Projets de démonstration
Pour vous aider à démarrer rapidement avec Runtime MetaHuman Lip Sync, deux projets de démonstration prêts à l'emploi sont disponibles. Tous deux sont construits avec Unreal Engine 5.6+, sont uniquement en Blueprint et fonctionnent multiplateforme sur Windows, Mac, Linux, iOS, Android et les plateformes basées sur Android (y compris Meta Quest).
Projets de démonstration disponibles
- NPC conversationnel IA / Avatar interactif
- Démonstration de base du synchronisme labial
Un flux de travail complet d'avatar conversationnel IA combinant la reconnaissance vocale, un chatbot IA (LLM), la synthèse vocale et la lecture audio avec un synchronisme labial en temps réel – le tout fonctionnant ensemble dans un seul projet. Adapté à une large gamme de cas d'utilisation – y compris les jeux, les bornes interactives, la production virtuelle, les installations muséales, les assistants numériques et les simulations de formation.
Aperçu du Pipeline
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Lorsque le LLM est en mode Streaming, sa sortie est divisée phrase par phrase et envoyée au TTS dès que chaque phrase est terminée, plutôt que d'attendre la réponse complète, afin de minimiser la latence.
Vidéos
Aperçu rapide (~30 sec)
Une courte démonstration du projet en action.
Guide complet
Un guide détaillé couvrant la configuration, les réglages et l'ensemble du pipeline conversationnel.
Téléchargements
Plugins requis et facultatifs
Le projet de démonstration est modulaire - vous n'avez besoin que des plugins pour les fournisseurs que vous souhaitez utiliser.
| Plugin | Objectif | Obligatoire ? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animation de synchronisation labiale | ✅ Toujours |
| Runtime Audio Importer | Capture et traitement audio | ✅ Toujours |
| Runtime Speech Recognizer | Reconnaissance vocale hors ligne (whisper.cpp) | ✅ Toujours |
| Runtime AI Chatbot Integrator | LLM externes (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) et/ou TTS externe (OpenAI, ElevenLabs) | 🔶 Optionnel |
| Runtime Local LLM | Inférence LLM locale via llama.cpp (modèles Llama, Mistral, Gemma, etc., GGUF) | 🔶 Optionnel |
| Runtime Text To Speech | TTS local via Piper et Kokoro | 🔶 Optionnel |
Bien que chaque plugin ci-dessus soit individuellement optionnel, vous avez besoin d'au moins un fournisseur LLM et d'au moins un fournisseur TTS pour que la démo fonctionne. Mélangez et associez librement (par exemple, LLM local + TTS ElevenLabs, ou LLM OpenAI + TTS local).
Architecture modulaire
Dans le dossier Content, vous trouverez un dossier Modules qui contient trois sous-dossiers :
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Si vous n'avez pas acquis un (ou plusieurs) des plugins optionnels, supprimez simplement le(s) dossier(s) correspondant(s). Les ressources de base du projet de démonstration (instance de jeu, widgets, etc.) ne référencent pas directement ces modules, donc leur suppression n'entraînera pas d'erreurs de référence de ressources. L'interface de configuration masquera automatiquement tout fournisseur dont le dossier est manquant.
Cette modularité s'applique uniquement aux fournisseurs LLM et TTS. La Reconnaissance Vocale (Runtime Speech Recognizer) et le Lip Sync (Runtime MetaHuman Lip Sync) font partie du projet de démonstration de base et sont toujours requis.
