Configuration du plugin
Configuration du modèle
Pour un fonctionnement fiable avec les modèles Realistic et Mood-Enabled Realistic, recréez le générateur avant chaque nouvelle lecture audio plutôt que de le réutiliser lors de longues périodes de silence. Consultez Recréation du générateur dans la section Dépannage pour plus de détails.
Configuration du modèle standard
Le nœud Create Runtime Viseme Generator utilise des paramètres par défaut qui fonctionnent bien pour la plupart des scénarios. La configuration est gérée via les propriétés du nœud de mélange de l'Animation Blueprint.
Pour les options de configuration de l'Animation Blueprint, consultez la section Configuration du Lip Sync ci-dessous.
Configuration de modèle réaliste
Le nœud Create Realistic MetaHuman Lip Sync Generator accepte un paramètre Configuration optionnel qui vous permet de personnaliser le comportement du générateur :
Type de modèle
Le paramètre Type de modèle détermine la version du modèle réaliste à utiliser :
| Type de modèle | Performance | Qualité Visuelle | Gestion du bruit | Cas d'utilisation recommandés |
|---|---|---|---|---|
| Hautement optimisé (Par défaut) | Performances maximales, utilisation CPU minimale | Bonne qualité | Peut montrer des mouvements de bouche notables en présence de bruits de fond ou de sons non vocaux. | Environnements audio propres, scénarios critiques en termes de performances |
| Semi-optimisé | Bonnes performances, utilisation modérée du CPU. | Haute qualité | Meilleure stabilité avec un audio bruité | Performance équilibrée et qualité, conditions audio mixtes |
| Original | Adapté pour une utilisation en temps réel sur les processeurs modernes. | La plus haute qualité | Le plus stable avec le bruit de fond et les sons non vocaux. | Productions de haute qualité, environnements audio bruyants, lorsque la précision maximale est nécessaire |
Paramètres de performance
Intra Op Threads : Contrôle le nombre de threads utilisés pour les opérations internes de traitement du modèle.
- 0 (Par défaut/Automatique) : Utilise la détection automatique (généralement 1/4 des cœurs CPU disponibles, maximum 4)
- 1-16 : Spécifiez manuellement le nombre de threads. Des valeurs plus élevées peuvent améliorer les performances sur les systèmes multi-cœurs, mais utilisent davantage de CPU.
Inter Op Threads : Contrôle le nombre de threads utilisés pour l'exécution parallèle de différentes opérations du modèle.
- 0 (Par défaut/Automatique) : Utilise la détection automatique (généralement 1/8 des cœurs CPU disponibles, maximum 2)
- 1-8 : Spécifiez manuellement le nombre de threads. Généralement maintenu bas pour un traitement en temps réel.
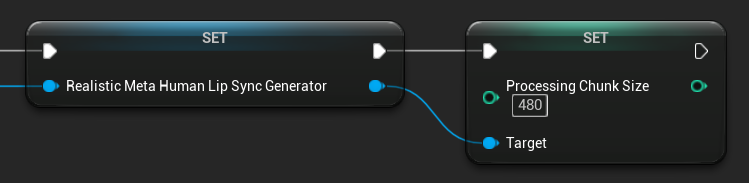
Taille du bloc de traitement
La taille du bloc de traitement détermine le nombre d'échantillons traités à chaque étape d'inférence. La valeur par défaut est de 160 échantillons (10 ms d'audio à 16 kHz) :
- Des valeurs plus petites offrent des mises à jour plus fréquentes mais augmentent l'utilisation du CPU
- Des valeurs plus grandes réduisent la charge du CPU mais peuvent diminuer la réactivité de la synchronisation labiale
- Il est recommandé d'utiliser des multiples de 160 pour un alignement optimal
Configuration du modèle avec gestion de l'humeur
Le nœud Create Realistic MetaHuman Lip Sync With Mood Generator offre des options de configuration supplémentaires au-delà du modèle réaliste de base :
Configuration de base
Lookahead Ms : Timing d'anticipation en millisecondes pour une meilleure précision de synchronisation labiale.
