प्लगइन का उपयोग कैसे करें
Runtime AI Chatbot Integrator दो मुख्य कार्यक्षमताएँ प्रदान करता है: टेक्स्ट-टू-टेक्स्ट चैट और टेक्स्ट-टू-स्पीच (TTS)। दोनों सुविधाएँ एक समान वर्कफ़्लो का पालन करती हैं:
- अपना API प्रदाता टोकन पंजीकृत करें
- सुविधा-विशिष्ट सेटिंग्स कॉन्फ़िगर करें
- अनुरोध भेजें और प्रतिक्रियाओं को संसाधित करें
प्रदाता टोकन पंजीकृत करें
किसी भी अनुरोध को भेजने से पहले, RegisterProviderToken फ़ंक्शन का उपयोग करके अपना API प्रदाता टोकन पंजीकृत करें।
Ollama स्थानीय रूप से चलता है और इसे API टोकन की आवश्यकता नहीं होती है। Ollama के लिए आप इस चरण को छोड़ सकते हैं।
- Blueprint
- C++
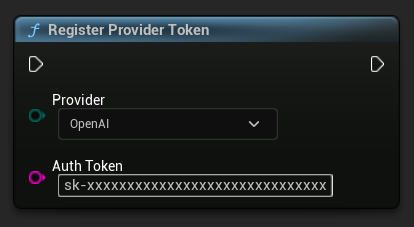
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
// Register other providers as needed
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::Anthropic,
TEXT("sk-ant-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::DeepSeek,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
etc
टेक्स्ट-टू-टेक्स्ट चैट कार्यक्षमता
प्लगइन प्रत्येक प्रदाता के लिए दो चैट अनुरोध मोड का समर्थन करता है:
नॉन-स्ट्रीमिंग चैट अनुरोध
एक ही कॉल में पूर्ण प्रतिक्रिया प्राप्त करें।
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
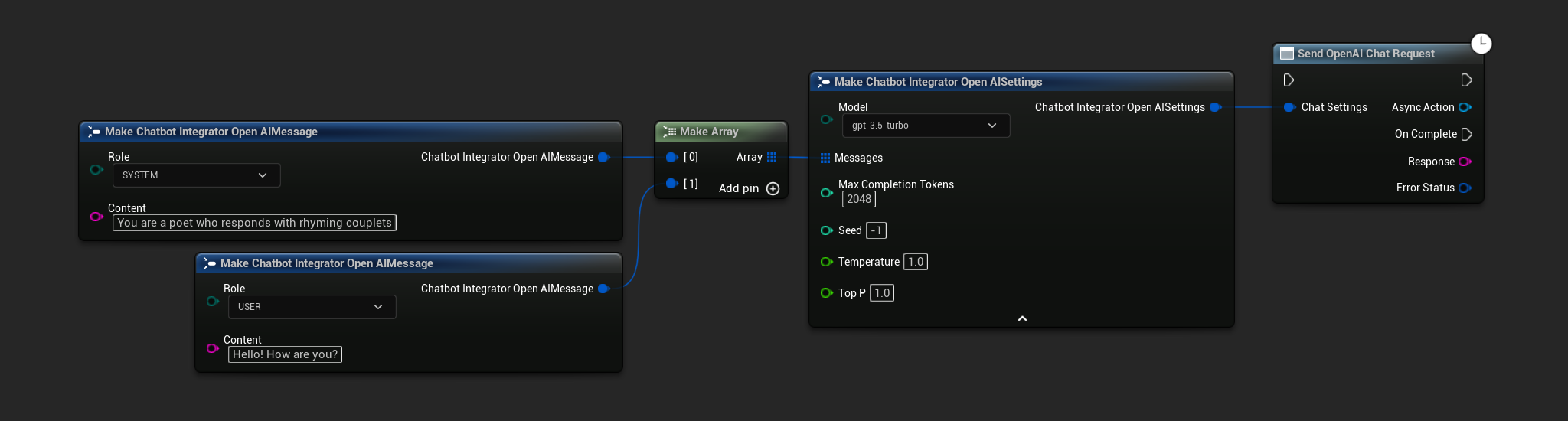
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
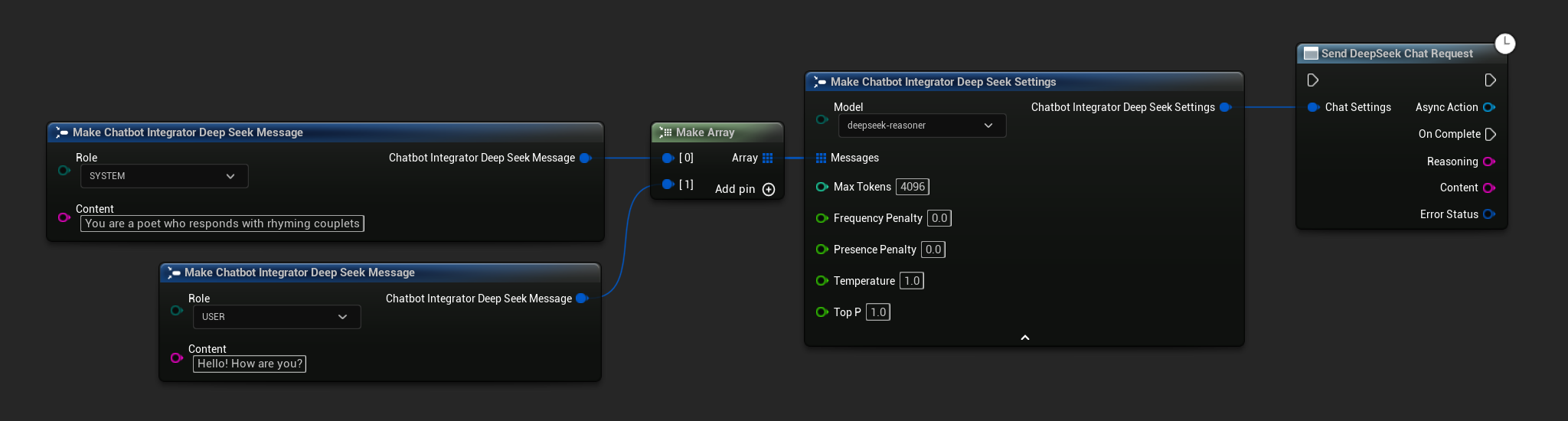
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
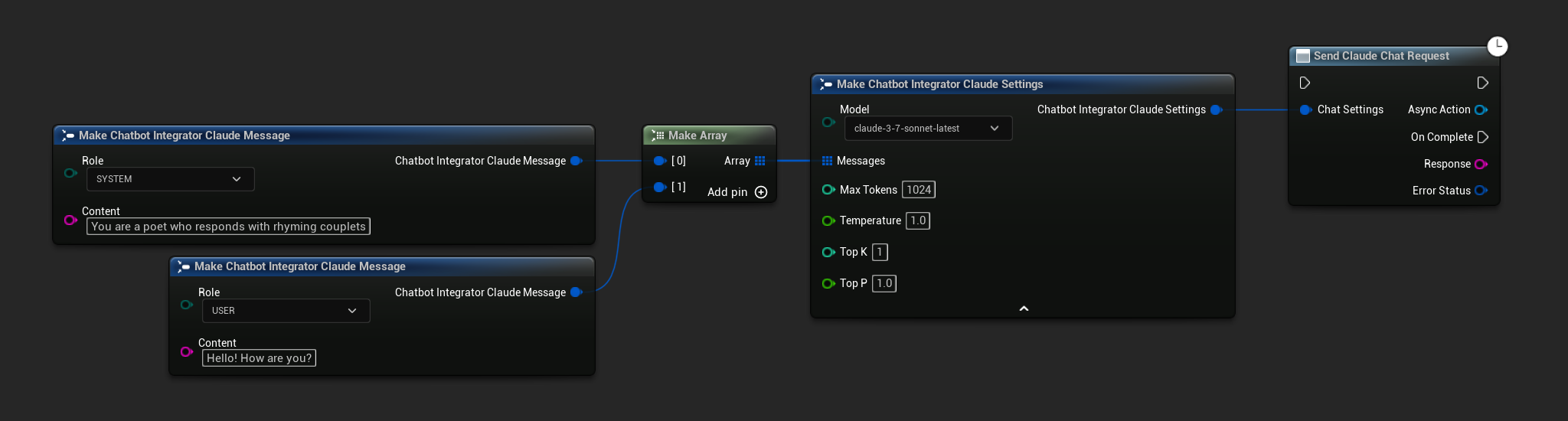
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaude::SendChatRequestNative(
Settings,
FOnClaudeChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
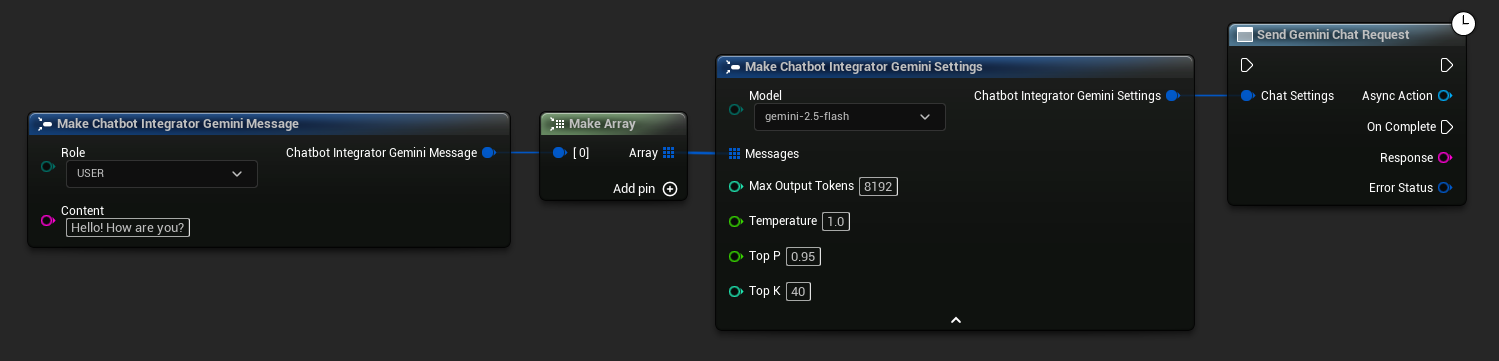
// Example of sending a non-streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGemini::SendChatRequestNative(
Settings,
FOnGeminiChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
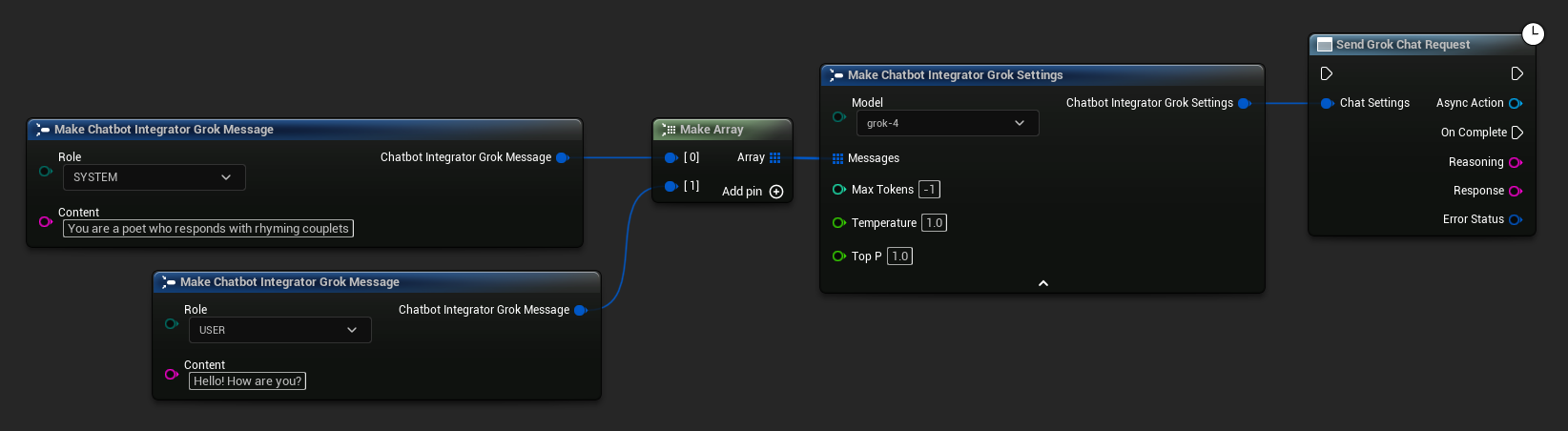
// Example of sending a non-streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrok::SendChatRequestNative(
Settings,
FOnGrokChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Response: %s, Error: %d: %s"),
*Reasoning, *Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
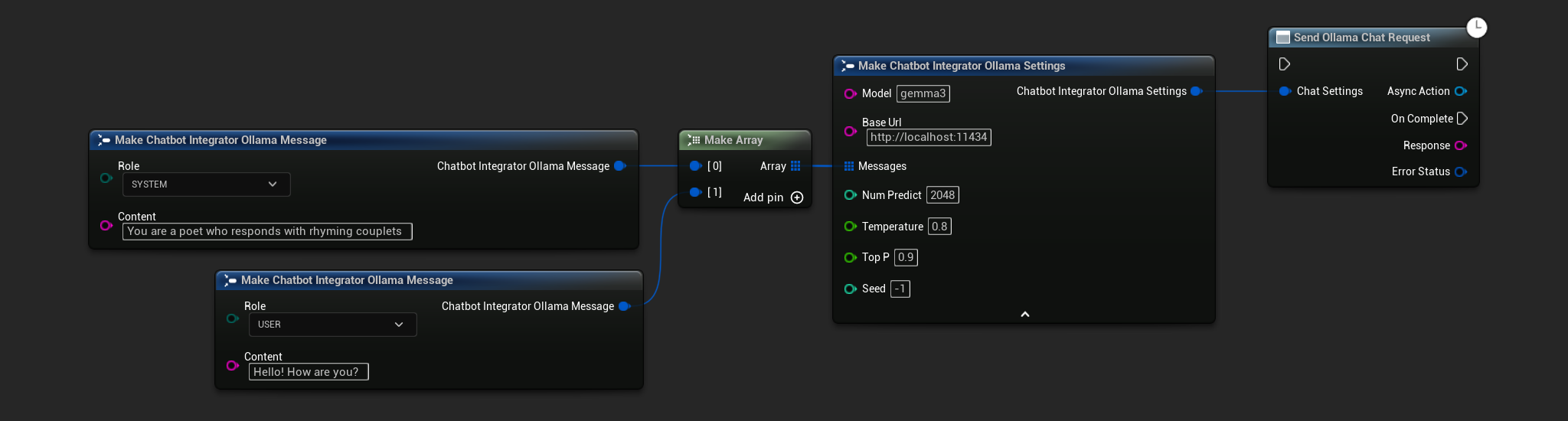
// Example of sending a non-streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllama::SendChatRequestNative(
Settings,
FOnOllamaChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
स्ट्रीमिंग चैट अनुरोध
