Progetti Demo
Per aiutarti a iniziare rapidamente con Runtime MetaHuman Lip Sync, sono disponibili due progetti demo pronti all'uso. Entrambi sono realizzati con Unreal Engine 5.6+, sono solo Blueprint e funzionano multipiattaforma su Windows, Mac, Linux, iOS, Android e piattaforme basate su Android (incluso Meta Quest).
Progetti Demo Disponibili
- AI NPC conversazionale / Avatar interattivo
- Demo Base di Lip Sync
Un flusso di lavoro completo AI per avatar conversazionali che combina riconoscimento vocale, un chatbot AI (LLM), sintesi vocale e riproduzione audio con sincronizzazione labiale in tempo reale, il tutto in esecuzione in un unico progetto. Adatto a una vasta gamma di casi d'uso, tra cui chioschi interattivi, produzione virtuale, installazioni museali, assistenti digitali, simulazioni di formazione e giochi.
Panoramica della Pipeline
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
Video
Anteprima rapida (~30 sec)
Una breve dimostrazione della demo in azione.
Procedura dettagliata
Una procedura dettagliata che copre installazione, configurazione e l'intera pipeline conversazionale.
Download
Plugin necessari e opzionali
Il progetto demo è modulare – servono solo i plugin per i provider che si desidera utilizzare.
| Plugin | Scopo | Necessario? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animazione labiale sincronizzata | ✅ Sempre |
| Runtime Audio Importer | Cattura ed elaborazione audio | ✅ Sempre |
| Runtime Speech Recognizer | Riconoscimento vocale offline (whisper.cpp) | ✅ Sempre |
| Runtime AI Chatbot Integrator | LLM esterni (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) e/o TTS esterni (OpenAI, ElevenLabs) | 🔶 Opzionale |
| Runtime Local LLM | Inferenza LLM locale tramite llama.cpp (Llama, Mistral, Gemma, ecc., modelli GGUF) | 🔶 Opzionale |
| Runtime Text To Speech | TTS locale tramite Piper e Kokoro | 🔶 Opzionale |
Anche se ogni plugin sopra elencato è singolarmente opzionale, è necessario almeno un provider LLM e almeno un provider TTS affinché la demo funzioni. Mescola e abbina liberamente (ad es. LLM locale + TTS ElevenLabs, oppure LLM OpenAI + TTS locale).
Architettura modulare
Nella cartella Content troverai una cartella Modules che contiene tre sottocartelle:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
Se non hai acquisito uno (o più) dei plugin opzionali, elimina semplicemente le cartelle corrispondenti. Le risorse base del progetto demo (istanza del gioco, widget, ecc.) non fanno riferimento diretto a questi moduli, quindi eliminarli non causerà errori di riferimento. L'interfaccia di configurazione nasconderà automaticamente qualsiasi provider la cui cartella sia assente.
Questa modularità si applica solo ai provider LLM e TTS. Il Riconoscimento Vocale (Runtime Speech Recognizer) e il Lip Sync (Runtime MetaHuman Lip Sync) fanno parte del progetto demo base e sono sempre richiesti.
Al primo avvio, Unreal potrebbe chiedere se disabilitare eventuali plugin opzionali mancanti - fai clic su Sì. Assicurati di aver eliminato anche la cartella Content/Modules/ corrispondente (vedi sopra).
Layout del Progetto Demo
L'interfaccia utente mostrata di seguito è interamente realizzata con UMG (Unreal Motion Graphics) ed è intesa esclusivamente per dimostrare la pipeline - riconoscimento vocale → LLM → TTS → Lip Sync. Sei libero di ridisegnarla o sostituirla per adattarla al design visivo del tuo progetto, allo schema di controllo o alla piattaforma (VR/AR, mobile, console, chiosco, ecc.). Se alcuni widget non sono necessari nel tuo caso d'uso, puoi anche semplicemente nasconderli (ad esempio impostando la loro visibilità su Collapsed o Hidden).

| Zona | Cosa c'è |
|---|---|
| Centro | Il personaggio MetaHuman. |
| Lato sinistro | Quattro pulsanti di configurazione (Riconoscimento Vocale, AI Chatbot, Text To Speech, Animazioni), descritti in dettaglio di seguito. |
| In basso al centro | Un pulsante Inizia Registrazione. Cliccalo per iniziare una conversazione vocale: il microfono viene catturato, trascritto, inviato al LLM, la risposta viene sintetizzata via TTS e riprodotta con lip sync, completamente senza mani. |
| Destra centro | Un widget cronologia conversazione che mostra l'intero scambio tra te e l'IA (messaggi sia dell'utente che dell'assistente). Include anche un campo di input testuale, in modo da poter digitare i messaggi direttamente senza usare il riconoscimento vocale, utile per test, accessibilità o quando non è disponibile un microfono. |
Puoi alternare liberamente entrambe le modalità di input nella stessa sessione - parlare alcuni messaggi, digitarne altri.
