प्लगइन का उपयोग कैसे करें
Runtime Text To Speech प्लगइन डाउनलोड करने योग्य आवाज़ मॉडल का उपयोग करके पाठ को वाक् में संश्लेषित करता है। ये मॉडल संपादक के भीतर प्लगइन सेटिंग्स में प्रबंधित किए जाते हैं, डाउनलोड किए जाते हैं, और रनटाइम उपयोग के लिए पैकेज किए जाते हैं। आरंभ करने के लिए नीचे दिए गए चरणों का पालन करें।
संपादक पक्ष
अपने प्रोजेक्ट के लिए उपयुक्त आवाज़ मॉडल यहाँ वर्णित अनुसार डाउनलोड करें। आप एक ही समय में कई आवाज़ मॉडल डाउनलोड कर सकते हैं।
रनटाइम पक्ष
सिंथेसाइज़र बनाने के लिए CreateRuntimeTextToSpeech फ़ंक्शन का उपयोग करें। सुनिश्चित करें कि आप इसका संदर्भ बनाए रखते हैं (जैसे ब्लूप्रिंट्स में एक अलग वेरिएबल या C++ में UPROPERTY के रूप में) ताकि यह गार्बेज कलेक्ट न हो जाए।
- Blueprint
- C++
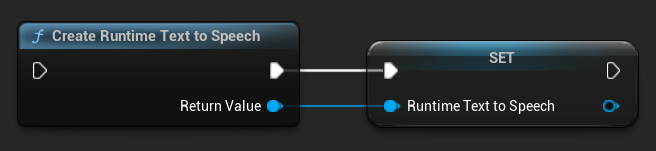
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
भाषण संश्लेषण
प्लगइन टेक्स्ट-टू-स्पीच संश्लेषण के दो मोड प्रदान करता है:
- नियमित टेक्स्ट-टू-स्पीच: पूरे टेक्स्ट को संश्लेषित करता है और पूरा होने पर संपूर्ण ऑडियो लौटाता है
- स्ट्रीमिंग टेक्स्ट-टू-स्पीच: जैसे-जैसे ऑडियो चंक्स जनरेट होते हैं, उन्हें प्रदान करता है, जिससे रियल-टाइम प्रोसेसिंग संभव होती है
