प्लगइन का उपयोग कैसे करें
Runtime Speech Recognizerर प्लगइन इनकमिंग ऑडियो डेटा से शब्दों को पहचानने के लिए डिज़ाइन किया गया है। यह इंजन के साथ काम करने के लिए whisper.cpp के थोड़े संशोधित संस्करण का उपयोग करता है। प्लगइन का उपयोग करने के लिए, इन चरणों का पालन करें:
एडिटर साइड
- अपने प्रोजेक्ट के लिए उपयुक्त भाषा मॉडल का चयन करें जैसा कि यहाँ वर्णित है।
रनटाइम साइड
- एक स्पीच रिकग्नाइज़र बनाएं और आवश्यक पैरामीटर्स सेट करें (CreateSpeechRecognizer, पैरामीटर्स के लिए यहाँ देखें)।
- आवश्यक डेलिगेट्स से बाइंड करें (OnRecognitionFinished, OnRecognizedTextSegment और OnRecognitionError)।
- स्पीच रिकग्निशन शुरू करें (StartSpeechRecognition)।
- ऑडियो डेटा प्रोसेस करें और डेलिगेट्स से परिणामों की प्रतीक्षा करें (ProcessAudioData)।
- आवश्यकता पड़ने पर स्पीच रिकग्नाइज़र को रोकें (उदाहरण के लिए, OnRecognitionFinished ब्रॉडकास्ट के बाद)।
प्लगइन फ़्लोटिंग पॉइंट 32-बिट इंटरलीव्ड PCM फॉर्मेट में इनकमिंग ऑडियो का समर्थन करता है। जबकि यह Runtime Audio Importer के साथ अच्छी तरह से काम करता है, यह सीधे इस पर निर्भर नहीं करता है।
