Guide de traitement audio
Ce guide explique comment configurer différentes méthodes d'entrée audio pour alimenter vos générateurs de synchronisation labiale. Assurez-vous d'avoir terminé le Guide de configuration avant de continuer.
Traitement de l’entrée audio
Vous devez configurer une méthode pour traiter l'entrée audio. Il existe plusieurs façons de procéder selon votre source audio.
- Microphone (temps réel)
- Microphone (Lecture)
- Synthèse vocale (locale)
- Synthèse vocale (API externes)
- À partir d'un fichier/tampon audio
- Tampon audio de streaming
Cette approche effectue la synchronisation labiale en temps réel pendant que vous parlez dans le microphone :
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec humeur
- Créez une Onde Sonore Capturable à l'aide de Runtime Audio Importer.
- Pour Linux avec Pixel Streaming, utilisez Pixel Streaming Capturable Sound Wave à la place.
- Avant de commencer à capturer l'audio, liez-vous au délégué
OnPopulateAudioData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime - Commencez à capturer l'audio depuis le microphone
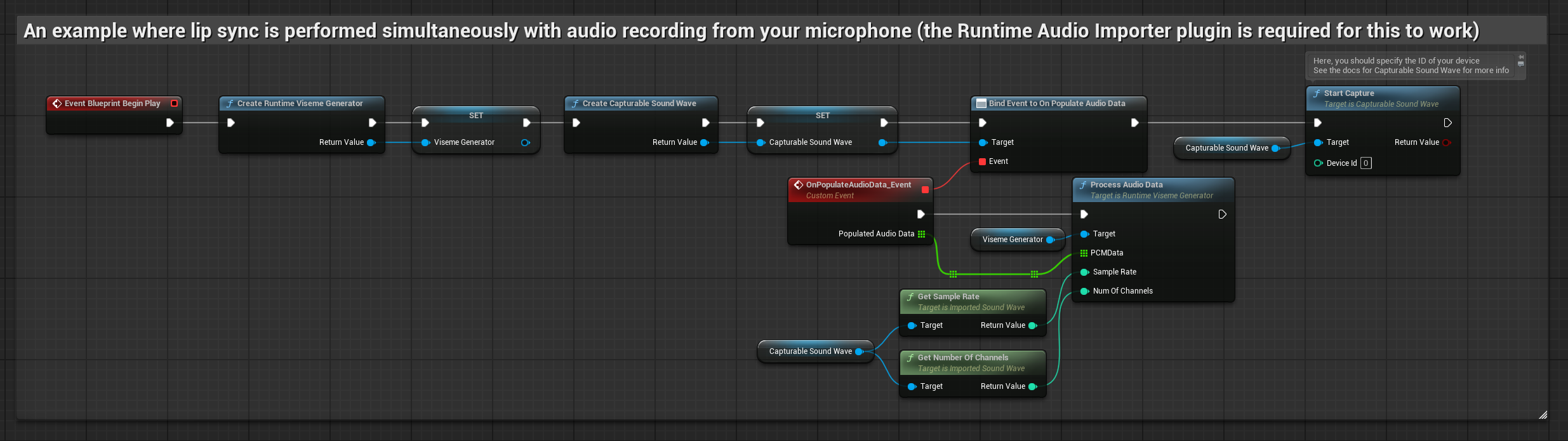
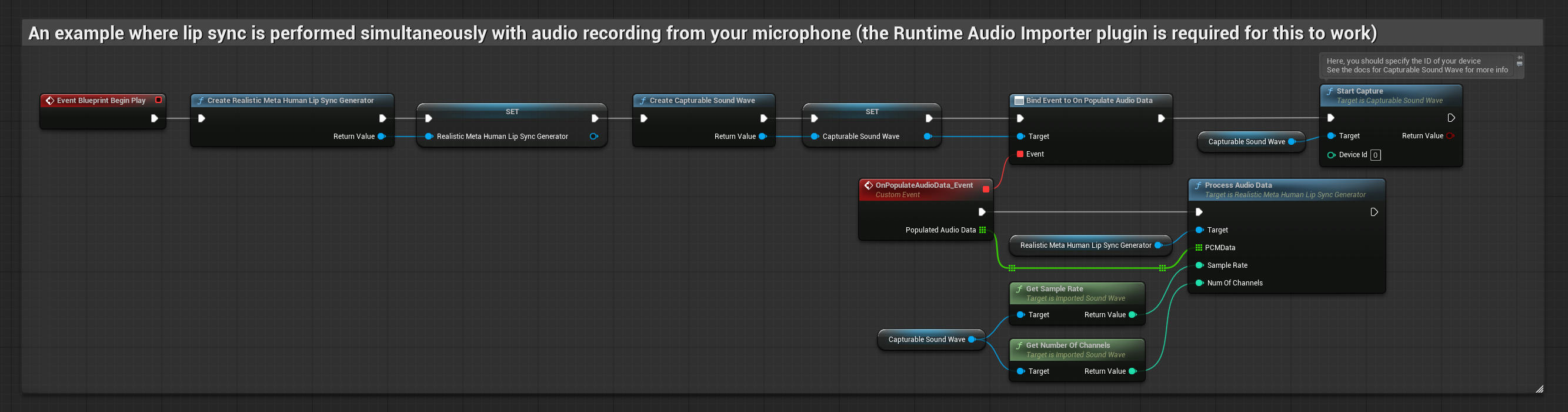
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
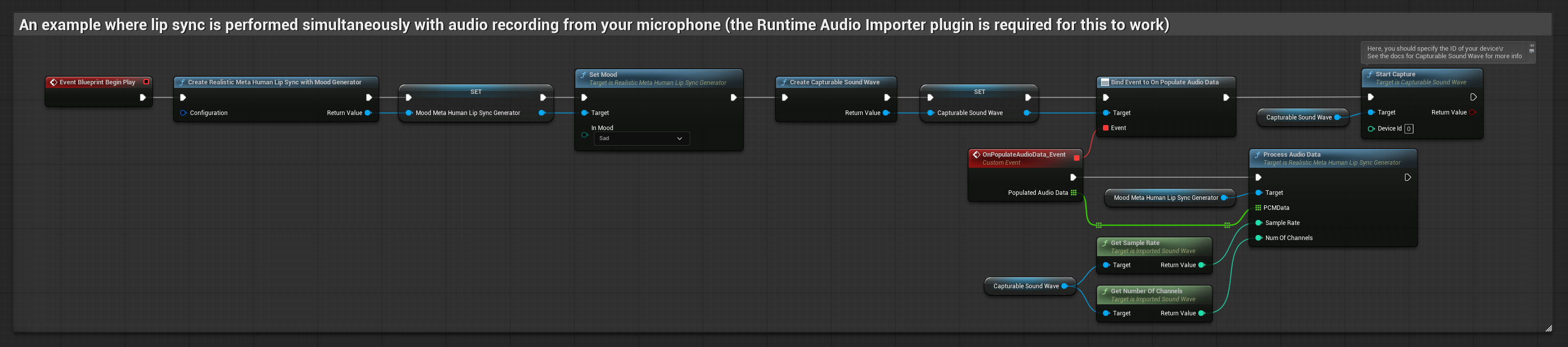
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
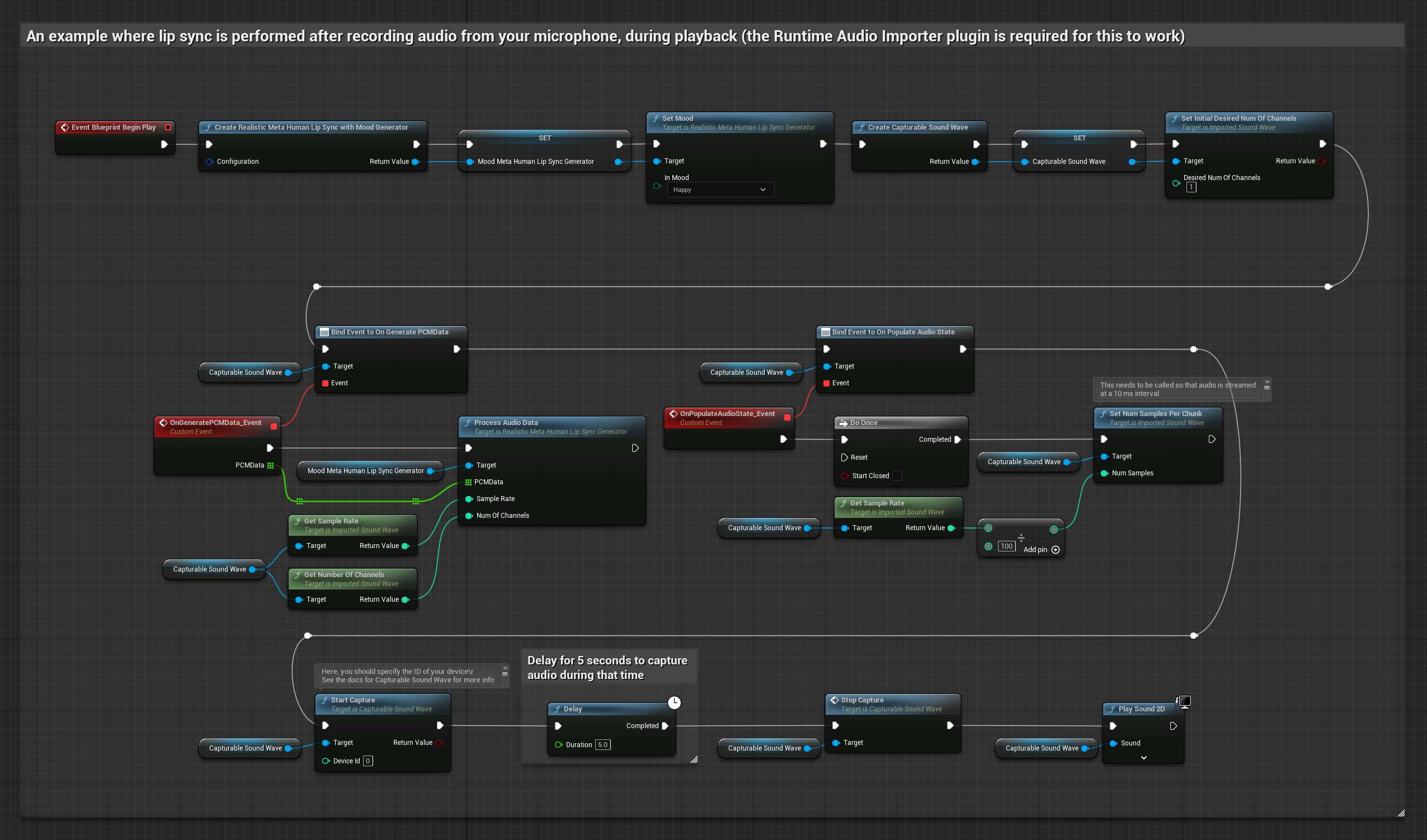
Cette approche capture l'audio depuis un microphone, puis le rejoue avec une synchronisation labiale :
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Créez une Onde Sonore Capturable à l'aide de Runtime Audio Importer.
