プラグインの使用方法
このガイドでは、ランタイムAPIの全機能について説明します。LLMインスタンスの作成、モデルの読み込み、メッセージの送信、ランタイムでのモデルのダウンロード、状態管理、ユーティリティ関数について解説します。
LLMインスタンスを作成する
まず、Runtime Local LLM オブジェクトを作成します。ブループリントの変数や C++ の UPROPERTY として参照を保持し、早期のガベージコレクションを防ぎます。
- ブループリント
- C++
UPROPERTY()
URuntimeLocalLLM* LLM;
LLM = URuntimeLocalLLM::CreateRuntimeLocalLLM();
モデルをロードする
メッセージを送信する前にモデルを読み込む必要があります。このプラグインは、ワークフローに応じていくつかの読み込み方法を提供しています。
名前で読み込み
エディタ設定パネルからモデルを管理する場合は、Load Model (By Name)を使用してください。
- ブループリント
- C++
- UE 5.3 以前
- UE 5.4+
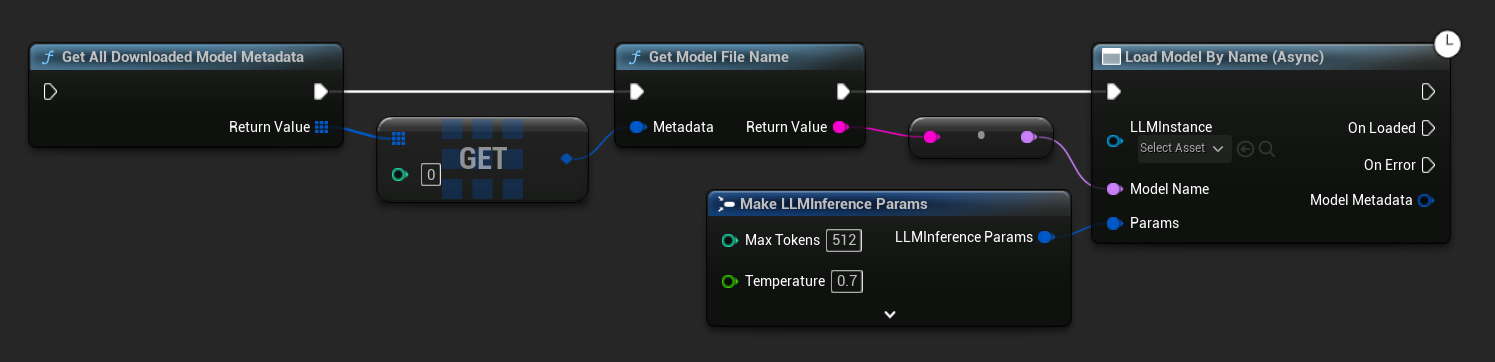
UE 5.3以前ではドロップダウンが表示されないため、利用可能なモデルを手動で取得する必要があります。Get All Downloaded Model Metadataを使用して、インデックス0(または必要なモデル)の要素を取得し、それをGet Model File Nameに渡して名前の文字列を取得し、その文字列をLoad Model (By Name)に渡します。
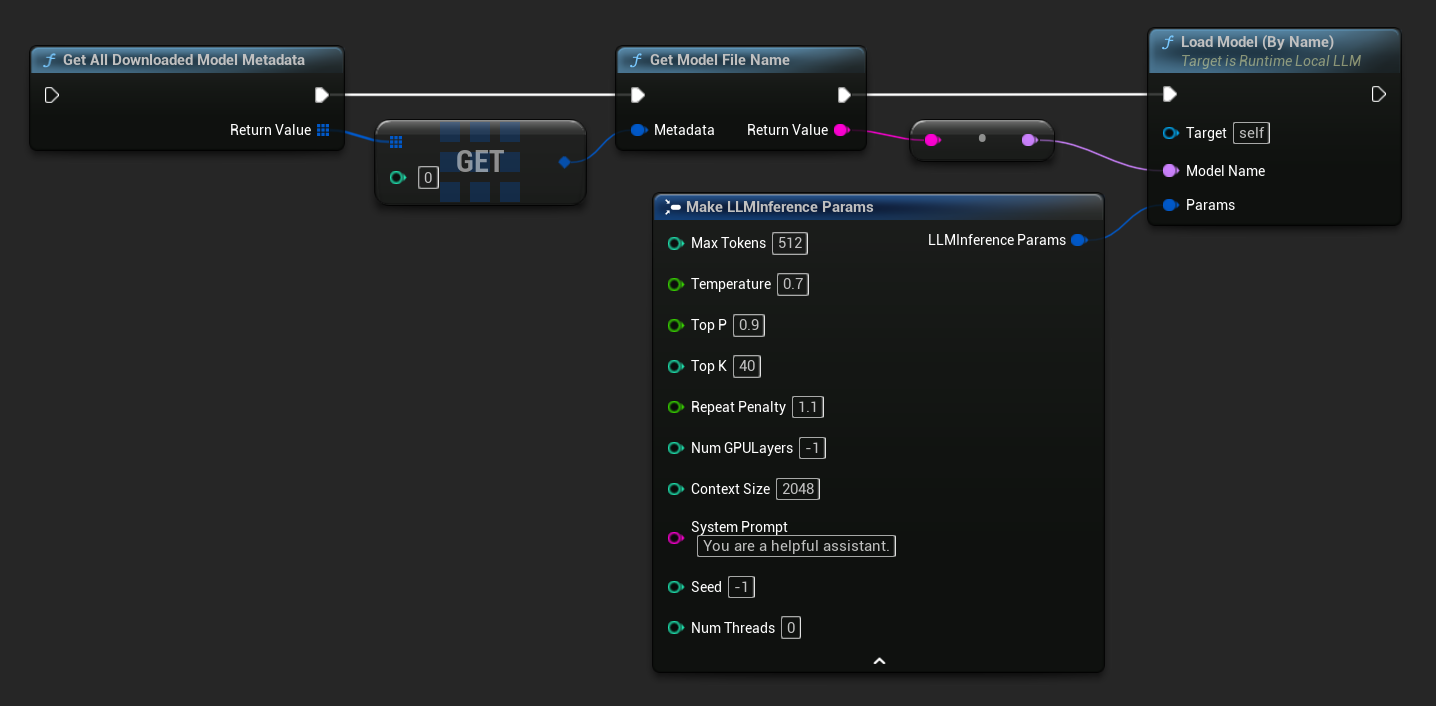
UE 5.4以降では、Load Model (By Name) はディスク上のすべてのモデルのドロップダウンリストを表示します。読み込みたいモデルを選択するだけです。
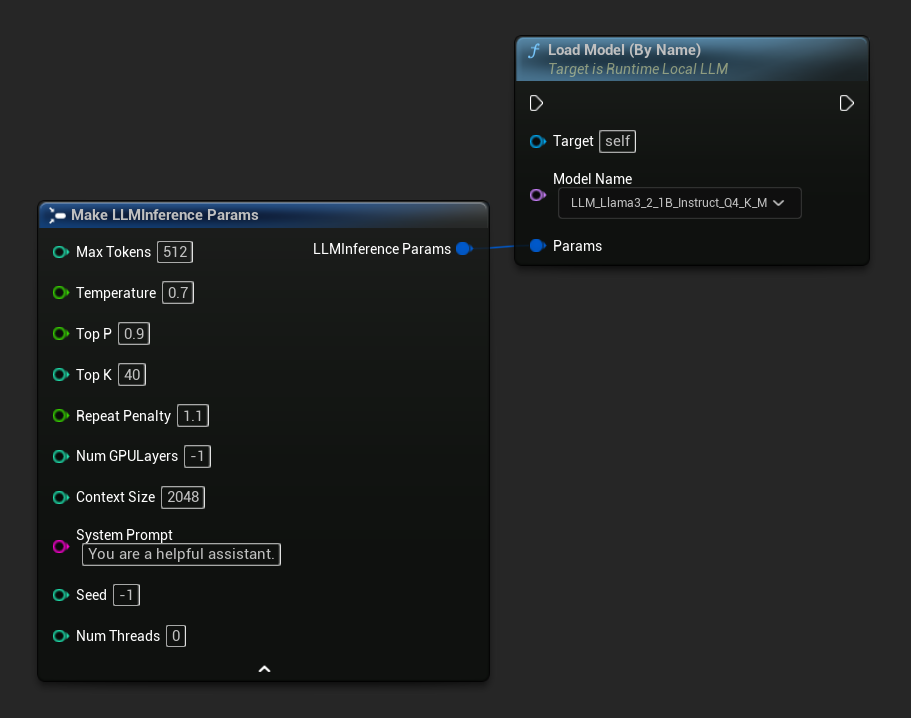
C++では、GetAllDownloadedModelMetadataを使用して利用可能なモデルを取得し、GetModelFileNameで名前を取得してLoadModelByNameに渡します。
FLLMInferenceParams Params;
Params.MaxTokens = 512;
Params.Temperature = 0.7f;
Params.SystemPrompt = TEXT("You are a helpful assistant.");
TArray<FLLMModelMetadata> DownloadedModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
if (DownloadedModels.Num() > 0)
{
const FLLMModelMetadata& Model = DownloadedModels[0]; // Select the first available model
FString ModelFileName = URuntimeLLMLibrary::GetModelFileName(Model);
LLM->LoadModelByName(FName(*ModelFileName), Params);
}
ファイルパスから読み込む
.gguf ファイルへの絶対ファイルパスから直接モデルを読み込みます:
- ブループリント
- C++
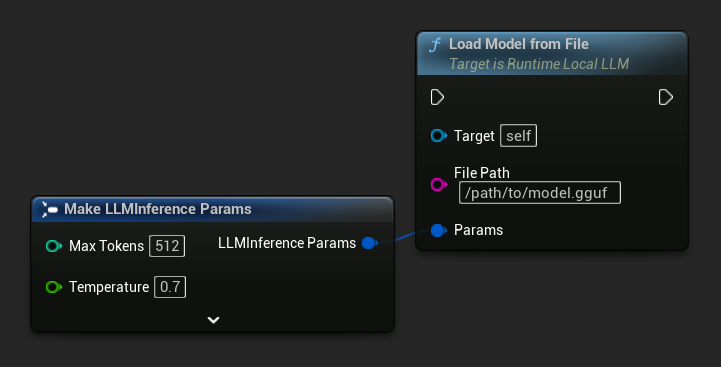
FLLMInferenceParams Params;
LLM->LoadModelFromFile(TEXT("/path/to/model.gguf"), Params);
URLから読み込む(ダウンロードして読み込む)
URLからモデルをダウンロードし(ディスク上にない場合)、自動的に読み込みます。ファイルが既にローカルに存在する場合は、ダウンロードはスキップされます。
- ブループリント
- C++
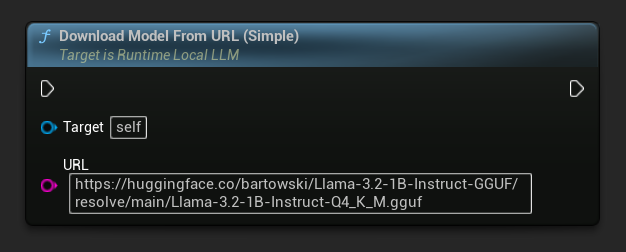
最もシンプルなバリアントはURLのみを受け取ります。メタデータはファイル名から取得されます。
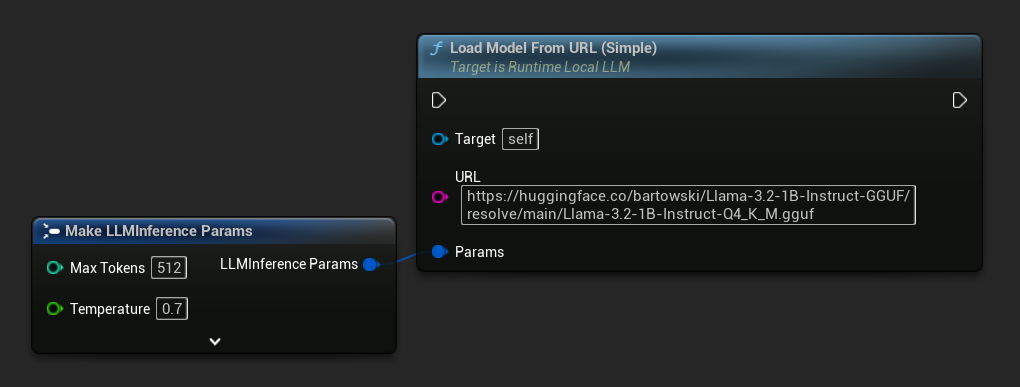
また、より豊かなモデル情報を得るために、完全なモデルメタデータを含む Load Model From URL を使用することもできます。
