Come usare il plugin
Questa guida copre l'API runtime completa: creare un'istanza LLM, caricare modelli, inviare messaggi, scaricare modelli in fase di esecuzione, gestire lo stato e funzioni di utilità.
Creare un'istanza LLM
Inizia creando un oggetto Runtime Local LLM. Mantieni un riferimento ad esso (ad esempio come variabile in Blueprints o una UPROPERTY in C++) per evitare la raccolta dei rifiuti prematura.
- Blueprint
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
Carica un Modello
Devi caricare un modello prima di inviare messaggi. Il plugin offre diversi metodi di caricamento in base al tuo flusso di lavoro.
Carica per Nome
Se gestisci i modelli attraverso il pannello delle impostazioni dell'editor, usa Load Model (By Name).
- Blueprint
- C++
- UE 5.3 and earlier
- UE 5.4+
In UE 5.3 and earlier il menu a discesa non appare, quindi devi recuperare manualmente i modelli disponibili. Usa Get All Downloaded Model Metadata, prendi l'elemento all'indice 0 (o il modello di cui hai bisogno), passalo a Get Model File Name per ottenere la stringa del nome, quindi passalo a Load Model (By Name).
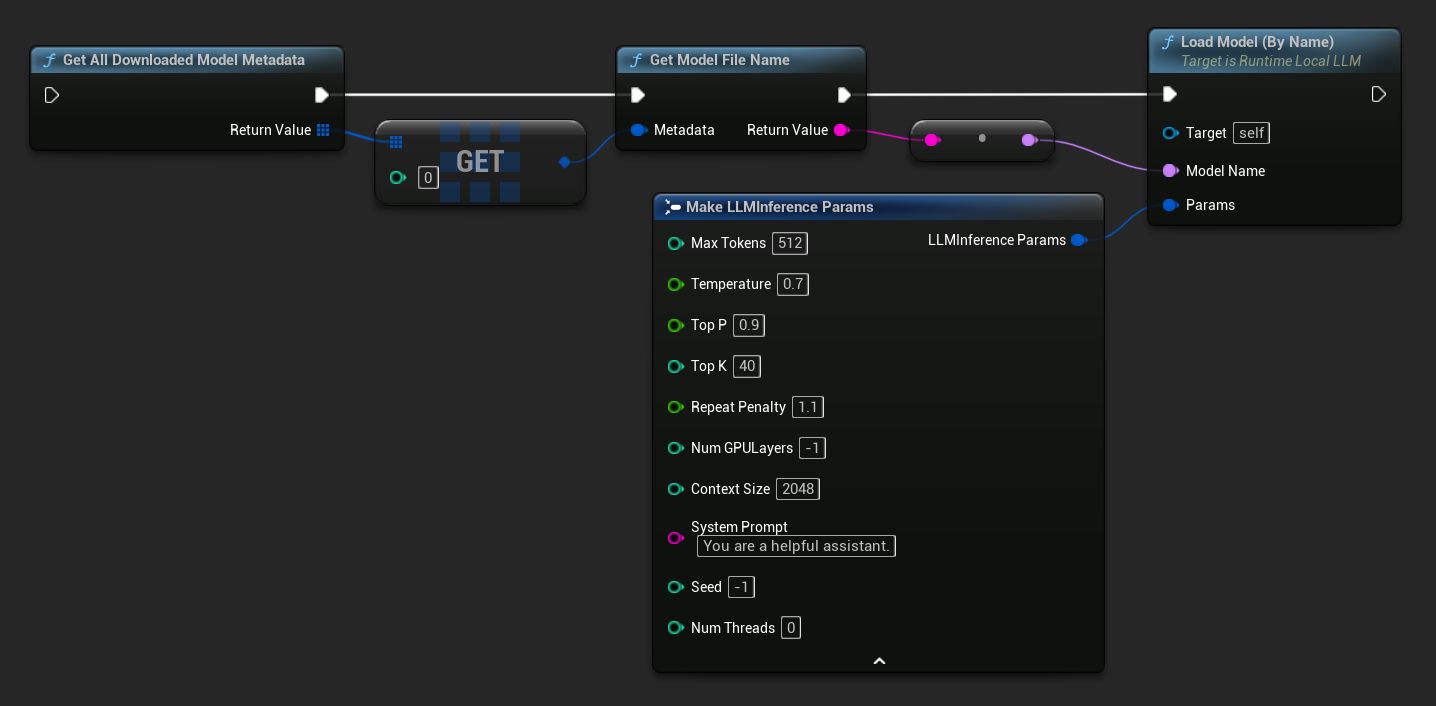
In UE 5.4 and later, Load Model (By Name) presenta un menu a discesa con tutti i modelli su disco – seleziona semplicemente il modello che vuoi caricare.
