Guida all'Elaborazione Audio
Questa guida spiega come configurare diversi metodi di input audio per fornire dati audio ai tuoi generatori di lip sync. Assicurati di aver completato la Guida di Configurazione prima di procedere.
Elaborazione dell'Input Audio
Devi configurare un metodo per elaborare l'input audio. Ci sono diversi modi per farlo a seconda della tua sorgente audio.
- Microfono (Tempo reale)
- Microfono (Riproduzione)
- Text-to-Speech (Locale)
- Text-to-Speech (API Esterne)
- Da File/Buffer Audio
- Buffer Audio in Streaming
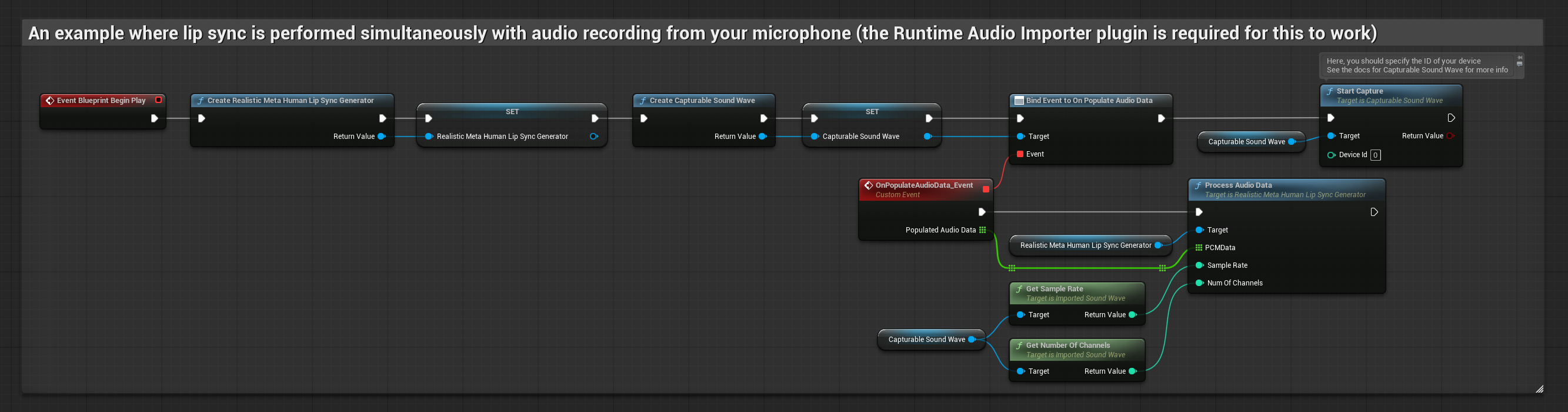
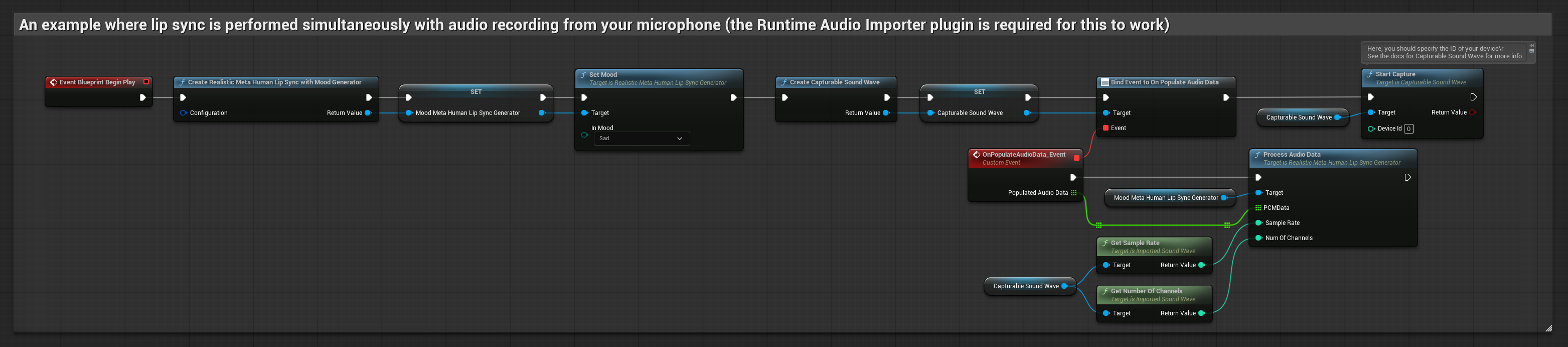
Questo approccio esegue il lip sync in tempo reale mentre si parla nel microfono:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Crea una Capturable Sound Wave utilizzando Runtime Audio Importer
