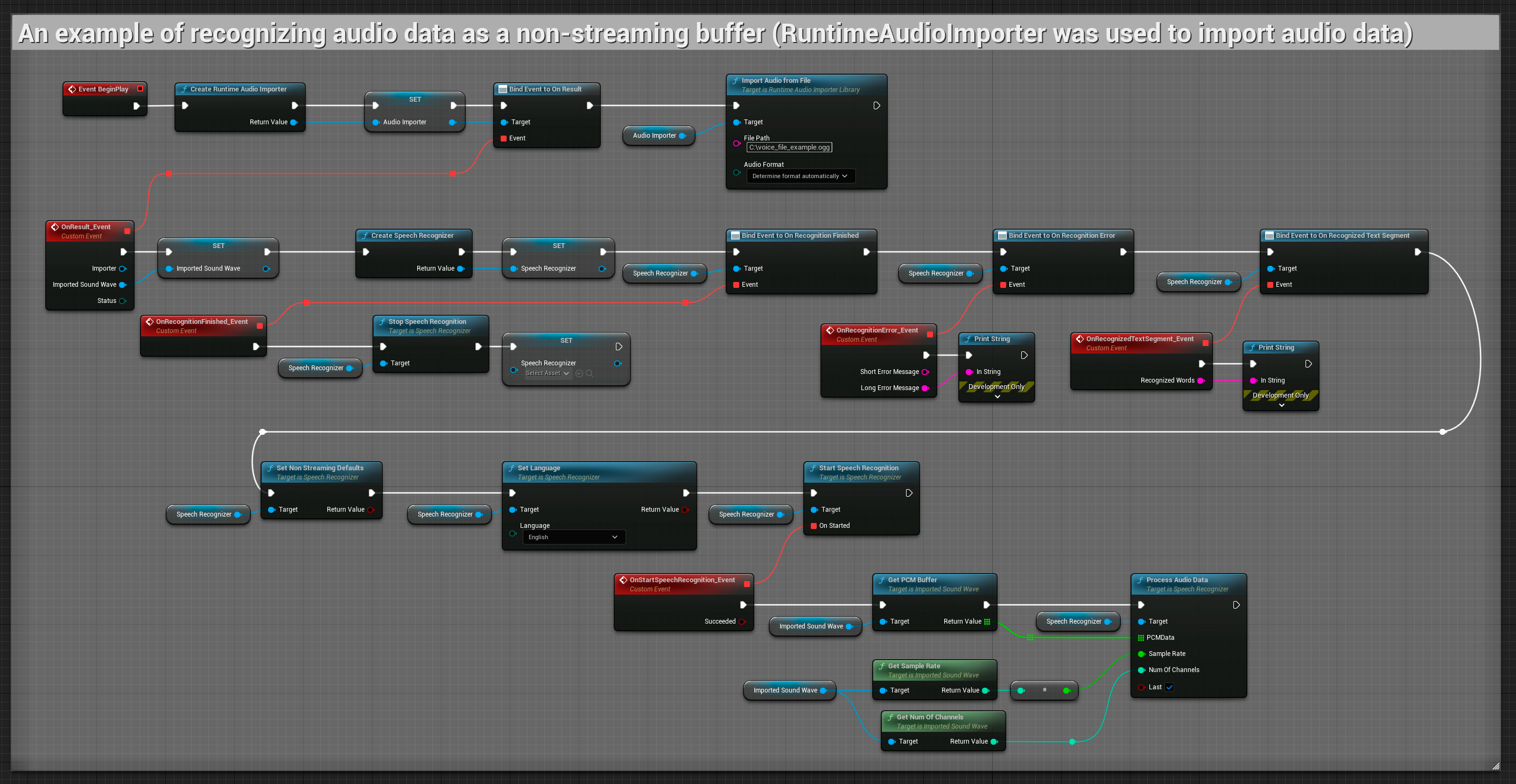
El plugin admite audio entrante en el formato PCM entrelazado de 32 bits en punto flotante. Si bien funciona bien con el Runtime Audio Importer, no depende directamente de él.