प्रत्येक मोड वॉइस मॉडल चयन के लिए दो विधियों का समर्थन करता है:
- नाम से: अपने नाम से एक वॉइस मॉडल चुनें (UE 5.4+ के लिए अनुशंसित)
- ऑब्जेक्ट द्वारा: सीधे संदर्भ द्वारा एक वॉइस मॉडल चुनें (UE 5.3 और पहले के लिए अनुशंसित)
नियमित टेक्स्ट-टू-स्पीच
नाम से
- Blueprint
- C++
Text To Speech (By Name) फ़ंक्शन UE 5.4 से शुरू होने वाले ब्लूप्रिंट्स में अधिक सुविधाजनक है। यह आपको डाउनलोड किए गए मॉडलों की ड्रॉपडाउन सूची से वॉइस मॉडल चुनने की अनुमति देता है। UE संस्करण 5.3 से नीचे में, यह ड्रॉपडाउन प्रकट नहीं होता है, इसलिए यदि आप पुराने संस्करण का उपयोग कर रहे हैं, तो आपको आवश्यक वॉइस मॉडल का चयन करने के लिए GetDownloadedVoiceModels द्वारा लौटाए गए वॉइस मॉडल्स की सरणी पर मैन्युअल रूप से पुनरावृति करनी होगी।
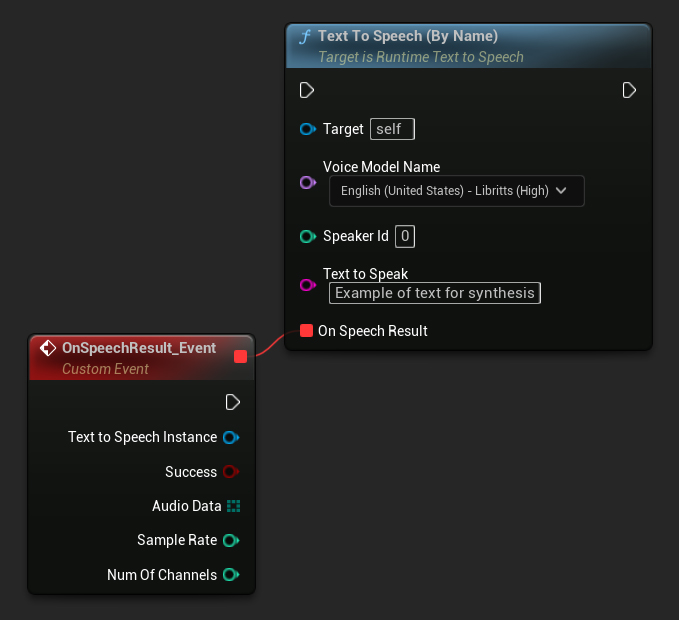
C++ में, ड्रॉपडाउन सूची की कमी के कारण वॉइस मॉडल का चयन थोड़ा अधिक जटिल हो सकता है। आप डाउनलोड किए गए वॉइस मॉडल के नाम पुनर्प्राप्त करने के लिए GetDownloadedVoiceModelNames फ़ंक्शन का उपयोग कर सकते हैं और आवश्यक एक का चयन कर सकते हैं। इसके बाद, आप चयनित वॉइस मॉडल नाम का उपयोग करके टेक्स्ट को संश्लेषित करने के लिए TextToSpeechByName फ़ंक्शन को कॉल कर सकते हैं।