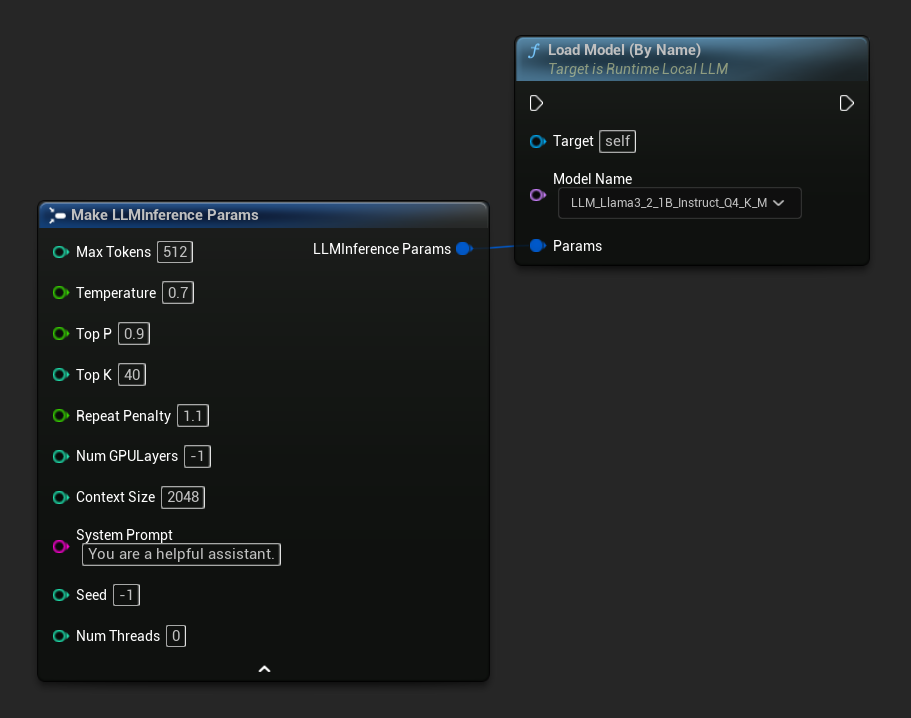
In C++, usa GetAllDownloadedModelMetadata per recuperare i modelli disponibili e GetModelFileName per ottenere il nome da passare a LoadModelByName:
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
Carica dal percorso del file
Carica un modello direttamente da un percorso assoluto di file verso un file .gguf:
- Blueprint
- C++
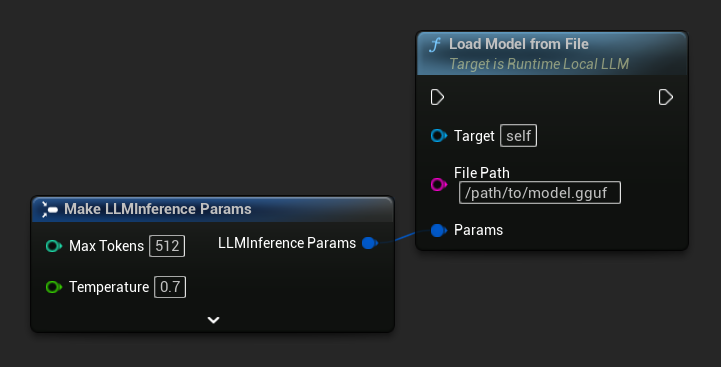
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
Carica da URL (Scarica e Carica)
Scarica un modello da un URL (se non già presente su disco) e lo carica automaticamente. Se il file esiste già localmente, il download viene saltato.
- Blueprint
- C++
La variante più semplice richiede solo un URL - i metadati vengono ricavati dal nome del file:
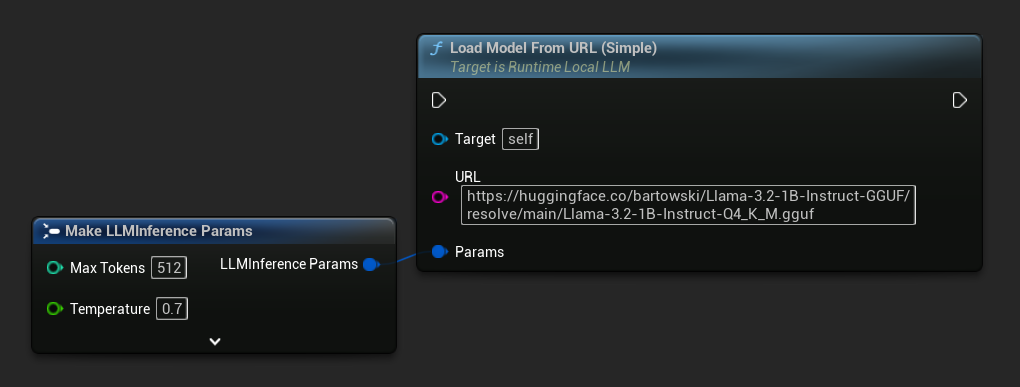
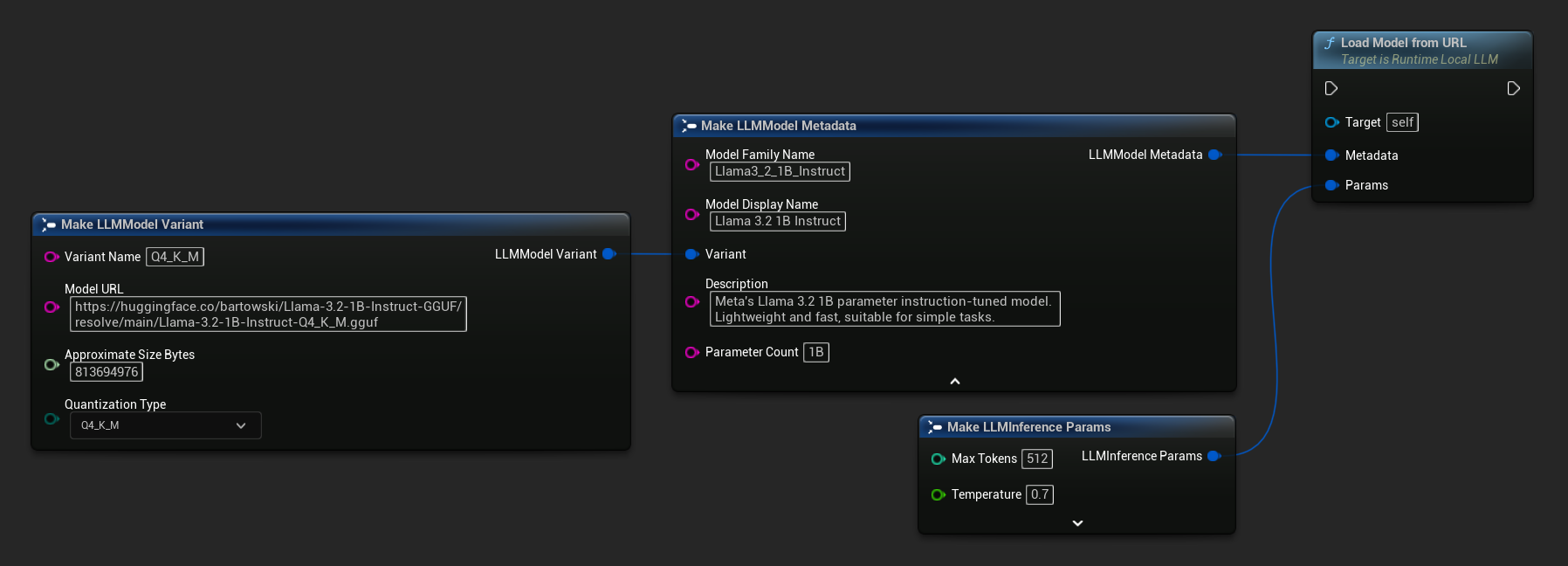
