Configurazione del Plugin
Configurazione del Modello
Configurazione del Modello Standard
Il nodo Create Runtime Viseme Generator utilizza impostazioni predefinite che funzionano bene per la maggior parte degli scenari. La configurazione viene gestita attraverso le proprietà del nodo di blending dell'Animation Blueprint.
Per le opzioni di configurazione dell'Animation Blueprint, consultare la sezione Configurazione Lip Sync di seguito.
Configurazione del Modello Realistico
Il nodo Create Realistic MetaHuman Lip Sync Generator accetta un parametro opzionale Configuration che consente di personalizzare il comportamento del generatore:
Tipo di Modello
L'impostazione Model Type determina quale versione del modello realistico utilizzare:
| Tipo di Modello | Prestazioni | Qualità Visiva | Gestione del Rumore | Casi d'Uso Consigliati |
|---|---|---|---|---|
| Altamente Ottimizzato (Predefinito) | Prestazioni più elevate, utilizzo CPU più basso | Buona qualità | Può mostrare movimenti della bocca evidenti con rumore di fondo o suoni non vocali | Ambienti audio puliti, scenari critici per le prestazioni |
| Semi-Ottimizzato | Buone prestazioni, utilizzo CPU moderato | Alta qualità | Maggiore stabilità con audio rumoroso | Bilanciamento prestazioni/qualità, condizioni audio miste |
| Originale | Adatto per l'uso in tempo reale su CPU moderne | Qualità più alta | Maggiore stabilità con rumore di fondo e suoni non vocali | Produzioni di alta qualità, ambienti audio rumorosi, quando è necessaria la massima precisione |
Impostazioni di Prestazione
Intra Op Threads: Controlla il numero di thread utilizzati per le operazioni di elaborazione interna del modello.
- 0 (Predefinito/Automatico): Utilizza il rilevamento automatico (tipicamente 1/4 dei core CPU disponibili, massimo 4)
- 1-16: Specifica manualmente il numero di thread. Valori più alti possono migliorare le prestazioni su sistemi multi-core ma utilizzano più CPU
Inter Op Threads: Controlla il numero di thread utilizzati per l'esecuzione parallela di diverse operazioni del modello.
- 0 (Predefinito/Automatico): Utilizza il rilevamento automatico (tipicamente 1/8 dei core CPU disponibili, massimo 2)
- 1-8: Specifica manualmente il numero di thread. Di solito mantenuto basso per l'elaborazione in tempo reale
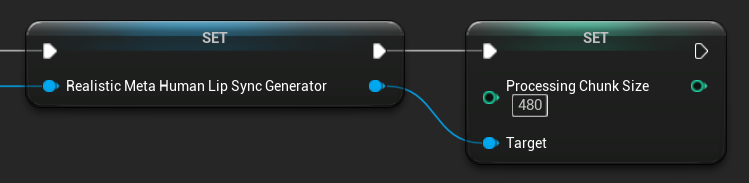
Dimensione del Blocco di Elaborazione
La Processing Chunk Size determina quanti campioni vengono elaborati in ogni passaggio di inferenza. Il valore predefinito è 160 campioni (10ms di audio a 16kHz):
- Valori più piccoli forniscono aggiornamenti più frequenti ma aumentano l'utilizzo della CPU
- Valori più grandi riducono il carico sulla CPU ma possono diminuire la reattività del lip sync
- Si consiglia di utilizzare multipli di 160 per un allineamento ottimale
Configurazione del Modello con Umore
Il nodo Create Realistic MetaHuman Lip Sync With Mood Generator fornisce opzioni di configurazione aggiuntive oltre al modello realistico di base:
Configurazione di Base
Lookahead Ms: Tempo di anticipo in millisecondi per una migliore precisione del lip sync.
- Predefinito: 80ms
- Intervallo: 20ms a 200ms (deve essere divisibile per 20)
- Valori più alti forniscono una migliore sincronizzazione ma aumentano la latenza
Output Type: Controlla quali controlli facciali vengono generati.
- Full Face: Tutti gli 81 controlli facciali (sopracciglia, occhi, naso, bocca, mascella, lingua)
- Mouth Only: Solo i controlli relativi a bocca, mascella e lingua
Performance Settings: Utilizza le stesse impostazioni Intra Op Threads e Inter Op Threads del modello realistico regolare.
