Lista dei parametri di riconoscimento
Questi parametri possono essere impostati solo mentre il riconoscitore non è in esecuzione.
Questa non è una lista esaustiva dei parametri disponibili in Whisper. Solo i più importanti sono esposti qui. Se necessario, questa lista verrà aggiornata.
Imposta Parametri di Riconoscimento
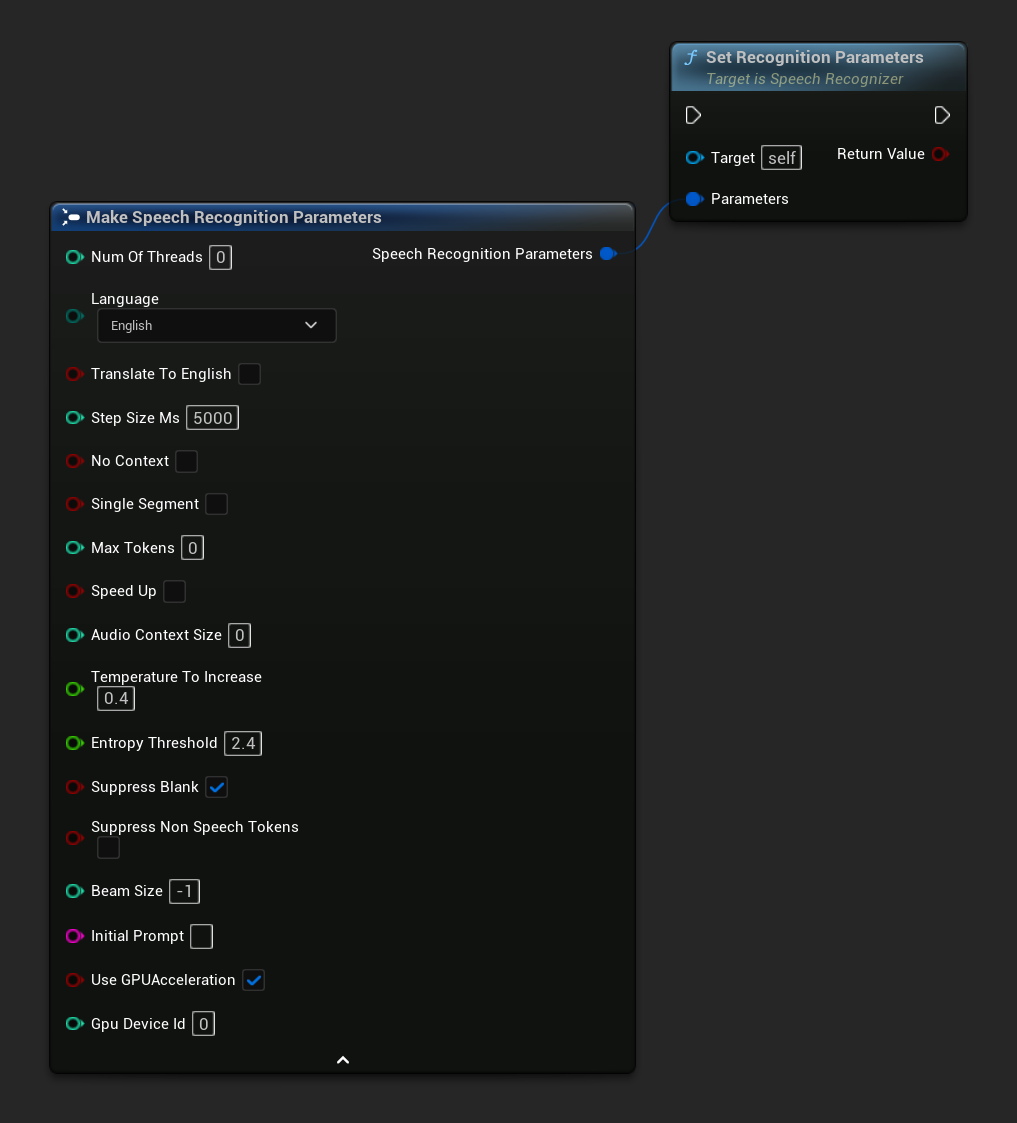
Imposta i parametri per il riconoscimento vocale. Se vuoi cambiare solo parametri specifici, considera l'uso delle singole funzioni setter.
Imposta Predefiniti per Streaming
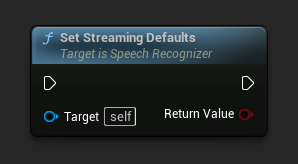
Imposta i parametri predefiniti adatti per il riconoscimento vocale in streaming.
Questa funzione sovrascrive tutti i parametri precedentemente applicati. Assicurati di chiamarla prima di impostare i tuoi parametri personalizzati se hai bisogno di usare i predefiniti per streaming come configurazione di base.
