Come utilizzare il plugin
Il plugin Runtime Speech Recognizer è progettato per riconoscere parole dai dati audio in ingresso. Utilizza una versione leggermente modificata di whisper.cpp per funzionare con il motore. Per utilizzare il plugin, segui questi passaggi:
Lato editor
- Seleziona i modelli linguistici appropriati per il tuo progetto come descritto qui.
Lato runtime
- Crea un Speech Recognizer e imposta i parametri necessari (CreateSpeechRecognizer, per i parametri vedi qui).
- Collega i delegati necessari (OnRecognitionFinished, OnRecognizedTextSegment e OnRecognitionError).
- Avvia il riconoscimento vocale (StartSpeechRecognition).
- Elabora i dati audio e attendi i risultati dai delegati (ProcessAudioData).
- Ferma il riconoscitore vocale quando necessario (ad esempio, dopo la trasmissione di OnRecognitionFinished).
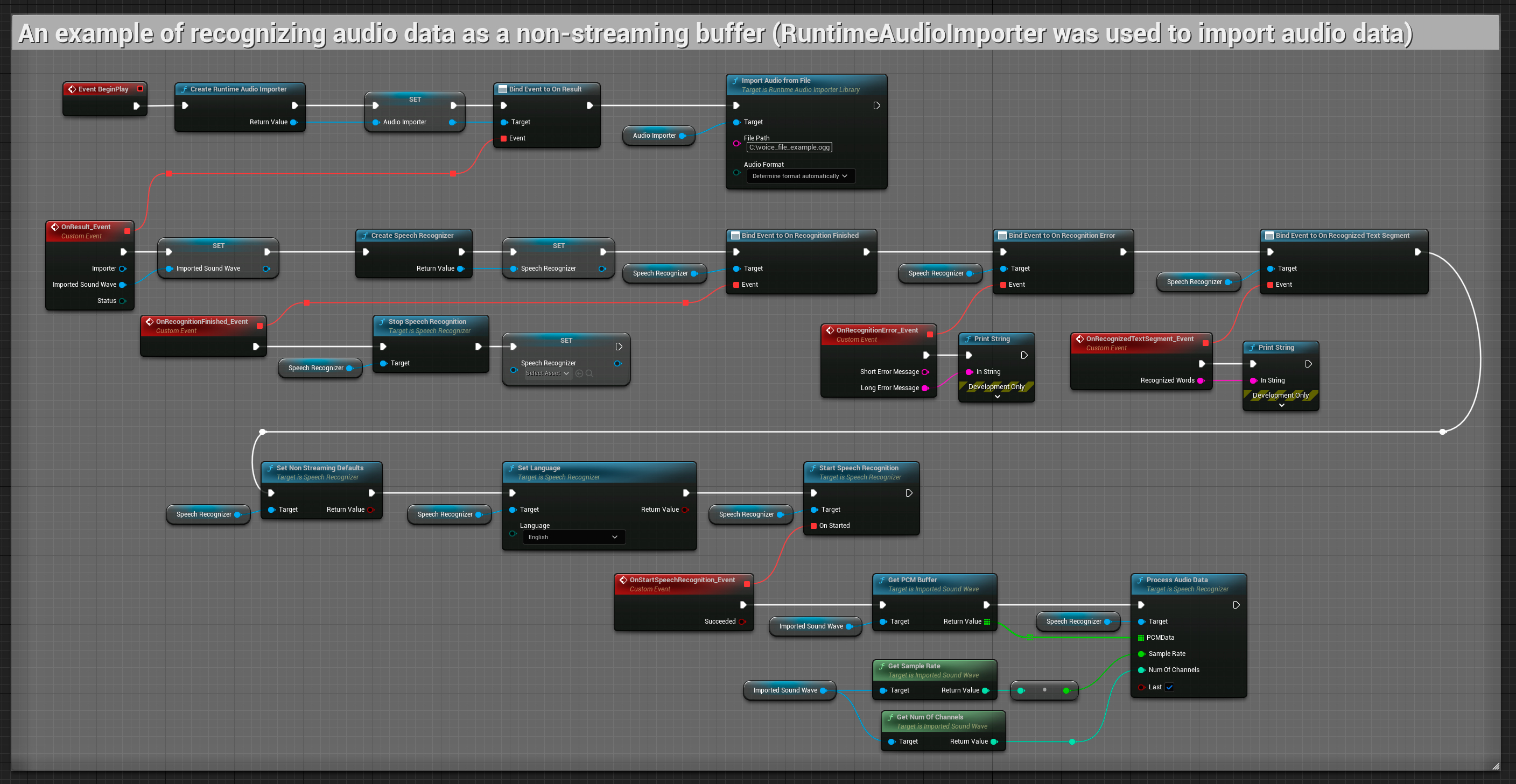
Il plugin supporta audio in ingresso nel formato PCM interleaved a 32 bit in virgola mobile. Sebbene funzioni bene con Runtime Audio Importer, non ne dipende direttamente.