Impostazioni dell'Umore
Umidi Disponibili:
- Neutrale, Felice, Triste, Disgusto, Rabbia, Sorpresa, Paura
- Sicuro, Eccitato, Annoiato, Giocoso, Confuso
Intensità dell'Umore: Controlla quanto fortemente l'umore influisce sull'animazione (da 0.0 a 1.0)
Controllo dell'Umore in Runtime
È possibile regolare le impostazioni dell'umore durante il runtime utilizzando le seguenti funzioni:
- Set Mood: Cambia il tipo di umore corrente
- Set Mood Intensity: Regola quanto fortemente l'umore influisce sull'animazione (da 0.0 a 1.0)
- Set Lookahead Ms: Modifica il tempo di anticipo per la sincronizzazione
- Set Output Type: Passa tra i controlli Full Face e Mouth Only

Guida alla Selezione dell'Umore
Scegli umori appropriati in base al tuo contenuto:
| Umore | Ideale Per | Intervallo Tipico di Intensità |
|---|---|---|
| Neutrale | Conversazione generale, narrazione, stato predefinito | 0.5 - 1.0 |
| Felice | Contenuti positivi, dialoghi allegri, celebrazioni | 0.6 - 1.0 |
| Triste | Contenuti malinconici, scene emotive, momenti cupi | 0.5 - 0.9 |
| Disgusto | Reazioni negative, contenuti sgradevoli, rifiuto | 0.4 - 0.8 |
| Rabbia | Dialoghi aggressivi, scene di confronto, frustrazione | 0.6 - 1.0 |
| Sorpresa | Eventi inaspettati, rivelazioni, reazioni di shock | 0.7 - 1.0 |
| Paura | Situazioni minacciose, ansia, dialoghi nervosi | 0.5 - 0.9 |
| Sicuro | Presentazioni professionali, dialoghi di leadership, discorsi assertivi | 0.7 - 1.0 |
| Eccitato | Contenuti energici, annunci, dialoghi entusiastici | 0.8 - 1.0 |
| Annoiato | Contenuti monotoni, dialoghi disinteressati, discorsi stanchi | 0.3 - 0.7 |
| Giocoso | Conversazioni informali, umorismo, interazioni spensierate | 0.6 - 0.9 |
| Confuso | Dialoghi ricchi di domande, incertezza, sconcerto | 0.4 - 0.8 |
Configurazione dell'Animation Blueprint
Configurazione del Lip Sync
- Standard Model
- Modelli Realistici
Il nodo Blend Runtime MetaHuman Lip Sync ha opzioni di configurazione nel suo pannello delle proprietà:
| Proprietà | Predefinito | Descrizione |
|---|---|---|
| Interpolation Speed | 25 | Controlla la velocità con cui i movimenti delle labbra transitano tra i visemi. Valori più alti risultano in transizioni più veloci e brusche. |
| Reset Time | 0.2 | La durata in secondi dopo la quale il lip sync viene ripristinato. Utile per evitare che il lip sync continui dopo che l'audio si è fermato. |
Animazione della Risata
Puoi anche aggiungere animazioni della risata che risponderanno dinamicamente alle risate rilevate nell'audio:
- Aggiungi il nodo
Blend Runtime MetaHuman Laughter - Collega la tua variabile
RuntimeVisemeGeneratoral pinViseme Generator - Se stai già utilizzando il lip sync:
- Collega l'output dal nodo
Blend Runtime MetaHuman Lip SyncalSource Posedel nodoBlend Runtime MetaHuman Laughter - Collega l'output del nodo
Blend Runtime MetaHuman Laughteral pinResultdell'Output Pose
- Collega l'output dal nodo
- Se utilizzi solo la risata senza lip sync:
- Collega la tua posa sorgente direttamente al
Source Posedel nodoBlend Runtime MetaHuman Laughter - Collega l'output al pin
Result
- Collega la tua posa sorgente direttamente al
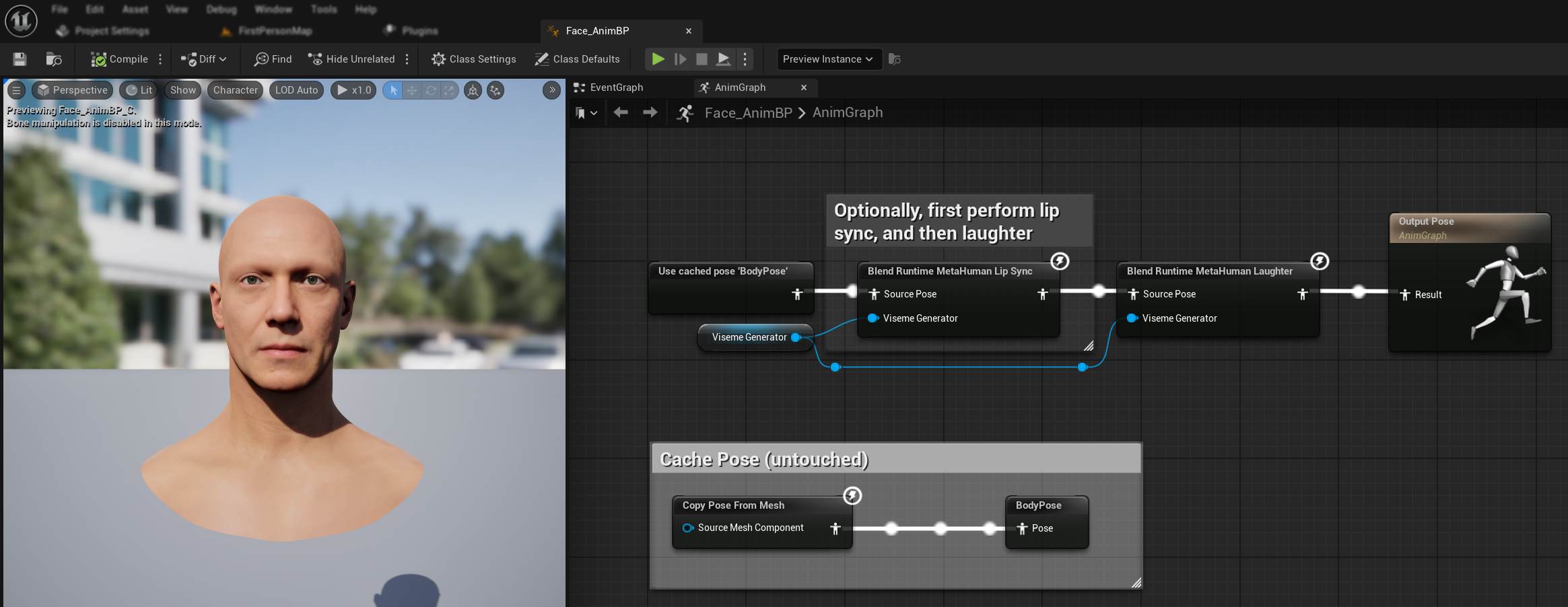
Quando viene rilevata una risata nell'audio, il tuo personaggio si animerà dinamicamente di conseguenza:
Configurazione della Risata
Il nodo Blend Runtime MetaHuman Laughter ha le sue opzioni di configurazione:
| Proprietà | Default | Descrizione |
|---|---|---|
| Velocità di Interpolazione | 25 | Controlla la rapidità con cui i movimenti delle labbra passano tra le animazioni della risata. Valori più alti risultano in transizioni più veloci e brusche. |
| Tempo di Reset | 0.2 | La durata in secondi dopo la quale la risata viene resettata. Utile per evitare che la risata continui dopo che l'audio si è fermato. |
| Peso Massimo della Risata | 0.7 | Scala l'intensità massima dell'animazione della risata (0.0 - 1.0). |
Nota: Il rilevamento della risata è attualmente disponibile solo con il Modello Standard.