Parámetros de reconocimiento
El plugin admite el reconocimiento de datos de audio tanto en streaming como no streaming. Para ajustar los parámetros de reconocimiento para tu caso de uso específico, llama a SetStreamingDefaults o SetNonStreamingDefaults. Además, tienes la flexibilidad de establecer manualmente parámetros individuales como el número de hilos, el tamaño del paso, si traducir el lenguaje entrante a inglés, y si usar transcripción pasada. Consulta la Lista de Parámetros de Reconocimiento para una lista completa de los parámetros disponibles.
Mejorar el rendimiento
Por favor, consulta la sección Cómo mejorar el rendimiento para obtener consejos sobre cómo optimizar el rendimiento del plugin.
Detección de Actividad de Voz (VAD)
Al procesar la entrada de audio, especialmente en escenarios de streaming, se recomienda usar la Detección de Actividad de Voz (VAD) para filtrar segmentos de audio vacíos o solo de ruido antes de que lleguen al reconocedor. Este filtrado se puede habilitar en el lado de la onda de sonido capturable usando el plugin Runtime Audio Importer, lo que ayuda a evitar que los modelos de lenguaje alucinen - intentando encontrar patrones en el ruido y generando transcripciones incorrectas.
Para obtener resultados óptimos de reconocimiento de voz, recomendamos usar el proveedor Silero VAD que ofrece una tolerancia al ruido superior y una detección de voz más precisa. El Silero VAD está disponible como una extensión del plugin Runtime Audio Importer. Para instrucciones detalladas sobre la configuración de VAD, consulta la documentación de Detección de Actividad de Voz.
Los nodos copiables en los ejemplos a continuación utilizan el proveedor de VAD predeterminado por razones de compatibilidad. Para mejorar la precisión del reconocimiento, puedes cambiar fácilmente a Silero VAD mediante:
- Instalar la extensión Silero VAD como se describe en la sección Extensión Silero VAD
- Después de activar VAD con el nodo Toggle VAD, añade un nodo Set VAD Provider y selecciona "Silero" del menú desplegable
En el proyecto demo incluido con el plugin, VAD está activado por defecto. Puedes encontrar más información sobre la implementación del demo en Proyecto Demo.
Ejemplos
Estos ejemplos ilustran cómo usar el plugin Runtime Speech Recognizer con entrada de audio tanto en streaming como no streaming, utilizando el Runtime Audio Importer para obtener datos de audio como ejemplo. Ten en cuenta que se requiere la descarga por separado de RuntimeAudioImporter para acceder al mismo conjunto de funciones de importación de audio mostradas en los ejemplos (por ejemplo, capturable sound wave e ImportAudioFromFile). Estos ejemplos tienen únicamente la intención de ilustrar el concepto central y no incluyen manejo de errores.
Ejemplos de entrada de audio en streaming
Nota: En UE 5.3 y otras versiones, podrías encontrar nodos faltantes después de copiar Blueprints. Esto puede ocurrir debido a diferencias en la serialización de nodos entre versiones del motor. Siempre verifica que todos los nodos estén correctamente conectados en tu implementación.
1. Reconocimiento básico en streaming
Este ejemplo demuestra la configuración básica para capturar datos de audio del micrófono como un flujo usando Capturable sound wave y pasarlo al reconocedor de voz. Graba el habla durante unos 5 segundos y luego procesa el reconocimiento, haciéndolo adecuado para pruebas rápidas e implementaciones simples. Nodos copiables.