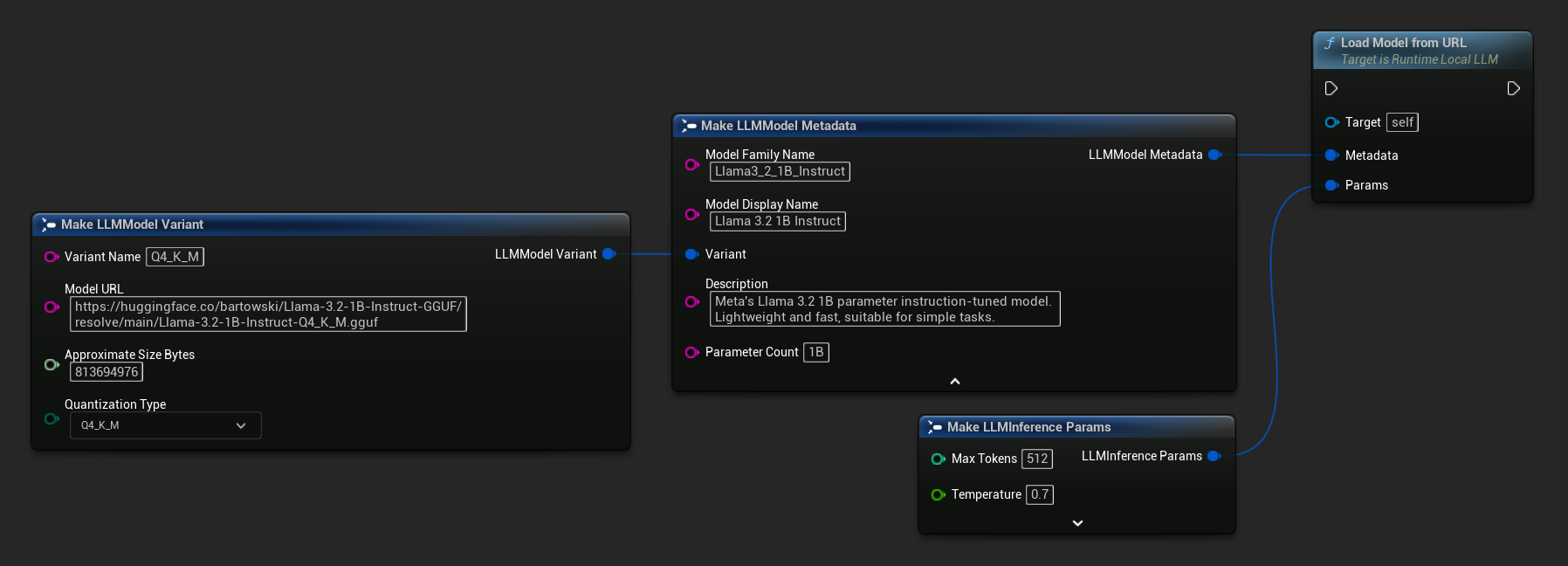
FLLMInferenceParams Params;
// Simple: URL only - metadata is derived from the filename
LLM->LoadModelFromURLSimple(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"), Params);
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->LoadModelFromURL(Metadata, Params);
非同期ロード(ブループリント)
出力ピンを介してロード完了とエラーを処理し、手動でデリゲートをバインドする代わりに、2つの非同期ノードが利用可能です。
Load Model By Name (Async) は Load Model (By Name) をミラーリングします。UE 5.4+ では、ディスク上のすべてのモデルのドロップダウンが表示されます。
- UE 5.4+
- UE 5.3 以前
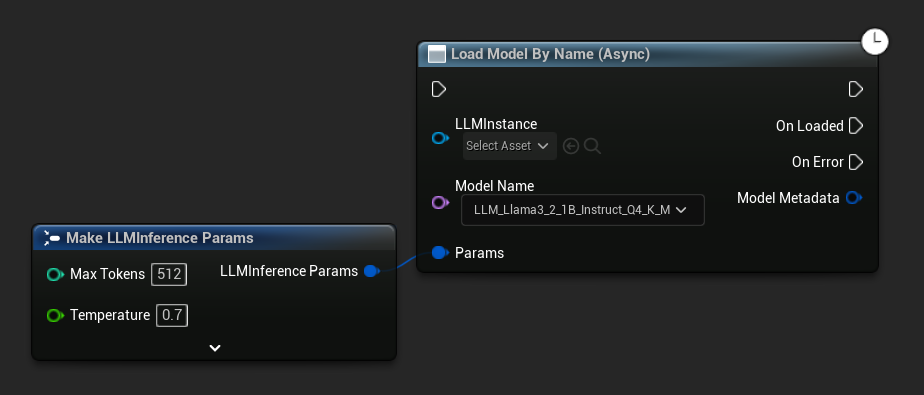
UE 5.3以前ではドロップダウンは表示されません。Get All Downloaded Model Metadata を使用し、インデックス0(または必要なモデル)の要素を取得して Get Model File Name に渡し、その後 Load Model By Name (Async) に渡してください。
Load Model From File (Async) は代わりに絶対ファイルパスを受け取ります。
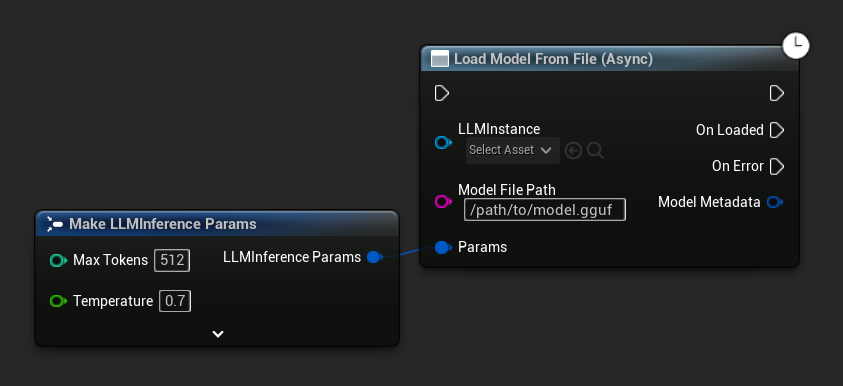
イベントをバインドする
LLMインスタンスのデリゲートにバインドしてコールバックを受信します。すべてのコールバックはゲームスレッド上で発火します。
- ブループリント
- C++
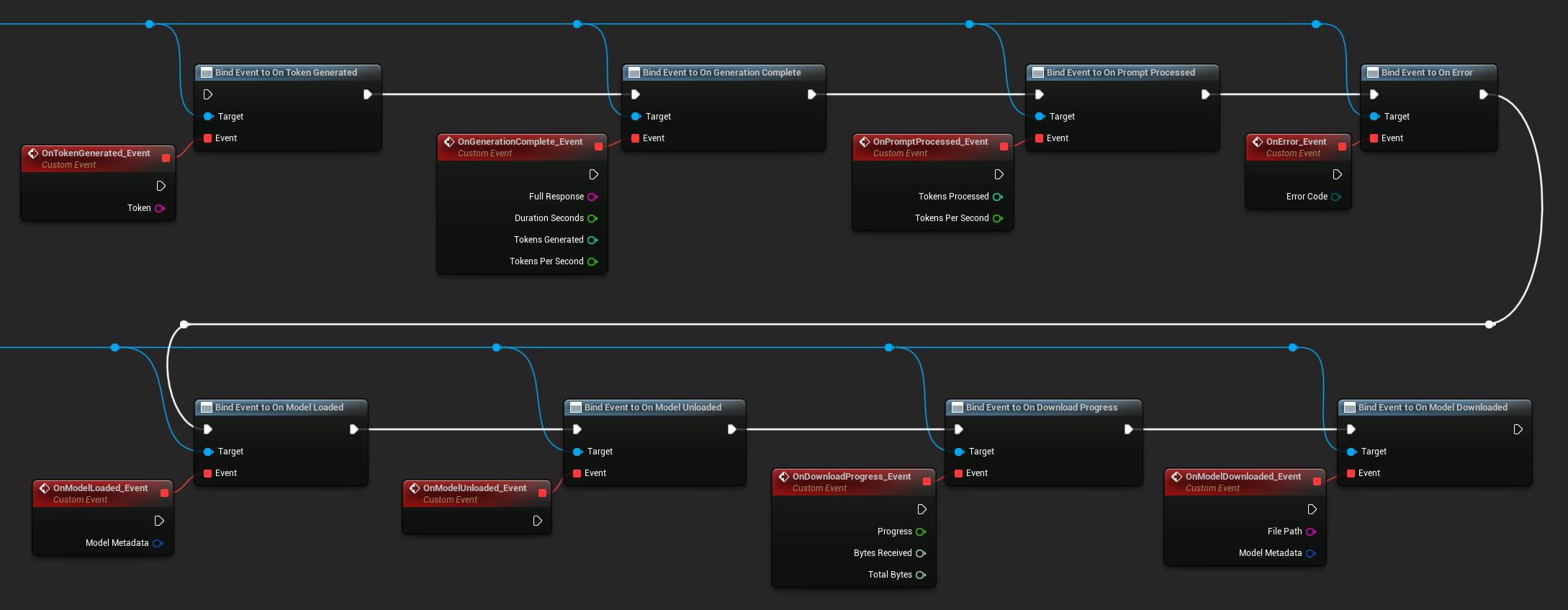
利用可能なデリゲート:
- トークン生成時: 出力トークンごとに発生します
- 生成完了時: 完全な応答の準備ができたときに発生し、所要時間、トークン数、1秒あたりのトークン数を報告します
- プロンプト処理時: 入力プロンプトが処理された後、生成が開始される前に発生します
- エラー時: いずれかの操作中にエラーが発生した場合に発生します
- モデル読み込み完了時: モデルの読み込みが完了したときに発生します
- モデルアンロード時: モデルがアンロードされたときに発生します
- ダウンロード進捗時: モデルのダウンロード中に定期的に発生します(進捗率、受信バイト数、総バイト数)
- モデルダウンロード完了時: ダウンロードのみの操作が完了したときに発生します
- 会話保存時: 会話がJSONファイルに書き込まれたときに発生します
- 会話読み込み時: 会話がファイルまたはメモリスナップショットから読み込まれたときに発生します
- 履歴要約時: 自動要約が古いメッセージを圧縮したときに発生します(メッセージ数、節約されたトークン数、要約を報告します)
LLM->OnTokenGeneratedNative.AddLambda([](const FString& Token)
{
});
LLM->OnGenerationCompleteNative.AddLambda(
[](const FString& FullResponse, float DurationSeconds, int32 TokensGenerated, float TokensPerSecond)
{
});
LLM->OnPromptProcessedNative.AddLambda([](int32 TokensProcessed, float TokensPerSecond)
{
});
LLM->OnErrorNative.AddLambda([](ELLMErrorCode ErrorCode)
{
});
LLM->OnModelLoadedNative.AddLambda([](const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnModelUnloadedNative.AddLambda([]()
{
});