- Pour Linux avec Pixel Streaming, utilisez Pixel Streaming Capturable Sound Wave à la place.
- Démarrer la capture audio depuis le microphone
- Avant de lire l'onde sonore capturable, liez-vous à son délégué
OnGeneratePCMData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime
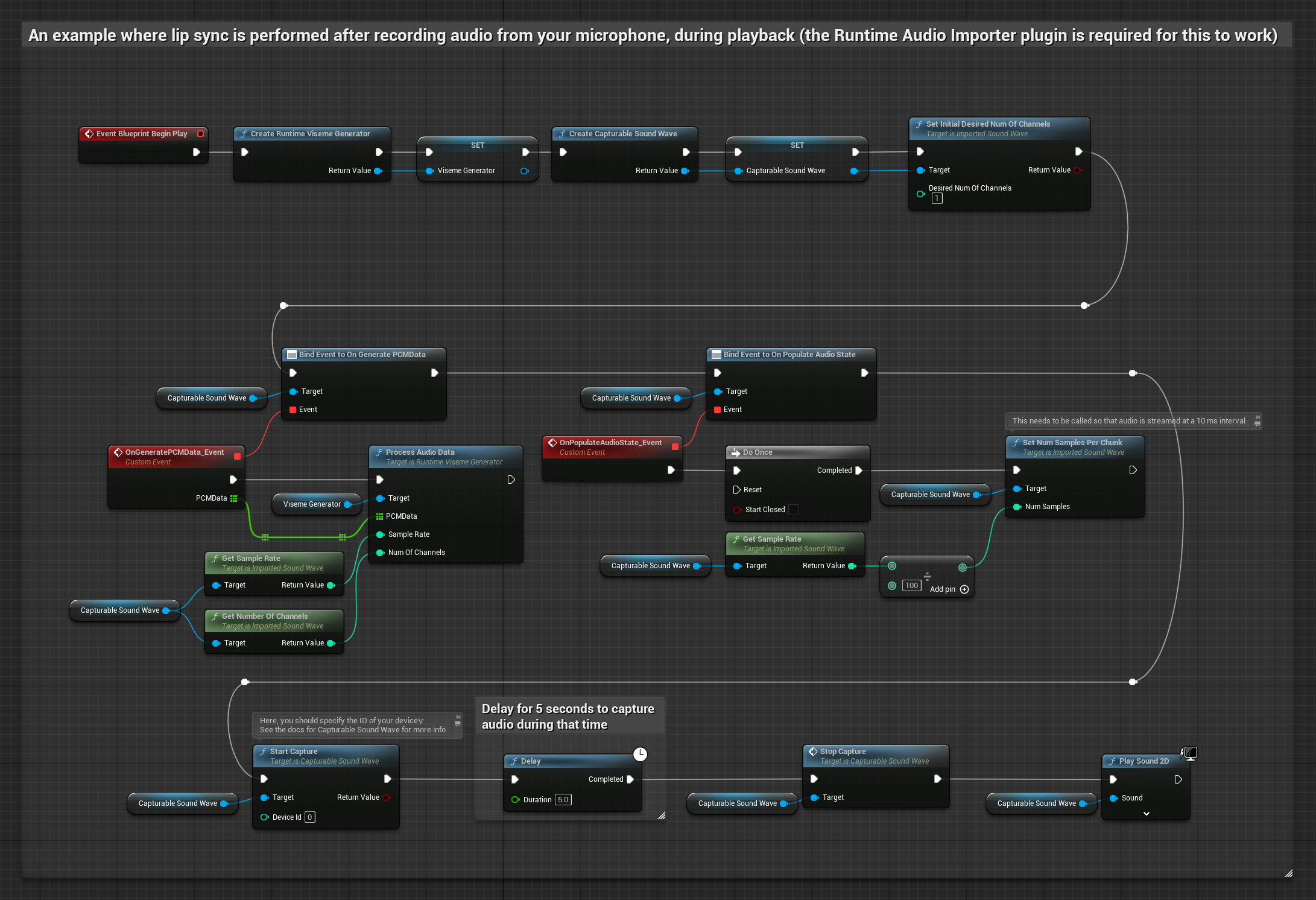
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
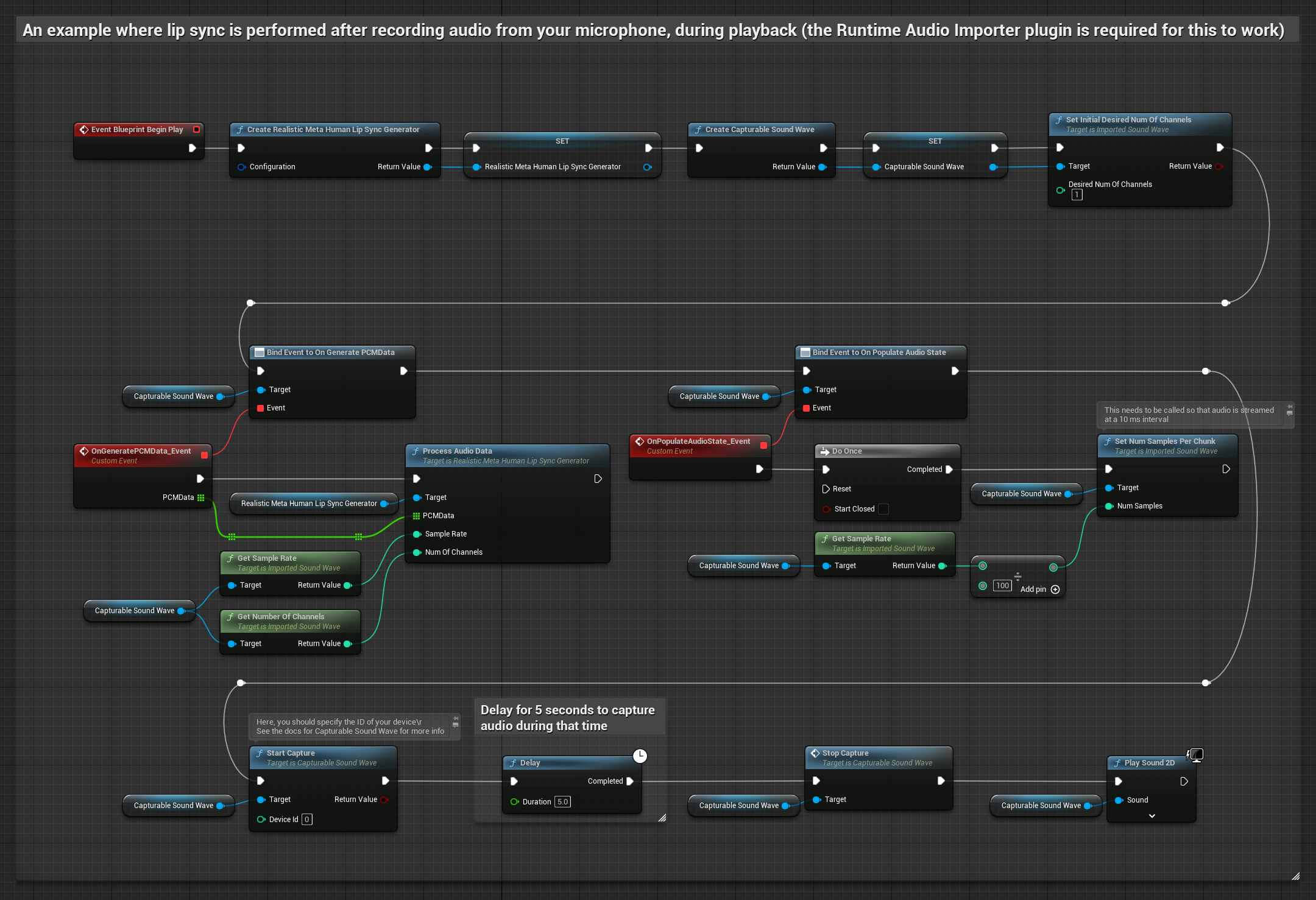
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
- Régulier
- Streaming
Cette approche synthétise la parole à partir du texte en utilisant un TTS local et effectue la synchronisation labiale.