रिकग्निशन पैरामीटर्स
प्लगइन स्ट्रीमिंग और नॉन-स्ट्रीमिंग ऑडियो डेटा रिकग्निशन दोनों का समर्थन करता है। अपने विशिष्ट उपयोग के मामले के लिए रिकग्निशन पैरामीटर्स को समायोजित करने के लिए, SetStreamingDefaults या SetNonStreamingDefaults को कॉल करें। इसके अतिरिक्त, आपके पास व्यक्तिगत पैरामीटर्स जैसे थ्रेड्स की संख्या, स्टेप साइज़, क्या इनकमिंग भाषा को अंग्रेजी में अनुवाद करना है, और क्या पिछले ट्रांसक्रिप्शन का उपयोग करना है, को मैन्युअल रूप से सेट करने की लचीलापन है। उपलब्ध पैरामीटर्स की पूरी सूची के लिए रिकग्निशन पैरामीटर लिस्ट देखें।
प्रदर्शन में सुधार
कृपया प्लगइन के प्रदर्शन को अनुकूलित करने के तरीकों के लिए प्रदर्शन कैसे सुधारें सेक्शन देखें।
वॉयस एक्टिविटी डिटेक्शन (VAD)
ऑडियो इनपुट को प्रोसेस करते समय, विशेष रूप से स्ट्रीमिंग परिदृश्यों में, रिकग्नाइज़र तक पहुँचने से पहले खाली या शोर-मात्र ऑडियो सेगमेंट्स को फ़िल्टर करने के लिए वॉयस एक्टिविटी डिटेक्शन (VAD) का उपयोग करने की सिफारिश की जाती है। इस फ़िल्टरिंग को Runtime Audio Importer प्लगइन का