Il nodo Blend Realistic MetaHuman Lip Sync ha opzioni di configurazione nel suo pannello delle proprietà:
| Proprietà | Default | Descrizione |
|---|---|---|
| Velocità di Interpolazione | 30 | Controlla la rapidità con cui le espressioni facciali cambiano durante la parola attiva. Valori più alti risultano in transizioni più veloci e brusche. |
| Velocità di Interpolazione a Riposo | 15 | Controlla la rapidità con cui le espressioni facciali ritornano allo stato di riposo/neutro. Valori più bassi creano ritorni più fluidi e graduali alla posa di riposo. |
| Tempo di Reset | 0.2 | Durata in secondi dopo la quale il lip sync si resetta allo stato di riposo. Utile per evitare che le espressioni continuino dopo che l'audio si è fermato. |
| Preserva Stato di Riposo | false | Se abilitato, preserva l'ultimo stato emotivo durante i periodi di inattività invece di resettare al neutro. |
| Preserva Espressioni degli Occhi | true | Controlla se i controlli facciali relativi agli occhi vengono preservati durante lo stato di riposo. Efficace solo quando Preserva Stato di Riposo è abilitato. |
| Preserva Espressioni delle Sopracciglia | true | Controlla se i controlli facciali relativi alle sopracciglia vengono preservati durante lo stato di riposo. Efficace solo quando Preserva Stato di Riposo è abilitato. |
| Preserva Forma della Bocca | false | Controlla se i controlli della forma della bocca (esclusi i movimenti specifici del parlato come lingua e mandibola) vengono preservati durante lo stato di riposo. Efficace solo quando Preserva Stato di Riposo è abilitato. |
Preservazione dello Stato di Riposo
La funzionalità Preserva Stato di Riposo affronta il modo in cui il modello Realistico gestisce i periodi di silenzio. A differenza del modello Standard che utilizza visemi discreti e ritorna costantemente a valori zero durante il silenzio, la rete neurale del modello Realistico può mantenere un posizionamento facciale sottile che differisce dalla posa di riposo predefinita del MetaHuman.
Quando Abilitare:
- Mantenere espressioni emotive tra segmenti di parlato
- Preservare i tratti della personalità del personaggio
- Garantire continuità visiva nelle sequenze cinematografiche
Opzioni di Controllo Regionale:
- Espressioni degli Occhi: Preserva lo strizzamento, l'allargamento degli occhi e il posizionamento delle palpebre
- Espressioni delle Sopracciglia: Mantiene il posizionamento delle sopracciglia e della fronte
- Forma della Bocca: Mantiene la curvatura generale della bocca permettendo ai movimenti del parlato (lingua, mandibola) di resettarsi
Combinazione con Animazioni Esistenti
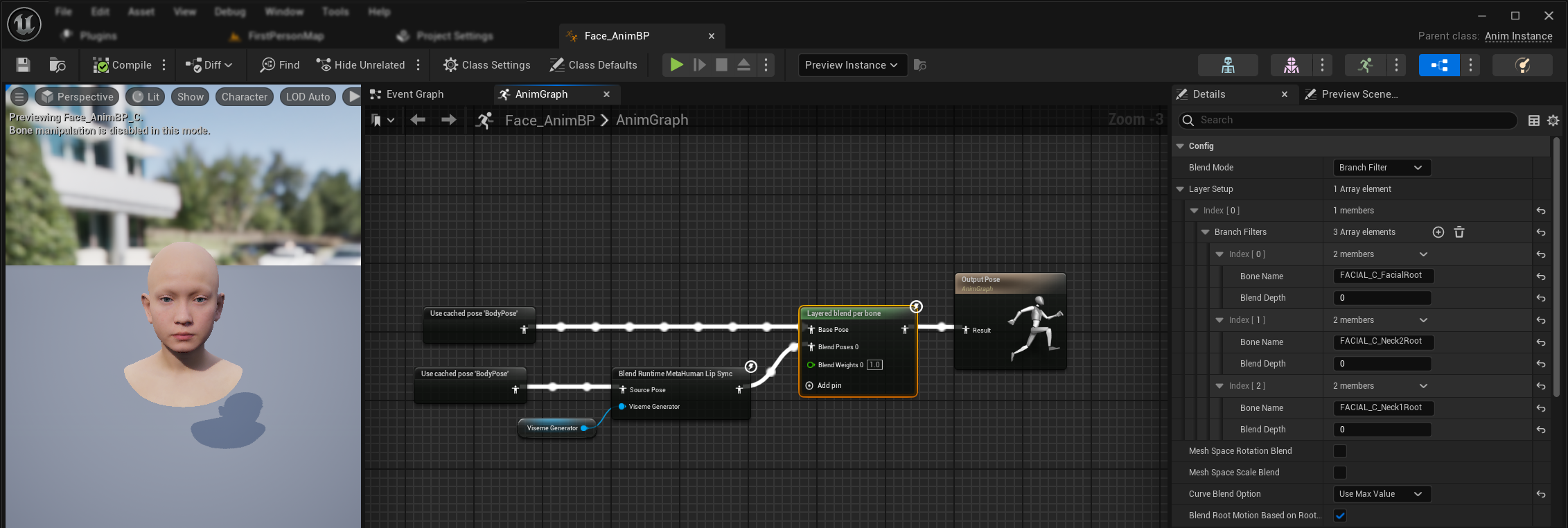
Per applicare il lip sync e la risata insieme ad animazioni corporee esistenti e animazioni facciali personalizzate senza sovrascriverle:
- Aggiungi un nodo
Layered blend per bonetra le tue animazioni corporee e l'output finale. Assicurati cheUse Attached Parentsia true. - Configura la struttura dei layer:
- Aggiungi 1 elemento all'array
