Comment utiliser le plugin
Ce guide couvre l'API d'exécution complète : création d'une instance LLM, chargement de modèles, envoi de messages, téléchargement de modèles à l'exécution, gestion d'état et fonctions utilitaires.
Créez une instance LLM
Commencez par créer un objet Runtime Local LLM. Conservez une référence vers celui-ci (par exemple en tant que variable dans les Blueprints ou une UPROPERTY en C++) pour éviter une collecte de déchets prématurée.
- Blueprint
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
Charger un modèle
Vous devez charger un modèle avant d'envoyer des messages. Le plugin propose plusieurs méthodes de chargement selon votre flux de travail.
Charger par nom
Si vous gérez les modèles via le panneau des paramètres de l'éditeur, utilisez Load Model (By Name).
- Blueprint
- C++
- UE 5.3 et versions antérieures
- UE 5.4+
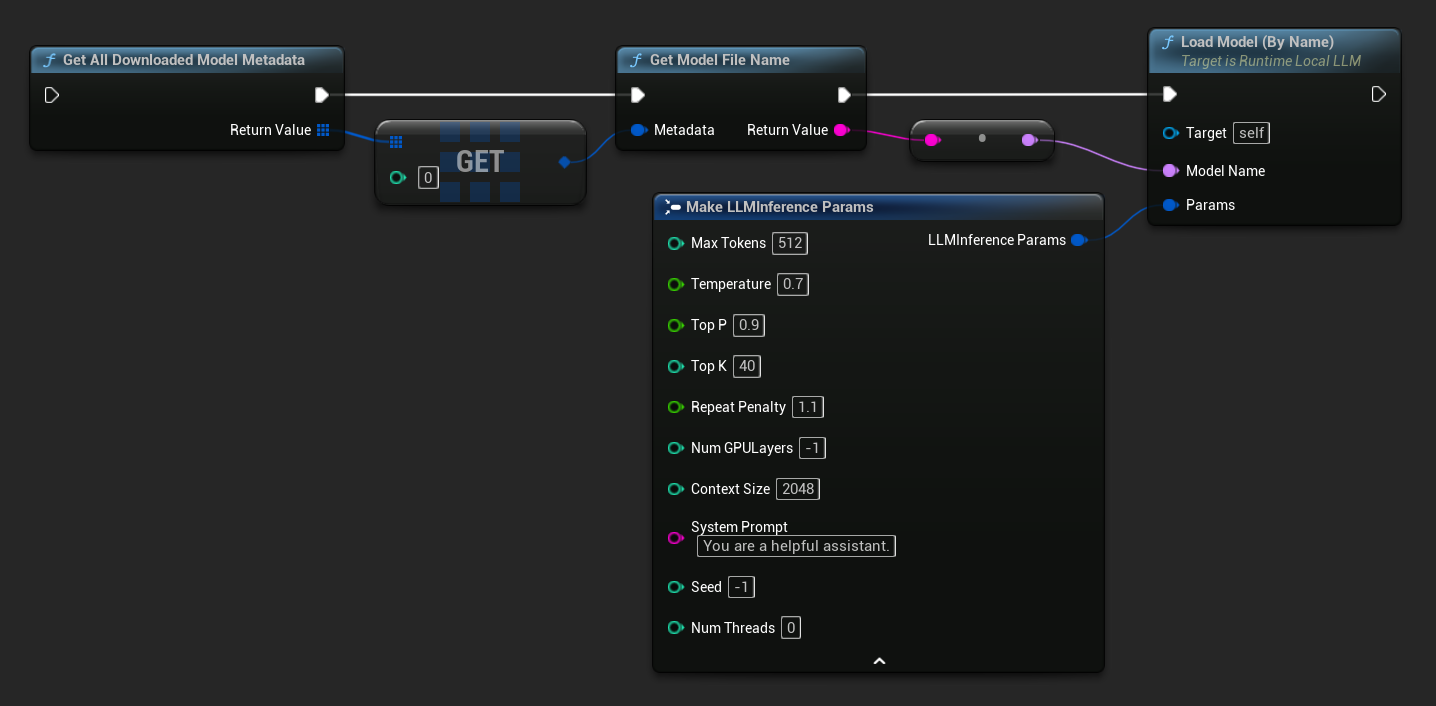
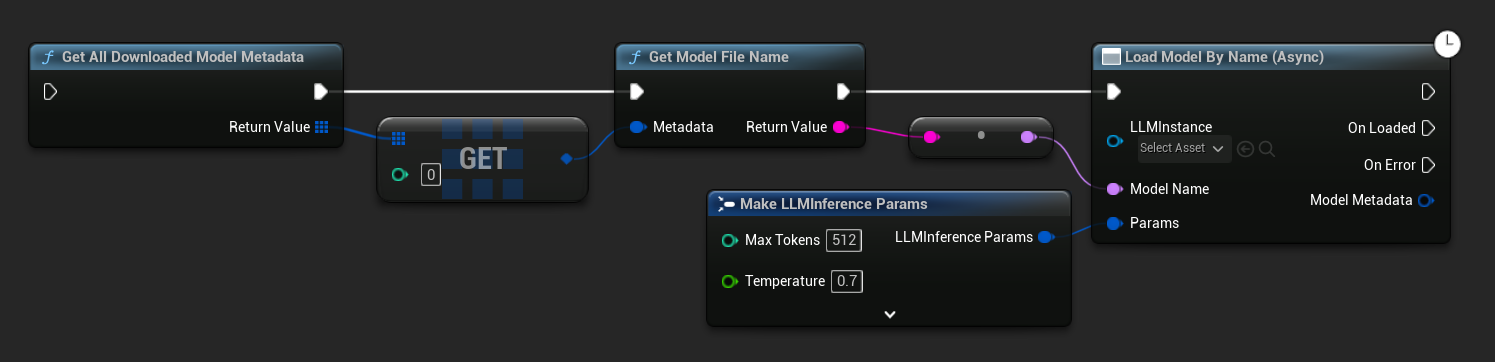
Dans UE 5.3 et versions antérieures, le menu déroulant n'apparaît pas, vous devez donc récupérer les modèles disponibles manuellement. Utilisez Get All Downloaded Model Metadata, obtenez l'élément à l'index 0 (ou le modèle dont vous avez besoin), passez-le à Get Model File Name pour récupérer la chaîne de nom, puis transmettez-la à Load Model (By Name).