Características clave de esta configuración:
- Duración de grabación fija de 5 segundos
- Reconocimiento simple de una sola vez
- Requisitos de configuración mínimos
- Perfecto para pruebas y prototipado
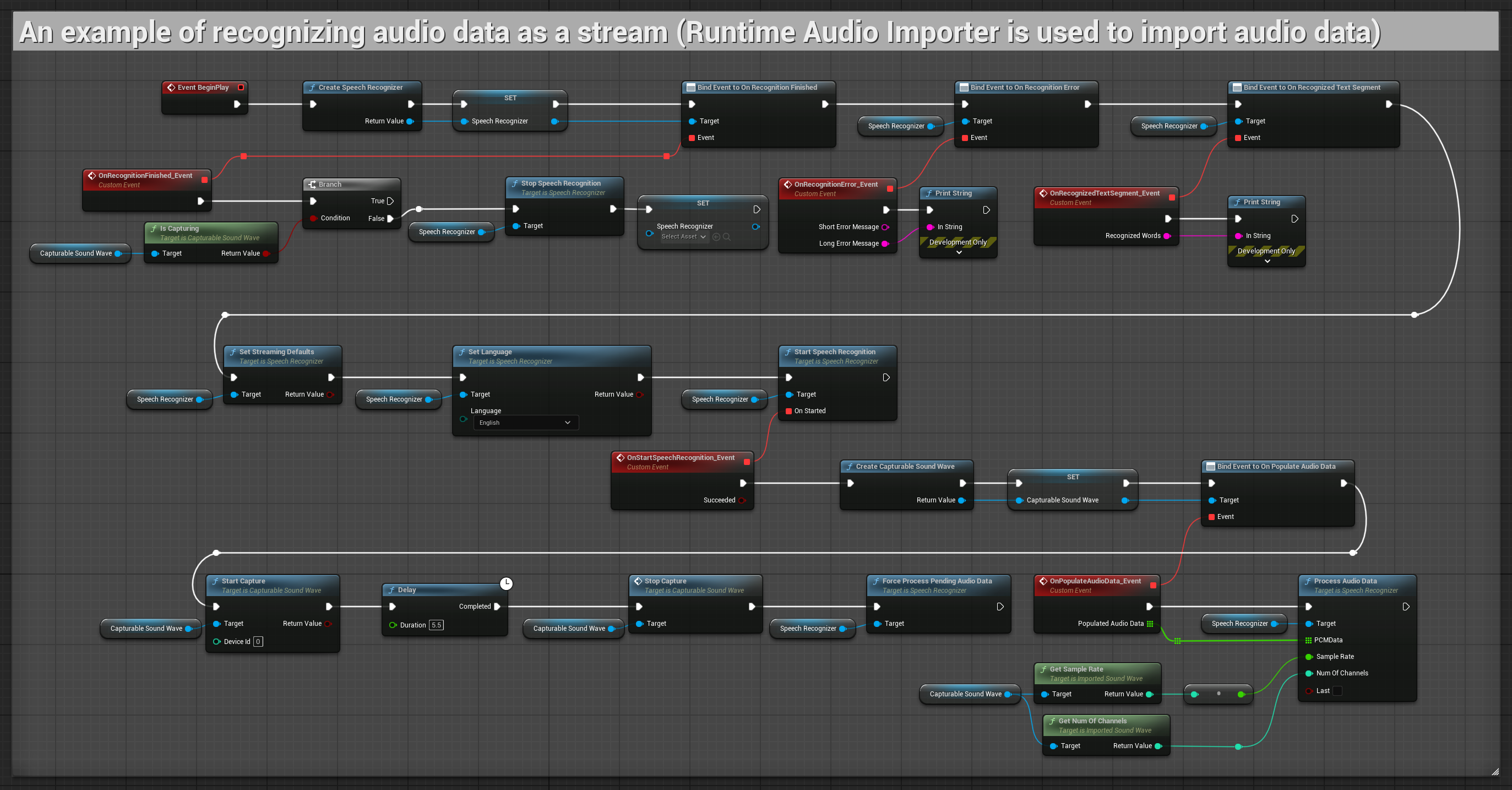
2. Reconocimiento en streaming controlado
Este ejemplo extiende la configuración básica de streaming añadiendo control manual sobre el proceso de reconocimiento. Te permite iniciar y detener el reconocimiento a voluntad, haciéndolo adecuado para escenarios donde necesitas control preciso sobre cuándo ocurre el reconocimiento. Nodos copiables.
