オーディオ処理ガイド
このガイドでは、リップシンクジェネレーターにオーディオデータを供給するための、さまざまなオーディオ入力方法の設定方法について説明します。先にセットアップガイドを完了していることを確認してください。
音声入力処理
音声入力を処理する方法を設定する必要があります。音声ソースに応じて、いくつかの方法があります。
- マイク(リアルタイム)
- マイク(再生)
- テキスト読み上げ(ローカル)
- テキスト読み上げ(外部API)
- オーディオファイル/バッファから
- ストリーミングオーディオバッファ
このアプローチは、マイクに向かって話している間、リアルタイムでリップシンクを実行します。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime Audio Importerを使用してキャプチャ可能なサウンドウェーブを作成する
- Linux と Pixel Streaming を使用する場合は、代わりに Pixel Streaming Capturable Sound Wave を使用してください。
- オーディオのキャプチャを開始する前に、
OnPopulateAudioDataデリゲートにバインドします - バインドされた関数内で、ランタイムビジームジェネレーターから
ProcessAudioDataを呼び出します - マイクからのオーディオキャプチャを開始します
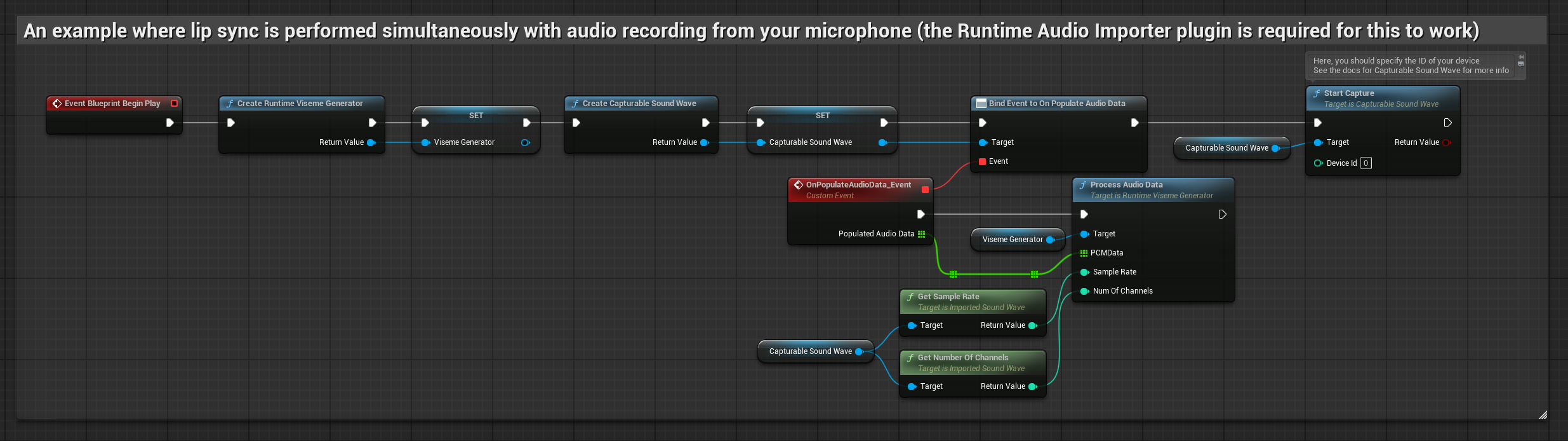
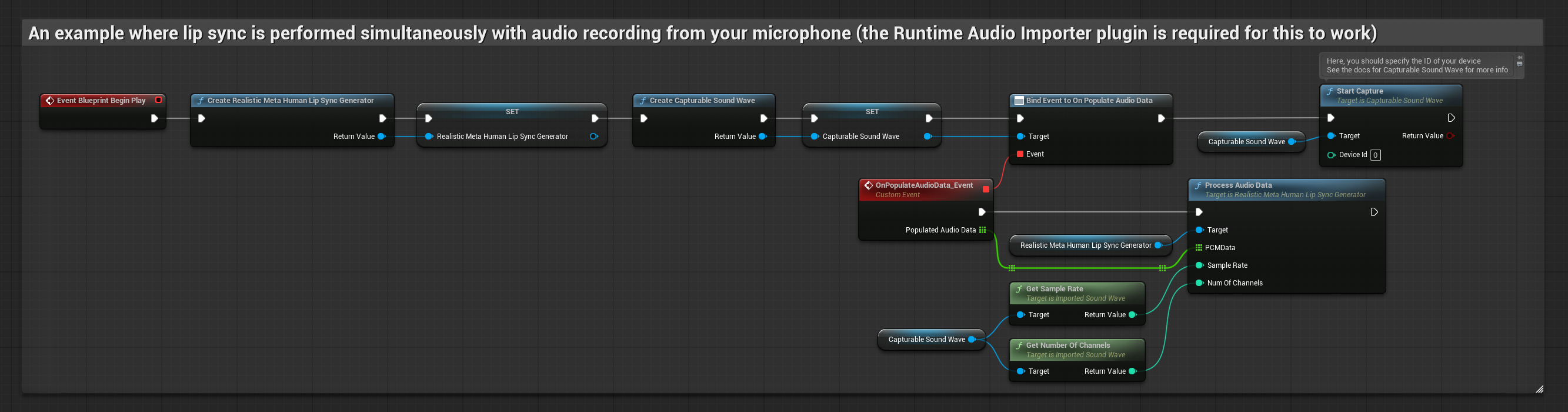
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。
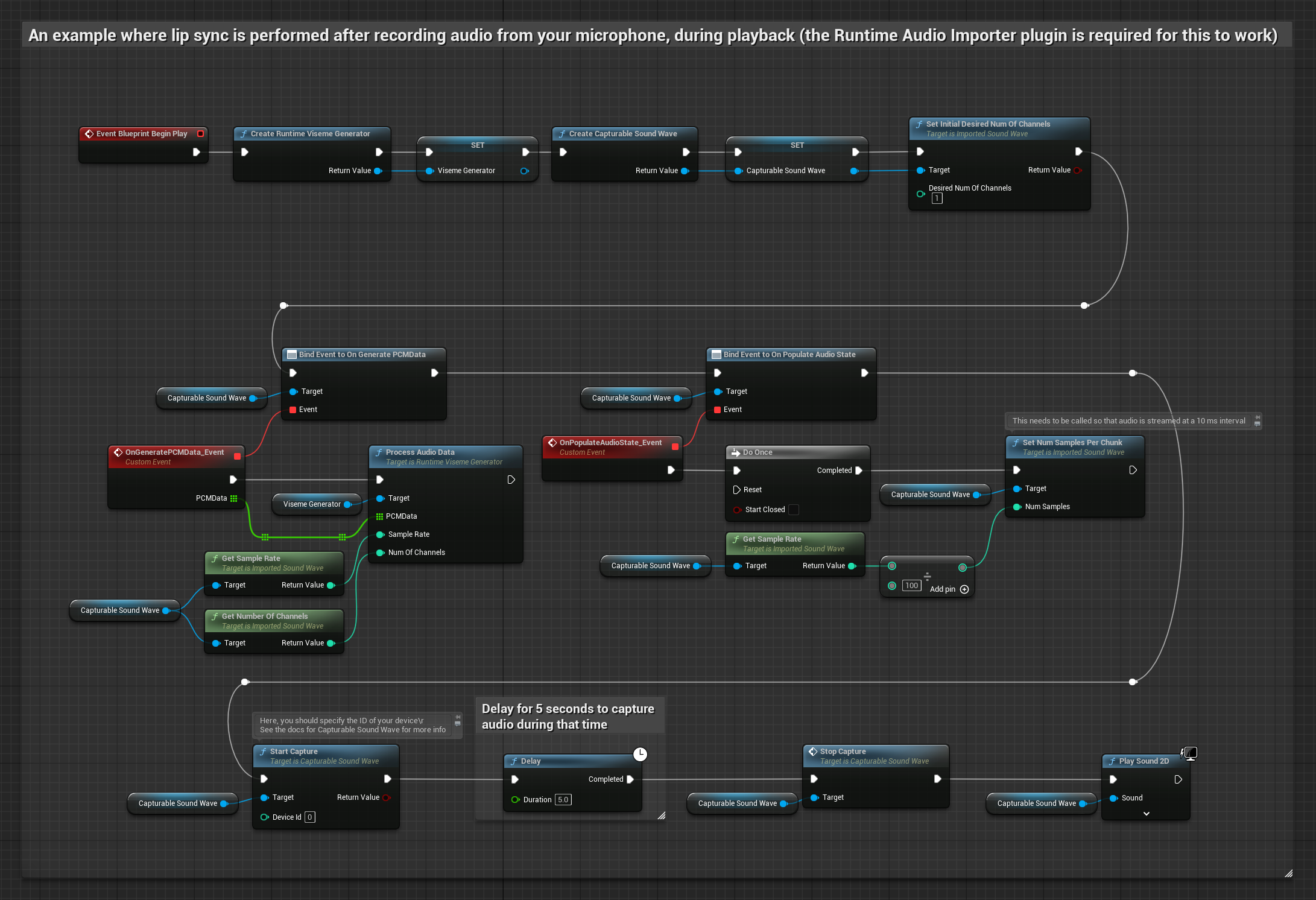
