Détection d'activité vocale
Streaming Sound Wave, ainsi que ses types dérivés tels que Capturable Sound Wave, prend en charge la détection d'activité vocale (VAD). VAD filtre les données audio entrantes pour remplir le tampon interne uniquement lorsque la voix est détectée.
Le plugin offre deux implémentations VAD :
- VAD par défaut
- Silero VAD
L'implémentation par défaut utilise libfvad, une bibliothèque légère de détection d'activité vocale qui fonctionne efficacement sur toutes les plateformes et versions de moteur prises en charge par Runtime Audio Importer.
Disponible en tant que plugin d'extension, Silero VAD est un détecteur d'activité vocale basé sur un réseau neuronal qui offre une précision supérieure, en particulier dans les environnements bruyants. Il utilise l'apprentissage automatique pour distinguer plus fiablement la parole du bruit de fond.
Utilisation de base
Pour activer la VAD après avoir créé une Sound Wave, utilisez la fonction ToggleVAD :
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
StreamingSoundWave->ToggleVAD(true);
Après avoir activé VAD, vous pouvez le réinitialiser à tout moment:
- Blueprint
- C++
// Reset the VAD
StreamingSoundWave->ResetVAD();
Paramètres VAD par défaut
Lorsque vous utilisez le fournisseur VAD par défaut, vous pouvez ajuster son agressivité en changeant le mode VAD :
- Blueprint
- C++
// Set the VAD mode (only works with the default VAD provider)
StreamingSoundWave->SetVADMode(ERuntimeVADMode::VeryAggressive);
Le paramètre mode contrôle l'agressivité avec laquelle le VAD filtre l’audio. Des valeurs plus élevées sont plus restrictives, ce qui signifie qu’elles sont moins susceptibles de signaler des faux positifs, mais risquent de manquer certains passages parlés.
Fournisseurs VAD
Après avoir activé la VAD avec la fonction ToggleVAD, vous pouvez choisir entre différents fournisseurs de détection d'activité vocale pour répondre à vos besoins. Le fournisseur par défaut est intégré, tandis que des fournisseurs supplémentaires tels que Silero VAD sont disponibles via des plugins d'extension.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Make sure to call ToggleVAD(true) before setting the provider
// Set the VAD provider to Silero VAD
StreamingSoundWave->SetVADProvider(URuntimeSileroVADProvider::StaticClass());
Obtention du fournisseur VAD actuel
Vous pouvez récupérer le fournisseur VAD actuellement assigné à une onde sonore en streaming en utilisant la fonction GetVADProvider. Cela est utile lorsque vous devez accéder à des fonctionnalités spécifiques au fournisseur, telles que les paramètres de seuil de parole du Silero VAD, sans avoir à conserver une référence séparée.
- Blueprint
- C++
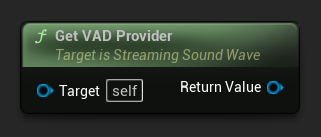
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Get the currently assigned VAD provider
URuntimeVADProviderBase* VADProvider = StreamingSoundWave->GetVADProvider();
Pour accéder aux fonctionnalités spécifiques au fournisseur, castez le fournisseur retourné vers le type souhaité. Par exemple, pour accéder aux fonctionnalités spécifiques à Silero VAD :
- Blueprint
- C++
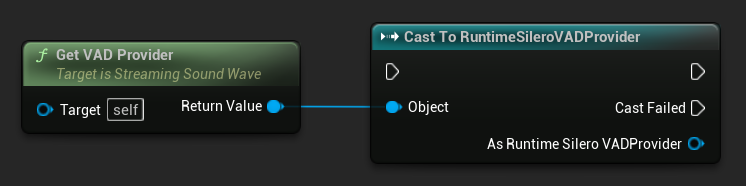
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Get the currently assigned VAD provider and cast it to the Silero VAD provider
if (URuntimeSileroVADProvider* SileroVADProvider = Cast<URuntimeSileroVADProvider>(StreamingSoundWave->GetVADProvider()))
{
// Use Silero VAD-specific functionality, such as SetSpeechThreshold
}
Silero VAD Extension
Silero VAD fournit une détection de la parole plus précise utilisant des réseaux neuronaux. Pour l'utiliser :
-
Assurez-vous que le plugin Runtime Audio Importer est déjà installé dans votre projet.
