Fournisseurs de Traduction
L'AI Localization Automator prend en charge cinq fournisseurs d'IA différents, chacun avec des forces et des options de configuration uniques. Choisissez le fournisseur qui correspond le mieux aux besoins, au budget et aux exigences de qualité de votre projet.
Ollama (IA Locale)
Idéal pour : Projets sensibles à la confidentialité, traduction hors ligne, utilisation illimitée
Ollama exécute des modèles d'IA localement sur votre machine, offrant une confidentialité et un contrôle complets sans coûts d'API ni exigence de connexion Internet.
Modèles Populaires
- translategemma:12b (Modèle de traduction spécialisé basé sur Gemma 3)
- llama3.2 (Usage général recommandé)
- mistral (Alternative efficace)
- codellama (Traductions conscientes du code)
- Et bien d'autres modèles communautaires
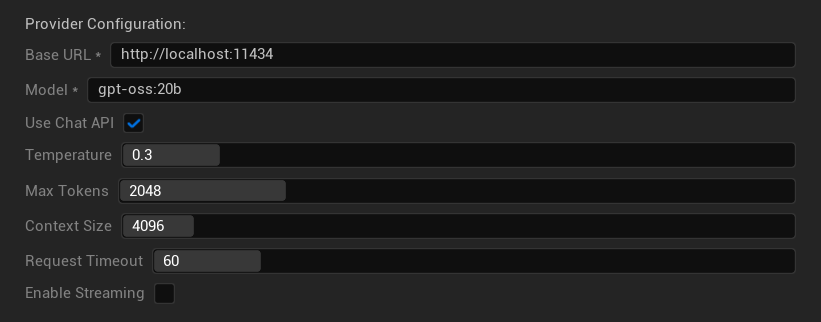
Options de Configuration
- URL de base : Serveur Ollama local (par défaut :
http://localhost:11434) - Modèle : Nom du modèle installé localement (requis)
- Utiliser l'API Chat : Activer pour une meilleure gestion des conversations
- Température : 0.0-2.0 (0.3 recommandé)
- Tokens maximum : 1-8 192 tokens
- Taille du contexte : 512-32 768 tokens
- Délai d'expiration de la requête : 10-300 secondes (les modèles locaux peuvent être plus lents)
- Activer le streaming : Pour le traitement des réponses en temps réel
Forces
- ✅ Confidentialité totale (aucune donnée ne quitte votre machine)
- ✅ Aucun coût d'API ni limite d'utilisation
- ✅ Fonctionne hors ligne
- ✅ Contrôle total des paramètres du modèle
- ✅ Grande variété de modèles communautaires
- ✅ Pas de verrouillage fournisseur
Considérations
- 💻 Nécessite une configuration locale et un matériel capable
- ⚡ Généralement plus lent que les fournisseurs cloud
- 🔧 Configuration plus technique requise
- 📊 La qualité de traduction varie considérablement selon le modèle (certains peuvent dépasser les fournisseurs cloud)
- 💾 Besoins de stockage importants pour les modèles
Configuration d'Ollama
- Installer Ollama : Téléchargez depuis ollama.ai et installez sur votre système
- Télécharger les modèles : Utilisez
ollama pull translategemma:12bpour télécharger le modèle de votre choix - Démarrer le serveur : Ollama s'exécute automatiquement, ou démarrez avec
ollama serve - Configurer le plugin : Définissez l'URL de base et le nom du modèle dans les paramètres du plugin
- Tester la connexion : Le plugin vérifiera la connectivité lorsque vous appliquerez la configuration
OpenAI
Idéal pour : La plus haute qualité de traduction globale, vaste sélection de modèles
OpenAI fournit des modèles de langage de premier plan via leur API Chat Completions, y compris les derniers modèles GPT, les modèles de raisonnement et les modèles activés pour la recherche web.