- Per Linux con Pixel Streaming, usa invece Pixel Streaming Capturable Sound Wave
- Prima di iniziare a catturare l'audio, collega il delegato
OnPopulateAudioData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator - Inizia a catturare l'audio dal microfono
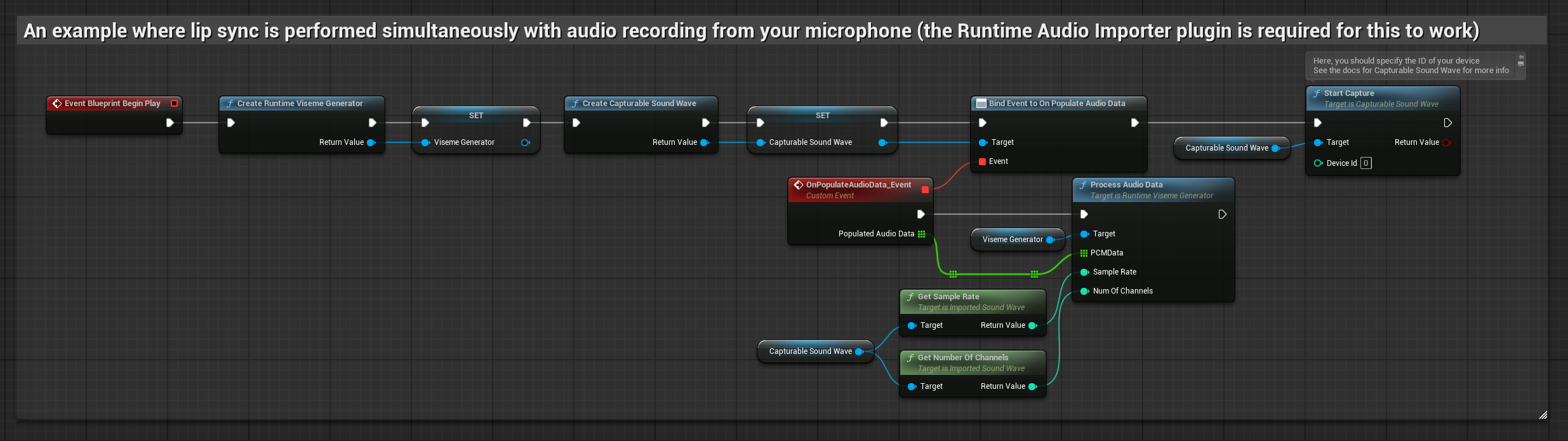
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
Questo approccio cattura l'audio da un microfono, poi lo riproduce con lip sync:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Crea una Capturable Sound Wave utilizzando Runtime Audio Importer
- Per Linux con Pixel Streaming, usa invece Pixel Streaming Capturable Sound Wave
- Inizia la cattura audio dal microfono