Parametri di riconoscimento
Il plugin supporta il riconoscimento di dati audio sia in streaming che non in streaming. Per adattare i parametri di riconoscimento al tuo caso d'uso specifico, chiama SetStreamingDefaults o SetNonStreamingDefaults. Inoltre, hai la flessibilità di impostare manualmente parametri individuali come il numero di thread, la dimensione del passo, se tradurre la lingua in ingresso in inglese e se utilizzare la trascrizione passata. Fai riferimento all'Elenco dei Parametri di Riconoscimento per una lista completa dei parametri disponibili.
Migliorare le prestazioni
Si prega di fare riferimento alla sezione Come migliorare le prestazioni per suggerimenti su come ottimizzare le prestazioni del plugin.
Rilevamento dell'Attività Vocale (VAD)
Quando si elabora l'input audio, specialmente in scenari di streaming, si raccomanda di utilizzare il Rilevamento dell'Attività Vocale (VAD) per filtrare i segmenti audio vuoti o contenenti solo rumore prima che raggiungano il riconoscitore. Questo filtraggio può essere abilitato sul lato dell'onda sonora catturabile utilizzando il plugin Runtime Audio Importer, il che aiuta a prevenire che i modelli linguistici allucinino - tentando di trovare pattern nel rumore e generando trascrizioni errate.
Per risultati ottimali nel riconoscimento vocale, raccomandiamo di utilizzare il provider Silero VAD che offre una tolleranza al rumore superiore e un rilevamento vocale più accurato. Il Silero VAD è disponibile come estensione del plugin Runtime Audio Importer. Per istruzioni dettagliate sulla configurazione del VAD, fai riferimento alla documentazione sul Rilevamento dell'Attività Vocale.
I nodi copiabili negli esempi seguenti utilizzano il provider VAD predefinito per motivi di compatibilità. Per migliorare l'accuratezza del riconoscimento, puoi facilmente passare a Silero VAD:
- Installando l'estensione Silero VAD come descritto nella sezione Estensione Silero VAD
- Dopo aver abilitato il VAD con il nodo Toggle VAD, aggiungi un nodo Set VAD Provider e seleziona "Silero" dal menu a tendina
Nel progetto demo incluso con il plugin, il VAD è abilitato di default. Puoi trovare maggiori informazioni sull'implementazione demo in Demo Project.
Esempi
Questi esempi illustrano come utilizzare il plugin Runtime Speech Recognizer sia con input audio in streaming che non in streaming, utilizzando Runtime Audio Importer per ottenere i dati audio come esempio. Si prega di notare che è necessario scaricare separatamente RuntimeAudioImporter per accedere allo stesso set di funzionalità di importazione audio mostrate negli esempi (ad esempio, capturable sound wave e ImportAudioFromFile). Questi esempi sono esclusivamente intesi per illustrare il concetto principale e non includono la gestione degli errori.
Esempi di input audio in streaming
Nota: In UE 5.3 e altre versioni, potresti incontrare nodi mancanti dopo aver copiato i Blueprints. Ciò può verificarsi a causa di differenze nella serializzazione dei nodi tra le versioni del motore. Verifica sempre che tutti i nodi siano correttamente connessi nella tua implementazione.
