प्लगइन का उपयोग कैसे करें
यह गाइड संपूर्ण रनटाइम API को कवर करती है: एक LLM इंस्टेंस बनाना, मॉडल लोड करना, संदेश भेजना, रनटाइम पर मॉडल डाउनलोड करना, स्थिति प्रबंधित करना और उपयोगिता फ़ंक्शन।
एक LLM इंस्टेंस बनाएँ
सबसे पहले एक Runtime Local LLM ऑब्जेक्ट बनाएँ। इसका एक संदर्भ बनाए रखें (जैसे कि Blueprints में एक वेरिएबल के रूप में या C++ में एक UPROPERTY) ताकि समय से पहले गारबेज कलेक्शन को रोका जा सके।
- Blueprint
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
एक मॉडल लोड करें
संदेश भेजने से पहले आपको एक मॉडल लोड करना होगा। प्लगइन आपके वर्कफ़्लो के आधार पर कई लोडिंग विधियाँ प्रदान करता है।
नाम से लोड करें
यदि आप एडिटर सेटिंग्स पैनल के माध्यम से मॉडल प्रबंधित करते हैं, तो Load Model (By Name) का उपयोग करें।
- Blueprint
- C++
- UE 5.3 and earlier
- UE 5.4+
UE 5.3 और उससे पहले के संस्करणों में ड्रॉपडाउन दिखाई नहीं देता है, इसलिए आपको उपलब्ध मॉडलों को मैन्युअल रूप से प्राप्त करना होगा। Get All Downloaded Model Metadata का उपयोग करें, इंडेक्स 0 (या आपको जिस मॉडल की आवश्यकता हो) पर तत्व प्राप्त करें, इसे Get Model File Name में पास करें ताकि नाम स्ट्रिंग प्राप्त हो सके, फिर उसे Load Model (By Name) में पास करें।
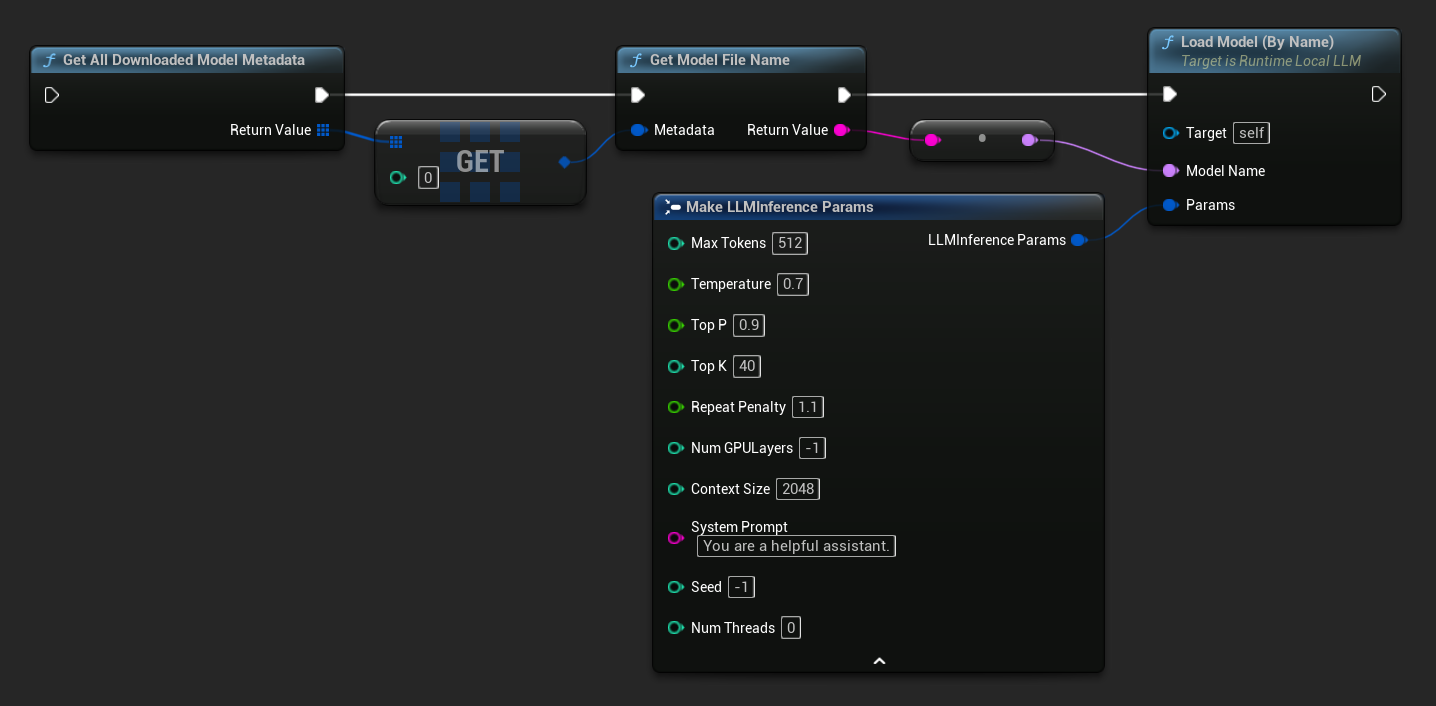
UE 5.4 और बाद के संस्करणों में, Load Model (By Name) डिस्क पर सभी मॉडलों का ड्रॉपडाउन प्रस्तुत करता है - बस उस मॉडल का चयन करें जिसे आप लोड करना चाहते हैं।