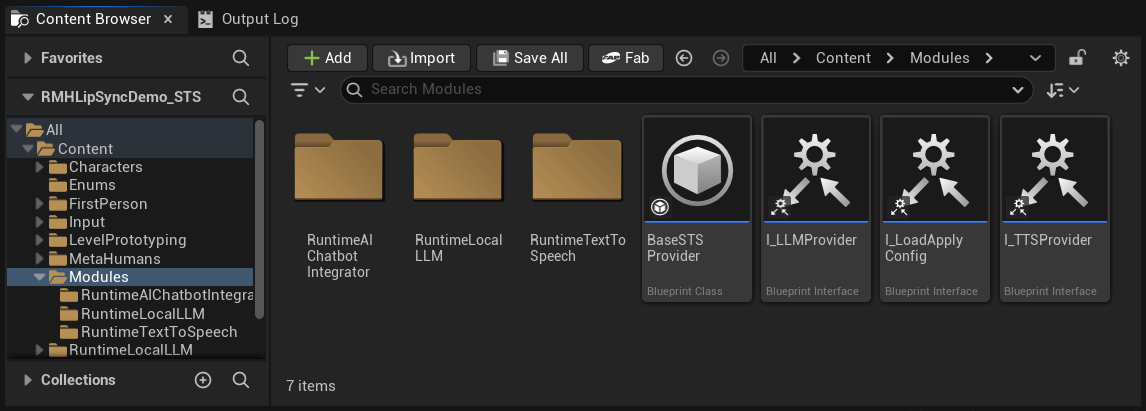
Au premier lancement, Unreal peut demander s'il faut désactiver les plugins optionnels manquants - cliquez sur Oui. Assurez-vous d'avoir également supprimé le dossier Content/Modules/ correspondant (voir ci-dessus).
Disposition du projet de démonstration
L'interface utilisateur présentée ci-dessous est entièrement construite avec UMG (Unreal Motion Graphics) et vise uniquement à démontrer le pipeline - reconnaissance vocale → LLM → TTS → synchronisation labiale. Vous êtes libre de la restyler ou de la remplacer pour l'adapter au design visuel, au schéma de contrôle ou à la plateforme de votre projet (VR/AR, mobile, console, borne interactive, etc.). Si certains widgets ne sont pas nécessaires dans votre cas d'usage, vous pouvez simplement les masquer (par exemple, définir leur visibilité sur Réduit ou Masqué).

| Area | Qu'y a-t-il |
|---|---|
| Centre | Le personnage MetaHuman. |
| Côté gauche | Quatre boutons de configuration (Reconnaissance vocale, Chatbot IA, Synthèse vocale, Animations), décrits en détail ci-dessous. |
| Centre en bas | Un bouton Démarrer l'enregistrement. Cliquez dessus pour lancer une conversation vocale : votre microphone est capturé, transcrit, envoyé au LLM, la réponse est synthétisée via TTS, puis lue avec synchronisation labiale, le tout en mode mains libres. |
| Centre droit | Un widget d’historique de conversation affichant l’intégralité des échanges entre vous et l’IA (messages de l’utilisateur et de l’assistant). Il comprend également un champ de saisie de texte, vous permettant de taper des messages directement sans utiliser la reconnaissance vocale, utile pour les tests, l’accessibilité ou lorsqu’un microphone n’est pas disponible. |
Vous pouvez mélanger librement les deux modes de saisie dans la même session - prononcer certains messages, en taper d'autres.
Si le lip sync continue de décaler de plus en plus par rapport à l'audio plus vous testez (pas seulement un délai fixe), consultez la section Taille du bloc de traitement sous Configurer les animations ci-dessous.