अधिक गतिशील इंटरैक्शन के लिए रीयल-टाइम में प्रतिक्रिया चंक प्राप्त करें।
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
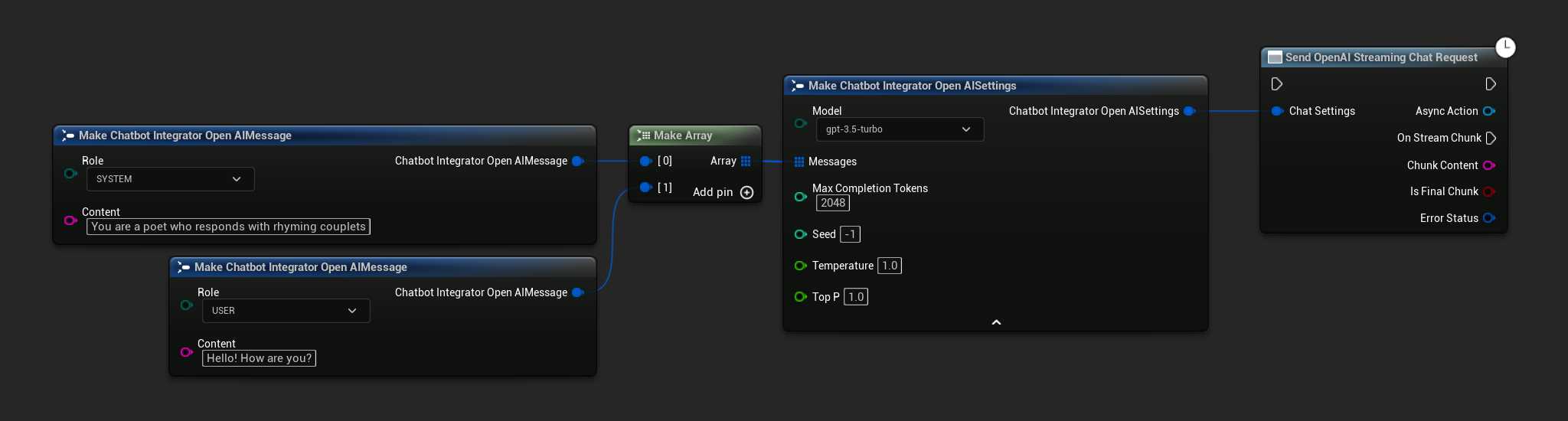
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAIStreamingSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
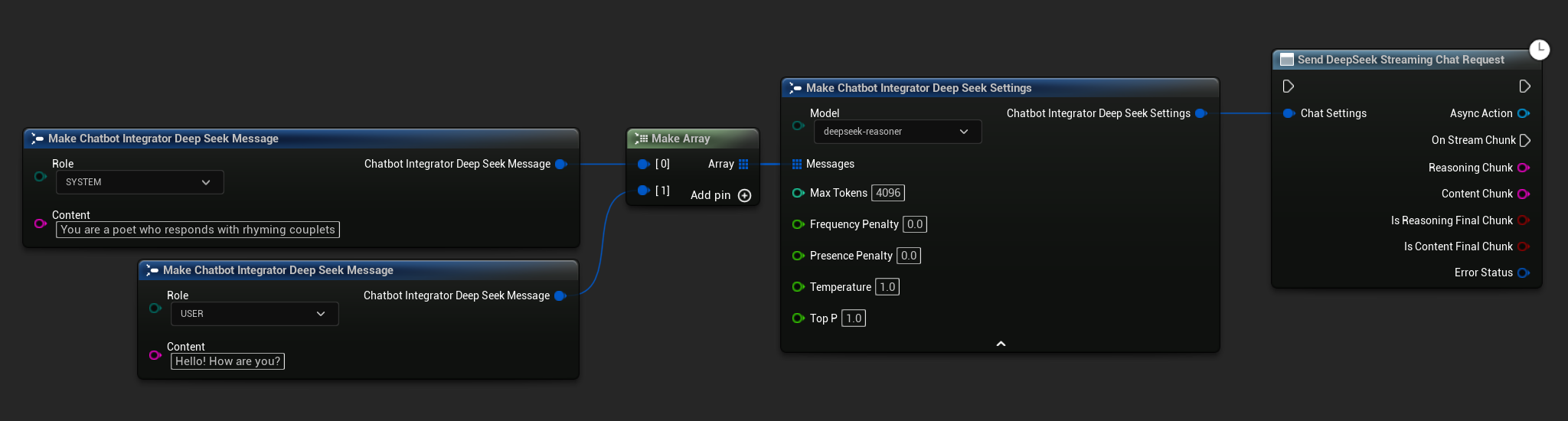
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
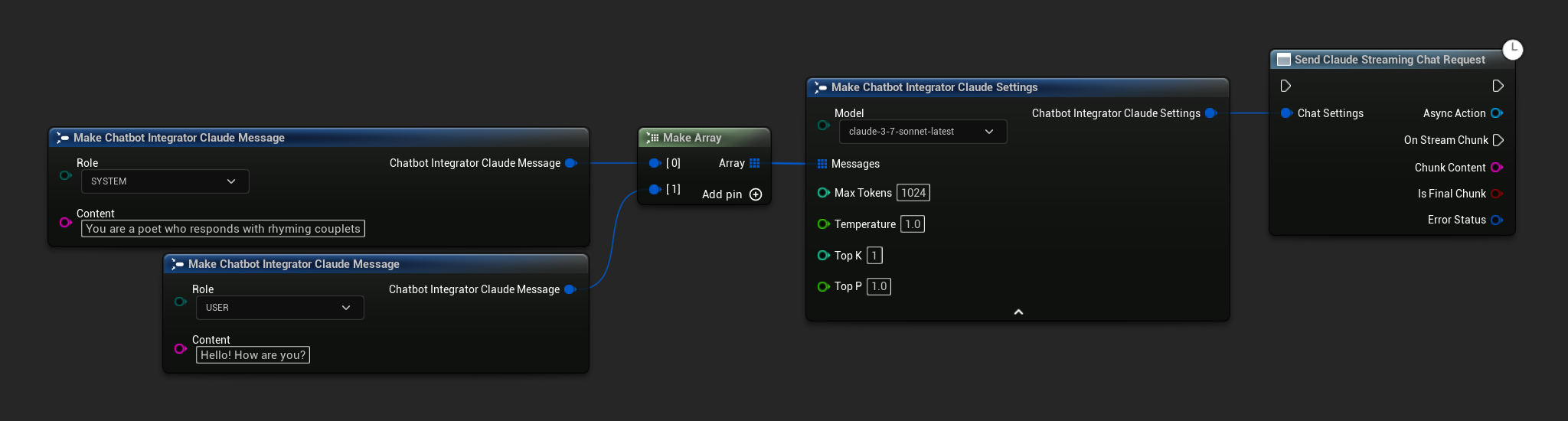
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
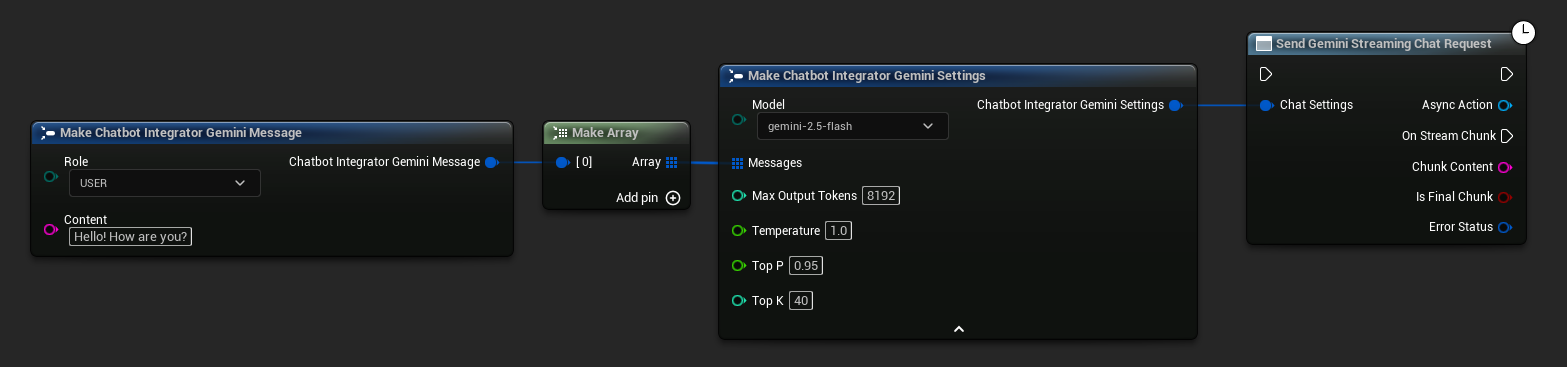
// Example of sending a streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGeminiStream::SendStreamingChatRequestNative(
Settings,
FOnGeminiChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
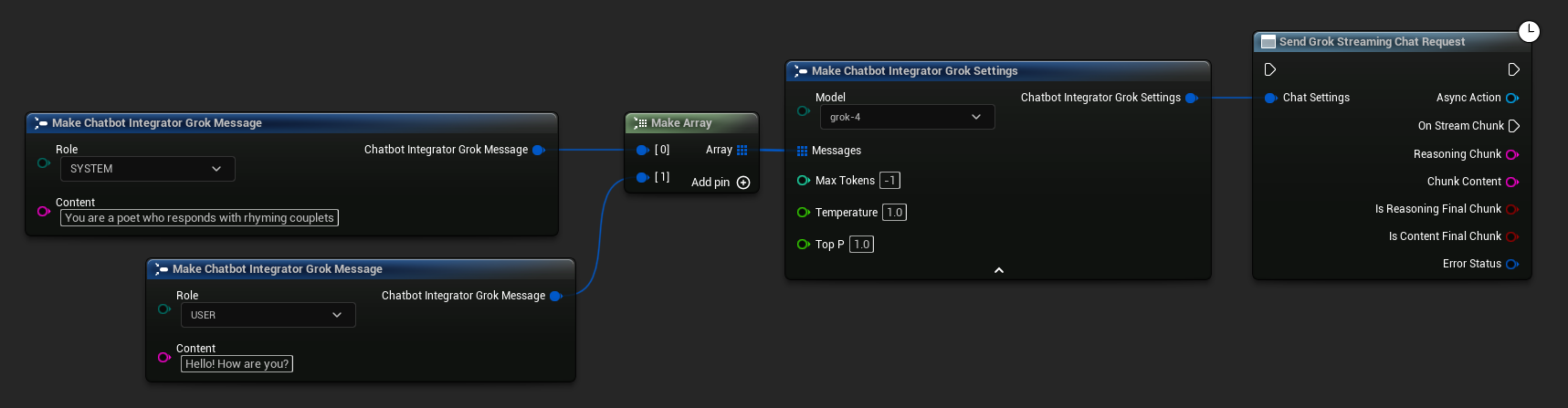
// Example of sending a streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrokStream::SendStreamingChatRequestNative(
Settings,
FOnGrokChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
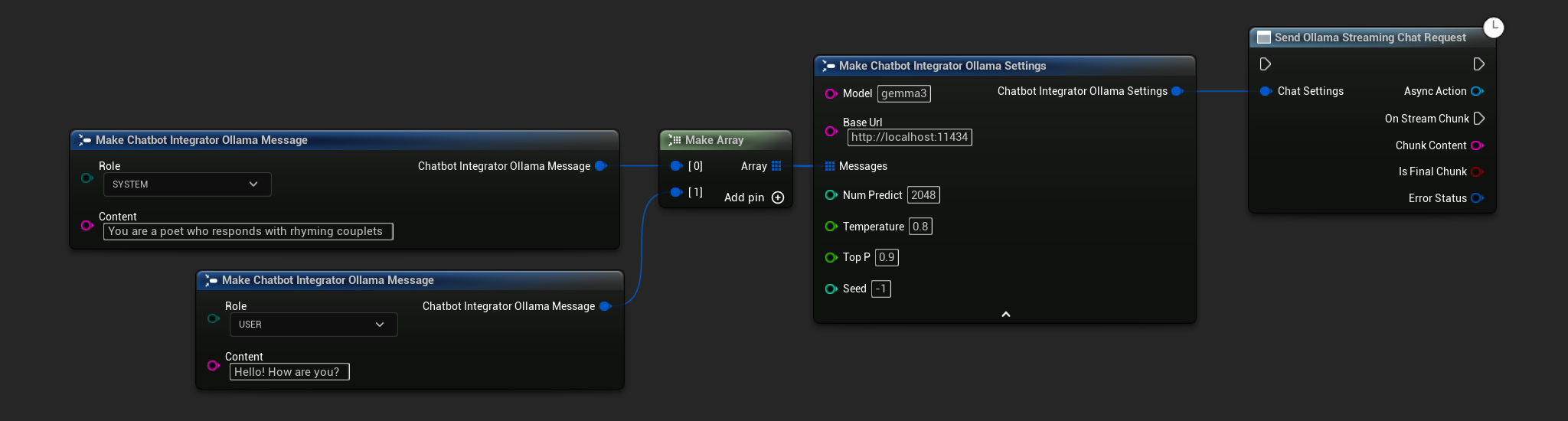
// Example of sending a streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllamaStream::SendStreamingChatRequestNative(
Settings,
FOnOllamaChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
टेक्स्ट-टू-स्पीच (TTS) कार्यक्षमता
अग्रणी TTS प्रदाताओं का उपयोग करके टेक्स्ट को उच्च-गुणवत्ता वाले स्पीच ऑडियो में बदलें। प्लगइन कच्चे ऑडियो डेटा (TArray<uint8>) लौटाता है जिसे आप अपनी परियोजना की आवश्यकताओं के अनुसार प्रोसेस कर सकते हैं।
जबकि नीचे दिए गए उदाहरण Runtime Audio Importer प्लगइन (देखें ऑडियो इम्पोर्टिंग दस्तावेज़ीकरण) का उपयोग करके प्लेबैक के लिए ऑडियो प्रोसेसिंग प्रदर्शित करते हैं, Runtime AI Chatbot Integrator लचीला होने के लिए डिज़ाइन किया गया है। प्लगइन केवल कच्चा ऑडियो डेटा लौटाता है, जो आपको अपने विशिष्ट उपयोग के मामले के लिए इसे कैसे प्रोसेस करें, इस पर पूर्ण स्वतंत्रता देता है, जिसमें ऑडियो प्लेबैक, फ़ाइल में सहेजना, आगे की ऑडियो प्रोसेसिंग, अन्य सिस्टम को ट्रांसमिट करना, कस्टम विज़ुअलाइज़ेशन, और बहुत कुछ शामिल हो सकता है।
नॉन-स्ट्रीमिंग TTS अनुरोध
नॉन-स्ट्रीमिंग TTS अनुरोध पूरे टेक्स्ट के प्रोसेस हो जाने के बाद एक ही प्रतिक्रिया में संपूर्ण ऑडियो डेटा लौटाते हैं। यह दृष्टिकोण छोटे टेक्स्ट के लिए उपयुक्त है जहां संपूर्ण ऑडियो के लिए प्रतीक्षा करना समस्याग्रस्त नहीं है।
- OpenAI TTS
- ElevenLabs TTS
- Google Cloud TTS
- Azure TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnOpenAITTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
}
)
);
- Blueprint
- C++