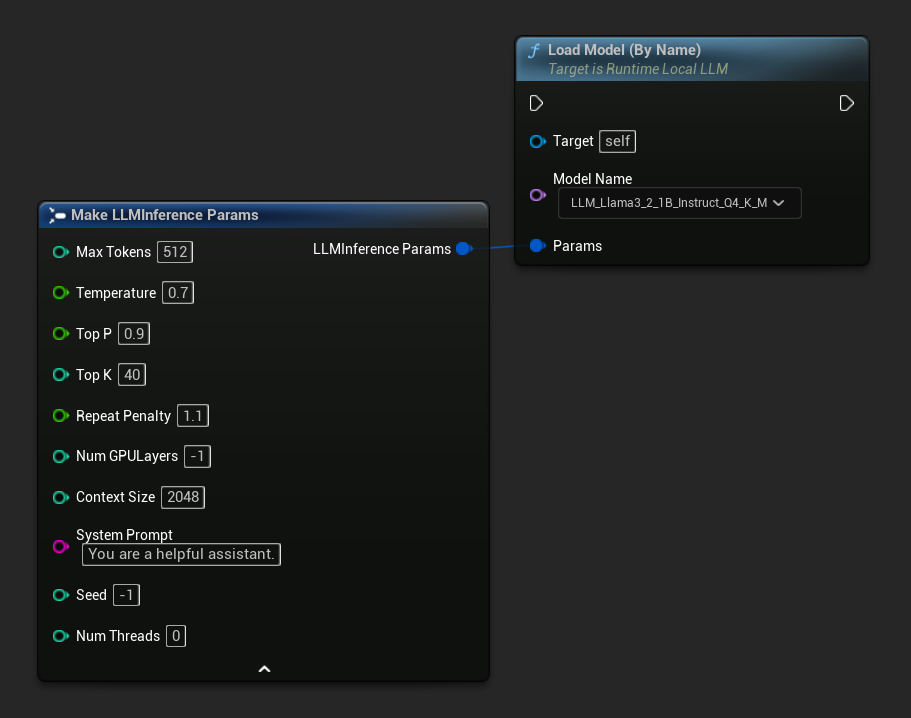
C++ में, उपलब्ध मॉडलों को प्राप्त करने के लिए GetAllDownloadedModelMetadata का उपयोग करें और GetModelFileName से नाम प्राप्त करें जिसे LoadModelByName को पास किया जा सके:
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
फ़ाइल पथ से लोड करें
किसी .gguf फ़ाइल के लिए एक निरपेक्ष फ़ाइल पथ से सीधे मॉडल लोड करें:
- Blueprint
- C++
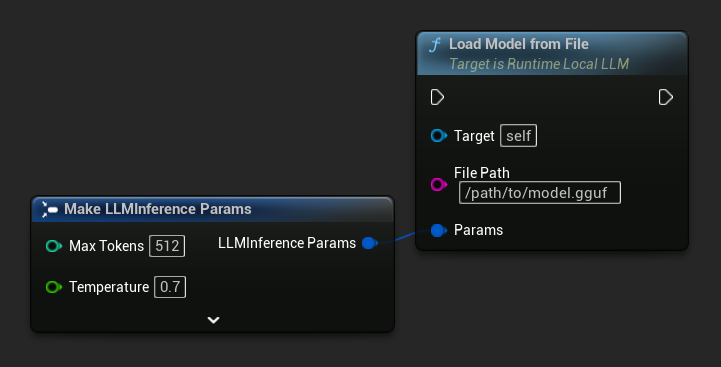
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
URL से लोड करें (डाउनलोड करें और लोड करें)
एक URL से मॉडल डाउनलोड करें (यदि डिस्क पर पहले से मौजूद नहीं है) और इसे स्वचालित रूप से लोड करें। यदि फ़ाइल स्थानीय रूप से पहले से मौजूद है, तो डाउनलोड छोड़ दिया जाता है।
- Blueprint
- C++
सबसे सरल प्रकार केवल एक URL लेता है - फ़ाइल नाम से मेटाडेटा प्राप्त किया जाता है:
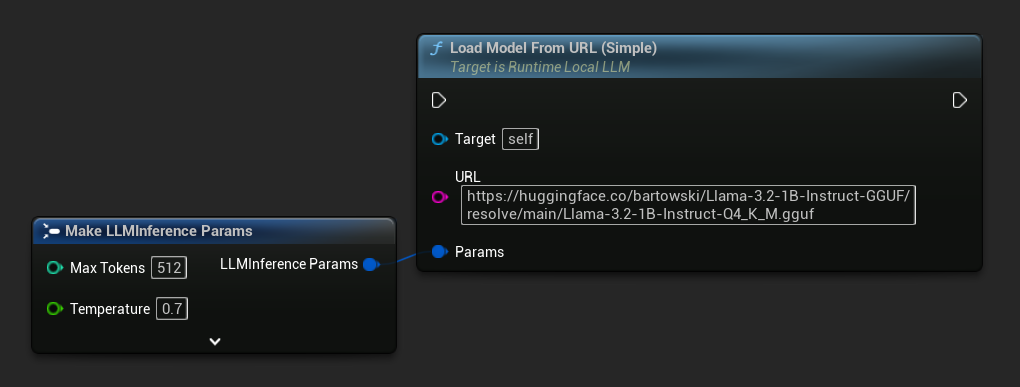
आप अधिक समृद्ध मॉडल जानकारी के लिए Load Model From URL का उपयोग पूर्ण मॉडल मेटाडेटा के साथ भी कर सकते हैं:
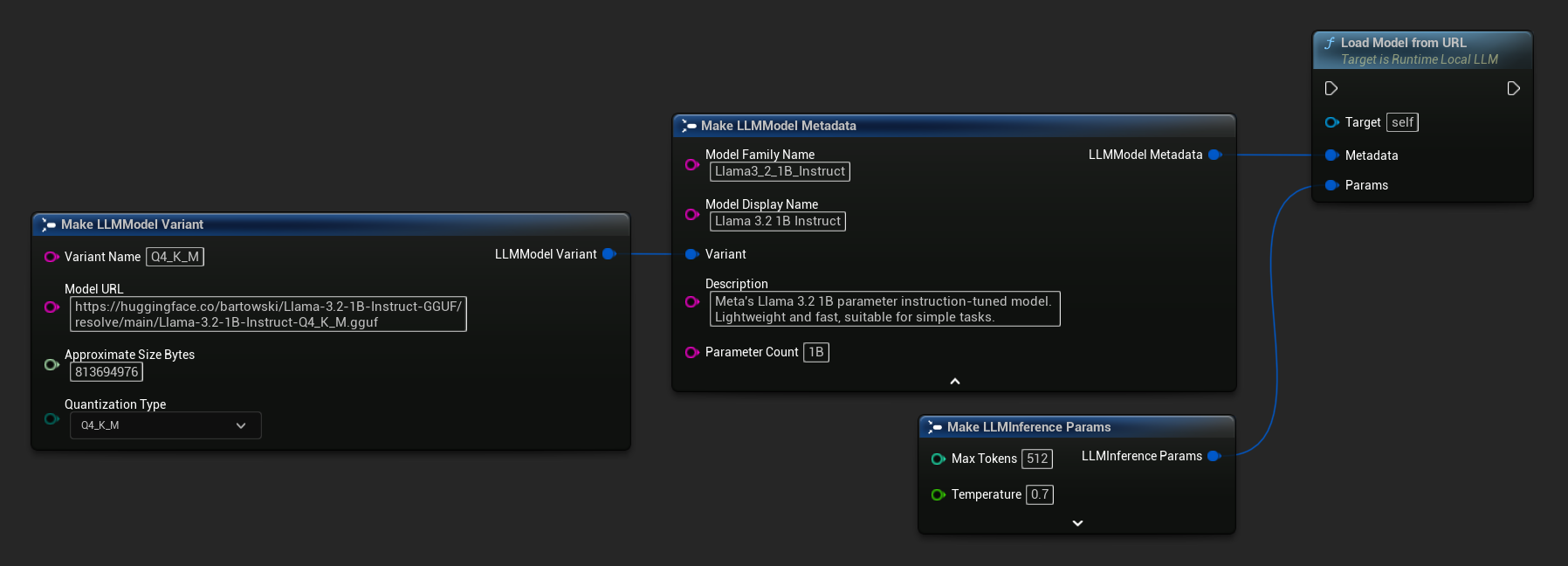
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
अतुल्यकालिक लोड (Blueprint)
लोड पूर्ण होने और त्रुटियों को डेलीगेट्स को मैन्युअली बाइंड करने के बजाय आउटपुट पिन्स के माध्यम से संभालने के लिए, दो अतुल्यकालिक नोड्स उपलब्ध हैं।