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
ऑब्जेक्ट द्वारा
- Blueprint
- C++
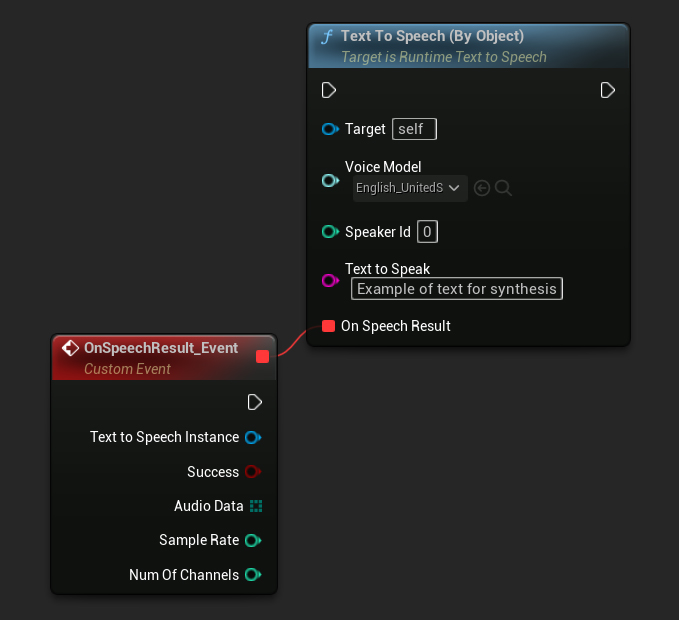
Text To Speech (By Object) फ़ंक्शन Unreal Engine के सभी संस्करणों में काम करता है लेकिन आवाज़ मॉडल को एसेट संदर्भों की ड्रॉपडाउन सूची के रूप में प्रस्तुत करता है, जो कम सहज है। यह विधि UE 5.3 और पहले के लिए उपयुक्त है, या यदि आपके प्रोजेक्ट को किसी भी कारण से आवाज़ मॉडल एसेट के सीधे संदर्भ की आवश्यकता है।
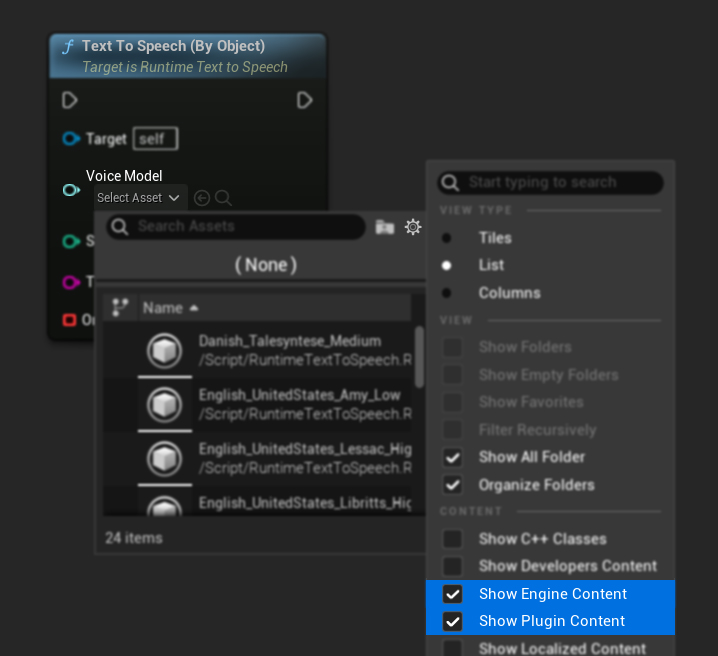
यदि आपने मॉडल डाउनलोड किए हैं लेकिन उन्हें नहीं देख सकते हैं, तो Voice Model ड्रॉपडाउन खोलें, सेटिंग्स (गियर आइकन) पर क्लिक करें, और मॉडल को दृश्यमान बनाने के लिए Show Plugin Content और Show Engine Content दोनों को सक्षम करें।
C++ में, ड्रॉपडाउन सूची की कमी के कारण आवाज़ मॉडल का चयन थोड़ा अधिक जटिल हो सकता है। आप डाउनलोड किए गए आवाज़ मॉडल के नाम पुनः प्राप्त करने के लिए GetDownloadedVoiceModelNames फ़ंक्शन का उपयोग कर सकते हैं और आवश्यक एक का चयन कर सकते हैं। फिर, आप आवाज़ मॉडल ऑब्जेक्ट प्राप्त करने के लिए GetVoiceModelFromName फ़ंक्शन का उपयोग कर सकते हैं और इसे टेक्स्ट को संश्लेषित करने के लिए TextToSpeechByObject फ़ंक्शन में पास कर सकते हैं।