उपयोग करके कैप्चर करने योग्य साउंड वेव साइड पर सक्षम किया जा सकता है, जो भाषा मॉडल्स को हॉलुसिनेट करने - शोर में पैटर्न ढूंढने और गलत ट्रांसक्रिप्शन उत्पन्न करने के प्रयास से रोकने में मदद करता है।
इष्टतम स्पीच रिकग्निशन परिणामों के लिए, हम सिलेरो VAD प्रोवाइडर का उपयोग करने की सिफारिश करते हैं जो उत्कृष्ट शोर सहनशीलता और अधिक सटीक स्पीच डिटेक्शन प्रदान करता है। सिलेरो VAD Runtime Audio Importer प्लगइन के एक्सटेंशन के रूप में उपलब्ध है। VAD कॉन्फ़िगरेशन के विस्तृत निर्देशों के लिए, वॉयस एक्टिविटी डिटेक्शन डॉक्युमेंटेशन देखें।
नीचे दिए गए उदाहरणों में कॉपी करने योग्य नोड्स संगतता कारणों से डिफ़ॉल्ट VAD प्रदाता का उपयोग करते हैं। पहचान सटीकता बढ़ाने के लिए, आप आसानी से Silero VAD पर स्विच कर सकते हैं:
- Silero VAD Extension section में वर्णित के अनुसार Silero VAD एक्सटेंशन इंस्टॉल करके
- Toggle VAD नोड के साथ VAD सक्षम करने के बाद, एक Set VAD Provider नोड जोड़ें और ड्रॉपडाउन से "Silero" चुनें
प्लगइन के साथ शामिल डेमो प्रोजेक्ट में, VAD डिफ़ॉल्ट रूप से सक्षम है। आप Demo Project पर डेमो कार्यान्वयन के बारे में अधिक जानकारी प्राप्त कर सकते हैं।