Load Model By Name (Async) Load Model (By Name) को दर्पित करता है - UE 5.4+ में यह डिस्क पर सभी मॉडलों की ड्रॉपडाउन प्रस्तुत करता है:
- UE 5.4+
- UE 5.3 और उससे पहले
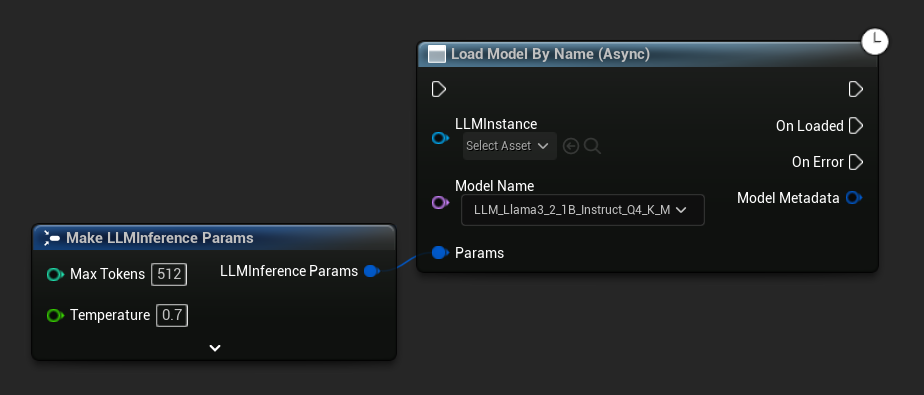
UE 5.3 और उससे पहले में ड्रॉपडाउन दिखाई नहीं देता। Get All Downloaded Model Metadata का उपयोग करें, इंडेक्स 0 पर मौजूद एलिमेंट प्राप्त करें (या जिस मॉडल की आपको आवश्यकता है), उसे Get Model File Name में पास करें, फिर उसे Load Model By Name (Async) में पास करें।
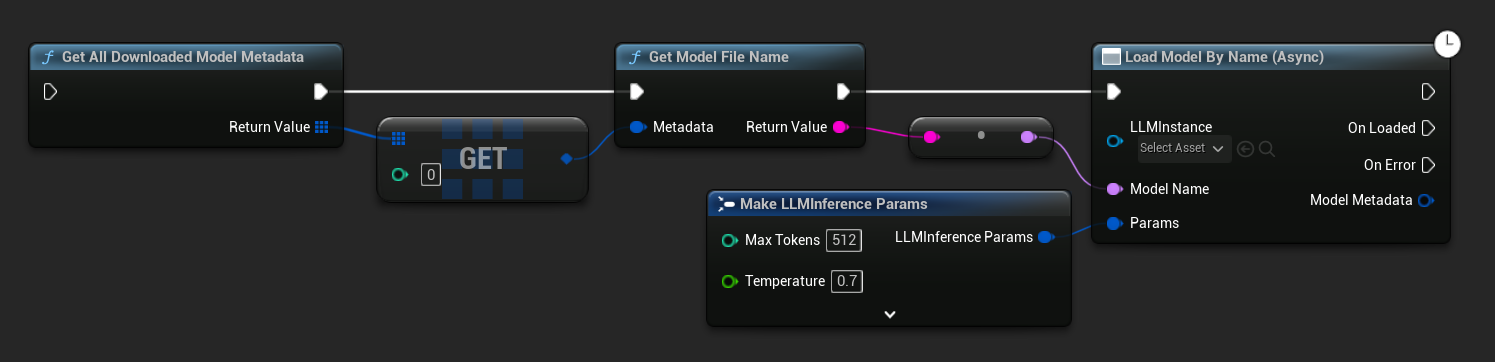
Load Model From File (Async) इसके बजाय एक पूर्ण फ़ाइल पथ लेता है:
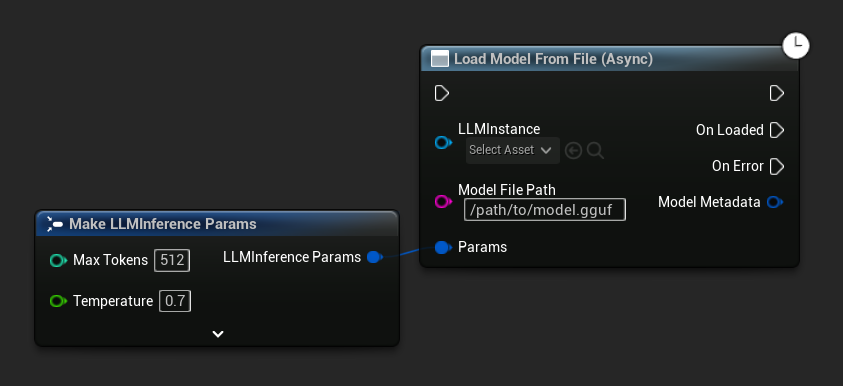
इवेंट बाइंड करें
LLM इंस्टेंस के डेलीगेट्स से कॉलबैक प्राप्त करने के लिए बाइंड करें। सभी कॉलबैक गेम थ्रेड पर सक्रिय होते हैं।
- Blueprint
- C++
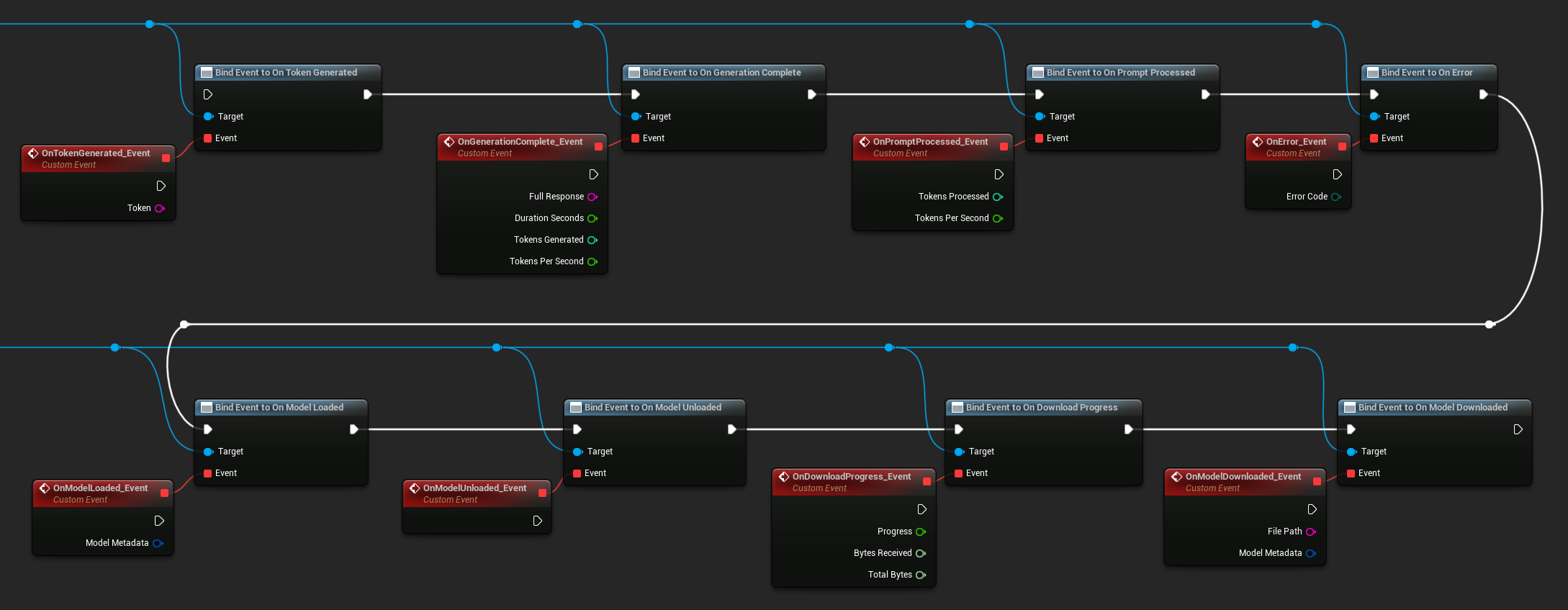
उपलब्ध डेलीगेट्स:
- On Token Generated: प्रत्येक आउटपुट टोकन पर सक्रिय होता है
- On Generation Complete: पूर्ण प्रतिक्रिया तैयार होने पर, अवधि, टोकन गणना और प्रति सेकंड टोकन के साथ सक्रिय होता है
- On Prompt Processed: प्रॉम्प्ट के प्रोसेस हो जाने के बाद, जनरेशन आरंभ होने से पहले सक्रिय होता है
- On Error: किसी भी ऑपरेशन के दौरान त्रुटि होने पर सक्रिय होता है
- On Model Loaded: मॉडल का लोड होना समाप्त होने पर सक्रिय होता है
- On Model Unloaded: मॉडल अनलोड होने पर सक्रिय होता है