È anche possibile utilizzare Load Model From URL con metadati completi del modello per informazioni più ricche sul modello:
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
Caricamento Asincrono (Blueprint)
Per gestire il completamento e gli errori di caricamento tramite pin di output invece di associare manualmente i delegati, sono disponibili due nodi asincroni.
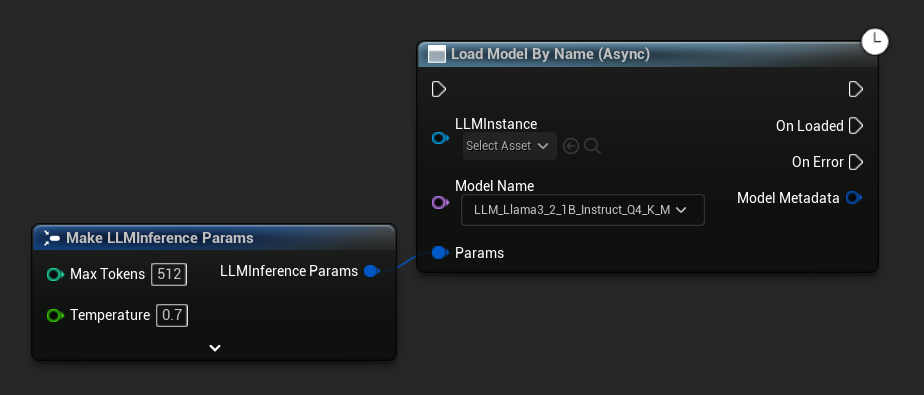
Load Model By Name (Async) rispecchia Load Model (By Name) - in UE 5.4+ presenta un menu a discesa di tutti i modelli su disco:
- UE 5.4+
- UE 5.3 e precedenti
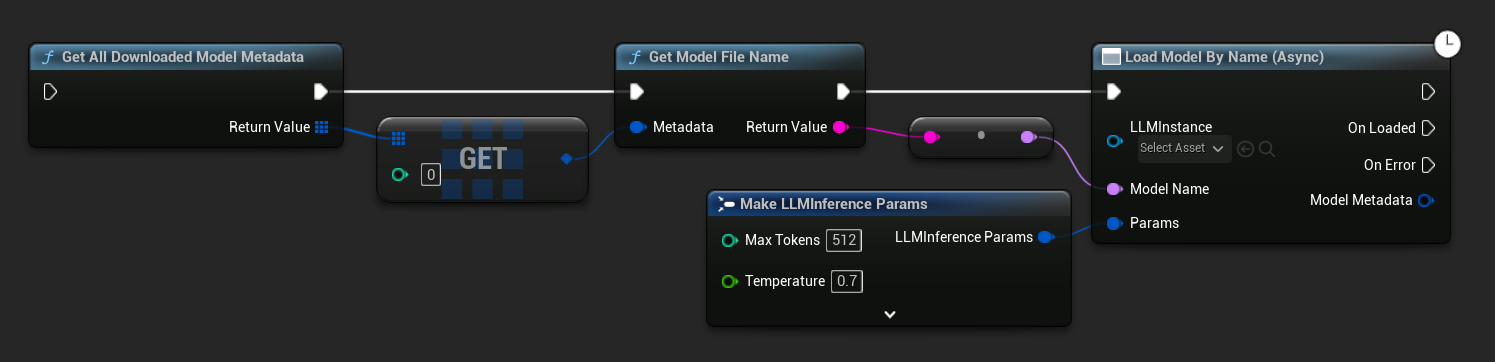
In UE 5.3 e precedenti il menu a discesa non appare. Usa Get All Downloaded Model Metadata, prendi l'elemento all'indice 0 (o il modello che ti serve), passalo a Get Model File Name, quindi passalo a Load Model By Name (Async).