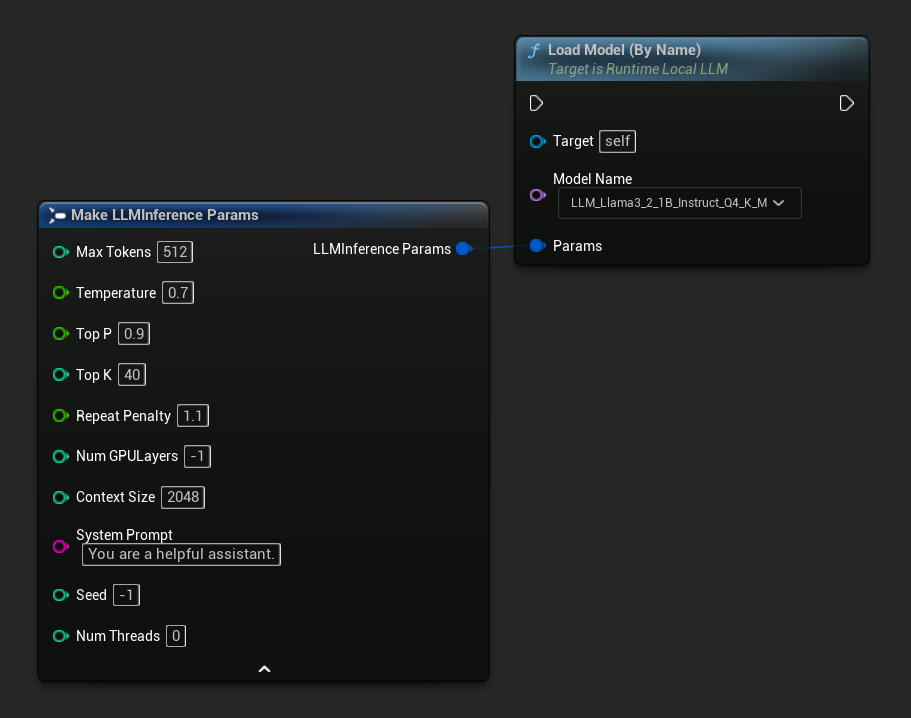
Dans UE 5.4 et versions ultérieures, Load Model (By Name) présente une liste déroulante de tous les modèles sur le disque – sélectionnez simplement le modèle que vous souhaitez charger.
En C++, utilisez GetAllDownloadedModelMetadata pour récupérer les modèles disponibles et GetModelFileName pour obtenir le nom à passer à LoadModelByName.
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
Charger depuis le chemin de fichier
Chargez un modèle directement depuis un chemin de fichier absolu vers un fichier .gguf :
- Blueprint
- C++
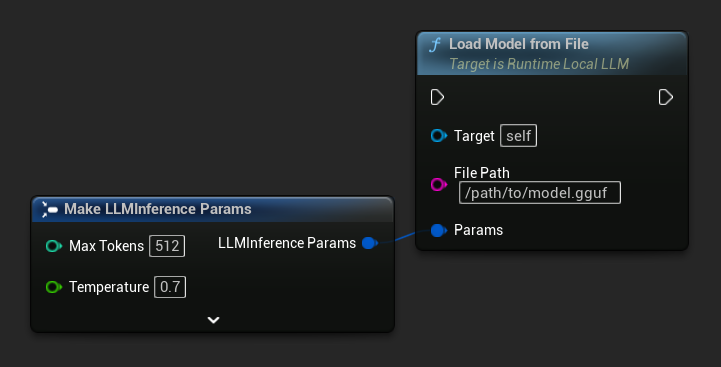
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
Charger depuis une URL (Télécharger et charger)
Télécharge un modèle depuis une URL (s'il n'est pas déjà sur le disque) et le charge automatiquement. Si le fichier existe déjà localement, le téléchargement est ignoré.
- Blueprint
- C++
La variante la plus simple ne prend qu'une URL - les métadonnées sont dérivées du nom de fichier :
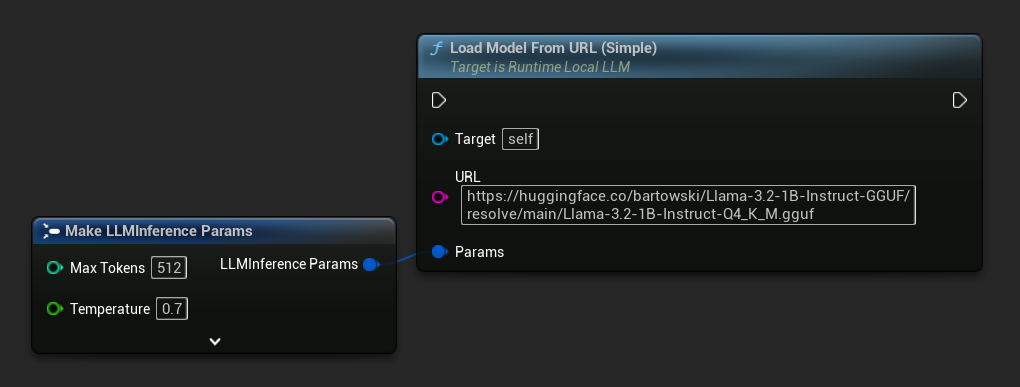
Vous pouvez également utiliser Load Model From URL avec les métadonnées complètes du modèle pour obtenir des informations plus riches sur celui-ci.
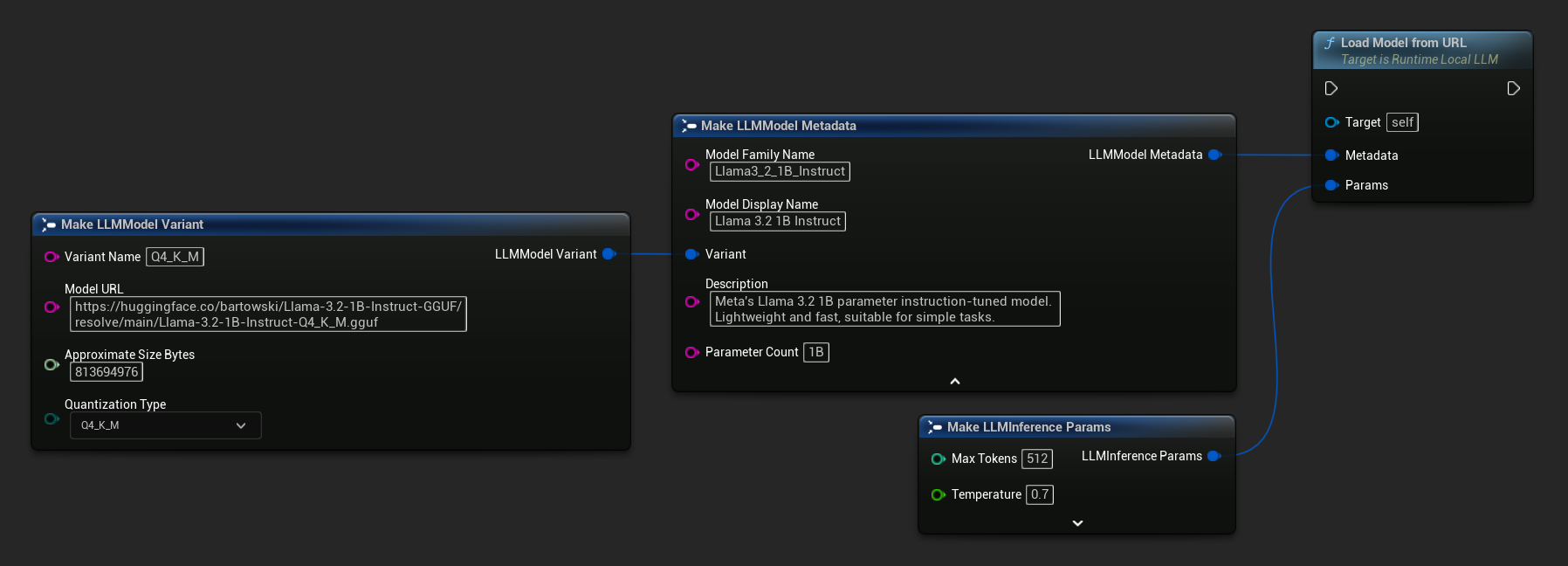
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
Chargement asynchrone (Blueprint)
Pour gérer la fin du chargement et les erreurs via des broches de sortie au lieu de lier manuellement des délégués, deux nœuds asynchrones sont disponibles.