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Utilisez Runtime Text To Speech pour générer de la parole à partir de texte
- Utilisez Runtime Audio Importer pour importer l'audio synthétisé
- Avant de lire l'onde sonore importée, liez-vous à son délégué
OnGeneratePCMData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime
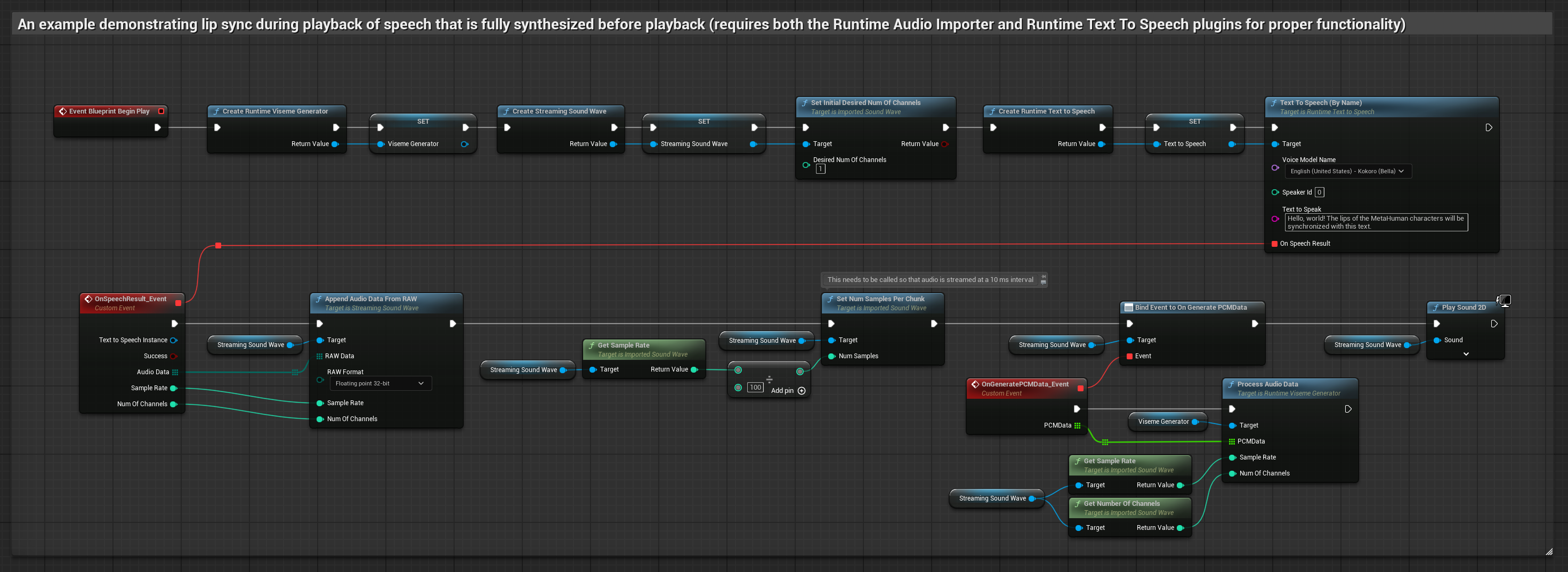
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
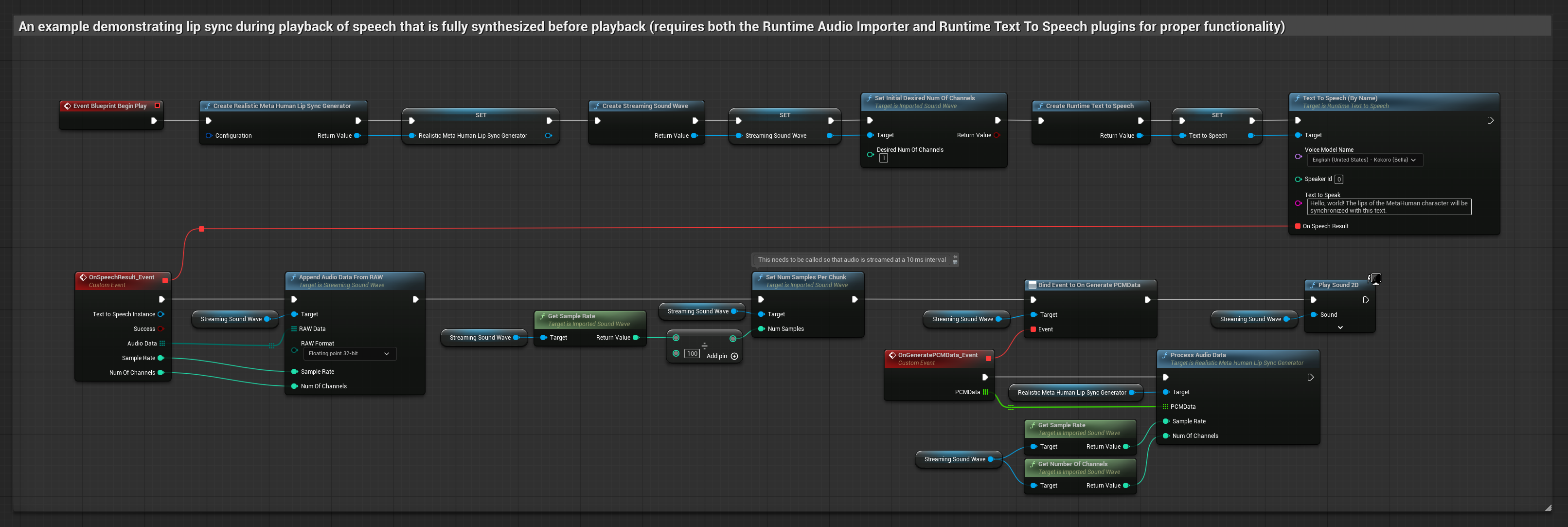
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
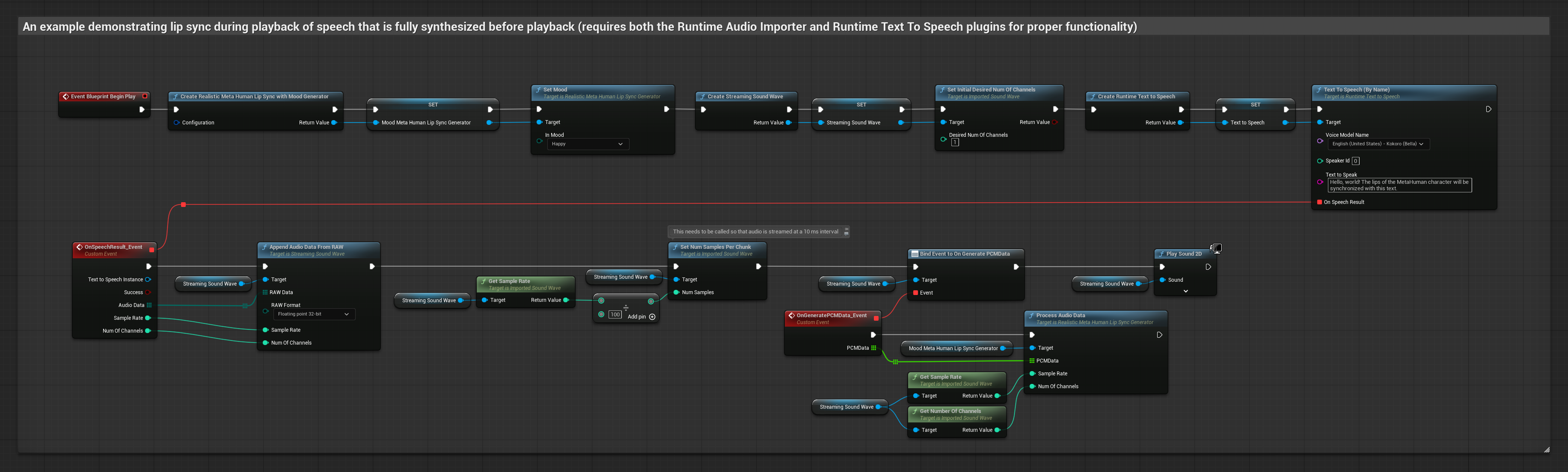
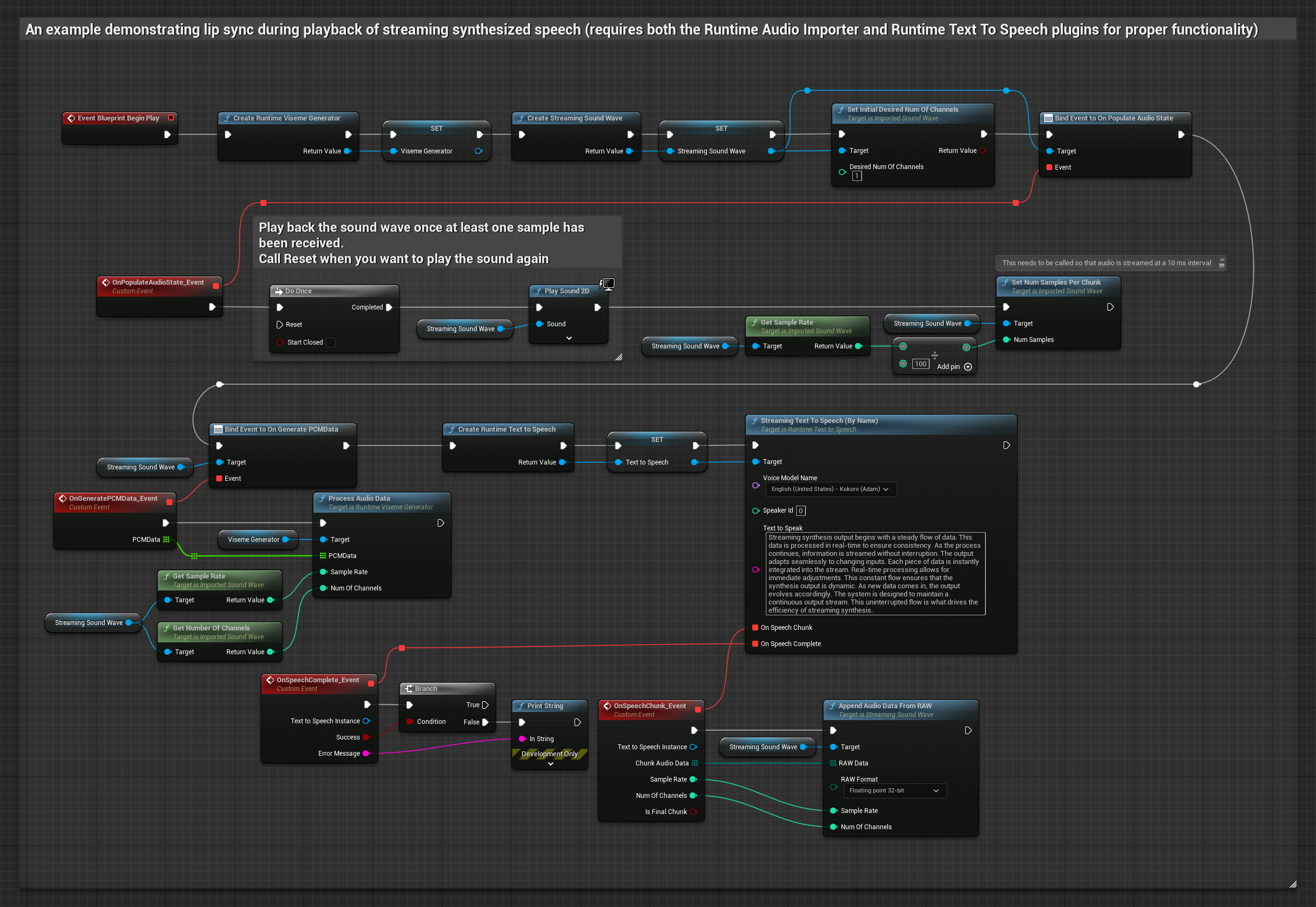
Cette approche utilise la synthèse vocale en streaming avec un synchronisme labial en temps réel :
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Utilisez Runtime Text To Speech pour générer un flux vocal à partir de texte
