ऑडियो प्रसंस्करण गाइड
यह गाइड आपके लिप सिंक जनरेटरों को ऑडियो डेटा फीड करने के लिए विभिन्न ऑडियो इनपुट विधियों को सेट अप करने का तरीका बताती है। आगे बढ़ने से पहले सुनिश्चित करें कि आपने सेटअप गाइड पूरा कर लिया है।
ऑडियो इनपुट प्रसंस्करण
आपको ऑडियो इनपुट को प्रोसेस करने की एक विधि सेट अप करने की आवश्यकता है। यह आपके ऑडियो स्रोत के आधार पर कई तरीकों से किया जा सकता है।
- माइक्रोफोन (रियल-टाइम)
- माइक्रोफोन (प्लेबैक)
- टेक्स्ट-टू-स्पीच (लोकल)
- Text-to-Speech (External APIs)
- From Audio File/Buffer
- Streaming Audio Buffer
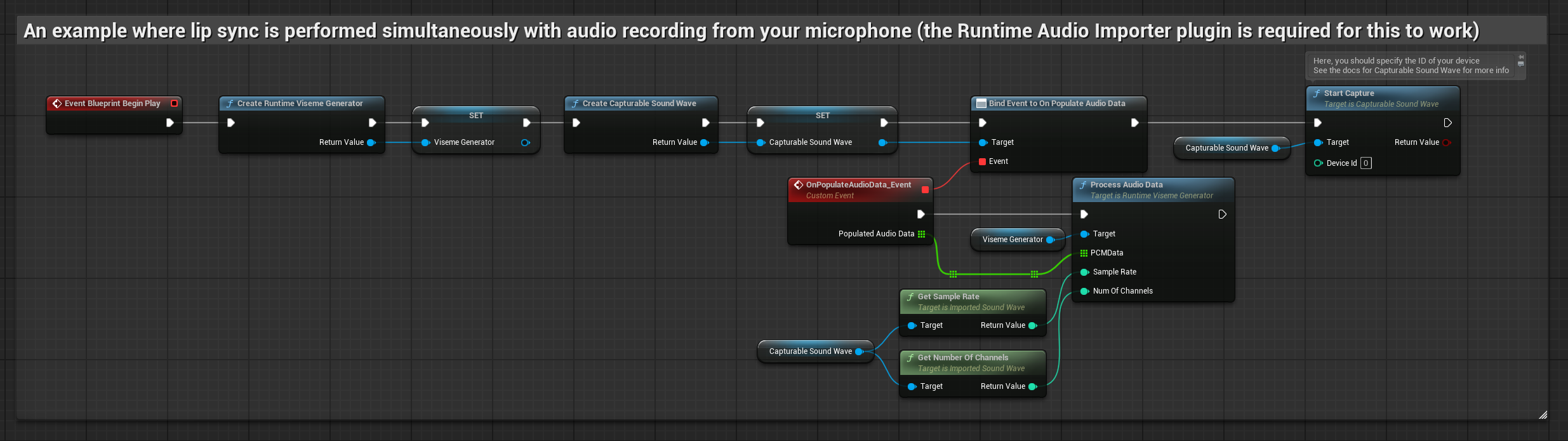
यह दृष्टिकोण माइक्रोफोन में बोलते समय रियल-टाइम में लिप सिंक करता है:
- स्टैंडर्ड मॉडल
- यथार्थवादी मॉडल
- मूड-सक्षम यथार्थवादी मॉडल
- Runtime Audio Importer का उपयोग करके एक Capturable Sound Wave बनाएं
- Pixel Streaming के साथ Linux के लिए, इसके बजाय Pixel Streaming Capturable Sound Wave का उपयोग करें
- ऑडियो कैप्चर करना शुरू करने से पहले,
OnPopulateAudioDataडेलीगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें - माइक्रोफोन से ऑडियो कैप्चर करना शुरू करें