उदाहरण
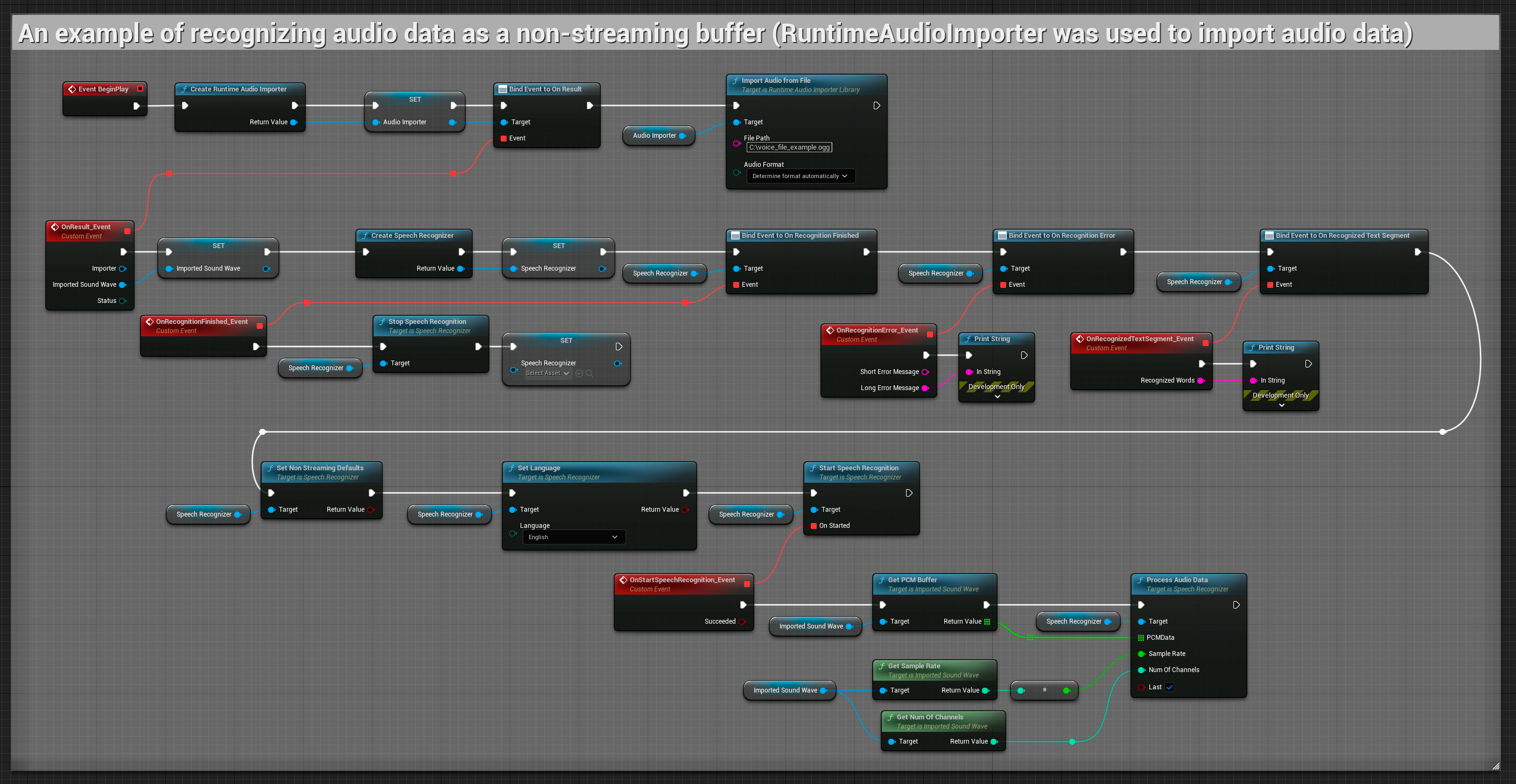
ये उदाहरण दर्शाते हैं कि कैसे Runtime Speech Recognizer प्लगइन का उपयोग स्ट्रीमिंग और नॉन-स्ट्रीमिंग ऑडियो इनपुट दोनों के साथ किया जाए, उदाहरण के रूप में ऑडियो डेटा प्राप्त करने के लिए Runtime Audio Importer का उपयोग करते हुए। कृपया ध्यान दें कि उदाहरणों में दिखाए गए ऑडियो आयात सुविधाओं के समान सेट (जैसे कैप्चर करने योग्य साउंड वेव और ImportAudioFromFile) तक पहुंचने के लिए RuntimeAudioImporter का अलग से डाउनलोड करना आवश्यक है। ये उदाहरण केवल मूल अवधारणा को दर्शाने के लिए हैं और इनमें त्रुटि प्रबंधन शामिल नहीं है।
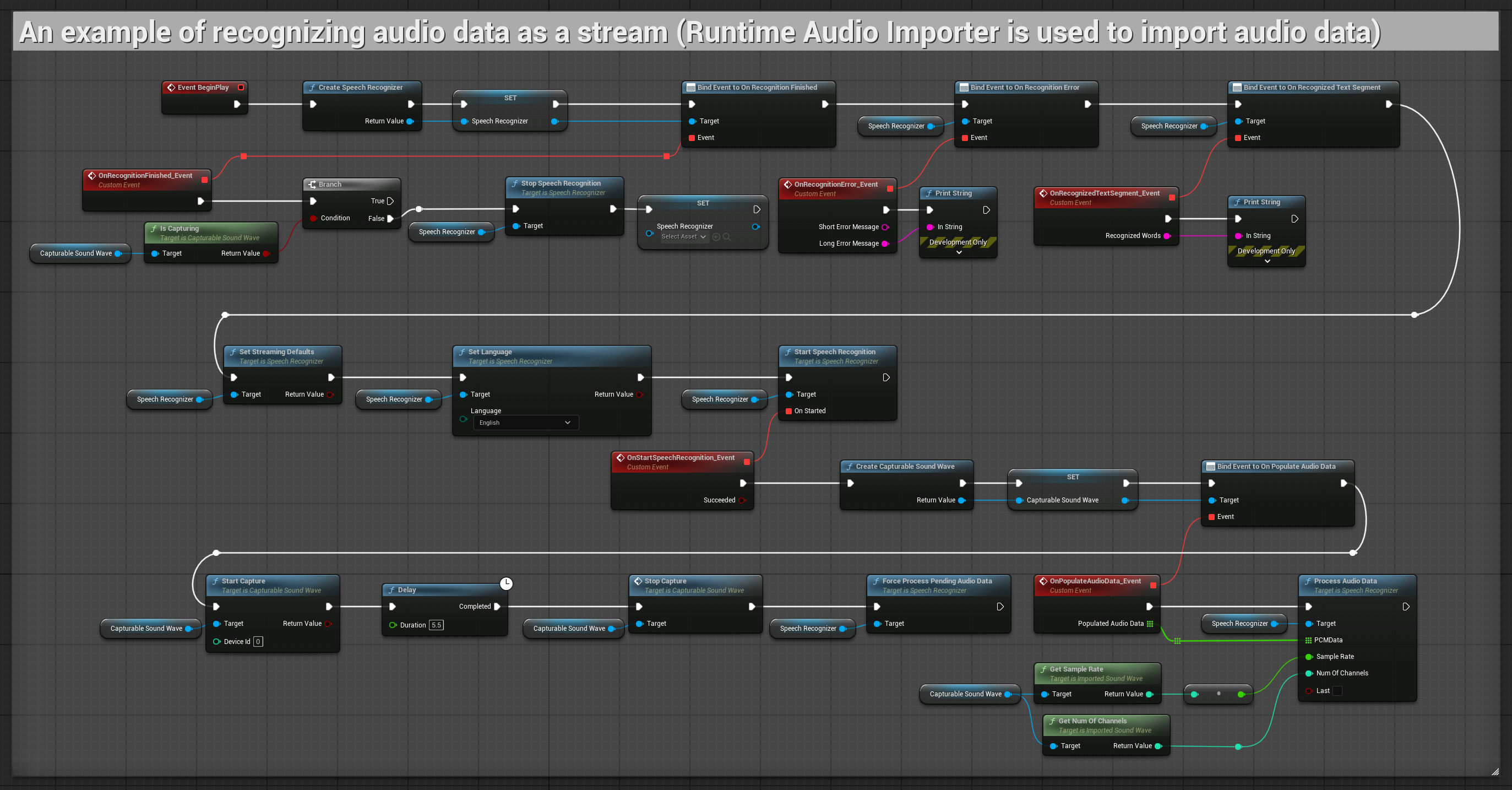
स्ट्रीमिंग ऑडियो इनपुट उदाहरण
नोट: UE 5.3 और अन्य संस्करणों में, Blueprints को कॉपी करने के बाद आपको नोड्स गायब होने की समस्या का सामना करना पड़ सकता है। यह इंजन संस्करणों के बीच नोड सीरियलाइज़ेशन में अंतर के कारण हो सकता है। हमेशा सुनिश्चित करें कि आपके कार्यान्वयन में सभी नोड्स ठीक से जुड़े हुए हैं।
1. बेसिक स्ट्रीमिंग पहचान