- Par défaut : 80 ms
- Plage : 20 ms à 200 ms (doit être divisible par 20)
- Des valeurs plus élevées offrent une meilleure synchronisation mais augmentent la latence
Type de sortie : Contrôle les contrôles faciaux qui sont générés.
- Visage complet : Les 81 contrôles faciaux (sourcils, yeux, nez, bouche, mâchoire, langue)
- Bouche uniquement : Seuls les contrôles liés à la bouche, à la mâchoire et à la langue
Paramètres de performance : Utilise les mêmes réglages de threads Intra Op et Inter Op que le modèle réaliste standard.
Paramètres d’humeur
Moods disponibles :
- Neutre, Heureux, Triste, Dégoût, Colère, Surprise, Peur
- Confiant, Excité, Ennuyé, Enjoué, Confus
Intensité de l’humeur : Contrôle à quel point l’humeur affecte l’animation (0.0 à 1.0)
Contrôle d’Humeur en Temps Réel
Vous pouvez ajuster les paramètres d'humeur pendant l'exécution à l'aide des fonctions suivantes :
- Définir l'humeur : Modifier le type d'humeur actuel
- Définir l'intensité de l'humeur : Ajuster la force avec laquelle l'humeur affecte l'animation (0.0 à 1.0)
- Définir l'avance (ms) : Modifier le timing d'avance pour la synchronisation
- Définir le type de sortie : Basculer entre les contrôles Visage complet et Bouche uniquement

Guide de sélection de l'humeur
Choisissez des humeurs appropriées en fonction de votre contenu :
| Mood | Idéal pour | Plage d'intensité typique |
|---|---|---|
| Neutre | Conversation générale, narration, état par défaut | 0,5 - 1,0 |
| Heureux | Contenu positif, dialogues joyeux, célébrations | 0,6 - 1,0 |
| Triste | Contenu mélancolique, scènes émotionnelles, moments sombres | 0,5 - 0,9 |
| Dégoût | Réactions négatives, contenu déplaisant, rejet | 0,4 - 0,8 |
| Colère | Dialogues agressifs, scènes conflictuelles, frustration | 0,6 - 1,0 |
| Surprise | Événements inattendus, révélations, réactions de choc | 0,7 - 1,0 |
| Peur | Situations menaçantes, anxiété, dialogue nerveux | 0,5 - 0,9 |
| Confiant | Présentations professionnelles, dialogue de leadership, discours assertif | 0,7 - 1,0 |
| Excité | Contenu énergique, annonces, dialogue enthousiaste | 0,8 - 1,0 |
| Ennuyé | Contenu monotone, dialogue désintéressé, discours fatigué | 0,3 - 0,7 |
| Joueur | Conversation décontractée, humour, interactions légères | 0,6 - 0,9 |
| Confus(e) | Dialogue chargé de questions, incertitude, perplexité | 0,4 - 0,8 |
Configuration du Blueprint d'Animation
Configuration de la synchronisation labiale
- Modèle Standard
- Modèles réalistes
Le nœud Blend Runtime MetaHuman Lip Sync dispose d'options de configuration dans son panneau de propriétés :
| Propriété | Défaut | Description |
|---|---|---|
| Vitesse d'interpolation | 25 | Contrôle la rapidité avec laquelle les mouvements des lèvres passent d'un visème à l'autre. Des valeurs plus élevées entraînent des transitions plus rapides et plus abruptes. |
| Réinitialiser le temps | 0,2 | La durée en secondes après laquelle la synchronisation labiale est réinitialisée. Cela permet d'éviter que la synchronisation labiale ne se poursuive après l'arrêt de l'audio. |
Animation de rire
Vous pouvez également ajouter des animations de rire qui réagiront dynamiquement aux rires détectés dans l'audio.