- Utilisez Runtime Audio Importer pour importer l'audio synthétisé
- Avant de lire l'onde sonore en streaming, liez-vous à son délégué
OnGeneratePCMData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime
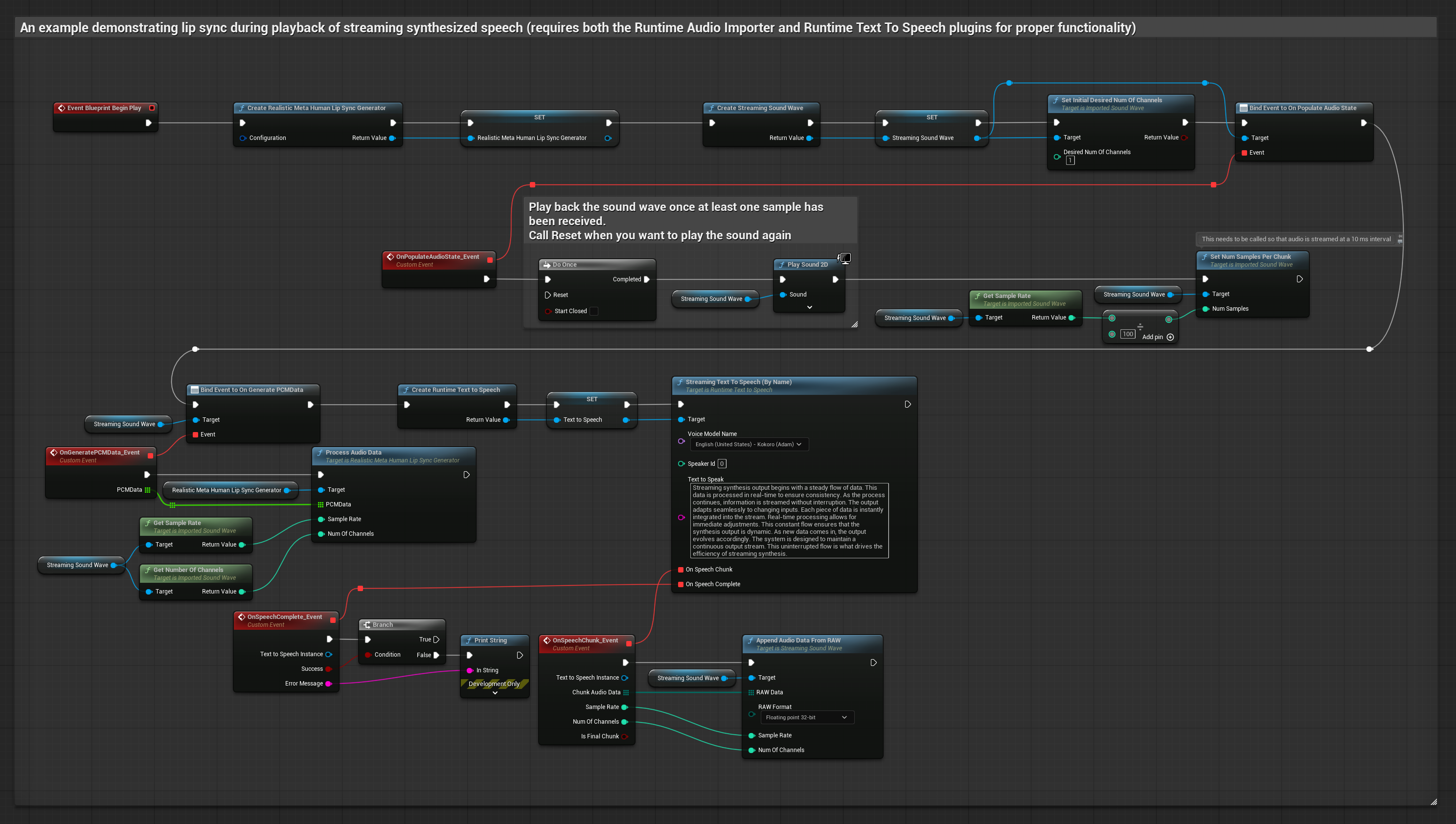
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
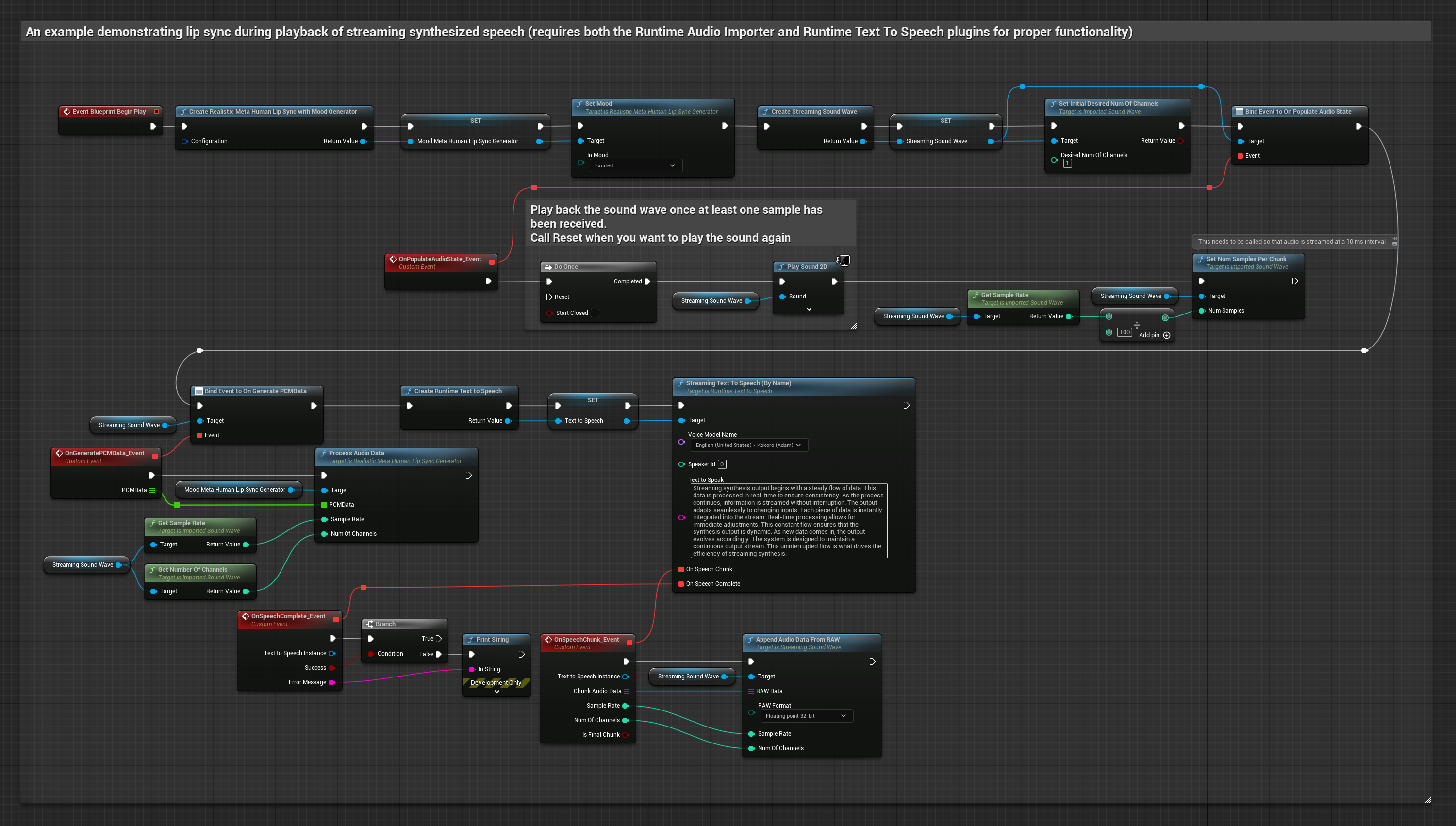
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
- Régulier
- Streaming
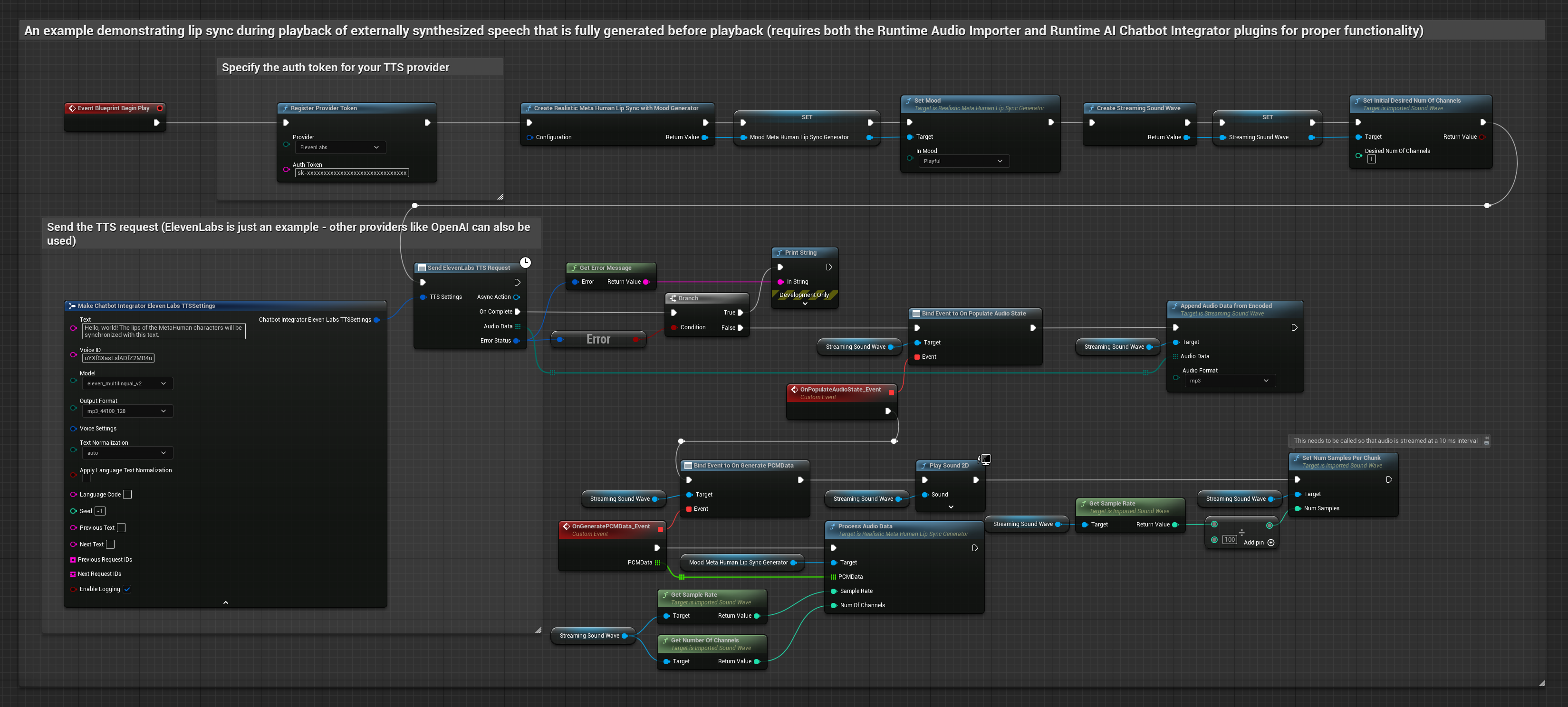
Cette approche utilise le plugin Runtime AI Chatbot Integrator pour générer de la parole synthétisée à partir de services d'IA (OpenAI ou ElevenLabs) et effectuer la synchronisation labiale.
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Utilisez Runtime AI Chatbot Integrator pour générer de la parole à partir de texte à l'aide d'API externes (OpenAI, ElevenLabs, etc.)
