पहचान पैरामीटर सूची
ये पैरामीटर केवल तभी सेट किए जा सकते हैं जब रिकग्नाइज़र चल नहीं रहा हो।
यह Whisper में उपलब्ध पैरामीटर की संपूर्ण सूची नहीं है। केवल सबसे महत्वपूर्ण पैरामीटर यहाँ प्रदर्शित किए गए हैं। यदि आवश्यक हो, तो इस सूची को अपडेट किया जाएगा।
पहचान पैरामीटर सेट करें
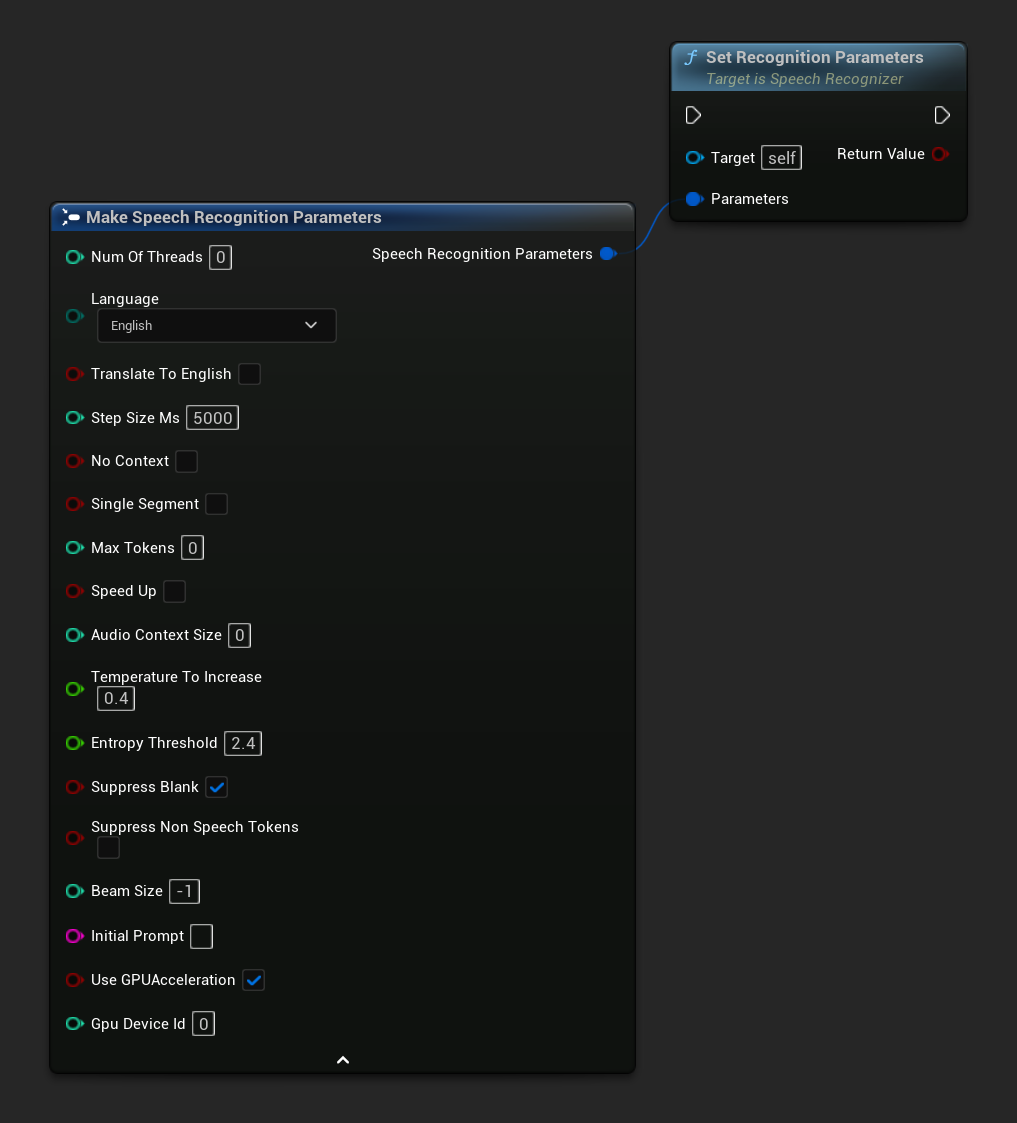
स्पीच रिकग्निशन के लिए पैरामीटर सेट करता है। यदि आप केवल विशिष्ट पैरामीटर बदलना चाहते हैं, तो व्यक्तिगत सेटर फ़ंक्शन का उपयोग करने पर विचार करें।
स्ट्रीमिंग डिफ़ॉल्ट सेट करें
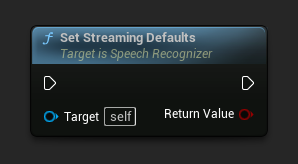
स्ट्रीमिंग स्पीच रिकग्निशन के लिए उपयुक्त डिफ़ॉल्ट पैरामीटर सेट करता है।
यह फ़ंक्शन पहले से लागू किए गए सभी पैरामीटर को ओवरराइट कर देता है। यदि आपको स्ट्रीमिंग डिफ़ॉल्ट को आधार कॉन्फ़िगरेशन के रूप में उपयोग करने की आवश्यकता है, तो सुनिश्चित करें कि आप अपने कस्टम पैरामीटर सेट करने से पहले इसे कॉल करें।
नॉन-स्ट्रीमिंग डिफ़ॉल्ट सेट करें
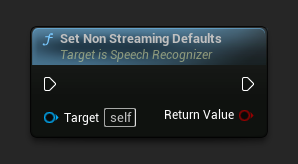
नॉन-स्ट्रीमिंग स्पीच रिकग्निशन के लिए उपयुक्त डिफ़ॉल्ट पैरामीटर सेट करता है।
यह फ़ंक्शन पहले से लागू किए गए सभी पैरामीटर को ओवरराइट कर देता है। यदि आपको नॉन-स्ट्रीमिंग डिफ़ॉल्ट को आधार कॉन्फ़िगरेशन के रूप में उपयोग करने की आवश्यकता है, तो सुनिश्चित करें कि आप अपने कस्टम पैरामीटर सेट करने से पहले इसे कॉल करें।
थ्रेड्स की संख्या सेट करें
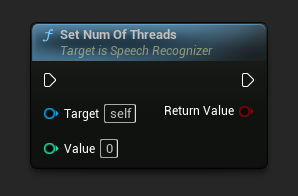
स्पीच रिकग्निशन के लिए उपयोग करने के लिए थ्रेड्स की संख्या सेट करता है। कोर की संख्या का उपयोग करने के लिए इस मान को 0 पर सेट करें।
भाषा सेट करें
स्पीच रिकग्निशन के लिए उपयोग करने के लिए भाषा सेट करता है। यह एडिटर सेटिंग्स में चयनित भाषा मॉडल द्वारा समर्थित होनी चाहिए।
भाषा को ऑटो पर सेट करने से पहचान की सटीकता और प्रदर्शन कम हो जाएगा।
पता चली भाषा प्राप्त करें