यह उदाहरण माइक्रोफोन से ऑडियो डेटा को Capturable sound wave का उपयोग करके स्ट्रीम के रूप में कैप्चर करने और इसे स्पीच रिकग्नाइज़र को पास करने के लिए बेसिक सेटअप प्रदर्शित करता है। यह लगभग 5 सेकंड के लिए भाषण रिकॉर्ड करता है और फिर पहचान को प्रोसेस करता है, जिससे यह त्वरित परीक्षणों और सरल कार्यान्वयन के लिए उपयुक्त होता है। कॉपी करने योग्य नोड्स.
इस सेटअप की मुख्य विशेषताएं:
- निश्चित 5-सेकंड रिकॉर्डिंग अवधि
- सरल एक-शॉट पहचान
- न्यूनतम सेटअप आवश्यकताएं
- परीक्षण और प्रोटोटाइपिंग के लिए आदर्श
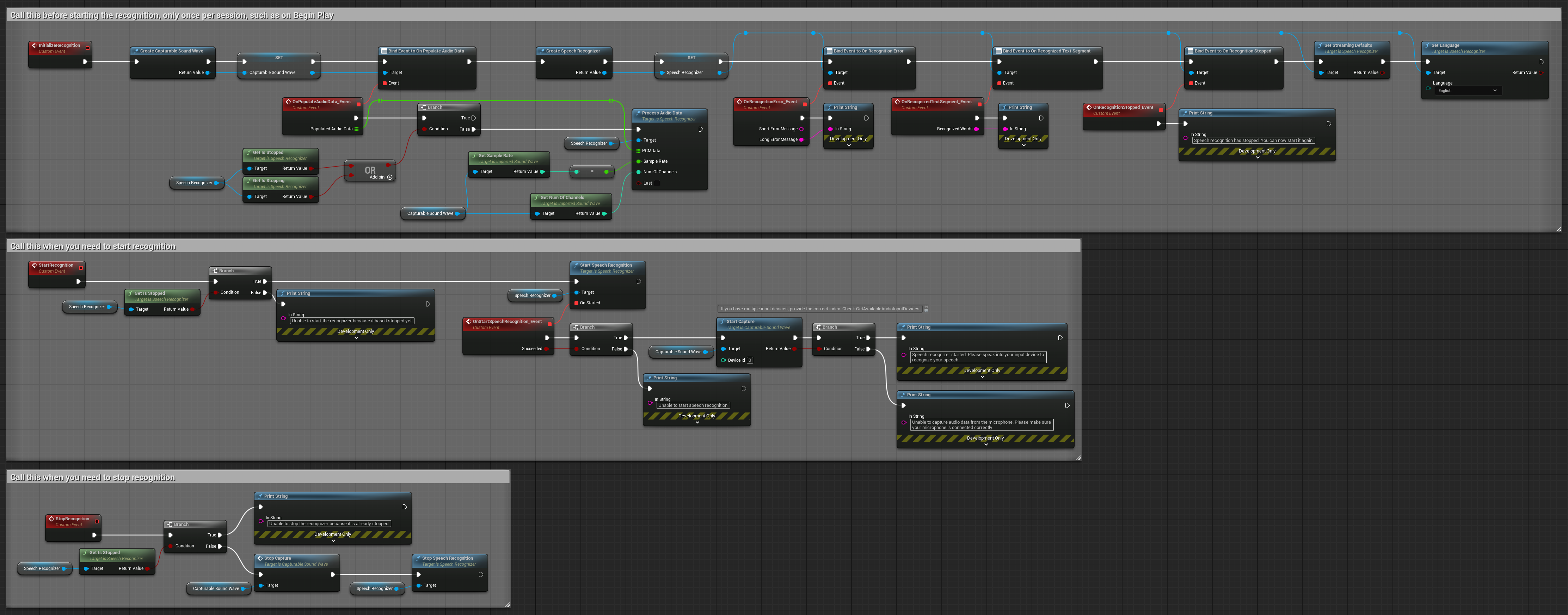
2. नियंत्रित स्ट्रीमिंग पहचान
यह उदाहरण पहचान प्रक्रिया पर मैनुअल नियंत्रण जोड़कर बेसिक स्ट्रीमिंग सेटअप का विस्तार करता है। यह आपको इच्छानुसार पहचान शुरू और रोकने की अनुमति देता है, जिससे यह उन परिदृश्यों के लिए उपयुक्त होता है जहाँ आपको सटीक नियंत्रण की आवश्यकता होती है कि पहचान कब होती है। कॉपी करने योग्य नोड्स.
इस सेटअप की मुख्य विशेषताएं:
- मैन्युअल स्टार्ट/स्टॉप कंट्रोल
- निरंतर पहचान क्षमता
- लचीला रिकॉर्डिंग अवधि
- इंटरैक्टिव एप्लिकेशन के लिए उपयुक्त
