推論パラメータ
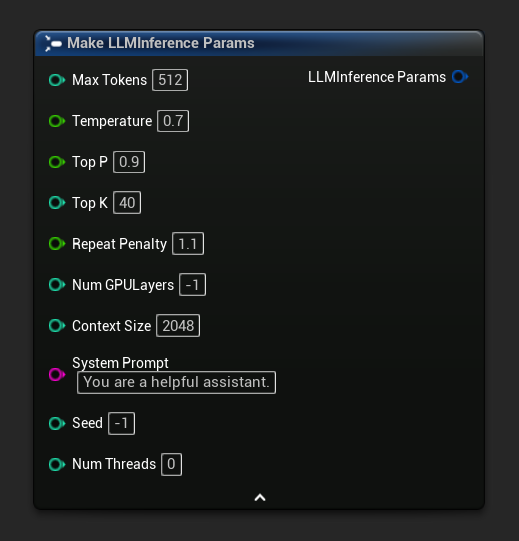
LLM推論パラメータ構造は、モデルの読み込みとテキスト生成の方法を制御します。これらのパラメータはモデルを読み込む際に渡します。このページでは、各パラメータとその効果について説明します。
パラメータリファレンス
| パラメータ | Type | デフォルト | 範囲 | 説明 |
|---|---|---|---|---|
| 最大トークン数 | int32 | 512 | 1~8192 | 1回の応答で生成する最大トークン数 |
| 温度 | float | 0.7 | 0.0~2.0 | ランダム性を制御します。0.0 = 決定論的。値が高いほど、より創造的な出力になります。 |
| Top P | float | 0.9 | 0.0~1.0 | Nucleusサンプリング。累積確率がこの値を超えるトークンのみが考慮されます。 |
| Top K | int32 | 40 | 0~200 | 上位K個の最も確率の高いトークンに選択を制限します。0 = 無効 |
| 繰り返しペナルティ | float | 1.1 | 0.0~3.0 | 出力に既に出現したトークンにペナルティを課します。1.0 = ペナルティなし |
| GPUレイヤー数 | int32 | -1 | -1~200 | GPUにオフロードするモデルレイヤー。-1 = 自動。0 = CPUのみ。 |
| コンテキストサイズ | int32 | 2048 | 128~131072 | 最大コンテキストウィンドウ(トークン数)。値を大きくすると、より多くのメモリを使用します。 |
| システムプロンプト | FString | 「あなたは役立つアシスタントです。」 | — | システムの動作を形成するシステム指示 |
| シード | int32 | -1 | -1+ | 出力を再現可能にするためのランダムシード。-1 = ランダム |
| スレッド数 | int32 | 0 | 0~128 | 生成に使用するCPUスレッド数。0 = 自動 |
使用方法
- ブループリント
- C++
推論パラメータは、ロードノードおよび非同期ノード上で構造体ピンとして表示されます。構造体を分解して個別の値を設定します。
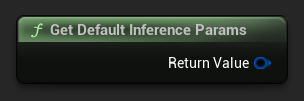
デフォルトのパラメータセットを開始点として取得するには、Get Default Inference Params を使用します。
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
プラットフォームの推奨事項
モバイル / VR(Android、iOS、Meta Quest)
- コンテキストサイズ: 1024~2048
- GPUレイヤー数: デバイスがGPUコンピュート対応を確認していない限り、0(CPUのみ)
- 最大トークン数: 応答性の高いインタラクションには256未満
- スレッド数: デバイスに応じて2~4
デスクトップ(Windows、Mac、Linux)
- コンテキストサイズ: ほとんどの会話で2048~8192
- GPUレイヤー数: -1(自動)でGPUアクセラレーションを利用可能な場合に活用
- スレッド数: 0(自動)
- 最大トークン数: 長い応答には512~2048
長時間の会話
アプリケーションが長時間のセッション(NPCの対話、永続的なアシスタント、ロールプレイ)にわたって会話を維持する場合は、単にコンテキストサイズを増やすのではなく、自動要約と組み合わせることを検討してください。自動要約を有効にした2048~4096の適度なコンテキストサイズは、レイテンシとメモリ使用量を安定させます。一方、大きなコンテキストウィンドウでは、生成ごとに徐々に処理が遅くなります。詳細は自動コンテキスト要約をご覧ください。