अंतिम पहचान से पता चली भाषा प्राप्त करता है। भाषा को एक एनम मान के रूप में लौटाता है।
नोट: यह फ़ंक्शन केवल तभी काम करता है जब पहचान की जा चुकी हो। यह ऑटो लौटाता है यदि भाषा का पता लगाना विफल रहा या नहीं किया गया। यह विशेष रूप से उपयोगी है जब ऑटो भाषा पहचान का उपयोग करके यह पहचानने के लिए कि वास्तव में कौन सी भाषा पहचानी गई थी।
भाषा कोड प्राप्त करें
एक भाषा एनम मान को उसके भाषा कोड स्ट्रिंग में परिवर्तित करता है (उदाहरण के लिए, En -> "en", Fr -> "fr", De -> "de")।
भाषा का पूरा नाम प्राप्त करें
एक भाषा एनम मान को उसके पूरे भाषा नाम में परिवर्तित करता है (उदाहरण के लिए, En -> "English", Fr -> "French", De -> "German")।
अंग्रेजी में अनुवाद करने के लिए सेट करें
![]()
सेट करता है कि क्या पहचाने गए शब्दों का अंग्रेजी में अनुवाद करना है। यदि सही है, तो भाषा मॉडल बहुभाषी होना चाहिए।
स्टेप साइज़ सेट करें
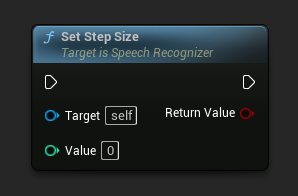
मिलीसेकंड में स्टेप साइज़ सेट करता है। यह निर्धारित करता है कि पहचान के लिए ऑडियो डेटा कितनी बार भेजना है। डिफ़ॉल्ट मान 5000 ms (5 सेकंड) है।
नो कॉन्टेक्स्ट सेट करें
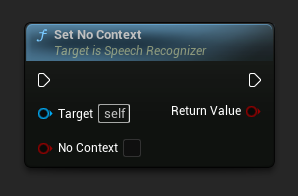
सेट करता है कि क्या डिकोडर के लिए प्रारंभिक प्रॉम्प्ट के रूप में पिछले ट्रांसक्रिप्शन (यदि कोई हो) का उपयोग करना है।
सिंगल सेगमेंट सेट करें
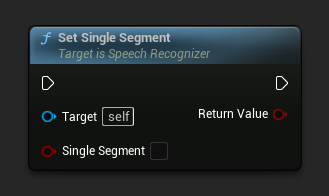
सेट करता है कि क्या सिंगल सेगमेंट आउटपुट को फोर्स करना है (स्ट्रीमिंग के लिए उपयोगी)।
मैक्स टोकन सेट करें
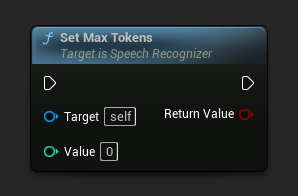
प्रति टेक्स्ट सेगमेंट टोकन की अधिकतम संख्या सेट करता है। कोई सीमा नहीं के लिए 0 का उपयोग करें।
स्पीड अप सेट करें
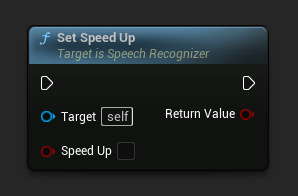
सेट करता है कि क्या फेज वोकोडर का उपयोग करके पहचान को 2x तेज करना है। आउटपुट की गुणवत्ता में सुधार करने के लिए इसे false के रूप में सेट करें।
ऑडियो कॉन्टेक्स्ट साइज़ सेट करें
