Liste des paramètres de reconnaissance
Ces paramètres ne peuvent être définis que lorsque le reconnaisseur n'est pas en cours d'exécution.
Ceci n'est pas une liste exhaustive des paramètres disponibles dans Whisper. Seuls les plus importants sont exposés ici. Si nécessaire, cette liste sera mise à jour.
Définir les paramètres de reconnaissance
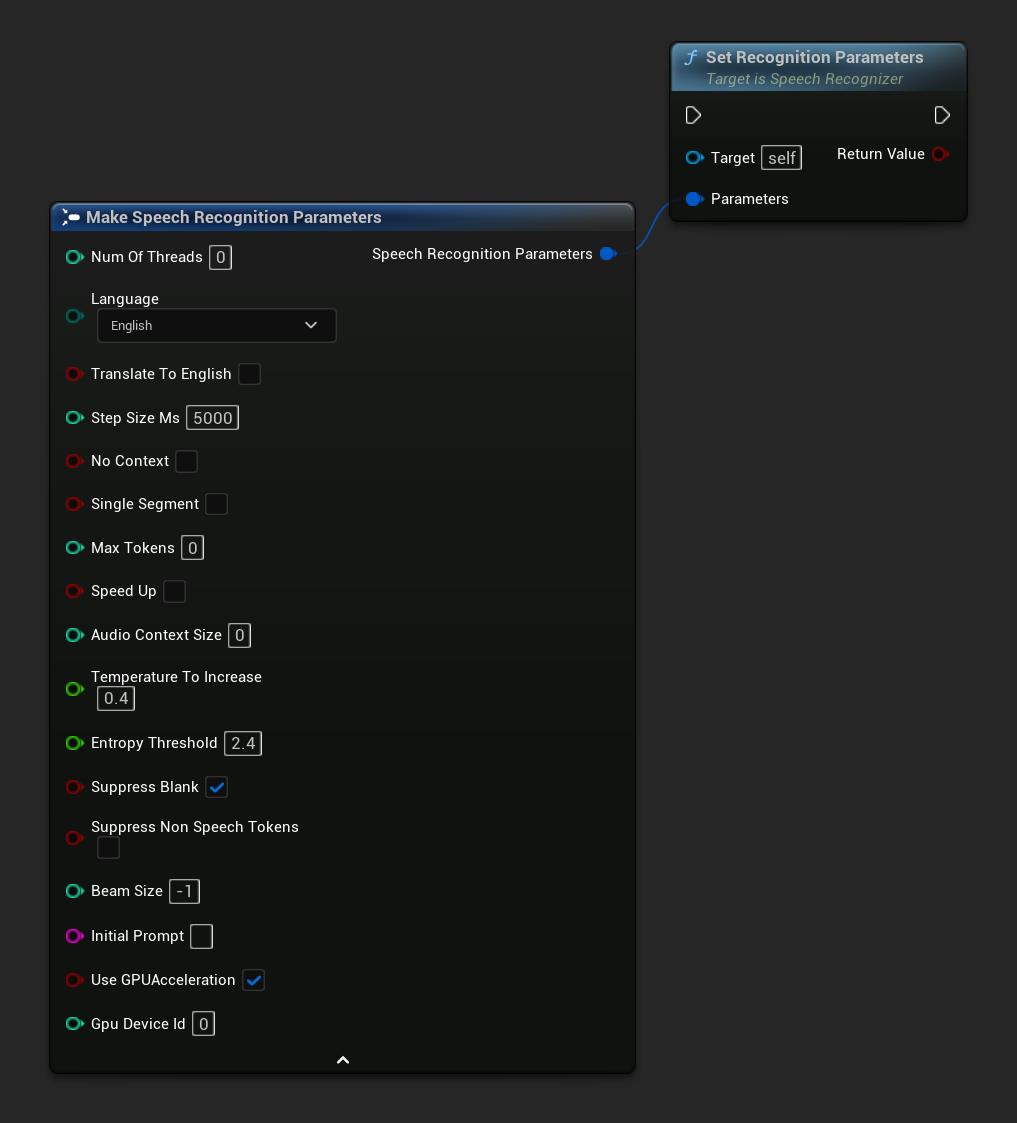
Définit les paramètres pour la reconnaissance vocale. Si vous souhaitez modifier uniquement des paramètres spécifiques, envisagez d'utiliser les fonctions de définition individuelles.
Définir les paramètres par défaut pour le streaming
Définit les paramètres par défaut adaptés à la reconnaissance vocale en streaming.
