Cómo usar el plugin
El plugin Runtime Text To Speech sintetiza texto en voz utilizando modelos de voz descargables. Estos modelos se gestionan en la configuración del plugin dentro del editor, se descargan y se empaquetan para su uso en tiempo de ejecución. Sigue los pasos a continuación para comenzar.
Lado del editor
Descarga los modelos de voz apropiados para tu proyecto como se describe aquí. Puedes descargar múltiples modelos de voz al mismo tiempo.
Lado de tiempo de ejecución
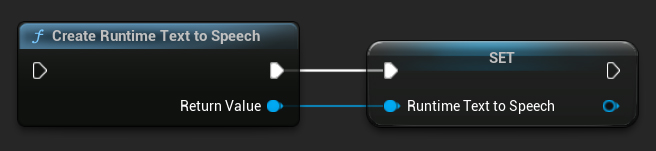
Crea el sintetizador utilizando la función CreateRuntimeTextToSpeech. Asegúrate de mantener una referencia a él (por ejemplo, como una variable separada en Blueprints o UPROPERTY en C++) para evitar que sea recolectado como basura.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Sintetizando Voz
El plugin ofrece dos modos de síntesis de texto a voz:
- Texto a Voz Regular: Sintetiza el texto completo y devuelve el audio completo cuando termina
- Texto a Voz en Streaming: Proporciona fragmentos de audio a medida que se generan, permitiendo procesamiento en tiempo real
Cada modo soporta dos métodos para seleccionar modelos de voz:
- Por Nombre: Selecciona un modelo de voz por su nombre (recomendado para UE 5.4+)
- Por Objeto: Selecciona un modelo de voz por referencia directa (recomendado para UE 5.3 y anteriores)
Texto a Voz Regular
Por Nombre
- Blueprint
- C++