Load Model By Name (Async) reflète Load Model (By Name) - dans UE 5.4+, il présente une liste déroulante de tous les modèles sur le disque :
- UE 5.4+
- UE 5.3 et versions antérieures
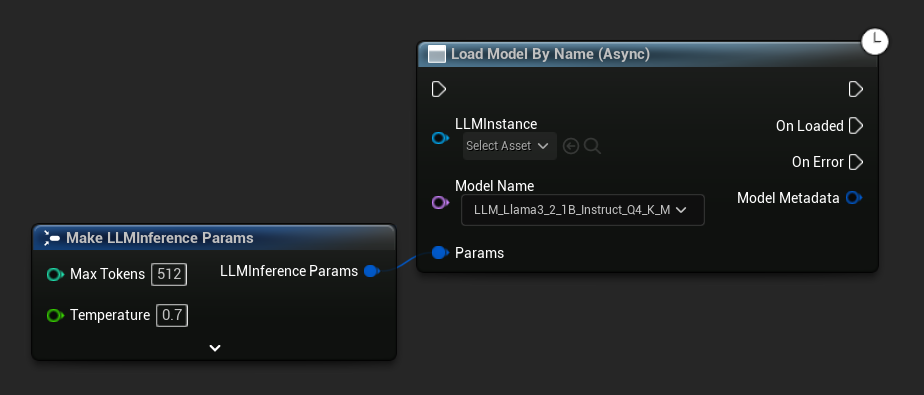
Dans UE 5.3 et versions antérieures, le menu déroulant n'apparaît pas. Utilisez Get All Downloaded Model Metadata, récupérez l'élément à l'index 0 (ou le modèle dont vous avez besoin), transmettez-le à Get Model File Name, puis transmettez-le à Load Model By Name (Async).
Load Model From File (Async) prend un chemin de fichier absolu à la place :
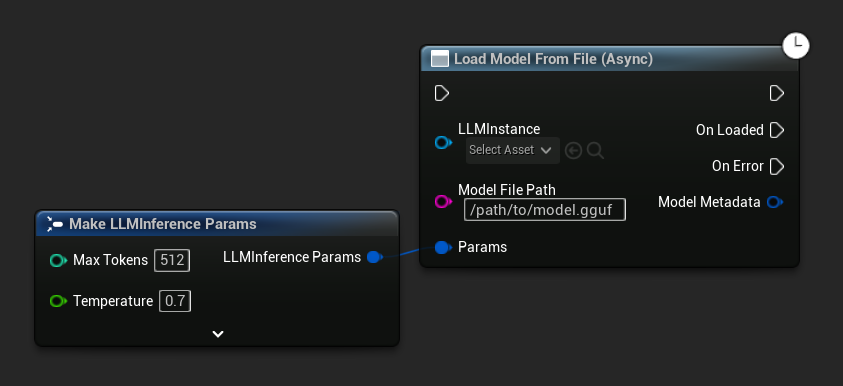
Lier les événements
Liez-vous aux délégués de l'instance LLM pour recevoir des rappels. Tous les rappels sont déclenchés sur le thread de jeu.
- Blueprint
- C++
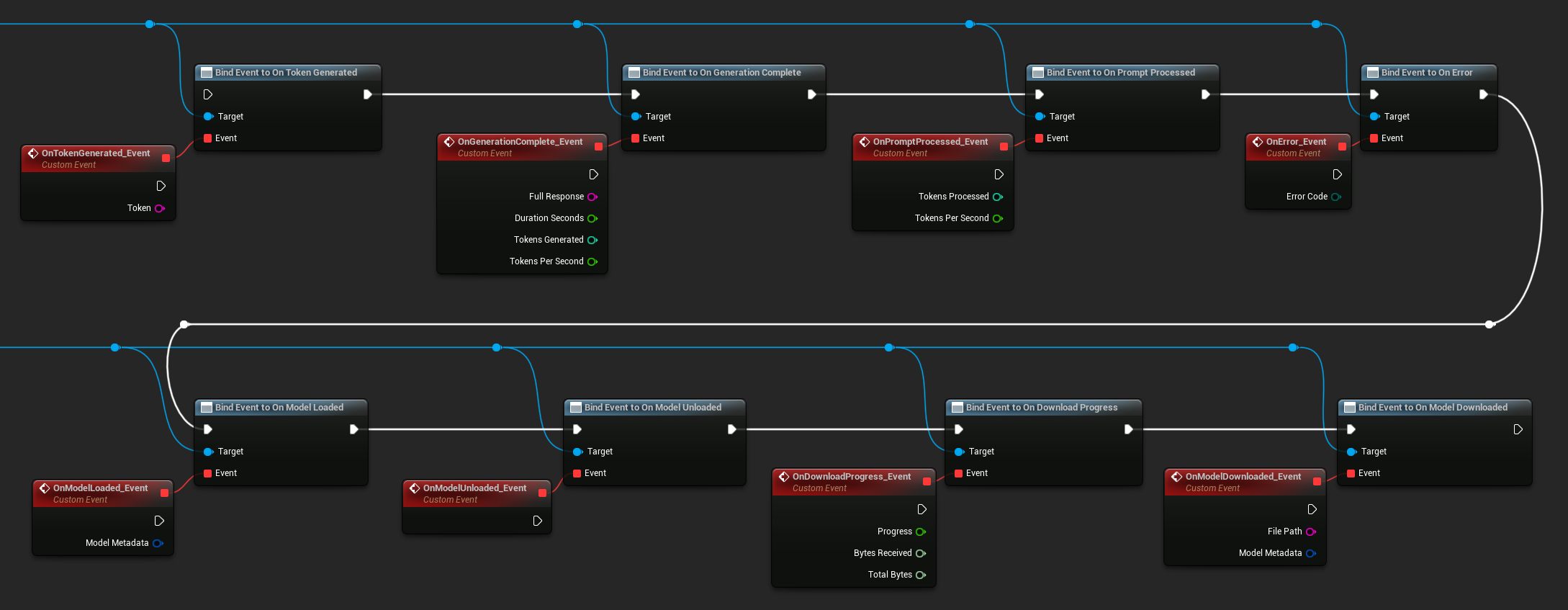
Délégués disponibles :
- Sur jeton généré : se déclenche pour chaque jeton de sortie
- Sur génération terminée : se déclenche lorsque la réponse complète est prête, avec la durée, le nombre de jetons et les jetons par seconde
- Sur invite traitée : se déclenche après le traitement de l'invite d'entrée, avant le début de la génération
- Sur erreur : se déclenche si une erreur survient pendant une opération
- Sur modèle chargé : se déclenche lorsqu'un modèle a fini de se charger
- Sur modèle déchargé : se déclenche lorsque le modèle est déchargé
- Sur progression du téléchargement : se déclenche périodiquement pendant le téléchargement d'un modèle (fraction de progression, octets reçus, octets totaux)
- Sur modèle téléchargé : se déclenche lorsqu'une opération de téléchargement uniquement est terminée
- Sur conversation sauvegardée : se déclenche lorsqu'une conversation a été écrite dans un fichier JSON
- Sur conversation chargée : se déclenche lorsqu'une conversation a été chargée depuis un fichier ou un instantané mémoire
- Sur historique résumé : se déclenche lorsque l'auto-résumé compresse les messages plus anciens (rapporte le nombre de messages, les jetons économisés et le résumé)
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda(
[](const FString& FullResponse, float DurationSeconds, int32 TokensGenerated, float TokensPerSecond)
{
});