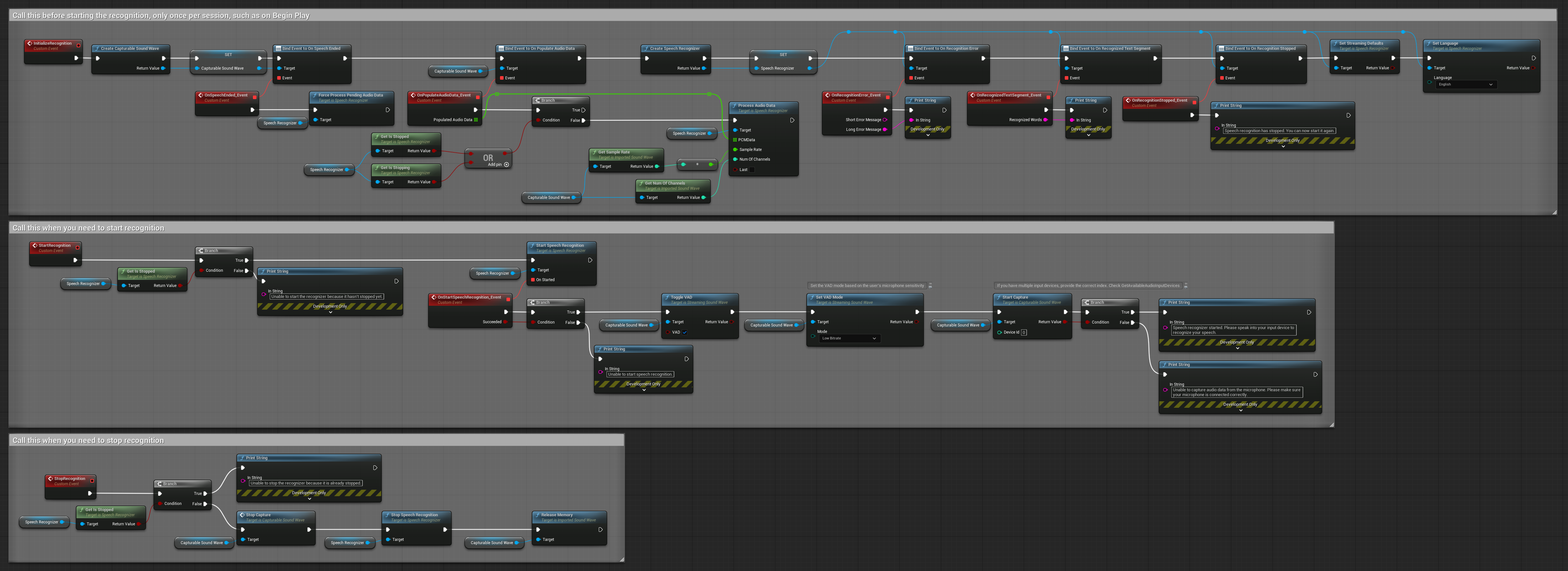
3. वॉयस-एक्टिवेटेड कमांड रिकग्निशन
यह उदाहरण कमांड रिकग्निशन परिदृश्यों के लिए अनुकूलित है। यह स्ट्रीमिंग रिकग्निशन को वॉयस एक्टिविटी डिटेक्शन (VAD) के साथ जोड़ता है ताकि उपयोगकर्ता के बोलना बंद करने पर स्वचालित रूप से स्पीच को प्रोसेस किया जा सके। रिकग्नाइज़र संचित स्पीच को तभी प्रोसेस करना शुरू करता है जब साइलेंस डिटेक्ट होती है, जिससे यह कमांड-आधारित इंटरफेस के लिए आदर्श बनता है। कॉपी करने योग्य नोड्स.
इस सेटअप की मुख्य विशेषताएं:
- मैन्युअल स्टार्ट/स्टॉप कंट्रोल
- स्पीच सेगमेंट का पता लगाने के लिए वॉयस एक्टिविटी डिटेक्शन (VAD) सक्षम
- साइलेंस डिटेक्ट होने पर स्वचालित रिकग्निशन ट्रिगरिंग
- छोटी कमांड रिकग्निशन के लिए इष्टतम
- केवल वास्तविक स्पीच को पहचानकर प्रोसेसिंग ओवरहेड कम किया गया
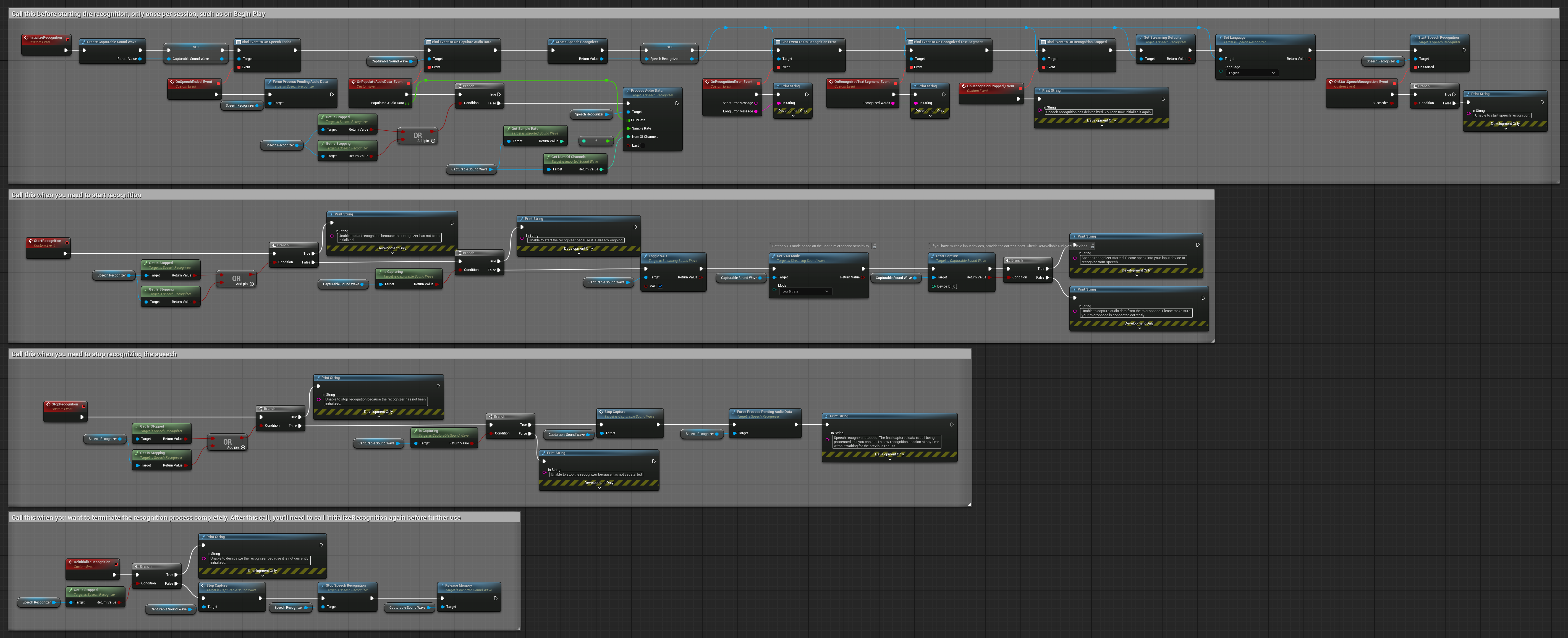
4. फाइनल बफर प्रोसेसिंग के साथ ऑटो-इनिशियलाइज़िंग वॉयस रिकग्निशन