Características clave de esta configuración:
- Control manual de inicio/detención
- Capacidad de reconocimiento continuo
- Duración de grabación flexible
- Adecuado para aplicaciones interactivas
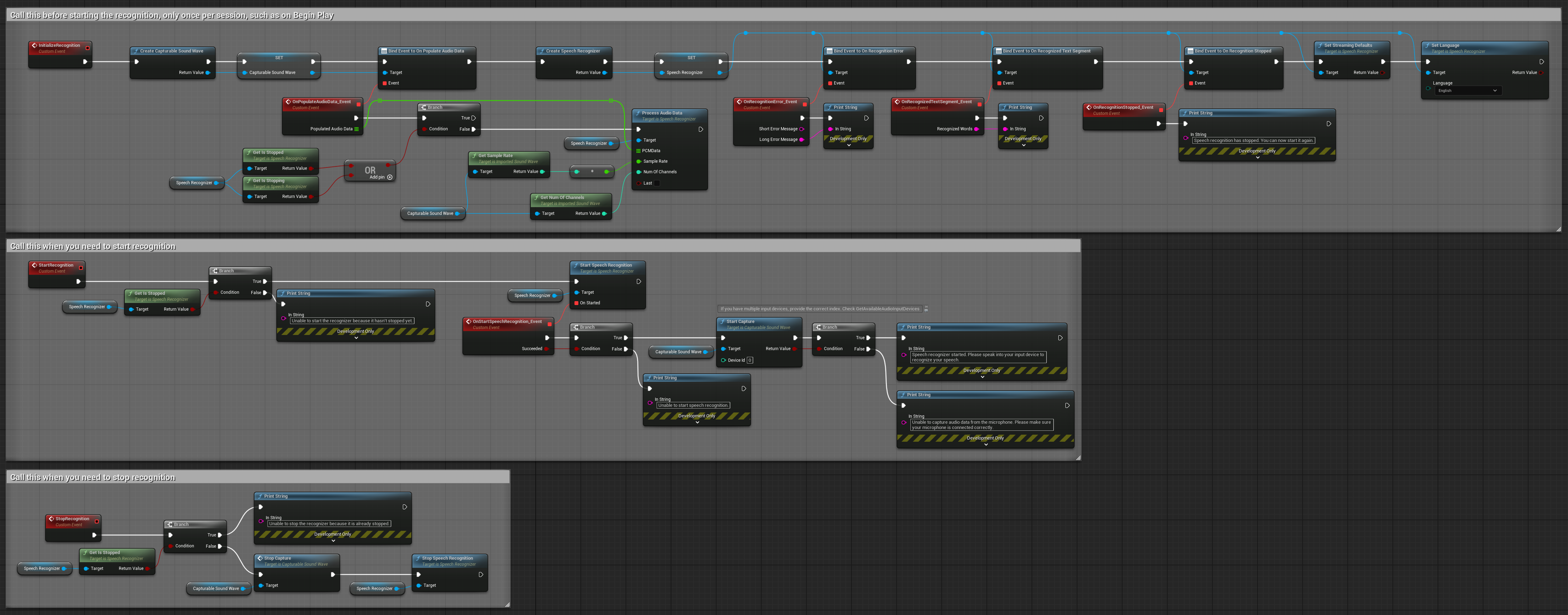
3. Reconocimiento de comandos activado por voz
Este ejemplo está optimizado para escenarios de reconocimiento de comandos. Combina el reconocimiento en streaming con la Detección de Actividad de Voz (VAD) para procesar automáticamente el habla cuando el usuario deja de hablar. El reconocedor comienza a procesar el habla acumulada solo cuando se detecta silencio, lo que lo hace ideal para interfaces basadas en comandos. Nodos copiables.