LLM->OnPromptProcessedNative.AddLambda([](int32 TokensProcessed, float TokensPerSecond)
{
});
LLM->OnErrorNative.AddLambda([](ELLMErrorCode ErrorCode)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnModelUnloadedNative.AddLambda([]()
{
});
LLM->OnDownloadProgressNative.AddLambda([](float Progress, int64 BytesReceived, int64 TotalBytes)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& FilePath, const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnConversationSavedNative.AddLambda([](const FString& FilePath)
{
});
LLM->OnConversationLoadedNative.AddLambda([](const FLLMConversationSnapshot& Snapshot)
{
});
LLM->OnHistorySummarizedNative.AddLambda([](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
});
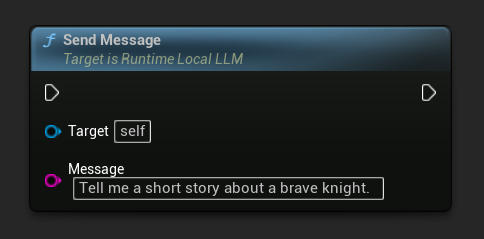
Envoyer des messages
Une fois le modèle chargé, envoyez un message utilisateur pour générer une réponse :
- Blueprint
- C++
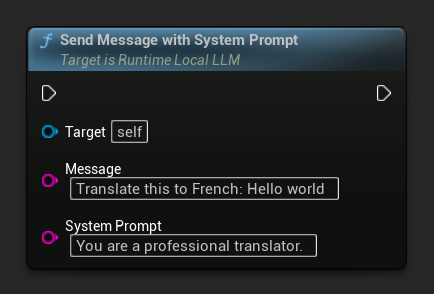
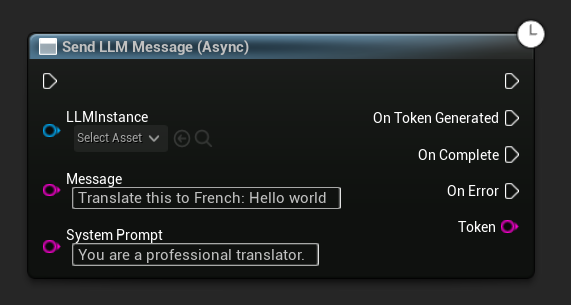
Pour remplacer le prompt système pour un message spécifique, utilisez Send Message With System Prompt :
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
Les jetons transitent via OnTokenGenerated au fur et à mesure de leur production. Lorsque la génération se termine, OnGenerationComplete se déclenche avec la réponse complète, la durée, le nombre de jetons et les jetons par seconde.
Envoyer un message de manière asynchrone (Blueprint)
Le nœud Envoyer un message LLM (Async) fournit des broches de sortie dédiées pour les jetons, la complétion et les erreurs :
Télécharger des modèles à l'exécution
Outre le flux de téléchargement et chargement décrit ci-dessus, vous pouvez télécharger un modèle sur le disque sans le charger. Cela est utile pour pré-mettre en cache des modèles dans un écran de chargement ou un menu de paramètres.
- Blueprint
- C++
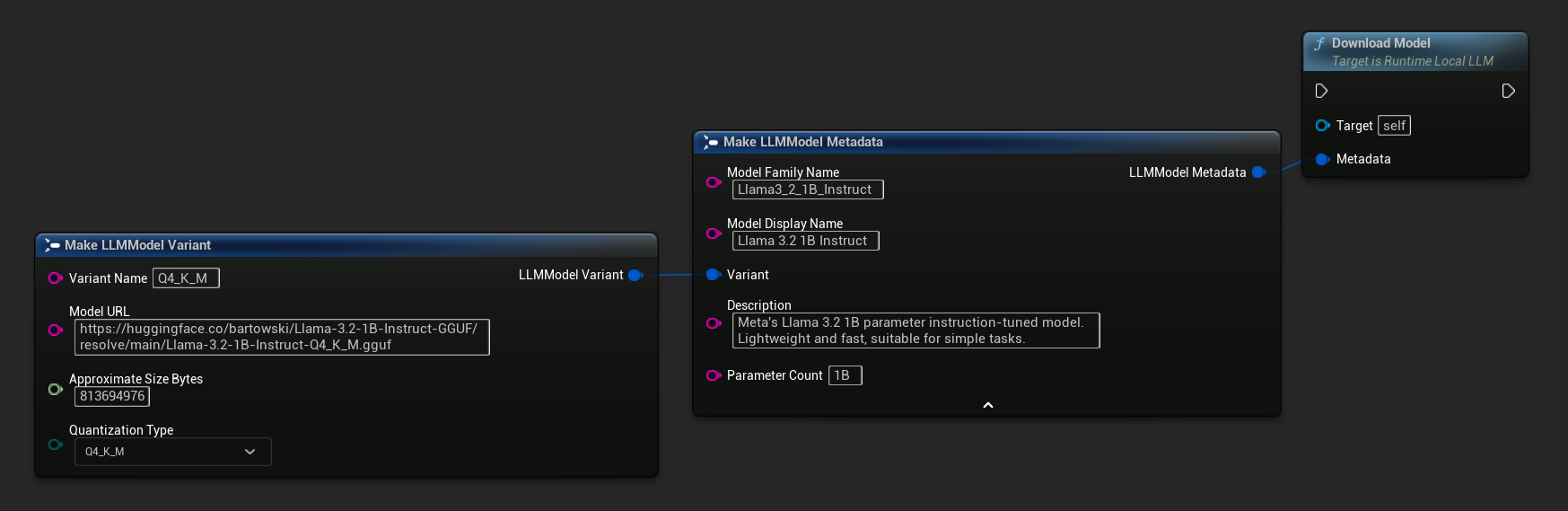
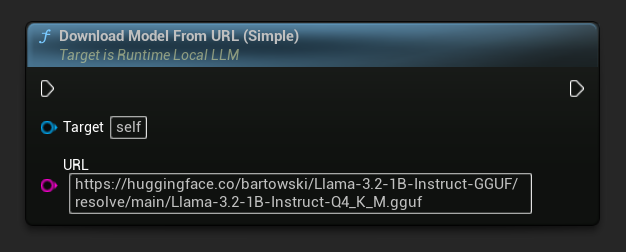
Une variante uniquement URL est également disponible :
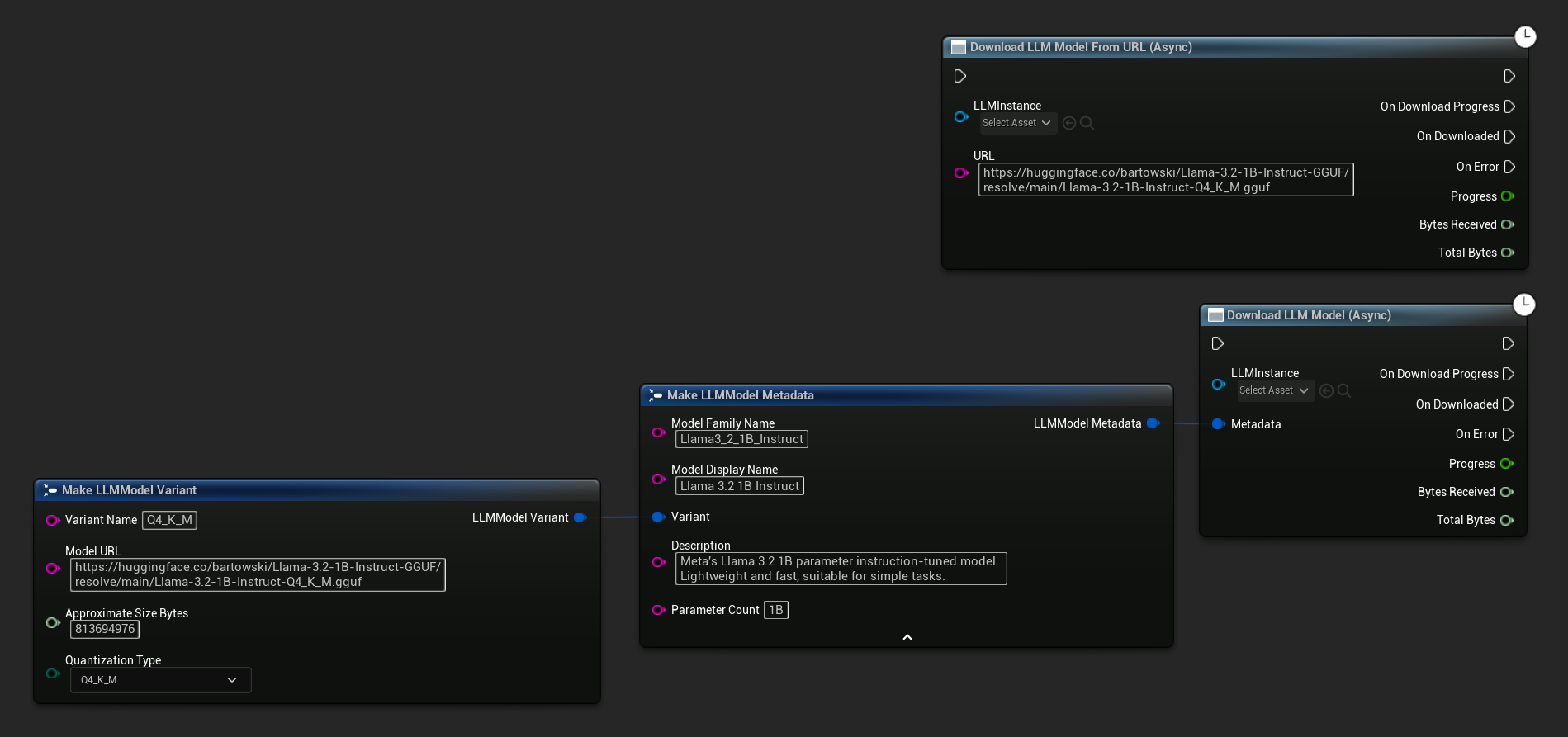
Les nœuds Download LLM Model (Async) et Download LLM Model From URL (Async) fournissent des broches de sortie pour la progression, l'achèvement et les erreurs :
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