- Ajoutez le nœud
Blend Runtime MetaHuman Laughter - Connectez votre variable
RuntimeVisemeGeneratorà la brocheViseme Generator - Si vous utilisez déjà la synchronisation labiale :
- Connectez la sortie du nœud
Blend Runtime MetaHuman Lip Syncà laSource Posedu nœudBlend Runtime MetaHuman Laughter - Connectez la sortie du nœud
Blend Runtime MetaHuman Laughterà la brocheResultde laOutput Pose
- Connectez la sortie du nœud
- Si vous utilisez uniquement le rire sans synchronisation labiale :
- Connectez votre pose source directement à la
Source Posedu nœudBlend Runtime MetaHuman Laughter - Connectez la sortie à la broche
Result
- Connectez votre pose source directement à la
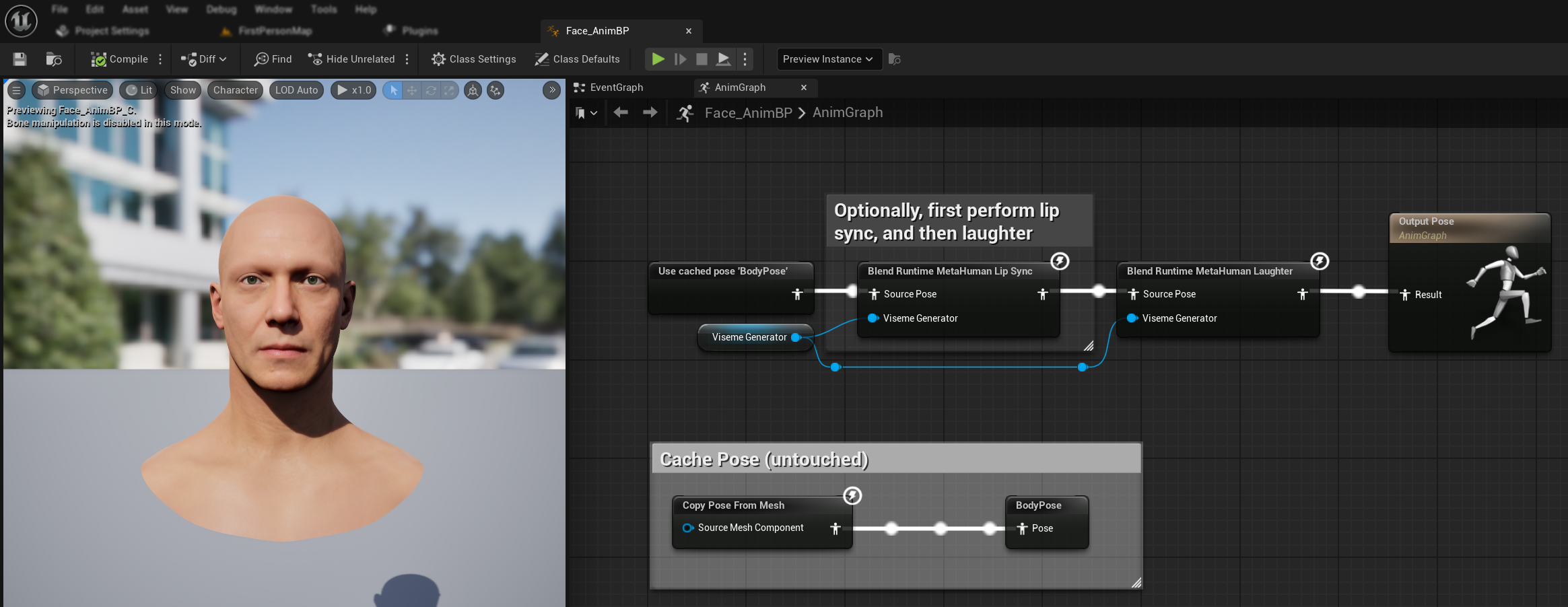
Lorsque le rire est détecté dans l'audio, votre personnage s'animera dynamiquement en conséquence :
Configuration du rire
Le nœud Blend Runtime MetaHuman Laughter possède ses propres options de configuration :
| Propriété | Défaut | Description |
|---|---|---|
| Vitesse d'interpolation | 25 | Contrôle la rapidité avec laquelle les mouvements des lèvres passent d'une animation de rire à une autre. Des valeurs plus élevées entraînent des transitions plus rapides et plus brusques. |
| Réinitialiser le temps | 0,2 | La durée en secondes après laquelle le rire est réinitialisé. Cela permet d'éviter que le rire ne se poursuive après l'arrêt de l'audio. |
| Poids maximal du rire | 0,7 | Définit l'intensité maximale de l'animation de rire (0.0 - 1.0). |
Remarque : La détection du rire est actuellement disponible uniquement avec le modèle Standard.