- Prima di riprodurre la capturable sound wave, collega il suo delegato
OnGeneratePCMData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator
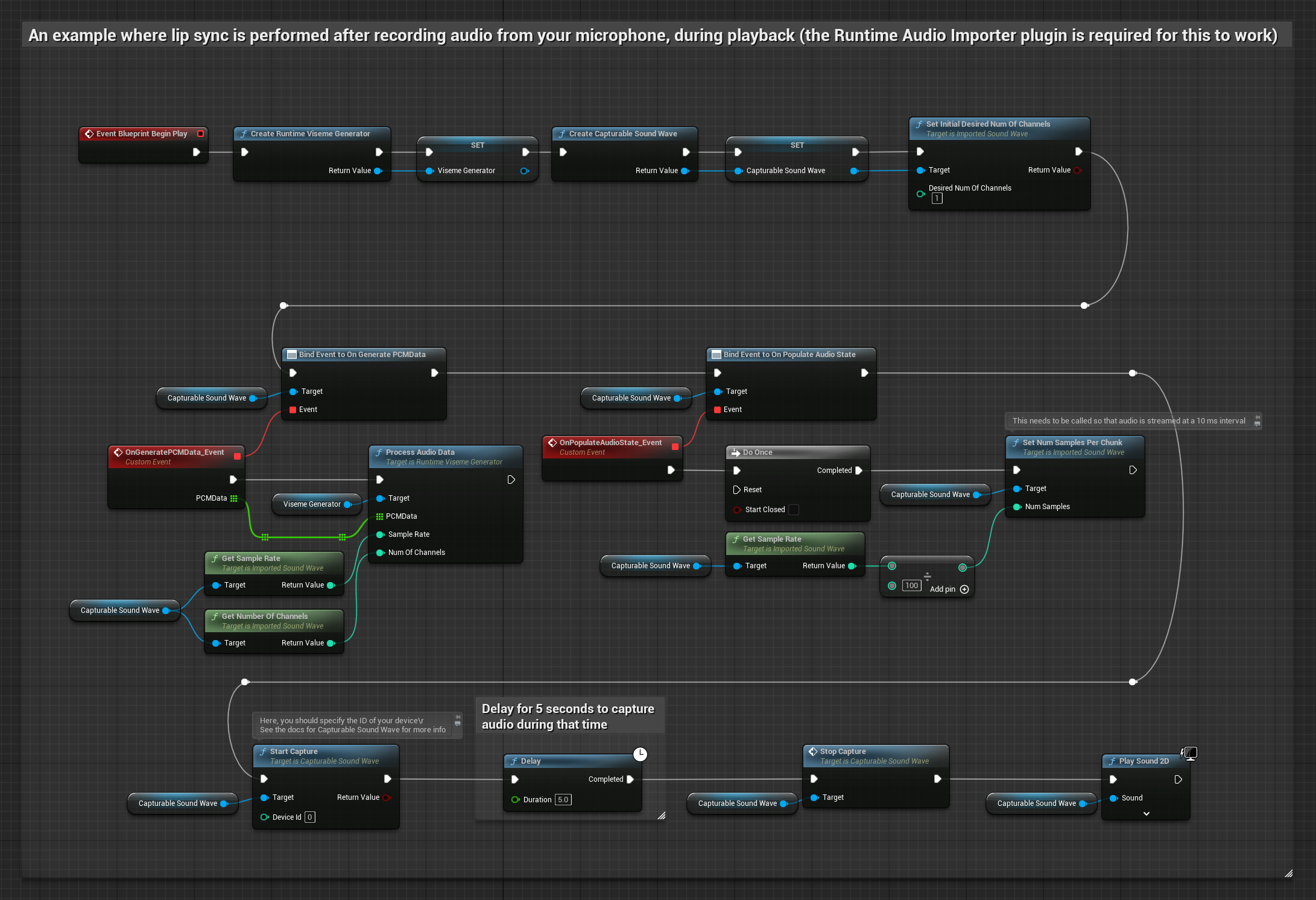
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
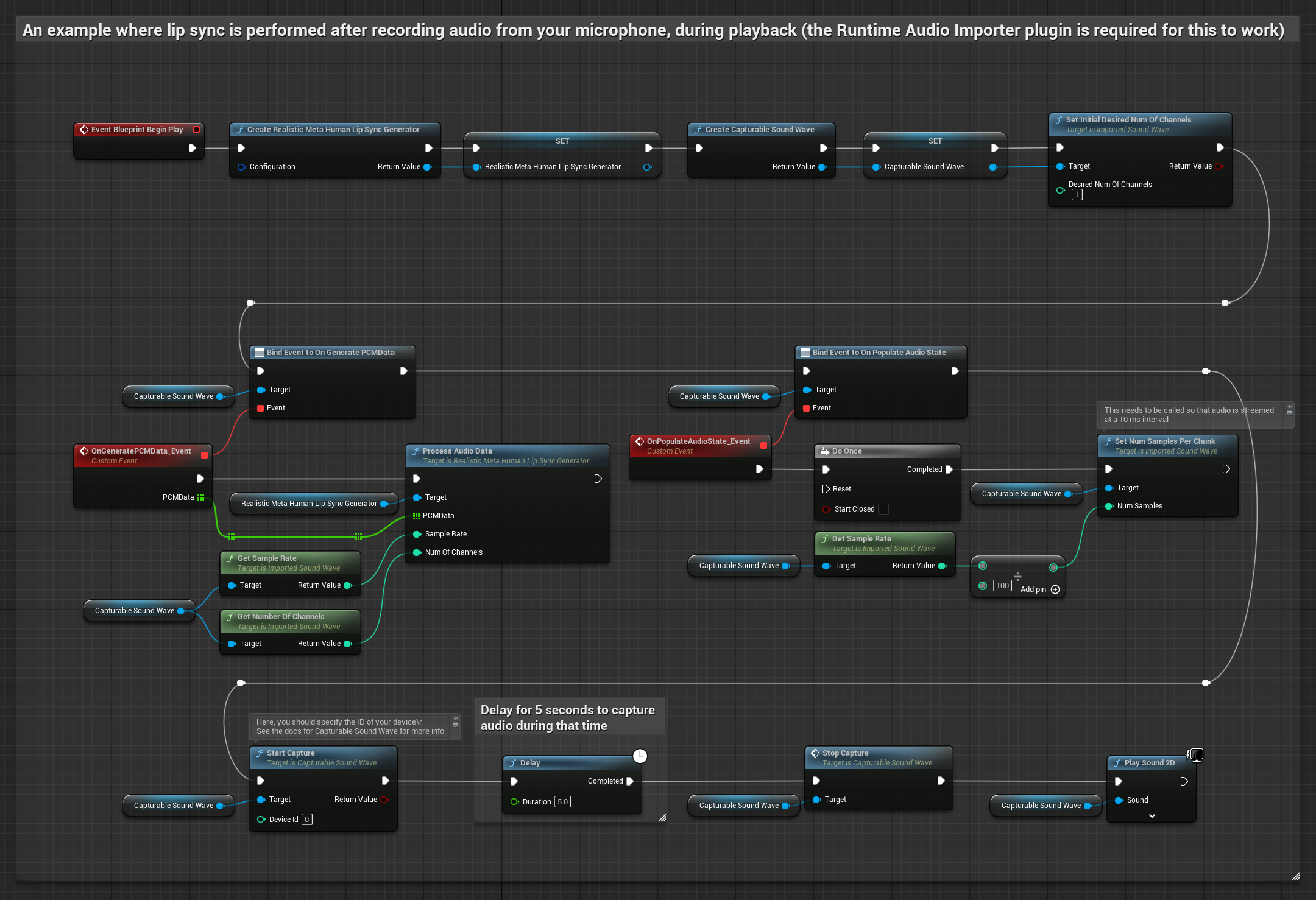
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
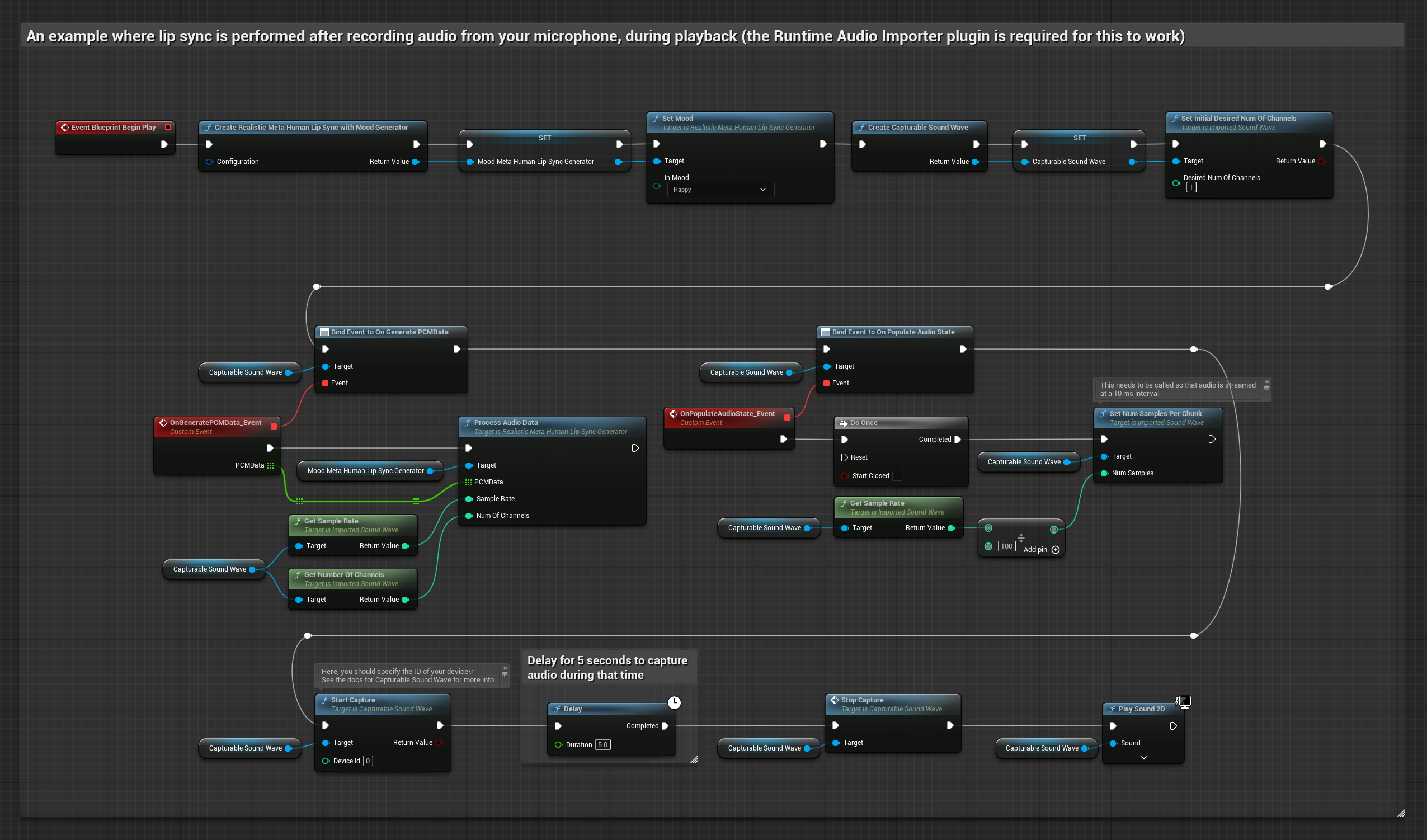
- Regolare
- Streaming
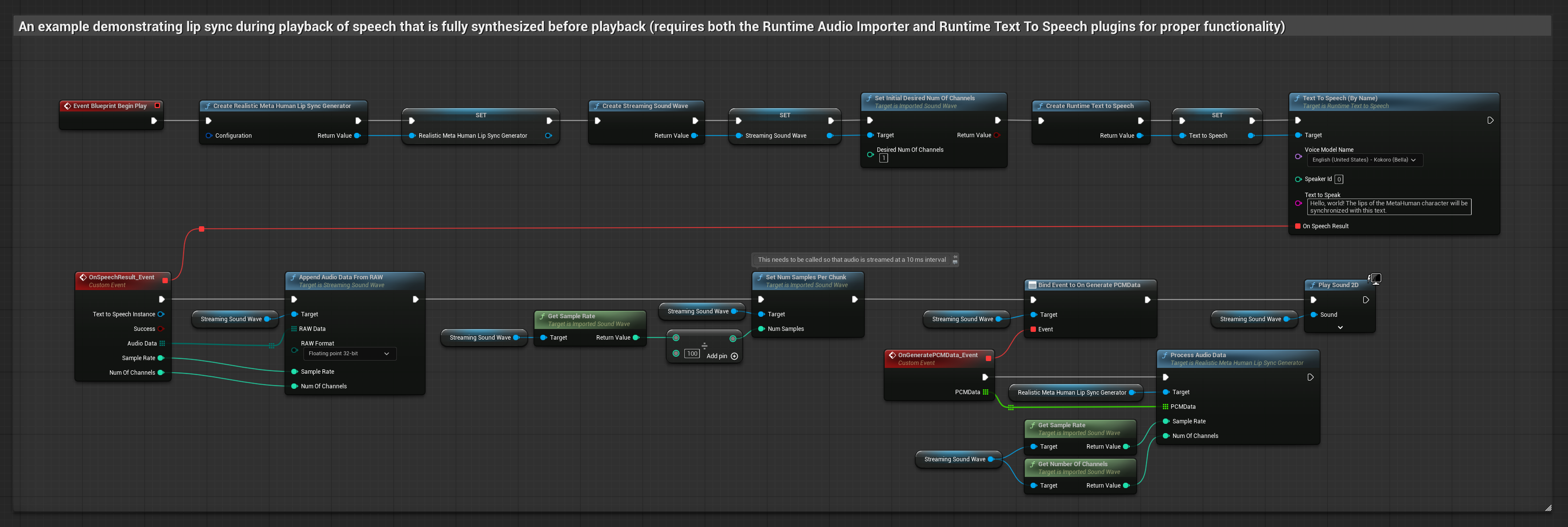
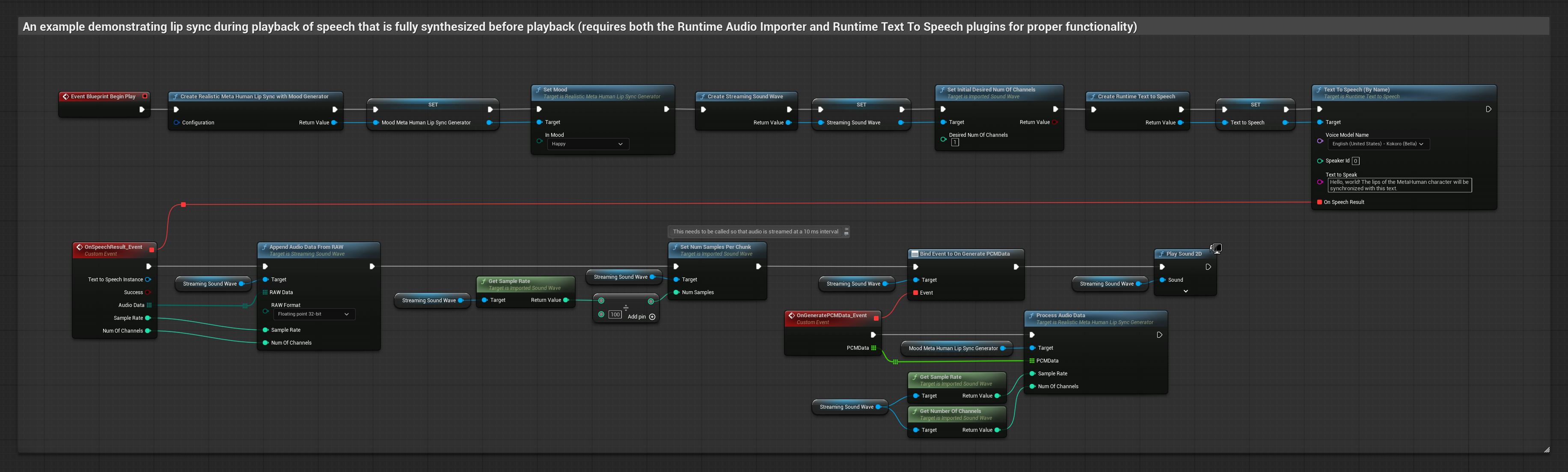
Questo approccio sintetizza il parlato dal testo utilizzando TTS locale ed esegue il lip sync:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Usa Runtime Text To Speech per generare parlato dal testo
- Usa Runtime Audio Importer per importare l'audio sintetizzato