Layer Setup - Aggiungi 3 elementi ai
Branch Filtersper il layer, con i seguentiBone Name:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Aggiungi 1 elemento all'array
- Importante per animazioni facciali personalizzate: In
Curve Blend Option, seleziona "Use Max Value". Questo permette alle animazioni facciali personalizzate (espressioni, emozioni, ecc.) di essere stratificate correttamente sopra il lip sync. - Effettua le connessioni:
- Animazioni esistenti (come
BodyPose) → inputBase Pose - Output dell'animazione facciale (dal nodo lip sync e/o risata) → input
Blend Poses 0 - Nodo layered blend → posa
Resultfinale
- Animazioni esistenti (come
Selezione del Set di Morph Target
- Modello Standard
- Modelli Realistici
Il Modello Standard utilizza asset di pose che supportano intrinsecamente qualsiasi convenzione di denominazione dei morph target attraverso la configurazione personalizzata dell'asset di pose. Non è necessaria alcuna configurazione aggiuntiva.
Il nodo Blend Realistic MetaHuman Lip Sync include una proprietà Morph Target Set che determina quale convenzione di denominazione dei morph target utilizzare per l'animazione facciale:
| Morph Target Set | Descrizione | Casi d'Uso |
|---|---|---|
| MetaHuman (Default) | Nomi standard dei morph target MetaHuman (es. CTRL_expressions_jawOpen) | Personaggi MetaHuman |
| ARKit | Nomi compatibili con Apple ARKit (es. JawOpen, MouthSmileLeft) | Personaggi basati su ARKit |
Affinamento del Comportamento del Lip Sync
Controllo della Protrusione della Lingua
Nel modello standard di lip sync, potresti notare un eccessivo movimento in avanti della lingua durante certi fonemi. Per controllare la protrusione della lingua:
- Dopo il tuo nodo di blend del lip sync, aggiungi un nodo
Modify Curve - Fai clic con il tasto destro sul nodo
Modify Curvee seleziona Add Curve Pin - Aggiungi un curve pin con il nome
CTRL_expressions_tongueOut - Imposta la proprietà Apply Mode del nodo su Scale
- Regola il parametro Value per controllare l'estensione della lingua (es. 0.8 per ridurre la protrusione del 20%)
Controllo dell'Apertura della Mandibola
Il lip sync realistico può produrre movimenti della mandibola eccessivamente reattivi a seconda del contenuto audio e dei requisiti visivi. Per regolare l'intensità dell'apertura della mandibola:
- Dopo il tuo nodo di blend del lip sync, aggiungi un nodo
Modify Curve - Fai clic con il tasto destro sul nodo
Modify Curvee seleziona Add Curve Pin - Aggiungi un curve pin con il nome
CTRL_expressions_jawOpen - Imposta la proprietà Apply Mode del nodo su Scale
- Regola il parametro Value per controllare l'ampiezza dell'apertura della mandibola (es. 0.9 per ridurre il movimento della mandibola del 10%)
Affinamento Specifico per Umore
Per i modelli abilitati all'umore, puoi affinare specifiche espressioni emotive:
Controllo delle Sopracciglia:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- Sollevamento della parte interna delle sopraccigliaCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- Sollevamento della parte esterna delle sopraccigliaCTRL_expressions_browDownL/CTRL_expressions_browDownR- Abbassamento delle sopracciglia
Controllo dell'Espressione degli Occhi:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Strizzamento degli occhiCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Sollevamento delle guance
Confronto e Selezione del Modello
Scelta tra i Modelli
Quando decidi quale modello di lip sync utilizzare per il tuo progetto, considera questi fattori:
| Considerazione | Modello Standard | Modello Realistico | Modello Realistico Abilitato all'Umore |
|---|---|---|---|
| Compatibilità del Personaggio | MetaHumans e tutti i tipi di personaggi personalizzati | Personaggi MetaHumans (e ARKit) | Personaggi MetaHumans (e ARKit) |
| Qualità Visiva | Buon lip sync con prestazioni efficienti | Realismo migliorato con movimenti della bocca più naturali | Realismo migliorato con espressioni emotive |
| Prestazioni | Ottimizzato per tutte le piattaforme inclusi mobile/VR | Requisiti di risorse più elevati | Requisiti di risorse più elevati |
| Funzionalità | 14 visemi, rilevamento della risata | 81 controlli facciali, 3 livelli di ottimizzazione | 81 controlli facciali, 12 umori, output configurabile |
| Supporto Piattaforma | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Casi d'Uso | Applicazioni generali, giochi, VR/AR, mobile | Esperienze cinematografiche, interazioni ravvicinate | Narrazione emotiva, interazione avanzata con i personaggi |
Compatibilità con la Versione del Motore
Se stai utilizzando Unreal Engine 5.2, i Modelli Realistici potrebbero non funzionare correttamente a causa di un bug nella libreria di ricampionamento di UE. Per gli utenti di UE 5.2 che necessitano di funzionalità di lip sync affidabili, si prega di utilizzare il Modello Standard.
Questo problema è specifico di UE 5.2 e non influisce sulle altre versioni del motore.
Raccomandazioni sulle Prestazioni
- Per la maggior parte dei progetti, il Modello Standard offre un eccellente equilibrio tra qualità e prestazioni
- Usa il Modello Realistico quando hai bisogno della massima fedeltà visiva per i personaggi MetaHuman
- Usa il Modello Realistico Abilitato all'Umore quando il controllo dell'espressione emotiva è importante per la tua applicazione
- Considera le capacità prestazionali della piattaforma target quando scegli tra i modelli
- Testa diversi livelli di ottimizzazione per trovare il miglior equilibrio per il tuo caso d'uso specifico
Risoluzione dei Problemi
Problemi Comuni
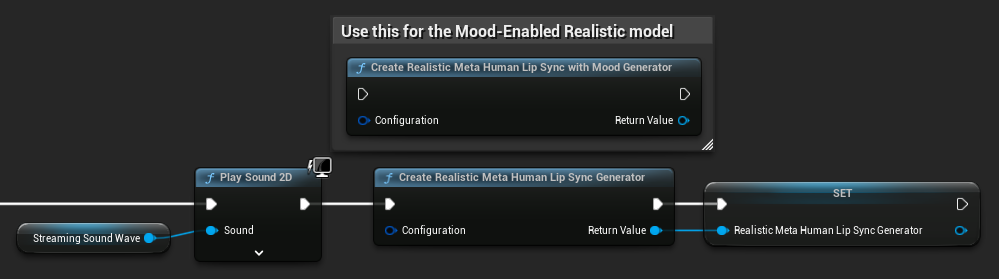
Ricreazione del Generatore per Modelli Realistici: Per un funzionamento affidabile e coerente con i Modelli Realistici, si consiglia di ricreare il generatore ogni volta che si desidera alimentare nuovi dati audio dopo un periodo di inattività. Ciò è dovuto al comportamento del runtime ONNX che può causare l'arresto del lip sync quando si riutilizzano generatori dopo periodi di silenzio.