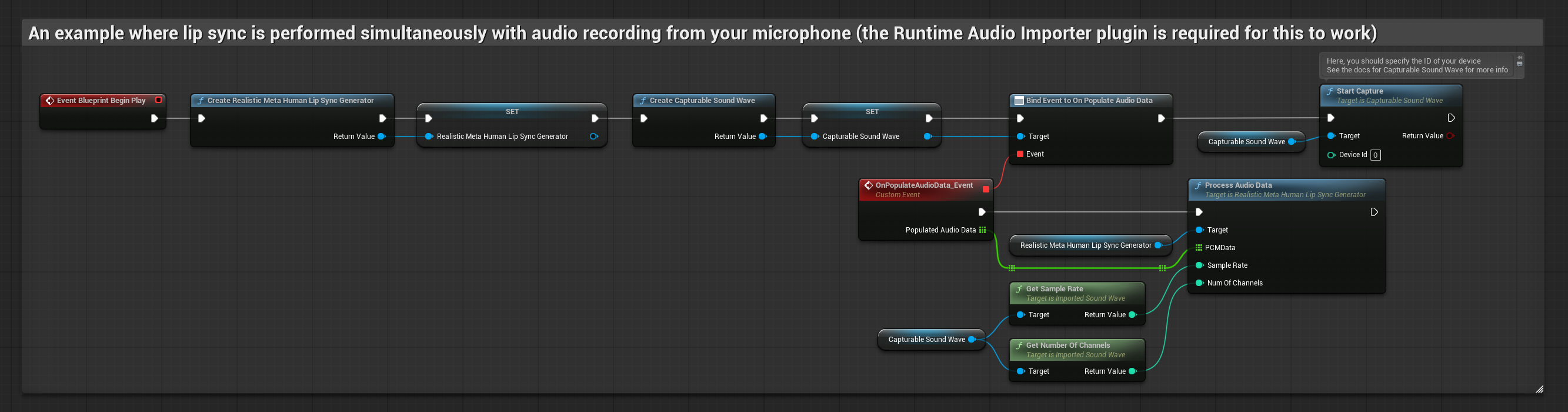
यथार्थवादी मॉडल स्टैंडर्ड मॉडल के समान ही ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
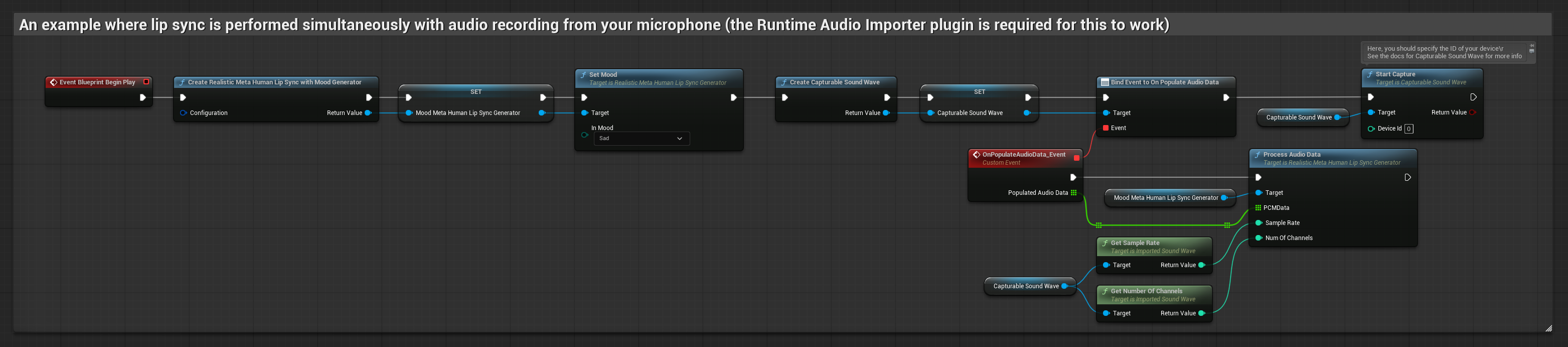
मूड-सक्षम मॉडल समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
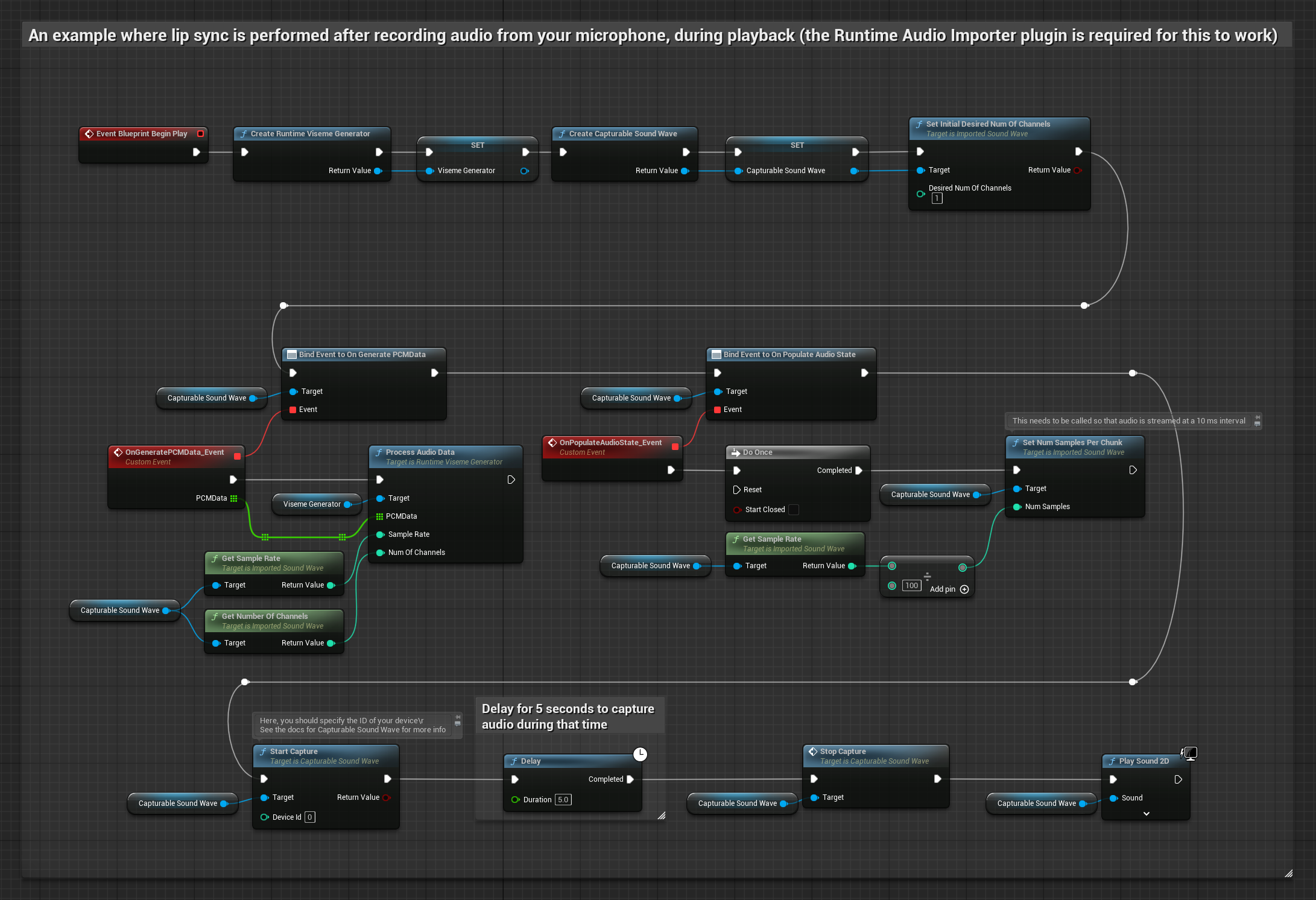
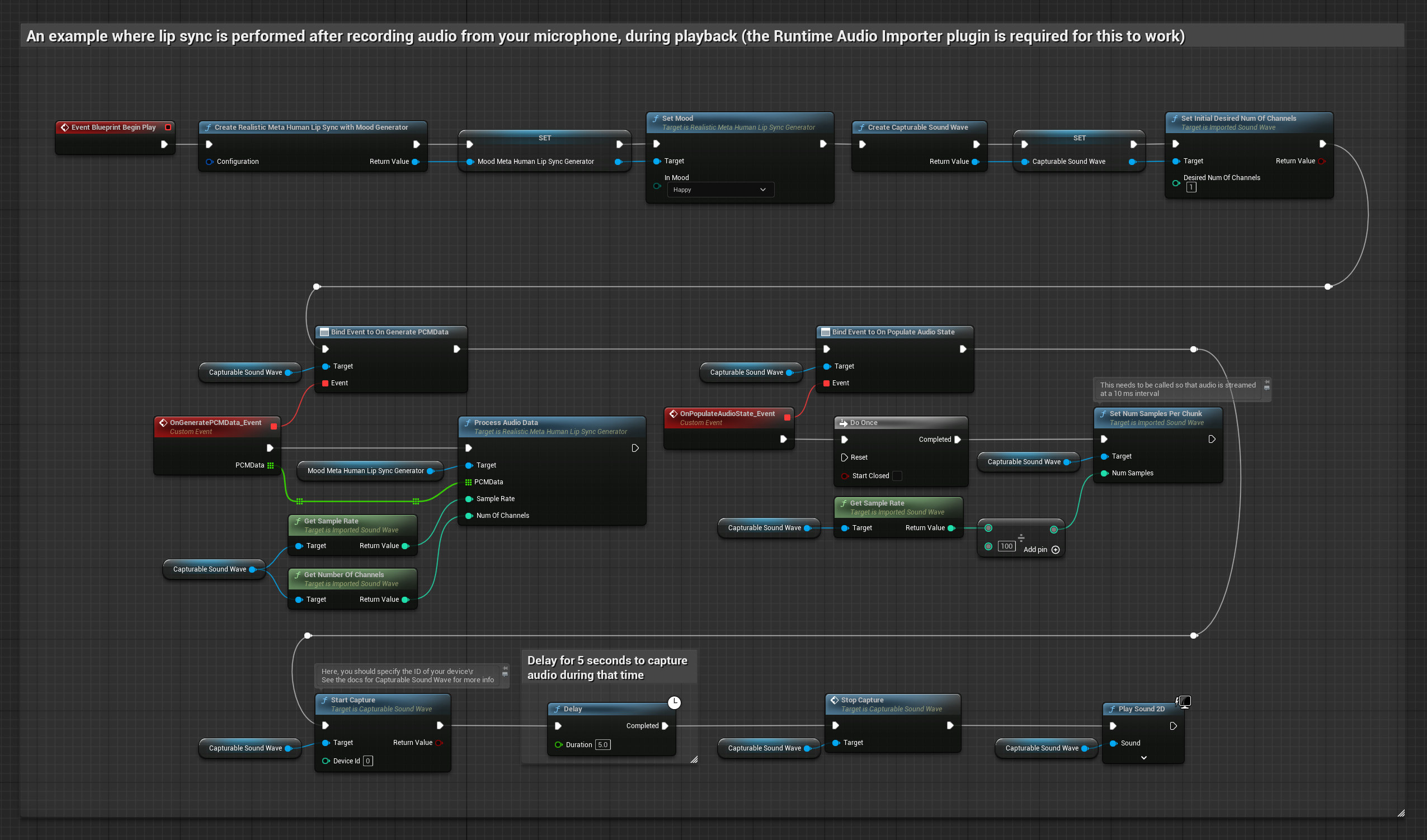
यह दृष्टिकोण माइक्रोफोन से ऑडियो कैप्चर करता है, फिर उसे लिप सिंक के साथ प्लेबैक करता है:
- स्टैंडर्ड मॉडल
- यथार्थवादी मॉडल
- मूड-सक्षम यथार्थवादी मॉडल
- Runtime Audio Importer का उपयोग करके एक Capturable Sound Wave बनाएं
- Pixel Streaming के साथ Linux के लिए, इसके बजाय Pixel Streaming Capturable Sound Wave का उपयोग करें
- माइक्रोफोन से ऑडियो कैप्चर शुरू करें
- कैप्चर करने योग्य साउंड वेव को प्लेबैक करने से पहले, इसके
OnGeneratePCMDataडेलीगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें
यथार्थवादी मॉडल स्टैंडर्ड मॉडल के समान ही ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
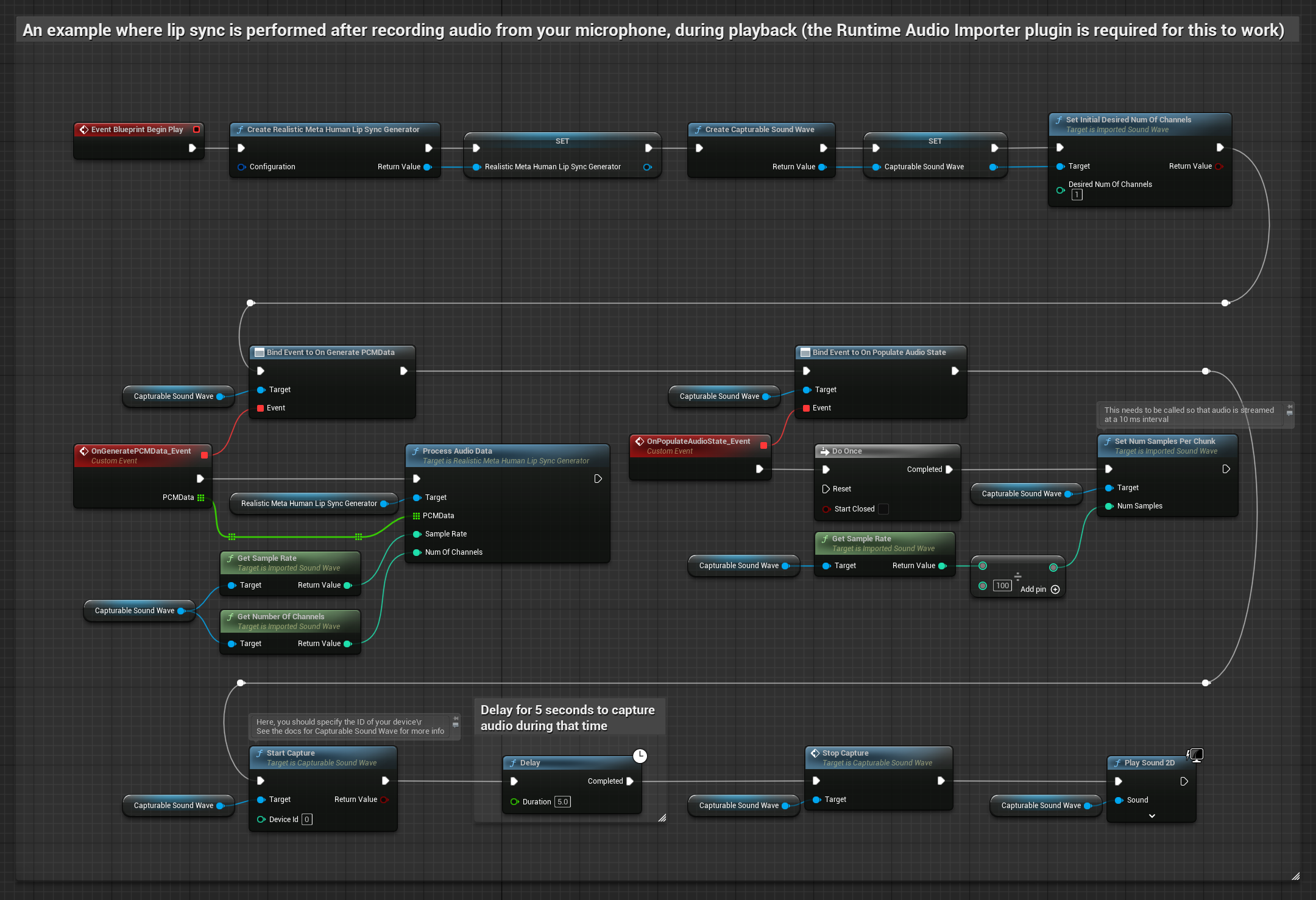
मूड-सक्षम मॉडल समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