-
Pour UE 5.5 et versions antérieures : Avant de télécharger le plugin d'extension Silero VAD, assurez-vous que NNERuntimeORT est désactivé dans votre projet. Avoir NNERuntimeORT activé peut provoquer des plantages lors de l'utilisation de Silero VAD sur ces versions du moteur en raison de conflits.
-
Téléchargez le plugin d'extension Silero VAD depuis ici
-
Extrayez le dossier de l'archive téléchargée dans le dossier
Pluginsde votre projet (créez ce dossier s'il n'existe pas). -
Pour UE 5.6 et versions ultérieures : Modifiez le fichier
RuntimeAudioImporterSileroVAD.upluginpour ajouter la dépendance NNERuntimeORT. Dans le champ "Plugins", après l'inclusion de RuntimeAudioImporter, ajoutez :,{"Name": "NNERuntimeORT","Enabled": true} -
Reconstruisez votre projet (cette extension nécessite un projet C++)
-
Le VAD par défaut fonctionne avec toutes les versions du moteur prises en charge par Runtime Audio Importer (UE 4.24, 4.25, 4.26, 4.27, 5.0, 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7 et 5.8)
-
Silero VAD prend en charge Unreal Engine 4.27 et toutes les versions d'UE5 (4.27, 5.0, 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7 et 5.8)
-
UE 5.5 et versions antérieures : NNERuntimeORT doit être désactivé avant d’utiliser Silero VAD pour éviter des plantages dus à des conflits de plugins. Dans UE 5.3 spécifiquement, NNERuntimeORTCpu et NNERuntimeORTGpu doivent également être désactivés.
-
Exigence UE 5.6+ : À partir d'Unreal Engine 5.6, l'extension Silero VAD nécessite que la dépendance du plugin NNERuntimeORT soit ajoutée manuellement au fichier
.uplugin. -
Silero VAD est disponible pour Windows, Linux, Mac, Android (y compris Meta Quest) et iOS.
-
Cette extension est fournie sous forme de code source et nécessite un projet C++ pour être utilisée.
-
Pour plus d'informations sur la compilation manuelle de plugins, consultez le tutoriel Construction de plugins.
Une fois installé, vous pouvez le sélectionner comme votre fournisseur VAD en utilisant la fonction SetVADProvider avec le fournisseur de classe Silero.
Seuil de parole
Le fournisseur Silero VAD expose un paramètre Speech Threshold qui contrôle le score de confiance minimum (issu de la sortie de probabilité de parole du réseau neuronal) requis pour considérer un segment audio comme de la parole. Vous pouvez le définir à l'aide de la fonction SetSpeechThreshold, disponible après avoir récupéré le fournisseur avec GetVADProvider et l’avoir converti en type de fournisseur Silero VAD.
- Blueprint
- C++
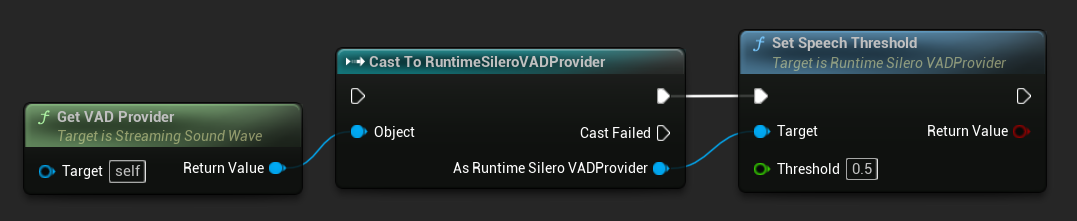
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Make sure the VAD provider has already been set to Silero VAD via SetVADProvider
// Get the VAD provider and cast it to the Silero VAD provider
if (URuntimeSileroVADProvider* SileroVADProvider = Cast<URuntimeSileroVADProvider>(StreamingSoundWave->GetVADProvider()))
{
// Set the speech threshold
bool bSuccess = SileroVADProvider->SetSpeechThreshold(0.5f);
}
SetSpeechThreshold retourne true si le seuil a été appliqué avec succès, et false sinon (par exemple, si la valeur est hors de la plage valide).