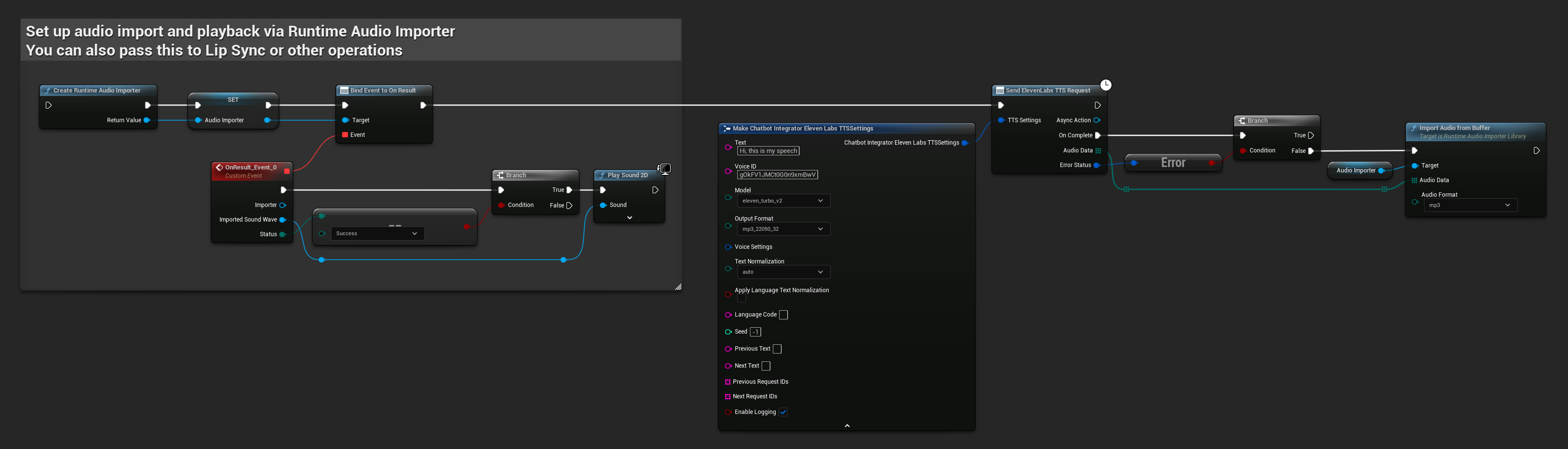
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process audio data as needed
}
}
)
);
- Blueprint
- C++
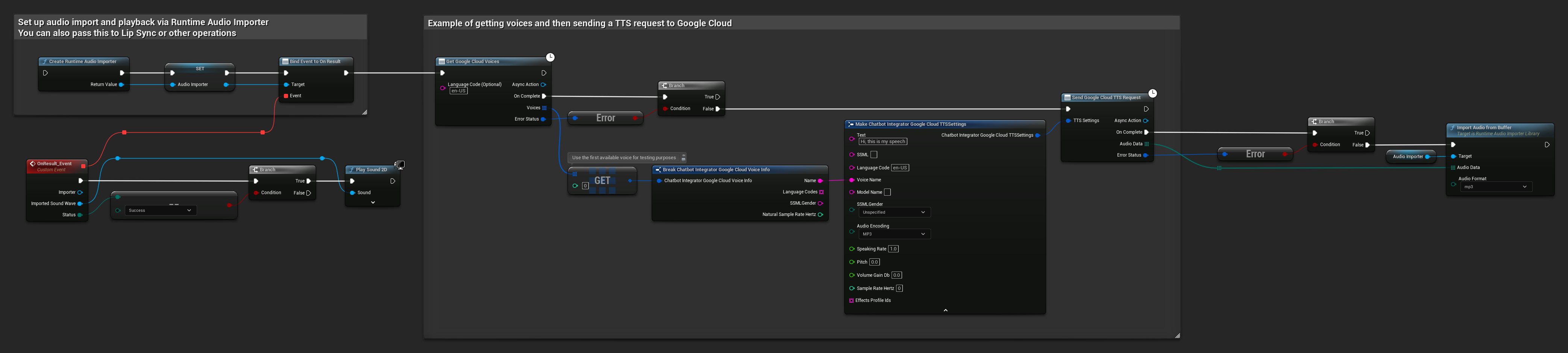
// Example of getting voices and then sending a TTS request to Google Cloud
// First, get available voices
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_GoogleCloudVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s"), *FirstVoice.Name);
// Now send TTS request with the selected voice
FChatbotIntegrator_GoogleCloudTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.LanguageCode = FirstVoice.LanguageCodes.Num() > 0 ? FirstVoice.LanguageCodes[0] : TEXT("en-US");
TTSSettings.VoiceName = FirstVoice.Name;
TTSSettings.AudioEncoding = EChatbotIntegrator_GoogleCloudAudioEncoding::MP3;
UAIChatbotIntegratorGoogleCloudTTS::SendTTSRequestNative(
TTSSettings,
FOnGoogleCloudTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
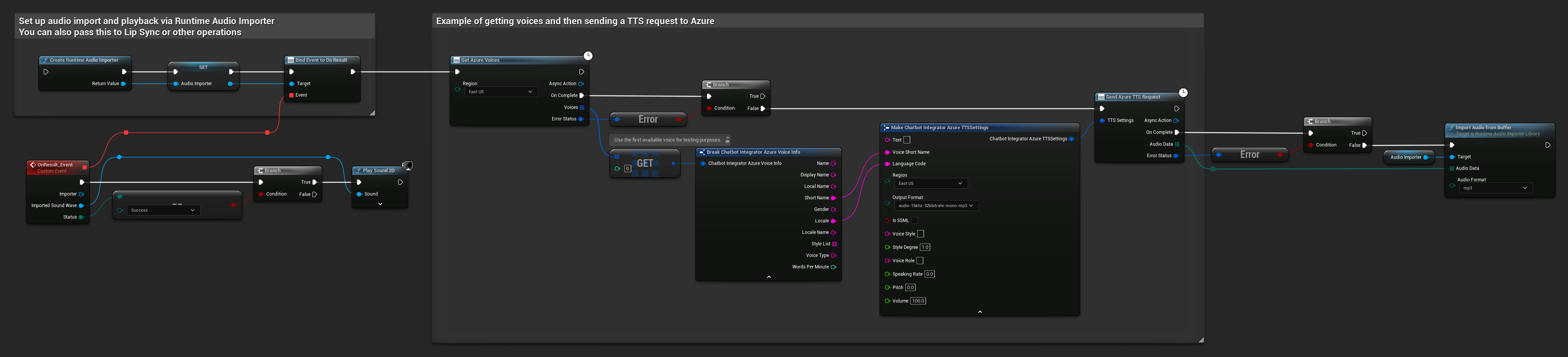
// Example of getting voices and then sending a TTS request to Azure
// First, get available voices
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_AzureVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s (%s)"), *FirstVoice.DisplayName, *FirstVoice.ShortName);
// Now send TTS request with the selected voice
FChatbotIntegrator_AzureTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceShortName = FirstVoice.ShortName;
TTSSettings.LanguageCode = FirstVoice.Locale;
TTSSettings.Region = EChatbotIntegrator_AzureRegion::EAST_US;
TTSSettings.OutputFormat = EChatbotIntegrator_AzureTTSFormat::AUDIO_16KHZ_32KBITRATE_MONO_MP3;
UAIChatbotIntegratorAzureTTS::SendTTSRequestNative(
TTSSettings,
FOnAzureTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
Streaming TTS Requests
Streaming TTS वास्तविक समय में ऑडियो चंक्स डिलीवर करता है जैसे वे जनरेट होते हैं, जिससे आप पूरे ऑडियो के सिंथेसाइज़ होने का इंतज़ार करने के बजाय डेटा को इंक्रीमेंटली प्रोसेस कर सकते हैं। यह लंबे टेक्स्ट के लिए महसूस की जाने वाली लेटेंसी को काफी कम कर देता है और रियल-टाइम एप्लिकेशन्स को सक्षम बनाता है। ElevenLabs Streaming TTS डायनामिक टेक्स्ट जनरेशन सिनेरियोस के लिए एडवांस्ड चंक्ड स्ट्रीमिंग फंक्शन्स का भी समर्थन करता है।
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
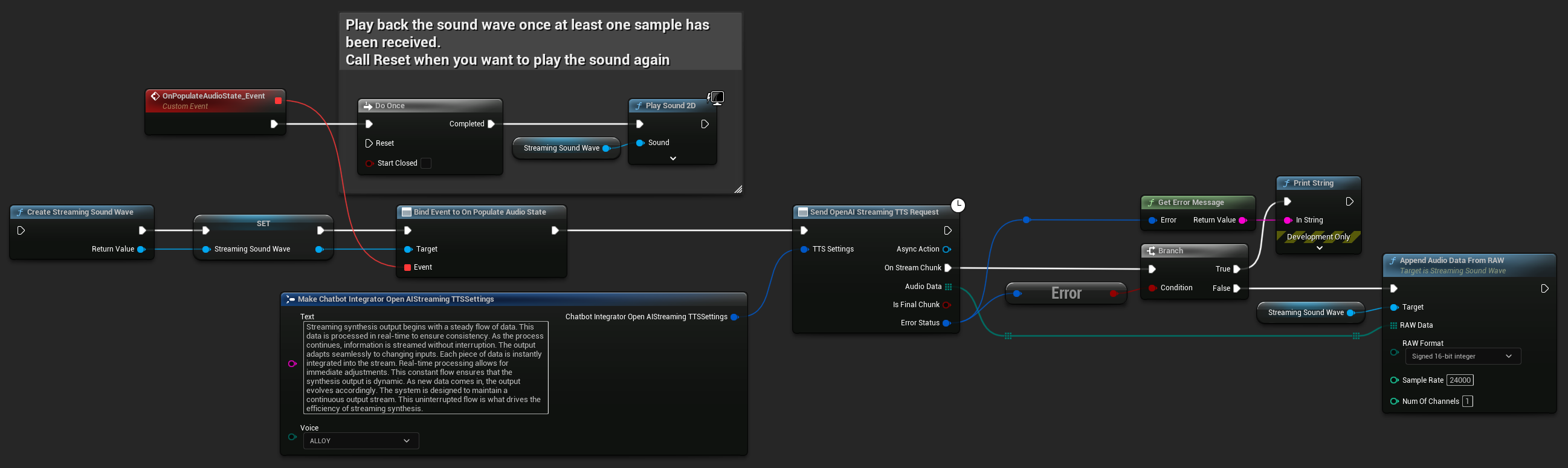
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
}));
}