LLM->OnDownloadProgressNative.AddLambda([](float Progress, int64 BytesReceived, int64 TotalBytes)
{
});
LLM->OnModelDownloadedNative.AddLambda([](const FString& FilePath, const FLLMModelMetadata& ModelMetadata)
{
});
LLM->OnConversationSavedNative.AddLambda([](const FString& FilePath)
{
});
LLM->OnConversationLoadedNative.AddLambda([](const FLLMConversationSnapshot& Snapshot)
{
});
LLM->OnHistorySummarizedNative.AddLambda([](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
});
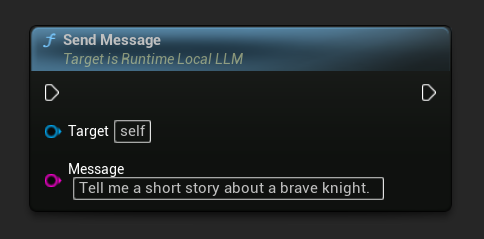
メッセージを送信
モデルが読み込まれたら、ユーザーメッセージを送信して応答を生成します。
- ブループリント
- C++
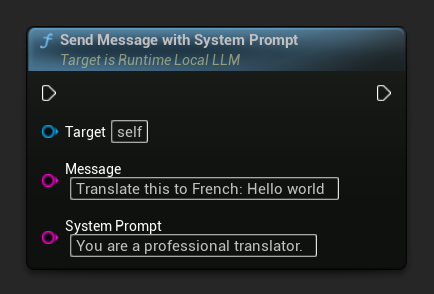
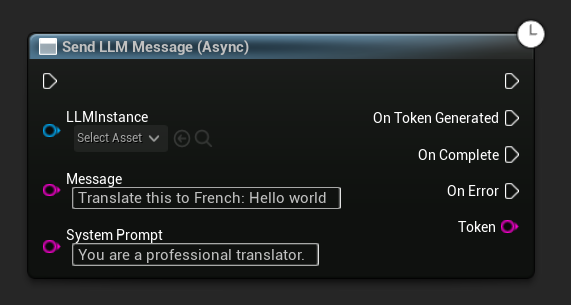
特定のメッセージに対してシステムプロンプトを上書きするには、Send Message With System Prompt を使用します。
LLM->SendMessage(TEXT("Tell me a short story about a brave knight."));
// With a custom system prompt override
LLM->SendMessageWithSystemPrompt(
TEXT("Translate this to French: Hello world"),
TEXT("You are a professional translator.")
);
OnTokenGenerated を通じてトークンが生成されるたびにストリームされます。生成が完了すると、OnGenerationComplete が発火し、完全な応答、所要時間、トークン数、および1秒あたりのトークン数が提供されます。
非同期メッセージ送信(ブループリント)
Send LLM Message (Async) ノードは、トークン、完了、エラー専用の出力ピンを提供します。
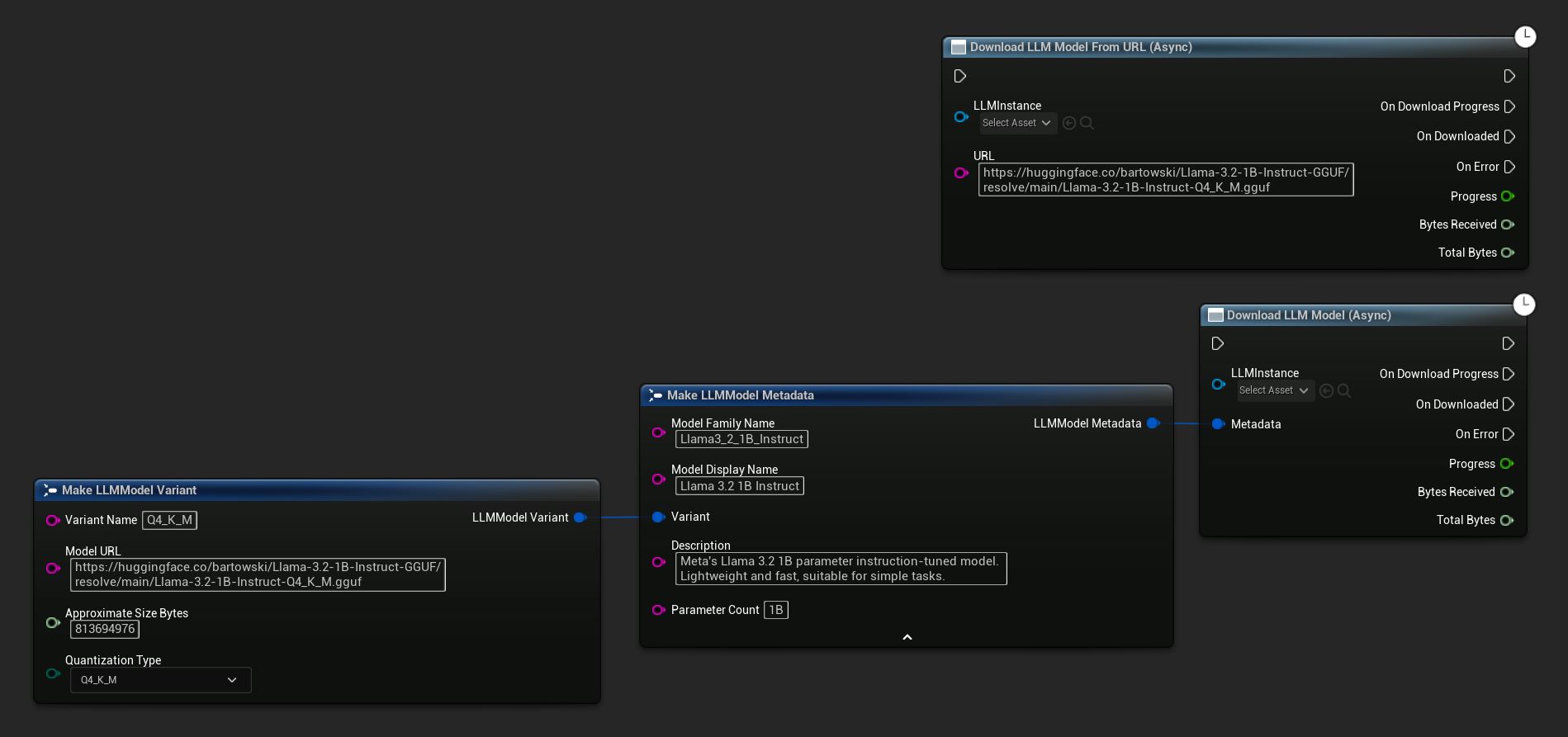
ランタイムでモデルをダウンロードする
上記のダウンロードおよびロードのフローに加えて、モデルをロードせずにディスクにダウンロードすることもできます。これは、ローディング画面や設定メニューでモデルを事前にキャッシュする場合に便利です。
- ブループリント
- C++
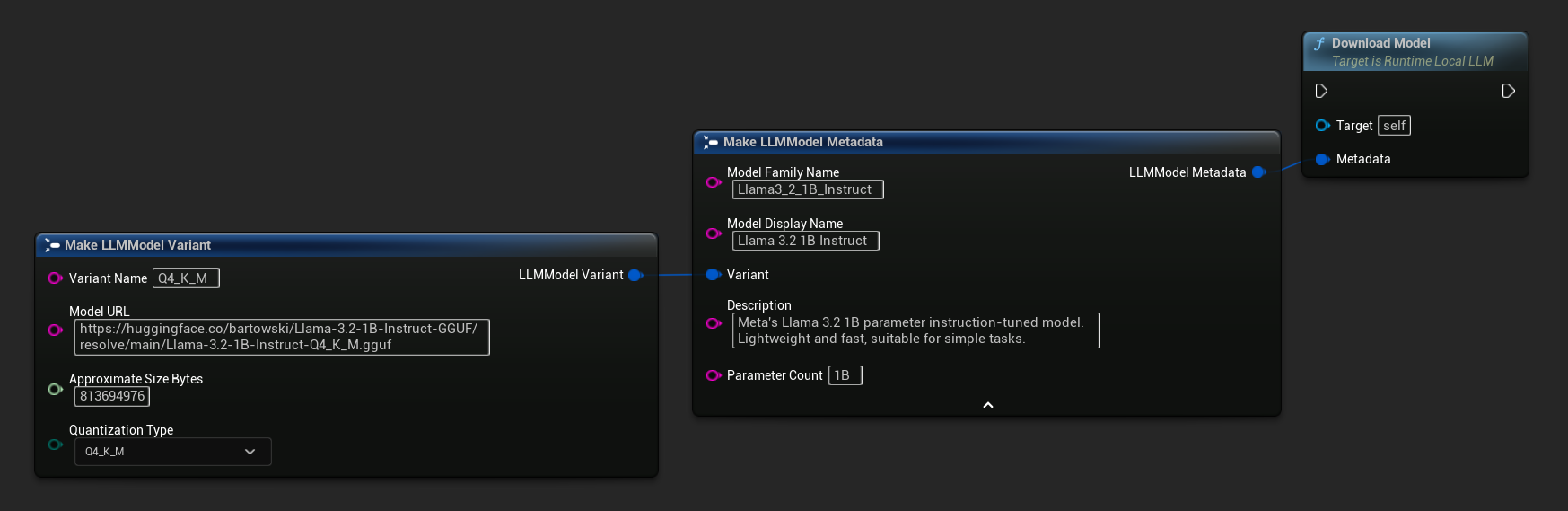
URLのみのバリアントも利用可能です:
Download LLM Model (Async) ノードと Download LLM Model From URL (Async) ノードは、進捗状況、完了、エラー用の出力ピンを提供します。
// With full metadata
FLLMModelMetadata Metadata;
Metadata.ModelFamilyName = TEXT("Llama3_2_1B_Instruct");
Metadata.ModelDisplayName = TEXT("Llama 3.2 1B Instruct");
Metadata.Description = TEXT("Meta's Llama 3.2 1B parameter instruction-tuned model. Lightweight and fast, suitable for simple tasks.");
Metadata.ParameterCount = TEXT("1B");
Metadata.Variant.VariantName = TEXT("Q4_K_M");
Metadata.Variant.ModelURL = TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf");
Metadata.Variant.ApproximateSizeBytes = 776LL * 1024 * 1024;