Imposta Predefiniti per Non-Streaming
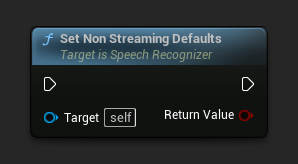
Imposta i parametri predefiniti adatti per il riconoscimento vocale non in streaming.
Questa funzione sovrascrive tutti i parametri precedentemente applicati. Assicurati di chiamarla prima di impostare i tuoi parametri personalizzati se hai bisogno di usare i predefiniti per non-streaming come configurazione di base.
Imposta Numero di Thread
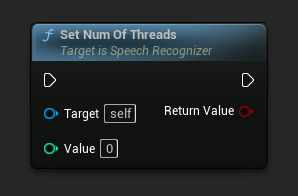
Imposta il numero di thread da usare per il riconoscimento vocale. Imposta questo valore a 0 per usare il numero di core.
Imposta Lingua
Imposta la lingua da usare per il riconoscimento vocale. Deve essere supportata dal modello linguistico selezionato nelle impostazioni dell'Editor.
Impostare la lingua su Auto diminuirà la precisione e le prestazioni del riconoscimento.
Ottieni Lingua Rilevata
Ottiene la lingua rilevata dall'ultimo riconoscimento. Restituisce la lingua come valore enumerato.
Nota: Questa funzione funziona solo dopo che è stato eseguito un riconoscimento. Restituisce Auto se il rilevamento della lingua è fallito o non è stato eseguito. Questo è particolarmente utile quando si usa il rilevamento automatico della lingua per identificare quale lingua è stata effettivamente riconosciuta.
Ottieni Codice Lingua
Converte un valore enumerato di lingua nella sua stringa di codice lingua (es., En -> "en", Fr -> "fr", De -> "de").
Ottieni Nome Completo Lingua
Converte un valore enumerato di lingua nel suo nome completo della lingua (es., En -> "English", Fr -> "French", De -> "German").
Imposta Traduci in Inglese
![]()
Imposta se tradurre le parole riconosciute in inglese. Se vero, il modello linguistico deve essere multilingue.
Imposta Dimensione Passo
Imposta la dimensione del passo in millisecondi. Determina quanto spesso inviare i dati audio per il riconoscimento. Il valore predefinito è 5000 ms (5 secondi).
Imposta Nessun Contesto
Imposta se usare la trascrizione passata (se presente) come prompt iniziale per il decodificatore.
Imposta Segmento Singolo
Imposta se forzare l'output a segmento singolo (utile per lo streaming).
Imposta Token Massimi
Imposta il numero massimo di token per segmento di testo. Usa 0 per nessun limite.
Imposta Velocizza
Imposta se velocizzare il riconoscimento di 2x usando il Phase Vocoder. Impostalo su false per migliorare la qualità dell'output.
Imposta Dimensione Contesto Audio
Imposta la dimensione del contesto audio. Impostalo su 0 per migliorare la qualità dell'output.
Imposta Temperatura da Aumentare
Imposta la temperatura da aumentare quando si torna indietro quando la decodifica non riesce a soddisfare una delle soglie sottostanti.
Imposta Soglia di Entropia
Imposta la soglia di entropia. Se il rapporto di compressione è più alto di questo valore, tratta la decodifica come fallita. Simile a "compression_ratio_threshold" di OpenAI
Imposta Sopprimi Spazi Vuoti
![]()
Imposta se sopprimere gli spazi vuoti che compaiono negli output.
Imposta Sopprimi Token Non Vocali
Imposta se sopprimere i token non vocali che compaiono negli output.
Imposta Dimensione Fascio
Imposta il numero di fasci nella ricerca a fascio. Applicabile solo quando la temperatura è zero.
Imposta Prompt Iniziale
Imposta il prompt iniziale per la prima finestra. Questo può essere usato per fornire contesto al riconoscimento per renderlo più probabile che preveda correttamente le parole, ad esempio vocabolari personalizzati o nomi propri.
Per maggiori dettagli sulle strategie di prompting efficaci, consulta la Guida al Prompting di Whisper.
Imposta Accelerazione GPU
Imposta se usare l'accelerazione GPU per il riconoscimento vocale (applicabile solo su Windows al momento).
Imposta ID Dispositivo GPU
Imposta l'ID del dispositivo GPU da usare per il riconoscimento vocale. Il valore predefinito è 0. Questo è utile per sistemi con più GPU per specificare quale GPU dovrebbe essere usata per il processo di riconoscimento. Se l'ID del dispositivo GPU specificato non è valido, verrà usato invece il primo indice di dispositivo GPU disponibile.