Le délégué OnDownloadProgress signale la progression pendant le téléchargement. OnModelDownloaded se déclenche lorsque le fichier est enregistré sur le disque.
Pour annuler un téléchargement en cours :
- Blueprint
- C++
LLM->CancelDownload();
Le plugin empêche automatiquement les téléchargements en double : si un téléchargement est déjà en cours pour le même modèle, les appels suivants sont ignorés.
Arrêter la génération
Pour interrompre une génération en cours :
- Blueprint
- C++
LLM->StopGeneration();
Réinitialiser le contexte de la conversation
Effacez l'historique de la conversation pour en démarrer une nouvelle :
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
Enregistrer et charger les conversations
Le plugin peut conserver l'historique des conversations sur le disque au format JSON ou le garder en mémoire sous forme d'instantané. Par défaut, l'invite système est exclue des sauvegardes, de sorte que le même historique de conversation peut être chargé dans différentes instances LLM avec des règles système différentes. Ceci est utile pour les scénarios multi-PNJ, où chaque personnage a sa propre mémoire mais peut partager ou différer dans ses instructions système.
Enregistrer dans un fichier
Enregistrez la conversation actuelle dans un fichier JSON sur le disque.
- Blueprint
- C++
Le paramètre Include System Prompt contrôle si le message système (s'il est présent) est écrit dans le fichier. La valeur par défaut est false pour la portabilité entre les PNJ.
On Conversation Saved se déclenche lorsque le fichier est écrit.
// Excludes system prompt by default
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"));
// Include the system prompt in the file
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"), /*bIncludeSystemPrompt=*/ true);
Charger depuis un fichier
Charger une conversation à partir d’un fichier JSON :
- Blueprint
- C++
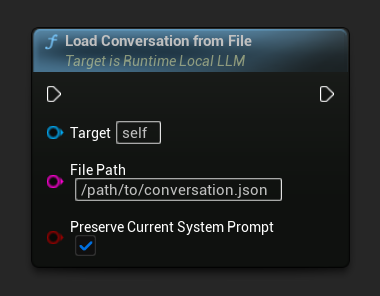
Le paramètre Conserver l'invite système actuelle (par défaut true) maintient l'invite système actuellement chargée intacte tout en échangeant l'historique de conversation sauvegardé. Il s'agit du paramètre recommandé pour l'échange de mémoire des PNJ.