- Prima di riprodurre la sound wave importata, collega il suo delegato
OnGeneratePCMData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
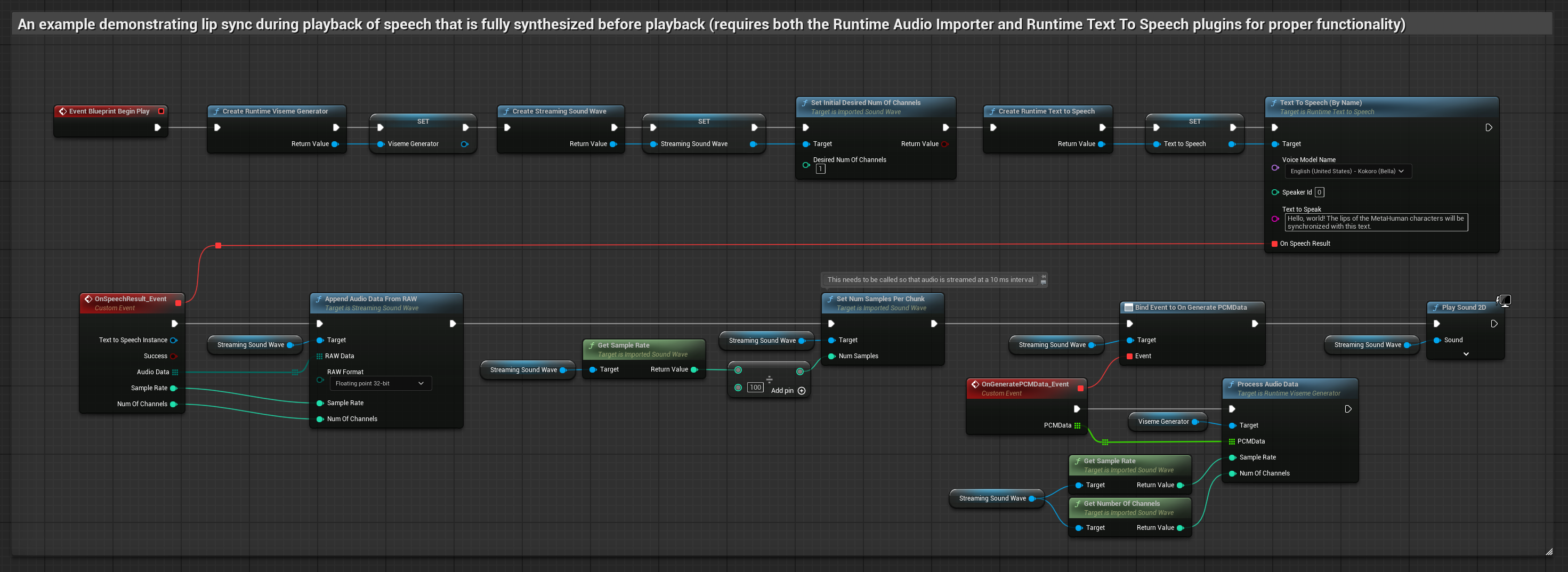
Questo approccio utilizza la sintesi text-to-speech in streaming con lip sync in tempo reale:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Usa Runtime Text To Speech per generare parlato in streaming dal testo
- Usa Runtime Audio Importer per importare l'audio sintetizzato
- Prima di riprodurre la sound wave in streaming, collega il suo delegato
OnGeneratePCMData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator
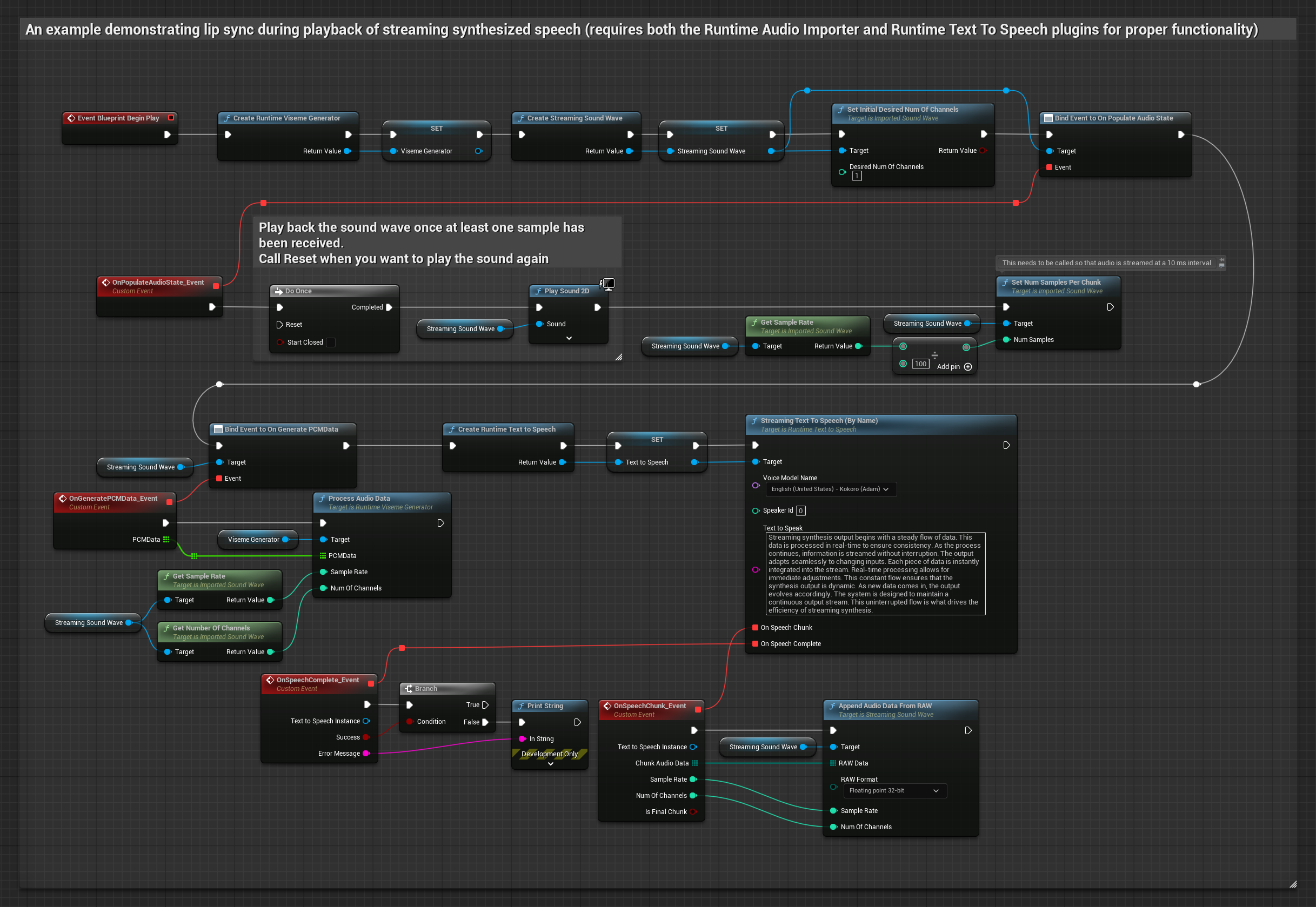
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
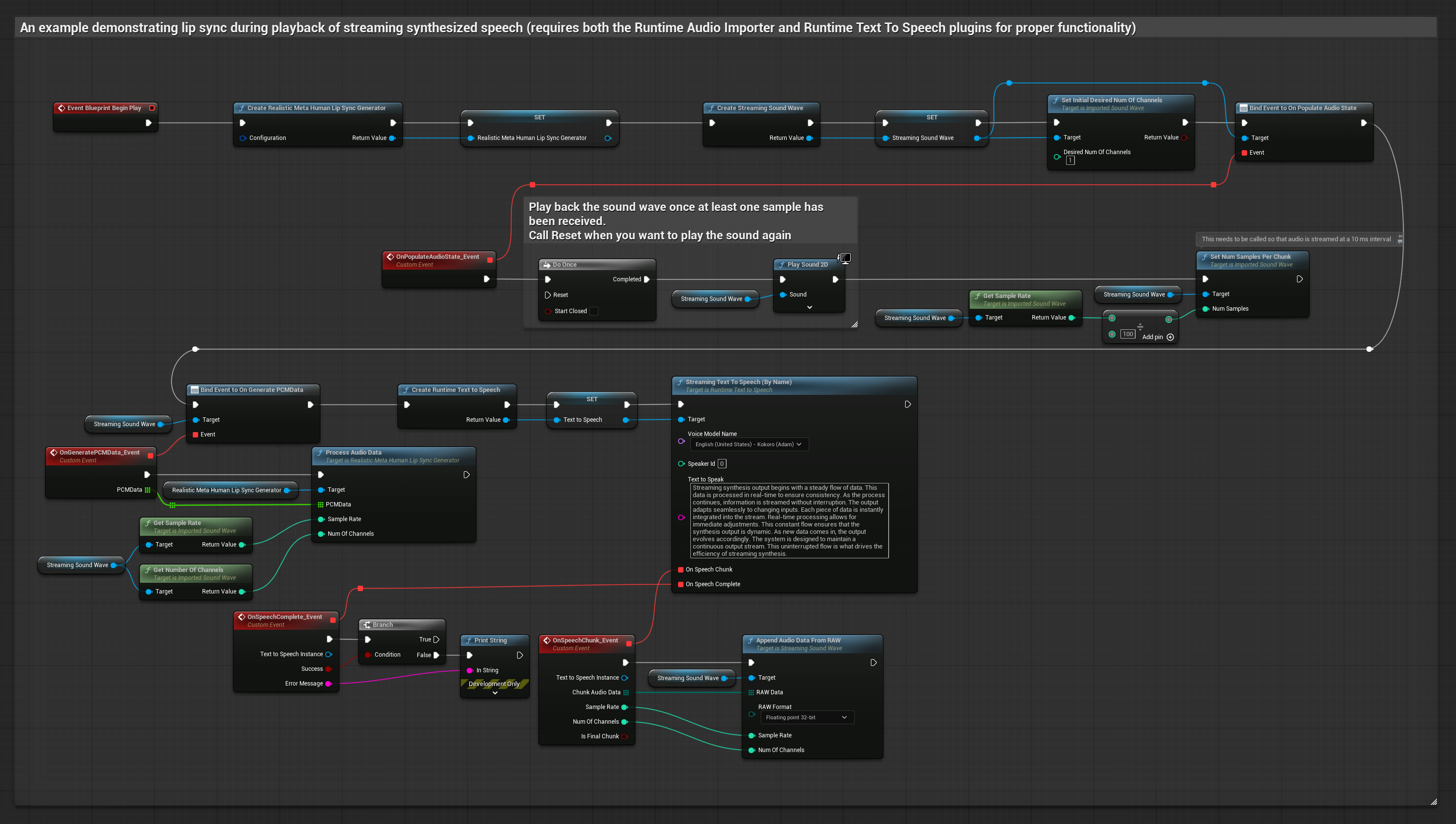