- नियमित
- स्ट्रीमिंग
यह दृष्टिकोण लोकल TTS का उपयोग करके टेक्स्ट से स्पीच सिंथेसाइज़ करता है और लिप सिंक करता है:
- स्टैंडर्ड मॉडल
- यथार्थवादी मॉडल
- मूड-सक्षम यथार्थवादी मॉडल
- टेक्स्ट से स्पीच जनरेट करने के लिए Runtime Text To Speech का उपयोग करें
- सिंथेसाइज़ किए गए ऑडियो को इम्पोर्ट करने के लिए Runtime Audio Importer का उपयोग करें
- इम्पोर्ट किए गए साउंड वेव को प्लेबैक करने से पहले, इसके
OnGeneratePCMDataडेलीगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें
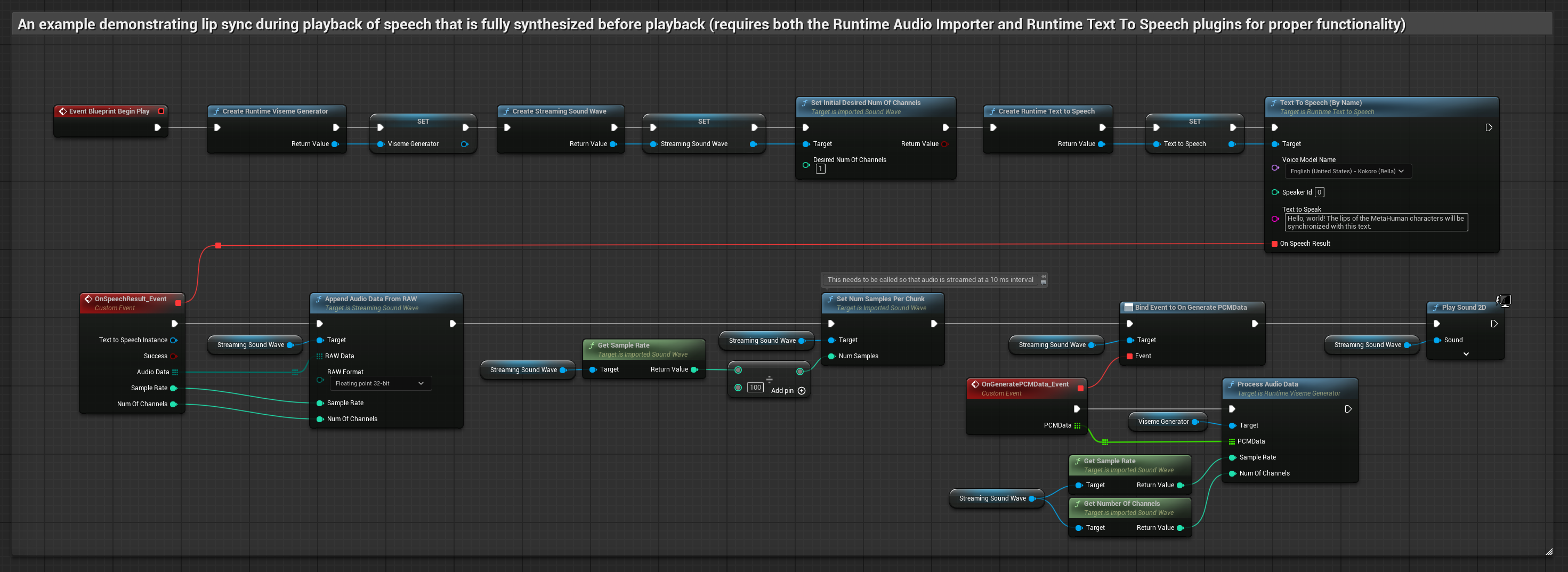
यथार्थवादी मॉडल स्टैंडर्ड मॉडल के समान ही ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
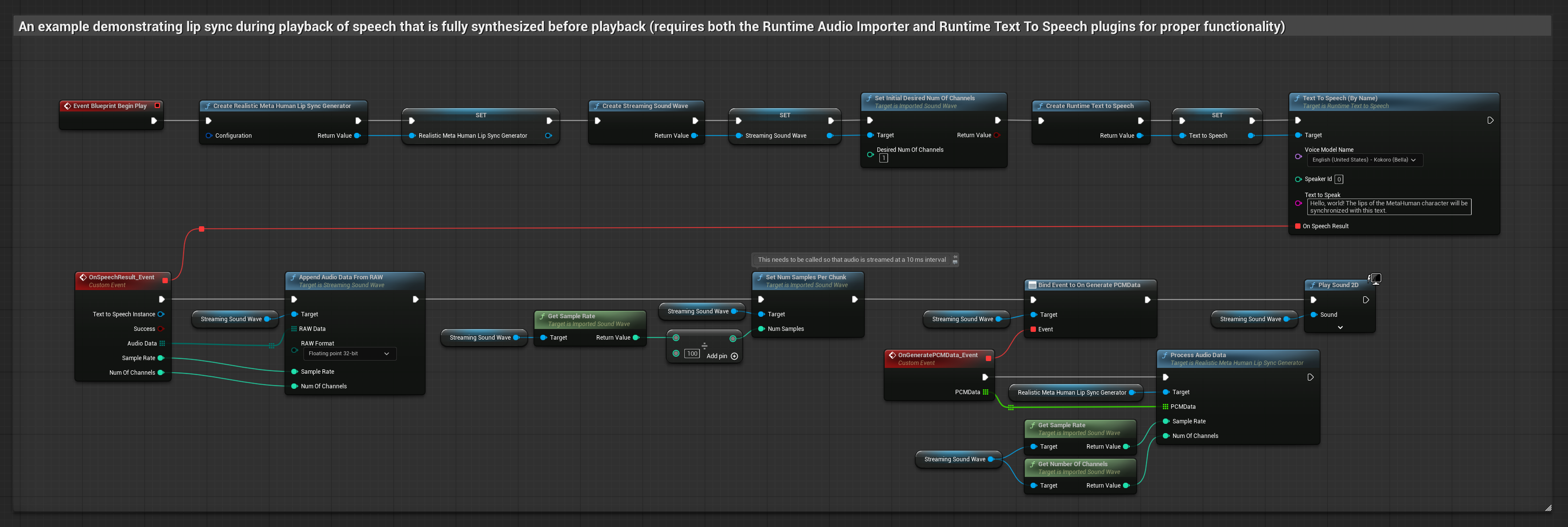
मूड-सक्षम मॉडल समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
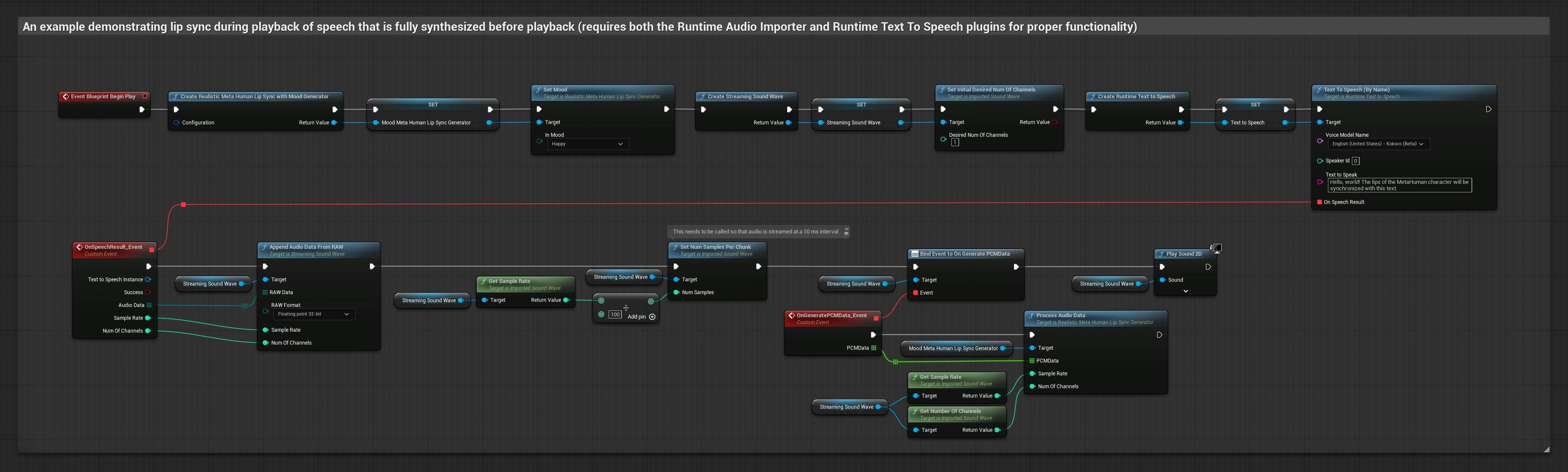
यह दृष्टिकोण रियल-टाइम लिप सिंक के साथ स्ट्रीमिंग टेक्स्ट-टू-स्पीच सिंथेसिस का उपयोग करता है:
- स्टैंडर्ड मॉडल
- यथार्थवादी मॉडल
- मूड-सक्षम यथार्थवादी मॉडल
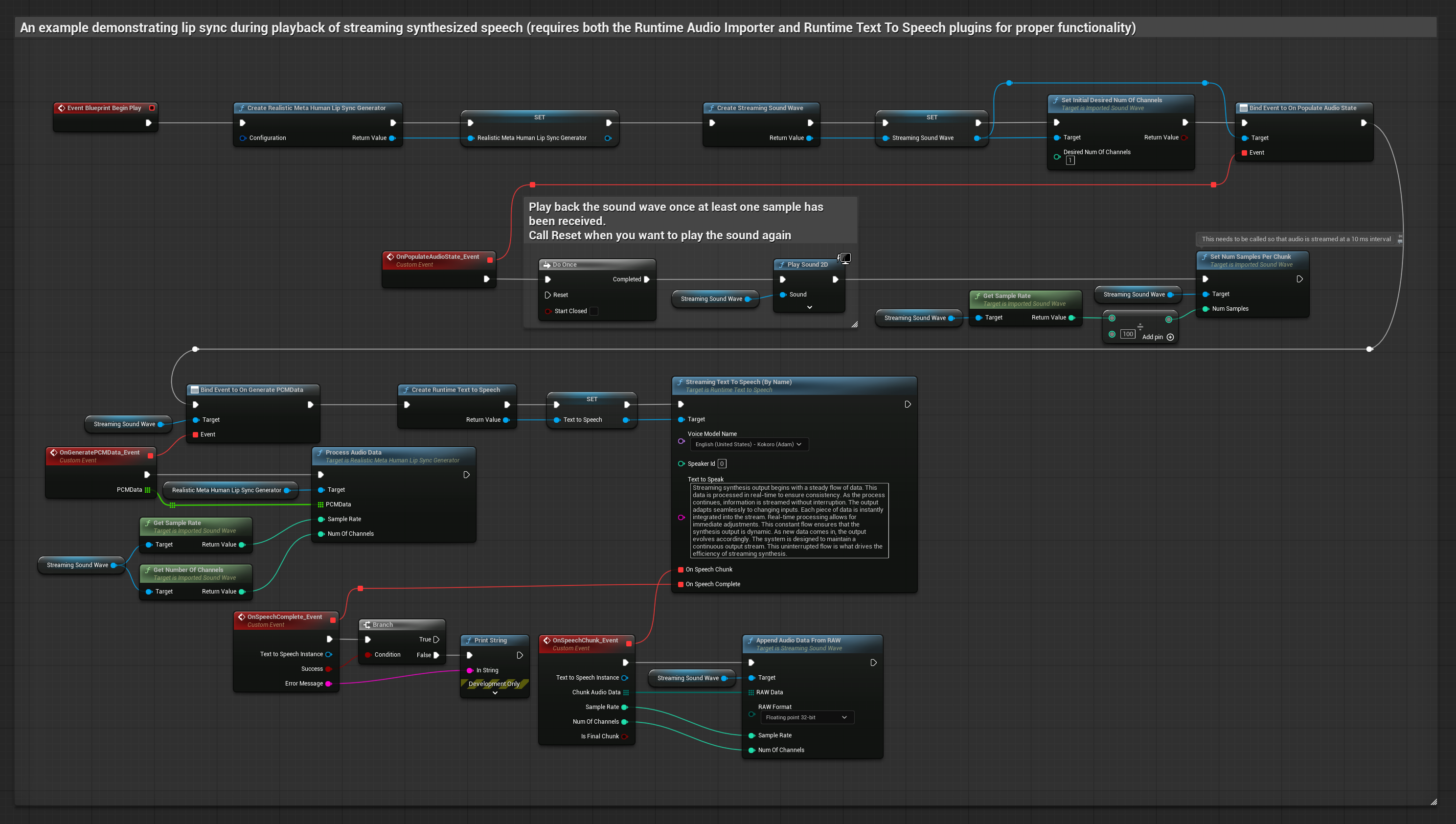
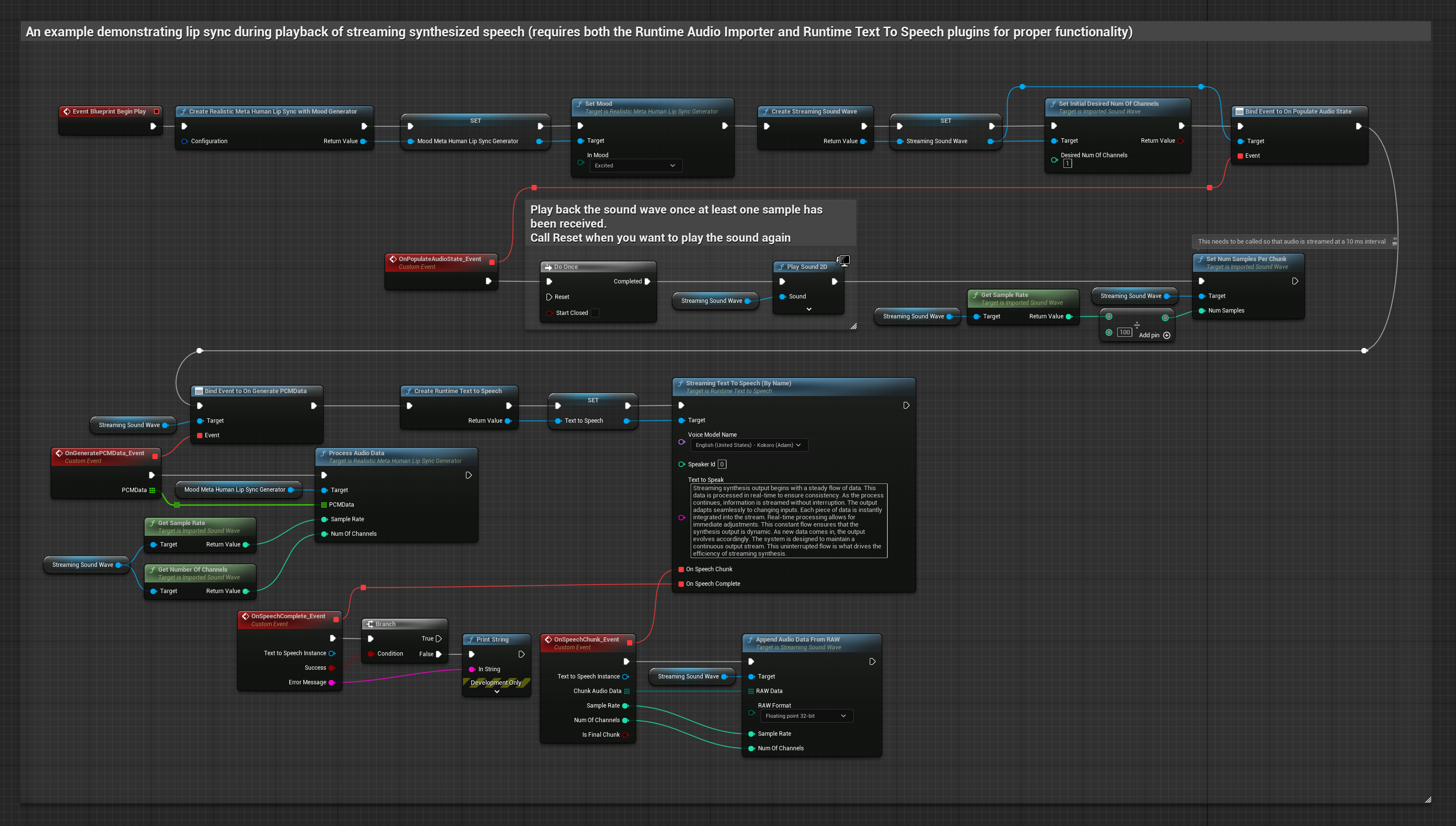