Sur Conversation Chargée se déclenche avec l'instantané chargé.
// Keep current system prompt, swap in the saved history
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"));
// Replace the system prompt with whatever's in the file
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"), /*bPreserveCurrentSystemPrompt=*/ false);
Captures instantanées en mémoire (Workflow Multi-PNJ)
Pour un échange rapide de PNJ pendant le jeu, enregistrez la conversation en cours en mémoire plutôt que de l'écrire sur le disque. Ce modèle est la méthode recommandée pour gérer de nombreux PNJ partageant un seul modèle chargé :
- Blueprint
- C++
Le modèle multi-PNJ typique utilise une Map de Nom → Instantané de Conversation LLM sur votre gestionnaire de PNJ ou état de jeu :
- Lorsque vous quittez un PNJ : appelez
Save Conversation To Memory, puis dansOn Conversation Loaded(qui se déclenche également pour la livraison d’instantané), stockez l’instantané dans votre carte indexée par le nom du PNJ. - Lorsque vous passez à un autre PNJ : lisez l’instantané depuis votre carte et appelez
Load Conversation From Memoryavec l’optionPreserve Current System Promptactivée.

Puisque le prompt système reste chargé lors des changements, la « personnalité » de chaque PNJ peut être soit encodée dans un prompt système par PNJ (appelez Send Message With System Prompt une fois après un changement pour le mettre à jour), soit partagée entre tous les PNJ.
// Maintain per-NPC snapshots
UPROPERTY()
TMap<FName, FLLMConversationSnapshot> NPCMemories;
// Save the currently active NPC's memory before switching
LLM->OnConversationLoadedNative.AddLambda([this](const FLLMConversationSnapshot& Snapshot)
{
NPCMemories.Add(CurrentNPC, Snapshot);
});
LLM->SaveConversationToMemory();
// Activate another NPC's memory
if (const FLLMConversationSnapshot* Found = NPCMemories.Find(NextNPC))
{
LLM->LoadConversationFromMemory(*Found, /*bPreserveCurrentSystemPrompt=*/ true);
CurrentNPC = NextNPC;
}
Les instantanés sont indépendants du modèle : ils stockent les messages, pas l'état du cache KV. Un même instantané peut être chargé dans un modèle différent (bien que le style conversationnel puisse changer). Le champ OriginModelFamilyName sur l'instantané vous permet de vérifier quel modèle l'a produit, si vous souhaitez imposer une compatibilité.
Résumé automatique du contexte
Les conversations longues finissent par dépasser la fenêtre de contexte du modèle, ce qui normalement tronquerait l'historique ou provoquerait des erreurs. La fonction de résumé automatique du plugin surveille l'utilisation du contexte et, lorsqu'un seuil configuré est dépassé, résume les messages plus anciens en un seul message de « mémoire » avant que la réponse suivante ne soit générée. Cela maintient les coûts de tokens et la latence stables pour des conversations d'une durée indéfinie.
La synthèse est effectuée par le même modèle chargé, donc aucun second modèle ni appel API n'est nécessaire.
Activer la synthèse automatique
- Blueprint
- C++
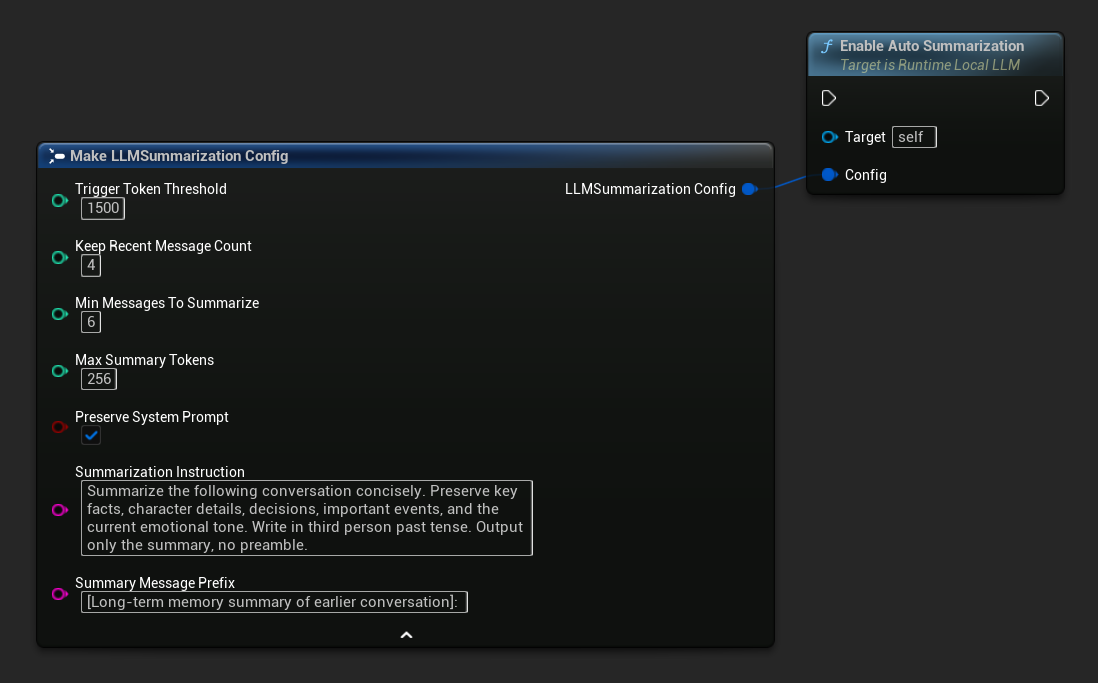
Utilisez Get Default Summarization Config pour obtenir des valeurs par défaut raisonnables, puis ajustez selon vos besoins :
FLLMSummarizationConfig Config = URuntimeLocalLLM::GetDefaultSummarizationConfig();
Config.TriggerTokenThreshold = 1500;
Config.KeepRecentMessageCount = 4;
Config.MinMessagesToSummarize = 6;
LLM->EnableAutoSummarization(Config);
Une fois activé, le résumé s'exécute automatiquement avant chaque appel SendMessage lorsque nécessaire, sans action supplémentaire requise.
Par défaut, le résumé automatique s'exécute avant le traitement d'un nouveau message, car il doit reconstruire le contexte, ce qui ne peut pas se faire en toute sécurité en même temps que la génération d'une réponse. Si vous préférez qu'il s'exécute après la réponse, pendant que le joueur lit et tape, désactivez le résumé automatique et pilotez-le manuellement : liez-vous à On Generation Complete, vérifiez Get Used Context Length par rapport à votre seuil, et appelez Summarize Now si celui-ci est dépassé. Comme Summarize Now se met en file d'attente sur la même file de tâches en arrière-plan, il s'exécutera juste après la fin de la réponse et avant le traitement du message suivant.