- On Download Progress: मॉडल डाउनलोड के दौरान समय-समय पर सक्रिय होता है (प्रगति अंश, प्राप्त बाइट्स, कुल बाइट्स)
- On Model Downloaded: डाउनलोड-मात्र ऑपरेशन पूर्ण होने पर सक्रिय होता है
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda([](const FString& FullResponse)
{
});
LLM->OnPromptProcessedNative.AddLambda([]()
{
});
LLM->OnErrorNative.AddLambda([](const FString& ErrorMessage)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FString& ModelName)
{
});
LLM->OnModelUnloadedNative.AddLambda([](const FString& ModelName)
{
});
LLM->OnDownloadProgressNative.AddLambda([](const FString& ModelName, float Progress)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& ModelName)
{
});
संदेश भेजें
एक बार मॉडल लोड हो जाने के बाद, प्रतिक्रिया उत्पन्न करने के लिए एक उपयोगकर्ता संदेश भेजें:
- Blueprint
- C++
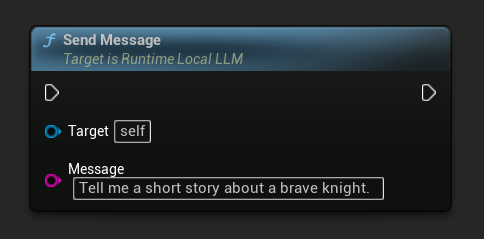
एक विशिष्ट संदेश के लिए सिस्टम प्रॉम्प्ट को ओवरराइड करने के लिए, Send Message With System Prompt का उपयोग करें:
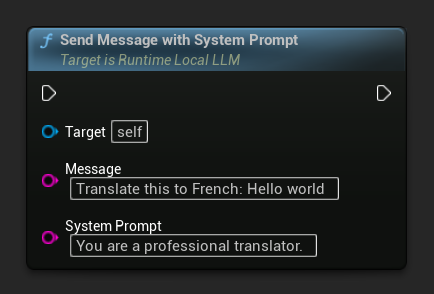
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
जैसे ही टोकन उत्पन्न होते हैं, वे OnTokenGenerated के माध्यम से स्ट्रीम होते हैं। जब जनरेशन समाप्त होता है, OnGenerationComplete पूर्ण प्रतिक्रिया, अवधि, टोकन गणना और tokens-per-second के साथ सक्रिय होता है।
