Lista de parámetros de reconocimiento
Estos parámetros solo se pueden configurar mientras el reconocedor no está en ejecución.
Esta no es una lista exhaustiva de los parámetros disponibles en Whisper. Solo se exponen aquí los más importantes. Si es necesario, esta lista se actualizará.
Establecer Parámetros de Reconocimiento
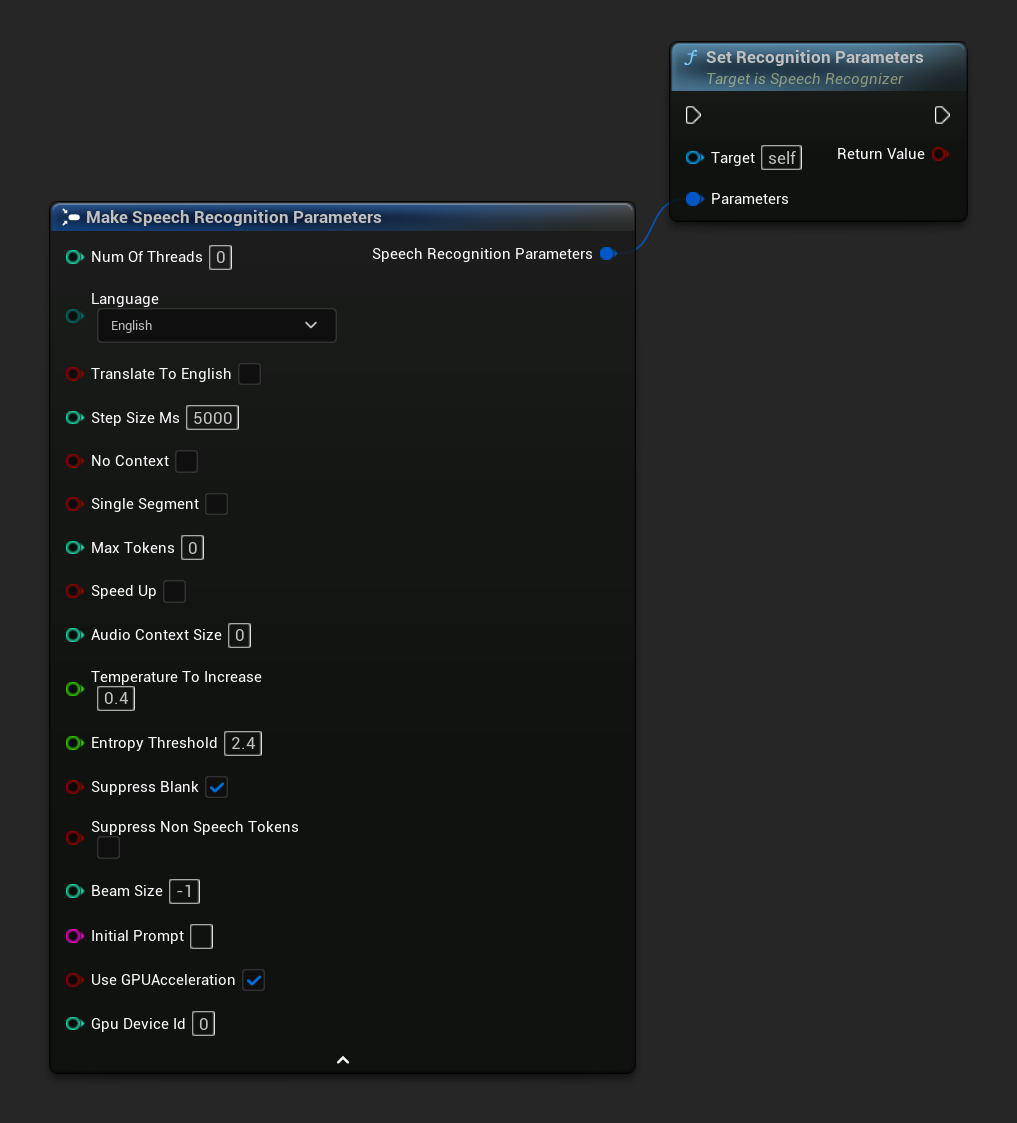
Establece los parámetros para el reconocimiento de voz. Si deseas cambiar solo parámetros específicos, considera usar las funciones de establecimiento individuales.
Establecer Valores Predeterminados para Streaming
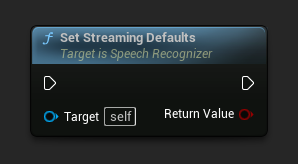
Establece los parámetros predeterminados adecuados para el reconocimiento de voz en streaming.