Modèles Disponibles
Famille GPT-5 (Modèles phares)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
Famille GPT-4.1 (Haute performance)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
Famille GPT-4o (Multimodale)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
Série O (Modèles de raisonnement — température/top_p non pris en charge)
- o1, o1-pro, o3, o3-mini, o4-mini
Modèles de Recherche Web (Température/top_p non pris en charge)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
Anciens / Prévisualisation
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
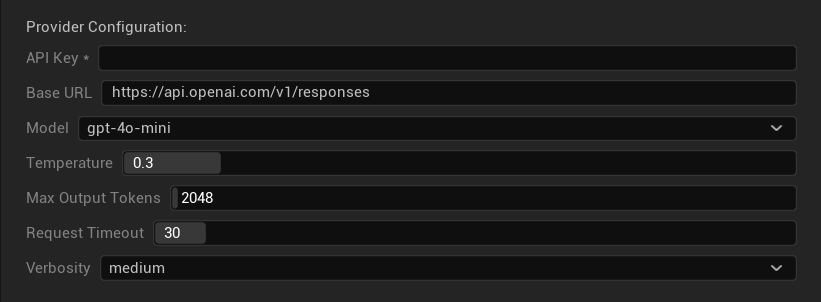
Options de Configuration
- Clé API : Votre clé API OpenAI (requise)
- URL de base : Point de terminaison de l'API (par défaut :
https://api.openai.com/v1/chat/completions) - Modèle : Choisissez parmi les modèles disponibles listés ci-dessus
- Utiliser la température : Activer/désactiver le paramètre de température (ignoré automatiquement pour les modèles de raisonnement de la série o et les modèles de recherche web)
- Température : 0.0–2.0 (0.3 recommandé pour la cohérence de la traduction)
- Top P : Paramètre d'échantillonnage nucléus 0.0–1.0 (ignoré pour les modèles de raisonnement de la série o et les modèles de recherche web)
- Tokens de complétion maximum : 1–128 000 tokens (inclut à la fois les tokens de sortie et de raisonnement)
- Délai d'expiration de la requête : 5–300 secondes
Forces
- ✅ Qualité de traduction constamment élevée
- ✅ Excellente compréhension du contexte
- ✅ Préservation forte du format
- ✅ Prise en charge linguistique étendue
- ✅ Disponibilité de l'API fiable
Considérations
- 💰 Coût plus élevé par requête
- 🌐 Nécessite une connexion Internet
- ⏱️ Limites d'utilisation basées sur le niveau
Anthropic Claude
Idéal pour : Traductions nuancées, contenu créatif, applications axées sur la sécurité
Les modèles Claude excellent dans la compréhension du contexte et des nuances, ce qui les rend idéaux pour les jeux riches en narration et les scénarios de localisation complexes.
Modèles Disponibles
Famille Claude 4.6 (Dernière version)
- claude-opus-4-6, claude-sonnet-4-6
Famille Claude 4.5
- claude-haiku-4-5 (Rapide et efficace)
- claude-sonnet-4-5, claude-opus-4-5
Famille Claude 4.x
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Famille Claude 3.x (Ancienne)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
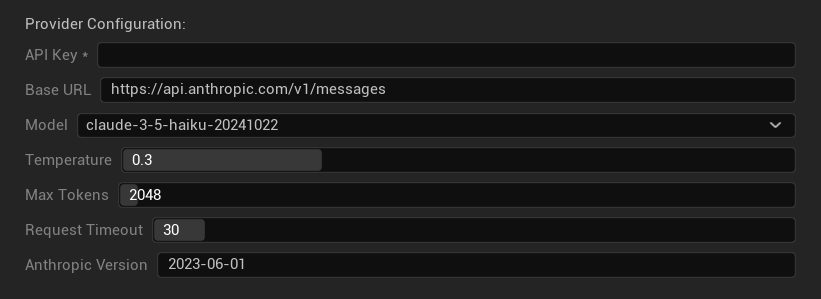
Options de Configuration
- Clé API : Votre clé API Anthropic (requise)
- URL de base : Point de terminaison de l'API Claude
- Modèle : Sélectionnez dans la famille de modèles Claude
- Température : 0.0–1.0 (0.3 recommandé)
- Top K : Paramètre d'échantillonnage Top-K (0 = non défini)
- Tokens maximum : 1–64 000 tokens
- Délai d'expiration de la requête : 5–300 secondes
- Version Anthropic : En-tête de version de l'API
Forces
- ✅ Conscience contextuelle exceptionnelle
- ✅ Excellent pour le contenu créatif/narratif
- ✅ Fonctionnalités de sécurité solides
- ✅ Capacités de raisonnement détaillées (pensée étendue sur les modèles 3.7+)
- ✅ Excellente capacité à suivre les instructions
Considérations
- 💰 Modèle de tarification premium
- 🌐 Connexion Internet requise
- 📏 Les limites de tokens varient selon le modèle
DeepSeek
Idéal pour : Traduction économique, débit élevé, projets soucieux du budget
DeepSeek offre une qualité de traduction compétitive à une fraction du coût des autres fournisseurs, ce qui le rend idéal pour les projets de localisation à grande échelle.
Modèles Disponibles
- deepseek-chat (Usage général, recommandé)
- deepseek-reasoner (Capacités de raisonnement améliorées)
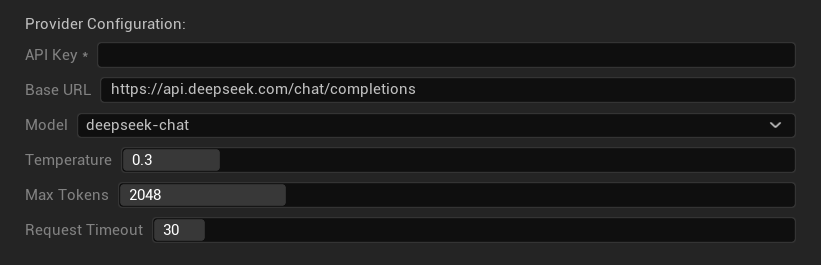
Options de Configuration
- Clé API : Votre clé API DeepSeek (requise)
- URL de base : Point de terminaison de l'API DeepSeek
- Modèle : Choisissez entre les modèles chat et reasoner
- Température : 0.0-2.0 (0.3 recommandé)
- Tokens maximum : 1-8 192 tokens
- Délai d'expiration de la requête : 5-300 secondes
Forces
- ✅ Très économique
- ✅ Bonne qualité de traduction
- ✅ Temps de réponse rapides
- ✅ Configuration simple
- ✅ Limites de débit élevées
Considérations
- 📏 Limites de tokens plus basses
- 🆕 Fournisseur plus récent (moins d'historique)
- 🌐 Nécessite une connexion Internet
Google Gemini
Idéal pour : Projets multilingues, traduction économique, intégration à l'écosystème Google
Les modèles Gemini offrent de solides capacités multilingues avec une tarification compétitive et des fonctionnalités uniques comme le mode de réflexion pour un raisonnement amélioré.