Ad esempio, potresti ricreare il generatore di lip sync ad ogni avvio della riproduzione, come ogni volta che chiami Play Sound 2D o usi qualsiasi altro metodo per avviare la riproduzione di un'onda sonora e il lip sync:
Posizione del Plugin per l'Integrazione con Runtime Text To Speech: Quando si utilizza Runtime MetaHuman Lip Sync insieme a Runtime Text To Speech (entrambi i plugin utilizzano ONNX Runtime), potresti riscontrare problemi nelle build impacchettate se i plugin sono installati nella cartella Marketplace del motore. Per risolvere:
- Individua entrambi i plugin nella cartella di installazione di UE sotto
\Engine\Plugins\Marketplace(es.C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Sposta sia la cartella
RuntimeMetaHumanLipSynccheRuntimeTextToSpeechnella cartellaPluginsdel tuo progetto - Se il tuo progetto non ha una cartella
Plugins, creane una nella stessa directory del file.uproject - Riavvia l'Unreal Editor
Questo risolve i problemi di compatibilità che possono verificarsi quando più plugin basati su ONNX Runtime vengono caricati dalla directory Marketplace del motore.
Configurazione del Packaging (Windows): Se il lip sync non funziona correttamente nel tuo progetto impacchettato su Windows, assicurati di utilizzare la configurazione di build Shipping invece di Development. La configurazione Development può causare problemi con il runtime ONNX dei modelli realistici nelle build impacchettate.
Per risolvere:
- Nelle Impostazioni del Progetto → Packaging, imposta la Build Configuration su Shipping
- Ripacchetta il tuo progetto
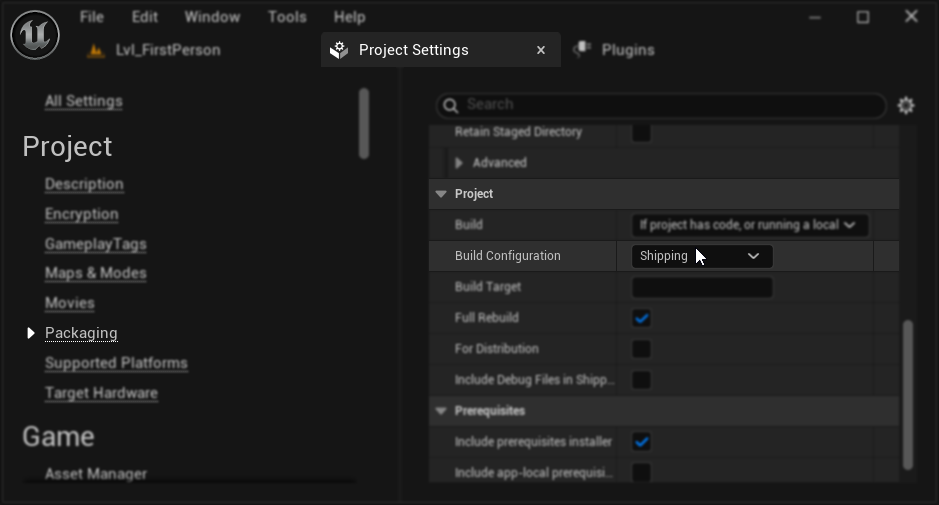
In alcuni progetti solo Blueprint, Unreal Engine potrebbe comunque compilare in configurazione Development anche quando Shipping è selezionata. Se ciò accade, converti il tuo progetto in un progetto C++ aggiungendo almeno una classe C++ (può essere vuota). Per farlo, vai su Tools → New C++ Class nel menu dell'editor UE e crea una classe vuota. Questo forzerà il progetto a compilare correttamente in configurazione Shipping. Il tuo progetto può rimanere solo Blueprint a livello funzionale, la classe C++ è necessaria solo per la corretta configurazione di build.
Responsività Degradata del Lip Sync: Se riscontri che il lip sync diventa meno reattivo nel tempo quando si utilizza Streaming Sound Wave o Capturable Sound Wave, ciò potrebbe essere causato dall'accumulo di memoria. Per impostazione predefinita, la memoria viene riallocata ogni volta che viene aggiunto nuovo audio. Per prevenire questo problema, chiama periodicamente la funzione ReleaseMemory per liberare la memoria accumulata, ad esempio ogni 30 secondi circa.
Ottimizzazione delle Prestazioni:
- Regola la Dimensione del Chunk di Elaborazione per i modelli realistici in base ai tuoi requisiti prestazionali
- Usa un numero appropriato di thread per il tuo hardware target
- Considera di utilizzare il tipo di output Mouth Only per i modelli abilitati all'umore quando l'animazione facciale completa non è necessaria