Esta función sobrescribe todos los parámetros aplicados previamente. Asegúrate de llamar a esta función antes de establecer tus parámetros personalizados si necesitas usar los valores predeterminados de streaming como configuración base.
Establecer Valores Predeterminados para No Streaming
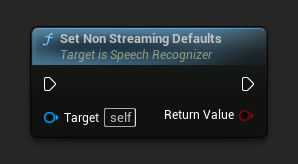
Establece los parámetros predeterminados adecuados para el reconocimiento de voz no en streaming.
Esta función sobrescribe todos los parámetros aplicados previamente. Asegúrate de llamar a esta función antes de establecer tus parámetros personalizados si necesitas usar los valores predeterminados de no streaming como configuración base.
Establecer Número de Hilos
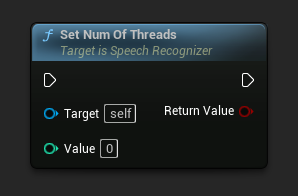
Establece el número de hilos a utilizar para el reconocimiento de voz. Establece este valor en 0 para usar el número de núcleos.
Establecer Idioma
Establece el idioma a utilizar para el reconocimiento de voz. Debe ser compatible con el modelo de idioma seleccionado en la configuración del Editor.
Establecer el idioma en Auto disminuirá la precisión y el rendimiento del reconocimiento.
Obtener Idioma Detectado
Obtiene el idioma detectado del último reconocimiento. Devuelve el idioma como un valor de enumeración.
Nota: Esta función solo funciona después de que se ha realizado un reconocimiento. Devuelve Auto si la detección de idioma falló o no se realizó. Esto es particularmente útil cuando se usa la detección automática de idioma para identificar qué idioma se reconoció realmente.
Obtener Código de Idioma

Convierte un valor de enumeración de idioma a su cadena de código de idioma (por ejemplo, En -> "en", Fr -> "fr", De -> "de").
Obtener Nombre Completo del Idioma
Convierte un valor de enumeración de idioma a su nombre completo del idioma (por ejemplo, En -> "English", Fr -> "French", De -> "German").
Establecer Traducir al Inglés
![]()
Establece si se deben traducir las palabras reconocidas al inglés. Si es verdadero, el modelo de idioma debe ser multilingüe.
Establecer Tamaño del Paso
Establece el tamaño del paso en milisegundos. Determina con qué frecuencia enviar datos de audio para reconocimiento. El valor predeterminado es 5000 ms (5 segundos).
Establecer Sin Contexto
Establece si se debe usar la transcripción anterior (si existe) como indicación inicial para el decodificador.
Establecer Segmento Único
Establece si se debe forzar la salida de un solo segmento (útil para streaming).
Establecer Máximo de Tokens
Establece el número máximo de tokens por segmento de texto. Usa 0 para sin límite.
Establecer Acelerar
Establece si se debe acelerar el reconocimiento 2x usando Phase Vocoder. Establécelo como false para mejorar la calidad de la salida.
Establecer Tamaño del Contexto de Audio
Establece el tamaño del contexto de audio. Establécelo como 0 para mejorar la calidad de la salida.
Establecer Temperatura a Incrementar
Establece la temperatura a incrementar cuando se retrocede al fallar la decodificación al no cumplir con alguno de los umbrales siguientes.
Establecer Umbral de Entropía
Establece el umbral de entropía. Si la relación de compresión es mayor que este valor, trata la decodificación como fallida. Similar al "compression_ratio_threshold" de OpenAI
Establecer Suprimir en Blanco
![]()
Establece si se deben suprimir los espacios en blanco que aparecen en las salidas.
Establecer Suprimir Tokens No de Voz
Establece si se deben suprimir los tokens que no son de voz que aparecen en las salidas.
Establecer Tamaño del Haz
Establece el número de haces en la búsqueda por haz. Solo aplicable cuando la temperatura es cero.
Establecer Indicación Inicial
Establece la indicación inicial para la primera ventana. Esto se puede usar para proporcionar contexto al reconocimiento para que sea más probable que prediga las palabras correctamente, por ejemplo, vocabularios personalizados o nombres propios.
Para más detalles sobre estrategias efectivas de indicación, consulta la Guía de Indicación de Whisper.
Establecer Aceleración por GPU
Establece si se debe usar la aceleración por GPU para el reconocimiento de voz (solo aplicable en Windows por el momento).
Establecer ID del Dispositivo GPU
Establece el ID del dispositivo GPU a utilizar para el reconocimiento de voz. El valor predeterminado es 0. Esto es útil para sistemas con múltiples GPUs para especificar qué GPU debe usarse para el proceso de reconocimiento. Si el ID del dispositivo GPU especificado no es válido, se usará en su lugar el primer índice de dispositivo GPU disponible.