Boutons de configuration
Les quatre boutons de configuration sur la gauche ouvrent des panneaux dédiés pour chaque partie du pipeline :
1. Configurer la reconnaissance vocale
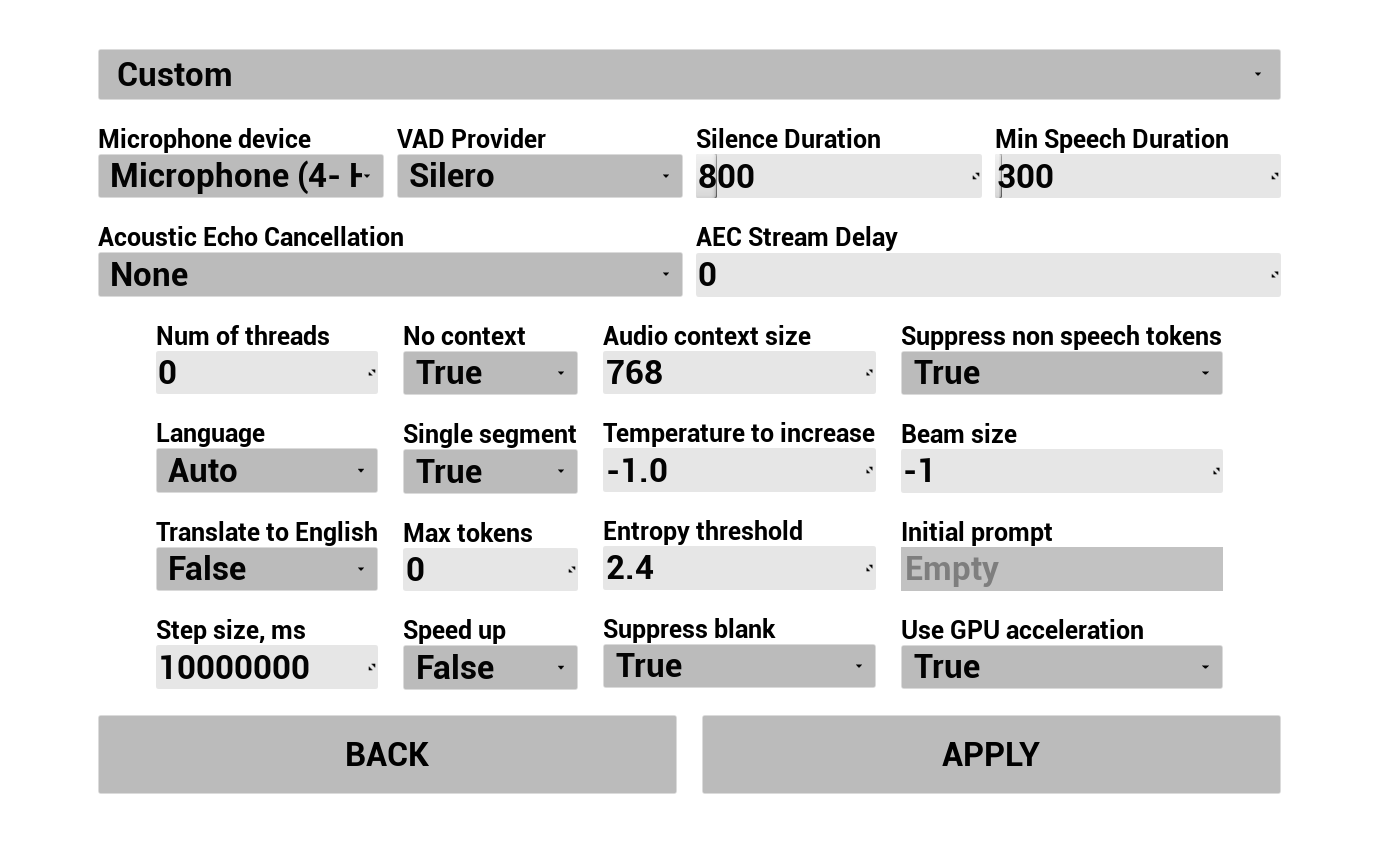
Configurez comment la voix de l'utilisateur est capturée et transcrite :
- Sélectionnez la langue