- Utilisez Runtime Audio Importer pour importer les données audio synthétisées
- Avant de lire l'onde sonore importée, liez-vous à son délégué
OnGeneratePCMData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime
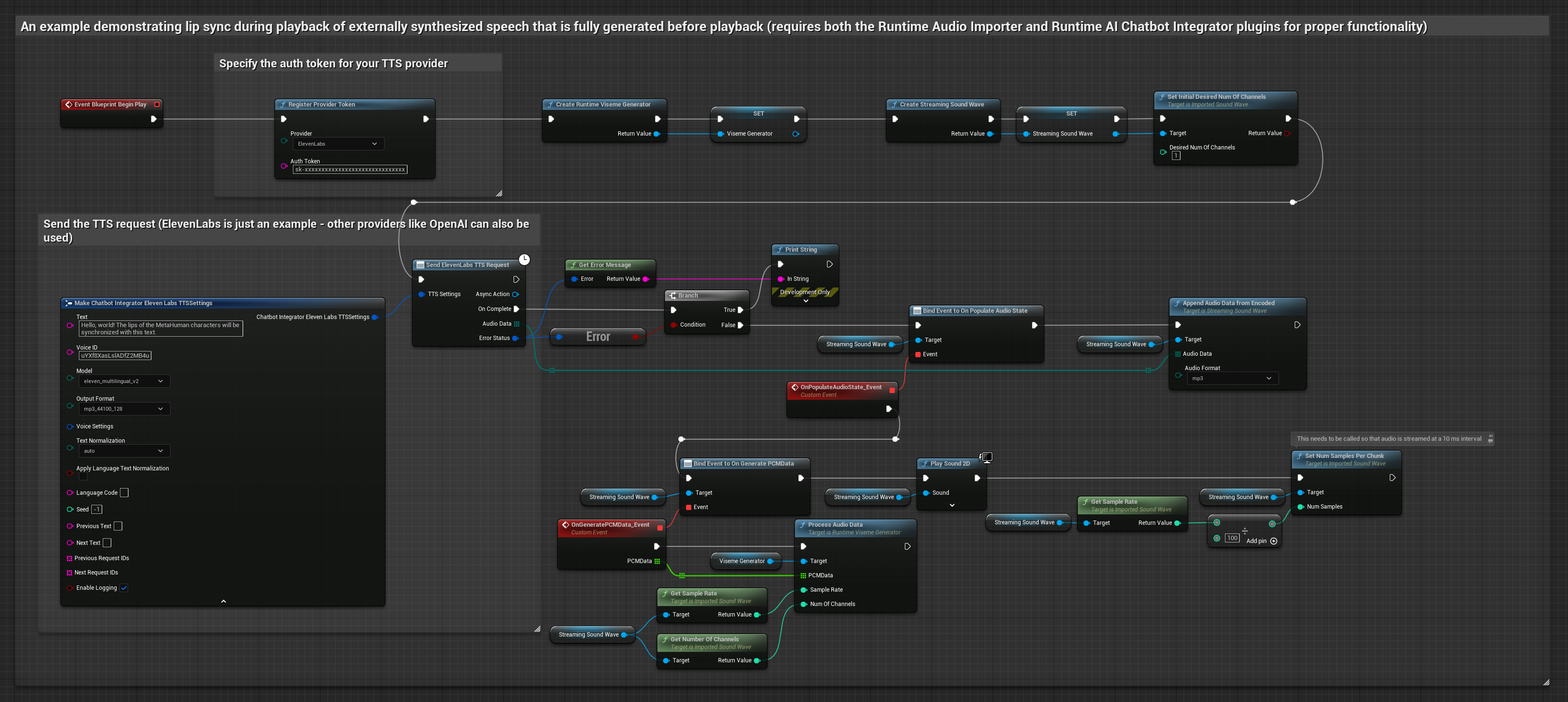
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
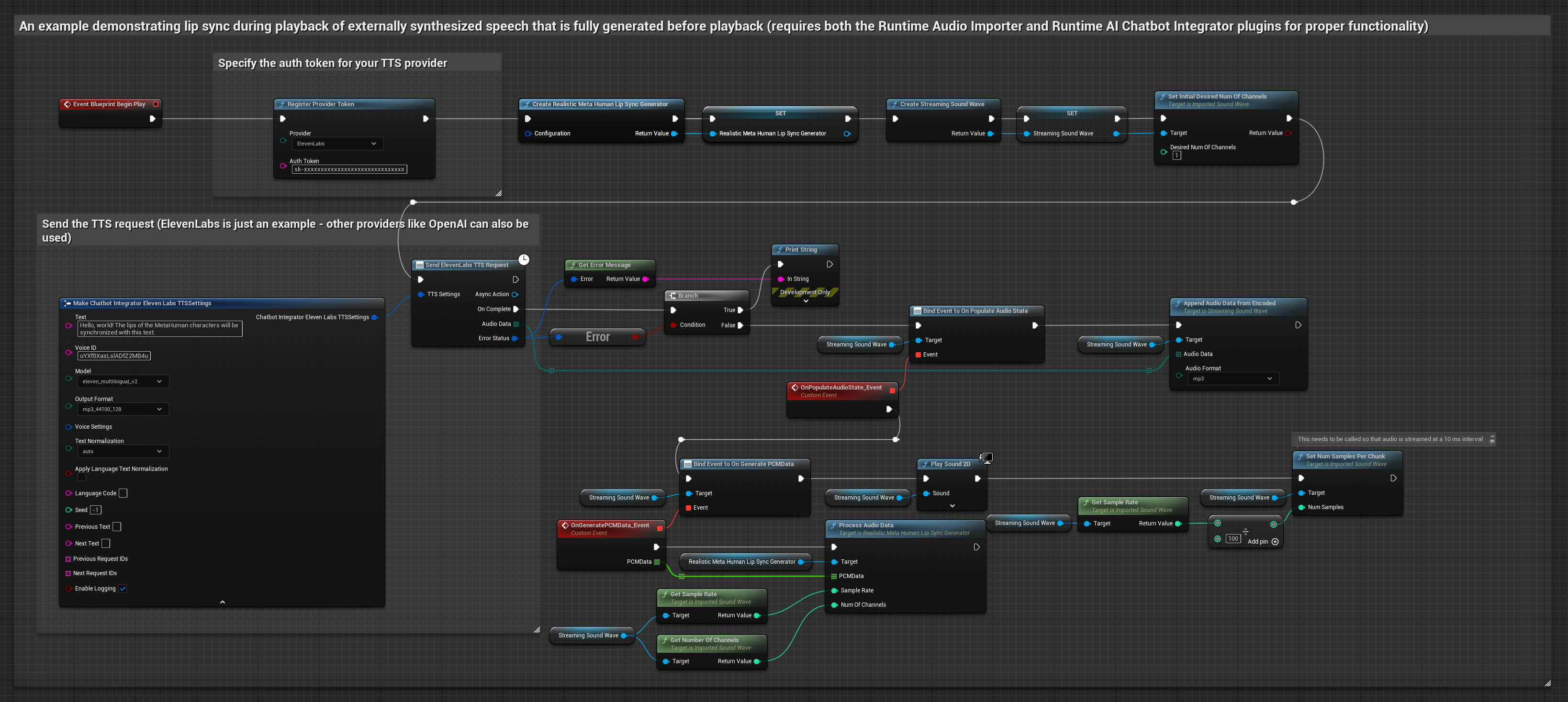
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
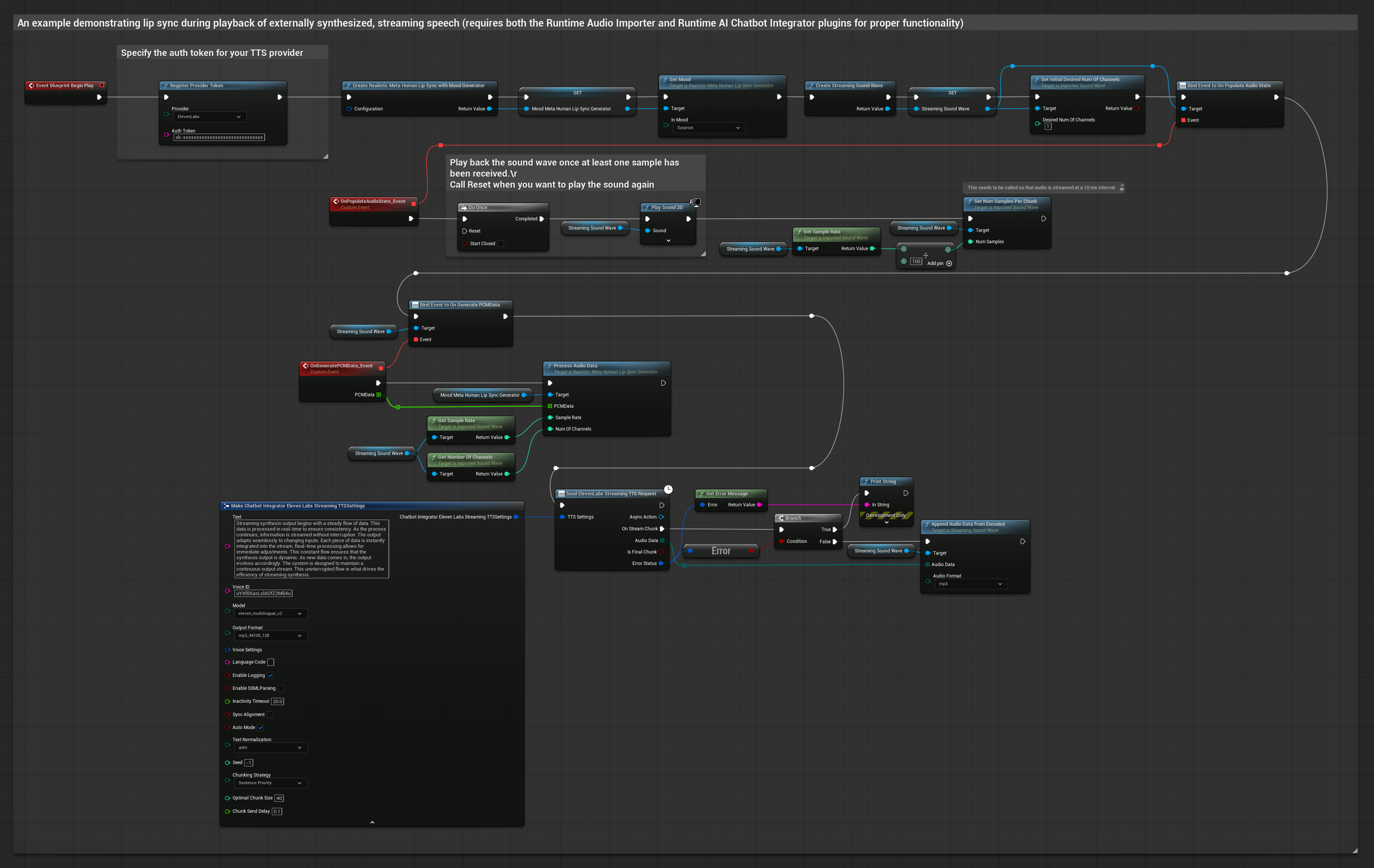
Cette approche utilise le plugin Runtime AI Chatbot Integrator pour générer un discours synthétisé en streaming à partir de services d'IA (OpenAI ou ElevenLabs) et effectuer un lip sync :
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Utilisez Runtime AI Chatbot Integrator pour vous connecter aux API TTS en streaming (comme l'API ElevenLabs Streaming)
- Utilisez Runtime Audio Importer pour importer les données audio synthétisées
- Avant de lire l'onde sonore en streaming, liez-vous à son délégué
OnGeneratePCMData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime
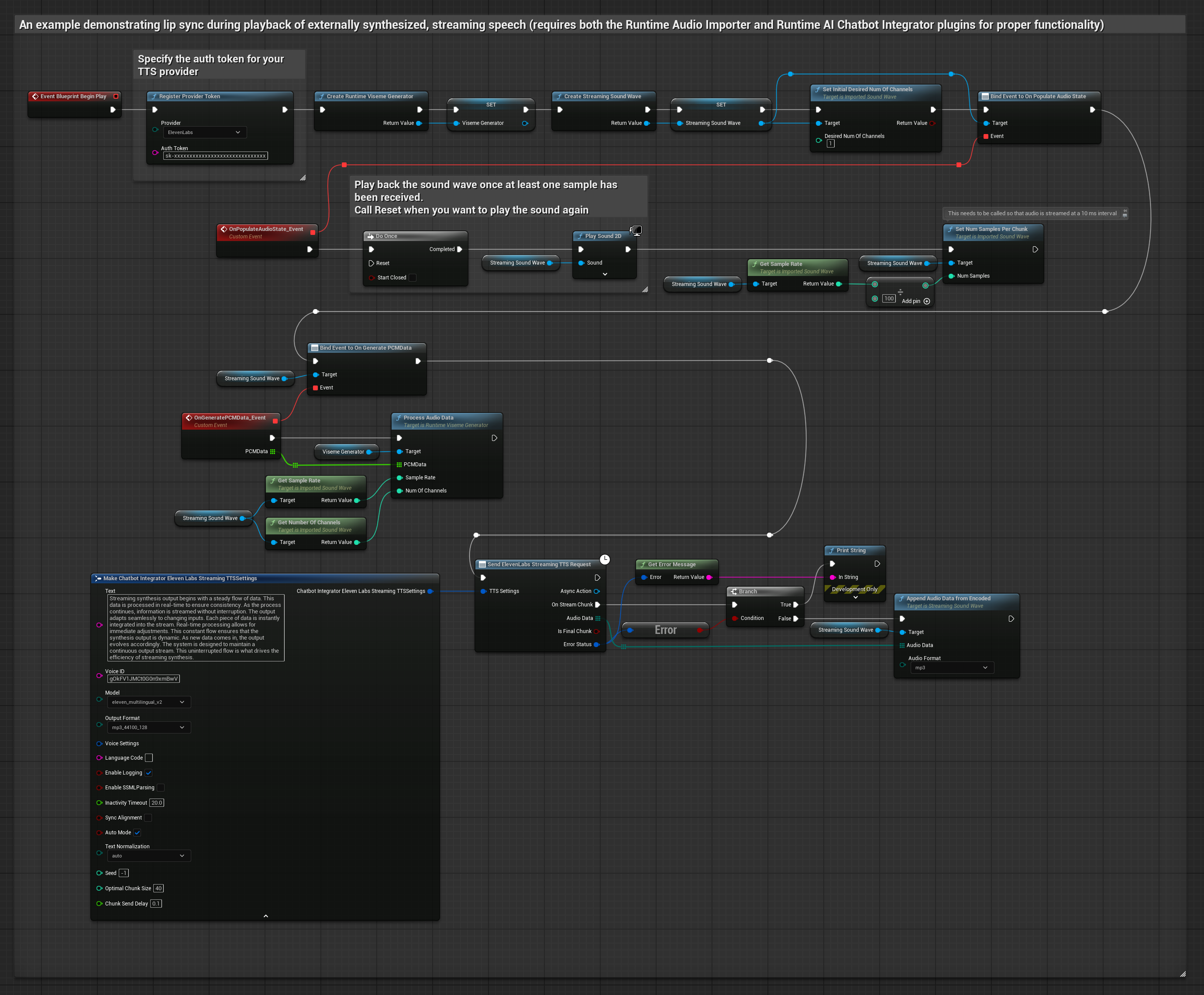
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
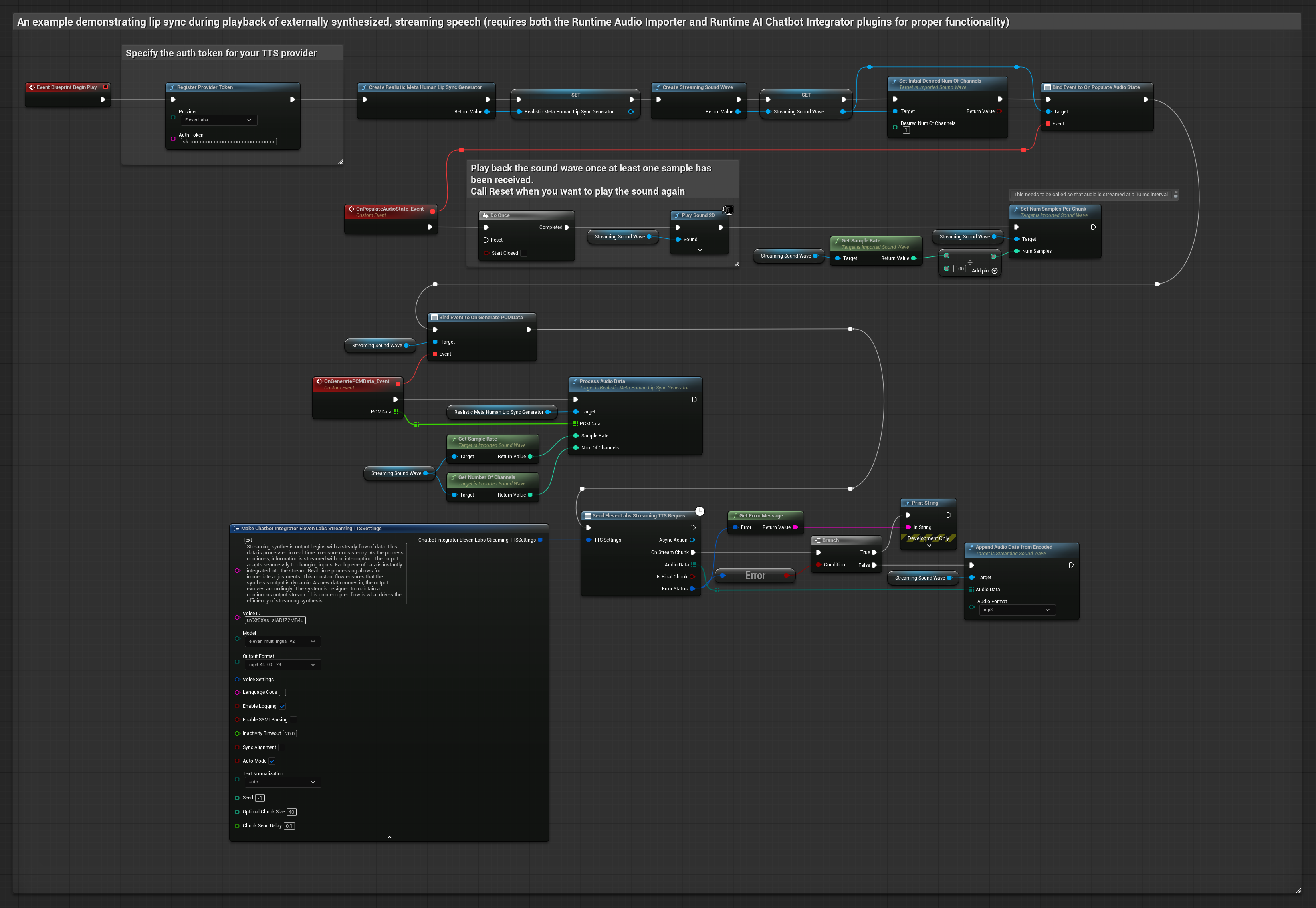
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