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
स्ट्रीमिंग टेक्स्ट-टू-स्पीच
लंबे टेक्स्ट के लिए या जब आप ऑडियो डेटा को रियल-टाइम में प्रोसेस करना चाहते हैं क्योंकि यह जेनरेट हो रहा है, तो आप टेक्स्ट-टू-स्पीच फ़ंक्शंस के स्ट्रीमिंग वर्जन का उपयोग कर सकते हैं:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNamein C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjectin C++)
ये फ़ंक्शंस ऑडियो डेटा को चंक्स में प्रदान करते हैं क्योंकि वे जेनरेट होते हैं, जिससे पूरी सिंथेसिस पूरी होने का इंतज़ार किए बिना तुरंत प्रोसेसिंग की अनुमति मिलती है। यह विभिन्न एप्लिकेशन जैसे रियल-टाइम ऑडियो प्लेबैक, लाइव विज़ुअलाइज़ेशन, या किसी भी स्थिति के लिए उपयोगी है जहाँ आपको स्पीच डेटा को इंक्रीमेंटली प्रोसेस करने की आवश्यकता होती है।
नाम से स्ट्रीमिंग
- Blueprint
- C++
Streaming Text To Speech (By Name) फ़ंक्शन नियमित वर्जन की तरह ही काम करता है लेकिन On Speech Chunk डेलिगेट के माध्यम से ऑडियो को चंक्स में प्रदान करता है।
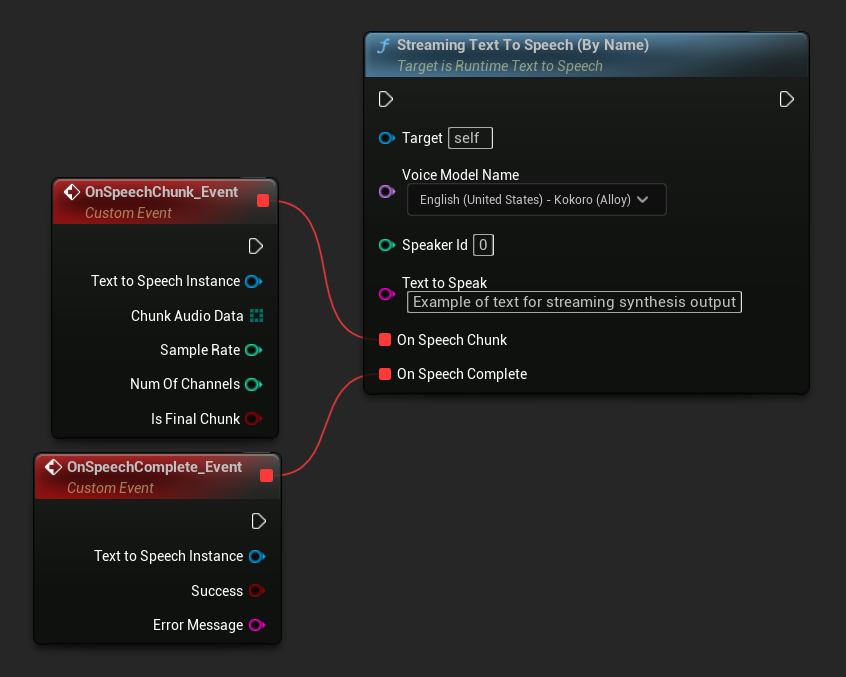
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
ऑब्जेक्ट द्वारा स्ट्रीमिंग
- Blueprint
- C++