Load Model From File (Async) accetta invece un percorso file assoluto:
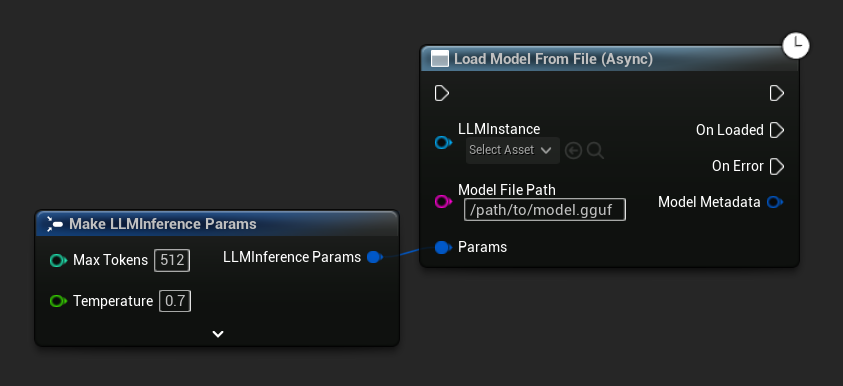
Associare Eventi
Associa i delegati dell'istanza LLM per ricevere callback. Tutti i callback vengono eseguiti sul thread di gioco.
- Blueprint
- C++
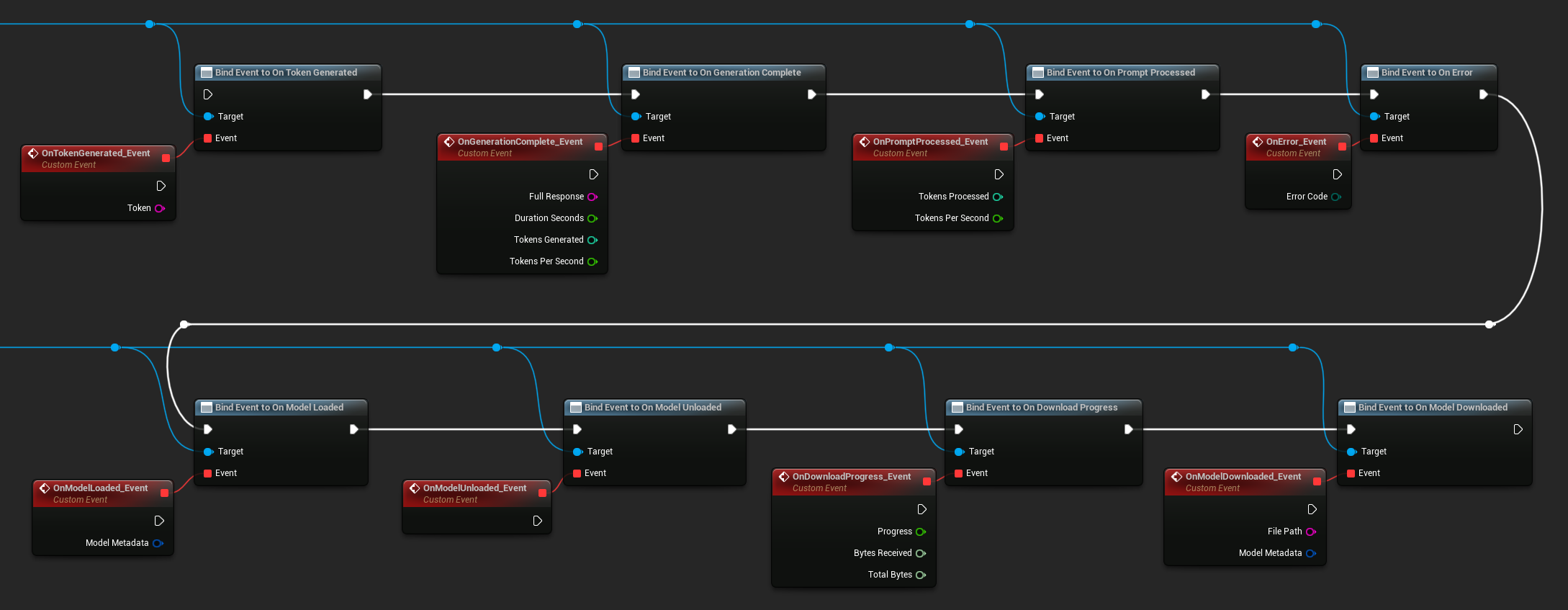
Delegati disponibili:
- On Token Generated: Si attiva per ogni token in output
- On Generation Complete: Si attiva quando la risposta completa è pronta, con durata, numero di token e token al secondo
- On Prompt Processed: Si attiva dopo che il prompt di input è stato elaborato, prima che inizi la generazione
- On Error: Si attiva se si verifica un errore durante qualsiasi operazione
- On Model Loaded: Si attiva quando un modello termina il caricamento
- On Model Unloaded: Si attiva quando il modello viene scaricato
- On Download Progress: Si attiva periodicamente durante un download del modello (frazione di progresso, byte ricevuti, byte totali)
- On Model Downloaded: Si attiva quando un'operazione di solo download viene completata
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda([](const FString& FullResponse)
{
});
LLM->OnPromptProcessedNative.AddLambda([]()
{
});
LLM->OnErrorNative.AddLambda([](const FString& ErrorMessage)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FString& ModelName)
{
});
LLM->OnModelUnloadedNative.AddLambda([](const FString& ModelName)
{
});
LLM->OnDownloadProgressNative.AddLambda([](const FString& ModelName, float Progress)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& ModelName)
{
});
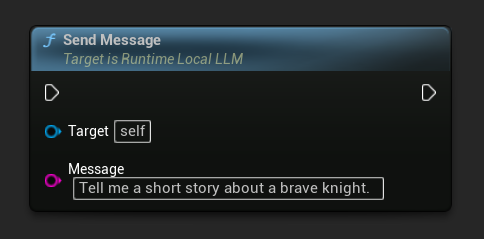
Inviare messaggi
Una volta caricato un modello, invia un messaggio utente per generare una risposta:
- Blueprint
- C++
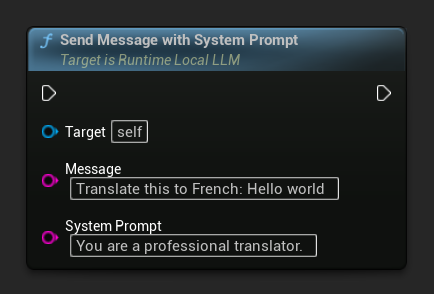
Per sovrascrivere il prompt di sistema per un messaggio specifico, utilizza Send Message With System Prompt:
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
I token fluiscono attraverso OnTokenGenerated man mano che vengono prodotti. Quando la generazione termina, OnGenerationComplete si attiva con la risposta completa, la durata, il conteggio dei token e i token al secondo.