Metadata.Variant.QuantizationType = ELLMQuantizationType::Q4_K_M;
LLM->DownloadModel(Metadata);
// URL only
LLM->DownloadModelFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf"));
OnDownloadProgress デリゲートはダウンロード中の進捗状況を報告します。OnModelDownloaded はファイルがディスクに保存されたときに発生します。
進行中のダウンロードをキャンセルするには:
- ブループリント
- C++
LLM->CancelDownload();
このプラグインは重複ダウンロードを自動的に防止します。同じモデルのダウンロードが既に進行中の場合、後続の呼び出しは無視されます。
生成を停止
生成を中断するには:
- ブループリント
- C++
LLM->StopGeneration();
会話コンテキストをリセット
会話履歴をクリアして、新しい会話を開始します。
- ブループリント
- C++
// Keep the system prompt
LLM->ResetContext(true);
// Clear everything including the system prompt
LLM->ResetContext(false);
会話の保存と読み込み
このプラグインは、会話履歴をJSONとしてディスクに保存するか、スナップショットとしてメモリ内に保持することができます。デフォルトでは、システムプロンプトは保存から除外されるため、同じ会話履歴を異なるシステムルールを持つ別のLLMインスタンスに読み込むことができます。これは、各キャラクターが独自のメモリを持ちながらも、システム指示を共有したり異なったりする可能性があるマルチNPCシナリオで有用です。
ファイルに保存
現在の会話をディスク上のJSONファイルに保存します:
- ブループリント
- C++
Include System Prompt パラメータは、システムメッセージ(存在する場合)をファイルに書き込むかどうかを制御します。デフォルトは false で、NPC間の移植性を確保します。
On Conversation Saved は、ファイルが書き込まれたときに発生します。
// Excludes system prompt by default
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"));
// Include the system prompt in the file
LLM->SaveConversationToFile(TEXT("/path/to/conversation.json"), /*bIncludeSystemPrompt=*/ true);
ファイルから読み込む
JSONファイルから会話を読み込みます:
- ブループリント
- C++
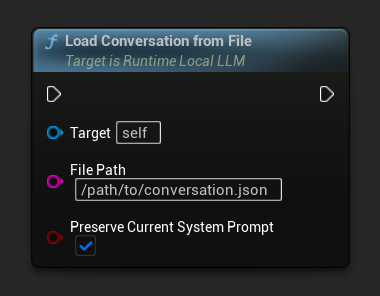
Preserve Current System Prompt パラメータ(デフォルトは true)は、現在読み込まれているシステムプロンプトを保持したまま、保存された会話履歴を入れ替えます。これはNPCのメモリ入れ替えに推奨される設定です。
On Conversation Loaded は、読み込まれたスナップショットとともに発火します。
// Keep current system prompt, swap in the saved history
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"));
// Replace the system prompt with whatever's in the file
LLM->LoadConversationFromFile(TEXT("/path/to/conversation.json"), /*bPreserveCurrentSystemPrompt=*/ false);
インメモリスナップショット(マルチNPCワークフロー)
ゲームプレイ中に高速でNPCを切り替えるには、現在の会話をディスクに書き込むのではなく、メモリにスナップショットとして保存します。このパターンは、単一の読み込まれたモデルを共有する多数のNPCを管理するための推奨方法です。