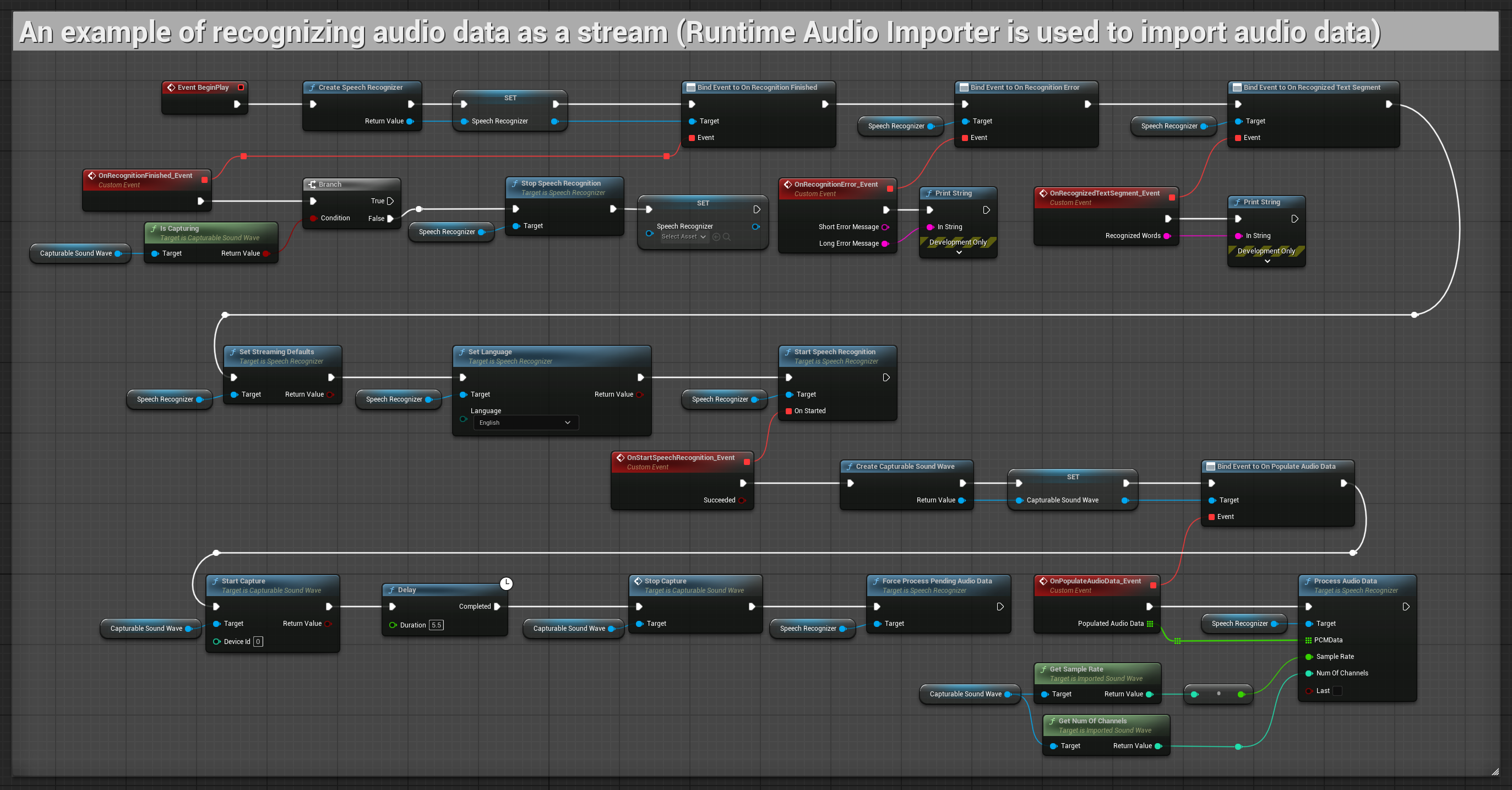
1. Riconoscimento in streaming di base
Questo esempio dimostra la configurazione di base per catturare i dati audio dal microfono come stream utilizzando la Capturable sound wave e passarli al riconoscitore vocale. Registra la voce per circa 5 secondi e poi elabora il riconoscimento, rendendolo adatto per test rapidi e implementazioni semplici. Nodi copiabili.