- Ajustez les paramètres de reconnaissance vocale (paramètres du modèle Whisper)
- Configurez l'AEC (annulation d'écho acoustique)
- Configurez la VAD (détection d'activité vocale)
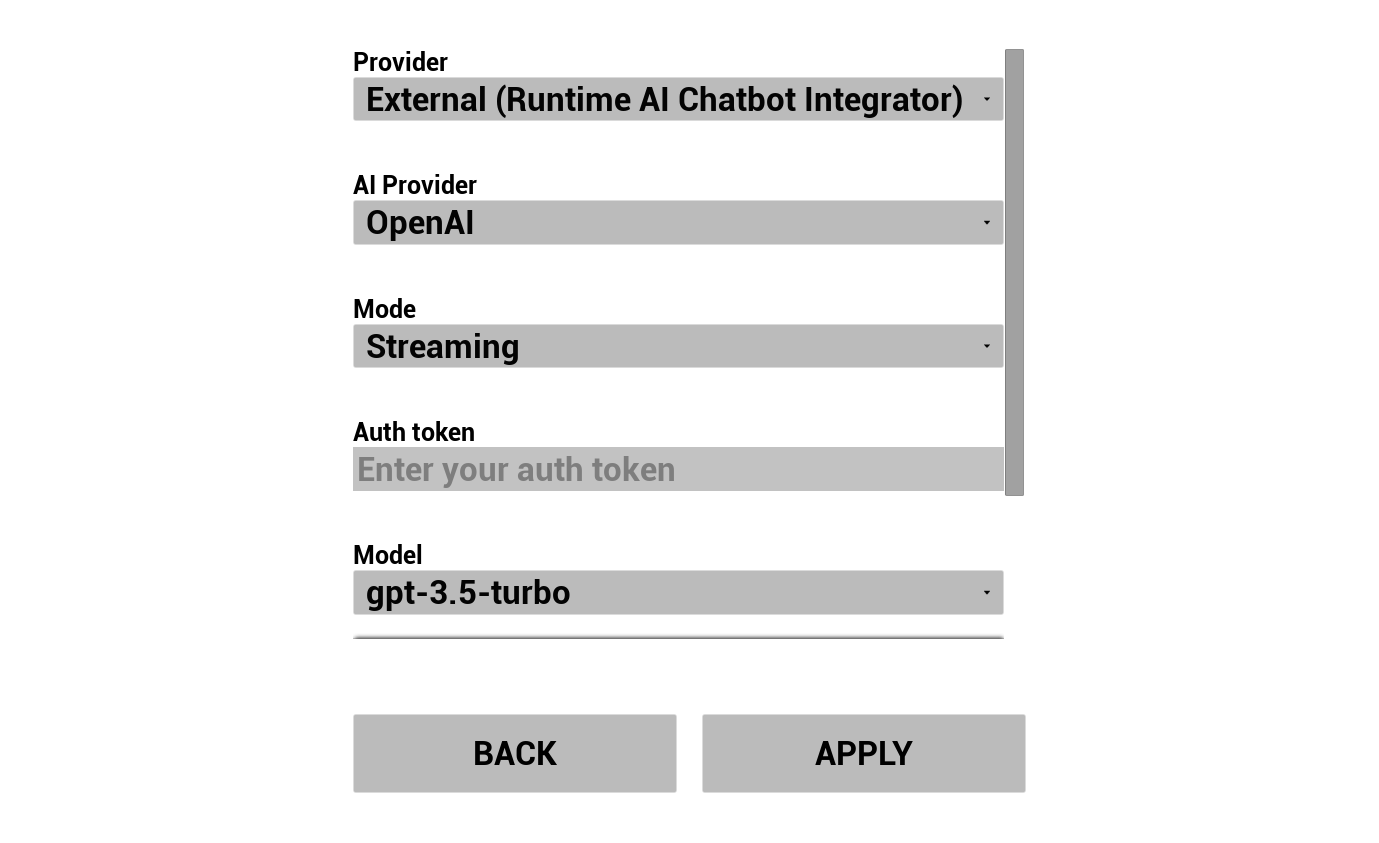
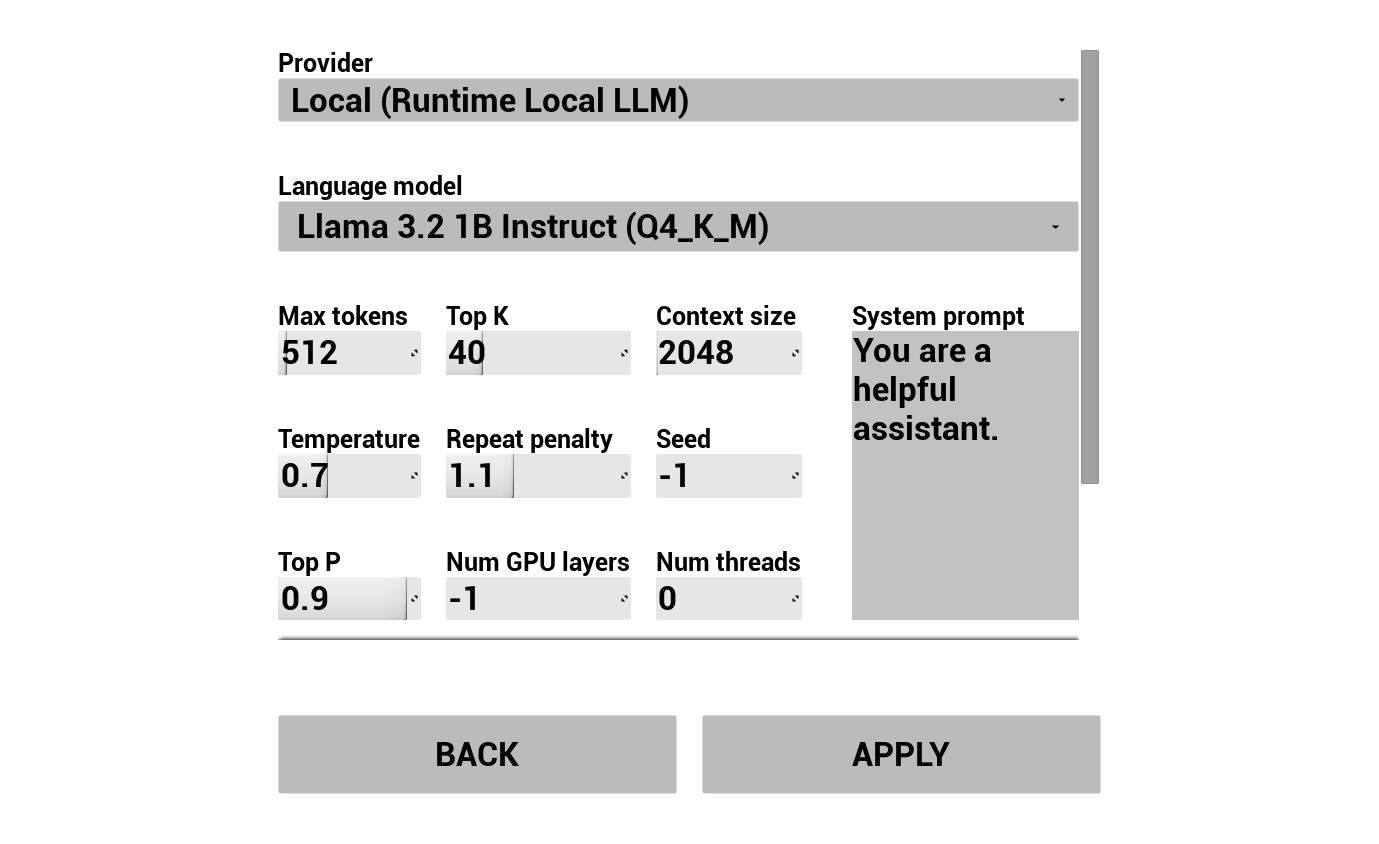
2. Configurer le chatbot IA
Choisissez votre fournisseur LLM et configurez-le :
- Sélectionnez le fournisseur (Runtime AI Chatbot Integrator ou Runtime Local LLM)
- Sélectionnez le mode : Régulier ou Streaming (dépend du fournisseur, le Streaming permet le transfert phrase par phrase au TTS, voir Aperçu du Pipeline)
- Pour les fournisseurs externes : jeton d'authentification, nom du modèle, etc.