Un seuil plus élevé rend la détection plus conservatrice : il réduit les faux positifs dus au bruit de fond, mais il peut également manquer les paroles plus faibles ou moins claires. Un seuil plus bas rend la détection plus sensible : il capte davantage de paroles, mais le risque de faux positifs augmente. La valeur par défaut est 0.5.
Détection du début et de la fin de la parole
La détection d'activité vocale ne se limite pas à détecter la présence de parole, mais permet également de détecter le début et la fin de l'activité vocale. C'est utile pour déclencher des événements lorsque la parole commence ou se termine pendant la lecture ou la capture.
Vous pouvez personnaliser la sensibilité de la détection du début et de la fin de la parole en ajustant des paramètres tels que la durée minimale de parole et la durée de silence. Ces paramètres aident à affiner la détection pour éviter les faux positifs, comme capter des bruits brefs ou des pauses trop courtes entre les paroles.
Durée minimale de parole
Le paramètre Minimum Speech Duration définit la durée minimale d'activité vocale continue requise pour déclencher un événement de début de parole. Cela permet de filtrer les bruits brefs qui ne devraient pas être considérés comme de la parole, afin de garantir que seule une activité vocale soutenue soit reconnue. La valeur par défaut de Minimum Speech Duration est 300 millisecondes.
- Blueprint
- C++
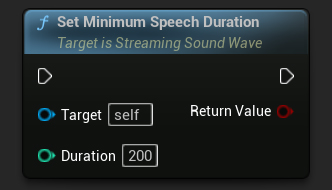
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Set the minimum speech duration
StreamingSoundWave->SetMinimumSpeechDuration(200);
Durée du silence
Le paramètre Durée de silence définit la durée de silence nécessaire pour déclencher un événement de fin de parole. Cela empêche la détection vocale de se terminer prématurément lors des pauses naturelles entre les mots ou les phrases. La valeur par défaut de Durée de silence est de 500 millisecondes.
- Blueprint
- C++
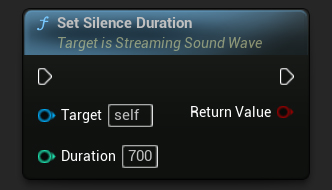
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Set the silence duration
StreamingSoundWave->SetSilenceDuration(700);
Liaison aux Speech Delegates
Vous pouvez vous lier à des délégués spécifiques lorsque la parole commence ou se termine. Cela est utile pour déclencher un comportement personnalisé basé sur l'activité vocale, comme démarrer ou arrêter la reconnaissance de texte, ou régler le volume d'autres sources audio.
- Blueprint
- C++
// Assuming StreamingSoundWave is a UE reference to a UStreamingSoundWave object (or its derived type, such as UCapturableSoundWave)
// Bind to the OnSpeechStartedNative delegate
StreamingSoundWave->OnSpeechStartedNative.AddWeakLambda(this, [this]()
{
// Handle the result when speech starts
});
// Bind to the OnSpeechEndedNative delegate
StreamingSoundWave->OnSpeechEndedNative.AddWeakLambda(this, [this]()
{
// Handle the result when speech ends
});
Comparaison des fournisseurs VAD
- VAD par défaut
- Silero VAD
VAD par défaut (libfvad)
Avantages:
- Léger et efficace
- Fonctionne sur toutes les plateformes
- Utilisation minimale des ressources
- Adapté aux appareils mobiles et à faible consommation
Idéal pour:
- Détection vocale simple dans des environnements calmes
- Applications mobiles
- Projets où la performance est une priorité
- Lorsque la prise en charge universelle des plateformes est requise
Silero VAD
Avantages :
- Précision accrue dans la détection vocale
- Tolérance au bruit supérieure dans les environnements difficiles
- Résultats plus cohérents entre différents locuteurs
- Options de configuration avancées pour un contrôle précis
Idéal pour :
- Applications nécessitant une détection vocale précise
- Environnements avec bruit de fond
- Systèmes de reconnaissance vocale
- Applications audio professionnelles
Silero VAD peut nécessiter plus de ressources de calcul que le VAD par défaut.