Pulsanti di Configurazione
I quattro pulsanti di configurazione a sinistra aprono pannelli dedicati per ciascuna parte della pipeline:
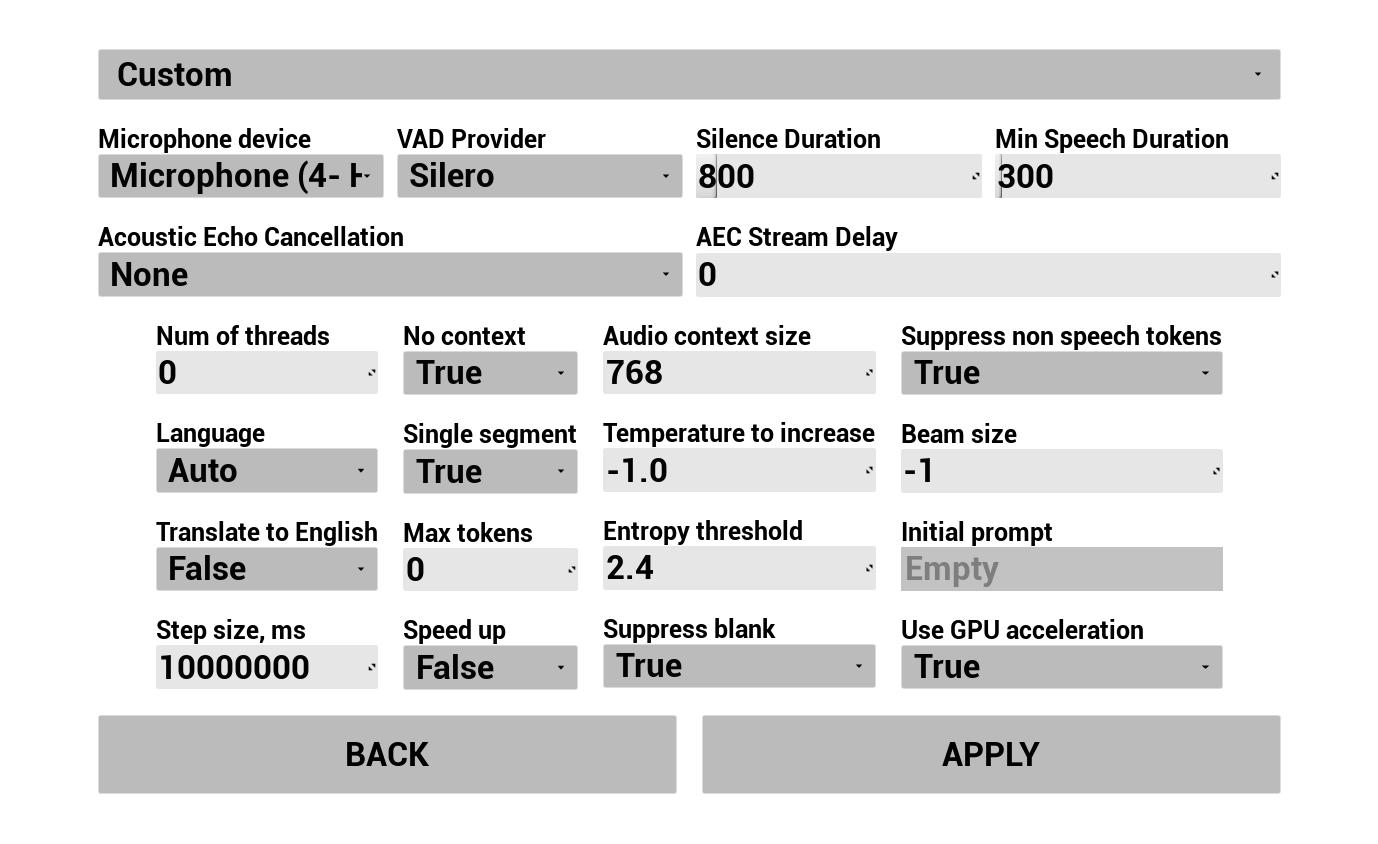
1. Configura Riconoscimento Vocale
Configura come la voce dell'utente viene catturata e trascritta:
- Seleziona la lingua
- Regola i parametri di riconoscimento vocale (impostazioni del modello Whisper)