Caratteristiche principali di questa configurazione:
- Durata di registrazione fissa di 5 secondi
- Riconoscimento one-shot semplice
- Requisiti di configurazione minimi
- Perfetto per test e prototipazione
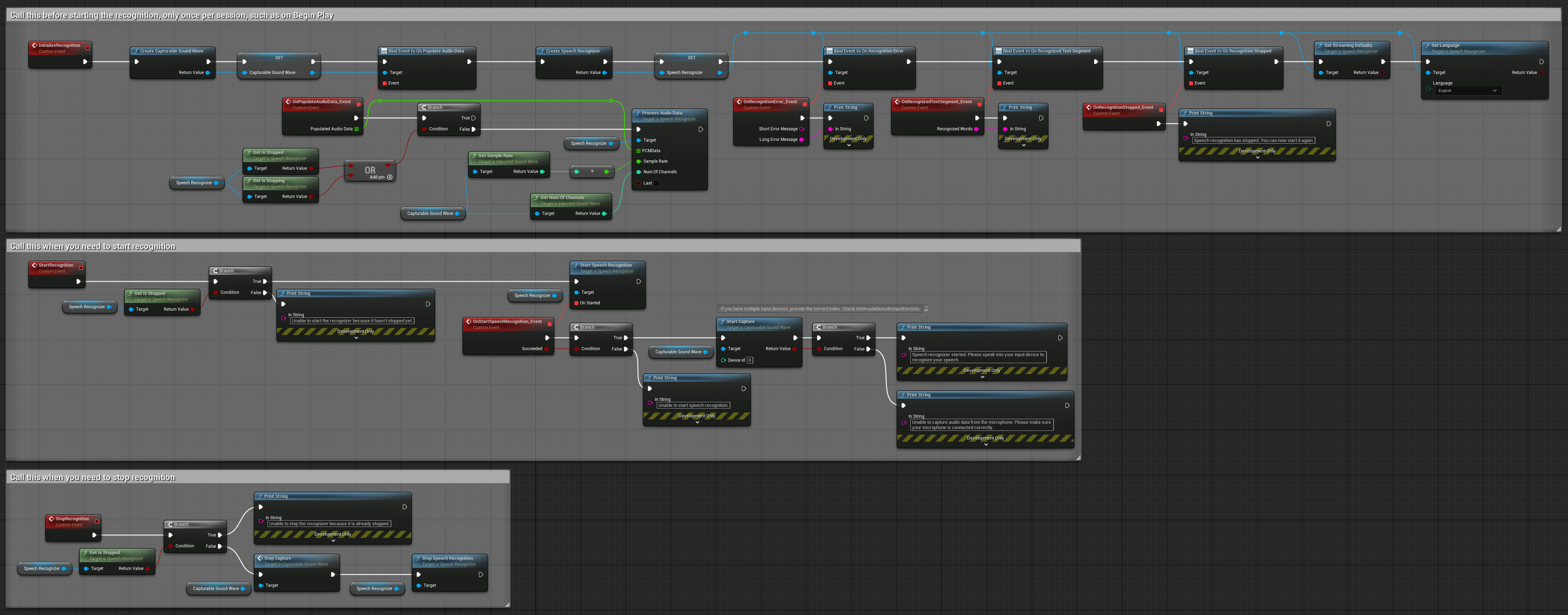
2. Riconoscimento in streaming controllato
Questo esempio estende la configurazione di streaming di base aggiungendo il controllo manuale sul processo di riconoscimento. Ti permette di avviare e fermare il riconoscimento a piacimento, rendendolo adatto per scenari in cui hai bisogno di un controllo preciso su quando avviene il riconoscimento. Nodi copiabili.