Le nœud Blend Realistic MetaHuman Lip Sync dispose d'options de configuration dans son panneau de propriétés :
| Propriété | Défaut | Description |
|---|---|---|
| Vitesse d'interpolation | 30 | Contrôle la rapidité avec laquelle les expressions faciales transitent pendant un discours actif. Des valeurs plus élevées entraînent des transitions plus rapides et plus abruptes. |
| Vitesse d'interpolation au repos | 15 | Contrôle la vitesse à laquelle les expressions faciales reviennent à l'état neutre/repos. Des valeurs plus faibles créent des retours plus fluides et progressifs vers la pose de repos. |
| Réinitialiser le temps | 0,2 | Durée en secondes après laquelle la synchronisation labiale revient à l'état inactif. Utile pour éviter que les expressions ne se poursuivent après l'arrêt de l'audio. |
| Préserver l'état inactif | faux | Lorsqu'il est activé, préserve le dernier état émotionnel pendant les périodes d'inactivité au lieu de revenir à un état neutre. |
| Préserver les expressions oculaires | true | Contrôle si les contrôles faciaux liés aux yeux sont préservés pendant l'état inactif. Uniquement effectif lorsque l'option Préserver l'état inactif est activée. |
| Préserver les expressions des sourcils | true | Contrôle si les contrôles faciaux liés aux sourcils sont préservés pendant l'état inactif. Uniquement effectif lorsque l'option Préserver l'état inactif est activée. |
| Préserver la forme de la bouche | faux | Contrôle si les formes de bouche (à l’exclusion des mouvements spécifiques à la parole comme la langue et la mâchoire) sont conservées pendant l’état inactif. Uniquement effectif lorsque l’option « Conserver l’état inactif » est activée. |
Conservation de l'état inactif
La fonctionnalité Preserve Idle State traite la manière dont le modèle Realistic gère les périodes de silence. Contrairement au modèle Standard qui utilise des visèmes discrètes et revient systématiquement à des valeurs nulles pendant le silence, le réseau neuronal du modèle Realistic peut maintenir un positionnement facial subtil qui diffère de la pose de repos par défaut du MetaHuman.