Características clave de esta configuración:
- Control manual de inicio/detención
- Detección de Actividad de Voz (VAD) activada para detectar segmentos de habla
- Activación automática del reconocimiento cuando se detecta silencio
- Óptimo para reconocimiento de comandos cortos
- Reducción de la sobrecarga de procesamiento al reconocer solo el habla real
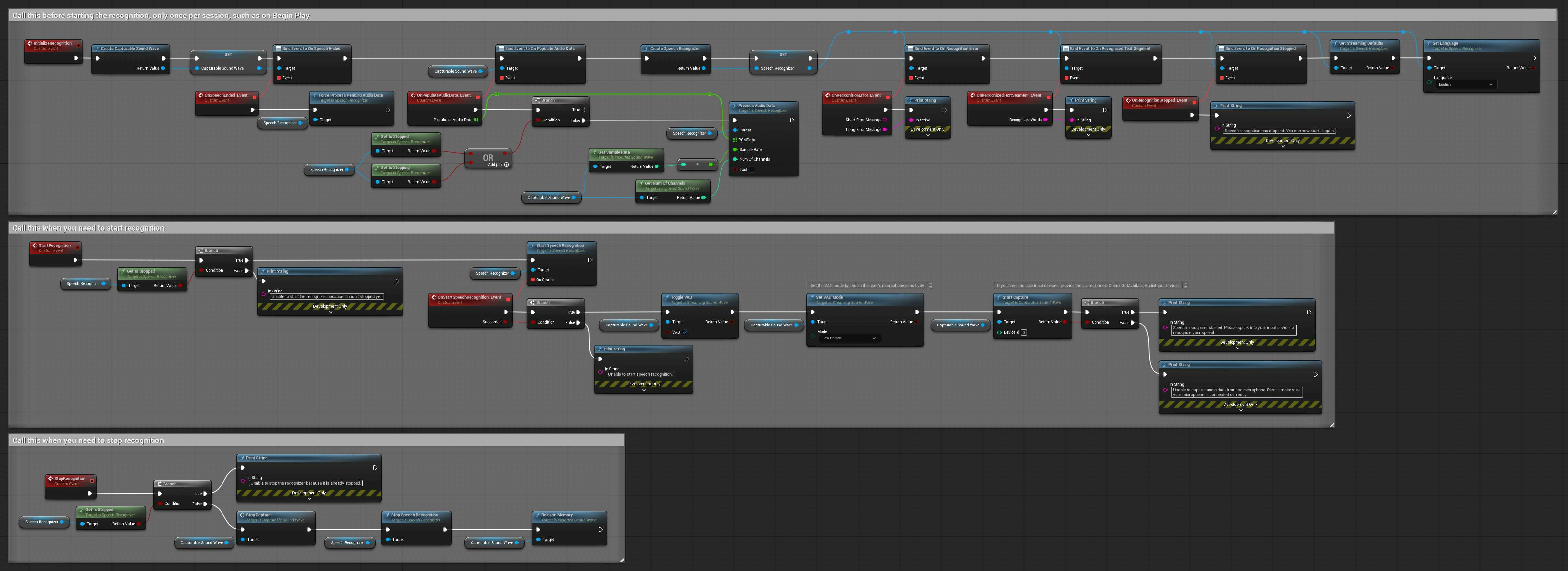
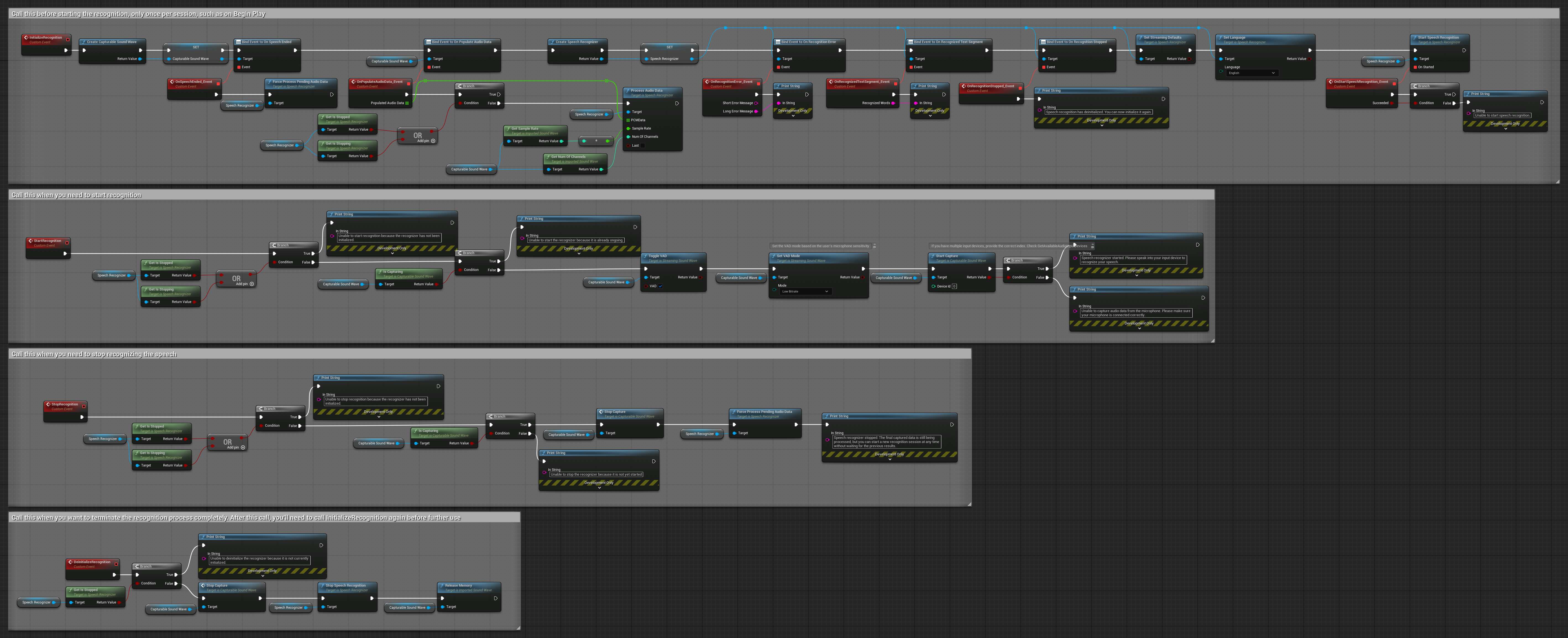
4. Reconocimiento de voz con auto-inicialización y procesamiento de búfer final
Este ejemplo es otra variación del enfoque de reconocimiento activado por voz con un manejo diferente del ciclo de vida. Inicia automáticamente el reconocedor durante la inicialización y lo detiene durante la desinicialización. Una característica clave es que procesa el último búfer de audio acumulado antes de detener el reconocedor, asegurando que no se pierdan datos de habla cuando el usuario desea finalizar el proceso de reconocimiento. Esta configuración es particularmente útil para aplicaciones donde se necesita capturar expresiones completas del usuario incluso al detenerse a mitad del habla. Nodos copiables.
Características clave de esta configuración:
- Auto-inicia el reconocedor en la inicialización
- Auto-detiene el reconocedor en la desinicialización
- Procesa el búfer de audio final antes de detenerse completamente
- Utiliza Detección de Actividad de Voz (VAD) para un reconocimiento eficiente
- Asegura que no se pierdan datos de habla al detenerse
Entrada de audio no streaming
Este ejemplo importa datos de audio a la onda sonora importada y reconoce todos los datos de audio una vez que han sido importados. Nodos copiables.