ElevenLabs Streaming TTS स्टैंडर्ड स्ट्रीमिंग और एडवांस्ड चंक्ड स्ट्रीमिंग दोनों मोड्स को सपोर्ट करता है, जो विभिन्न उपयोग के मामलों के लिए लचीलापन प्रदान करता है।
स्टैंडर्ड स्ट्रीमिंग मोड
स्टैंडर्ड स्ट्रीमिंग मोड पूर्वनिर्धारित टेक्स्ट को प्रोसेस करता है और ऑडियो चंक्स को उत्पन्न होते ही डिलीवर करता है।
- Blueprint
- C++
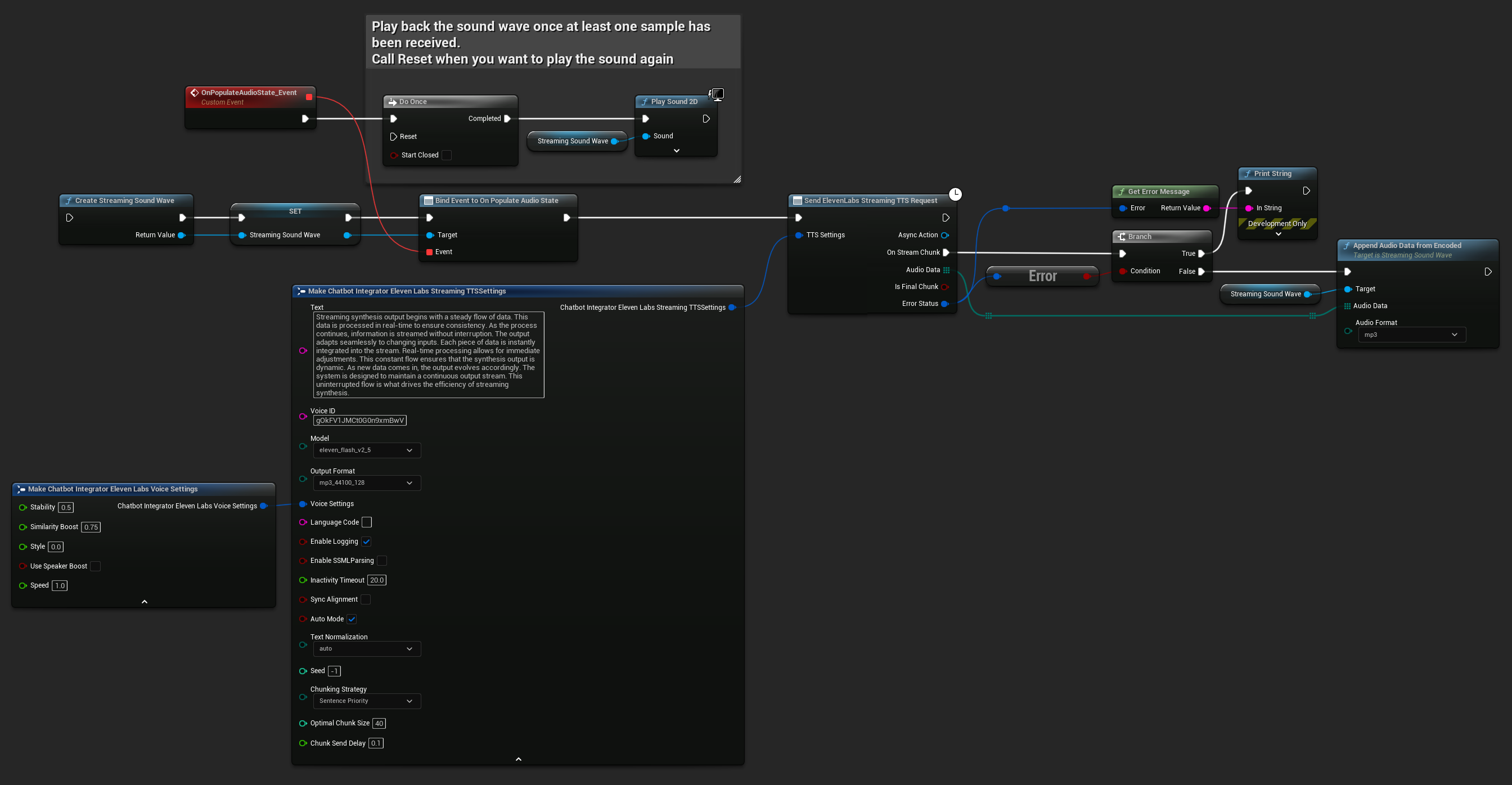
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = false; // Standard streaming mode
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
}));
}
चंक्ड स्ट्रीमिंग मोड
चंक्ड स्ट्रीमिंग मोड आपको संश्लेषण के दौरान टेक्स्ट को गतिशील रूप से जोड़ने की अनुमति देता है, यह रीयल-टाइम अनुप्रयोगों के लिए आदर्श है जहां टेक्स्ट वृद्धिशील रूप से उत्पन्न होता है (उदाहरण के लिए, एआई चैट प्रतिक्रियाएं जैसे-जैसे उत्पन्न होती हैं, उनका संश्लेषण किया जाता है)। इस मोड को सक्षम करने के लिए, अपनी TTS सेटिंग्स में bEnableChunkedStreaming को true पर सेट करें।
- Blueprint
- C++
प्रारंभिक सेटअप: अपनी TTS सेटिंग्स में चंक्ड स्ट्रीमिंग मोड को सक्षम करके और प्रारंभिक अनुरोध बनाकर चंक्ड स्ट्रीमिंग सेट करें। अनुरोध फ़ंक्शन एक एसिंक एक्शन ऑब्जेक्ट लौटाता है जो चंक्ड स्ट्रीमिंग सत्र का प्रबंधन करने के लिए विधियाँ प्रदान करता है:
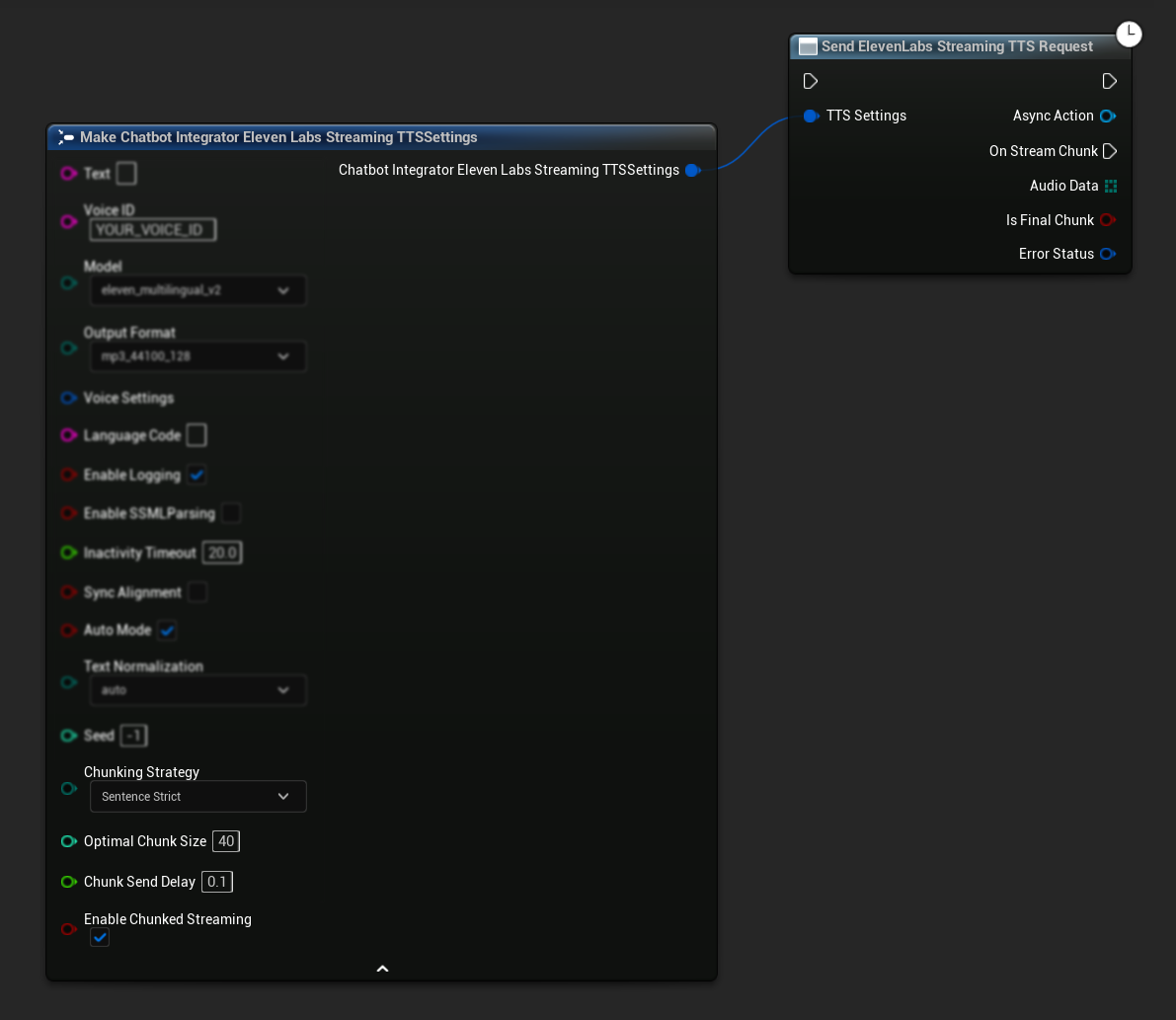
संश्लेषण के लिए टेक्स्ट जोड़ें:
सक्रिय चंक्ड स्ट्रीमिंग सत्र के दौरान गतिशील रूप से टेक्स्ट जोड़ने के लिए लौटाए गए एसिंक एक्शन ऑब्जेक्ट पर इस फ़ंक्शन का उपयोग करें। bContinuousMode पैरामीटर नियंत्रित करता है कि टेक्स्ट को कैसे संसाधित किया जाता है:

- जब
bContinuousModetrueहो: टेक्स्ट को आंतरिक रूप से तब तक बफ़र किया जाता है जब तक पूर्ण वाक्य सीमाएँ (पूर्ण विराम, विस्मयादिबोधक चिह्न, प्रश्न चिह्न) का पता नहीं चल जाता। सिस्टम स्वचालित रूप से संश्लेषण के लिए पूर्ण वाक्य निकालता है जबकि अधूरे टेक्स्ट को बफ़र में रखता है। इसका उपयोग तब करें जब टेक्स्ट टुकड़ों या आंशिक शब्दों में आता है जहां वाक्य पूर्णता अनिश्चित हो। - जब
bContinuousModefalseहो: टेक्स्ट को बफ़रिंग या वाक्य सीमा विश्लेषण के बिना तुरंत संसाधित किया जाता है। प्रत्येक कॉल के परिणामस्वरूप तत्काल चंक प्रोसेसिंग और संश्लेषण होता है। इसका उपयोग तब करें जब आपके पास पूर्व-निर्मित पूर्ण वाक्य या वाक्यांश हों जिन्हें सीमा पहचान की आवश्यकता नहीं होती।
निरंतर बफ़र फ्लश करें: एसिंक एक्शन ऑब्जेक्ट पर किसी भी बफ़र किए गए निरंतर टेक्स्ट के प्रसंस्करण को बाध्य करता है, भले ही कोई वाक्य सीमा का पता नहीं चला हो। उपयोगी जब आप जानते हैं कि कुछ समय के लिए और कोई टेक्स्ट नहीं आ रहा है:
निरंतर फ्लश टाइमआउट सेट करें: निर्दिष्ट टाइमआउट के भीतर कोई नया टेक्स्ट न आने पर एसिंक एक्शन ऑब्जेक्ट पर निरंतर बफ़र के स्वचालित फ्लशिंग को कॉन्फ़िगर करता है:
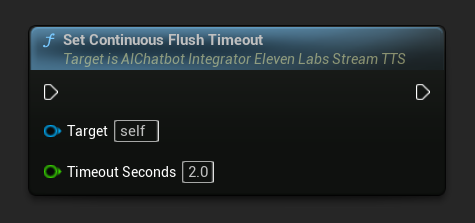
स्वचालित फ्लशिंग को अक्षम करने के लिए 0 पर सेट करें। रीयल-टाइम अनुप्रयोगों के लिए अनुशंसित मान 1-3 सेकंड हैं।
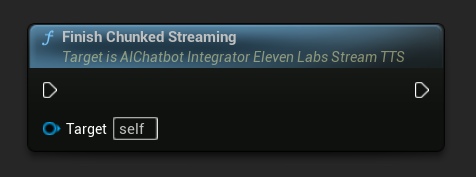
चंक्ड स्ट्रीमिंग समाप्त करें: एसिंक एक्शन ऑब्जेक्ट पर चंक्ड स्ट्रीमिंग सत्र को बंद करता है और वर्तमान संश्लेषण को अंतिम के रूप में चिह्नित करता है। जब आप टेक्स्ट जोड़ना समाप्त कर लें तो हमेशा इसे कॉल करें:
UPROPERTY()
UAIChatbotIntegratorElevenLabsStreamTTS* ChunkedTTSRequest;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartChunkedStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT(""); // Start with empty text in chunked mode
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = true; // Enable chunked streaming mode
// Store the returned async action object to call chunked streaming functions on it
ChunkedTTSRequest = UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(
GetWorld(),
TTSSettings,
FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && AudioData.Num() > 0)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
if (IsFinalChunk)
{
UE_LOG(LogTemp, Log, TEXT("Chunked streaming session completed"));
ChunkedTTSRequest = nullptr;
}
})
);
// Now you can append text dynamically as it becomes available
// For example, from an AI chat response stream:
AppendTextToTTS(TEXT("Hello, this is the first part of the message. "));
}
UFUNCTION(BlueprintCallable)
void AppendTextToTTS(const FString& AdditionalText)
{
// Call AppendTextForSynthesis on the returned async action object
if (ChunkedTTSRequest)
{
// Use continuous mode (true) when text is being generated word-by-word
// and you want to wait for complete sentences before processing
bool bContinuousMode = true;
bool bSuccess = ChunkedTTSRequest->AppendTextForSynthesis(AdditionalText, bContinuousMode);
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Successfully appended text: %s"), *AdditionalText);
}
}
}
// Configure continuous text buffering with custom timeout
UFUNCTION(BlueprintCallable)
void SetupAdvancedChunkedStreaming()
{
// Call SetContinuousFlushTimeout on the async action object
if (ChunkedTTSRequest)
{
// Set automatic flush timeout to 1.5 seconds
// Text will be automatically processed if no new text arrives within this timeframe
ChunkedTTSRequest->SetContinuousFlushTimeout(1.5f);