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
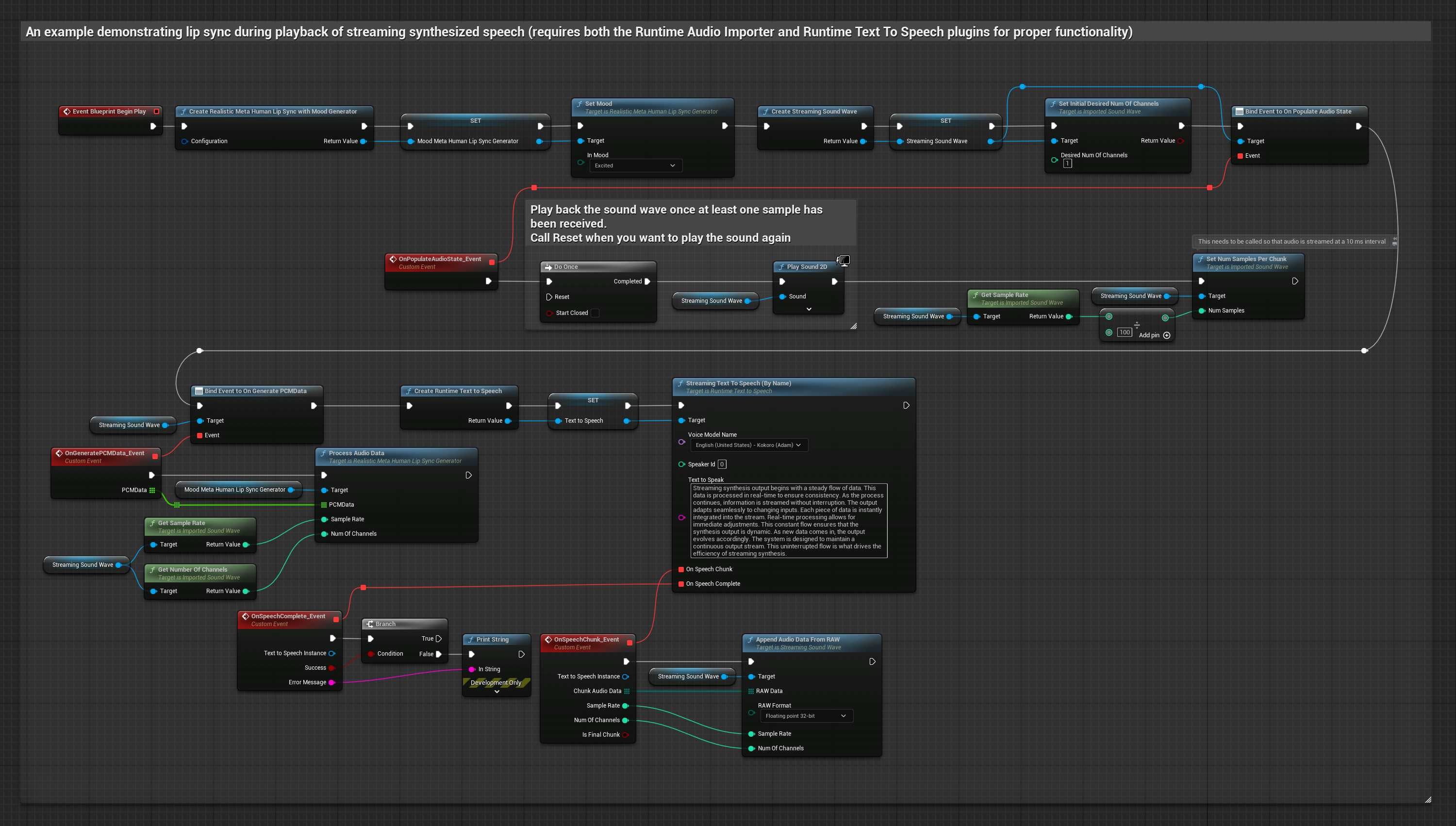
- Regolare
- Streaming
Questo approccio utilizza il plugin Runtime AI Chatbot Integrator per generare parlato sintetizzato da servizi AI (OpenAI o ElevenLabs) ed eseguire il lip sync:
- Modello Standard
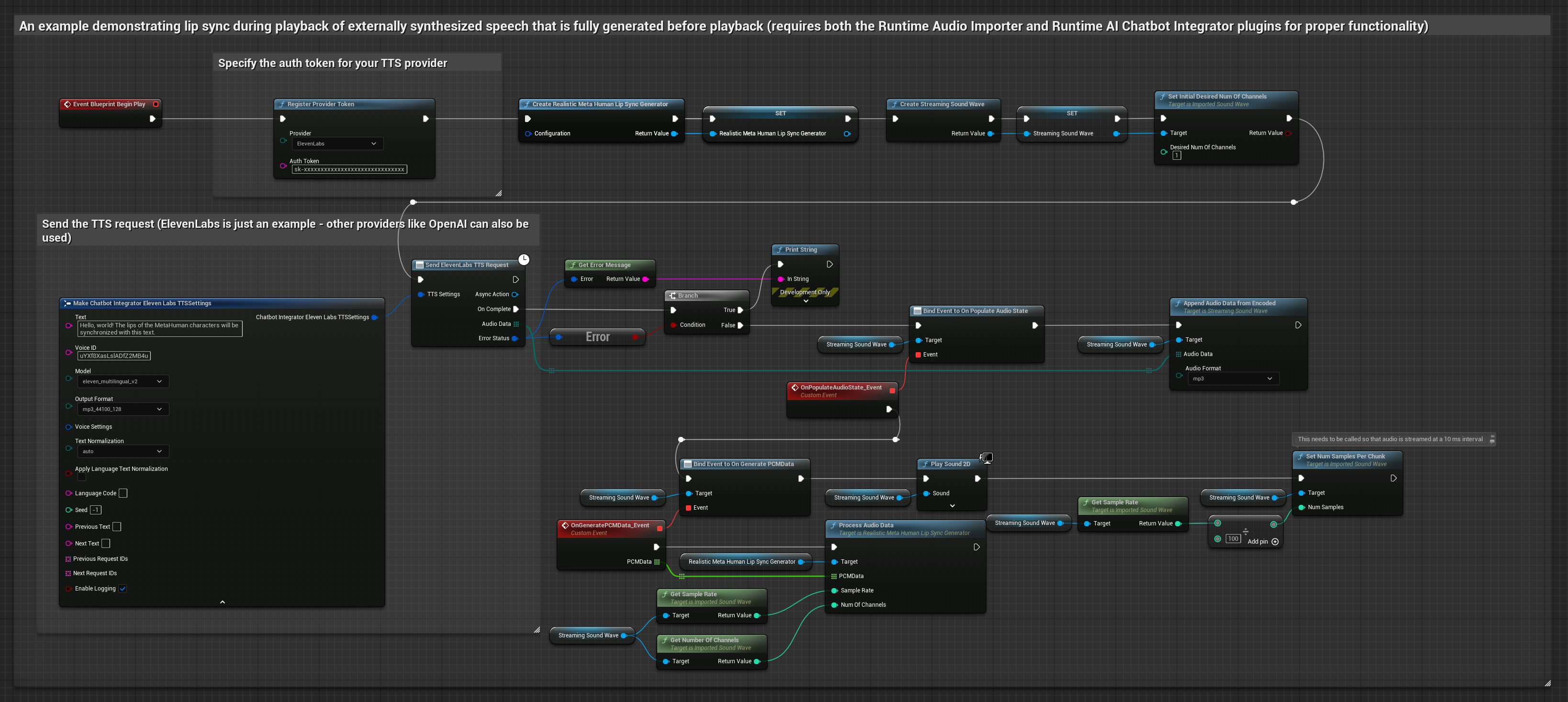
- Modello Realistico
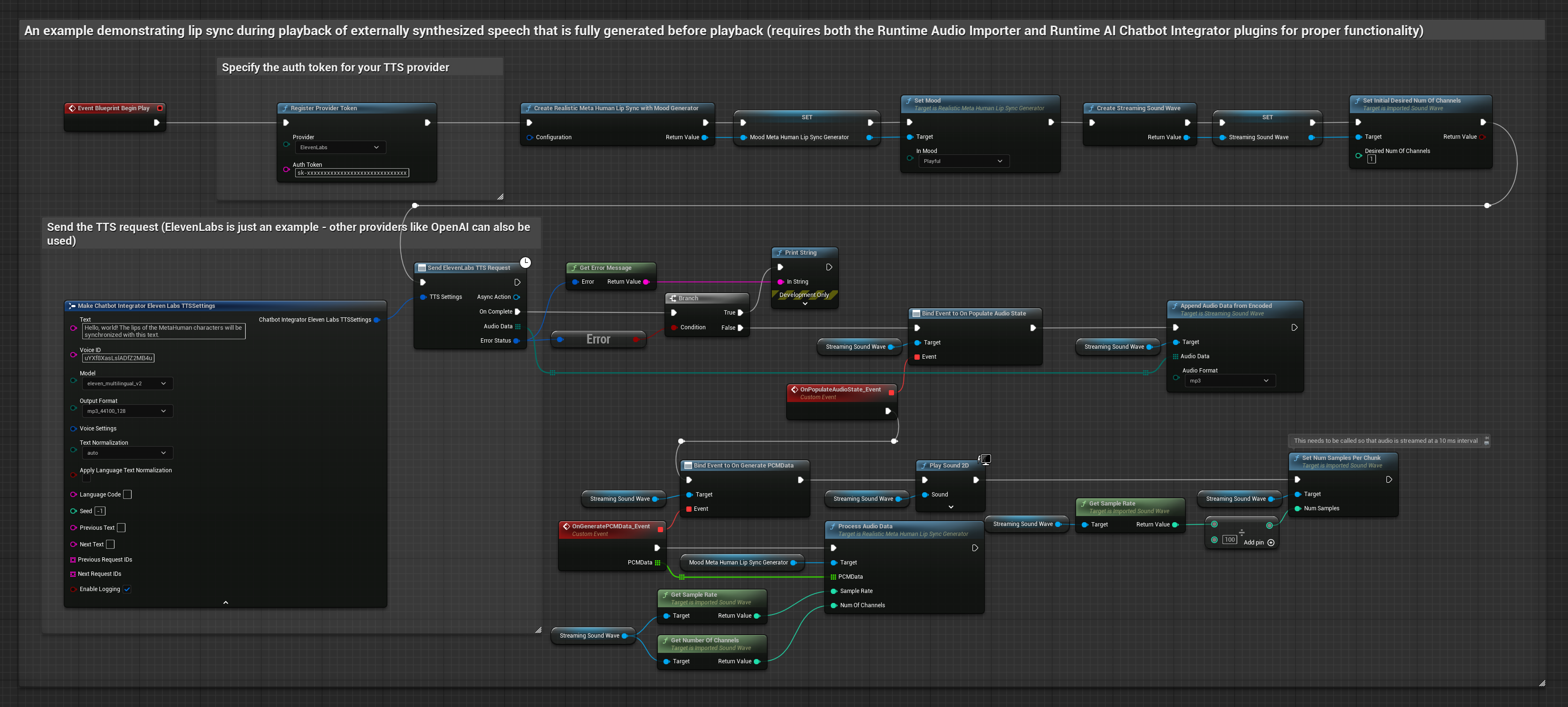
- Modello Realistico con Mood
- Usa Runtime AI Chatbot Integrator per generare parlato dal testo utilizzando API esterne (OpenAI, ElevenLabs, ecc.)
- Usa Runtime Audio Importer per importare i dati audio sintetizzati
- Prima di riprodurre la sound wave importata, collega il suo delegato
OnGeneratePCMData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator
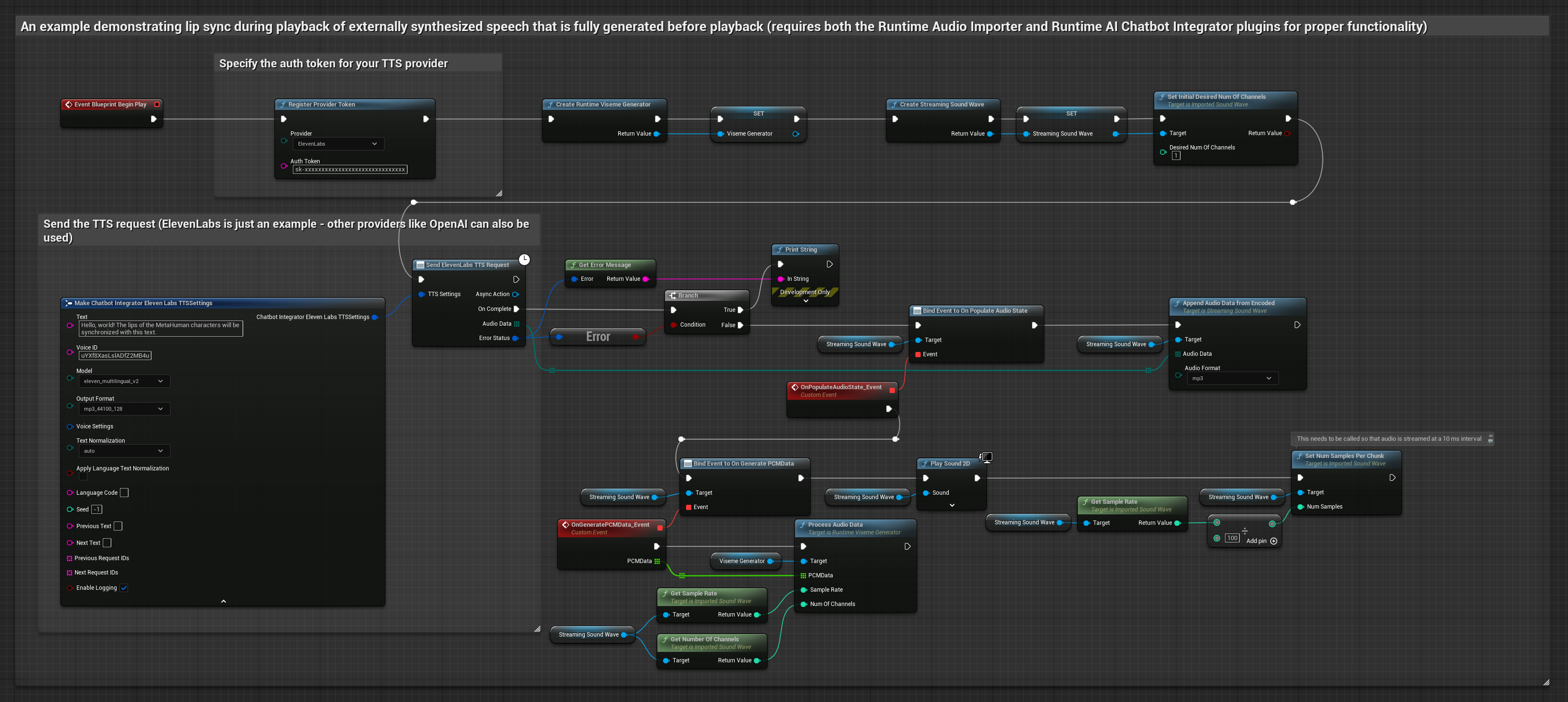
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
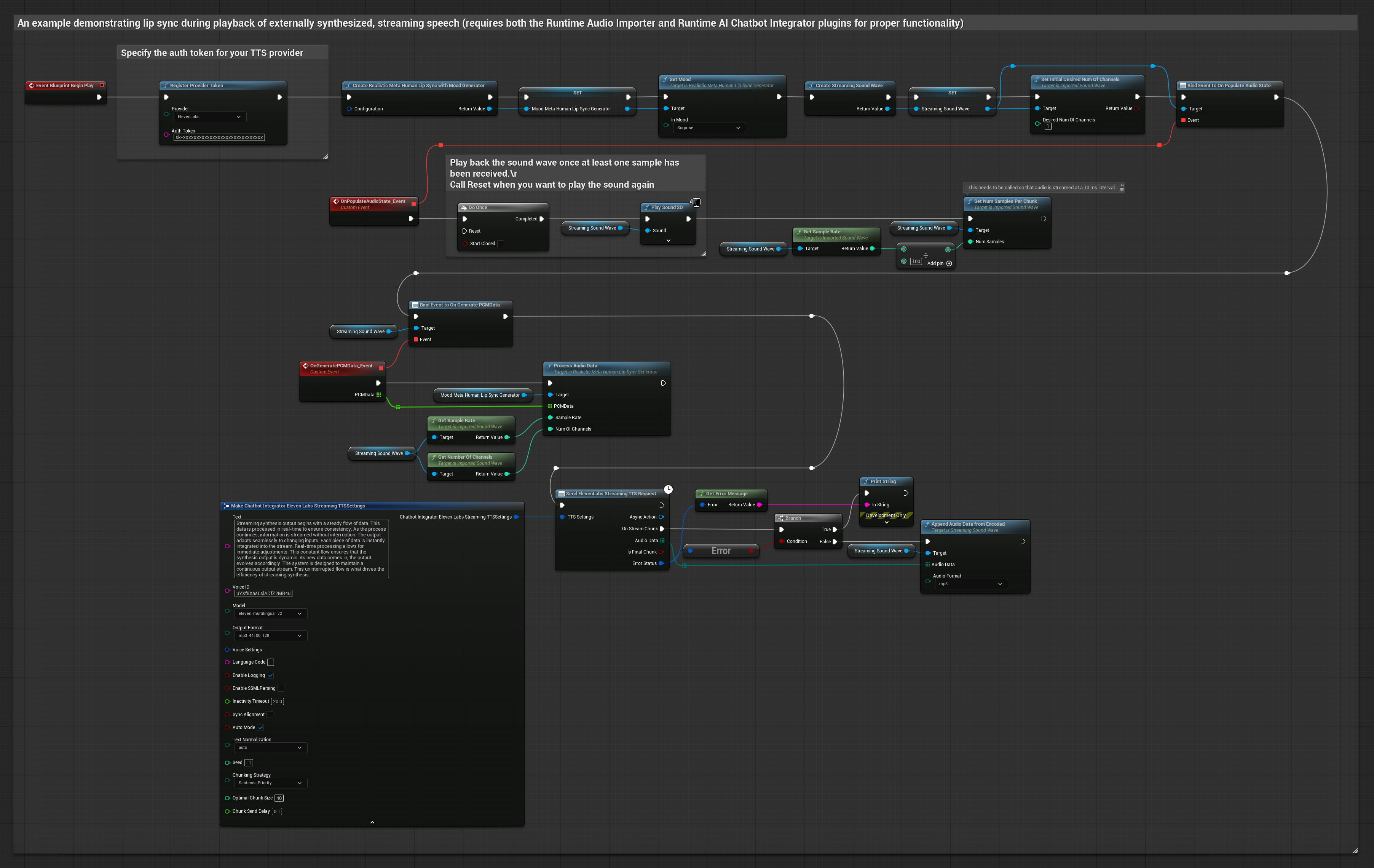
Questo approccio utilizza il plugin Runtime AI Chatbot Integrator per generare parlato sintetizzato in streaming da servizi AI (OpenAI o ElevenLabs) ed eseguire il lip sync:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Usa Runtime AI Chatbot Integrator per connettersi a API TTS in streaming (come ElevenLabs Streaming API)
- Usa Runtime Audio Importer per importare i dati audio sintetizzati
- Prima di riprodurre la sound wave in streaming, collega il suo delegato
OnGeneratePCMData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator
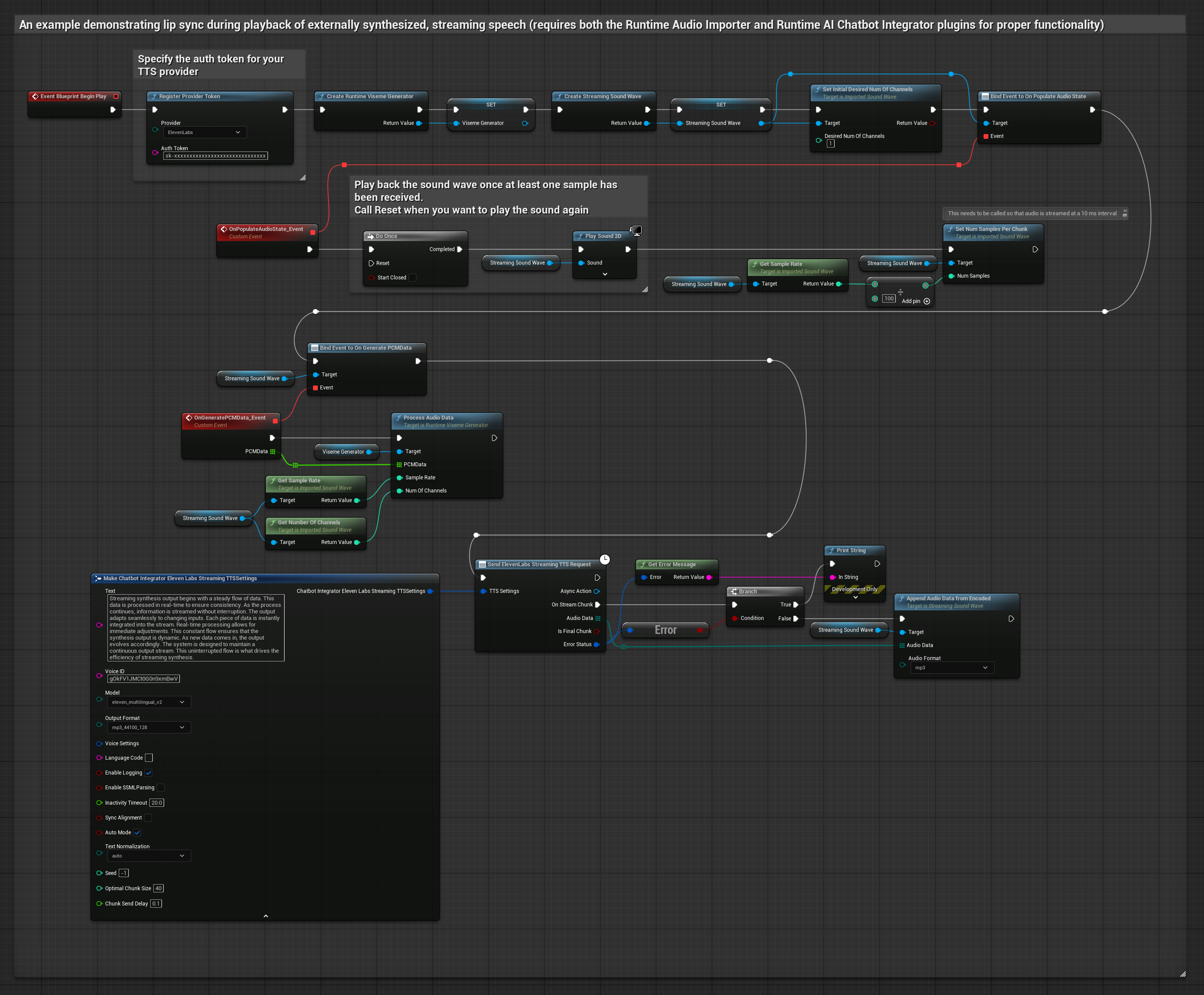
