अनुवाद प्रदाता
AI Localization Automator पाँच अलग-अलग AI प्रदाताओं का समर्थन करता है, जिनमें से प्रत्येक की अपनी अनूठी ताकतें और कॉन्फ़िगरेशन विकल्प हैं। अपनी परियोजना की आवश्यकताओं, बजट और गुणवत्ता आवश्यकताओं के अनुरूप सबसे उपयुक्त प्रदाता चुनें।
Ollama (Local AI)
सर्वोत्तम: गोपनीयता-संवेदनशील परियोजनाओं, ऑफ़लाइन अनुवाद, असीमित उपयोग के लिए
Ollama AI मॉडल आपके मशीन पर स्थानीय रूप से चलाता है, जो API लागत या इंटरनेट आवश्यकता के बिना पूर्ण गोपनीयता और नियंत्रण प्रदान करता है।
लोकप्रिय मॉडल
- translategemma:12b (Gemma 3 पर आधारित विशेष अनुवाद मॉडल)
- llama3.2 (सामान्य उद्देश्य के लिए अनुशंसित)
- mistral (कुशल विकल्प)
- codellama (कोड-जागरूक अनुवाद)
- और भी कई सामुदायिक मॉडल
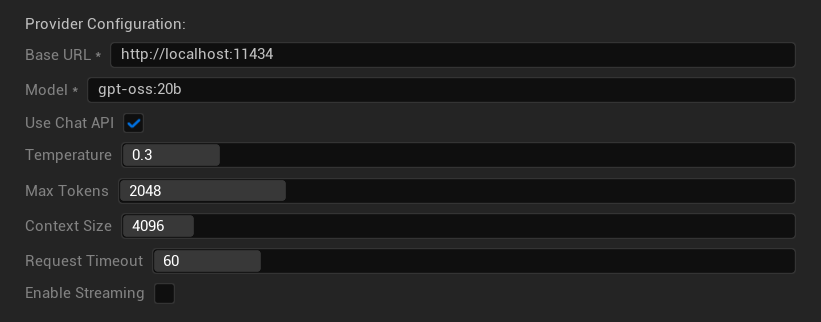
कॉन्फ़िगरेशन विकल्प
- बेस URL: स्थानीय Ollama सर्वर (डिफ़ॉल्ट:
http://localhost:11434) - मॉडल: स्थानीय रूप से इंस्टॉल किए गए मॉडल का नाम (आवश्यक)
- चैट API का उपयोग करें: बेहतर वार्तालाप हैंडलिंग के लिए सक्षम करें
- तापमान: 0.0-2.0 (0.3 अनुशंसित)
- अधिकतम टोकन: 1-8,192 टोकन
- संदर्भ आकार: 512-32,768 टोकन
- अनुरोध समय सीमा: 10-300 सेकंड (स्थानीय मॉडल धीमे हो सकते हैं)
- स्ट्रीमिंग सक्षम करें: रीयल-टाइम प्रतिक्रिया प्रसंस्करण के लिए
ताकतें
- ✅ पूर्ण गोपनीयता (कोई डेटा आपकी मशीन से बाहर नहीं जाता)
- ✅ कोई API लागत या उपयोग सीमा नहीं
- ✅ ऑफ़लाइन काम करता है
- ✅ मॉडल पैरामीटर पर पूर्ण नियंत्रण
- ✅ सामुदायिक मॉडलों की विस्तृत विविधता
- ✅ विक्रेता लॉक-इन नहीं
विचार
- 💻 स्थानीय सेटअप और सक्षम हार्डवेयर की आवश्यकता
- ⚡ आम तौर पर क्लाउड प्रदाताओं की तुलना में धीमा
- 🔧 अधिक तकनीकी सेटअप आवश्यक
- 📊 अनुवाद गुणवत्ता मॉडल के अनुसार काफी भिन्न होती है (कुछ क्लाउड प्रदाताओं से अधिक हो सकते हैं)
- 💾 मॉडलों के लिए बड़ी भंडारण आवश्यकताएँ
Ollama सेटअप करना
- Ollama इंस्टॉल करें: ollama.ai से डाउनलोड करें और अपने सिस्टम पर इंस्टॉल करें
- मॉडल डाउनलोड करें: अपना चुना हुआ मॉडल डाउनलोड करने के लिए
ollama pull translategemma:12bका उपयोग करें - सर्वर शुरू करें: Ollama स्वचालित रूप से चलता है, या
ollama serveसे शुरू करें - प्लगइन कॉन्फ़िगर करें: प्लगइन सेटिंग्स में बेस URL और मॉडल नाम सेट करें