- ブループリント
- C++
典型的なマルチNPCパターンでは、NPCマネージャーやゲームステート上に Map of Name → LLM Conversation Snapshot を使用します。
- NPCから切り替える場合:
Save Conversation To Memoryを呼び出し、On Conversation Loaded(スナップショット配信時にも発火)でスナップショットをNPC名をキーとしてマップに保存します。 - 別のNPCに切り替える場合: マップからスナップショットを読み取り、
Preserve Current System Promptを有効にしてLoad Conversation From Memoryを呼び出します。

システムプロンプトはスワップ間で読み込まれたままになるため、各NPCの「性格」は、NPCごとのシステムプロンプトにエンコードするか(スワップ後にSend Message With System Promptを1回呼び出して更新)、すべてのNPC間で共有することができます。
// Maintain per-NPC snapshots
UPROPERTY()
TMap<FName, FLLMConversationSnapshot> NPCMemories;
// Save the currently active NPC's memory before switching
LLM->OnConversationLoadedNative.AddLambda([this](const FLLMConversationSnapshot& Snapshot)
{
NPCMemories.Add(CurrentNPC, Snapshot);
});
LLM->SaveConversationToMemory();
// Activate another NPC's memory
if (const FLLMConversationSnapshot* Found = NPCMemories.Find(NextNPC))
{
LLM->LoadConversationFromMemory(*Found, /*bPreserveCurrentSystemPrompt=*/ true);
CurrentNPC = NextNPC;
}
スナップショットはモデルに依存しません。メッセージを保存するものであり、KVキャッシュの状態を保存するものではありません。同じスナップショットを別のモデルに読み込むことも可能です(ただし、会話のスタイルは変化する可能性があります)。スナップショットの OriginModelFamilyName フィールドを使用すると、互換性を強制したい場合に、どのモデルが生成したかを確認できます。
自動コンテキスト要約
長い会話は、最終的にモデルのコンテキストウィンドウを超えてしまい、通常は履歴が切り詰められるか、エラーが発生します。このプラグインの自動要約機能は、コンテキストの使用状況を監視し、設定されたしきい値を超えた場合、次の応答が生成される前に、古いメッセージを1つの「メモリ」メッセージに要約します。これにより、無制限に長い会話にわたって、トークンコストとレイテンシを安定させることができます。
要約は同じ読み込まれたモデルによって実行されるため、別のモデルやAPI呼び出しは必要ありません。
自動要約を有効にする
- ブループリント
- C++
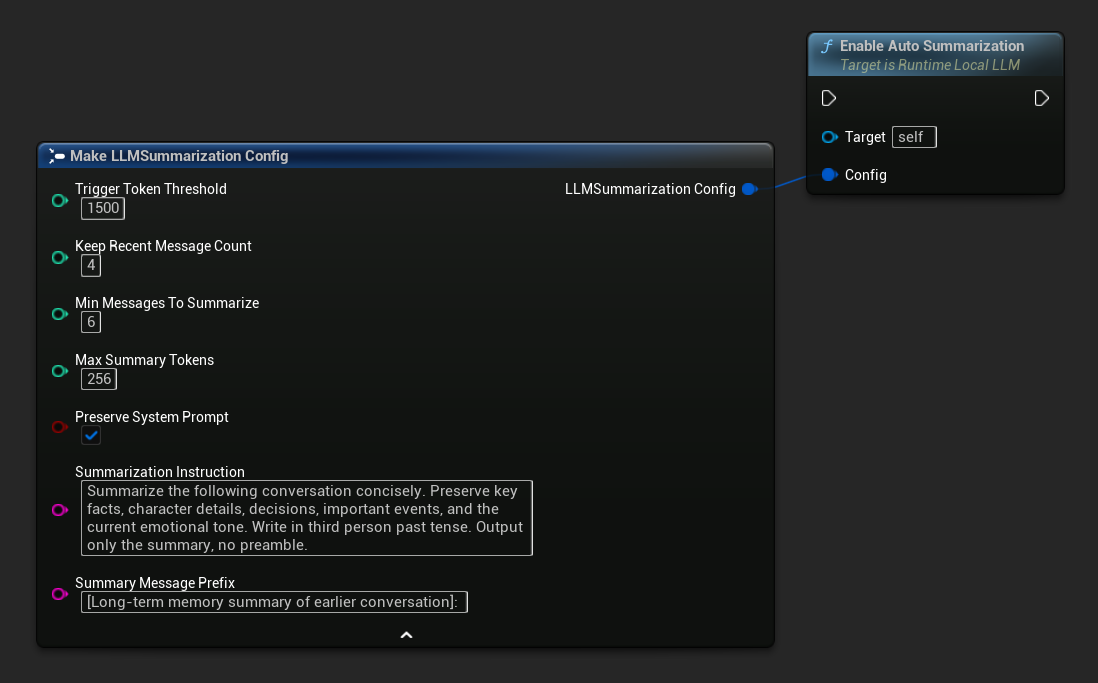
Get Default Summarization Config を使用して適切なデフォルト設定を取得し、必要に応じて調整してください。
FLLMSummarizationConfig Config = URuntimeLocalLLM::GetDefaultSummarizationConfig();
Config.TriggerTokenThreshold = 1500;
Config.KeepRecentMessageCount = 4;
Config.MinMessagesToSummarize = 6;
LLM->EnableAutoSummarization(Config);
有効にすると、必要に応じて各 SendMessage 呼び出しの前に自動的に要約が実行されるため、それ以上の操作は必要ありません。