Référence de configuration
| Paramètre | Type | Défaut | Description |
|---|---|---|---|
| Seuil de déclenchement du jeton | int32 | 1500 | La synthèse s'exécute lorsque les jetons de contexte utilisés dépassent cette valeur. Définissez-la par rapport à votre Context Size ; environ 60 à 75 % est une bonne règle empirique. |
| Conserver le nombre de messages récents | int32 | 4 | Les N messages les plus récents ne sont jamais résumés, préservant ainsi la cohérence immédiate de la conversation. |
| Messages Minimum à Résumer | int32 | 6 | Ignorer la synthèse si moins de ce nombre d'anciens messages sont éligibles (évite des résumés inutilement minuscules) |
| Nombre maximal de jetons de résumé | int32 | 256 | Longueur maximale du résumé généré en tokens |
| Préserver l'invite système | bool | true | Toujours garder le message système (index 0) intact. |
| Instruction de résumé | FString | (see default) | L'instruction envoyée au modèle pour produire le résumé |
| Préfixe du message de résumé | FString | « [Résumé de la mémoire à long terme de la conversation précédente] : » | Préfixé au résumé généré lorsqu'il est inséré dans la conversation en tant que message de mémoire avec le rôle d'assistant. |
Déclenchement manuel et écoute des résumés
Vous pouvez déclencher la synthèse manuellement à tout moment, indépendamment du seuil.
- Blueprint
- C++
Lie à On History Summarized pour être notifié lorsqu'un passage de résumé est terminé. L'événement indique combien de messages ont été supprimés, combien de jetons ont été économisés et le texte du résumé généré, utile pour afficher un indicateur subtil dans l'interface de discussion.
LLM->SummarizeNow();
LLM->OnHistorySummarizedNative.AddLambda(
[](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
UE_LOG(LogTemp, Log, TEXT("Summarized %d messages, saved %d tokens"), MessagesRemoved, TokensSaved);
});
Interrogation de la longueur de contexte utilisée
Utilisez Get Used Context Length pour vérifier combien de tokens sont actuellement occupés dans la fenêtre de contexte du modèle. Cette valeur est la même que celle que le déclencheur de résumé automatique intégré vérifie par rapport au Trigger Token Threshold.
- Blueprint
- C++
LLM->GetUsedContextLengthNative([](int32 UsedTokens)
{
UE_LOG(LogTemp, Log, TEXT("Used context: %d tokens"), UsedTokens);
});
Désactiver le résumé automatique
- Blueprint
- C++
LLM->DisableAutoSummarization();
La désactivation n'annule pas les résumés déjà appliqués à la conversation.
La synthèse prend un moment pour s'exécuter sur le thread d'arrière-plan (le modèle génère le résumé). Les rappels de flux de jetons sont supprimés pendant cette génération interne afin qu'ils n'apparaissent pas dans votre interface de chat. On History Summarized se déclenche une fois la jonction terminée.
Décharger un modèle
Libération des ressources lorsqu'un modèle n'est plus nécessaire :
- Blueprint
- C++
LLM->UnloadModel();
État de la requête
Vérifiez l'état actuel de l'instance LLM :
- Blueprint
- C++
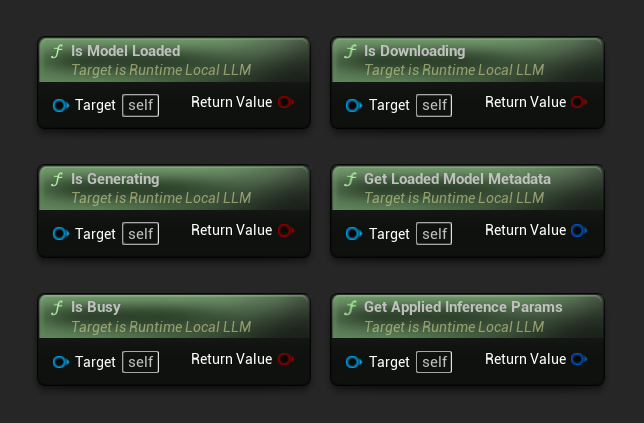
- Modèle chargé : Vrai si un modèle est prêt pour l'inférence
- En cours de génération : Vrai si la génération est en cours
- Occupé : Vrai si une opération (chargement, génération, téléchargement) est active
- En cours de téléchargement : Vrai si un téléchargement de modèle est en cours
- Obtenir les métadonnées du modèle chargé : Renvoie les métadonnées du modèle actuel
- Obtenir les paramètres d'inférence appliqués : Renvoie les paramètres appliqués lors du chargement