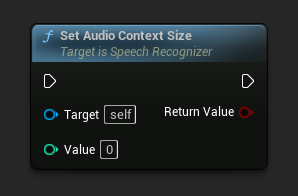
ऑडियो कॉन्टेक्स्ट का आकार सेट करता है। आउटपुट की गुणवत्ता में सुधार करने के लिए इसे 0 के रूप में सेट करें।
टेम्परेचर टू इंक्रीज़ सेट करें
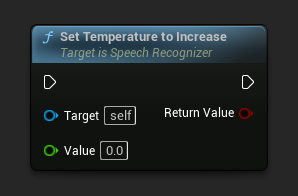
टेम्परेचर सेट करता है जिसे बढ़ाना है जब डिकोडिंग नीचे दी गई किसी भी थ्रेशोल्ड को पूरा करने में विफल रहने पर फॉलबैक होता है।
एन्ट्रॉपी थ्रेशोल्ड सेट करें
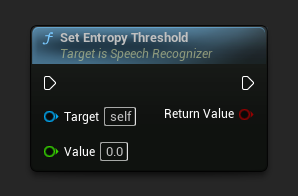
एन्ट्रॉपी थ्रेशोल्ड सेट करता है। यदि कम्प्रेशन अनुपात इस मान से अधिक है, तो डिकोडिंग को विफल मानें। OpenAI के "compression_ratio_threshold" के समान
सप्रेस ब्लैंक सेट करें
![]()
सेट करता है कि क्या आउटपुट में दिखाई देने वाले ब्लैंक को दबाना है।
सप्रेस नॉन स्पीच टोकन सेट करें
सेट करता है कि क्या आउटपुट में दिखाई देने वाले नॉन स्पीच टोकन को दबाना है।
बीम साइज़ सेट करें
बीम सर्च में बीम की संख्या सेट करें। केवल तभी लागू होता है जब तापमान शून्य हो।
इनिशियल प्रॉम्प्ट सेट करें
पहली विंडो के लिए प्रारंभिक प्रॉम्प्ट सेट करता है। इसका उपयोग पहचान के लिए संदर्भ प्रदान करने के लिए किया जा सकता है ताकि शब्दों को सही ढंग से भविष्यवाणी करने की संभावना अधिक हो, उदाहरण के लिए, कस्टम शब्दावली या प्रॉपर नाउन।
प्रभावी प्रॉम्प्टिंग रणनीतियों के अधिक विवरण के लिए, Whisper Prompting Guide देखें।
GPU एक्सेलेरेशन सेट करें
सेट करता है कि क्या स्पीच रिकग्निशन के लिए GPU एक्सेलेरेशन का उपयोग करना है (फिलहाल केवल Windows पर लागू)।
GPU डिवाइस ID सेट करें
स्पीच रिकग्निशन के लिए उपयोग करने के लिए GPU डिवाइस ID सेट करता है। डिफ़ॉल्ट मान 0 है। यह उन सिस्टम के लिए उपयोगी है जिनमें कई GPU हैं ताकि यह निर्दिष्ट किया जा सके कि पहचान प्रक्रिया के लिए किस GPU का उपयोग किया जाना चाहिए। यदि निर्दिष्ट GPU डिवाइस ID अमान्य है, तो इसके बजाय पहला उपलब्ध GPU डिवाइस इंडेक्स उपयोग किया जाएगा।