La función Text To Speech (By Name) es más conveniente en Blueprints a partir de UE 5.4. Te permite seleccionar modelos de voz de una lista desplegable de los modelos descargados. En versiones de UE inferiores a 5.3, esta lista desplegable no aparece, por lo que si estás usando una versión anterior, necesitarás iterar manualmente sobre el array de modelos de voz devuelto por GetDownloadedVoiceModels para seleccionar el que necesitas.
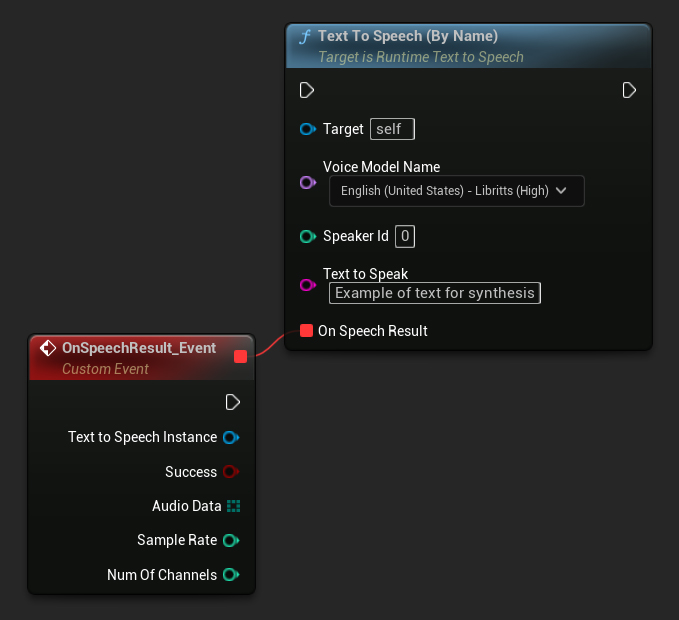
En C++, la selección de modelos de voz puede ser ligeramente más compleja debido a la falta de una lista desplegable. Puedes usar la función GetDownloadedVoiceModelNames para recuperar los nombres de los modelos de voz descargados y seleccionar el que necesites. Después, puedes llamar a la función TextToSpeechByName para sintetizar texto usando el nombre del modelo de voz seleccionado.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Por Objeto
- Blueprint
- C++
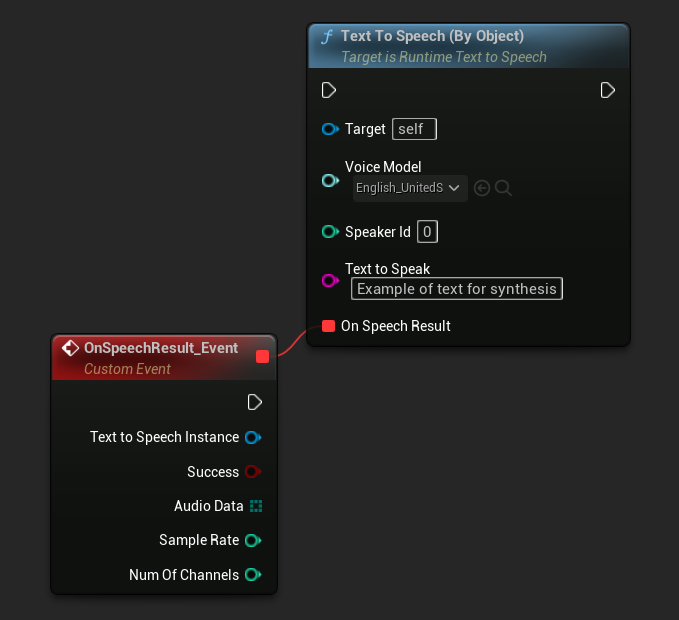
La función Text To Speech (By Object) funciona en todas las versiones de Unreal Engine pero presenta los modelos de voz como una lista desplegable de referencias de activos, lo cual es menos intuitivo. Este método es adecuado para UE 5.3 y anteriores, o si tu proyecto requiere una referencia directa a un activo de modelo de voz por cualquier motivo.
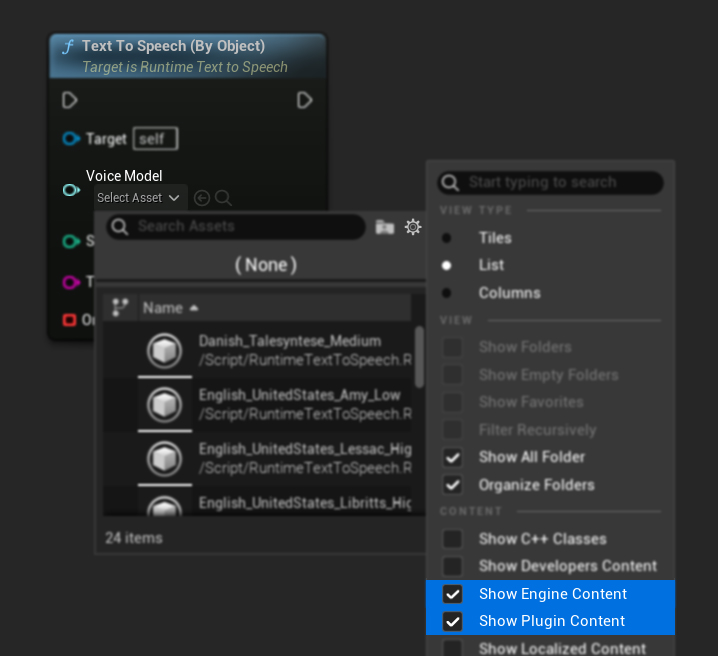
Si has descargado los modelos pero no puedes verlos, abre el desplegable Voice Model, haz clic en la configuración (icono de engranaje) y habilita tanto Show Plugin Content como Show Engine Content para hacer visibles los modelos.