- कनेक्शन परीक्षण करें: जब आप कॉन्फ़िगरेशन लागू करेंगे तो प्लगइन कनेक्टिविटी सत्यापित करेगा
OpenAI
सर्वोत्तम: उच्चतम समग्र अनुवाद गुणवत्ता, व्यापक मॉडल चयन के लिए
OpenAI अपने Chat Completions API के माध्यम से उद्योग-अग्रणी भाषा मॉडल प्रदान करता है, जिसमें नवीनतम GPT मॉडल, तर्क मॉडल और वेब खोज-सक्षम मॉडल शामिल हैं।
उपलब्ध मॉडल
GPT-5 परिवार (फ्लैगशिप मॉडल)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
GPT-4.1 परिवार (उच्च-प्रदर्शन)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
GPT-4o परिवार (मल्टीमॉडल)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O-सीरीज़ (तर्क मॉडल — तापमान/top_p समर्थित नहीं)
- o1, o1-pro, o3, o3-mini, o4-mini
वेब खोज मॉडल (तापमान/top_p समर्थित नहीं)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
लीगेसी / पूर्वावलोकन
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
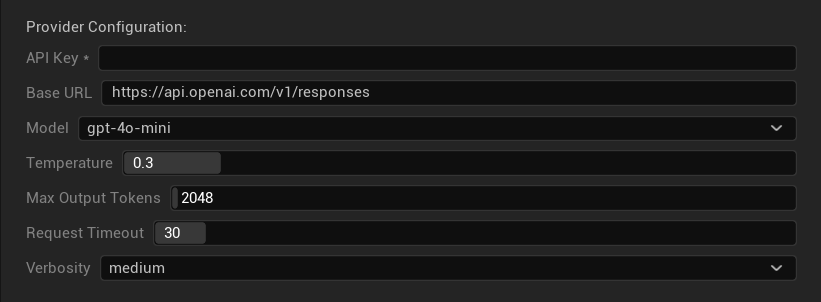
कॉन्फ़िगरेशन विकल्प
- API कुंजी: आपकी OpenAI API कुंजी (आवश्यक)
- बेस URL: API एंडपॉइंट (डिफ़ॉल्ट:
https://api.openai.com/v1/chat/completions) - मॉडल: ऊपर सूचीबद्ध उपलब्ध मॉडलों में से चुनें
- तापमान का उपयोग करें: तापमान पैरामीटर चालू/बंद करें (o-सीरीज़ तर्क और वेब खोज मॉडलों के लिए स्वचालित रूप से अनदेखा किया जाता है)
- तापमान: 0.0–2.0 (अनुवाद स्थिरता के लिए 0.3 अनुशंसित)
- टॉप P: 0.0–1.0 नाभिक नमूनाकरण पैरामीटर (o-सीरीज़ तर्क और वेब खोज मॉडलों के लिए अनदेखा किया जाता है)
- अधिकतम पूर्णता टोकन: 1–128,000 टोकन (आउटपुट और तर्क दोनों टोकन शामिल हैं)
- अनुरोध समय सीमा: 5–300 सेकंड
ताकतें
- ✅ लगातार उच्च-गुणवत्ता अनुवाद
- ✅ उत्कृष्ट संदर्भ समझ
- ✅ मजबूत प्रारूप संरक्षण
- ✅ व्यापक भाषा समर्थन
- ✅ विश्वसनीय API अपटाइम
विचार
- 💰 प्रति अनुरोध उच्च लागत
- 🌐 इंटरनेट कनेक्शन आवश्यक
- ⏱️ टियर के आधार पर उपयोग सीमाएँ
Anthropic Claude
सर्वोत्तम: सूक्ष्म अनुवाद, रचनात्मक सामग्री, सुरक्षा-केंद्रित अनुप्रयोगों के लिए
Claude मॉडल संदर्भ और सूक्ष्मता को समझने में उत्कृष्ट हैं, जो उन्हें कथा-प्रधान खेलों और जटिल स्थानीयकरण परिदृश्यों के लिए आदर्श बनाते हैं।
उपलब्ध मॉडल
Claude 4.6 परिवार (नवीनतम)
- claude-opus-4-6, claude-sonnet-4-6
Claude 4.5 परिवार
- claude-haiku-4-5 (तेज़ और कुशल)
- claude-sonnet-4-5, claude-opus-4-5