- टेक्स्ट से स्ट्रीमिंग स्पीच जनरेट करने के लिए Runtime Text To Speech का उपयोग करें
- सिंथेसाइज़ किए गए ऑडियो को इम्पोर्ट करने के लिए Runtime Audio Importer का उपयोग करें
- स्ट्रीमिंग साउंड वेव को प्लेबैक करने से पहले, इसके
OnGeneratePCMDataडेलीगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें
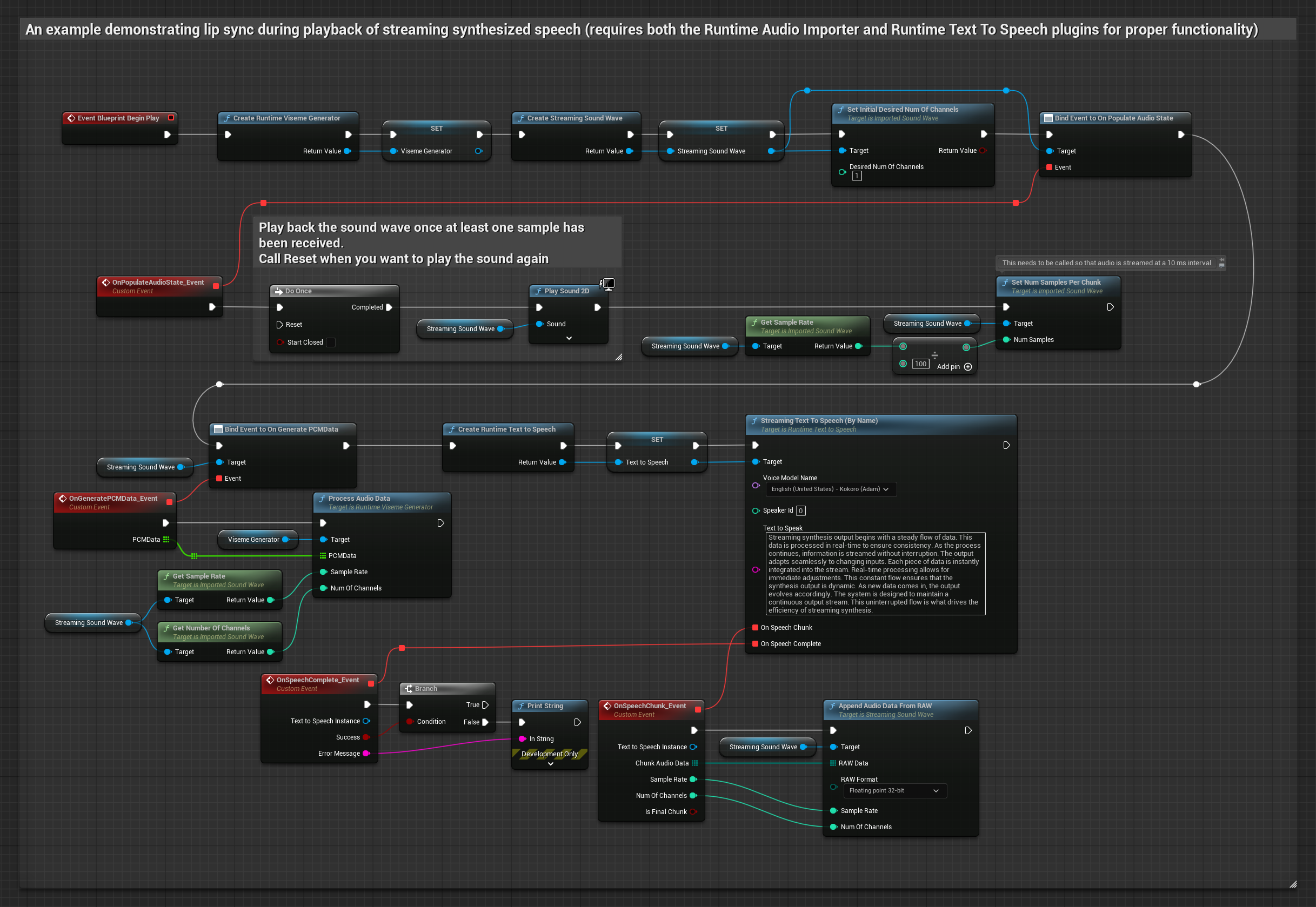
यथार्थवादी मॉडल स्टैंडर्ड मॉडल के समान ही ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
मूड-सक्षम मॉडल समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
- Regular
- Streaming
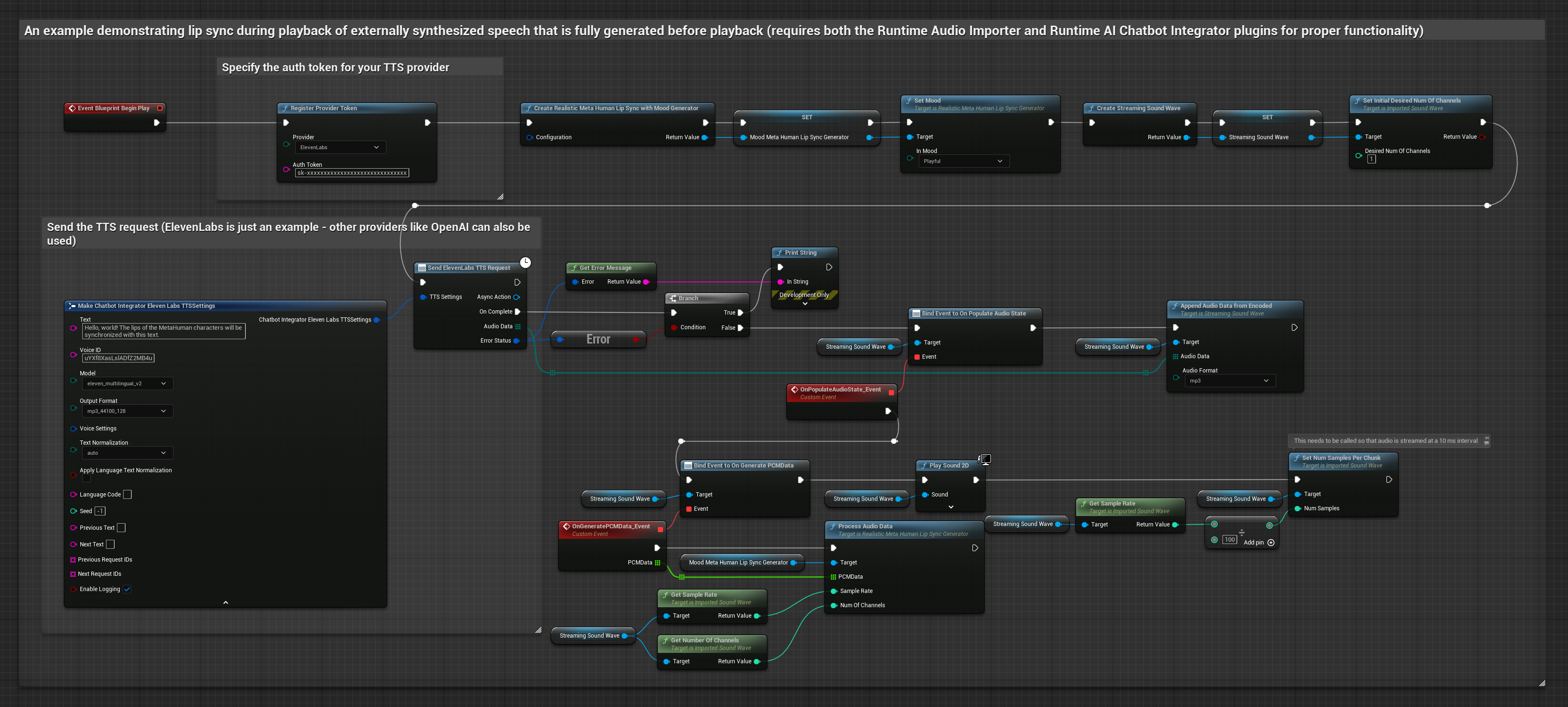
यह दृष्टिकोण संश्लेषित वाक् उत्पन्न करने के लिए Runtime AI Chatbot Integrator प्लगइन का उपयोग करता है AI सेवाओं (OpenAI या ElevenLabs) से और होंठ सिंक करता है:
- Standard Model
- Realistic Model
- Mood-Enabled Realistic Model
- बाहरी API (OpenAI, ElevenLabs, आदि) का उपयोग करके पाठ से वाक् उत्पन्न करने के लिए Runtime AI Chatbot Integrator का उपयोग करें
- संश्लेषित ऑडियो डेटा आयात करने के लिए Runtime Audio Importer का उपयोग करें
- आयातित साउंड वेव को प्लेबैक करने से पहले, इसके
OnGeneratePCMDataडेलिगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें
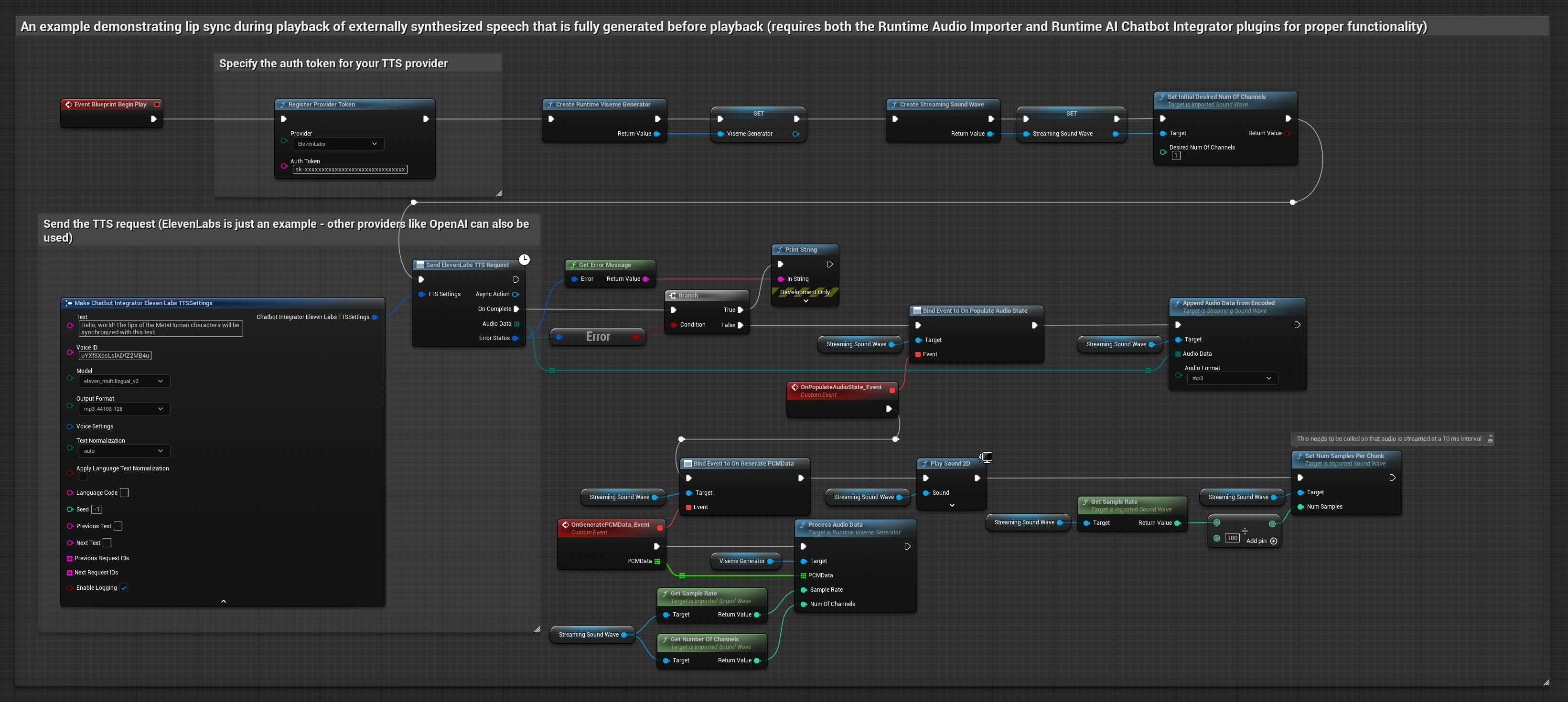
Realistic Model, Standard Model के समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
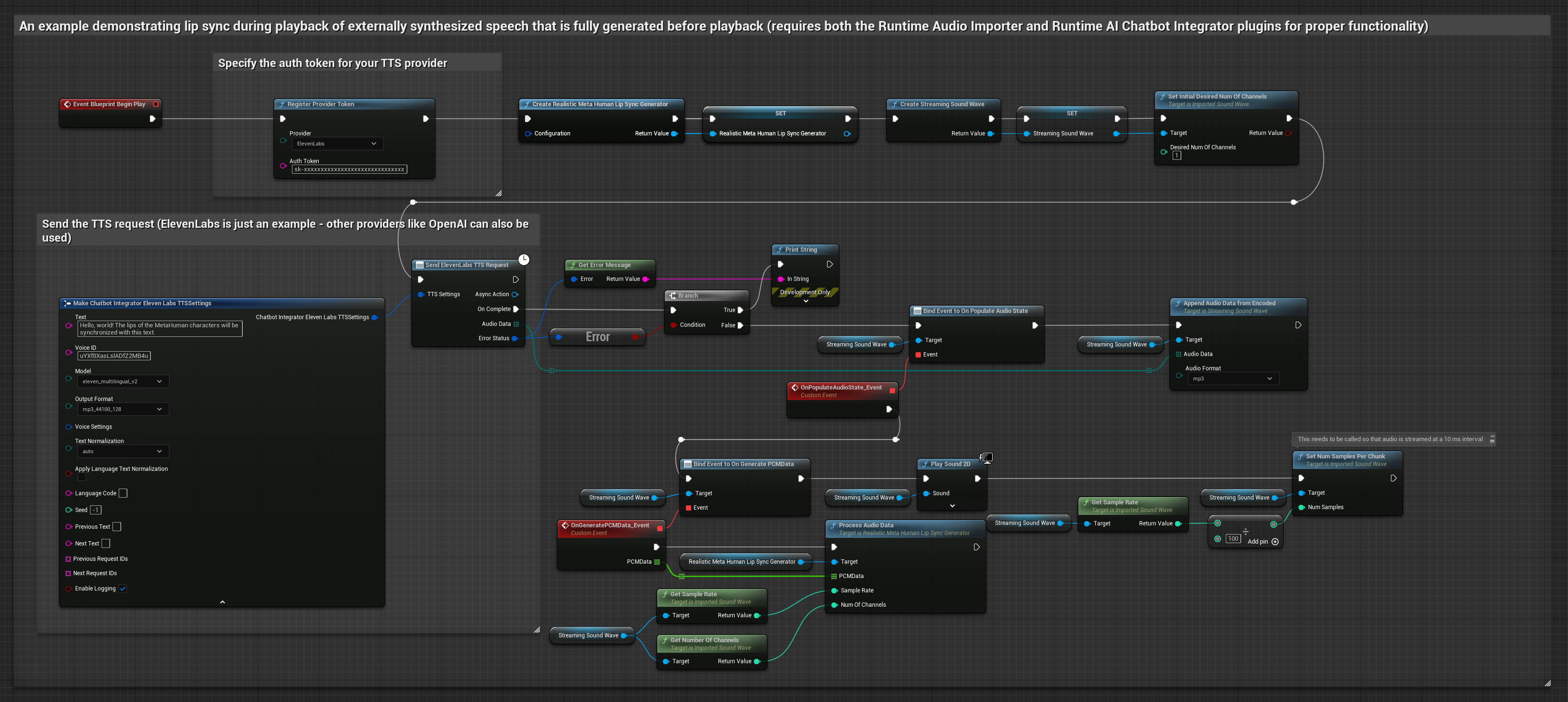
Mood-Enabled Model समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
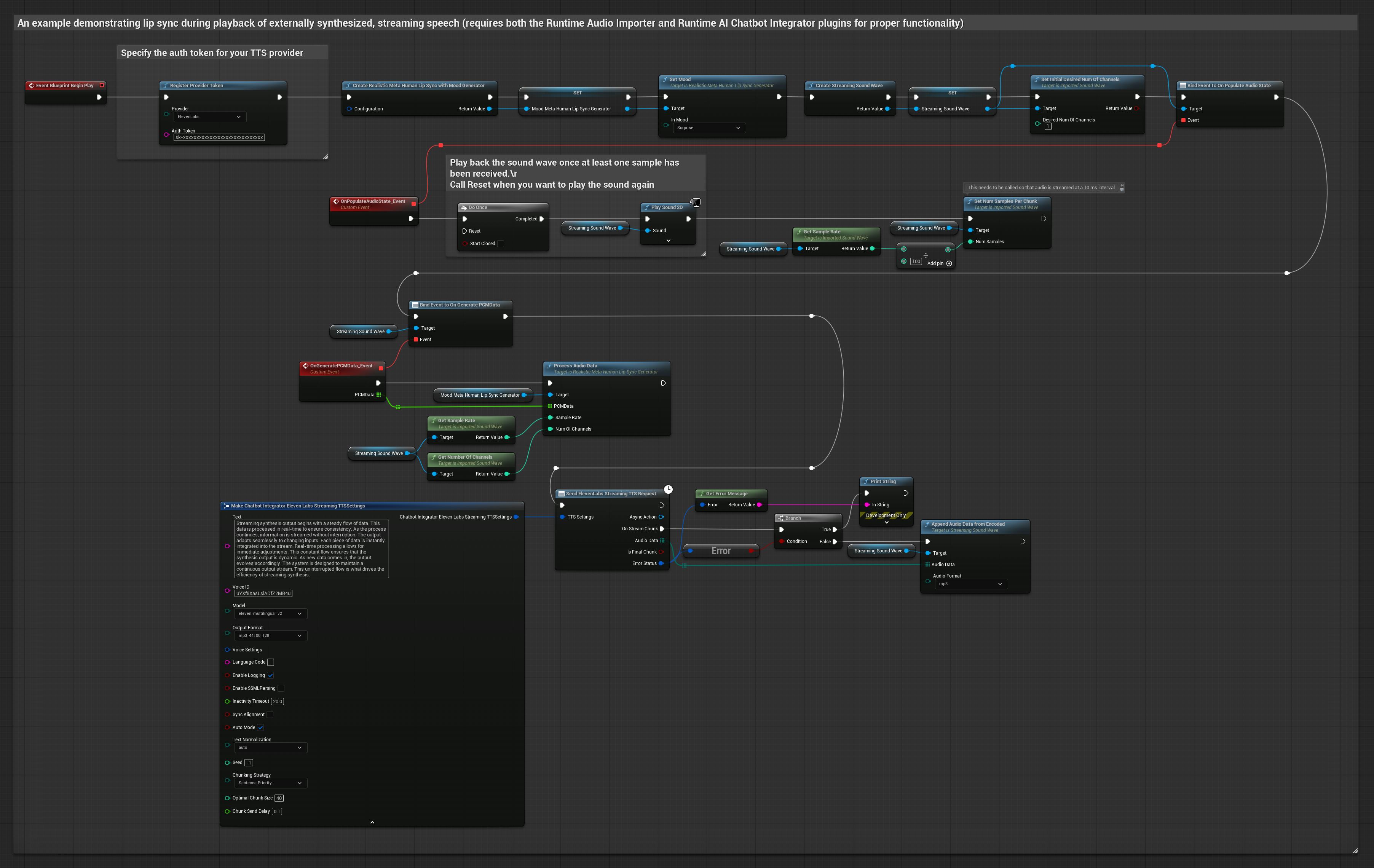
यह दृष्टिकोण संश्लेषित स्ट्रीमिंग वाक् उत्पन्न करने के लिए Runtime AI Chatbot Integrator प्लगइन का उपयोग करता है AI सेवाओं (OpenAI या ElevenLabs) से और होंठ सिंक करता है:
- Standard Model
- Realistic Model
- Mood-Enabled Realistic Model
- स्ट्रीमिंग TTS API (जैसे ElevenLabs Streaming API) से कनेक्ट करने के लिए Runtime AI Chatbot Integrator का उपयोग करें
- संश्लेषित ऑडियो डेटा आयात करने के लिए Runtime Audio Importer का उपयोग करें
- स्ट्रीमिंग साउंड वेव को प्लेबैक करने से पहले, इसके
OnGeneratePCMDataडेलिगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें
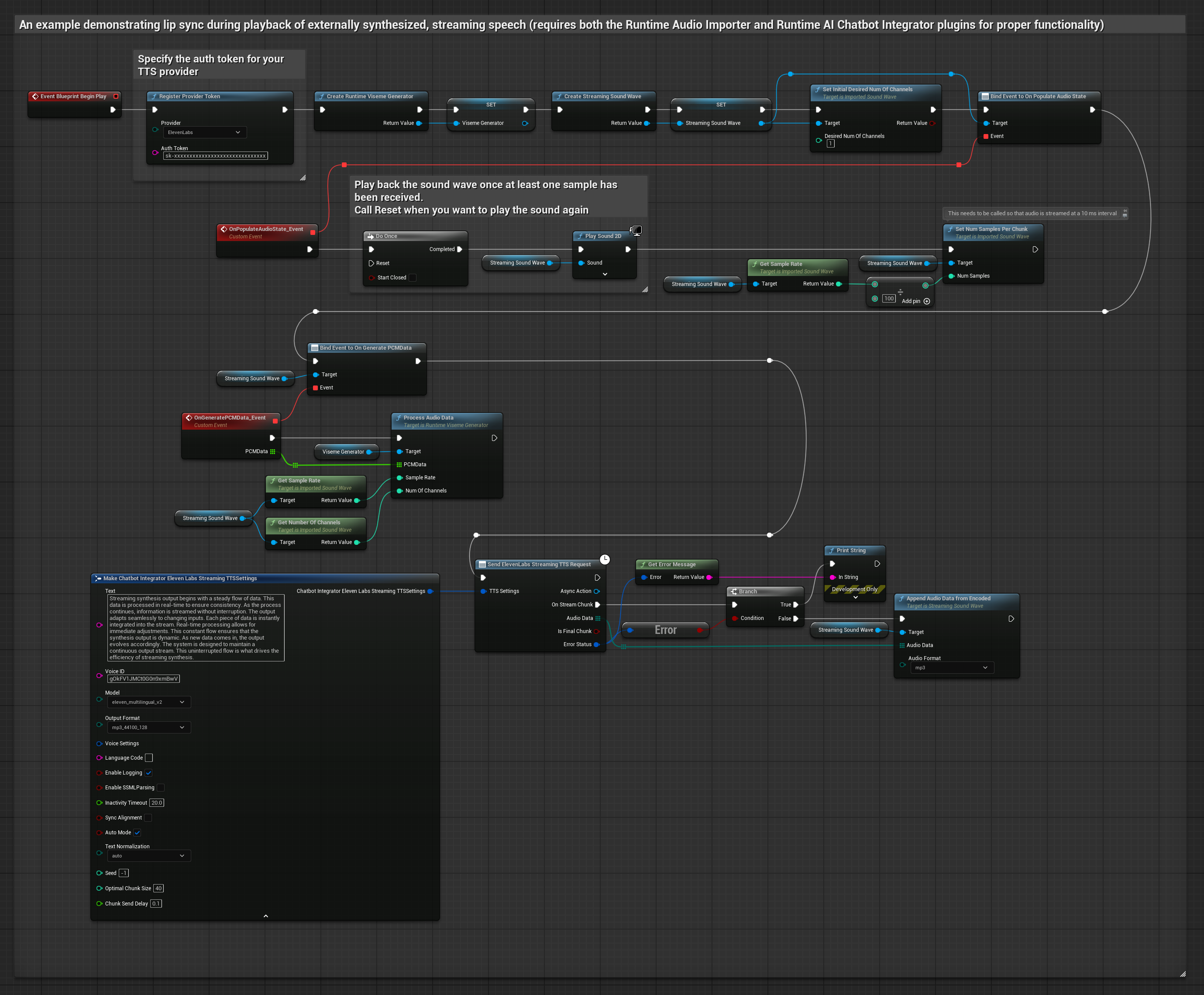
Realistic Model, Standard Model के समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