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
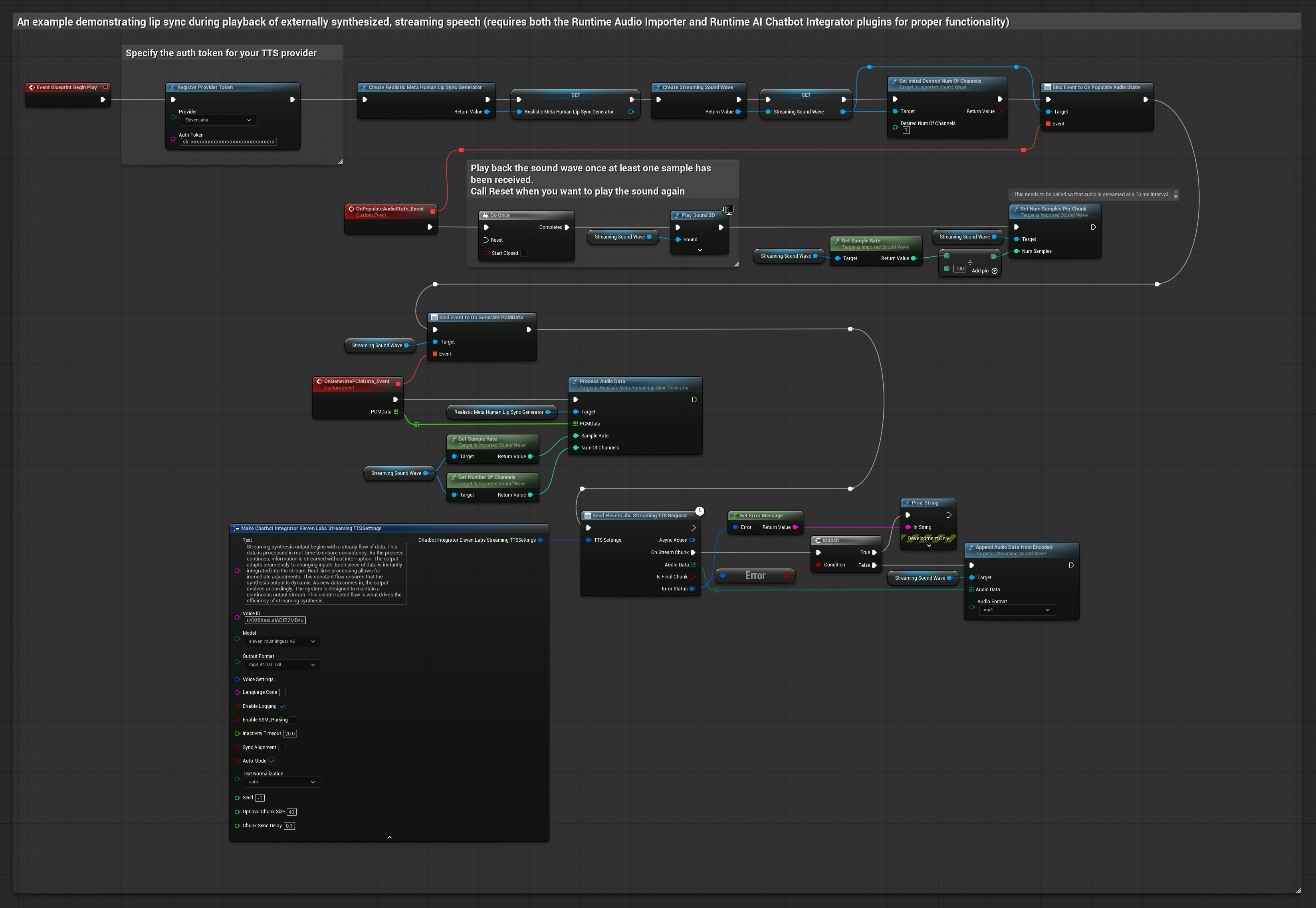
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
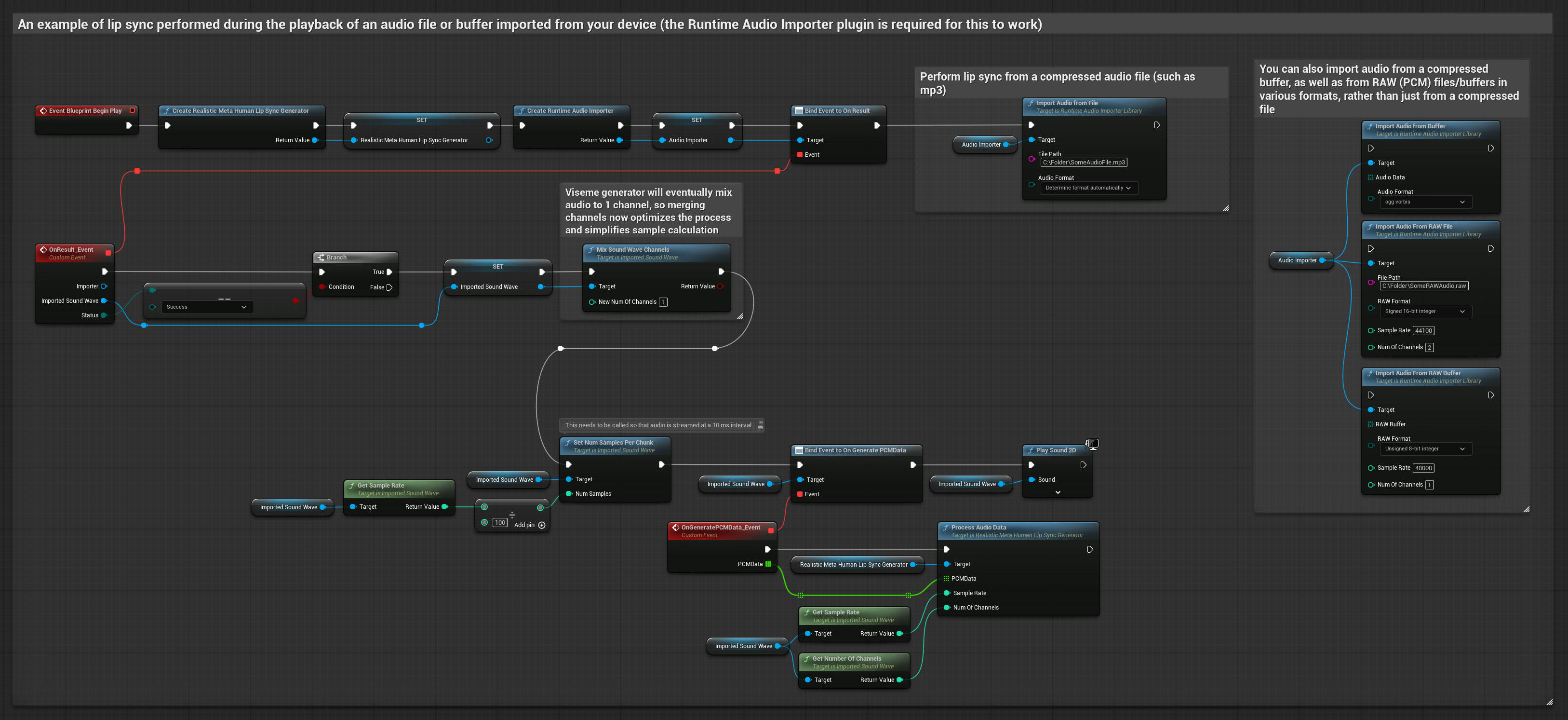
Questo approccio utilizza file audio preregistrati o buffer audio per il lip sync:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Usa Runtime Audio Importer per importare un file audio dal disco o dalla memoria
- Prima di riprodurre la sound wave importata, collega il suo delegato
OnGeneratePCMData - Nella funzione collegata, chiama
ProcessAudioDatadal tuo Runtime Viseme Generator - Riproduci la sound wave importata e osserva l'animazione del lip sync
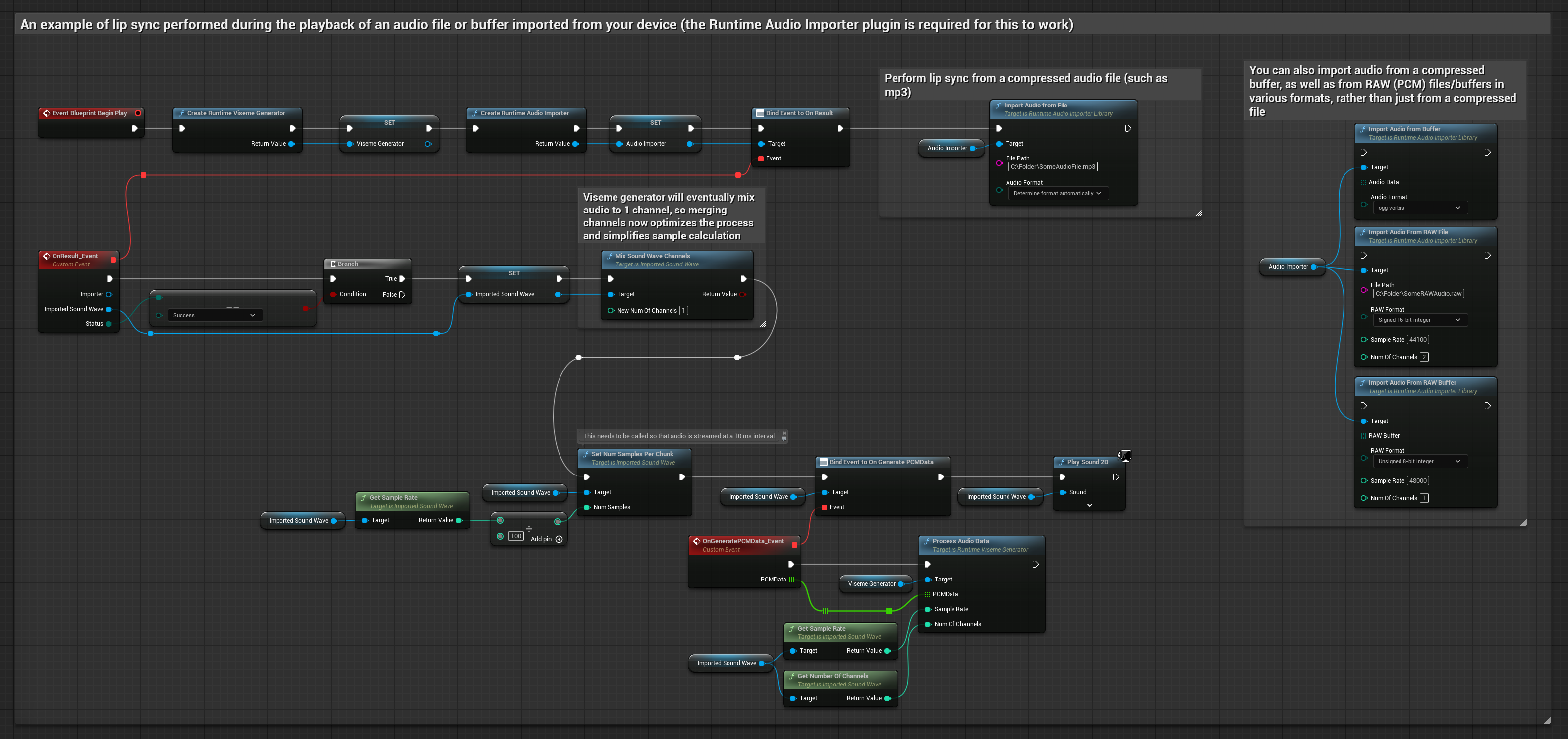
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.