Quand activer :
- Maintenir les expressions émotionnelles entre les segments de parole
- Préserver les traits de personnalité du personnage
- Assurer la continuité visuelle dans les séquences cinématiques
Options de contrôle régional :
- Expressions oculaires : Préserve le plissement, l'écarquillement des yeux et le positionnement des paupières
- Expressions des sourcils : Maintient le positionnement des sourcils et du front
- Forme de la bouche : Conserve la courbure générale de la bouche tout en permettant aux mouvements de la parole (langue, mâchoire) de se réinitialiser
Combinaison avec les animations existantes
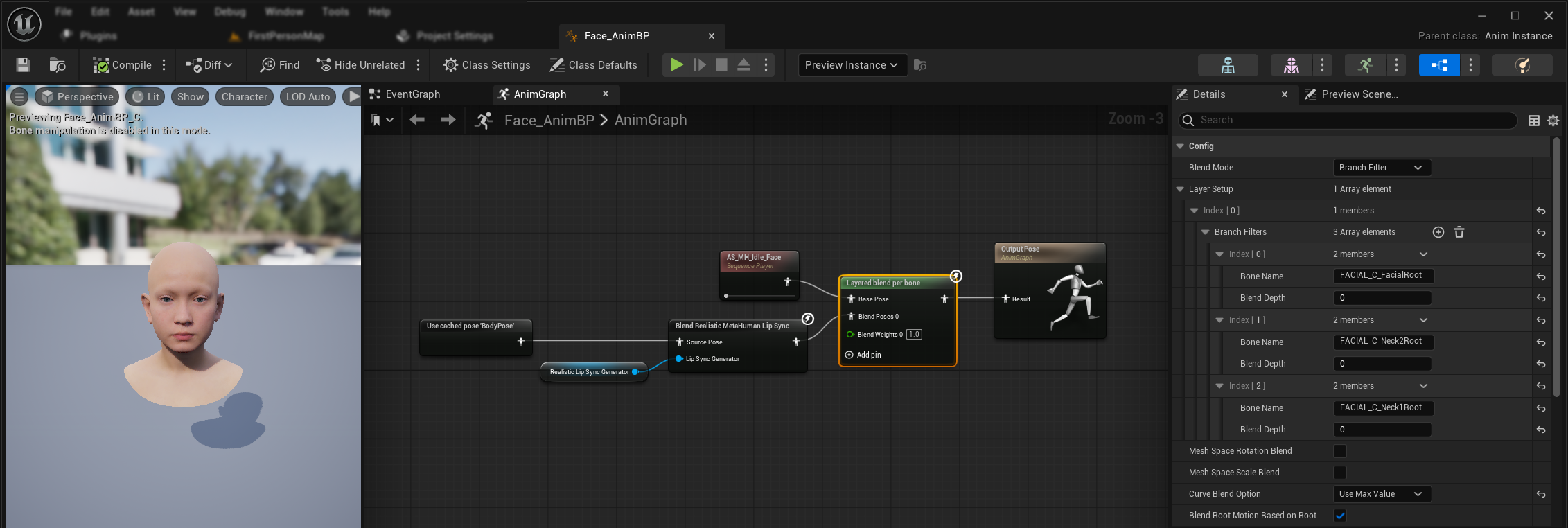
Pour appliquer la synchronisation labiale et le rire en parallèle des animations corporelles existantes et des animations faciales personnalisées sans les écraser :
Cette configuration s'applique à l'Animation Blueprint du visage, car le lip sync ne fait pas partie de l'Animation Blueprint du corps. Pour les animations corporelles personnalisées (par exemple, le torse, les bras et autres mouvements du corps), connectez simplement votre séquence d'animation (via un Sequence Player) directement à la pose de sortie dans l'Animation Blueprint du corps. Aucune configuration supplémentaire n'est nécessaire à cet endroit.
- Ajoutez un nœud
Layered blend per boneentre vos animations corporelles et la sortie finale. Assurez-vous queUse Attached Parentest vrai. - Configurez la configuration des couches :
- Ajoutez 1 élément au tableau
Layer Setup - Ajoutez 3 éléments aux
Branch Filterspour le calque, avec lesBone Names suivants :FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Ajoutez 1 élément au tableau
- Important pour les animations faciales personnalisées : Dans l'
Option de fusion de courbes, sélectionnez "Utiliser la valeur maximale". Cela permet aux animations faciales personnalisées (expressions, émotions, etc.) d'être correctement superposées au lip sync. - Effectuez les connexions :
- Votre animation personnalisée (généralement un
Sequence Playeravec l'actif de séquence d'animation souhaité) → entréeBase Pose - Sortie d'animation faciale (provenant des nœuds de synchronisation labiale et/ou de rire) → entrée
Blend Poses 0 - Nœud de fusion par couches → pose
Resultfinale
- Votre animation personnalisée (généralement un
Sélection de l'ensemble de cibles de morphing
- Modèle Standard
- Modèles réalistes
Le modèle standard utilise des assets de pose qui prennent en charge nativement toute convention de nommage de cibles de morphing grâce à la configuration personnalisée des assets de pose. Aucune configuration supplémentaire n'est nécessaire.