Claude 4.x परिवार
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Claude 3.x परिवार (लीगेसी)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
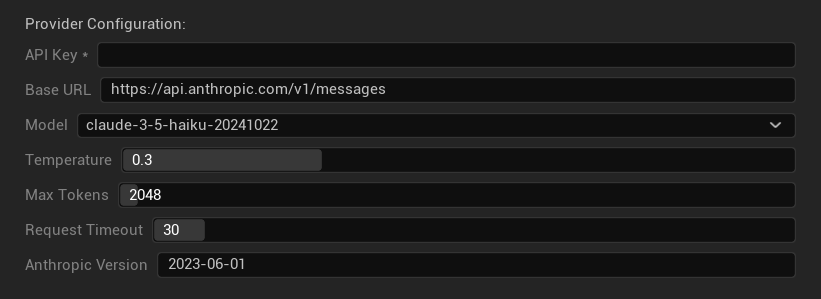
कॉन्फ़िगरेशन विकल्प
- API कुंजी: आपकी Anthropic API कुंजी (आवश्यक)
- बेस URL: Claude API एंडपॉइंट
- मॉडल: Claude मॉडल परिवार से चुनें
- तापमान: 0.0–1.0 (0.3 अनुशंसित)
- टॉप K: टॉप-के नमूनाकरण पैरामीटर (0 = सेट नहीं)
- अधिकतम टोकन: 1–64,000 टोकन
- अनुरोध समय सीमा: 5–300 सेकंड
- Anthropic संस्करण: API संस्करण हेडर
ताकतें
- ✅ असाधारण संदर्भ जागरूकता
- ✅ रचनात्मक/कथा सामग्री के लिए बढ़िया
- ✅ मजबूत सुरक्षा सुविधाएँ
- ✅ विस्तृत तर्क क्षमताएँ (3.7+ मॉडलों पर विस्तारित सोच)
- ✅ उत्कृष्ट निर्देश अनुसरण
विचार
- 💰 प्रीमियम मूल्य निर्धारण मॉडल
- 🌐 इंटरनेट कनेक्शन आवश्यक
- 📏 मॉडल के अनुसार टोकन सीमाएँ भिन्न होती हैं
DeepSeek
सर्वोत्तम: लागत-प्रभावी अनुवाद, उच्च थ्रूपुट, बजट-सचेत परियोजनाओं के लिए
DeepSeek अन्य प्रदाताओं की लागत के एक अंश में प्रतिस्पर्धी अनुवाद गुणवत्ता प्रदान करता है, जो इसे बड़े पैमाने की स्थानीयकरण परियोजनाओं के लिए आदर्श बनाता है।
उपलब्ध मॉडल
- deepseek-chat (सामान्य उद्देश्य, अनुशंसित)
- deepseek-reasoner (उन्नत तर्क क्षमताएँ)
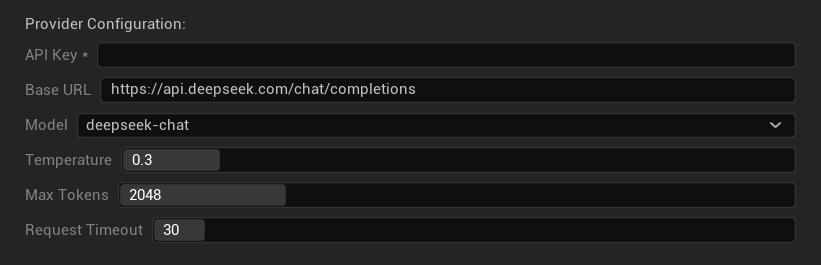
कॉन्फ़िगरेशन विकल्प
- API कुंजी: आपकी DeepSeek API कुंजी (आवश्यक)
- बेस URL: DeepSeek API एंडपॉइंट
- मॉडल: चैट और रीज़नर मॉडल के बीच चुनें
- तापमान: 0.0-2.0 (0.3 अनुशंसित)
- अधिकतम टोकन: 1-8,192 टोकन
- अनुरोध समय सीमा: 5-300 सेकंड
ताकतें
- ✅ बहुत लागत-प्रभावी
- ✅ अच्छी अनुवाद गुणवत्ता
- ✅ तेज़ प्रतिक्रिया समय
- ✅ सरल कॉन्फ़िगरेशन
- ✅ उच्च दर सीमाएँ
विचार
- 📏 कम टोकन सीमाएँ
- 🆕 नया प्रदाता (कम ट्रैक रिकॉर्ड)
- 🌐 इंटरनेट कनेक्शन आवश्यक
Google Gemini
सर्वोत्तम: बहुभाषी परियोजनाएँ, लागत-प्रभावी अनुवाद, Google पारिस्थितिकी तंत्र एकीकरण के लिए
Gemini मॉडल उन्नत तर्क के लिए सोच मोड जैसी अद्वितीय सुविधाओं के साथ प्रतिस्पर्धी मूल्य निर्धारण और मजबूत बहुभाषी क्षमताएँ प्रदान करते हैं।
उपलब्ध मॉडल
Gemini 3.x परिवार (पूर्वावलोकन)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Gemini 2.5 परिवार (सोच समर्थन के साथ)
- gemini-2.5-pro (सोच के साथ फ्लैगशिप)