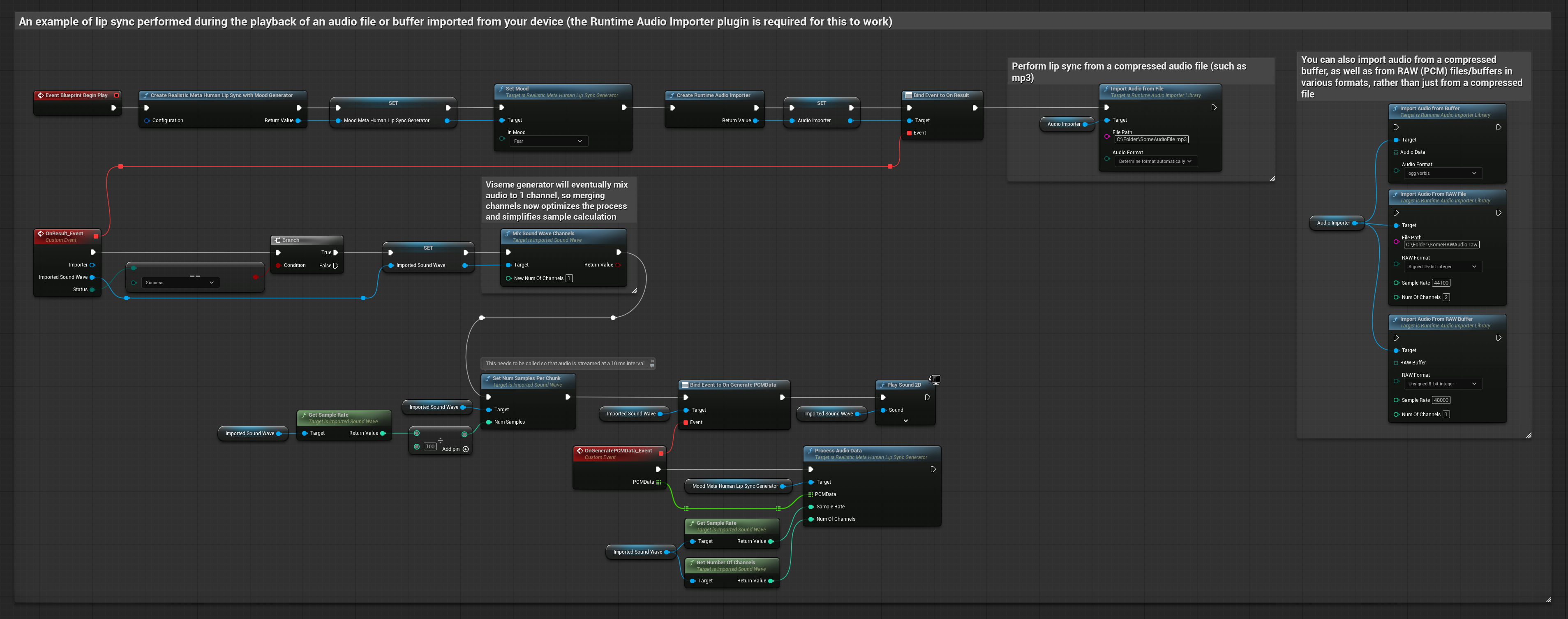
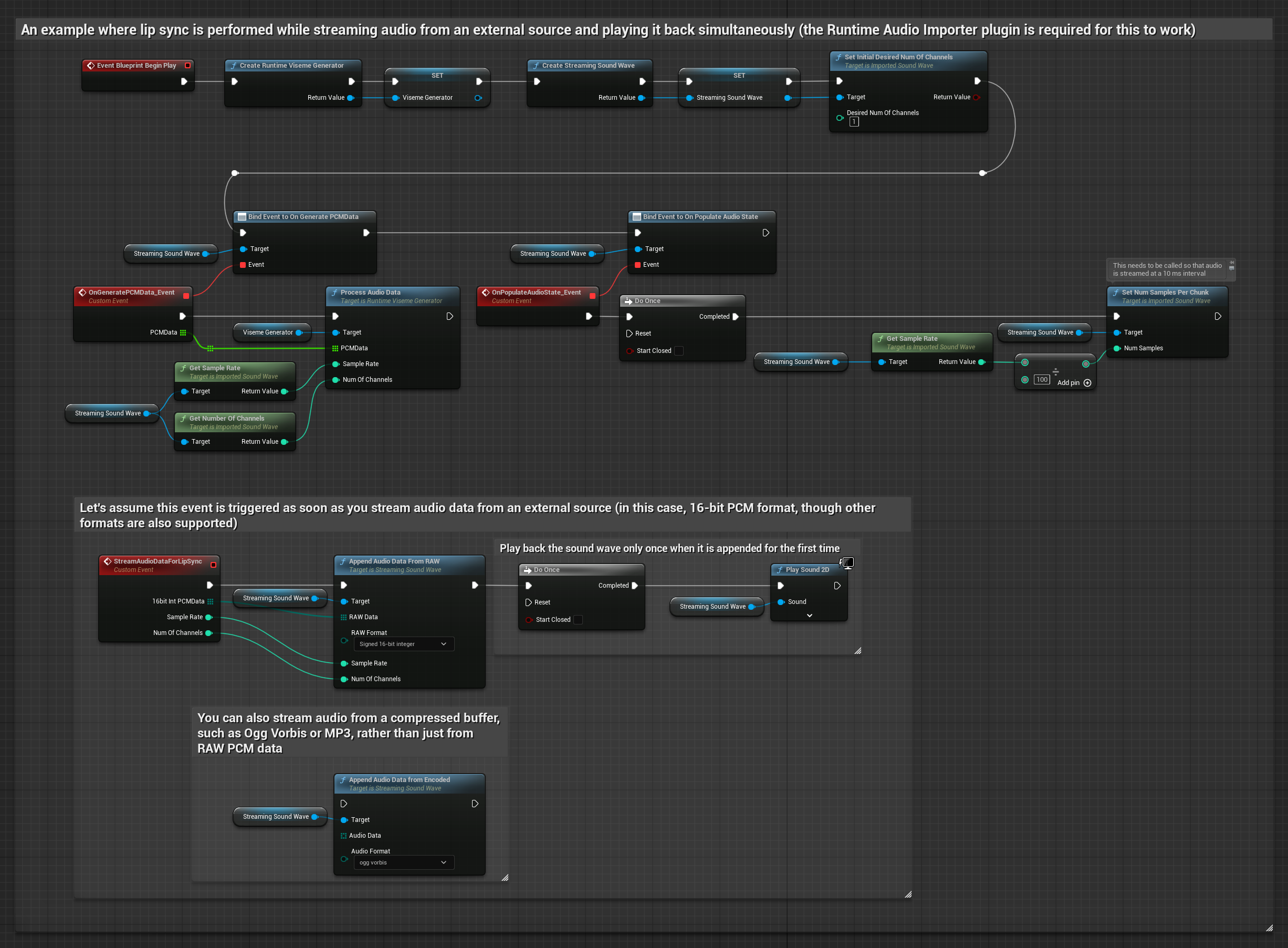
Per dati audio in streaming da un buffer, hai bisogno di:
- Modello Standard
- Modello Realistico
- Modello Realistico con Mood
- Dati audio in formato PCM float (un array di campioni in virgola mobile) disponibili dalla tua sorgente in streaming (o usa Runtime Audio Importer per supportare più formati)
- La frequenza di campionamento e il numero di canali
- Chiama
ProcessAudioDatadal tuo Runtime Viseme Generator con questi parametri man mano che i chunk audio diventano disponibili
Il Modello Realistico utilizza lo stesso flusso di lavoro di elaborazione audio del Modello Standard, ma con la variabile RealisticLipSyncGenerator invece di VisemeGenerator.
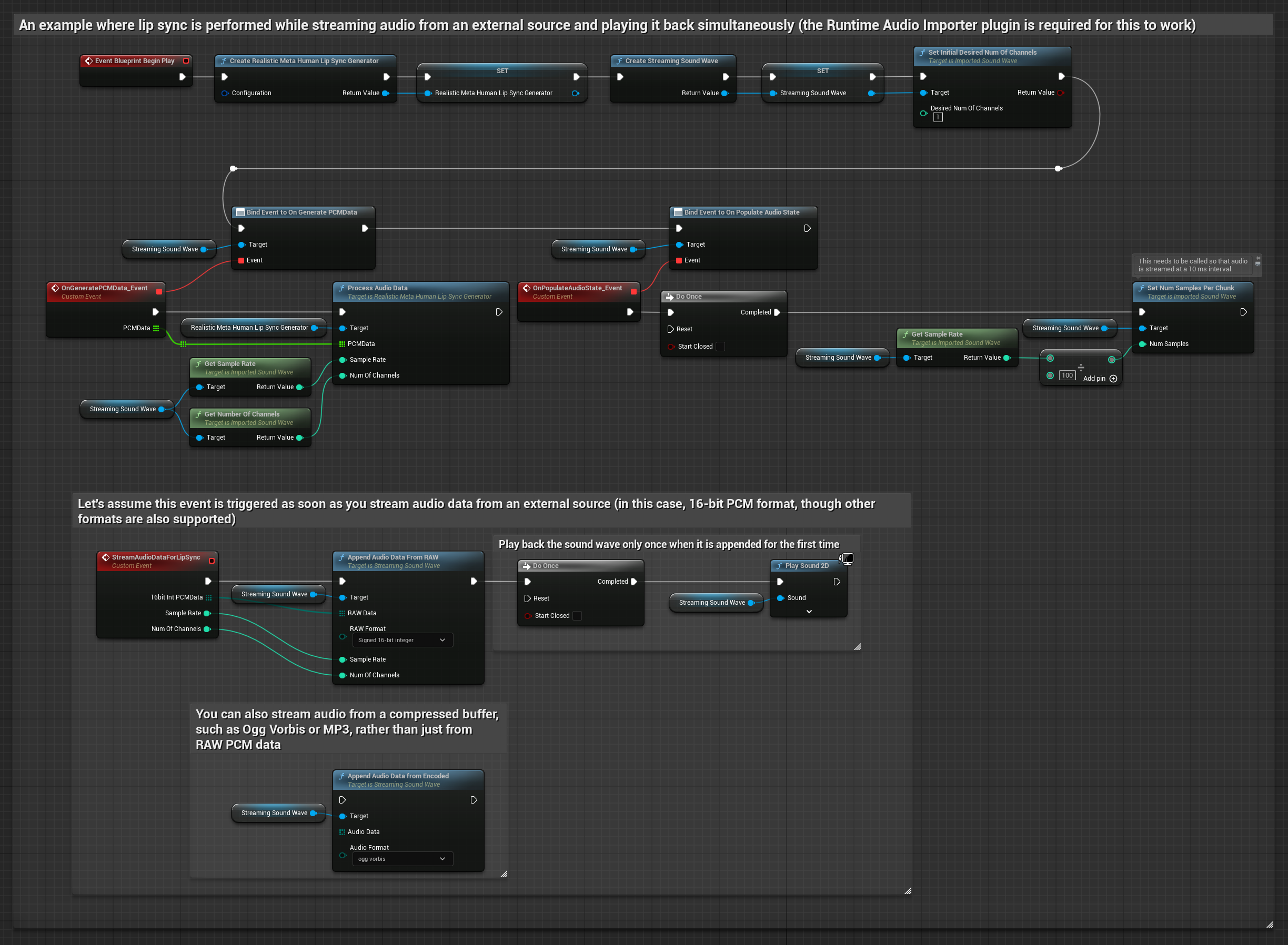
Il Modello con Mood utilizza lo stesso flusso di lavoro di elaborazione audio, ma con la variabile MoodMetaHumanLipSyncGenerator e capacità aggiuntive di configurazione del mood.

Nota: Quando si utilizzano sorgenti audio in streaming, assicurati di gestire appropriatamente i tempi di riproduzione audio per evitare riproduzioni distorte. Vedi la documentazione di Streaming Sound Wave per maggiori informazioni.
Suggerimenti per le Prestazioni di Elaborazione
-
Dimensione del Chunk: Aumentare l'opzione di configurazione
ProcessingChunkSizeconfiguration option (es. a 320, 480, o 640 campioni) può migliorare notevolmente la latenza con un impatto minimo sulla qualità o sulla reattività. -
Tipo di Modello: Quando si utilizzano modelli Realistic, passare al tipo di modello Altamente Ottimizzato (selezionato di default) può migliorare le prestazioni. Nota che il modello originale può produrre una qualità leggermente migliore, specialmente con audio rumoroso.
-
Gestione del Buffer: Il modello con mood elabora l'audio in frame da 320 campioni (20ms a 16kHz). Assicurati che la tempistica del tuo input audio sia allineata a questo per prestazioni ottimali.
-
Ricreazione del Generatore: Per un funzionamento affidabile con i modelli Realistic, ricrea il generatore ogni volta che vuoi fornire nuovi dati audio dopo un periodo di inattività.
Prossimi Passi
Una volta configurata l'elaborazione audio, potresti voler:
- Informarti sulle opzioni di Configurazione per ottimizzare il comportamento del tuo lip sync
- Aggiungere animazione della risata per una maggiore espressività
- Combinare il lip sync con animazioni facciali esistenti utilizzando le tecniche di stratificazione descritte nella guida di Configurazione