Async संदेश भेजें (Blueprint)
Send LLM Message (Async) नोड टोकन, पूर्णता और त्रुटियों के लिए समर्पित आउटपुट पिन प्रदान करता है:
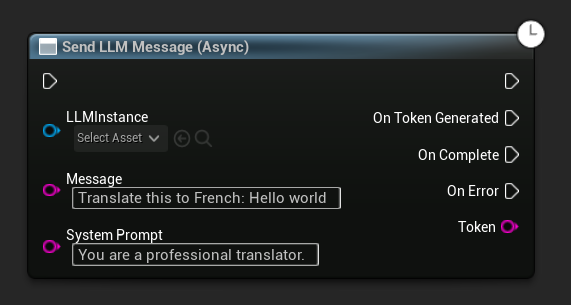
रनटाइम पर मॉडल डाउनलोड करें
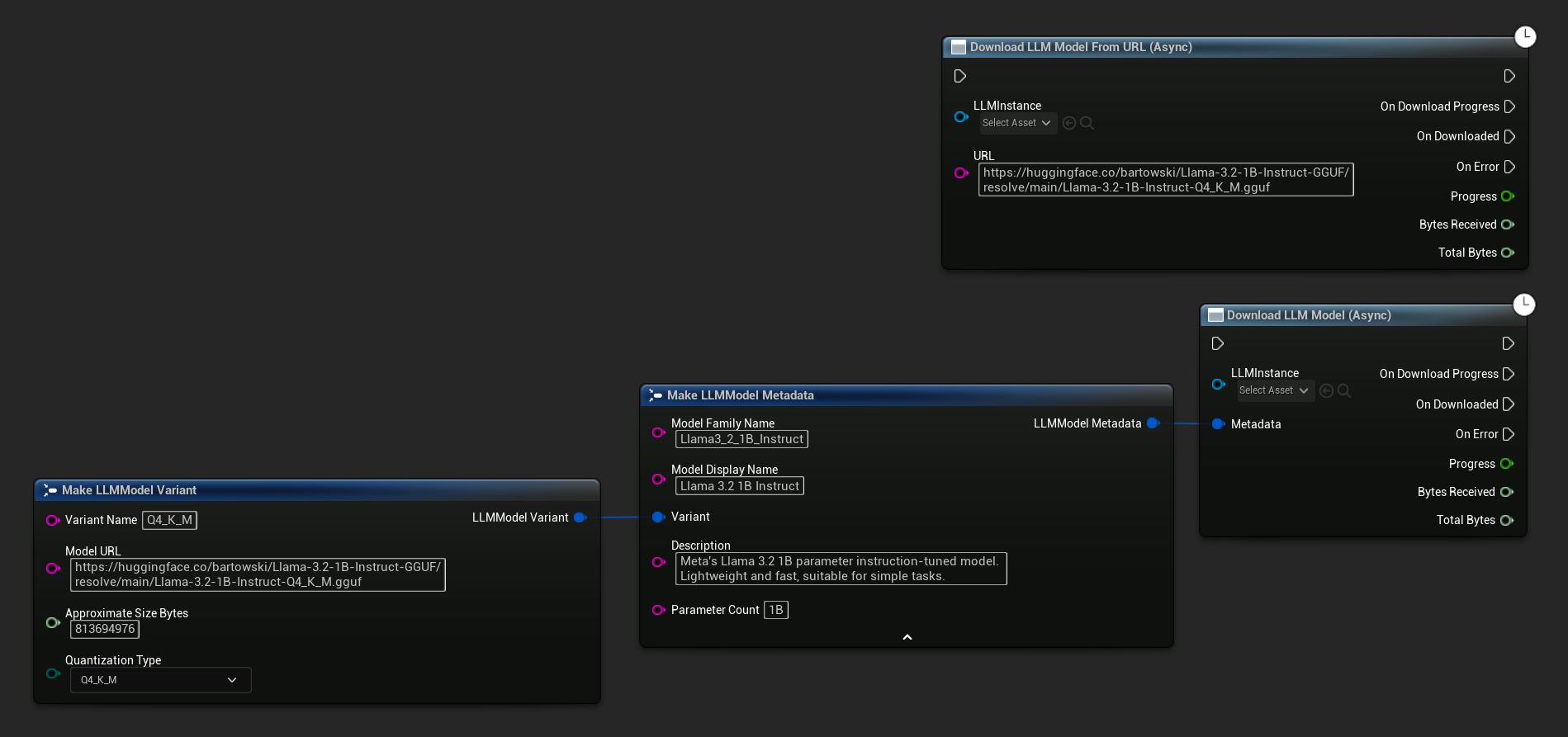
ऊपर वर्णित डाउनलोड-एंड-लोड प्रवाह के अलावा, आप किसी मॉडल को लोड किए बिना डिस्क पर डाउनलोड कर सकते हैं। यह लोडिंग स्क्रीन या सेटिंग्स मेनू में मॉडल को प्री-कैशिंग करने के लिए उपयोगी है।
- Blueprint
- C++
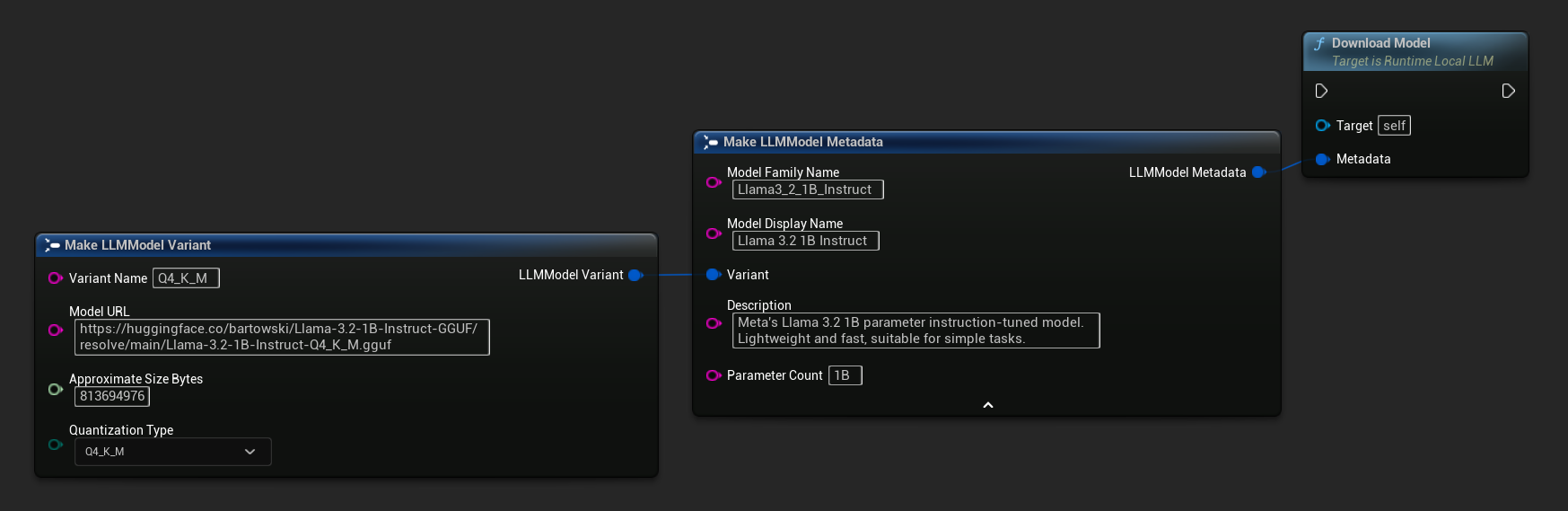
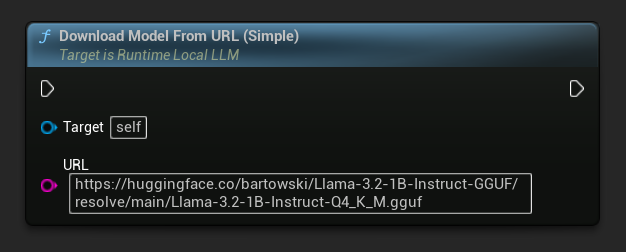
एक URL-केवल संस्करण भी उपलब्ध है:
Download LLM Model (Async) और Download LLM Model From URL (Async) नोड प्रगति, पूर्णता और त्रुटियों के लिए आउटपुट पिन प्रदान करता है:
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
OnDownloadProgress delegate डाउनलोड के दौरान प्रगति की सूचना देता है। OnModelDownloaded तब सक्रिय होता है जब फ़ाइल डिस्क पर सहेजी जाती है।
प्रगति में डाउनलोड रद्द करने के लिए:
- Blueprint
- C++
LLM->CancelDownload();
प्लगइन स्वचालित रूप से डुप्लिकेट डाउनलोड को रोकता है - यदि उसी मॉडल के लिए पहले से ही कोई डाउनलोड प्रगति पर है, तो बाद की कॉल्स को अनदेखा कर दिया जाता है।
जनरेशन रोकें
चल रही जनरेशन को बाधित करने के लिए:
- Blueprint
- C++
LLM->StopGeneration();
बातचीत संदर्भ रीसेट करें