Invio asincrono del messaggio (Blueprint)
Il nodo Send LLM Message (Async) fornisce pin di output dedicati per token, completamento ed errori:
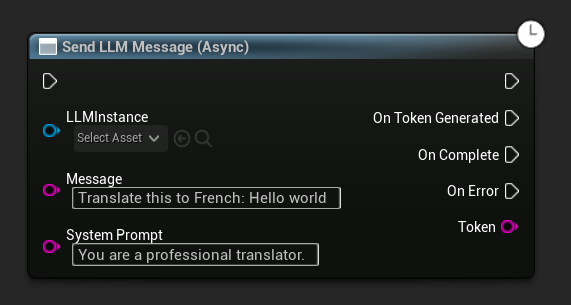
Scaricare modelli a runtime
Oltre al flusso di scaricamento e caricamento descritto sopra, è possibile scaricare un modello su disco senza caricarlo. Questo è utile per la memorizzazione anticipata dei modelli in una schermata di caricamento o nel menu delle impostazioni.
- Blueprint
- C++
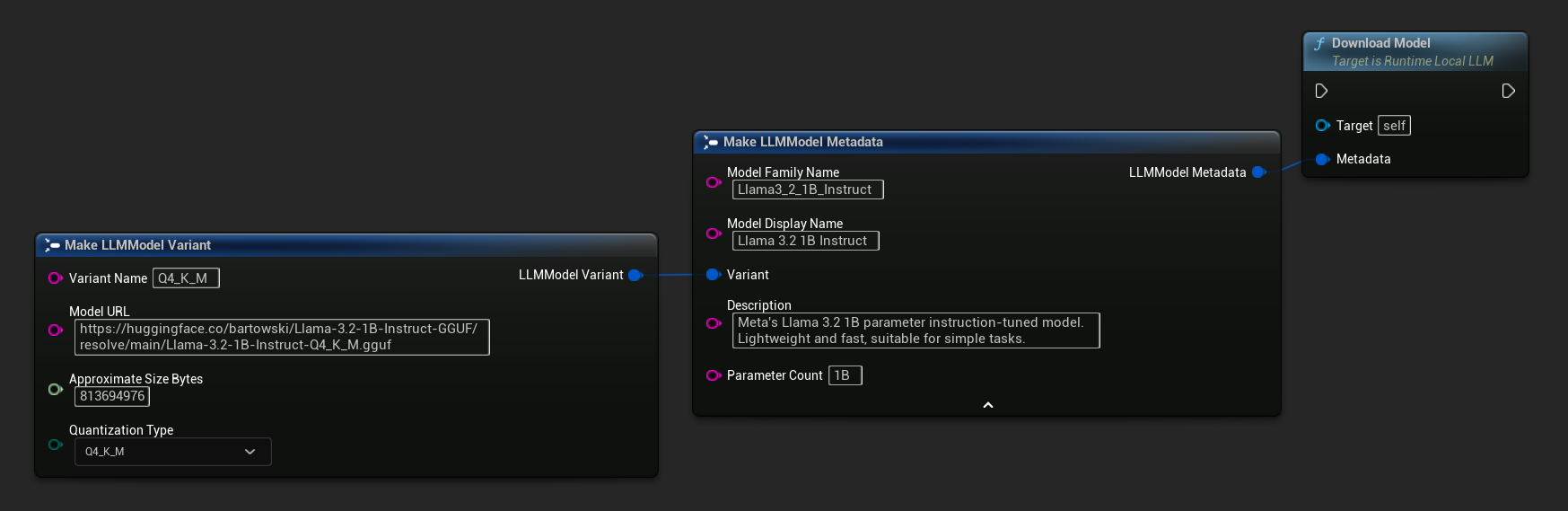
È disponibile anche una variante solo URL:
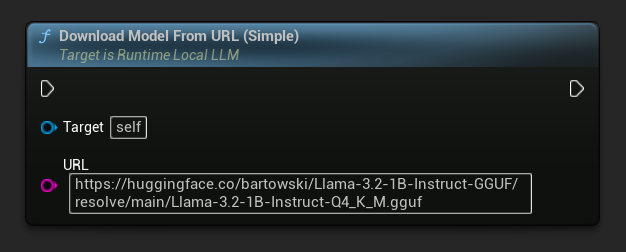
Il nodo Download LLM Model (Async) e Download LLM Model From URL (Async) fornisce pin di output per progresso, completamento ed errori:
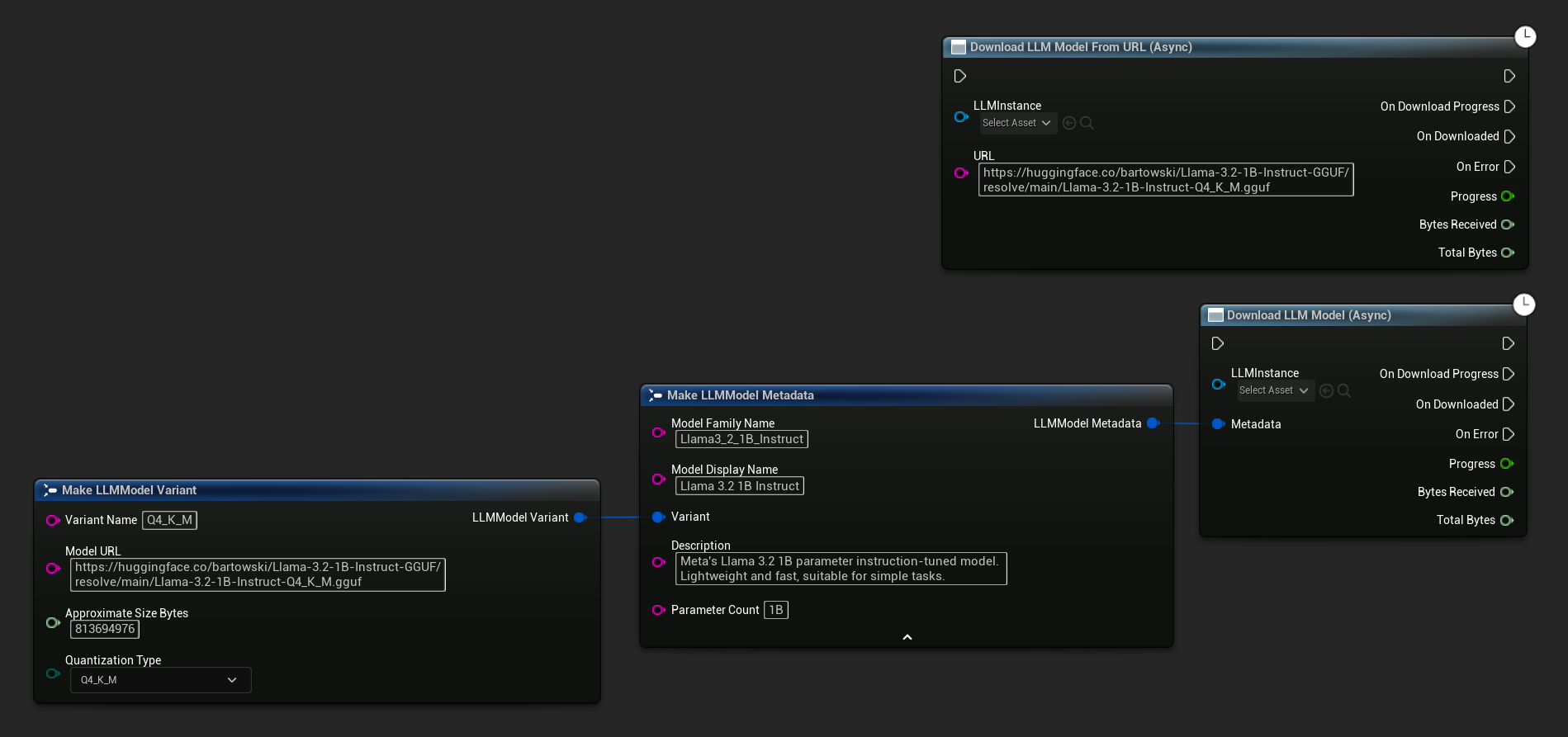
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
Il delegato OnDownloadProgress segnala lo stato di avanzamento durante il download. OnModelDownloaded viene attivato quando il file viene salvato su disco.
Per annullare un download in corso:
- Blueprint
- C++
LLM->CancelDownload();
Il plugin previene automaticamente i download duplicati: se è già in corso un download per lo stesso modello, le chiamate successive vengono ignorate.
Interrompere la Generazione