En C++, la selección de modelos de voz puede ser ligeramente más compleja debido a la falta de una lista desplegable. Puedes usar la función GetDownloadedVoiceModelNames para recuperar los nombres de los modelos de voz descargados y seleccionar el que necesites. Luego, puedes llamar a la función GetVoiceModelFromName para obtener el objeto del modelo de voz y pasarlo a la función TextToSpeechByObject para sintetizar texto.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Texto a Voz en Streaming
Para textos más largos o cuando quieres procesar datos de audio en tiempo real a medida que se generan, puedes usar las versiones de streaming de las funciones de Texto a Voz:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNameen C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjecten C++)
Estas funciones proporcionan datos de audio en fragmentos a medida que se generan, permitiendo un procesamiento inmediato sin tener que esperar a que se complete toda la síntesis. Esto es útil para diversas aplicaciones como la reproducción de audio en tiempo real, visualización en vivo, o cualquier escenario donde necesites procesar datos de voz de forma incremental.
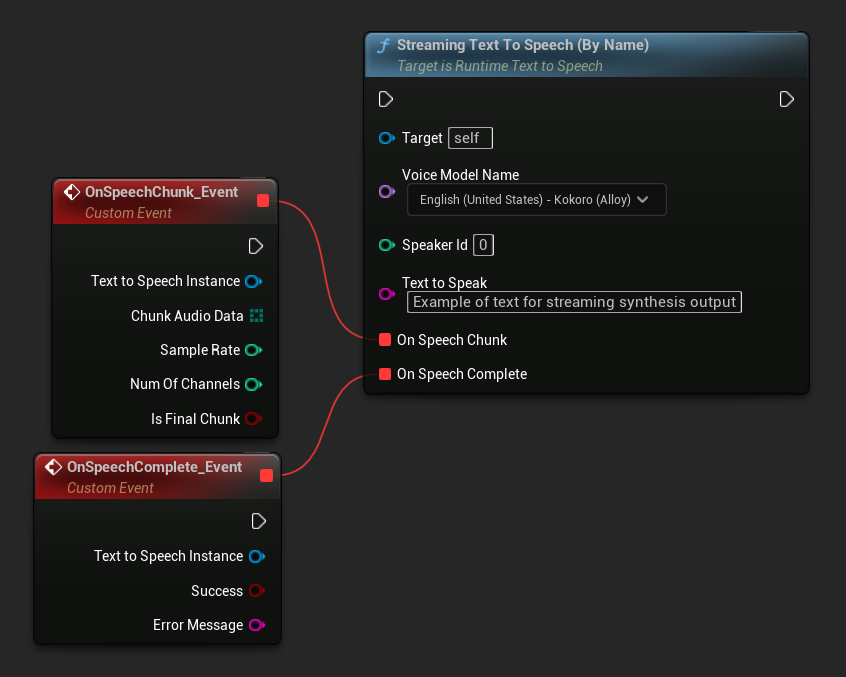
Streaming Por Nombre
- Blueprint
- C++