स्ट्रीमिंग टेक्स्ट टू स्पीच (बाय ऑब्जेक्ट) फ़ंक्शन समान स्ट्रीमिंग कार्यक्षमता प्रदान करता है लेकिन एक वॉइस मॉडल ऑब्जेक्ट रेफरेंस लेता है।
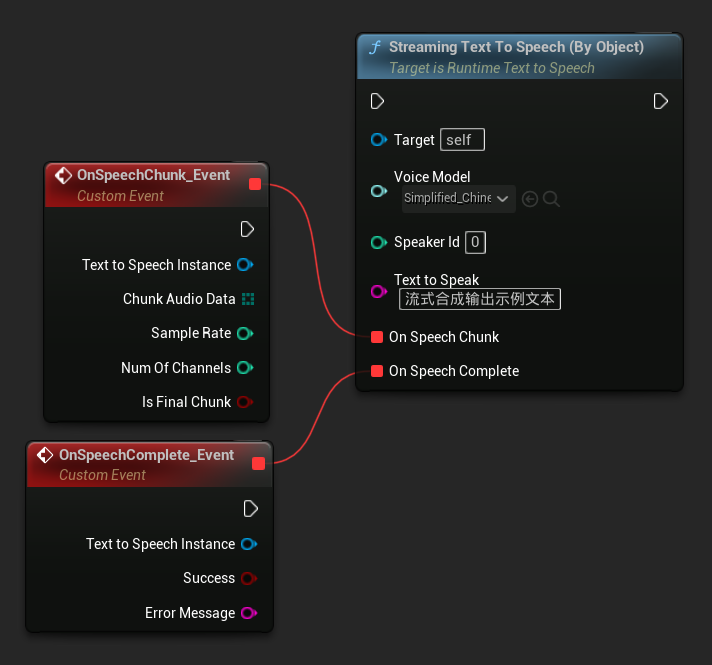
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
ऑडियो प्लेबैक
- Regular Playback
- स्ट्रीमिंग प्लेबैक
नियमित (नॉन-स्ट्रीमिंग) टेक्स्ट-टू-स्पीच के लिए, On Speech Result डेलिगेट संश्लेषित ऑडियो को PCM डेटा के रूप में फ्लोट फॉर्मेट में प्रदान करता है (ब्लूप्रिंट्स में बाइट ऐरे के रूप में या C++ में TArray<uint8> के रूप में), साथ ही Sample Rate और Num Of Channels भी प्रदान करता है।
प्लेबैक के लिए, कच्चे ऑडियो डेटा को प्लेयेबल साउंड वेव में बदलने के लिए Runtime Audio Importer प्लगइन का उपयोग करने की सिफारिश की जाती है।
- Blueprint
- C++
यहां एक उदाहरण है कि टेक्स्ट को संश्लेषित करने और ऑडियो चलाने के लिए ब्लूप्रिंट नोड्स कैसे दिख सकते हैं (कॉपी करने योग्य नोड्स):
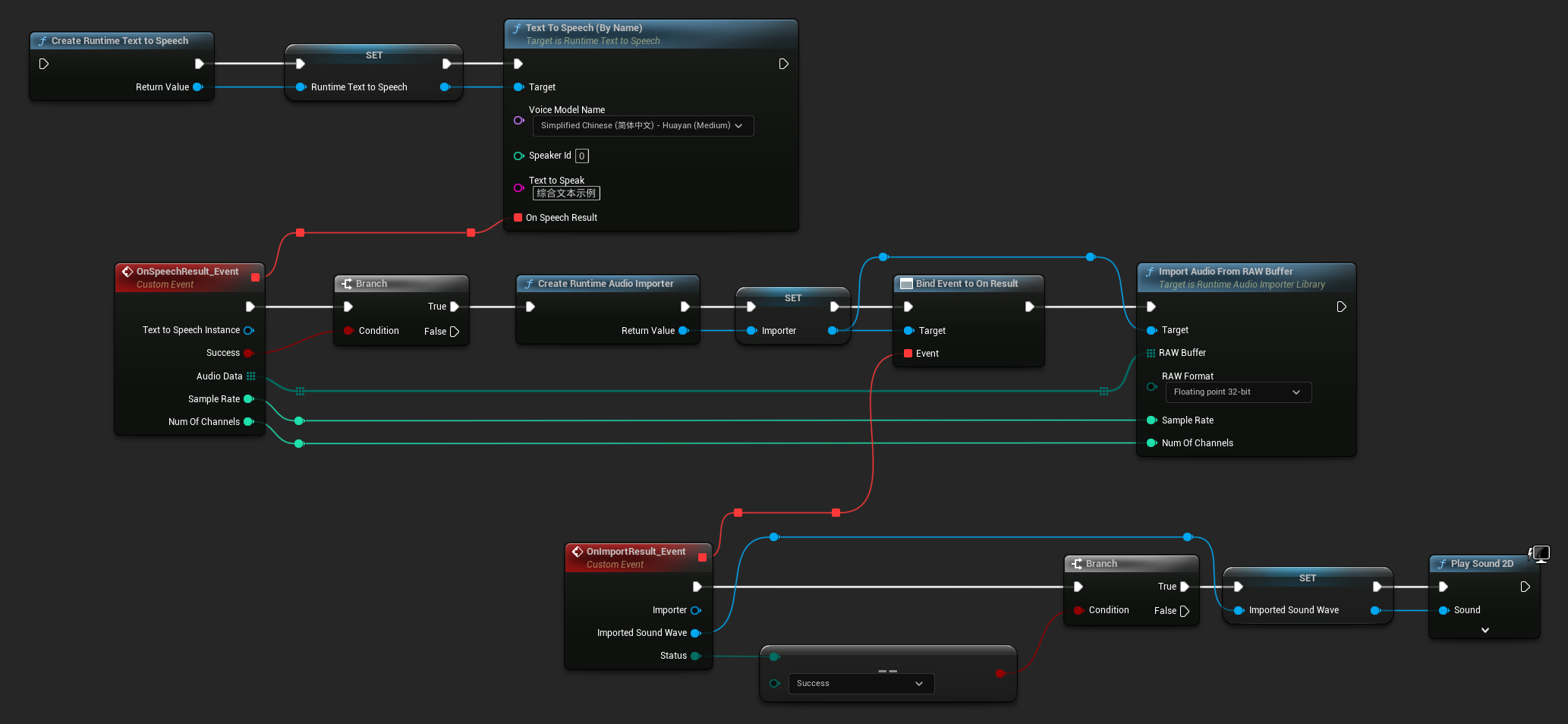
यहां एक उदाहरण है कि C++ में टेक्स्ट को संश्लेषित करने और ऑडियो चलाने के लिए कैसे करें:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