デフォルトでは、新しいメッセージが処理される前に自動要約が実行されます。これは、応答の生成と同時に安全に行うことができないコンテキストの再構築が必要なためです。代わりに、プレイヤーが読み取りや入力をしている間、応答後に自動要約を実行したい場合は、自動要約を無効にして手動で駆動してください。On Generation Completeにバインドし、Get Used Context Lengthをしきい値と照合し、それを超えた場合はSummarize Nowを呼び出します。Summarize Nowは同じバックグラウンドタスクキューにキューイングされるため、応答の完了直後、次のメッセージが処理される前に実行されます。
設定リファレンス
| パラメータ | Type | デフォルト | 説明 |
|---|---|---|---|
| トリガートークンしきい値 | int32 | 1500 | 要約は、使用されるコンテキストトークンがこの値を超えた場合に実行されます。この値はContext Sizeに応じて設定し、目安として60~75%程度が適切です。 |
| 最近のメッセージ数を保持 | int32 | 4 | 最新のN件のメッセージは決して要約されず、即時の会話の一貫性が維持されます。 |
| 要約する最小メッセージ数 | int32 | 6 | この数よりも少ない古いメッセージが要約対象となる場合、要約をスキップします(意味のない小さな要約を避けるため)。 |
| 最大サマリートークン数 | int32 | 256 | 生成される要約の最大トークン数 |
| システムプロンプトを保持する | bool | true | 常にシステムメッセージ(インデックス0)をそのまま保持してください。 |
| 要約指示 | FString | (see default) | 要約を生成するためにモデルに送信された指示 |
| サマリーメッセージプレフィックス | FString | 「[以前の会話の長期記憶サマリー]:」 | 生成されたサマリーがアシスタントロールのメモリメッセージとして会話に挿入されるときに、その先頭に付加されます。 |
手動トリガーと要約のリスニング
しきい値に関係なく、いつでも手動で要約をトリガーできます。
- ブループリント
- C++
On History Summarized にバインドすると、要約パスが完了したときに通知を受け取れます。このイベントは、削除されたメッセージ数、節約されたトークン数、生成された要約テキストを報告するため、チャットUIに控えめなインジケーターを表示するのに役立ちます。
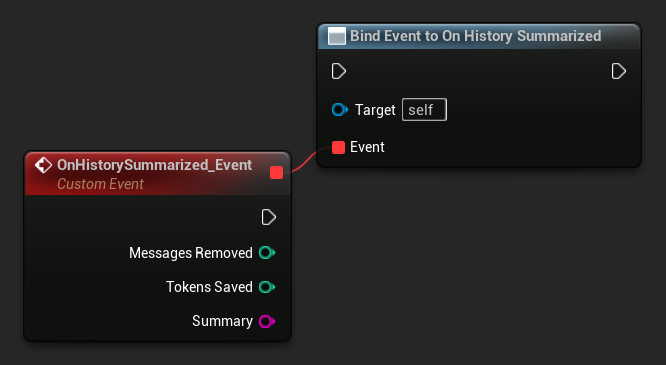
LLM->SummarizeNow();
LLM->OnHistorySummarizedNative.AddLambda(
[](int32 MessagesRemoved, int32 TokensSaved, const FString& Summary)
{
UE_LOG(LogTemp, Log, TEXT("Summarized %d messages, saved %d tokens"), MessagesRemoved, TokensSaved);
});
使用中のコンテキスト長をクエリ中
Get Used Context Lengthを使用して、モデルのコンテキストウィンドウに現在何トークンが占有されているかを確認します。これは、組み込みの自動要約トリガーがTrigger Token Thresholdと照合する値と同じです。
- ブループリント
- C++
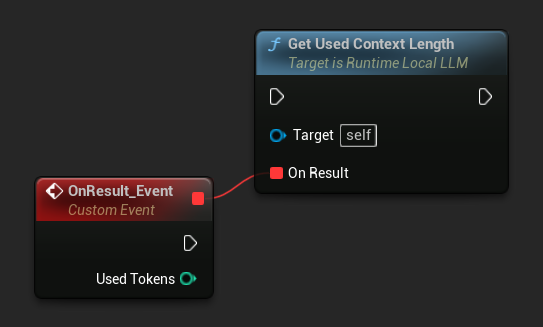
LLM->GetUsedContextLengthNative([](int32 UsedTokens)
{
UE_LOG(LogTemp, Log, TEXT("Used context: %d tokens"), UsedTokens);
});
自動要約を無効にする
- ブループリント
- C++
LLM->DisableAutoSummarization();
無効化しても、会話に既に適用された要約は元に戻りません。
要約はバックグラウンドスレッドで実行されるため、少し時間がかかります(モデルが要約を生成しています)。この内部生成中はトークンストリームコールバックが抑制されるため、チャットUIには表示されません。On History Summarizedはスプライスが完了した時点で発火します。
モデルをアンロードする
モデルが不要になった際にリソースを解放する方法:
- ブループリント
- C++
LLM->UnloadModel();
クエリ状態
LLMインスタンスの現在の状態を確認してください:
- ブループリント