- Pour le LLM local : sélectionnez un modèle GGUF, définissez la taille du contexte et d'autres paramètres d'inférence. Vous pouvez également télécharger votre propre modèle GGUF à l'exécution directement depuis la démo (par exemple via une URL) et l'utiliser immédiatement sans reconstruire le projet.
La liste déroulante des fournisseurs n'affiche que ceux dont le dossier de module de plugin est présent dans Content/Modules/.
3. Configurer la synthèse vocale
Choisissez votre fournisseur TTS et configurez les voix/modèles :
- Sélectionnez le fournisseur (Runtime AI Chatbot Integrator pour OpenAI/ElevenLabs, ou Runtime Text To Speech pour Piper/Kokoro local)
- Sélectionnez le mode : Normal ou Streaming (contrôle si l'audio est renvoyé en une seule fois ou au fur et à mesure de sa synthèse)
- Sélectionnez la voix/le modèle
- Ajustez les paramètres spécifiques au fournisseur

4. Configurer les Animations
Contrôlez les visuels de votre avatar IA :
- Choisissez entre 3 personnages MetaHuman pré-téléchargés (Aera, Ada, Orlando)
- Sélectionnez le modèle de synchronisation labiale (Standard ou Réaliste)
- Sélectionnez le type de modèle de synchronisation labiale - Hautement optimisé, Semi-optimisé ou Original (voir Type de modèle)
- Ajustez la taille du bloc de traitement - contrôle la fréquence d'exécution de l'inférence de synchronisation labiale (voir Taille du bloc de traitement)
- Si le lip sync prend du retard sur l'audio avec le temps en raison de la charge CPU, augmentez cette valeur à 480 ou 640.
- Sélectionnez une animation d’inactivité à jouer sur le MetaHuman pendant la conversation.

Préconfiguration de la démo dans l'éditeur
Lorsque vous travaillez avec la version source, vous pouvez pré-remplir les valeurs par défaut directement dans l'éditeur afin de ne pas avoir à les ressaisir à chaque exécution :
| What | Où |
|---|---|
| Paramètres généraux (modèle de synchronisation labiale, animation au repos, classe de personnage, reconnaissance vocale, etc.) | Content/LipSyncSTSGameInstance |
| Paramètres LLM externe / TTS externe (Intégrateur de chatbot IA runtime) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Paramètres du LLM local (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Paramètres TTS local (Synthèse vocale en temps réel) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Notes multiplateformes
Tous les plugins utilisés par la démo prennent en charge Windows, Mac, Linux, iOS, Android et les plateformes basées sur Android (y compris Meta Quest), de sorte que le projet de démonstration fonctionne également sur toutes ces plateformes. Cela le rend adapté au déploiement dans une grande variété d'environnements - des jeux et bornes de bureau aux applications mobiles, casques VR autonomes et configurations de production virtuelle sur plateau.
Pour les appareils moins puissants (mobiles, VR autonome), vous pouvez :
- Utilisez le modèle de synchronisation labiale standard au lieu de Réaliste - voir la comparaison des modèles
- Passez au type de modèle Hautement optimisé
- Augmentez la taille des blocs de traitement pour réduire la charge CPU
- Choisissez des modèles LLM / TTS plus petits
Voir Configuration spécifique à la plateforme pour les étapes de configuration supplémentaires sur Android, iOS, Mac et Linux.
Prise en charge du Pixel Streaming
Déploiement de la démo sur Pixel Streaming (cliquez pour développer)
Le projet de démonstration AI Conversationnel fonctionne également dans un environnement Pixel Streaming, vous permettant de diffuser l'avatar MetaHuman vers un client distant (par exemple un navigateur web) tout en capturant l'audio du microphone de l'utilisateur côté client. Une seule modification du projet de démonstration est nécessaire.