स्ट्रीमिंग टेक्स्ट-टू-स्पीच के लिए, आपको ऑडियो डेटा PCM डेटा के रूप में फ्लोट फॉर्मेट में (ब्लूप्रिंट्स में बाइट ऐरे के रूप में या C++ में TArray<uint8> के रूप में), Sample Rate और Num Of Channels के साथ चंक्स में प्राप्त होगा। प्रत्येक चंक को तुरंत प्रोसेस किया जा सकता है जैसे ही वह उपलब्ध होता है।
रियल-टाइम प्लेबैक के लिए, Runtime Audio Importer प्लगइन के Streaming Sound Wave का उपयोग करने की सिफारिश की जाती है, जो विशेष रूप से स्ट्रीमिंग ऑडियो प्लेबैक या रियल-टाइम प्रोसेसिंग के लिए डिज़ाइन किया गया है।
- ब्लूप्रिंट
- C++
यहाँ एक उदाहरण है कि स्ट्रीमिंग टेक्स्ट-टू-स्पीच और ऑडियो प्ले करने के लिए ब्लूप्रिंट नोड्स कैसे दिख सकते हैं (कॉपी करने योग्य नोड्स):
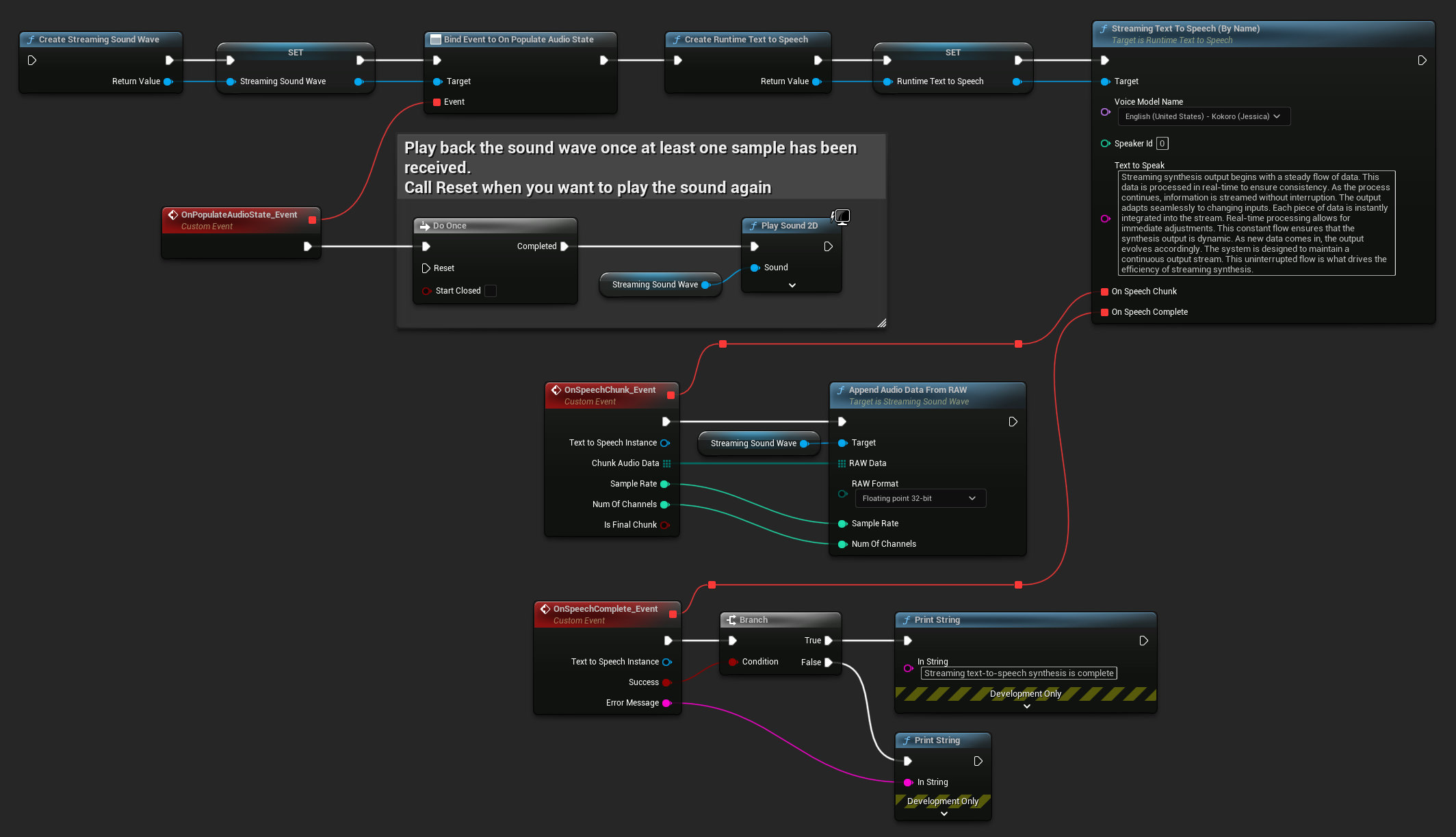
यहाँ एक उदाहरण है कि C++ में रियल-टाइम प्लेबैक के साथ स्ट्रीमिंग टेक्स्ट-टू-स्पीच को कैसे लागू किया जाए:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
टेक्स्ट-टू-स्पीच रद्द करना
आप किसी भी समय चल रहे टेक्स्ट-टू-स्पीच सिंथेसिस ऑपरेशन को रद्द कर सकते हैं अपने सिंथेसाइज़र इंस्टेंस पर CancelSpeechSynthesis फ़ंक्शन को कॉल करके:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
जब एक संश्लेषण रद्द किया जाता है:
- संश्लेषण प्रक्रिया जितनी जल्दी हो सके रुक जाएगी
- कोई भी चल रही कॉलबैक समाप्त कर दी जाएगी
- पूर्णता प्रतिनिधि को