La función Streaming Text To Speech (By Name) funciona de manera similar a la versión regular pero proporciona audio en fragmentos a través del delegado On Speech Chunk.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
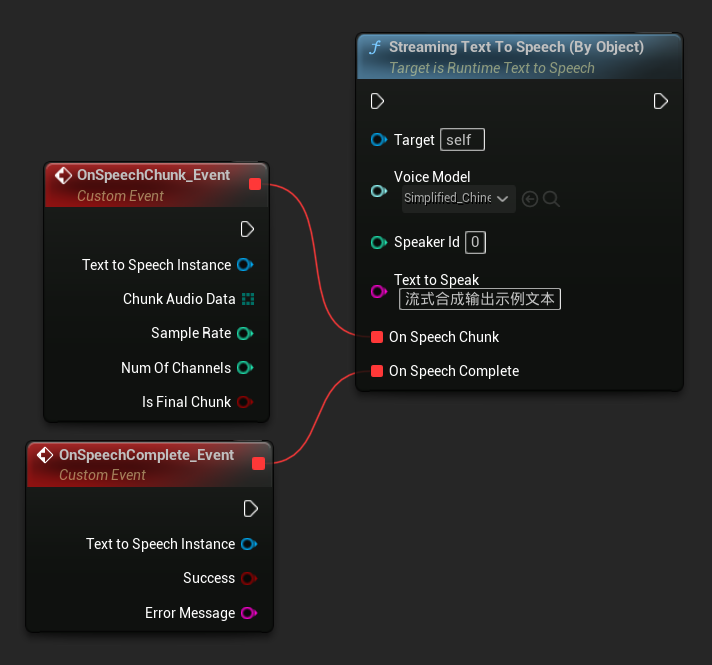
Streaming Por Objeto
- Blueprint
- C++
La función Streaming Text To Speech (By Object) proporciona la misma funcionalidad de streaming pero toma una referencia de objeto de modelo de voz.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Reproducción de Audio
- Reproducción Regular
- Reproducción en Streaming
Para el texto a voz regular (no en streaming), el delegado On Speech Result proporciona el audio sintetizado como datos PCM en formato float (como un array de bytes en Blueprints o TArray<uint8> en C++), junto con la Sample Rate y Num Of Channels.
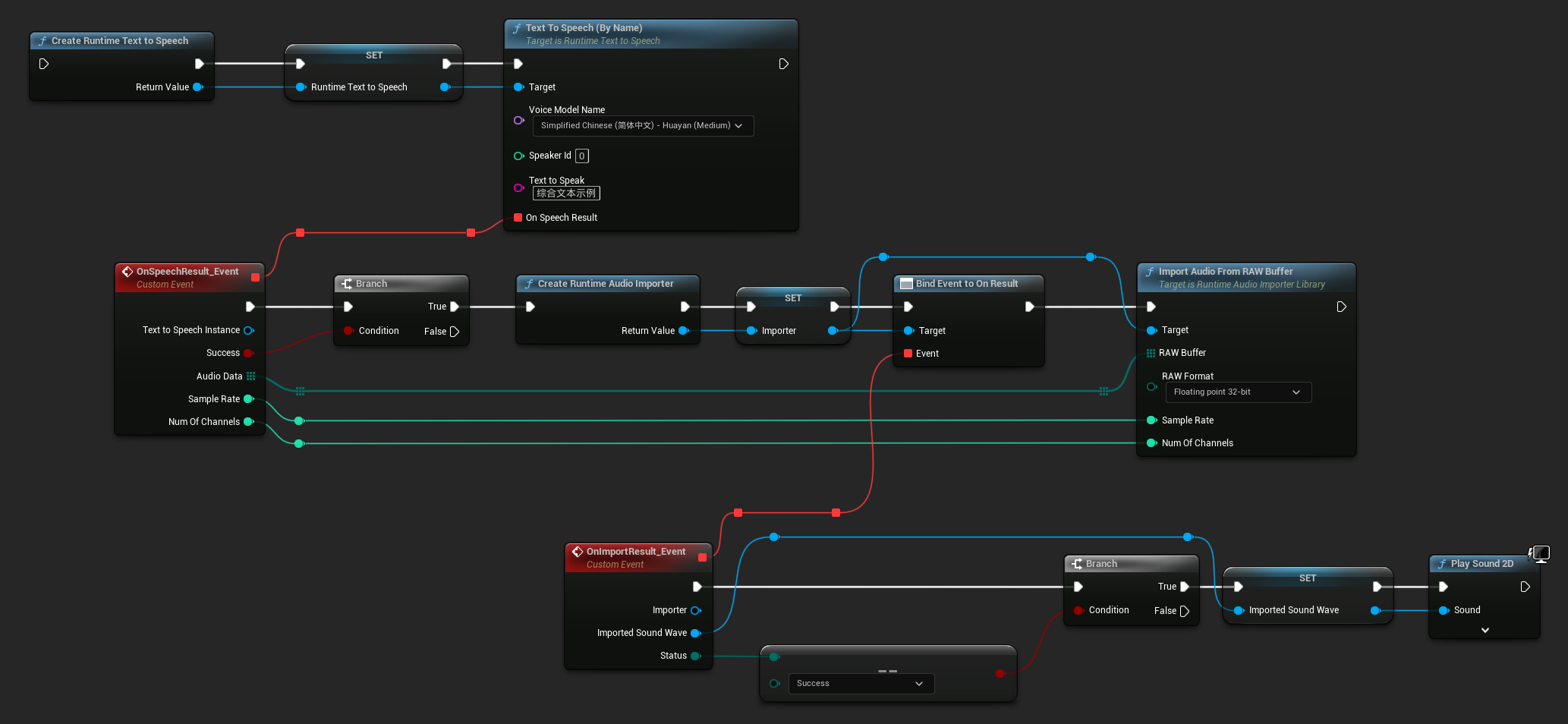
Para la reproducción, se recomienda utilizar el plugin Runtime Audio Importer para convertir los datos de audio sin procesar en una onda de sonido reproducible.
- Blueprint
- C++
Aquí hay un ejemplo de cómo podrían verse los nodos de Blueprint para sintetizar texto y reproducir el audio (Nodos copiables):