नई बातचीत शुरू करने के लिए बातचीत इतिहास साफ़ करें:
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
मॉडल अनलोड करें
जब किसी मॉडल की आवश्यकता न हो, तब संसाधन मुक्त करें:
- Blueprint
- C++
LLM->UnloadModel();
क्वेरी स्थिति
LLM इंस्टेंस की वर्तमान स्थिति जाँचें:
- Blueprint
- C++
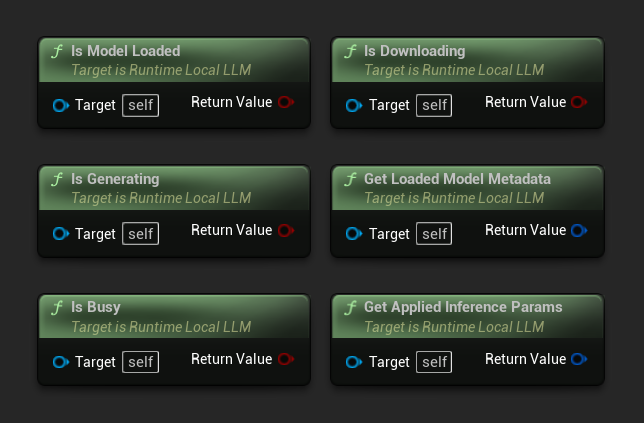
- Is Model Loaded: यदि कोई मॉडल अनुमान के लिए तैयार है तो सत्य
- Is Generating: यदि जनरेशन प्रगति में है तो सत्य
- Is Busy: यदि कोई ऑपरेशन (लोडिंग, जनरेटिंग, डाउनलोडिंग) सक्रिय है तो सत्य
- Is Downloading: यदि कोई मॉडल डाउनलोड प्रगति में है तो सत्य
- Get Loaded Model Metadata: वर्तमान मॉडल का मेटाडेटा लौटाता है
- Get Applied Inference Params: लोड करते समय लागू किए गए पैरामीटर लौटाता है
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
मॉडल लाइब्रेरी फ़ंक्शन
मॉडल फ़ाइलों को डिस्क पर प्रबंधित करने के लिए स्थैतिक उपयोगिता फ़ंक्शन का एक सेट प्रदान किया गया है। ये मॉडल चयन UI बनाने या रनटाइम पर मॉडल उपलब्धता की जाँच करने के लिए उपयोगी हैं।
डाउनलोड किए गए मॉडल नाम / मेटाडेटा प्राप्त करें
- Blueprint
- C++
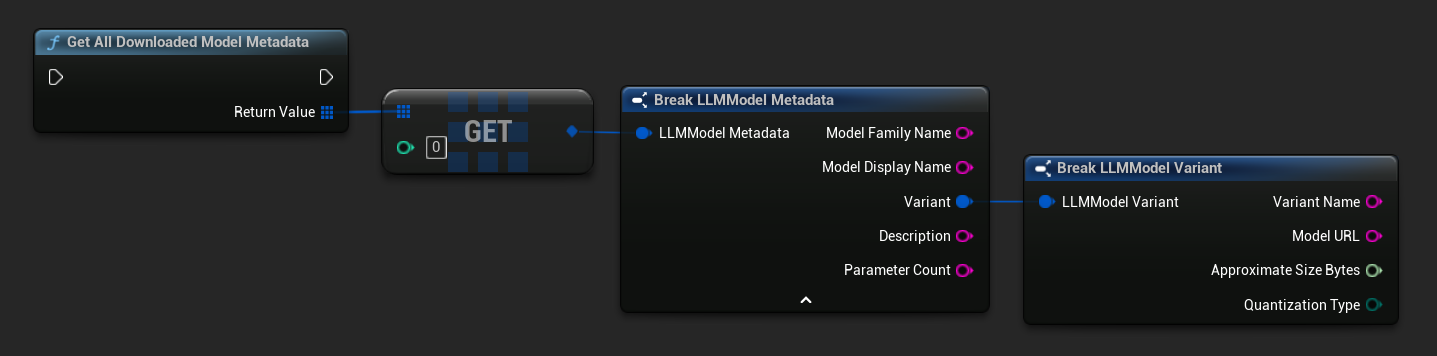
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
जांचें कि मॉडल डिस्क पर है या नहीं
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
मॉडल फ़ाइल पथ प्राप्त करें