}
}
// Example of handling real-time AI chat response synthesis
UFUNCTION(BlueprintCallable)
void HandleAIChatResponseForTTS(const FString& ChatChunk, bool IsStreamFinalChunk)
{
if (ChunkedTTSRequest)
{
if (!IsStreamFinalChunk)
{
// Append each chat chunk in continuous mode
// The system will automatically extract complete sentences for synthesis
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
}
else
{
// Add the final chunk
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
// Flush any remaining buffered text and finish the session
ChunkedTTSRequest->FlushContinuousBuffer();
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
}
// Example of immediate chunk processing (bypassing sentence boundary detection)
UFUNCTION(BlueprintCallable)
void AppendImmediateText(const FString& Text)
{
// Call AppendTextForSynthesis with continuous mode = false on the async action object
if (ChunkedTTSRequest)
{
// Use continuous mode = false for immediate processing
// Useful when you have complete sentences or phrases ready
ChunkedTTSRequest->AppendTextForSynthesis(Text, false);
}
}
UFUNCTION(BlueprintCallable)
void FinishChunkedTTS()
{
// Call FlushContinuousBuffer and FinishChunkedStreaming on the async action object
if (ChunkedTTSRequest)
{
// Flush any remaining buffered text
ChunkedTTSRequest->FlushContinuousBuffer();
// Mark the session as finished
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
ElevenLabs Chunked Streaming की प्रमुख विशेषताएं:
- निरंतर मोड: जब
bContinuousModetrueहोता है, तो पाठ को पूर्ण वाक्य सीमाओं का पता लगने तक बफर किया जाता है, फिर संश्लेषण के लिए संसाधित किया जाता है - तत्काल मोड: जब
bContinuousModefalseहोता है, तो पाठ को बिना बफरिंग के अलग-अलग चंक्स के रूप में तुरंत संसाधित किया जाता है - स्वचालित फ्लश: कॉन्फ़िगर करने योग्य टाइमआउट निर्दिष्ट समय सीमा के भीतर कोई नया इनपुट न आने पर बफर किए गए पाठ को संसाधित करता है
- वाक्य सीमा पहचान: वाक्य समाप्ति (., !, ?) का पता लगाता है और बफर किए गए पाठ से पूर्ण वाक्य निकालता है
- रियल-टाइम एकीकरण: वृद्धिशील पाठ इनपुट का समर्थन करता है जहां सामग्री समय के साथ टुकड़ों में आती है
- लचीला पाठ चंकिंग: संश्लेषण प्रसंस्करण को अनुकूलित करने के लिए कई रणनीतियाँ उपलब्ध (वाक्य प्राथमिकता, वाक्य सख्त, आकार आधारित)
उपलब्ध आवाजें प्राप्त करना
कुछ TTS प्रदाता उपलब्ध आवाजों को प्रोग्रामेटिक रूप से खोजने के लिए आवाज सूची API प्रदान करते हैं।
- Google Cloud Voices
- Azure Voices
