翻訳プロバイダー
AI Localization Automator は、それぞれ独自の強みと設定オプションを持つ5つの異なるAIプロバイダーをサポートしています。プロジェクトのニーズ、予算、品質要件に最適なプロバイダーを選択してください。
Ollama (ローカルAI)
最適な用途: プライバシーに敏感なプロジェクト、オフライン翻訳、無制限の使用
OllamaはAIモデルをマシン上でローカルに実行し、APIコストやインターネット接続を必要とせず、完全なプライバシーと制御を提供します。
人気モデル
- translategemma:12b (Gemma 3ベースの専門翻訳モデル)
- llama3.2 (汎用目的推奨)
- mistral (効率的な代替案)
- codellama (コードを意識した翻訳)
- その他多くのコミュニティモデル
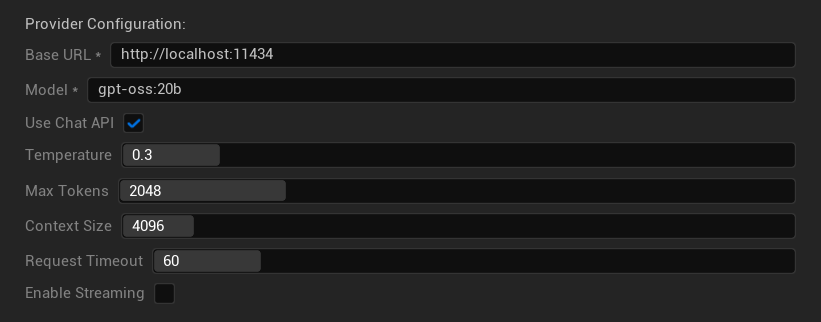
設定オプション
- ベースURL: ローカルのOllamaサーバー (デフォルト:
http://localhost:11434) - モデル: ローカルにインストールされたモデルの名前 (必須)
- チャットAPIを使用: より良い会話処理のために有効化
- 温度: 0.0-2.0 (0.3推奨)
- 最大トークン数: 1-8,192トークン
- コンテキストサイズ: 512-32,768トークン
- リクエストタイムアウト: 10-300秒 (ローカルモデルは遅くなる可能性あり)
- ストリーミングを有効化: リアルタイム応答処理用
強み
- ✅ 完全なプライバシー (データがマシンを離れない)
- ✅ APIコストや使用制限なし
- ✅ オフラインで動作
- ✅ モデルパラメータの完全な制御
- ✅ 多様なコミュニティモデル
- ✅ ベンダーロックインなし
考慮事項
- 💻 ローカルセットアップと十分なハードウェアが必要
- ⚡ 一般的にクラウドプロバイダーより遅い
- 🔧 より技術的なセットアップが必要
- 📊 翻訳品質はモデルによって大きく異なる (一部はクラウドプロバイダーを上回る可能性あり)
- 💾 モデルに大容量のストレージが必要
Ollamaのセットアップ
- Ollamaのインストール: ollama.ai からダウンロードし、システムにインストール
- モデルのダウンロード:
ollama pull translategemma:12bを使用して選択したモデルをダウンロード - サーバーの起動: Ollamaは自動的に実行されるか、
ollama serveで起動 - プラグインの設定: プラグイン設定でベースURLとモデル名を設定
- 接続テスト: 設定を適用するとプラグインが接続性を検証します
OpenAI
最適な用途: 全体的に最高の翻訳品質、豊富なモデル選択肢
OpenAIは、最新のGPTモデル、推論モデル、Web検索対応モデルを含む、業界をリードする言語モデルをChat Completions APIを通じて提供します。
利用可能なモデル
GPT-5ファミリー (フラッグシップモデル)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
GPT-4.1ファミリー (高性能)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
GPT-4oファミリー (マルチモーダル)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
Oシリーズ (推論モデル — temperature/top_p 非対応)
- o1, o1-pro, o3, o3-mini, o4-mini
Web検索モデル (Temperature/top_p 非対応)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
レガシー / プレビュー
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k