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
Fonctions de la bibliothèque de modèles
Un ensemble de fonctions utilitaires statiques est fourni pour gérer les fichiers de modèle sur le disque. Celles-ci sont utiles pour créer une interface utilisateur de sélection de modèle ou vérifier la disponibilité d'un modèle au moment de l'exécution.
Obtenir les noms / métadonnées des modèles téléchargés
- Blueprint
- C++
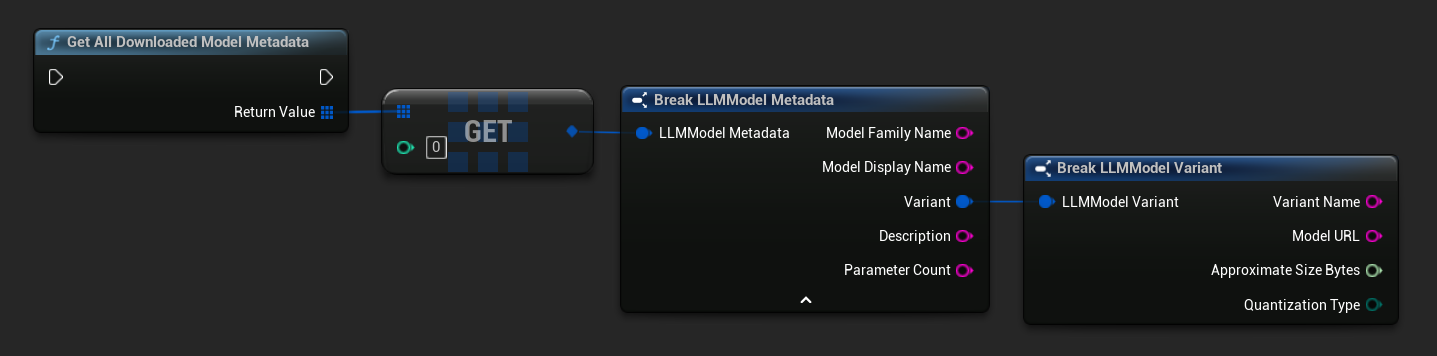
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
Vérifier si un modèle est sur le disque
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
Obtenir le chemin du fichier du modèle
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
Supprimer les fichiers du modèle
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
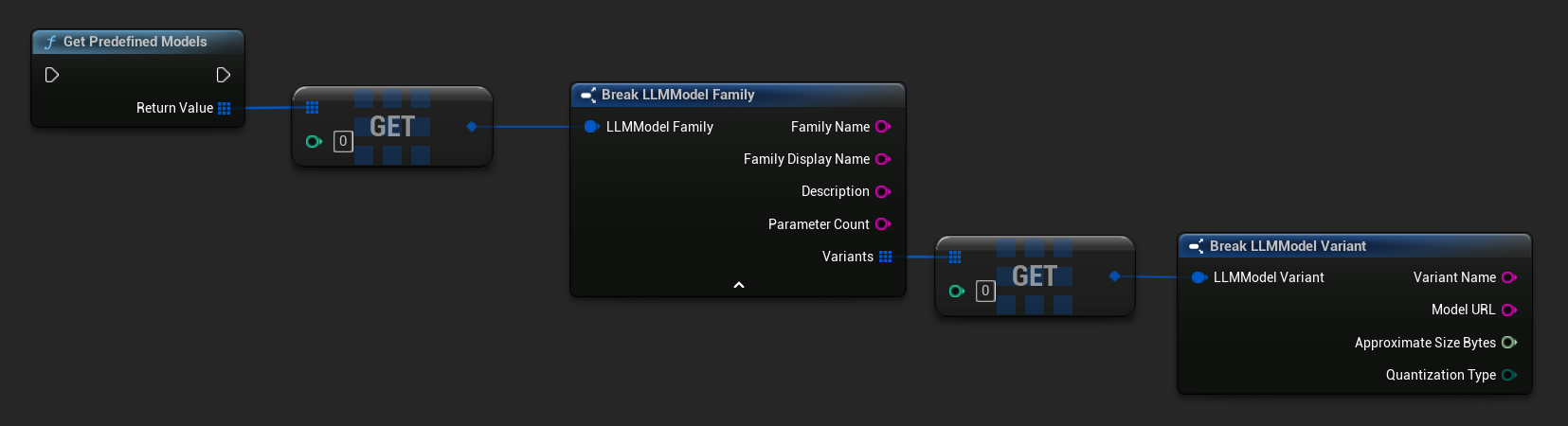
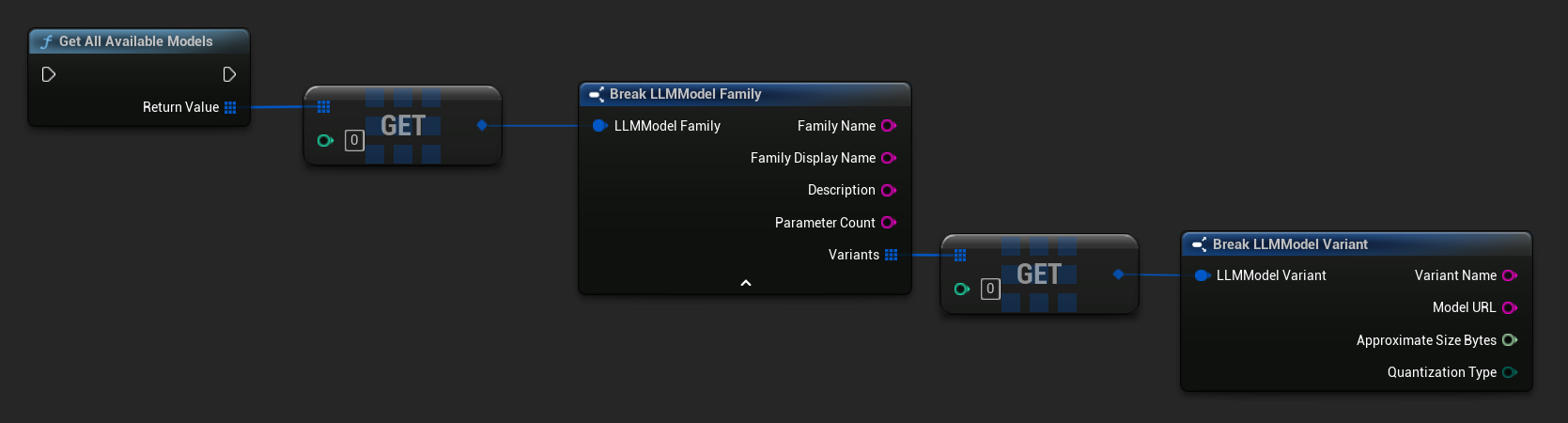
Obtenez les modèles prédéfinis et disponibles
- Blueprint
- C++
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
Générer des métadonnées à partir d'une URL
Construire des métadonnées de modèle à partir d'une URL brute (les champs sont dérivés du nom de fichier) :
- Blueprint
- C++
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
Fonctions utilitaires
Un ensemble de fonctions d’assistance est fourni pour le formatage et l’affichage des erreurs.
Octets en chaîne lisible
Convertit un nombre d'octets en une chaîne lisible par un humain (par exemple "4.07 Go"). Utile pour afficher la taille des modèles dans l'interface utilisateur.
Format de progression du téléchargement
Formate une chaîne de progression de téléchargement comme "1,23 Go / 4,07 Go (30,2 %)". Si la taille totale est inconnue, retourne uniquement la quantité reçue.
Obtenir la description de l'erreur / la chaîne du code d'erreur
Get LLM Error Description renvoie une description textuelle lisible pour un code d'erreur. Get LLM Error Code String renvoie le nom de la valeur de l'énumération sous forme de chaîne (utile pour la journalisation).
Référence des codes d'erreur
| Code | Valeur | Description |
|---|---|---|
| Inconnu | 0 | Une erreur non spécifiée |
| ModelLoadFailed | 10 | Le fichier GGUF n'a pas pu être chargé (fichier corrompu, format incompatible, etc.) |
| ContextCreateFailed | 11 | Échec de la création du contexte d'inférence |
| ModèleNonChargé | 20 | Une tentative d'inférence a été effectuée sans modèle chargé. |
| ChatTemplateFailed | 21 | Le modèle de chat du modèle n'a pas pu être appliqué. |
| TokenizationFailed | 22 | Le texte d'entrée n'a pas pu être tokenisé. |
| ContextOverflow | 23 | Le prompt + le contexte dépasse la taille de contexte configurée. |
| PromptDecodeFailed | 24 | Les jetons de l'invite n'ont pas pu être décodés. |
| ContextTooFullToGenerate | 25 | Espace de contexte insuffisant pour générer la sortie. |
| GenerationDecodeFailed | 30 | Un jeton n’a pas pu être décodé lors de la génération. |
| GenerationTruncated | 31 | Génération arrêtée car la limite maximale de jetons a été atteinte. |
| LLMInstanceNull | 40 | L'instance LLM est nulle ou invalide |
| ModelNotFoundOnDisk | 41 | Le fichier modèle n'existe pas au chemin attendu. |
| ModelURLEmpty | 42 | Un téléchargement a été demandé avec une URL vide. |
| Téléchargement du modèle annulé | 43 | Le téléchargement a été annulé. |
| ModelDownloadEmptyData | 44 | Le téléchargement est terminé mais le corps de la réponse était vide. |
| ÉchecDeSauvegardeDuTéléchargementDuModèle | 45 | Le téléchargement est terminé mais le fichier n'a pas pu être enregistré sur le disque. |