- C++
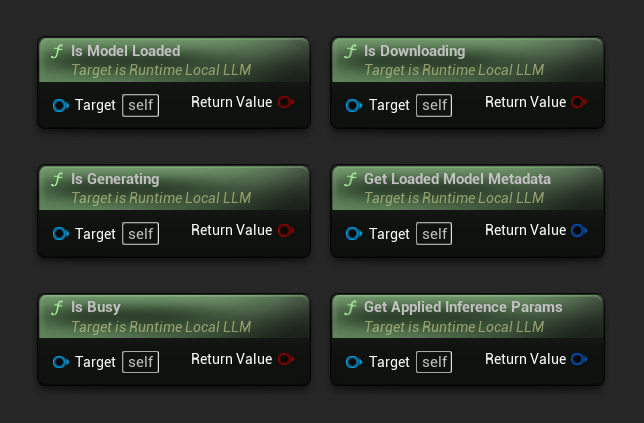
- モデルが読み込まれている: 推論の準備ができているモデルがある場合はTrue
- 生成中: 生成が進行中の場合はTrue
- ビジー状態: 何らかの操作(読み込み、生成、ダウンロード)がアクティブな場合はTrue
- ダウンロード中: モデルのダウンロードが進行中の場合はTrue
- 読み込まれたモデルのメタデータを取得: 現在のモデルのメタデータを返します
- 適用された推論パラメータを取得: 読み込み時に適用されたパラメータを返します
// Is Model Loaded - true if a model is ready for inference
if (LLM->IsModelLoaded())
{
FLLMModelMetadata Metadata = LLM->GetLoadedModelMetadata();
UE_LOG(LogTemp, Log, TEXT("Model: %s"), *Metadata.ModelDisplayName);
FLLMInferenceParams Params = LLM->GetAppliedInferenceParams();
UE_LOG(LogTemp, Log, TEXT("Context size: %d"), Params.ContextSize);
}
// Is Generating - true if token generation is currently active
if (LLM->IsGenerating())
{
UE_LOG(LogTemp, Log, TEXT("Generation in progress..."));
}
// Is Busy - true if any operation (loading, generating, downloading) is active
if (LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is busy, deferring request"));
}
// Is Downloading - true if a model download is currently in progress
if (LLM->IsDownloading())
{
UE_LOG(LogTemp, Log, TEXT("Model download in progress..."));
}
// Safe to send a new message or load a different model
if (!LLM->IsGenerating() && !LLM->IsBusy())
{
UE_LOG(LogTemp, Log, TEXT("LLM is idle and ready"));
}
モデルライブラリ関数
モデルファイルをディスク上で管理するための静的ユーティリティ関数セットが提供されています。これらは、モデル選択UIの構築や、実行時にモデルの利用可能性を確認するのに役立ちます。
ダウンロードしたモデル名/メタデータを取得
- ブループリント
- C++
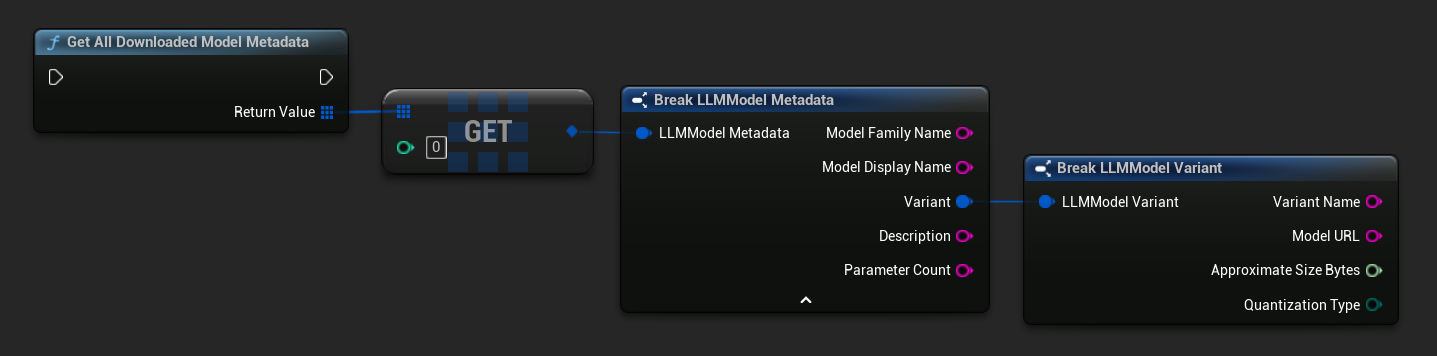
TArray<FName> ModelNames = URuntimeLLMLibrary::GetDownloadedModelNames();
TArray<FLLMModelMetadata> AllModels = URuntimeLLMLibrary::GetAllDownloadedModelMetadata();
for (const FLLMModelMetadata& Model : AllModels)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s (%s)"), *Model.ModelDisplayName, *Model.Variant.VariantName);
}
モデルがディスク上にあるか確認する
- ブループリント
- C++
bool bExists = URuntimeLLMLibrary::IsModelOnDisk(Metadata);
モデルファイルのパスを取得する
- ブループリント
- C++
FString FilePath = URuntimeLLMLibrary::GetModelFilePath(Metadata);
モデルファイルを削除する