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
मॉडल फ़ाइलें हटाएं
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
पूर्व-निर्धारित और उपलब्ध मॉडल प्राप्त करें
- Blueprint
- C++
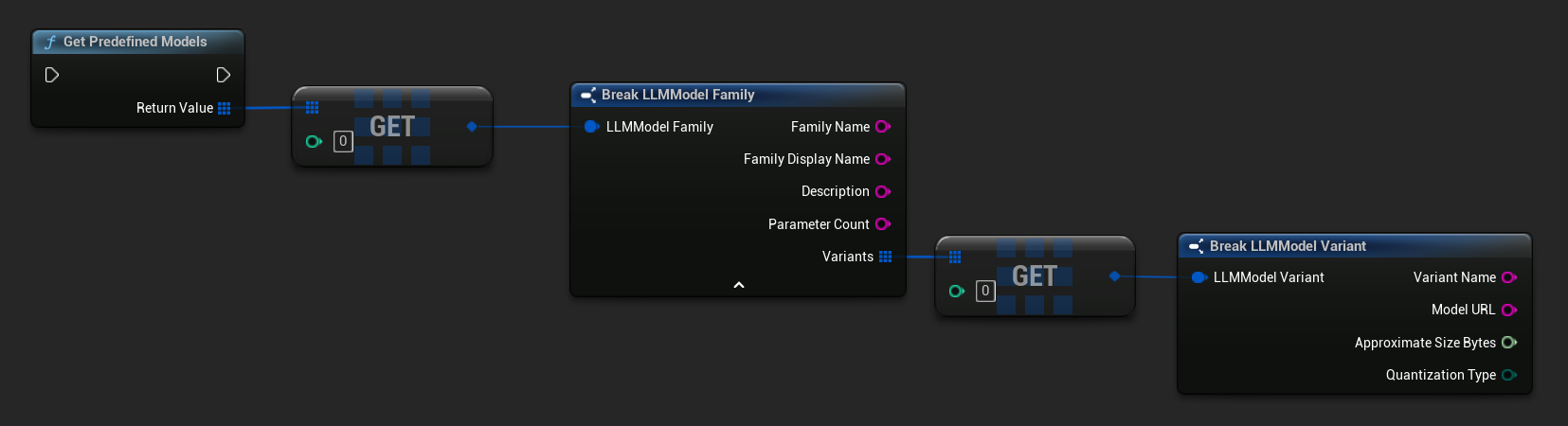
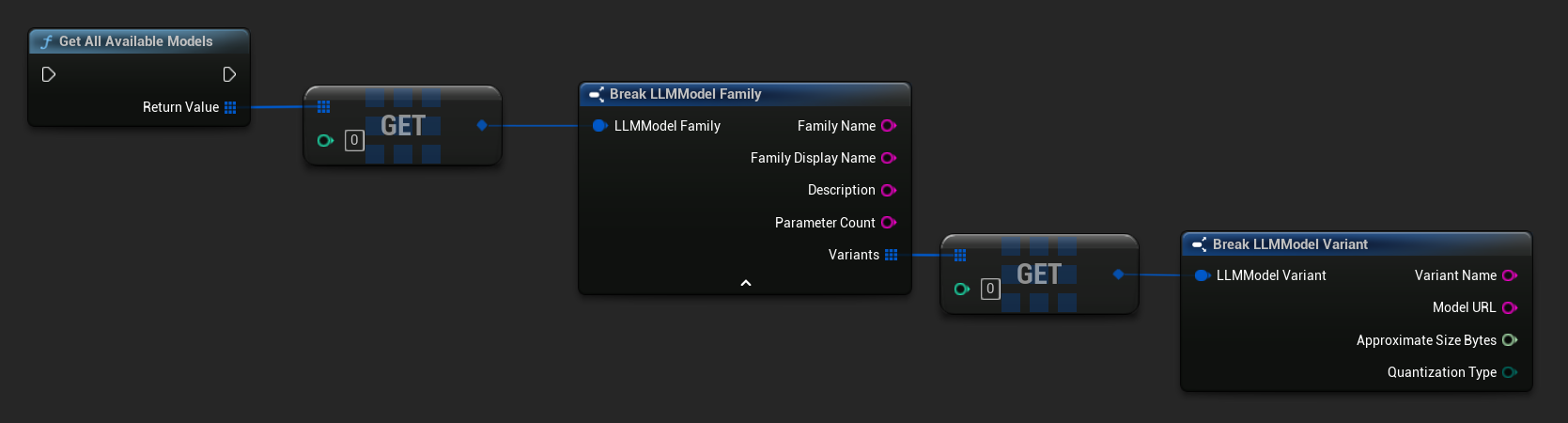
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
एक URL से मेटाडेटा बनाएं
एक कच्चे URL से मॉडल मेटाडेटा बनाएँ (फ़ील्ड फ़ाइल नाम से प्राप्त होते हैं):
- Blueprint
- C++
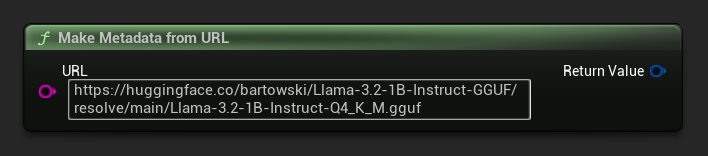
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
उपयोगिता फ़ंक्शन
स्वरूपण और त्रुटि प्रदर्शन के लिए सहायक फ़ंक्शनों का एक सेट प्रदान किया गया है।
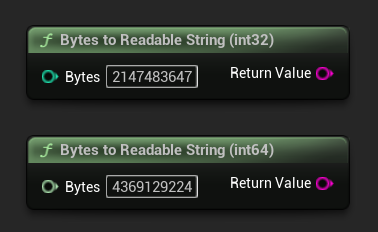
Bytes to Readable String
बाइट गिनती को मानव-पठनीय स्ट्रिंग (जैसे "4.07 GB") में बदलता है। UI में मॉडल आकार प्रदर्शित करने के लिए उपयोगी।
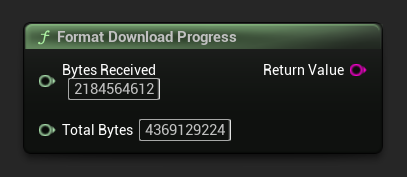
Format Download Progress
डाउनलोड प्रगति स्ट्रिंग को "1.23 GB / 4.07 GB (30.2%)" की तरह फ़ॉर्मेट करता है। यदि कुल आकार अज्ञात है, तो केवल प्राप्त राशि लौटाता है।
Get Error Description / Error Code String
Get LLM Error Description किसी त्रुटि कोड के लिए मानव-पठनीय पाठ विवरण लौटाता है। Get LLM Error Code String एनम मान नाम को एक स्ट्रिंग के रूप में लौटाता है (लॉगिंग के लिए उपयोगी)।
त्रुटि कोड संदर्भ
| कोड | मान | विवरण |