यह उदाहरण वॉयस-एक्टिवेटेड रिकग्निशन दृष्टिकोण का एक और रूपांतर है जिसमें अलग लाइफसाइकल हैंडलिंग है। यह इनिशियलाइज़ेशन के दौरान रिकग्नाइज़र को स्वचालित रूप से शुरू करता है और डीइनिशियलाइज़ेशन के दौरान इसे रोकता है। एक प्रमुख विशेषता यह है कि यह रिकग्नाइज़र को रोकने से पहले अंतिम संचित ऑडियो बफर को प्रोसेस करता है, यह सुनिश्चित करते हुए कि जब उपयोगकर्ता रिकग्निशन प्रक्रिया को समाप्त करना चाहता है तो कोई स्पीच डेटा खो न जाए। यह सेटअप विशेष रूप से उन एप्लिकेशन के लिए उपयोगी है जहां आपको मिड-स्पीच में रुकने पर भी उपयोगकर्ता के पूर्ण उच्चारण को कैप्चर करने की आवश्यकता होती है। कॉपी करने योग्य नोड्स.
इस सेटअप की मुख्य विशेषताएं:
- इनिशियलाइज़ेशन पर रिकग्नाइज़र को स्वचालित रूप से शुरू करता है
- डीइनिशियलाइज़ेशन पर रिकग्नाइज़र को स्वचालित रूप से रोकता है
- पूरी तरह से रोकने से पहले अंतिम ऑडियो बफर को प्रोसेस करता है
- कुशल रिकग्निशन के लिए वॉयस एक्टिविटी डिटेक्शन (VAD) का उपयोग करता है
- रोकते समय कोई स्पीच डेटा न खोने की गारंटी देता है
नॉन-स्ट्रीमिंग ऑडियो इनपुट
यह उदाहरण ऑडियो डेटा को इम्पोर्टेड साउंड वेव में इम्पोर्ट करता है और पूर्ण ऑडियो डेटा को एक बार इम्पोर्ट हो जाने के बाद पहचानता है। कॉपी करने योग्य नोड्स.