1. Installez l'extension Pixel Streaming pour Runtime Audio Importer
Le plugin Runtime Audio Importer fournit un plugin d'extension gratuit qui permet de capturer l'audio depuis un client Pixel Streaming. Selon la version de l'infrastructure Pixel Streaming que vous utilisez, installez l'un des éléments suivants :
- Extension Pixel Streaming (pour le plugin Pixel Streaming original), ou
- Extension Pixel Streaming 2 (pour le plugin Pixel Streaming 2 plus récent)
Les liens de téléchargement et les étapes d'installation sont disponibles ici : Pixel Streaming Audio Capture - Installation du plugin d'extension.
2. Remplacez le nœud d'onde sonore capturable dans LipSyncSTSGameInstance
Après l'installation du plugin d'extension :
- Dans le Content Browser, naviguez vers
/All/Gameet ouvrez l'assetLipSyncSTSGameInstance. - Passez au Event Graph.
- Localisez Event Init et suivez le flux d'exécution jusqu'à trouver la paire de nœuds :
Create Capturable Sound Wave→Set Capturable Sound Wave. - Remplacez l'appel
Create Capturable Sound WaveparCreate Pixel Streaming Capturable Sound WaveouCreate Pixel Streaming 2 Capturable Sound Wave, selon la version de l'infrastructure Pixel Streaming que vous ciblez. - Connectez sa sortie au même nœud
Set Capturable Sound Wave.
Après cela, le projet est prêt à être déployé sur Pixel Streaming : la reconnaissance vocale, le LLM, la TTS et le lip sync fonctionneront tous comme avant, mais avec l'audio capturé depuis le client distant au lieu d'un microphone local.
Apporter votre propre personnage
Le projet de démonstration est livré avec trois personnages MetaHuman d'exemple (Aera, Ada, Orlando), mais vous pouvez importer votre propre MetaHuman et l'utiliser dans la démo.
📺 Tutoriel vidéo : Ajout d’un personnage MetaHuman personnalisé au projet de démonstration
Le plugin Runtime MetaHuman Lip Sync lui-même prend en charge de nombreux autres systèmes de personnages au-delà des MetaHumans (personnages basés sur ARKit, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe, etc. - voir le Guide de configuration des personnages personnalisés). Que vous construisiez un PNJ de jeu, un présentateur virtuel, un assistant de kiosque ou un humain numérique pour la production virtuelle, le plugin s'adapte à votre pipeline de personnages.
Un projet de démonstration plus simple qui se concentre uniquement sur la fonctionnalité de synchronisation labiale elle-même, sans le flux de travail conversationnel IA complet. Idéal si vous souhaitez simplement voir la synchronisation labiale en action avec diverses sources audio.
Vidéo à la une
Téléchargements
Ce qui est inclus
Cette démo présente les workflows de base du lip sync :
- Entrée microphone - synchronisation labiale en temps réel à partir d'un audio en direct
- Lecture de fichier audio - synchronisation labiale à partir de fichiers audio importés
- Synthèse vocale - synchronisation labiale pilotée par la parole synthétisée
Plugins requis et facultatifs
| Plugin | Objectif | Obligatoire ? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animation de synchronisation labiale | ✅ Requis |
| Runtime Audio Importer | Importation et capture audio | ✅ Requis |
| Runtime Text To Speech | TTS local pour la scène de démonstration TTS | 🔶 Optionnel |
| Runtime AI Chatbot Integrator | Fournisseurs TTS externes (OpenAI, ElevenLabs) | 🔶 Optionnel |
Notes pour le modèle de synchronisation labiale standard
Si vous prévoyez d'utiliser le Modèle Standard (au lieu du Réaliste) dans l'un ou l'autre des projets de démonstration, vous devrez installer le plugin Standard Lip Sync Extension. Consultez Extension du modèle standard pour les instructions d'installation.
Besoin d'aide ?
Si vous rencontrez des problèmes lors de la configuration ou de l'exécution des projets de démonstration, n'hésitez pas à nous contacter :
Pour les demandes de développement personnalisé (par exemple, étendre la démo avec votre propre logique, l’adapter à une plateforme spécifique ou à un pipeline de personnages), contactez [email protected].