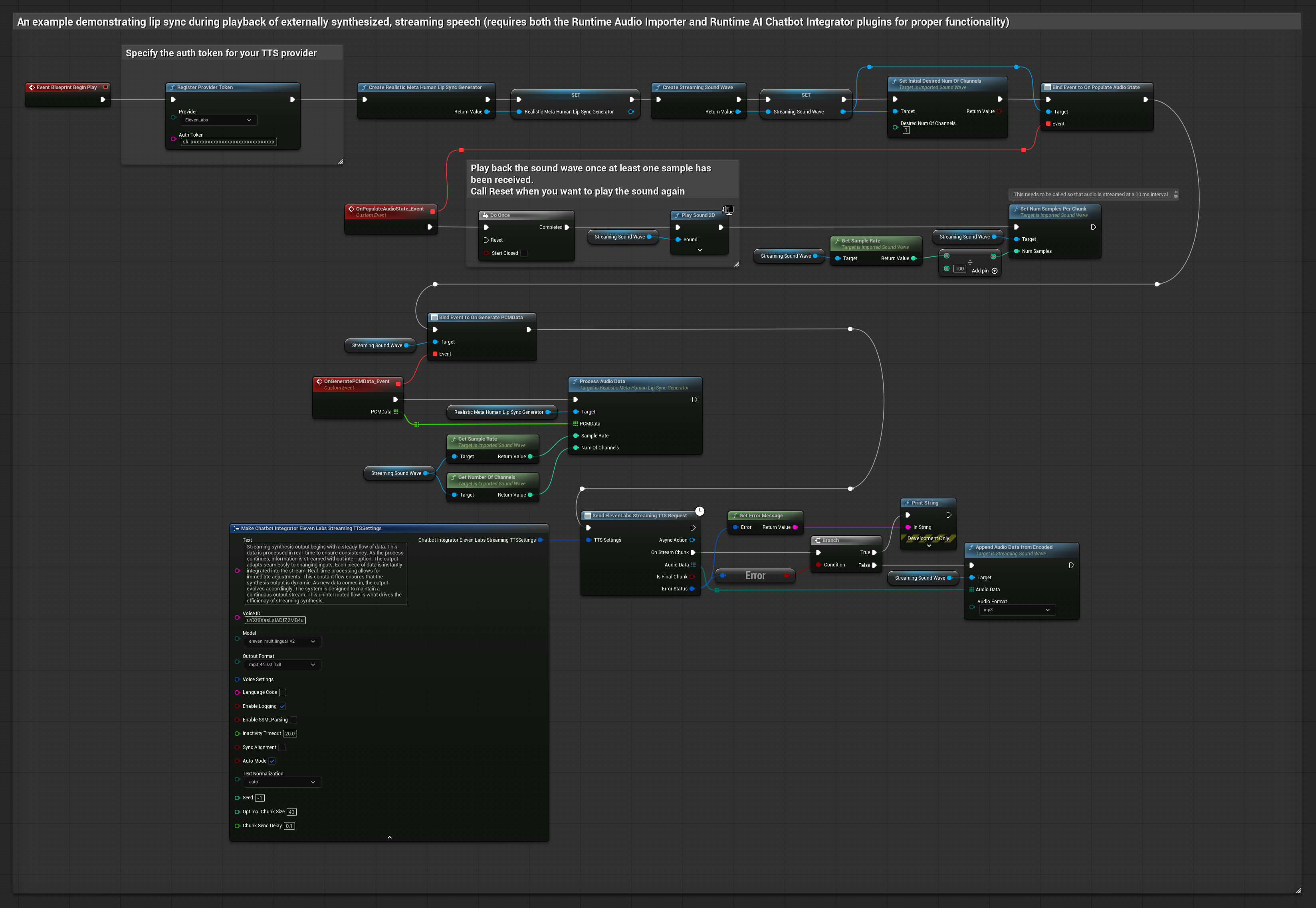
Mood-Enabled Model समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
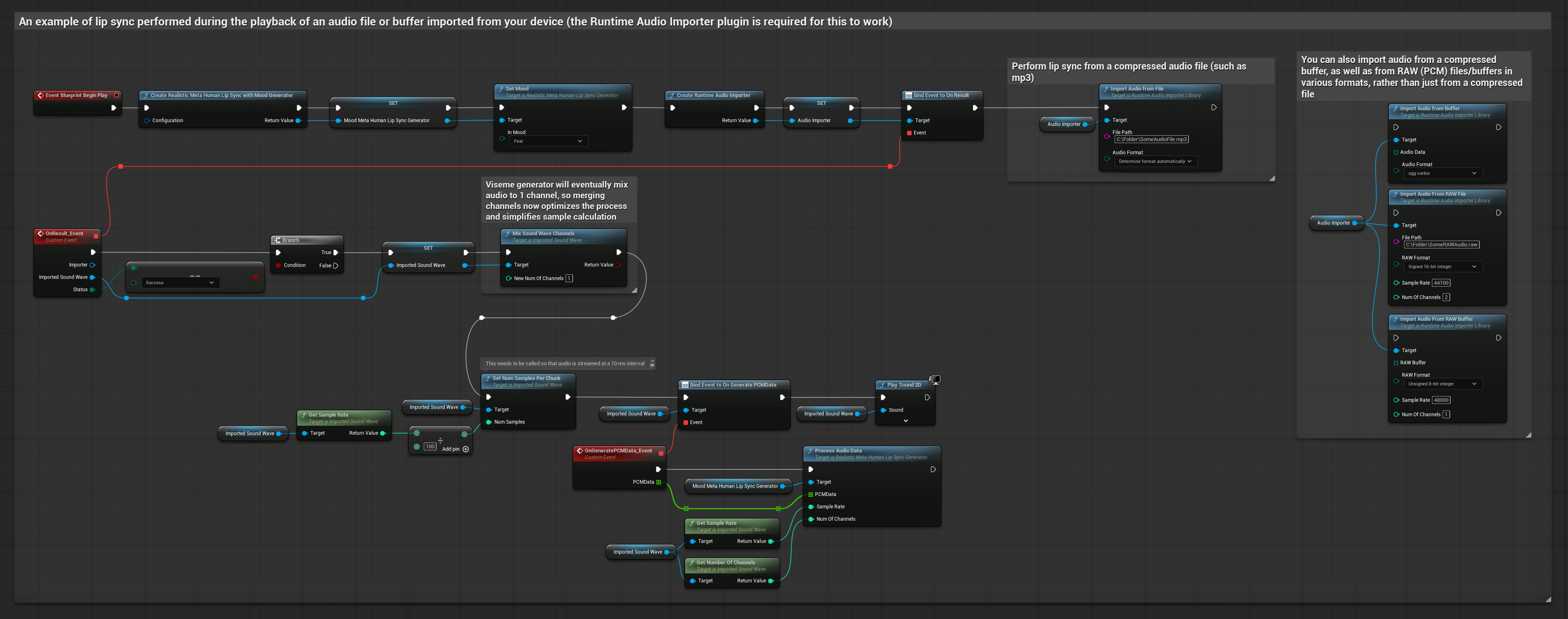
यह दृष्टिकोण होंठ सिंक के लिए पूर्व-रिकॉर्डेड ऑडियो फ़ाइलों या ऑडियो बफ़र्स का उपयोग करता है:
- Standard Model
- Realistic Model
- Mood-Enabled Realistic Model
- डिस्क या मेमोरी से एक ऑडियो फ़ाइल आयात करने के लिए Runtime Audio Importer का उपयोग करें
- आयातित साउंड वेव को प्लेबैक करने से पहले, इसके
OnGeneratePCMDataडेलिगेट से बाइंड करें - बाउंड फ़ंक्शन में, अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें - आयातित साउंड वेव प्ले करें और होंठ सिंक एनीमेशन देखें
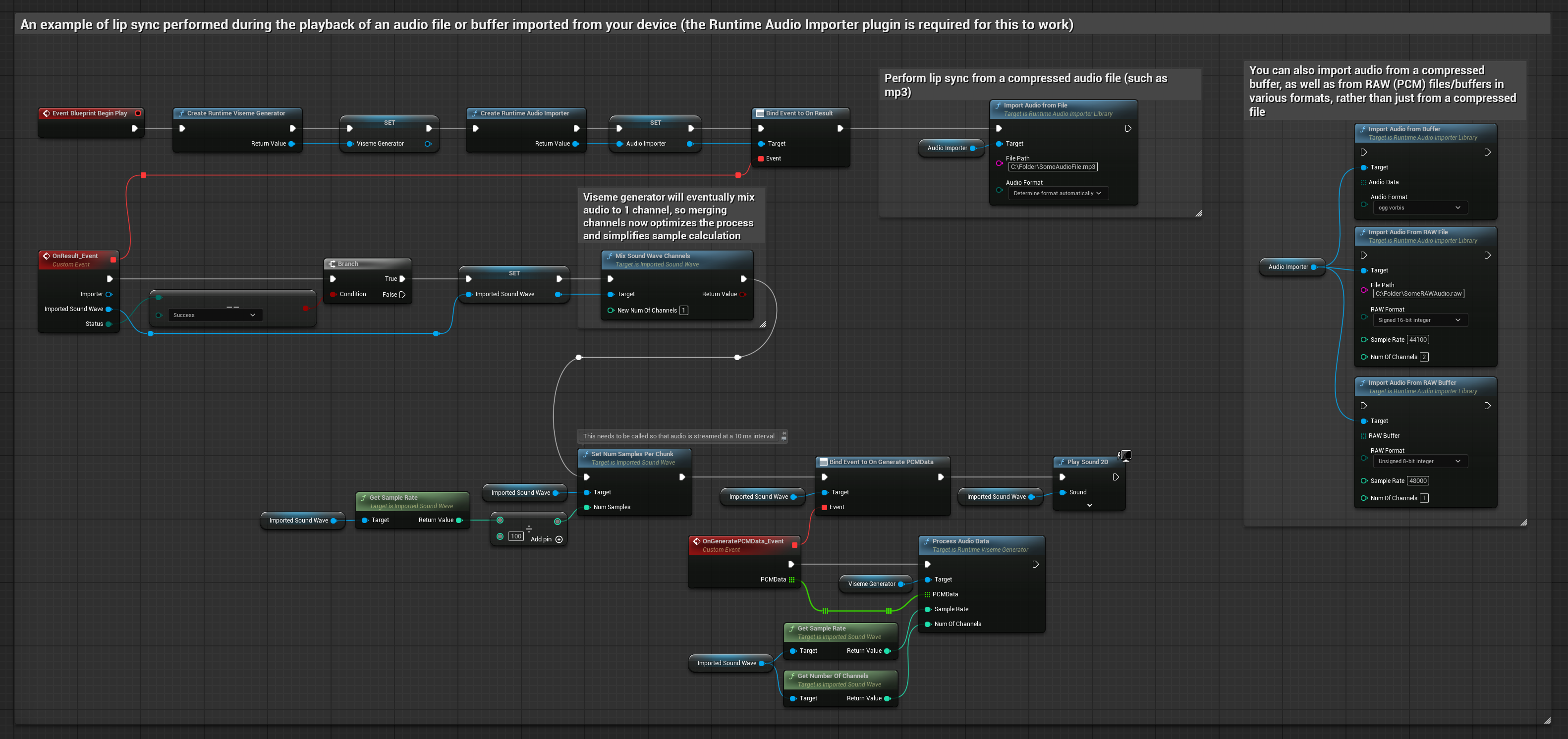
Realistic Model, Standard Model के समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
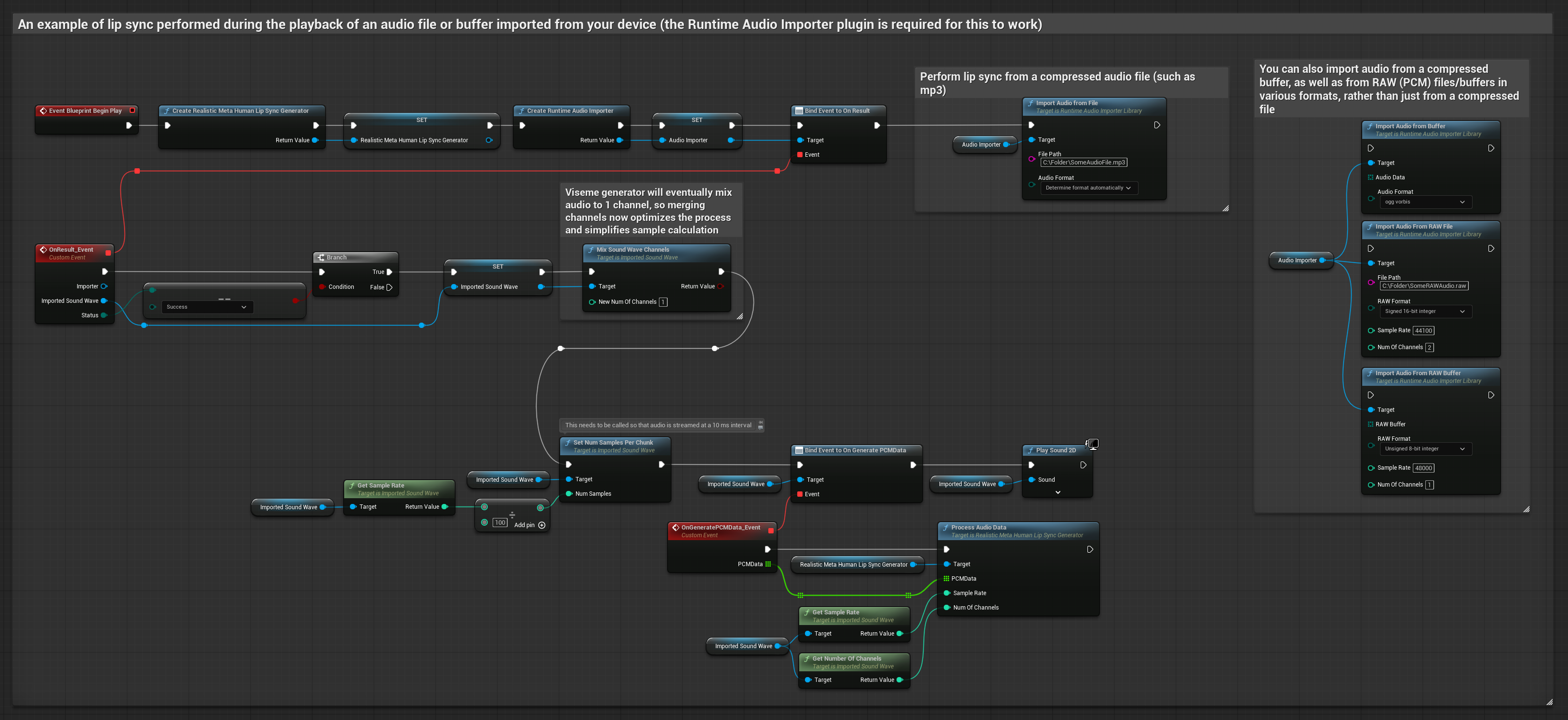
Mood-Enabled Model समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
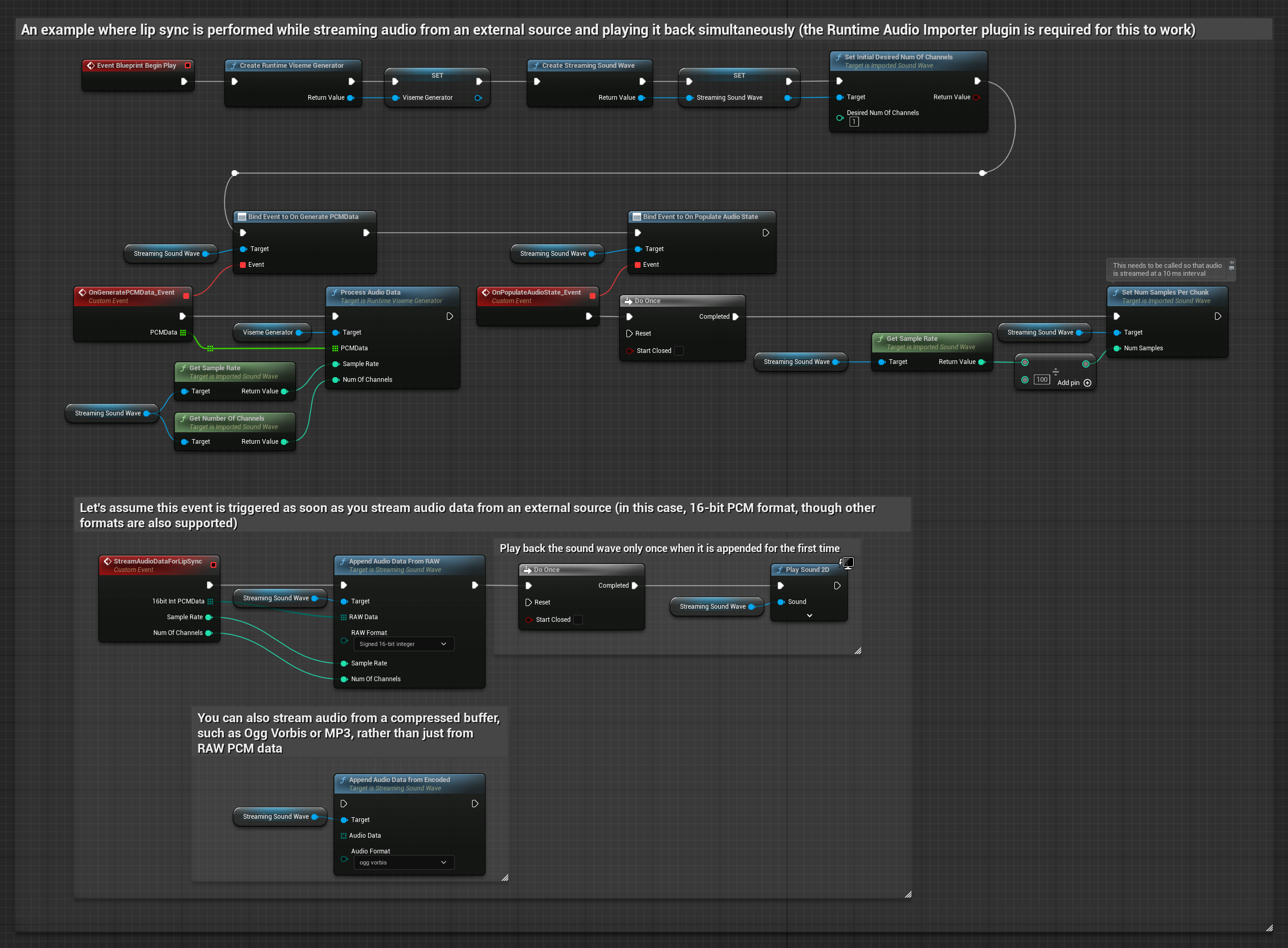
स्ट्रीमिंग ऑडियो डेटा के लिए, आपको चाहिए:
- Standard Model
- Realistic Model
- Mood-Enabled Realistic Model