Per interrompere una generazione in corso:
- Blueprint
- C++
LLM->StopGeneration();
Reimposta il contesto della conversazione
Cancella la cronologia della conversazione per avviare una nuova conversazione:
- Blueprint
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
Scaricare un Modello
Libera risorse quando un modello non è più necessario:
- Blueprint
- C++
LLM->UnloadModel();
Stato della query
Verifica lo stato corrente dell'istanza LLM:
- Blueprint
- C++
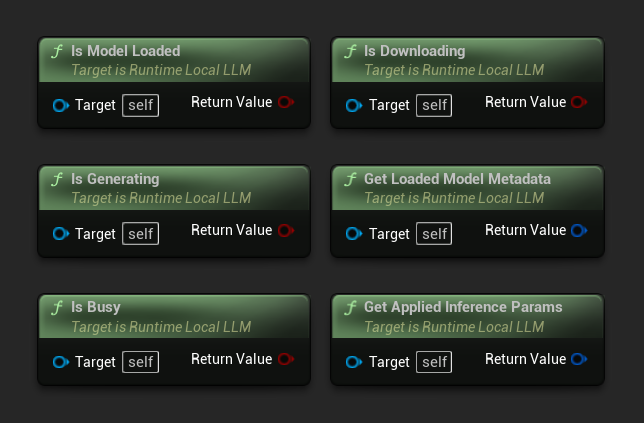
- Is Model Loaded: True se un modello è pronto per l'inferenza
- Is Generating: True se la generazione è in corso
- Is Busy: True se qualsiasi operazione (caricamento, generazione, download) è attiva
- Is Downloading: True se il download di un modello è in corso
- Get Loaded Model Metadata: Restituisce i metadati del modello corrente
- Get Applied Inference Params: Restituisce i parametri applicati durante il caricamento
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
Funzioni della Libreria Modelli
Un insieme di funzioni di utilità statiche è fornito per gestire i file dei modelli su disco. Queste sono utili per costruire un'interfaccia di selezione dei modelli o per verificare la disponibilità dei modelli in fase di esecuzione.