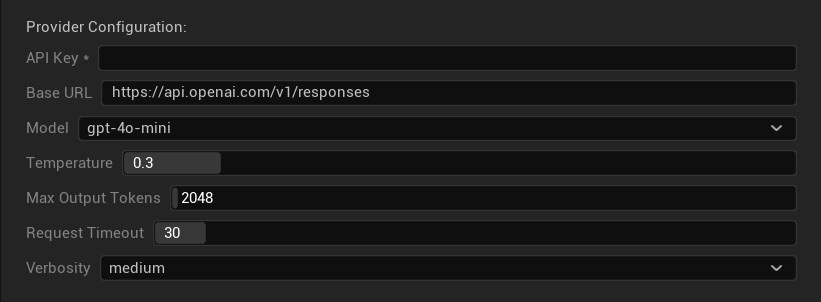
設定オプション
- APIキー: あなたのOpenAI APIキー (必須)
- ベースURL: APIエンドポイント (デフォルト:
https://api.openai.com/v1/chat/completions) - モデル: 上記の利用可能なモデルから選択
- 温度を使用: 温度パラメータのオン/オフ切り替え (oシリーズ推論およびWeb検索モデルでは自動的に無視)
- 温度: 0.0–2.0 (翻訳の一貫性のために0.3推奨)
- Top P: 0.0–1.0 の核サンプリングパラメータ (oシリーズ推論およびWeb検索モデルでは無視)
- 最大完了トークン数: 1–128,000トークン (出力と推論トークンの両方を含む)
- リクエストタイムアウト: 5–300秒
強み
- ✅ 一貫して高品質な翻訳
- ✅ 優れたコンテキスト理解
- ✅ 強力なフォーマット保持
- ✅ 幅広い言語サポート
- ✅ 信頼性の高いAPI稼働時間
考慮事項
- 💰 リクエストあたりのコストが高い
- 🌐 インターネット接続が必要
- ⏱️ ティアに基づく使用制限
Anthropic Claude
最適な用途: ニュアンスのある翻訳、クリエイティブコンテンツ、安全性重視のアプリケーション
Claudeモデルはコンテキストとニュアンスの理解に優れており、物語性の強いゲームや複雑なローカライゼーションシナリオに最適です。
利用可能なモデル
Claude 4.6ファミリー (最新)
- claude-opus-4-6, claude-sonnet-4-6
Claude 4.5ファミリー
- claude-haiku-4-5 (高速で効率的)
- claude-sonnet-4-5, claude-opus-4-5
Claude 4.xファミリー
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Claude 3.xファミリー (レガシー)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
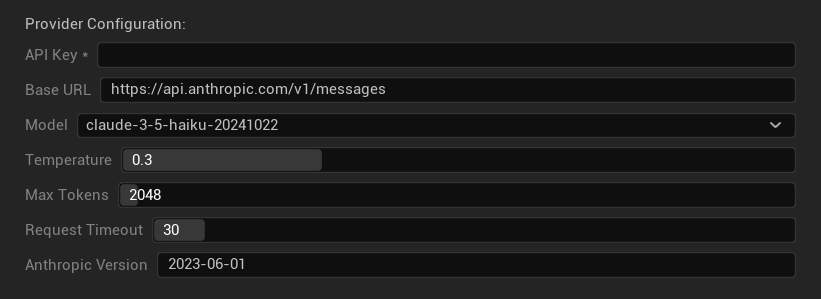
設定オプション
- APIキー: あなたのAnthropic APIキー (必須)
- ベースURL: Claude APIエンドポイント
- モデル: Claudeモデルファミリーから選択
- 温度: 0.0–1.0 (0.3推奨)
- Top K: Top-Kサンプリングパラメータ (0 = 設定なし)
- 最大トークン数: 1–64,000トークン
- リクエストタイムアウト: 5–300秒
- Anthropicバージョン: APIバージョンヘッダー
強み
- ✅ 卓越したコンテキスト認識
- ✅ クリエイティブ/物語コンテンツに最適
- ✅ 強力な安全機能
- ✅ 詳細な推論能力 (3.7+モデルでの拡張思考)
- ✅ 優れた指示追従
考慮事項
- 💰 プレミアム価格モデル
- 🌐 インターネット接続が必要
- 📏 モデルによってトークン制限が異なる
DeepSeek
最適な用途: コスト効率の良い翻訳、高スループット、予算重視のプロジェクト
DeepSeekは他のプロバイダーの数分の一のコストで競争力のある翻訳品質を提供し、大規模なローカライゼーションプロジェクトに最適です。
利用可能なモデル
- deepseek-chat (汎用目的、推奨)
- deepseek-reasoner (強化された推論能力)
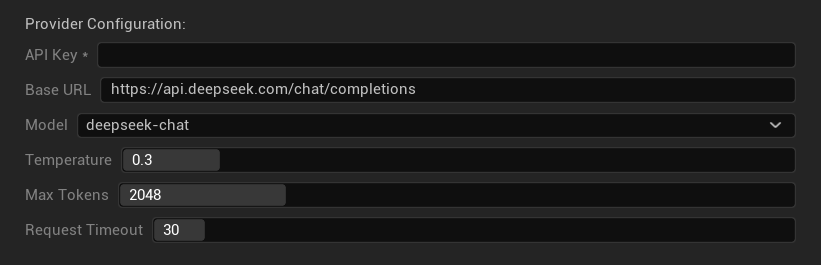
設定オプション
- APIキー: あなたのDeepSeek APIキー (必須)
- ベースURL: DeepSeek APIエンドポイント
- モデル: チャットモデルと推論モデルの間で選択
- 温度: 0.0-2.0 (0.3推奨)
