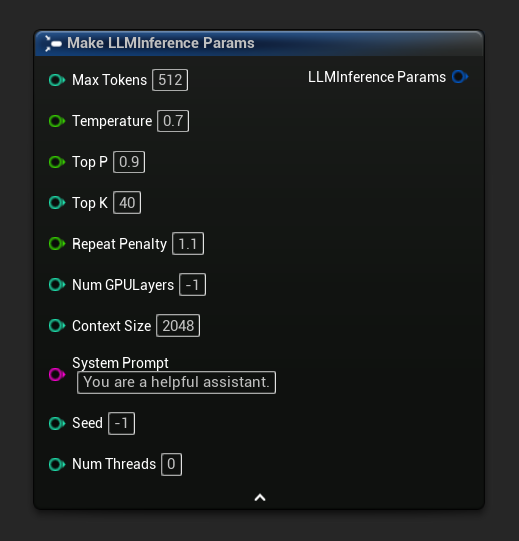
Paramètres d'inférence
La structure des paramètres d'inférence du LLM contrôle la manière dont le modèle charge et génère du texte. Vous transmettez ces paramètres lors du chargement d'un modèle. Cette page décrit chaque paramètre et son effet.
Référence des paramètres
| Paramètre | Type | Défaut | Gamme | Description |
|---|---|---|---|---|
| Max Tokens | int32 | 512 | 1–8192 | Nombre maximum de jetons à générer dans une seule réponse |
| Température | flottant | 0,7 | 0,0–2,0 | Contrôle le caractère aléatoire. 0.0 = déterministe. Des valeurs plus élevées = une sortie plus créative. |
| Top P | flottant | 0,9 | 0,0–1,0 | Échantillonnage par noyau. Seuls les jetons dont la probabilité cumulée dépasse cette valeur sont pris en compte. |
| Top K | int32 | 40 | 0–200 | Limite la sélection aux K tokens les plus probables. 0 = désactivé. |
| Pénalité de répétition | flottant | 1.1 | 0,0–3,0 | Pénalise les tokens qui apparaissent déjà dans la sortie. 1.0 = aucune pénalité |
| Couches GPU | int32 | -1 | -1–200 | Couches de modèle à décharger sur le GPU. -1 = automatique. 0 = CPU uniquement. |
| Taille du Contexte | int32 | 2048 | 128–131072 | Taille maximale de la fenêtre de contexte en tokens. Des valeurs plus élevées utilisent plus de mémoire. |
| Invite système | FString | "Vous êtes un assistant utile." | — | Instruction système qui façonne le comportement du modèle |
| Seed | int32 | -1 | -1+ | Graine aléatoire pour une sortie reproductible. -1 = aléatoire |
| Nombre de threads | int32 | 0 | 0–128 | Threads CPU pour la génération. 0 = automatique |
Utilisation
- Blueprint
- C++
Les paramètres d'inférence apparaissent sous forme d'une broche de structure sur les nœuds de chargement et asynchrones. Décomposez la structure pour définir des valeurs individuelles.
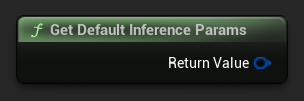
Pour obtenir un ensemble de paramètres par défaut comme point de départ, utilisez Get Default Inference Params :
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Recommandations de plateforme
Mobile / VR (Android, iOS, Meta Quest)
- Taille du contexte : 1024–2048
- Nombre de couches GPU : 0 (CPU uniquement) sauf si l’appareil prend en charge le calcul GPU confirmé
- Nombre maximal de tokens : Moins de 256 pour des interactions réactives
- Nombre de threads : 2–4 selon l’appareil
Bureau (Windows, Mac, Linux)
- Taille du contexte : 2048–8192 pour la plupart des conversations
- Nombre de couches GPU : -1 (auto) pour exploiter l'accélération GPU lorsqu'elle est disponible
- Nombre de threads : 0 (auto)
- Tokens maximum : 512–2048 pour des réponses plus longues
Conversations Longues
Si votre application maintient des conversations sur de longues sessions (dialogues de PNJ, assistants persistants, jeux de rôle), envisagez d'associer votre taille de contexte à une synthèse automatique plutôt que d'augmenter simplement la Taille du Contexte. Une Taille du Contexte modeste de 2048 à 4096 avec la synthèse automatique activée maintient une latence et une utilisation mémoire stables, tandis que des fenêtres de contexte plus grandes ralentissent progressivement chaque génération. Voir Synthèse automatique du contexte.