Le nœud Blend Realistic MetaHuman Lip Sync inclut une propriété Morph Target Set qui détermine la convention de nommage des cibles de morphing à utiliser pour l'animation faciale :
| Jeu de cibles de morphing | Description | Cas d'utilisation |
|---|---|---|
| MetaHuman (Par défaut) | Noms de cibles de morphing MetaHuman standard (par exemple, CTRL_expressions_jawOpen) | Personnages MetaHuman |
| ARKit | Noms compatibles avec Apple ARKit (par exemple, JawOpen, MouthSmileLeft) | Personnages basés sur ARKit |
Ajustement fin du comportement de synchronisation labiale
Mise à l'échelle de courbes spécifiques de synchronisation labiale
Vous pouvez atténuer (ou amplifier) les mouvements faciaux individuels produits par le lip sync à l'aide d'un nœud Modify Curve. Cela est utile lorsqu'une courbe particulière semble trop prononcée pour votre contenu audio ou votre personnage.
Configuration :
- Après votre nœud de fusion de synchronisation labiale, ajoutez un nœud
Modify Curve - Faites un clic droit sur le nœud et sélectionnez Add Curve Pin, puis saisissez le nom de la courbe que vous souhaitez mettre à l'échelle
- Définissez la propriété Apply Mode du nœud sur Scale
- Définissez le paramètre Value : les valeurs inférieures à 1,0 atténuent le mouvement, les valeurs supérieures à 1,0 l'amplifient (par exemple, 0,8 = réduction de 20 %)
Courbes couramment mises à l’échelle :
| Nom de la courbe | Objectif | S'applique à | Ajustement typique |
|---|---|---|---|
CTRL_expressions_tongueOut | Protrusion de la langue vers l'avant lors de certains phonèmes | Modèle standard | 0,8 pour réduire la protrusion |
CTRL_expressions_jawOpen | Plage d'ouverture de la mâchoire | Modèles réalistes | 0,9 pour réduire le mouvement de la mâchoire |
Vous pouvez ajouter plusieurs broches de courbe au même nœud Modify Curve pour mettre à l'échelle plusieurs courbes à la fois.
Ajustement fin spécifique à l’humeur
Pour les modèles compatibles avec l'humeur, vous pouvez affiner des expressions émotionnelles spécifiques :
Contrôle des sourcils :
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- Sourcil intérieur levéCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- Sourcil extérieur levéCTRL_expressions_browDownL/CTRL_expressions_browDownR- Abaissement des sourcils
Contrôle de l’expression des yeux :
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Plissement des yeuxCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Élévation des joues
Comparaison et sélection des modèles
Choisir entre les modèles
Lorsque vous décidez quel modèle de synchronisation labiale utiliser pour votre projet, tenez compte des facteurs suivants :
| Considération | Modèle Standard | Modèle réaliste | Modèle réaliste avec gestion de l'humeur |
|---|---|---|---|
| Compatibilité des personnages | MétaHumains et tous les types de personnages personnalisés | MetaHumans (et personnages ARKit) | MetaHumans (et personnages ARKit) |
| Qualité Visuelle | Bon lip sync avec des performances efficaces. | Réalisme amélioré avec des mouvements de bouche plus naturels | Réalisme amélioré avec expressions émotionnelles |
| Performance | Optimisé pour toutes les plateformes, y compris mobile/RV. | Exigences de ressources plus élevées | Exigences de ressources plus élevées |
| Fonctionnalités | 14 visèmes, détection du rire | 81 contrôles faciaux, 3 niveaux d'optimisation | 81 contrôles faciaux, 12 humeurs, sortie configurable |
| Prise en charge des plateformes | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Cas d'utilisation | Applications générales, jeux, VR/AR, mobile | Expériences cinématographiques, interactions en gros plan | Récit émotionnel, interaction avancée des personnages |
Compatibilité des versions du moteur
Si vous utilisez Unreal Engine 5.2, les modèles réalistes peuvent ne pas fonctionner correctement en raison d'un bug dans la bibliothèque de rééchantillonnage d'UE. Pour les utilisateurs d'UE 5.2 qui ont besoin d'une fonctionnalité de synchronisation labiale fiable, veuillez utiliser le Modèle Standard à la place.