Modèles Disponibles
Famille Gemini 3.x (Prévisualisation)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Famille Gemini 2.5 (Avec support de la réflexion)
- gemini-2.5-pro (Phare avec réflexion)
- gemini-2.5-flash (Rapide, avec support de la réflexion)
- gemini-2.5-flash-lite (Variante légère)
Famille Gemini 2.0
- gemini-2.0-flash, gemini-2.0-flash-lite
Alias les plus récents
- gemini-flash-latest, gemini-flash-lite-latest
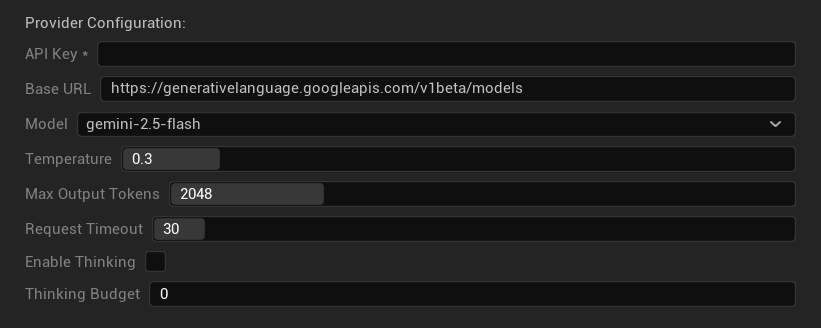
Options de Configuration
- Clé API : Votre clé API Google AI (requise)
- URL de base : Point de terminaison de l'API Gemini
- Modèle : Sélectionnez dans la famille de modèles Gemini
- Température : 0.0–2.0 (0.3 recommandé)
- Tokens de sortie maximum : 1–8 192 tokens
- Délai d'expiration de la requête : 5–300 secondes
- Activer la réflexion : Activer le raisonnement amélioré pour les modèles 2.5+
- Budget de réflexion : Contrôler l'allocation des tokens de réflexion (0 = pas de réflexion)
Forces
- ✅ Prise en charge multilingue solide
- ✅ Tarification compétitive
- ✅ Raisonnement avancé (mode réflexion)
- ✅ Intégration à l'écosystème Google
- ✅ Mises à jour régulières des modèles avec accès en prévisualisation aux modèles les plus récents
Considérations
- 🧠 Le mode réflexion augmente l'utilisation des tokens
- 📏 Limites de tokens variables selon le modèle
- 🌐 Connexion Internet requise
Choisir le Bon Fournisseur
| Fournisseur | Idéal pour | Qualité | Coût | Configuration | Confidentialité |
|---|---|---|---|---|---|
| Ollama | Confidentialité/hors ligne | Variable* | Gratuit | Avancée | Local |
| OpenAI | Qualité la plus élevée | ⭐⭐⭐⭐⭐ | 💰💰💰 | Facile | Cloud |
| Claude | Contenu créatif | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | Facile | Cloud |
| DeepSeek | Projets à budget limité | ⭐⭐⭐⭐ | 💰 | Facile | Cloud |
| Gemini | Multilingue | ⭐⭐⭐⭐ | 💰 | Facile | Cloud |
*La qualité pour Ollama varie considérablement selon le modèle local utilisé - certains modèles locaux modernes peuvent égaler ou dépasser les fournisseurs cloud.
Conseils de Configuration des Fournisseurs
Pour Tous les Fournisseurs Cloud :
- Stockez les clés API de manière sécurisée et ne les commettez pas dans le contrôle de version
- Commencez avec des paramètres de température conservateurs (0.3) pour des traductions cohérentes
- Surveillez votre utilisation de l'API et vos coûts
- Testez avec de petits lots avant les grandes sessions de traduction
Pour Ollama :
- Assurez-vous d'avoir suffisamment de RAM (8 Go+ recommandé pour les modèles plus grands)
- Utilisez un stockage SSD pour de meilleures performances de chargement des modèles
- Envisagez l'accélération GPU pour une inférence plus rapide
- Testez localement avant de vous y fier pour des traductions en production