- gemini-2.5-flash (तेज़, सोच समर्थन के साथ)
- gemini-2.5-flash-lite (हल्का वेरिएंट)
Gemini 2.0 परिवार
- gemini-2.0-flash, gemini-2.0-flash-lite
नवीनतम उपनाम
- gemini-flash-latest, gemini-flash-lite-latest
कॉन्फ़िगरेशन विकल्प
- API कुंजी: आपकी Google AI API कुंजी (आवश्यक)
- बेस URL: Gemini API एंडपॉइंट
- मॉडल: Gemini मॉडल परिवार से चुनें
- तापमान: 0.0–2.0 (0.3 अनुशंसित)
- अधिकतम आउटपुट टोकन: 1–8,192 टोकन
- अनुरोध समय सीमा: 5–300 सेकंड
- सोच सक्षम करें: 2.5+ मॉडलों के लिए उन्नत तर्क सक्रिय करें
- सोच बजट: सोच टोकन आवंटन को नियंत्रित करें (0 = कोई सोच नहीं)
ताकतें
- ✅ मजबूत बहुभाषी समर्थन
- ✅ प्रतिस्पर्धी मूल्य निर्धारण
- ✅ उन्नत तर्क (सोच मोड)
- ✅ Google पारिस्थितिकी तंत्र एकीकरण
- ✅ नवीनतम मॉडलों तक पूर्वावलोकन पहुंच के साथ नियमित मॉडल अपडेट
विचार
- 🧠 सोच मोड टोकन उपयोग बढ़ाता है
- 📏 मॉडल के अनुसार परिवर्तनशील टोकन सीमाएँ
- 🌐 इंटरनेट कनेक्शन आवश्यक
सही प्रदाता चुनना
| प्रदाता | सर्वोत्तम | गुणवत्ता | लागत | सेटअप | गोपनीयता |
|---|---|---|---|---|---|
| Ollama | गोपनीयता/ऑफ़लाइन | परिवर्तनशील* | मुफ़्त | उन्नत | स्थानीय |
| OpenAI | उच्चतम गुणवत्ता | ⭐⭐⭐⭐⭐ | 💰💰💰 | आसान | क्लाउड |
| Claude | रचनात्मक सामग्री | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | आसान | क्लाउड |
| DeepSeek | बजट परियोजनाएँ | ⭐⭐⭐⭐ | 💰 | आसान | क्लाउड |
| Gemini | बहुभाषी | ⭐⭐⭐⭐ | 💰 | आसान | क्लाउड |
*Ollama के लिए गुणवत्ता उपयोग किए गए स्थानीय मॉडल के आधार पर काफी भिन्न होती है - कुछ आधुनिक स्थानीय मॉडल क्लाउड प्रदाताओं से मेल खा सकते हैं या उनसे अधिक हो सकते हैं।
प्रदाता कॉन्फ़िगरेशन युक्तियाँ
सभी क्लाउड प्रदाताओं के लिए:
- API कुंजियों को सुरक्षित रूप से संग्रहीत करें और उन्हें संस्करण नियंत्रण में कमिट न करें
- सुसंगत अनुवादों के लिए रूढ़िवादी तापमान सेटिंग्स (0.3) से शुरुआत करें
- अपने API उपयोग और लागतों की निगरानी करें
- बड़े अनुवाद रन से पहले छोटे बैचों के साथ परीक्षण करें
Ollama के लिए:
- पर्याप्त RAM सुनिश्चित करें (बड़े मॉडलों के लिए 8GB+ अनुशंसित)
- बेहतर मॉडल लोडिंग प्रदर्शन के लिए SSD भंडारण का उपयोग करें
- तेज़ अनुमान के लिए GPU त्वरण पर विचार करें
- उत्पादन अनुवादों के लिए इस पर भरोसा करने से पहले स्थानीय रूप से परीक्षण करें