- Blueprint
- C++
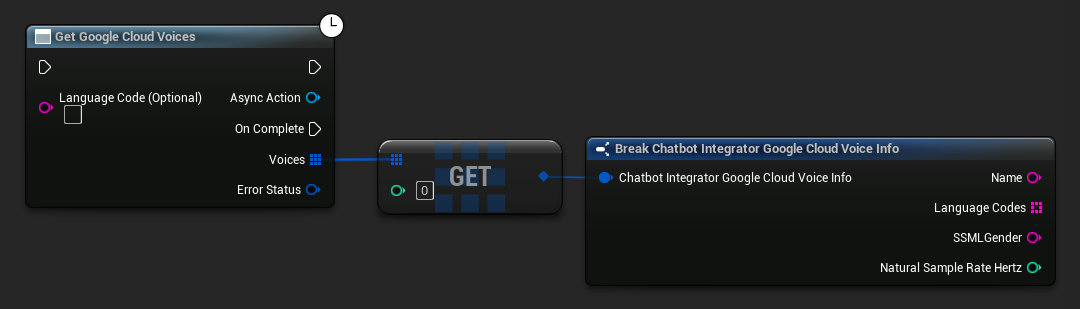
// Example of getting available voices from Google Cloud
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.Name, *Voice.SSMLGender);
}
}
}
)
);
- Blueprint
- C++
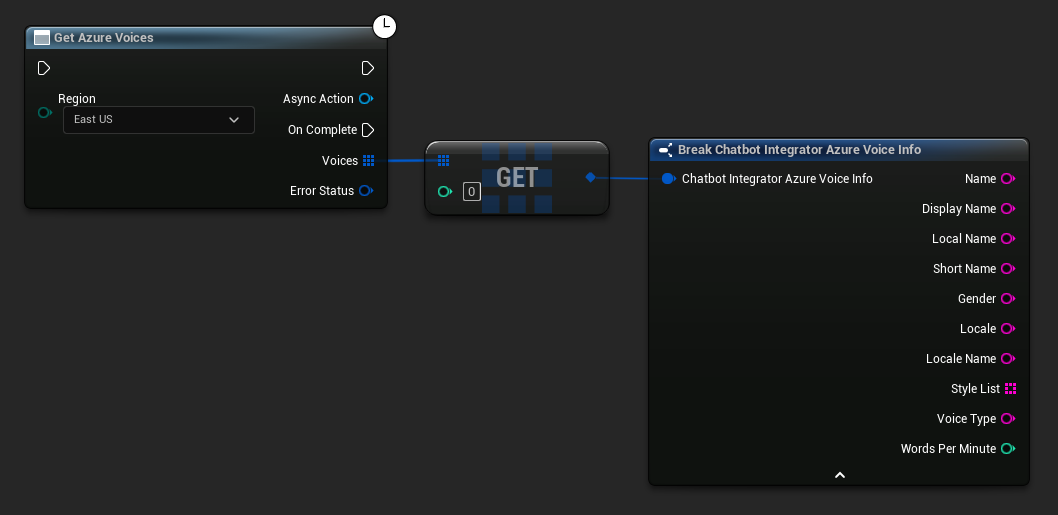
// Example of getting available voices from Azure
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.DisplayName, *Voice.Gender);
}
}
}
)
);
Ollama मॉडलों की सूची बनाना
आप ListOllamaModels फ़ंक्शन का उपयोग करके अपने स्थानीय Ollama इंस्टेंस से सभी उपलब्ध मॉडलों को क्वेरी कर सकते हैं। यह आपके UI में एक मॉडल पिकर को गतिशील रूप से भरने जैसे उपयोगी हो सकता है। GetModelNames हेल्पर सुविधा के लिए परिणाम से केवल नाम स्ट्रिंग्स निकालता है।
- Blueprint
- C++
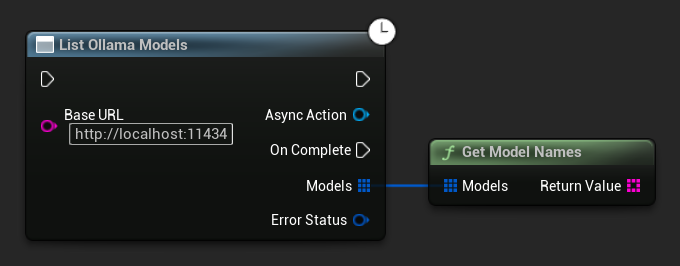
// Example of listing locally available Ollama models
UAIChatbotIntegratorOllamaModelList::ListModelsNative(
TEXT("http://localhost:11434"),
FOnOllamaListModelsResponseNative::CreateWeakLambda(
this,
[this](const TArray<FOllamaModelInfo>& Models, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const FOllamaModelInfo& Model : Models)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s | Family: %s | Parameters: %s | Quantization: %s | Size: %lld bytes"),
*Model.Name, *Model.Family, *Model.ParameterSize, *Model.QuantizationLevel, Model.Size);
}
// Convenience helper to get just the name strings, e.g. for a UI dropdown
TArray<FString> ModelNames = UAIChatbotIntegratorOllamaModelList::GetModelNames(Models);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to list Ollama models: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
त्रुटि प्रबंधन
किसी भी अनुरोध को भेजते समय, अपने कॉलबैक में ErrorStatus की जाँच करके संभावित त्रुटियों को संभालना महत्वपूर्ण है। ErrorStatus अनुरोध के दौरान होने वाली किसी भी समस्या के बारे में जानकारी प्रदान करता है।
- Blueprint
- C++
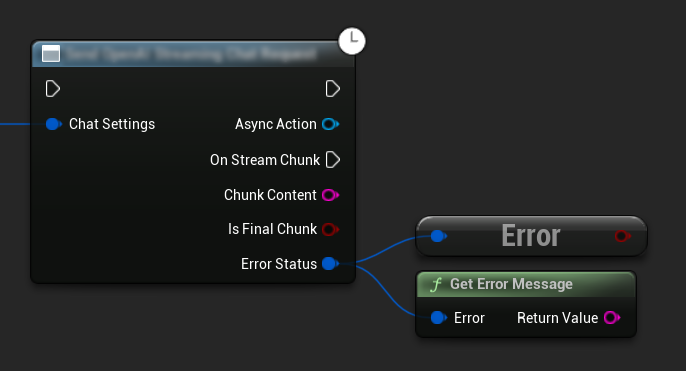
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
अनुरोध रद्द करना
यह प्लगइन आपको प्रगति में होने वाले टेक्स्ट-टू-टेक्स्ट और TTS अनुरोधों दोनों को रद्द करने की अनुमति देता है। यह तब उपयोगी हो सकता है जब आप एक लंबे समय तक चलने वाले अनुरोध को बाधित करना चाहते हैं या वार्तालाप प्रवाह को गतिशील रूप से बदलना चाहते हैं।
- Blueprint
- C++
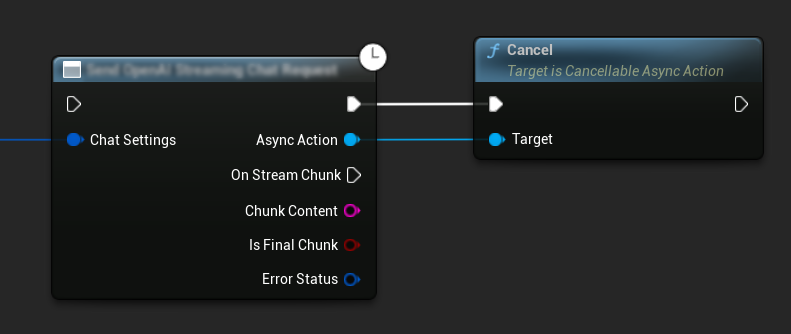
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
सर्वोत्तम अभ्यास
- हमेशा अपने कॉलबैक में