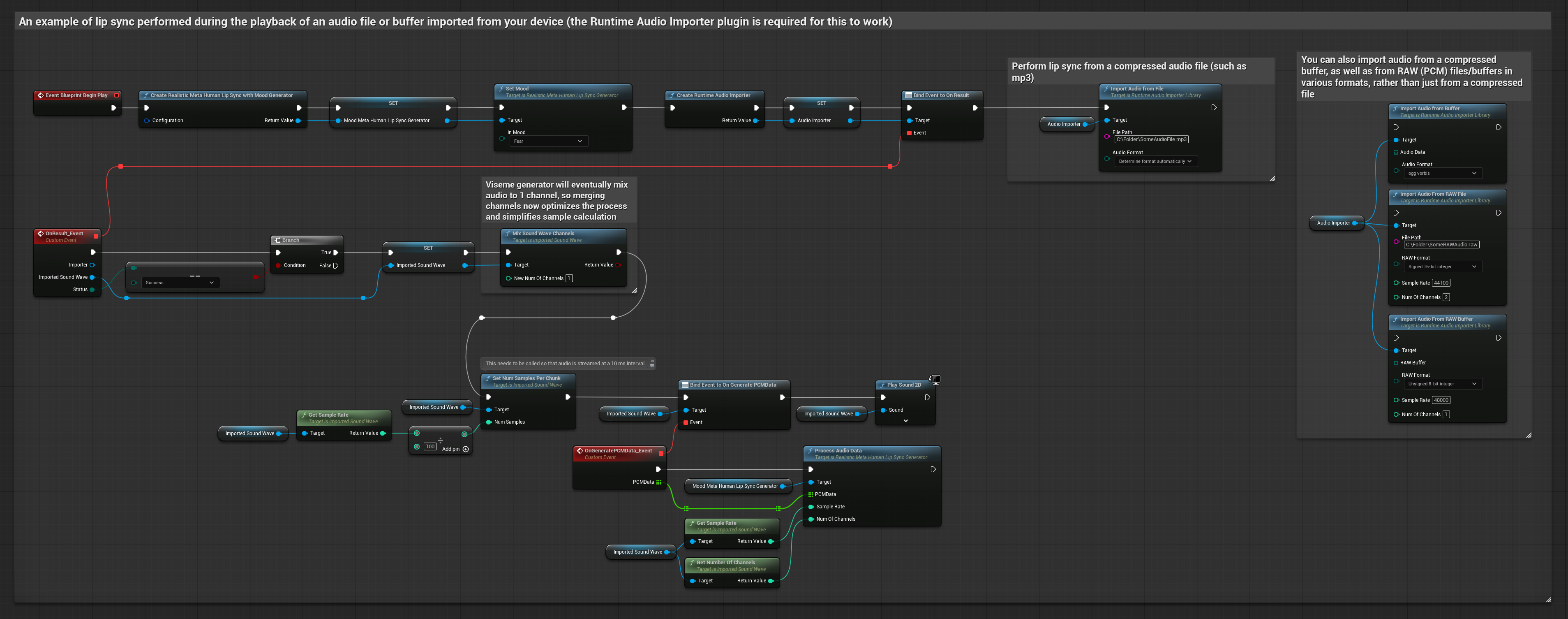
Cette approche utilise des fichiers audio préenregistrés ou des tampons audio pour la synchronisation labiale :
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Utilisez Runtime Audio Importer pour importer un fichier audio depuis le disque ou la mémoire
- Avant de lire l'onde sonore importée, liez-vous à son délégué
OnGeneratePCMData - Dans la fonction liée, appelez
ProcessAudioDatadepuis votre générateur de visèmes Runtime - Lisez l'onde sonore importée et observez l'animation de synchronisation labiale
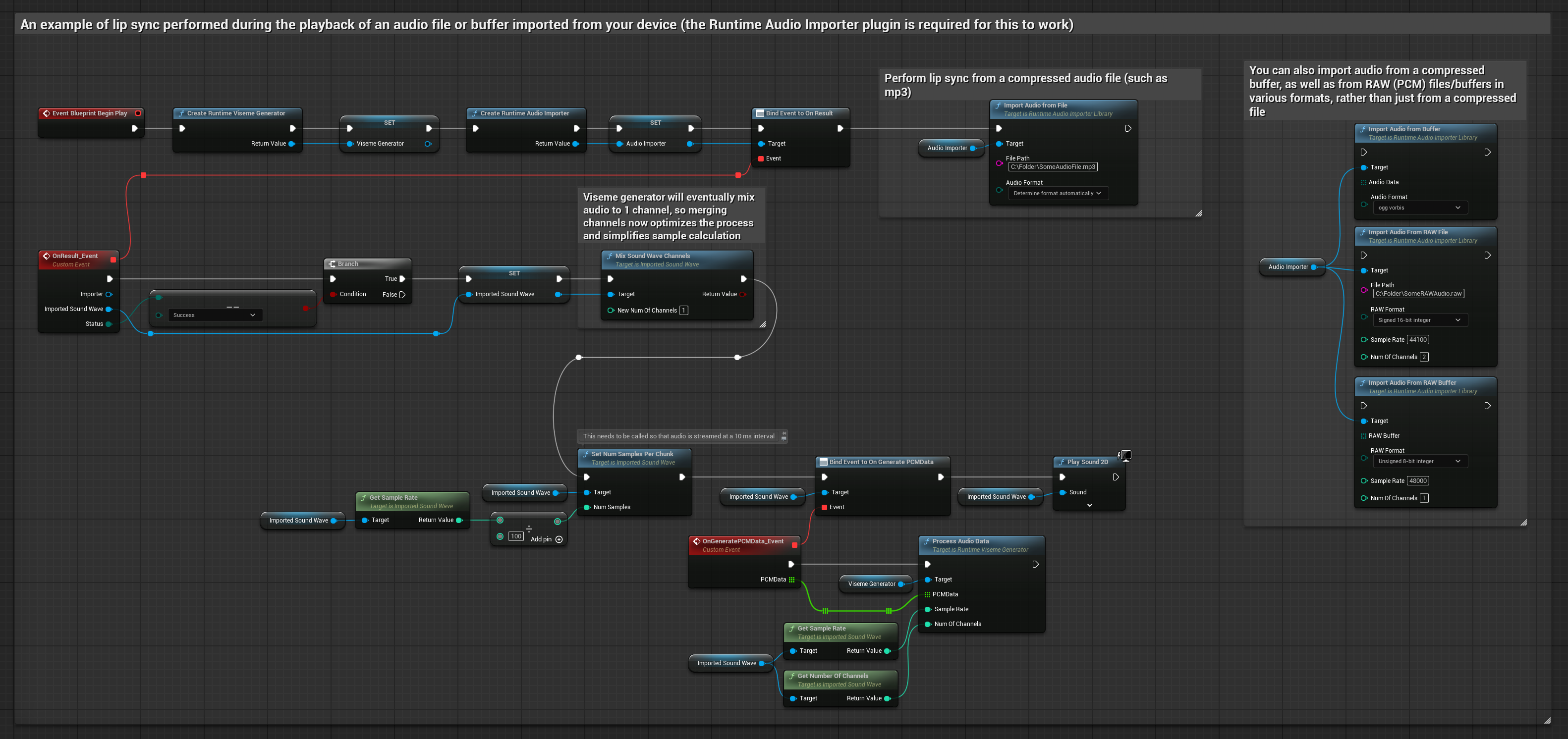
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
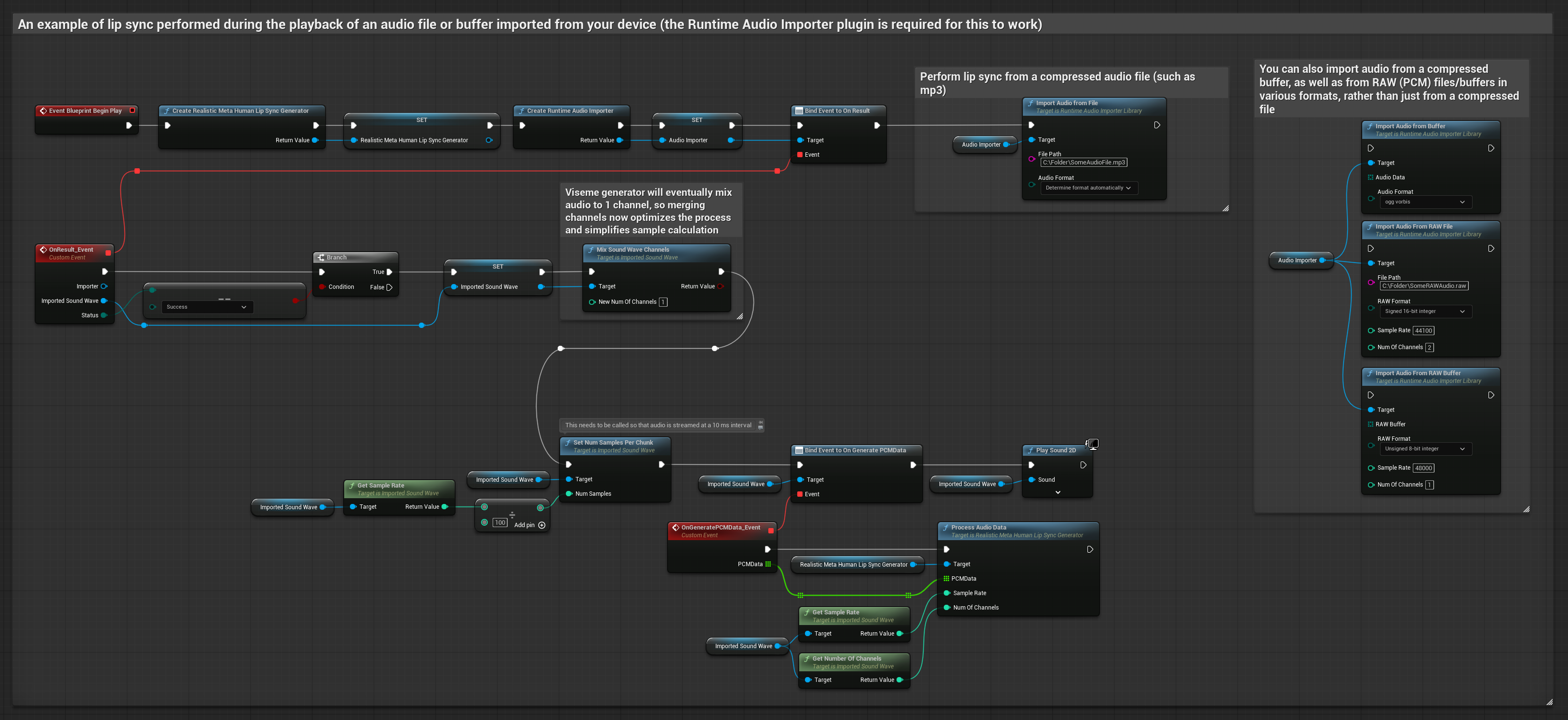
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
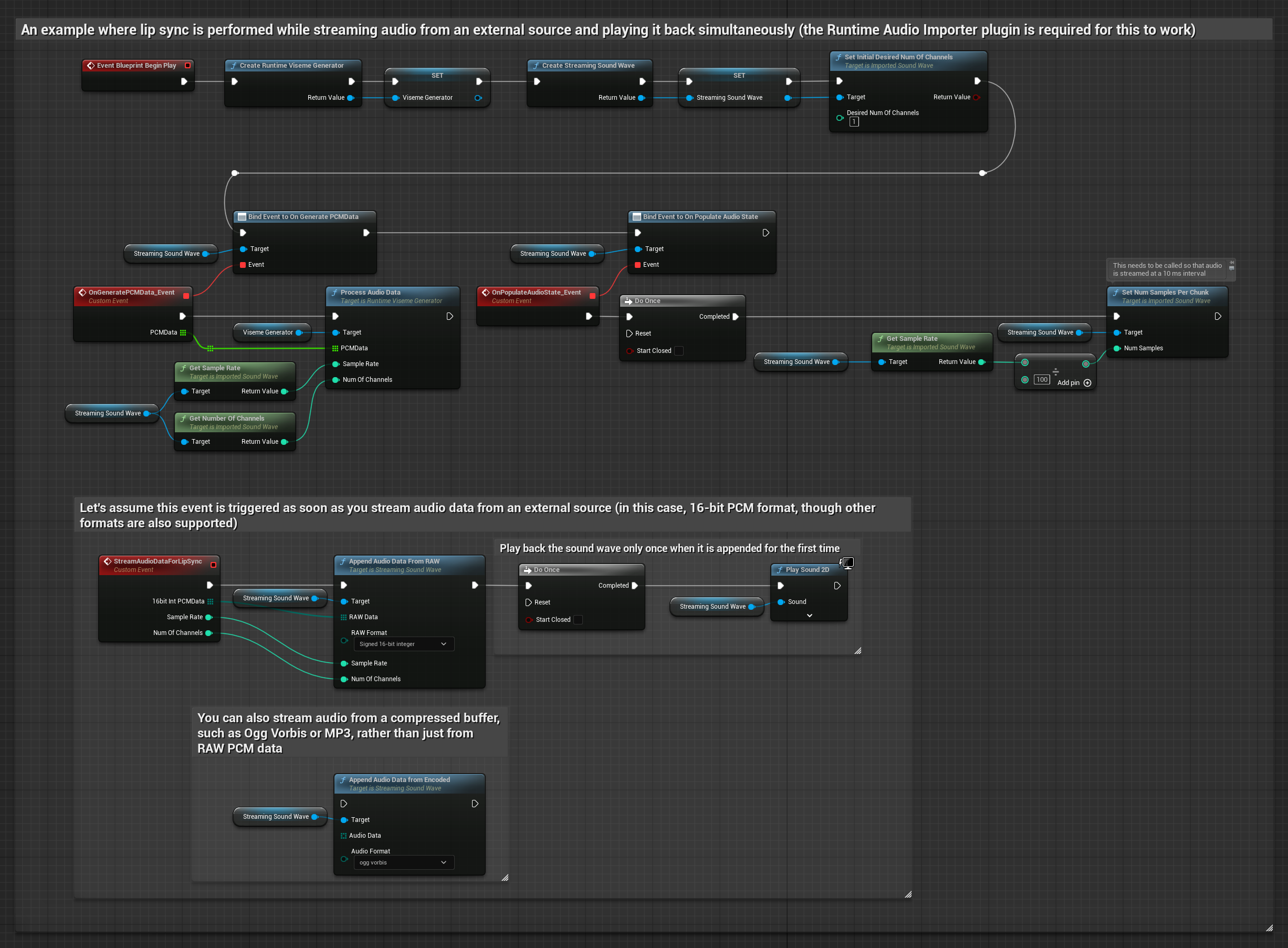
Pour diffuser des données audio à partir d'un tampon, vous avez besoin de :
- Modèle Standard
- Modèle réaliste
- Modèle réaliste avec gestion des émotions
- Données audio au format PCM flottant (un tableau d'échantillons flottants) disponibles depuis votre source de streaming (ou utilisez Runtime Audio Importer pour prendre en charge plus de formats)
- Le taux d'échantillonnage et le nombre de canaux