- फ्लोट PCM प्रारूप में ऑडियो डेटा (फ़्लोटिंग-पॉइंट नमूनों की एक सरणी) आपके स्ट्रीमिंग स्रोत से उपलब्ध (या अधिक प्रारूपों का समर्थन करने के लिए Runtime Audio Importer का उपयोग करें)
- सैंपल दर और चैनलों की संख्या
- जैसे ही ऑडियो चंक उपलब्ध होते हैं, इन पैरामीटर्स के साथ अपने Runtime Viseme Generator से
ProcessAudioDataको कॉल करें
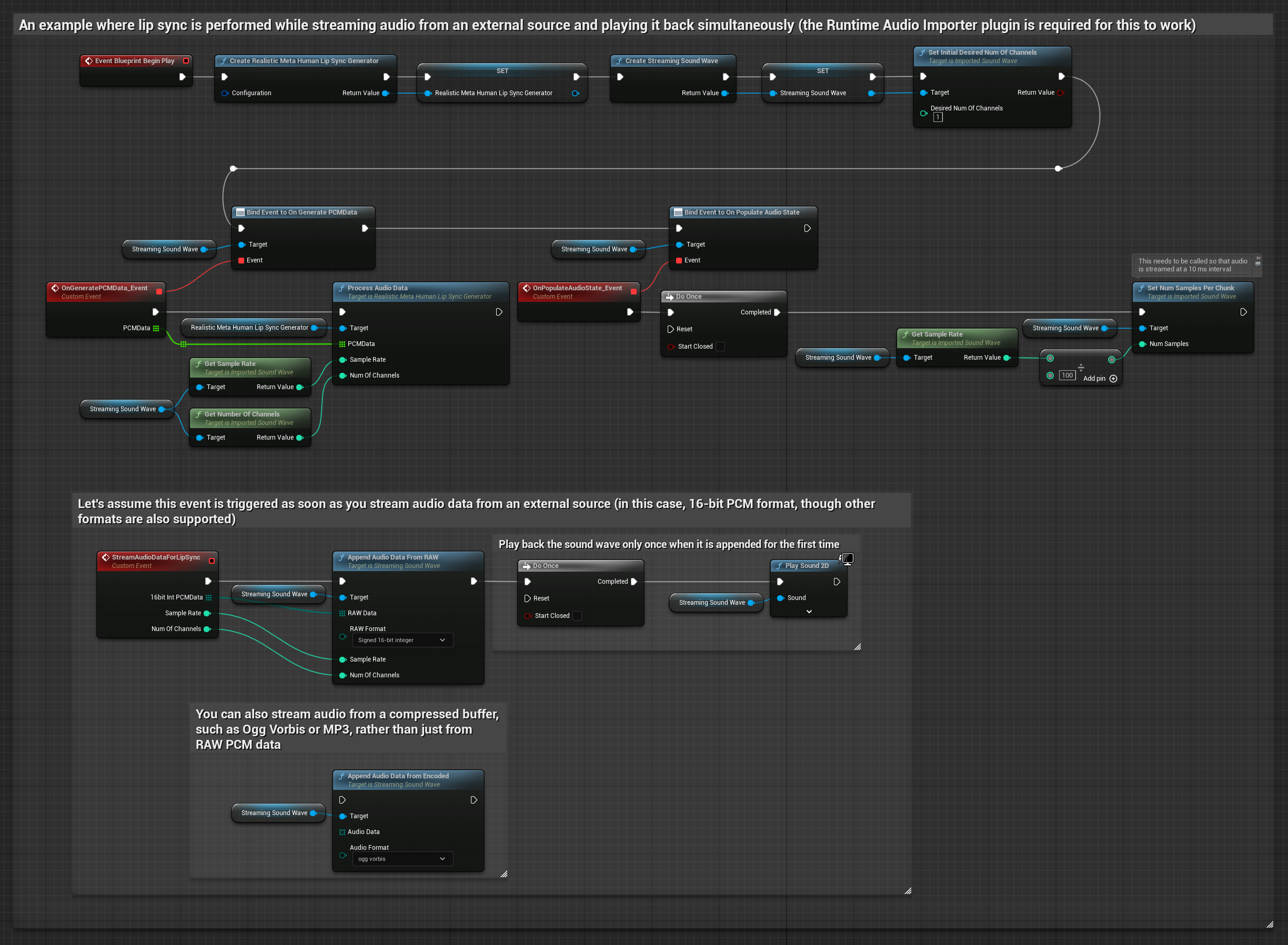
Realistic Model, Standard Model के समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन VisemeGenerator के बजाय RealisticLipSyncGenerator वेरिएबल के साथ।
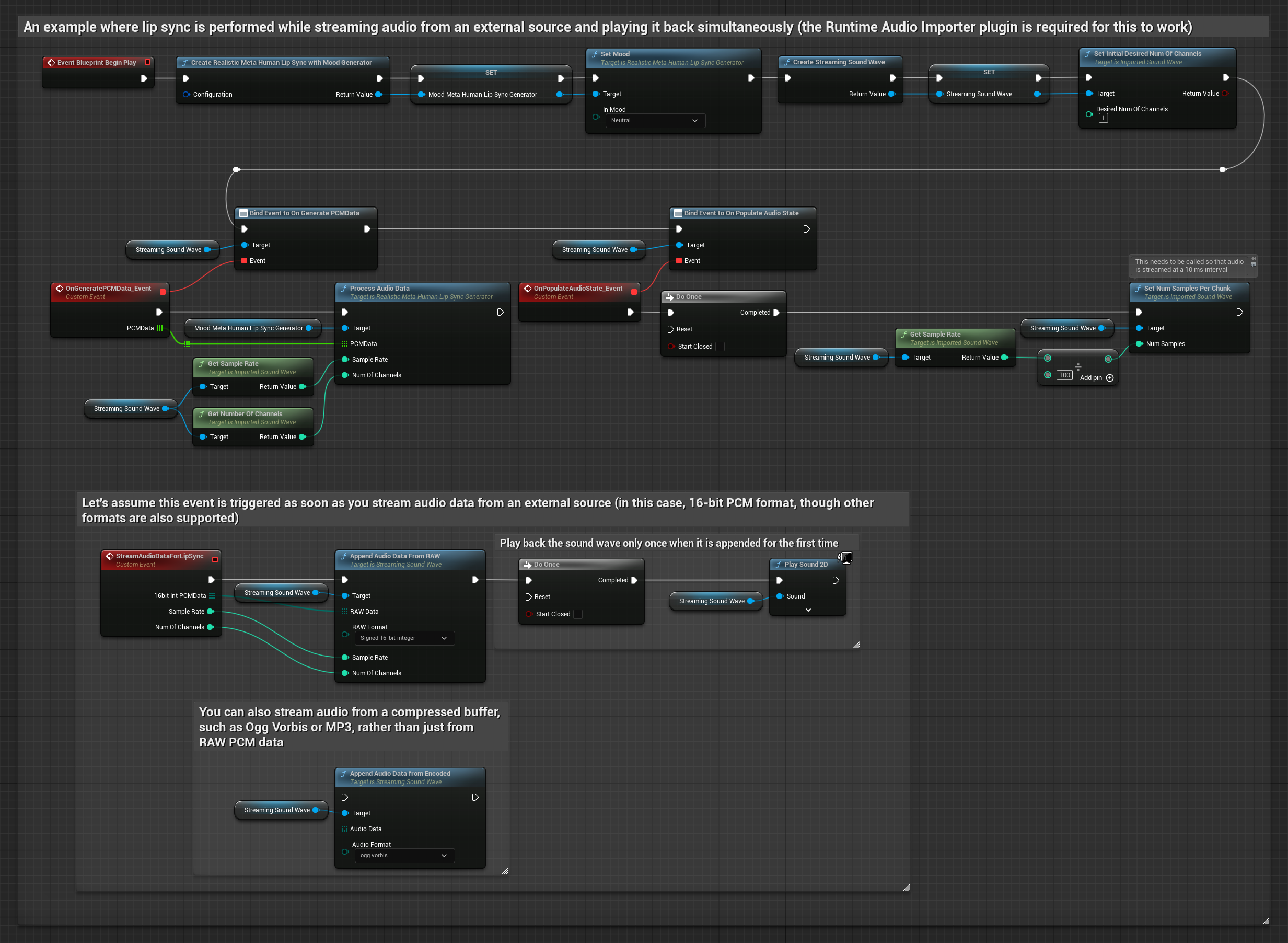
Mood-Enabled Model समान ऑडियो प्रोसेसिंग वर्कफ़्लो का उपयोग करता है, लेकिन MoodMetaHumanLipSyncGenerator वेरिएबल और अतिरिक्त मूड कॉन्फ़िगरेशन क्षमताओं के साथ।
नोट: स्ट्रीमिंग ऑडियो स्रोतों का उपयोग करते समय, विकृत प्लेबैक से बचने के लिए ऑडियो प्लेबैक टाइमिंग को उचित रूप से प्रबंधित करना सुनिश्चित करें। अधिक जानकारी के लिए Streaming Sound Wave दस्तावेज़ीकरण देखें।
प्रसंस्करण प्रदर्शन युक्तियाँ
-
चंक आकार:
ProcessingChunkSizeकॉन्फ़िगरेशन विकल्प को बढ़ाना (जैसे 320, 480, या 640 नमूनों तक) गुणवत्ता या प्रतिक्रियाशीलता पर न्यूनतम प्रभाव के साथ विलंबता में उल्लेखनीय सुधार कर सकता है। -
मॉडल प्रकार: Realistic मॉडल का उपयोग करते समय, अत्यधिक अनुकूलित मॉडल प्रकार (डिफ़ॉल्ट रूप से चयनित) पर स्विच करने से प्रदर्शन में सुधार हो सकता है। ध्यान दें कि मूल मॉडल थोड़ी बेहतर गुणवत्ता उत्पन्न कर सकता है, विशेष रूप से शोर वाले ऑडियो के साथ।
-
बफ़र प्रबंधन: मूड-सक्षम मॉडल ऑडियो को 320-नमूना फ़्रेम (16kHz पर 20ms) में संसाधित करता है। इष्टतम प्रदर्शन के लिए सुनिश्चित करें कि आपका ऑडियो इनपुट टाइमिंग इसके साथ संरेखित हो।
-
जनरेटर पुनर्निर्माण: रियलिस्टिक मॉडल के साथ विश्वसनीय संचालन के लिए, निष्क्रियता की अवधि के बाद नया ऑडियो डेटा फीड करना चाहते हैं तो हर बार जनरेटर को पुनः बनाएं।
अगले कदम
एक बार जब आपका ऑडियो प्रोसेसिंग सेटअप हो जाए, तो आप यह करना चाह सकते हैं:
- अपने लिप सिंक व्यवहार को ठीक-ट्यून करने के लिए कॉन्फ़िगरेशन विकल्पों के बारे में जानें
- बेहतर अभिव्यक्ति के लिए हँसी एनीमेशन जोड़ें
- कॉन्फ़िगरेशन गाइड में वर्णित लेयरिंग तकनीकों का उपयोग करके मौजूदा चेहरे के एनीमेशन के साथ लिप सिंक को संयोजित करें