|---|---|---|
| Unknown | 0 | एक अनिर्दिष्ट त्रुटि |
| ModelLoadFailed | 10 | GGUF फ़ाइल लोड होने में विफल रही (दूषित फ़ाइल, असंगत प्रारूप, आदि) |
| ContextCreateFailed | 11 | अनुमान संदर्भ बनाने में विफल |
| ModelNotLoaded | 20 | कोई मॉडल लोड किए बिना अनुमान का प्रयास किया गया |
| ChatTemplateFailed | 21 | मॉडल का चैट टेम्पलेट लागू करने में विफल |
| TokenizationFailed | 22 | इनपुट पाठ को टोकन में बदला नहीं जा सका |
| ContextOverflow | 23 | प्रॉम्प्ट + संदर्भ कॉन्फ़िगर किए गए संदर्भ आकार से अधिक है |
| PromptDecodeFailed | 24 | प्रॉम्प्ट टोकन डिकोड करने में विफल |
| ContextTooFullToGenerate | 25 | आउटपुट जनरेट करने के लिए पर्याप्त संदर्भ स्थान शेष नहीं है |
| GenerationDecodeFailed | 30 | जनरेशन के दौरान एक टोकन डिकोड करने में विफल |
| GenerationTruncated | 31 | अधिकतम टोकन सीमा तक पहुँचने के कारण जनरेशन रुक गई |
| LLMInstanceNull | 40 | LLM इंस्टेंस नल या अमान्य है |
| ModelNotFoundOnDisk | 41 | मॉडल फ़ाइल अपेक्षित पथ पर मौजूद नहीं है |
| ModelURLEmpty | 42 | खाली URL के साथ डाउनलोड का अनुरोध किया गया था |
| ModelDownloadCancelled | 43 | डाउनलोड रद्द कर दिया गया |
| ModelDownloadEmptyData | 44 | डाउनलोड पूरा हुआ लेकिन प्रतिक्रिया बॉडी खाली थी |
| ModelDownloadSaveFailed | 45 | डाउनलोड पूरा हुआ लेकिन फ़ाइल को डिस्क पर सहेजा नहीं जा सका |