bSuccess = falseके साथ और एक त्रुटि संदेश के साथ बुलाया जाएगा जो यह दर्शाता है कि संश्लेषण रद्द कर दिया गया था - संश्लेषण के लिए आवंटित किसी भी संसाधन को ठीक से साफ कर दिया जाएगा
यह लंबे पाठों के लिए या जब आपको एक नया संश्लेषण शुरू करने के लिए प्लेबैक को बाधित करने की आवश्यकता होती है, तो विशेष रूप से उपयोगी होता है।
स्पीकर चयन
दोनों Text To Speech फ़ंक्शन एक वैकल्पिक स्पीकर ID पैरामीटर स्वीकार करते हैं, जो तब उपयोगी होता है जब आप ऐसे वॉइस मॉडल के साथ काम कर रहे होते हैं जो कई स्पीकर का समर्थन करते हैं। आप यह जांचने के लिए कि क्या आपके चुने हुए वॉइस मॉडल द्वारा कई स्पीकर समर्थित हैं, GetSpeakerCountFromVoiceModel या GetSpeakerCountFromModelName फ़ंक्शन का उपयोग कर सकते हैं। यदि कई स्पीकर उपलब्ध हैं, तो Text To Speech फ़ंक्शन को कॉल करते समय बस अपना वांछित स्पीकर ID निर्दिष्ट करें। कुछ वॉइस मॉडल व्यापक विविधता प्रदान करते हैं - उदाहरण के लिए, English LibriTTS में 900 से अधिक विभिन्न स्पीकर चुनने के लिए शामिल हैं।
Runtime Audio Importer प्लगइन ऑडियो डेटा को एक फ़ाइल में निर्यात करने, इसे SoundCue, MetaSound, और अधिक में पास करने जैसी अतिरिक्त सुविधाएँ भी प्रदान करता है। अधिक जानकारी के लिए, Runtime Audio Importer दस्तावेज़ीकरण देखें।