Ottieni i nomi dei modelli scaricati / Metadati
- Blueprint
- C++
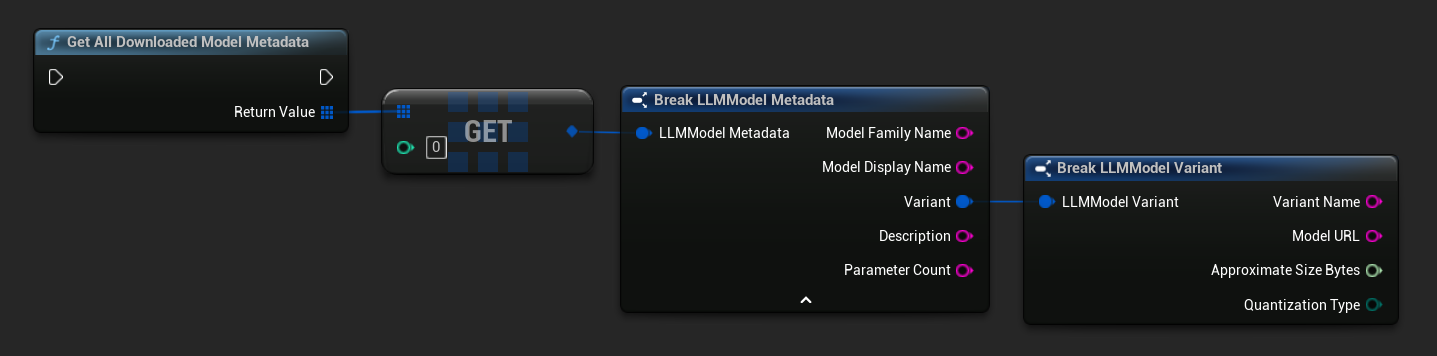
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
Verificare se un Modello è su Disco
- Blueprint
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
Ottieni il percorso del file del modello
- Blueprint
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
Eliminare i file del modello
- Blueprint
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
</TabItem>
</Tabs>
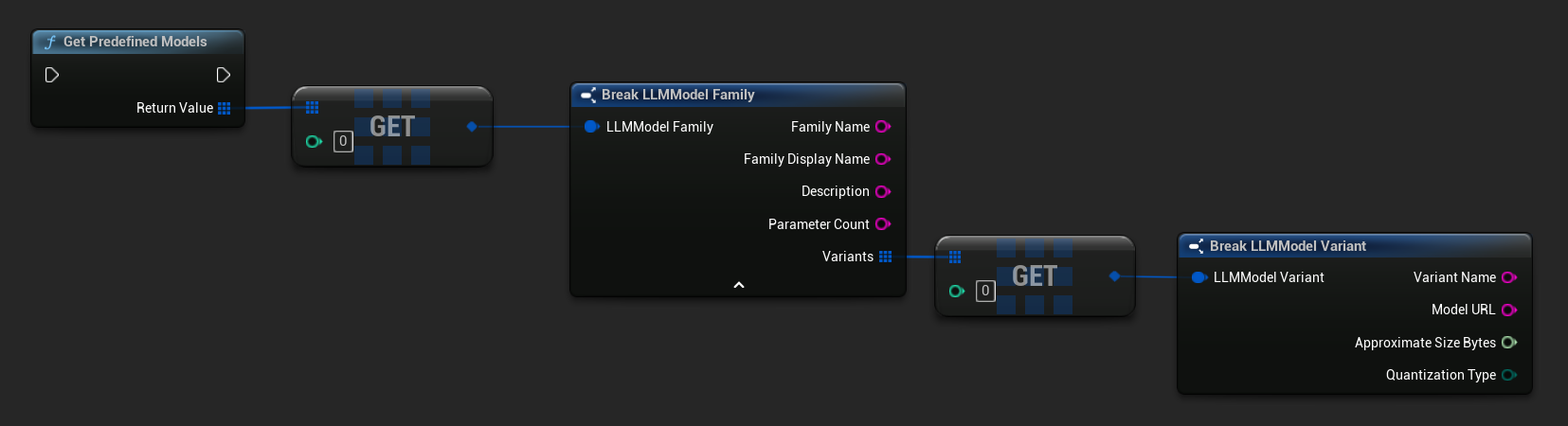
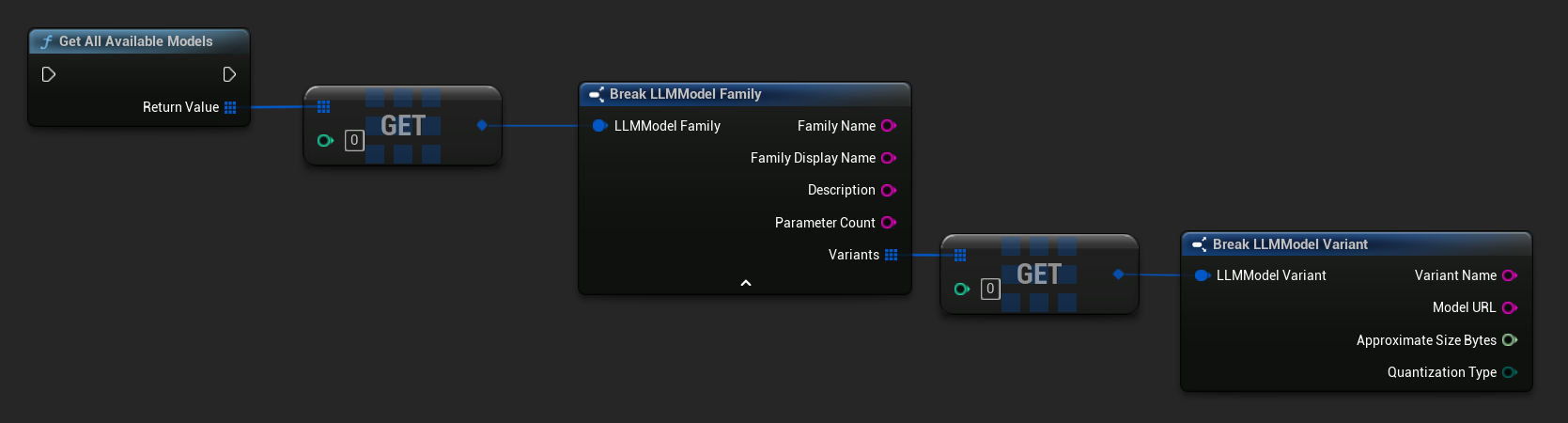
### Ottieni modelli predefiniti e disponibili {/* #get-pre-defined-and-available-models */}
<Tabs groupId="languages">
<TabItem value="blueprint" label="Blueprint">
</TabItem>
<TabItem value="c++" label="C++">
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
Crea metadati da un URL
Costruisci i metadati di un modello a partire da un URL grezzo (i campi sono derivati dal nome del file):
- Blueprint
- C++
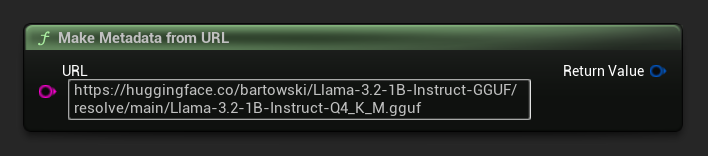
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
Funzioni di utilità
Viene fornito un insieme di funzioni di supporto per la formattazione e la visualizzazione degli errori.
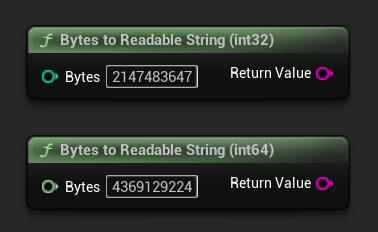
Da Byte a stringa leggibile
Converte un conteggio di byte in una stringa leggibile dall'uomo (ad es. "4.07 GB"). Utile per visualizzare le dimensioni dei modelli nell'interfaccia utente.
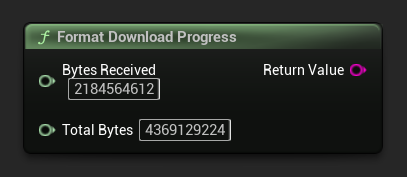
Formattazione dell'avanzamento del download
Formatta una stringa di avanzamento del download come "1.23 GB / 4.07 GB (30.2%)". Se la dimensione totale è sconosciuta, restituisce solo la quantità ricevuta.
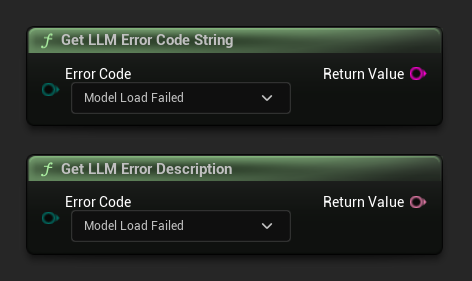
Ottieni descrizione dell'errore / Stringa del codice di errore