ErrorStatusकी जाँच करके संभावित त्रुटियों को संभालें - प्रत्येक प्रदाता के लिए API दर सीमाओं और लागतों का ध्यान रखें
- लंबे रूप या इंटरैक्टिव वार्तालापों के लिए स्ट्रीमिंग मोड का उपयोग करें
- संसाधनों का कुशलतापूर्वक प्रबंधन करने के लिए अब आवश्यक नहीं रहे अनुरोधों को रद्द करने पर विचार करें
- कथित विलंबता को कम करने के लिए लंबे पाठों के लिए स्ट्रीमिंग TTS का उपयोग करें
- ऑडियो प्रसंस्करण के लिए, Runtime Audio Importer प्लगइन एक सुविधाजनक समाधान प्रदान करता है, लेकिन आप अपनी परियोजना की आवश्यकताओं के आधार पर कस्टम प्रसंस्करण लागू कर सकते हैं
- तर्क मॉडल (DeepSeek Reasoner, Grok) का उपयोग करते समय, तर्क और सामग्री दोनों आउटपुट को उचित रूप से संभालें
- TTS सुविधाओं को लागू करने से पहले वॉइस लिस्टिंग API का उपयोग करके उपलब्ध आवाजों की खोज करें
- ElevenLabs चंक्ड स्ट्रीमिंग के लिए: जब पाठ वृद्धिशील रूप से उत्पन्न होता है (जैसे AI प्रतिक्रियाएं) तो निरंतर मोड का उपयोग करें और पूर्व-निर्मित पाठ चंक्स के लिए तत्काल मोड का उपयोग करें
- प्रतिक्रियाशीलता और प्राकृतिक भाषण प्रवाह के बीच संतुलन बनाने के लिए निरंतर मोड के लिए उपयुक्त फ्लश टाइमआउट कॉन्फ़िगर करें
- अपनी एप्लिकेशन की रीयल-टाइम आवश्यकताओं के आधार पर इष्टतम चंक आकार और भेजने में देरी चुनें
- Ollama के लिए: मॉडल नामों को हार्डकोड करने के बजाय उपलब्ध मॉडलों की गतिशील रूप से खोज करने के लिए
ListOllamaModelsका उपयोग करें
समस्या निवारण
- सत्यापित करें कि प्रत्येक प्रदाता के लिए आपकी API क्रेडेंशियल्स सही हैं
- अपने इंटरनेट कनेक्शन की जाँच करें
- सुनिश्चित करें कि TTS सुविधाओं के साथ काम करते समय आपके द्वारा उपयोग की जाने वाली कोई भी ऑडियो प्रसंस्करण लाइब्रेरी (जैसे Runtime Audio Importer) ठीक से स्थापित है
- TTS प्रतिक्रिया डेटा को प्रसंस्कृत करते समय सत्यापित करें कि आप सही ऑडियो प्रारूप का उपयोग कर रहे हैं
- स्ट्रीमिंग TTS के लिए, सुनिश्चित करें कि आप ऑडियो चंक्स को सही ढंग से संभाल रहे हैं
- तर्क मॉडल के लिए, सुनिश्चित करें कि आप तर्क और सामग्री दोनों आउटपुट को प्रसंस्कृत कर रहे हैं
- मॉडल उपलब्धता और क्षमताओं के लिए प्रदाता-विशिष्ट प्रलेखन की जाँच करें
- ElevenLabs चंक्ड स्ट्रीमिंग के लिए: सत्र को ठीक से बंद करने के लिए सुनिश्चित करें कि जब काम पूरा हो जाए तो
FinishChunkedStreamingको कॉल करें - निरंतर मोड समस्याओं के लिए: जाँच करें कि आपके पाठ में वाक्य सीमाएं ठीक से पहचानी गई हैं
- रीयल-टाइम अनुप्रयोगों के लिए: अपनी विलंबता आवश्यकताओं के आधार पर चंक भेजने में देरी और फ्लश टाइमआउट समायोजित करें
- Ollama के लिए: अनुरोध भेजने से पहले सुनिश्चित करें कि Ollama सर्वर चल रहा है और कॉन्फ़िगर किए गए
BaseUrlपर पहुँच योग्य है