Aquí hay un ejemplo de cómo sintetizar texto y reproducir el audio en C++:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Para el texto a voz en streaming, recibirás datos de audio en fragmentos como datos PCM en formato float (como un array de bytes en Blueprints o TArray<uint8> en C++), junto con la Frecuencia de Muestreo y el Número de Canales. Cada fragmento puede procesarse inmediatamente a medida que esté disponible.
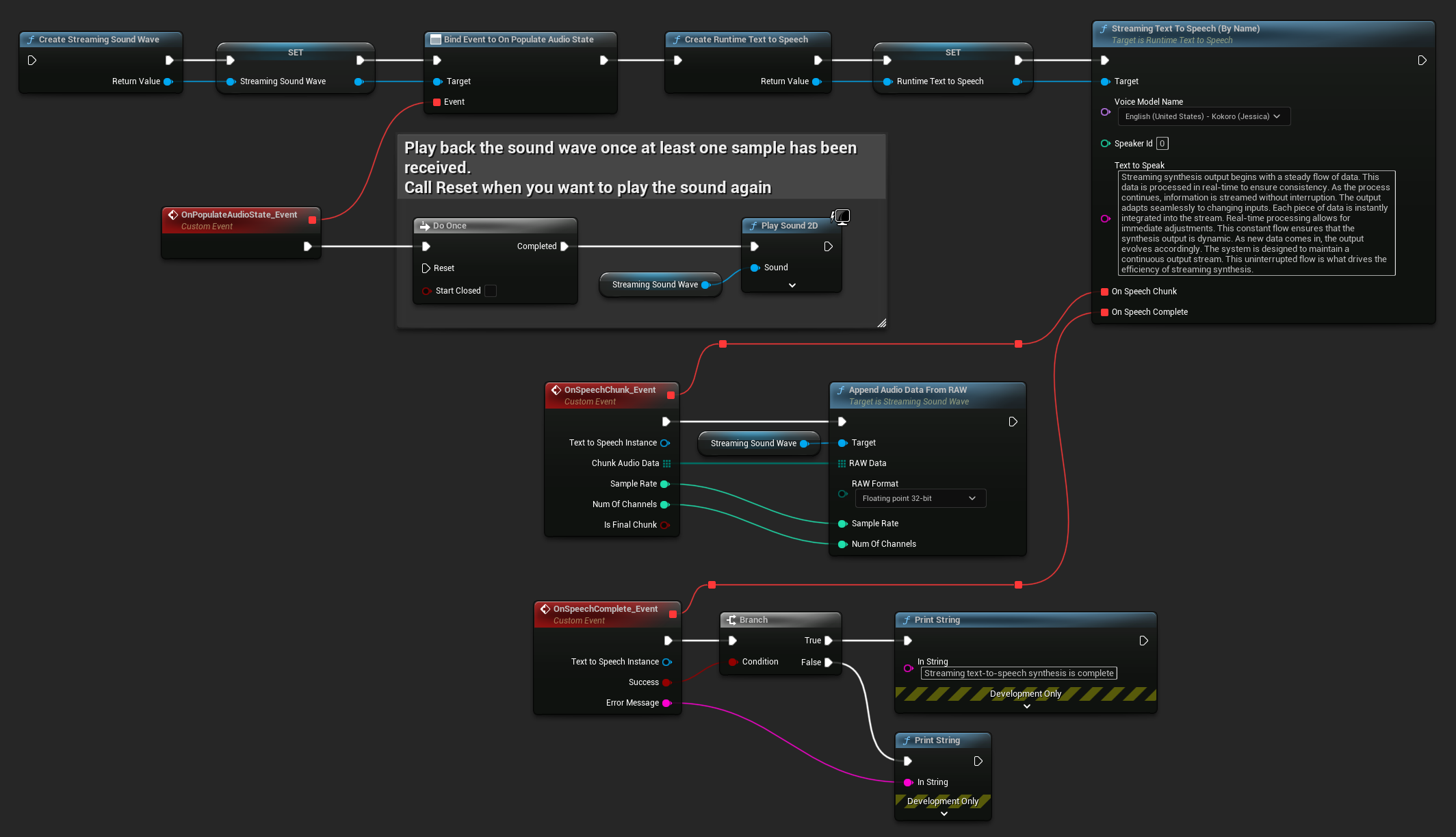
Para la reproducción en tiempo real, se recomienda utilizar el plugin Runtime Audio Importer y su Streaming Sound Wave, que está específicamente diseñado para la reproducción de audio en streaming o el procesamiento en tiempo real.
- Blueprint
- C++
Aquí tienes un ejemplo de cómo podrían verse los nodos de Blueprint para el texto a voz en streaming y la reproducción del audio (Nodos copiables):
Aquí tienes un ejemplo de cómo implementar el texto a voz en streaming con reproducción en tiempo real en C++:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Cancelación de Texto a Voz
Puedes cancelar una operación de síntesis de texto a voz en curso en cualquier momento llamando a la función CancelSpeechSynthesis en tu instancia del sintetizador:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Cuando se cancela una síntesis:
- El proceso de síntesis se detendrá lo antes posible
- Cualquier callback en curso será terminado
- El delegado de finalización será llamado con
bSuccess = falsey un mensaje de error indicando que la síntesis fue cancelada - Cualquier recurso asignado para la síntesis será limpiado apropiadamente
Esto es particularmente útil para textos largos o cuando necesitas interrumpir la reproducción para iniciar una nueva síntesis.
Selección de Speaker
Ambas funciones de Text To Speech aceptan un parámetro opcional de ID de speaker, lo cual es útil cuando se trabaja con modelos de voz que soportan múltiples speakers. Puedes usar las funciones GetSpeakerCountFromVoiceModel o GetSpeakerCountFromModelName para verificar si tu modelo de voz elegido soporta múltiples speakers. Si hay múltiples speakers disponibles, simplemente especifica tu ID de speaker deseado al llamar a las funciones de Text To Speech. Algunos modelos de voz ofrecen una amplia variedad - por ejemplo, English LibriTTS incluye más de 900 speakers diferentes para elegir.
El plugin Runtime Audio Importer también proporciona características adicionales como exportar datos de audio a un archivo, pasarlos a SoundCue, MetaSound, y más. Para más detalles, consulta la documentación de Runtime Audio Importer.