Cette fonction écrase tous les paramètres précédemment appliqués. Assurez-vous de l'appeler avant de définir vos paramètres personnalisés si vous avez besoin d'utiliser les paramètres par défaut de streaming comme configuration de base.
Définir les paramètres par défaut pour le non-streaming
Définit les paramètres par défaut adaptés à la reconnaissance vocale non-streaming.
Cette fonction écrase tous les paramètres précédemment appliqués. Assurez-vous de l'appeler avant de définir vos paramètres personnalisés si vous avez besoin d'utiliser les paramètres par défaut de non-streaming comme configuration de base.
Définir le nombre de threads
Définit le nombre de threads à utiliser pour la reconnaissance vocale. Définissez cette valeur sur 0 pour utiliser le nombre de cœurs.
Définir la langue
Définit la langue à utiliser pour la reconnaissance vocale. Doit être prise en charge par le modèle de langue sélectionné dans les paramètres de l'éditeur.
Définir la langue sur Auto diminuera la précision et les performances de la reconnaissance.
Obtenir la langue détectée
Obtient la langue détectée lors de la dernière reconnaissance. Renvoie la langue sous forme de valeur d'énumération.
Note : Cette fonction ne fonctionne qu'après qu'une reconnaissance a été effectuée. Elle renvoie Auto si la détection de langue a échoué ou n'a pas été effectuée. Ceci est particulièrement utile lors de l'utilisation de la détection automatique de langue pour identifier quelle langue a réellement été reconnue.
Obtenir le code de langue
Convertit une valeur d'énumération de langue en sa chaîne de code de langue (par exemple, En -> "en", Fr -> "fr", De -> "de").
Obtenir le nom complet de la langue
Convertit une valeur d'énumération de langue en son nom complet de langue (par exemple, En -> "English", Fr -> "French", De -> "German").
Définir la traduction en anglais
![]()
Définit s'il faut traduire les mots reconnus en anglais. Si vrai, le modèle de langue doit être multilingue.
Définir la taille du pas
Définit la taille du pas en millisecondes. Détermine la fréquence d'envoi des données audio pour la reconnaissance. La valeur par défaut est de 5000 ms (5 secondes).
Définir sans contexte
Définit s'il faut utiliser la transcription passée (le cas échéant) comme prompt initial pour le décodeur.
Définir segment unique
Définit s'il faut forcer une sortie en segment unique (utile pour le streaming).
Définir le nombre maximum de tokens
Définit le nombre maximum de tokens par segment de texte. Utilisez 0 pour aucune limite.
Définir l'accélération
Définit s'il faut accélérer la reconnaissance par 2x en utilisant le Phase Vocoder. Définissez-le sur false pour améliorer la qualité de la sortie.
Définir la taille du contexte audio
Définit la taille du contexte audio. Définissez-le sur 0 pour améliorer la qualité de la sortie.
Définir la température à augmenter
Définit la température à augmenter lors du repli lorsque le décodage échoue à atteindre l'un des seuils ci-dessous.
Définir le seuil d'entropie
Définit le seuil d'entropie. Si le taux de compression est supérieur à cette valeur, considérez le décodage comme ayant échoué. Similaire au "compression_ratio_threshold" d'OpenAI
Définir la suppression des blancs
![]()
Définit s'il faut supprimer les blancs apparaissant dans les sorties.
Définir la suppression des tokens non vocaux
Définit s'il faut supprimer les tokens non vocaux apparaissant dans les sorties.
Définir la taille du faisceau
Définit le nombre de faisceaux dans la recherche par faisceau. Applicable uniquement lorsque la température est zéro.
Définir le prompt initial
Définit le prompt initial pour la première fenêtre. Cela peut être utilisé pour fournir un contexte à la reconnaissance pour augmenter la probabilité de prédire correctement les mots, par exemple des vocabulaires personnalisés ou des noms propres.
Pour plus de détails sur les stratégies de prompting efficaces, consultez le Guide de prompting Whisper.
Définir l'accélération GPU
Définit s'il faut utiliser l'accélération GPU pour la reconnaissance vocale (applicable uniquement sur Windows pour le moment).
Définir l'ID du périphérique GPU
Définit l'ID du périphérique GPU à utiliser pour la reconnaissance vocale. La valeur par défaut est 0. Ceci est utile pour les systèmes avec plusieurs GPU pour spécifier quel GPU doit être utilisé pour le processus de reconnaissance. Si l'ID du périphérique GPU spécifié est invalide, le premier index de périphérique GPU disponible sera utilisé à la place.