Get LLM Error Description restituisce una descrizione testuale leggibile per un codice di errore. Get LLM Error Code String restituisce il nome del valore enum come stringa (utile per il logging).
Riferimento codici di errore
| Codice | Valore | Descrizione |
|---|---|---|
| Unknown | 0 | Un errore non specificato |
| ModelLoadFailed | 10 | Il file GGUF non è stato caricato (file danneggiato, formato incompatibile, ecc.) |
| ContextCreateFailed | 11 | Creazione del contesto di inferenza non riuscita |
| ModelNotLoaded | 20 | È stato tentato di eseguire l'inferenza senza un modello caricato |
| ChatTemplateFailed | 21 | Applicazione del template di chat del modello non riuscita |
| TokenizationFailed | 22 | Il testo di input non può essere tokenizzato |
| ContextOverflow | 23 | Il prompt + contesto supera la dimensione del contesto configurata |
| PromptDecodeFailed | 24 | Decodifica dei token del prompt non riuscita |
| ContextTooFullToGenerate | 25 | Spazio del contesto insufficiente per generare l'output |
| GenerationDecodeFailed | 30 | Un token non è stato decodificato durante la generazione |
| GenerationTruncated | 31 | La generazione è stata interrotta perché è stato raggiunto il limite massimo di token |
| LLMInstanceNull | 40 | L'istanza LLM è nulla o non valida |
| ModelNotFoundOnDisk | 41 | Il file del modello non esiste nel percorso previsto |
| ModelURLEmpty | 42 | È stato richiesto un download con un URL vuoto |
| ModelDownloadCancelled | 43 | Il download è stato annullato |
| ModelDownloadEmptyData | 44 | Il download è stato completato ma il corpo della risposta era vuoto |
| ModelDownloadSaveFailed | 45 | Il download è stato completato ma il file non può essere salvato su disco |