Caratteristiche principali di questa configurazione:
- Controllo manuale di avvio/arresto
- Capacità di riconoscimento continuo
- Durata di registrazione flessibile
- Adatto per applicazioni interattive
3. Riconoscimento di comandi attivati dalla voce
Questo esempio è ottimizzato per scenari di riconoscimento comandi. Combina il riconoscimento in streaming con il Rilevamento dell'Attività Vocale (VAD) per elaborare automaticamente il parlato quando l'utente smette di parlare. Il riconoscitore inizia a elaborare il parlato accumulato solo quando viene rilevato il silenzio, rendendolo ideale per interfacce basate su comandi. Nodi copiabili.
Caratteristiche principali di questa configurazione:
- Controllo manuale di avvio/arresto
- Rilevamento dell'Attività Vocale (VAD) abilitato per rilevare segmenti di parlato
- Attivazione automatica del riconoscimento quando viene rilevato silenzio
- Ottimale per il riconoscimento di comandi brevi
- Ridotto sovraccarico di elaborazione riconoscendo solo il parlato effettivo
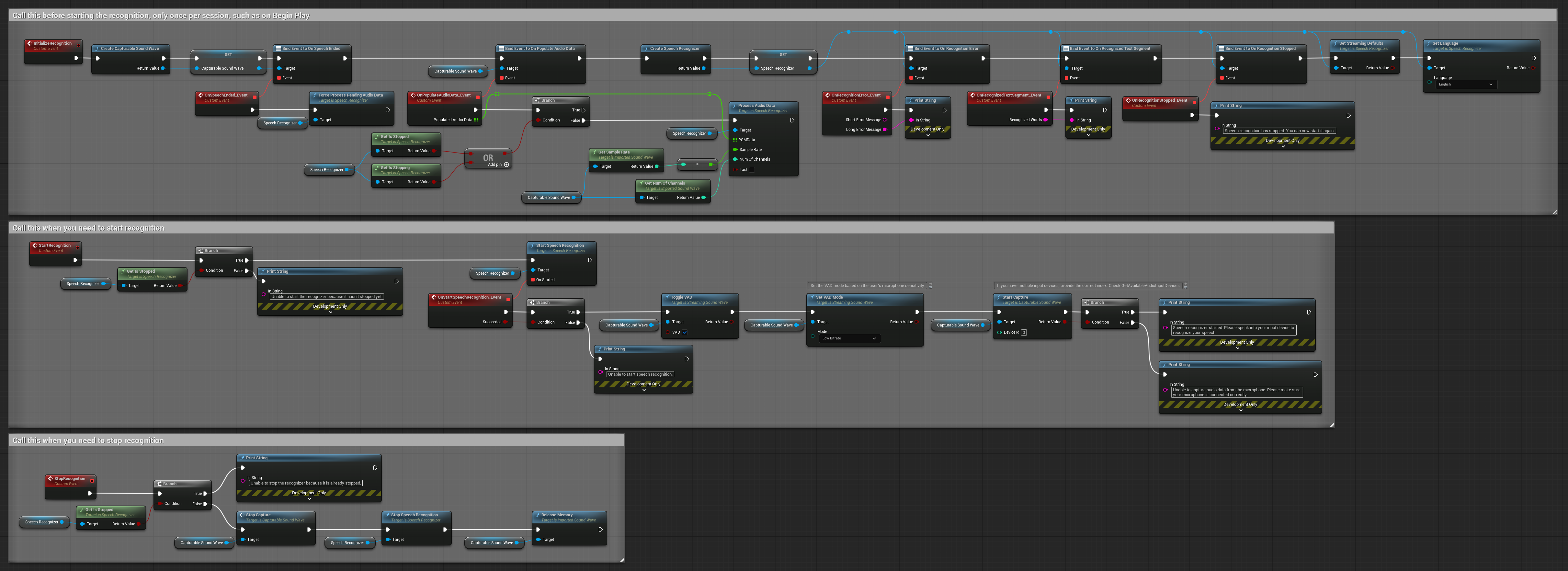
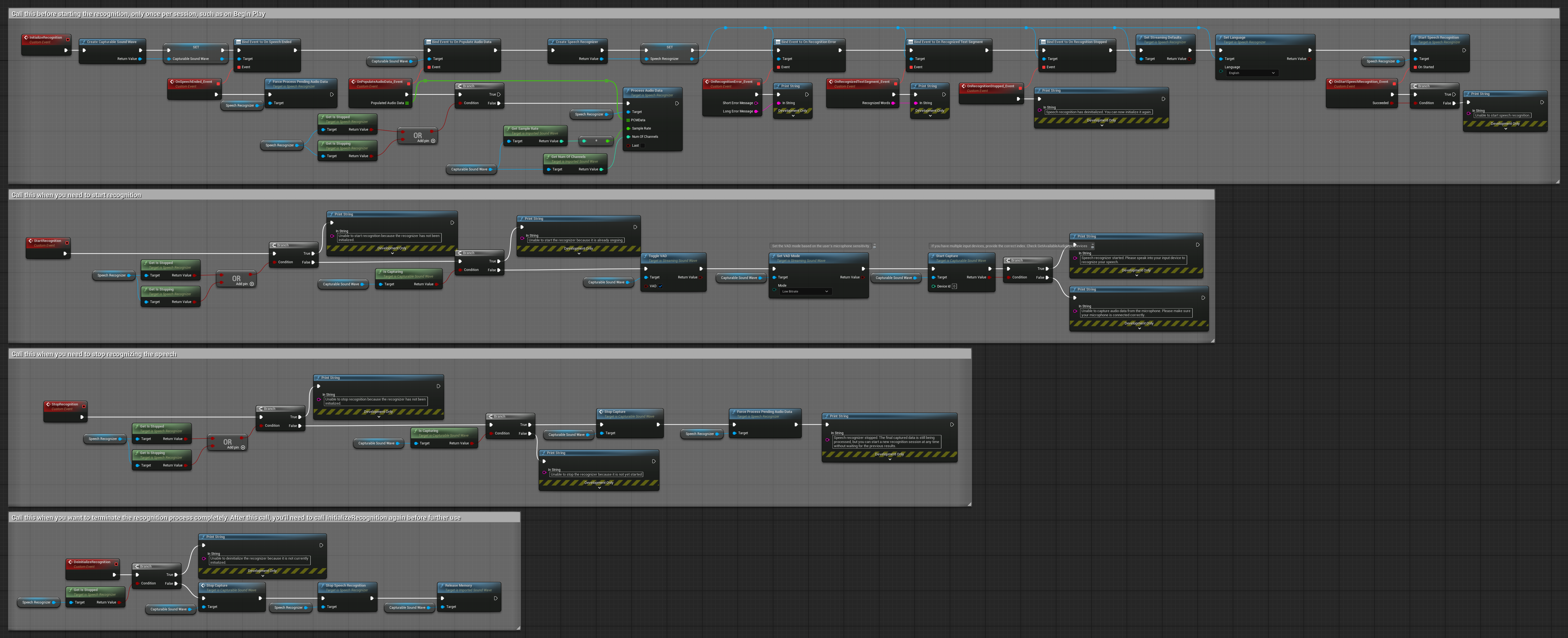
4. Riconoscimento vocale con auto-inizializzazione ed elaborazione del buffer finale
Questo esempio è un'altra variante dell'approccio di riconoscimento attivato dalla voce con una gestione del ciclo di vita differente. Avvia automaticamente il riconoscitore durante l'inizializzazione e lo arresta durante la deinizializzazione. Una caratteristica chiave è che elabora l'ultimo buffer audio accumulato prima di fermare il riconoscitore, garantendo che nessun dato vocale vada perso quando l'utente desidera terminare il processo di riconoscimento. Questa configurazione è particolarmente utile per applicazioni in cui è necessario catturare enunciati completi dell'utente anche quando si interrompe a metà del parlato. Nodi copiabili.
Caratteristiche principali di questa configurazione:
- Avvio automatico del riconoscitore all'inizializzazione
- Arresto automatico del riconoscitore alla deinizializzazione
- Elabora il buffer audio finale prima di fermarsi completamente
- Utilizza il Rilevamento dell'Attività Vocale (VAD) per un riconoscimento efficiente
- Garantisce che nessun dato vocale vada perso durante l'arresto
Input audio non in streaming
Questo esempio importa i dati audio nell'Imported sound wave e riconosce i dati audio completi una volta che sono stati importati. Nodi copiabili.