- ブループリント
- C++
bool bDeleted = URuntimeLLMLibrary::DeleteModelFiles(Metadata);
事前定義済みおよび利用可能なモデルを取得する
- ブループリント
- C++
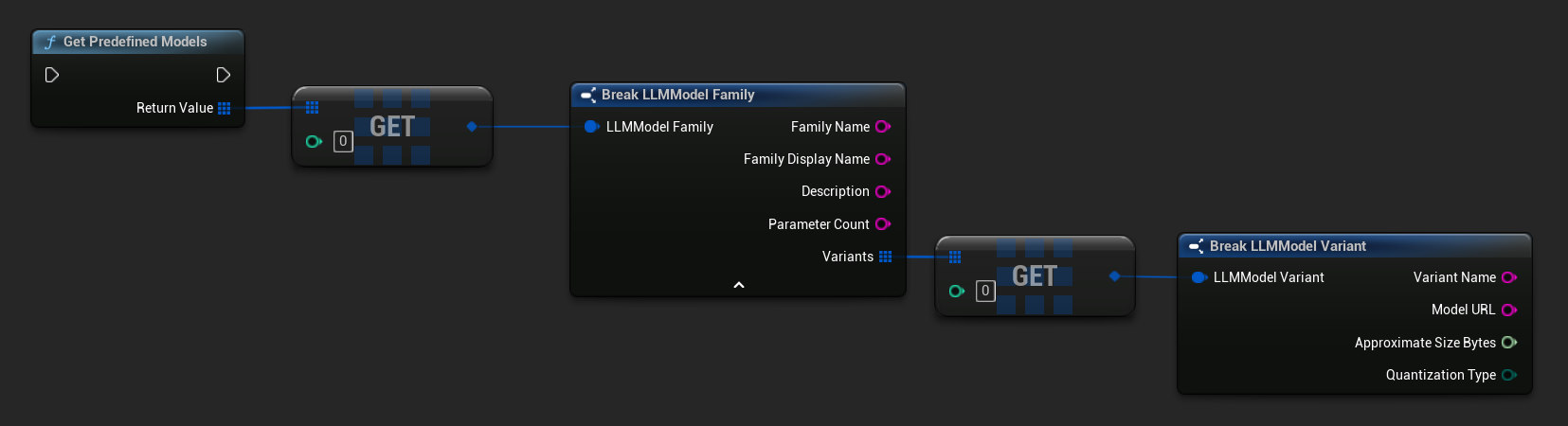
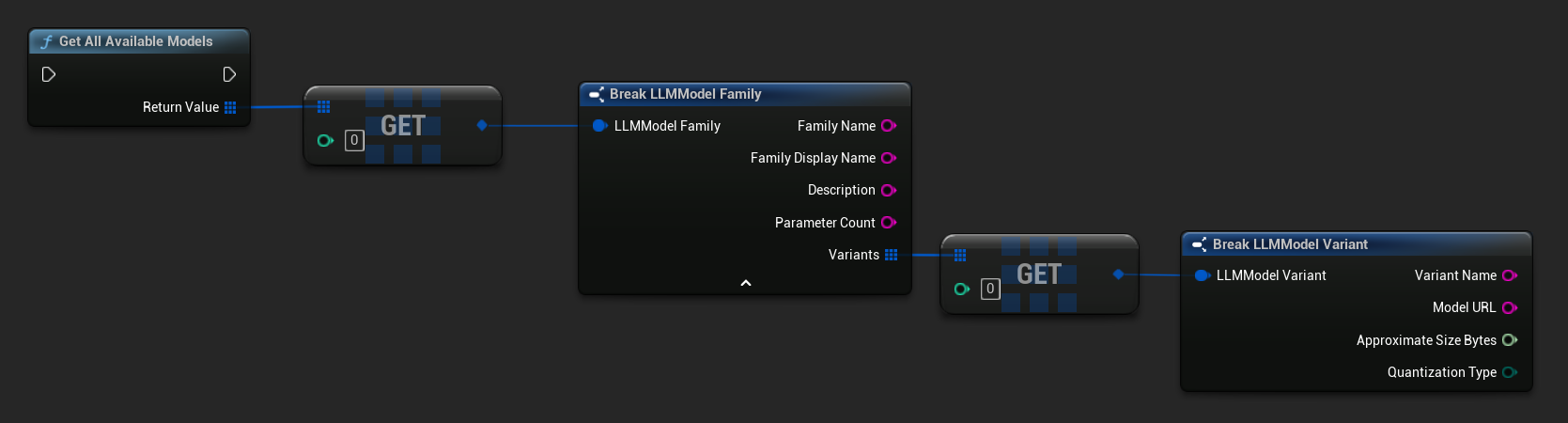
// Built-in catalog only
TArray<FLLMModelFamily> Predefined = URuntimeLLMLibrary::GetPredefinedModels();
// Catalog + custom imports
TArray<FLLMModelFamily> All = URuntimeLLMLibrary::GetAllAvailableModels();
URLからビルドメタデータを生成する
生のURLからモデルのメタデータを構築します(フィールドはファイル名から派生します)。
- ブループリント
- C++
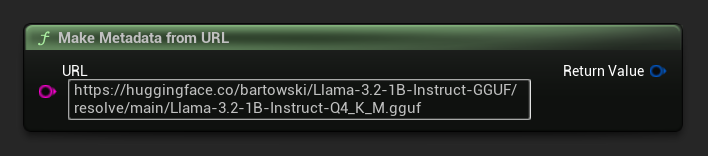
FLLMModelMetadata Metadata = URuntimeLocalLLM::MakeMetadataFromURL(
TEXT("https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.gguf")
);
ユーティリティ関数
書式設定とエラー表示のためのヘルパー関数セットが提供されています。
バイトを読み取り可能な文字列に変換
バイト数を人間が読みやすい文字列(例:「4.07 GB」)に変換します。UIでモデルサイズを表示するのに便利です。
フォーマットダウンロードの進行状況
ダウンロード進捗文字列を「1.23 GB / 4.07 GB (30.2%)」のようにフォーマットします。合計サイズが不明な場合は、受信済みの量のみを返します。
エラー説明の取得 / エラーコード文字列
Get LLM Error Description はエラーコードに対応する人間が読めるテキストの説明を返します。Get LLM Error Code String は列挙値の名前を文字列として返します(ログ記録に便利です)。
エラーコードリファレンス
| Code | 値 | 説明 |
|---|---|---|
| 不明 | 0 | 未指定のエラー |
| ModelLoadFailed | 10 | GGUFファイルの読み込みに失敗しました(ファイルの破損、互換性のない形式など)。 |
| ContextCreateFailed | 11 | 推論コンテキストの作成に失敗しました |
| モデル未読み込み | 20 | モデルがロードされていない状態で推論が試行されました。 |
| ChatTemplateFailed | 21 | モデルのチャットテンプレートの適用に失敗しました |
| トークン化失敗 | 22 | 入力テキストをトークン化できませんでした。 |
| ContextOverflow | 23 | プロンプトとコンテキストが設定されたコンテキストサイズを超えています。 |
| PromptDecodeFailed | 24 | プロンプトトークンのデコードに失敗しました。 |
| ContextTooFullToGenerate | 25 | 出力を生成するためのコンテキストスペースが不足しています。 |
| GenerationDecodeFailed | 30 | 生成中にトークンのデコードに失敗しました |
| GenerationTruncated | 31 | 生成が停止しました。最大トークン制限に達したためです。 |
| LLMInstanceNull | 40 | LLMインスタンスがnullまたは無効です。 |
| ModelNotFoundOnDisk | 41 | モデルファイルが期待されるパスに存在しません。 |
| ModelURLEmpty | 42 | 空のURLでダウンロードがリクエストされました。 |
| モデルダウンロードキャンセル済み | 43 | ダウンロードがキャンセルされました。 |
| ModelDownloadEmptyData | 44 | ダウンロードは完了しましたが、レスポンスボディが空でした。 |
| モデルダウンロード保存失敗 | 45 | ダウンロードは完了しましたが、ファイルをディスクに保存できませんでした。 |