- Appelez
ProcessAudioDatadepuis votre Runtime Viseme Generator avec ces paramètres au fur et à mesure que les morceaux audio deviennent disponibles
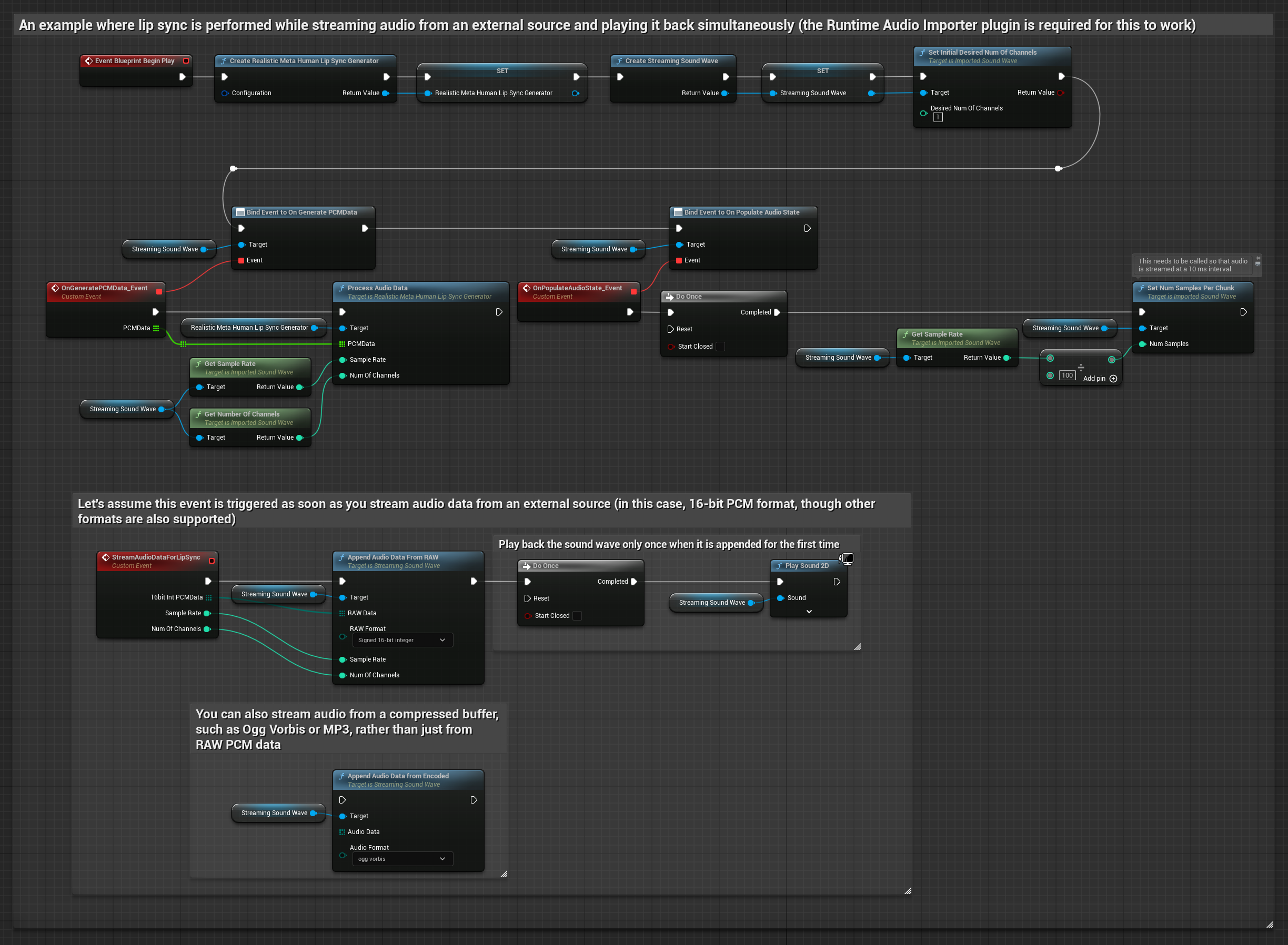
Le modèle réaliste utilise le même flux de traitement audio que le modèle standard, mais avec la variable RealisticLipSyncGenerator au lieu de VisemeGenerator.
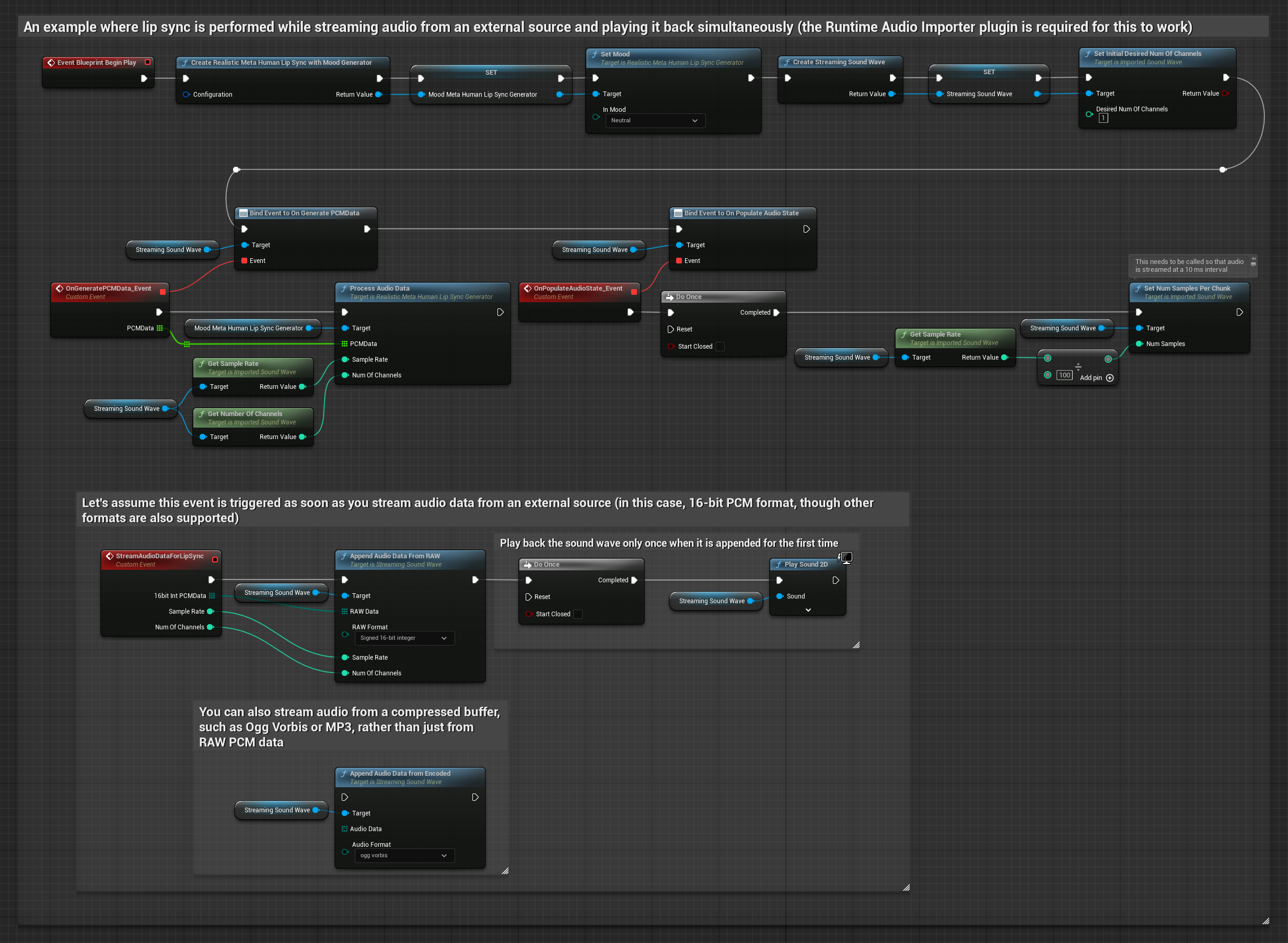
Le modèle compatible avec l'humeur utilise le même flux de traitement audio, mais avec la variable MoodMetaHumanLipSyncGenerator et des capacités supplémentaires de configuration de l'humeur.
Remarque : Lorsque vous utilisez des sources audio en streaming, assurez-vous de gérer correctement le timing de la lecture audio pour éviter une lecture déformée. Consultez la documentation Streaming Sound Wave pour plus d'informations.
Conseils de performance pour le traitement
-
Taille des Chunks : Augmenter l'option de configuration
ProcessingChunkSize(https://docs.georgy.dev/runtime-metahuman-lip-sync/plugin-configuration#processing-chunk-size) (par exemple à 320, 480 ou 640 échantillons) peut améliorer sensiblement la latence avec un impact minimal sur la qualité ou la réactivité. -
Type de modèle : Lors de l'utilisation de modèles réalistes, passer au type de modèle hautement optimisé (sélectionné par défaut) peut améliorer les performances. Notez que le modèle original peut produire une qualité légèrement supérieure, notamment avec un audio bruité.
-
Gestion des tampons : Le modèle compatible avec l’humeur traite l’audio par trames de 320 échantillons (20 ms à 16 kHz). Assurez-vous que le timing de votre entrée audio correspond à cela pour des performances optimales.
-
Recréation du générateur : Pour un fonctionnement fiable avec les modèles réalistes, recréez le générateur à chaque fois que vous souhaitez alimenter de nouvelles données audio après une période d'inactivité. Voir Recréation du générateur dans la section Dépannage pour l'explication.
Prochaines étapes
Une fois que vous avez configuré le traitement audio, vous pouvez souhaiter :
- Découvrez les options de configuration pour affiner le comportement de votre synchronisation labiale
- Ajoutez une animation de rire pour une expressivité renforcée
- Combinez la synchronisation labiale avec des animations faciales existantes en utilisant les techniques de superposition décrites dans le guide de configuration