Ce problème est spécifique à UE 5.2 et n'affecte pas les autres versions du moteur.
Recommandations de performance
- Pour la plupart des projets, le Modèle Standard offre un excellent équilibre entre qualité et performances
- Utilisez le Modèle Réaliste lorsque vous avez besoin de la plus haute fidélité visuelle pour les personnages MetaHuman
- Utilisez le Modèle Réaliste avec Humeur lorsque le contrôle de l'expression émotionnelle est important pour votre application
- Tenez compte des capacités de performance de votre plateforme cible lors du choix entre les modèles
- Testez différents niveaux d'optimisation pour trouver le meilleur équilibre pour votre cas d'utilisation spécifique
Dépannage
Problèmes courants
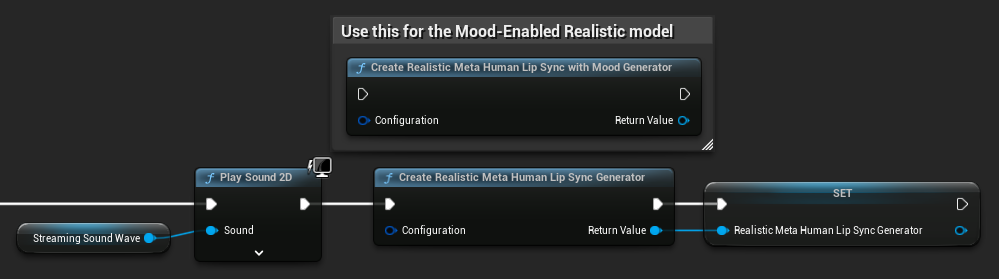
Recréation du générateur pour les modèles réalistes : Pour un fonctionnement fiable et cohérent avec les modèles réalistes, il est recommandé de recréer le générateur à chaque fois que vous souhaitez alimenter de nouvelles données audio après une période d'inactivité. Cela est dû au comportement du runtime ONNX qui peut entraîner l'arrêt de la synchronisation labiale lors de la réutilisation des générateurs après des périodes de silence.
Par exemple, vous pourriez recréer le générateur de synchronisation labiale à chaque début de lecture, comme lorsque vous appelez Play Sound 2D ou utilisez toute autre méthode pour démarrer la lecture d'une onde sonore et la synchronisation labiale :
Emplacement du plugin pour l'intégration de la synthèse vocale en temps réel : Lorsque vous utilisez Runtime MetaHuman Lip Sync avec Runtime Text To Speech (les deux plugins utilisent ONNX Runtime), vous pouvez rencontrer des problèmes dans les builds packagés si les plugins sont installés dans le dossier Marketplace du moteur. Pour résoudre ce problème :
- Localisez les deux plugins dans votre dossier d'installation UE sous
\Engine\Plugins\Marketplace(par exemple,C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Déplacez les dossiers
RuntimeMetaHumanLipSyncetRuntimeTextToSpeechvers le dossierPluginsde votre projet - Si votre projet ne possède pas de dossier
Plugins, créez-en un dans le même répertoire que votre fichier.uproject - Redémarrez l'éditeur Unreal
Cela résout les problèmes de compatibilité pouvant survenir lorsque plusieurs plugins basés sur ONNX Runtime sont chargés depuis le répertoire Marketplace du moteur.
