Parametri di inferenza
La struttura dei parametri di inferenza LLM controlla il modo in cui il modello viene caricato e genera testo. Questi parametri vengono passati durante il caricamento di un modello. Questa pagina descrive ogni parametro e il suo effetto.
Riferimento dei parametri
| Parametro | Tipo | Predefinito | Intervallo | Descrizione |
|---|---|---|---|---|
| Token massimi | int32 | 512 | 1–8192 | Numero massimo di token da generare in una singola risposta |
| Temperatura | float | 0.7 | 0.0–2.0 | Controlla la casualità. 0.0 = deterministica. Valori più alti = output più creativo |
| Top P | float | 0.9 | 0.0–1.0 | Campionamento nucleo. Vengono considerati solo i token la cui probabilità cumulativa supera questo valore |
| Top K | int32 | 40 | 0–200 | Limita la selezione ai primi K token più probabili. 0 = disabilitato |
| Penalità di ripetizione | float | 1.1 | 0.0–3.0 | Penalizza i token che compaiono già nell'output. 1.0 = nessuna penalità |
| Numero di livelli GPU | int32 | -1 | -1–200 | Livelli del modello da trasferire sulla GPU. -1 = automatico. 0 = solo CPU |
| Dimensione contesto | int32 | 2048 | 128–131072 | Dimensione massima della finestra di contesto in token. Valori maggiori usano più memoria |
| Prompt di sistema | FString | "You are a helpful assistant." | — | Istruzione di sistema che modella il comportamento del modello |
| Seme | int32 | -1 | -1+ | Seme casuale per output riproducibili. -1 = casuale |
| Numero di thread | int32 | 0 | 0–128 | Thread CPU per la generazione. 0 = automatico |
Uso
- Blueprint
- C++
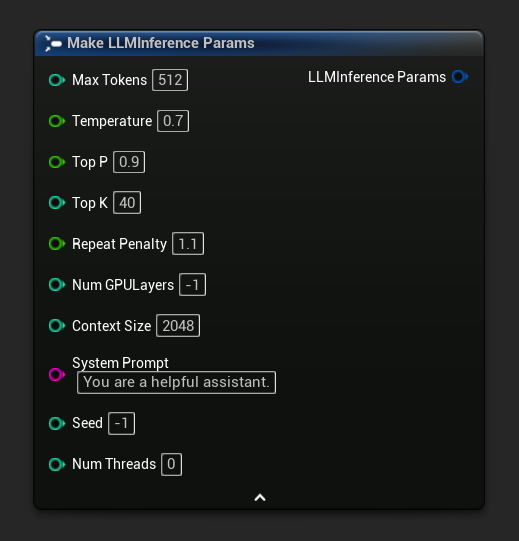
I parametri di inferenza appaiono come un pin di struttura sui nodi di caricamento e asincroni. Scomporre la struttura per impostare i singoli valori:
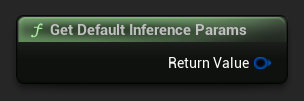
Per ottenere un insieme predefinito di parametri come punto di partenza, usa Get Default Inference Params:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
Raccomandazioni sulla piattaforma
Mobile / VR (Android, iOS, Meta Quest)
- Dimensione del contesto: 1024–2048
- Numero di strati GPU: 0 (solo CPU) a meno che il dispositivo non abbia confermato il supporto al calcolo GPU
- Token massimi: Meno di 256 per interazioni reattive
- Numero di thread: 2–4 a seconda del dispositivo
Desktop (Windows, Mac, Linux)
- Dimensione del contesto: 2048–8192 per la maggior parte delle conversazioni
- Numero di strati GPU: -1 (auto) per sfruttare l'accelerazione GPU quando disponibile
- Numero di thread: 0 (auto)
- Token massimi: 512–2048 per risposte più lunghe