- Configura AEC (Acoustic Echo Cancellation)
- Configura VAD (Voice Activity Detection)
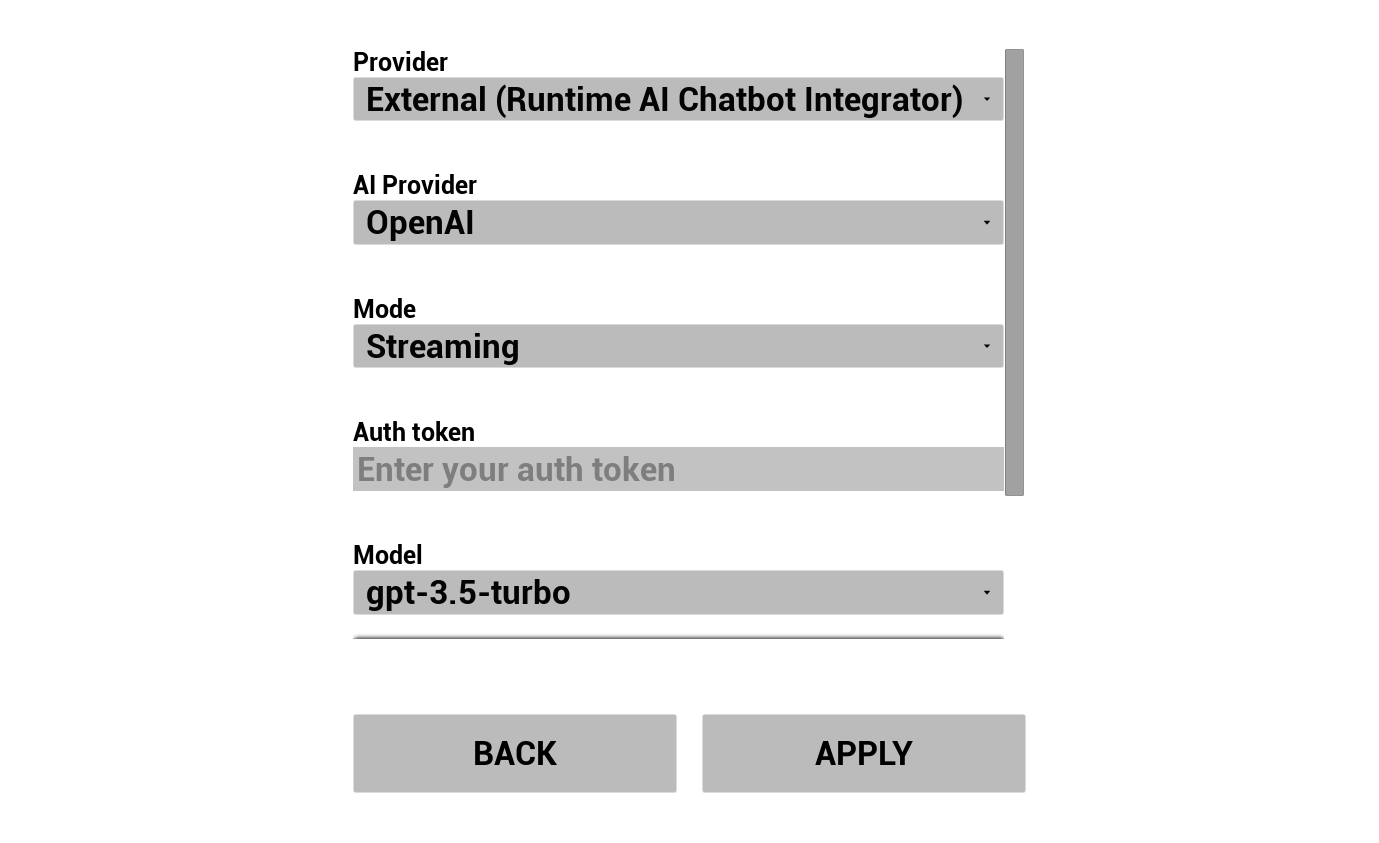
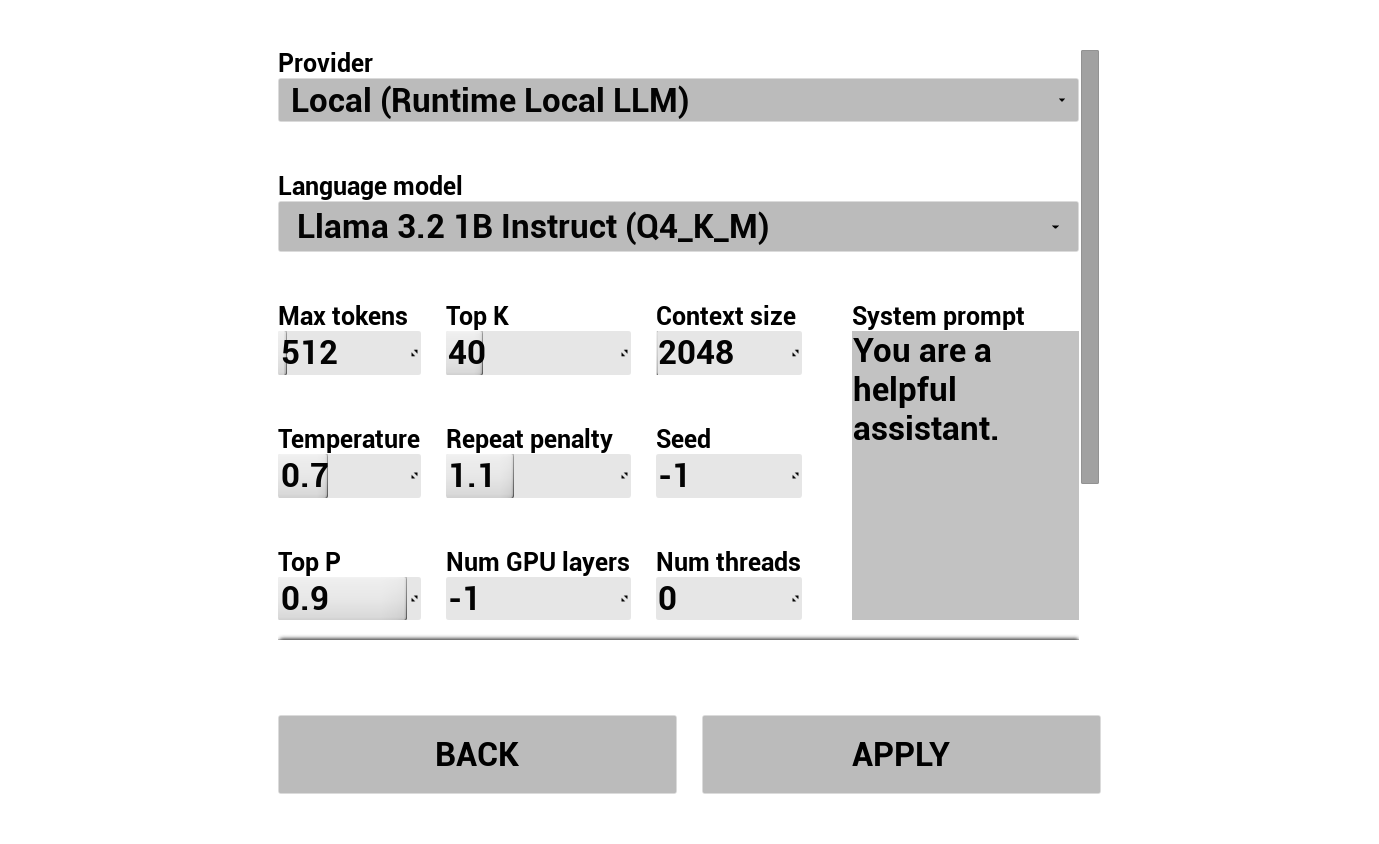
2. Configura AI Chatbot
Scegli il tuo provider LLM e configuralo:
- Seleziona provider (Runtime AI Chatbot Integrator o Runtime Local LLM)
- Per provider esterni: token di autenticazione, nome modello, ecc.
- Per LLM locale: seleziona un modello GGUF, imposta la dimensione del contesto e altri parametri di inferenza. Puoi anche scaricare il tuo modello GGUF in runtime direttamente dalla demo (ad esempio tramite URL) e utilizzarlo immediatamente senza ricompilare il progetto.
Il combobox dei provider mostra solo i provider la cui cartella del modulo del plugin è presente in Content/Modules/.