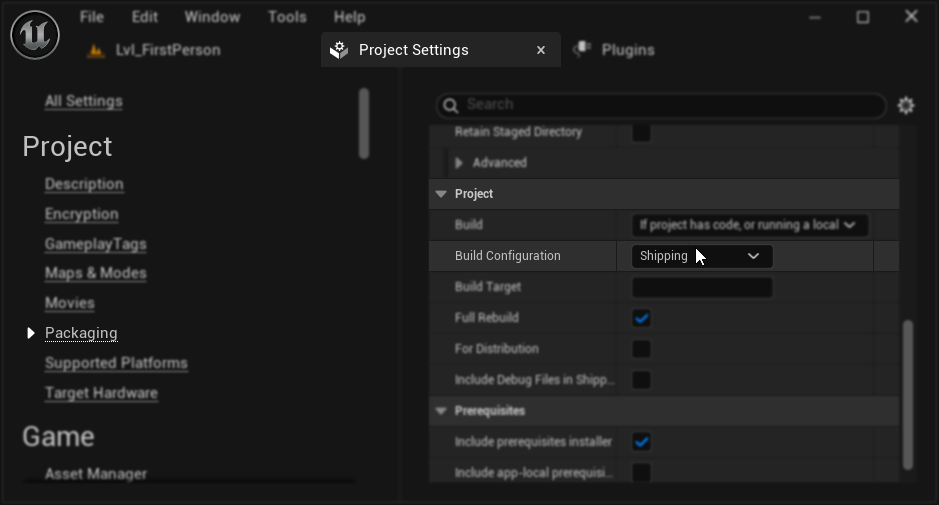
Configuration de packaging (Windows) : Si la synchronisation labiale ne fonctionne pas correctement dans votre projet packagé sous Windows, assurez-vous d'utiliser la configuration de build Shipping au lieu de Development. La configuration Development peut entraîner des problèmes avec le runtime ONNX des modèles réalistes dans les builds packagés.
Pour résoudre ceci :
- Dans vos Paramètres du projet → Empaquetage, définissez la Configuration de build sur Shipping
- Reconditionnez votre projet
Dans certains projets Blueprint uniquement, Unreal Engine peut encore compiler en configuration Development même lorsque Shipping est sélectionné. Si cela se produit, convertissez votre projet en projet C++ en ajoutant au moins une classe C++ (elle peut être vide). Pour ce faire, allez dans Outils → Nouvelle classe C++ dans le menu de l'éditeur UE et créez une classe vide. Cela forcera le projet à compiler correctement en configuration Shipping. Votre projet peut rester fonctionnellement Blueprint uniquement, la classe C++ n'est nécessaire que pour une configuration de compilation correcte.
Réactivité dégradée du Lip Sync : Si vous constatez que le lip sync devient moins réactif avec le temps lors de l'utilisation de Streaming Sound Wave ou Capturable Sound Wave, cela peut être dû à une accumulation de mémoire. Par défaut, la mémoire est réallouée à chaque ajout de nouvel audio. Pour éviter ce problème, appelez périodiquement la fonction ReleaseMemory pour libérer la mémoire accumulée, par exemple toutes les 30 secondes environ.
Optimisation des performances :
- Ajustez la taille des blocs de traitement pour les modèles réalistes en fonction de vos besoins de performance
- Utilisez des nombres de threads appropriés pour votre matériel cible
- Envisagez d'utiliser le type de sortie Bouche uniquement pour les modèles avec humeur lorsque l'animation faciale complète n'est pas nécessaire