- 最大トークン数: 1-8,192トークン
- リクエストタイムアウト: 5-300秒
強み
- ✅ 非常にコスト効率が良い
- ✅ 良好な翻訳品質
- ✅ 高速な応答時間
- ✅ シンプルな設定
- ✅ 高いレート制限
考慮事項
- 📏 トークン制限が低い
- 🆕 新しいプロバイダー (実績が少ない)
- 🌐 インターネット接続が必要
Google Gemini
最適な用途: 多言語プロジェクト、コスト効率の良い翻訳、Googleエコシステム統合
Geminiモデルは、競争力のある価格設定と、強化された推論のための思考モードなどの独自機能を備えた、強力な多言語機能を提供します。
利用可能なモデル
Gemini 3.xファミリー (プレビュー)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Gemini 2.5ファミリー (思考サポート付き)
- gemini-2.5-pro (思考機能付きフラッグシップ)
- gemini-2.5-flash (高速、思考サポート付き)
- gemini-2.5-flash-lite (軽量バリアント)
Gemini 2.0ファミリー
- gemini-2.0-flash, gemini-2.0-flash-lite
最新エイリアス
- gemini-flash-latest, gemini-flash-lite-latest
設定オプション
- APIキー: あなたのGoogle AI APIキー (必須)
- ベースURL: Gemini APIエンドポイント
- モデル: Geminiモデルファミリーから選択
- 温度: 0.0–2.0 (0.3推奨)
- 最大出力トークン数: 1–8,192トークン
- リクエストタイムアウト: 5–300秒
- 思考を有効化: 2.5+モデルの強化推論を有効化
- 思考予算: 思考トークン割り当てを制御 (0 = 思考なし)
強み
- ✅ 強力な多言語サポート
- ✅ 競争力のある価格設定
- ✅ 高度な推論 (思考モード)
- ✅ Googleエコシステム統合
- ✅ 最新モデルへのプレビューアクセスを伴う定期的なモデル更新
考慮事項
- 🧠 思考モードはトークン使用量を増加させる
- 📏 モデルによって可変のトークン制限
- 🌐 インターネット接続が必要
適切なプロバイダーの選択
| プロバイダー | 最適な用途 | 品質 | コスト | セットアップ | プライバシー |
|---|---|---|---|---|---|
| Ollama | プライバシー/オフライン | 可変* | 無料 | 高度 | ローカル |
| OpenAI | 最高品質 | ⭐⭐⭐⭐⭐ | 💰💰💰 | 簡単 | クラウド |
| Claude | クリエイティブコンテンツ | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | 簡単 | クラウド |
| DeepSeek | 予算重視プロジェクト | ⭐⭐⭐⭐ | 💰 | 簡単 | クラウド |
| Gemini | 多言語 | ⭐⭐⭐⭐ | 💰 | 簡単 | クラウド |
*Ollamaの品質は使用するローカルモデルによって大きく異なります - 一部の最新ローカルモデルはクラウドプロバイダーに匹敵または上回る可能性があります。
プロバイダー設定のヒント
すべてのクラウドプロバイダー向け:
- APIキーは安全に保管し、バージョン管理にコミットしないでください
- 一貫した翻訳のために控えめな温度設定 (0.3) から始めてください
- API使用量とコストを監視してください
- 大規模な翻訳実行前に小さなバッチでテストしてください
Ollama向け:
- 十分なRAMを確保してください (大規模モデルには8GB以上推奨)
- より良いモデル読み込みパフォーマンスのためにSSDストレージを使用してください
- 高速な推論のためにGPUアクセラレーションを検討してください
- 本番翻訳に依存する前にローカルでテストしてください