3. Configura Text To Speech
Scegli il tuo provider TTS e configura le voci/modelli:
- Seleziona provider (Runtime AI Chatbot Integrator per OpenAI/ElevenLabs, o Runtime Text To Speech per locale Piper/Kokoro)
- Seleziona voce/modello
- Regola i parametri specifici del provider

4. Configura Animazioni
Controlla l'aspetto del tuo avatar AI:
- Scegli tra 3 personaggi MetaHuman pre-scaricati (Aera, Ada, Orlando)
- Seleziona il modello di lip sync (Standard o Realistic)
- Seleziona il tipo di modello lip sync - Altamente Ottimizzato, Semi-Ottimizzato o Originale (vedi Tipo di Modello)
- Regola la Dimensione del Chunk di Elaborazione - controlla la frequenza con cui viene eseguita l'inferenza del lip sync (vedi Dimensione Chunk di Elaborazione)
- Seleziona un'animazione inattiva da riprodurre sul MetaHuman durante la conversazione

Pre-configurazione della Demo nell'Editor
Quando lavori con la versione sorgente, puoi precompilare i valori predefiniti direttamente nell'editor in modo che non sia necessario reinserirli a ogni esecuzione:
| Cosa | Dove |
|---|---|
| Impostazioni generali (modello lip sync, animazione inattiva, classe del personaggio, riconoscimento vocale, ecc.) | Content/LipSyncSTSGameInstance |
| Impostazioni LLM Esterno / TTS Esterno (Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Impostazioni LLM Locale (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| Impostazioni TTS Locale (Runtime Text To Speech) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
Note sulla Compatibilità Multipiattaforma
Tutti i plugin utilizzati dalla demo supportano Windows, Mac, Linux, iOS, Android e piattaforme basate su Android (incluso Meta Quest), quindi il progetto demo funziona su tutte queste. Questo lo rende adatto per il deploy in una vasta gamma di ambienti — da chioschi desktop e esperienze basate su browser a app mobili, visori VR autonomi e configurazioni di produzione virtuale sul set.
Per dispositivi meno potenti (mobile, VR autonomo), potresti voler:
- Utilizzare il modello lip sync Standard invece di Realistic - vedi il confronto dei modelli
- Passare al tipo di modello Altamente Ottimizzato
- Aumentare la Dimensione del Chunk di Elaborazione per ridurre il carico della CPU
- Scegliere modelli LLM / TTS più piccoli
Consulta Configurazione specifica per piattaforma per ulteriori passaggi di configurazione su Android, iOS, Mac e Linux.
Portare il Proprio Personaggio
Il progetto demo fornisce tre personaggi MetaHuman di esempio (Aera, Ada, Orlando), ma puoi importare il tuo MetaHuman e utilizzarlo nella demo.
📺 Video tutorial: Aggiungere un Personaggio MetaHuman Personalizzato al Progetto Demo
Il plugin Runtime MetaHuman Lip Sync stesso supporta molti altri sistemi di personaggi oltre ai MetaHuman (personaggi basati su ARKit, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe, ecc. - vedi la Guida alla Configurazione di Personaggi Personalizzati). Che tu stia costruendo un NPC per un gioco, un presentatore virtuale, un assistente per chiosco o un umano digitale per produzione virtuale, il plugin si adatta alla tua pipeline di personaggi.
Un progetto demo più semplice che si concentra esclusivamente sulla funzionalità lip sync in sé, senza l'intero flusso di lavoro conversazionale AI. Adatto se vuoi solo vedere il lip sync in azione con diverse sorgenti audio.
Video in Evidenza
Download
Cosa è Incluso
Questa demo mostra i flussi di lavoro di base del lip sync:
- Input da microfono - lip sync in tempo reale da audio dal vivo
- Riproduzione di file audio - lip sync da file audio importati
- Text-to-Speech - lip sync guidato da parlato sintetizzato
Plugin Richiesti e Opzionali
| Plugin | Scopo | Richiesto? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Animazione labiale | ✅ Richiesto |
| Runtime Audio Importer | Importazione e cattura audio | ✅ Richiesto |
| Runtime Text To Speech | TTS locale per la scena demo TTS | 🔶 Opzionale |
| Runtime AI Chatbot Integrator | Provider TTS esterni (OpenAI, ElevenLabs) | 🔶 Opzionale |
Note per il Modello di Lip Sync Standard
Se prevedi di utilizzare il Modello Standard (invece di Realistic) in uno dei progetti demo, dovrai installare il plugin Standard Lip Sync Extension. Consulta Estensione Modello Standard per le istruzioni di installazione.
Hai bisogno di aiuto?
Se incontri problemi durante la configurazione o l'esecuzione dei progetti demo, non esitare a contattarci:
Per richieste di sviluppo personalizzato (ad es. estendere la demo con la propria logica, adattarla per una piattaforma specifica o per una pipeline di personaggi), contatta [email protected].