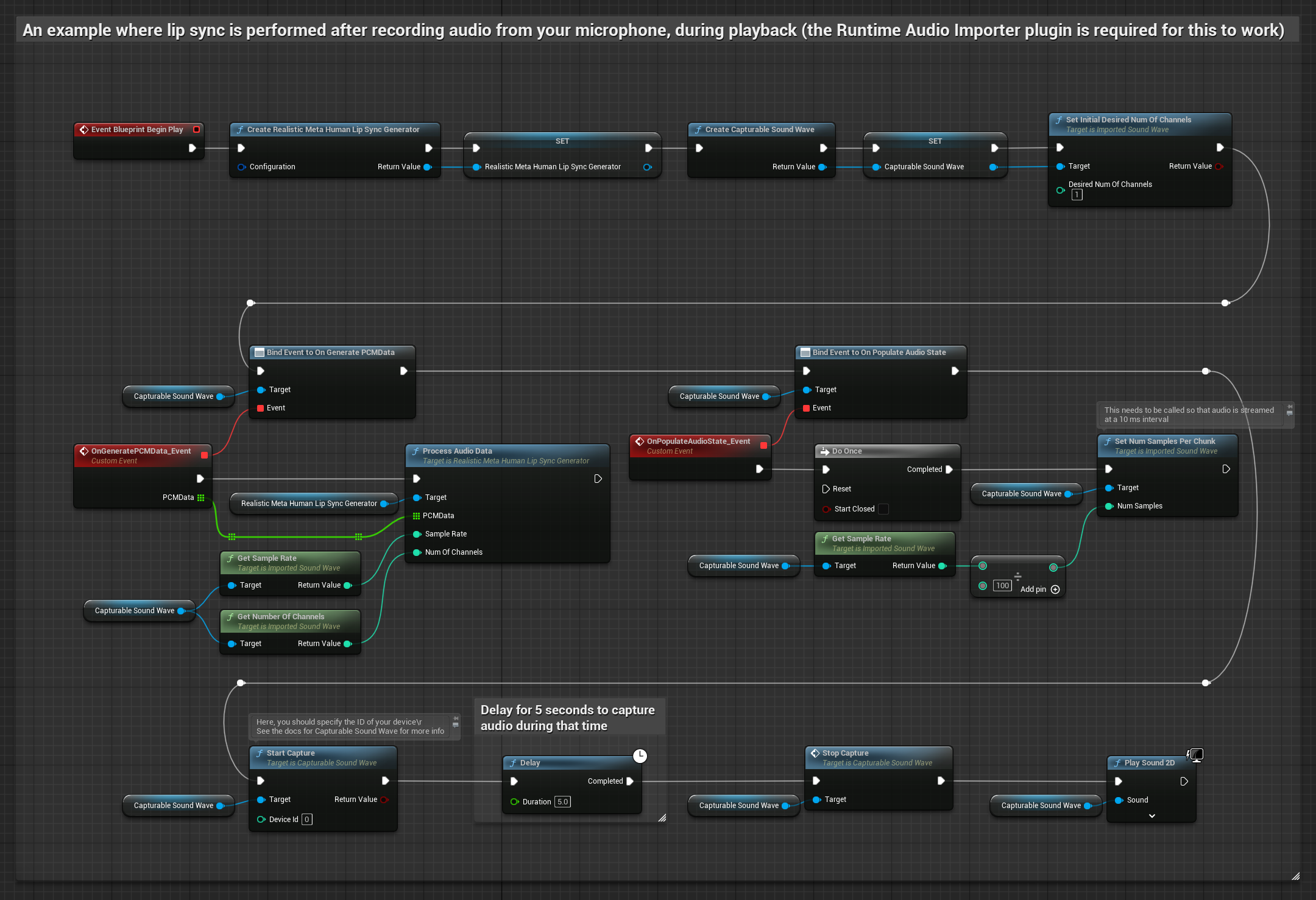
このアプローチでは、マイクから音声をキャプチャし、リップシンクとともに再生します。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime Audio Importerを使用してキャプチャ可能なサウンドウェーブを作成する
- Linux と Pixel Streaming を使用する場合は、代わりに Pixel Streaming Capturable Sound Wave を使用してください。
- マイクからオーディオキャプチャを開始する
- キャプチャ可能なサウンドウェーブを再生する前に、その
OnGeneratePCMDataデリゲートにバインドする - バインドされた関数内で、ランタイムビジームジェネレーターの
ProcessAudioDataを呼び出す
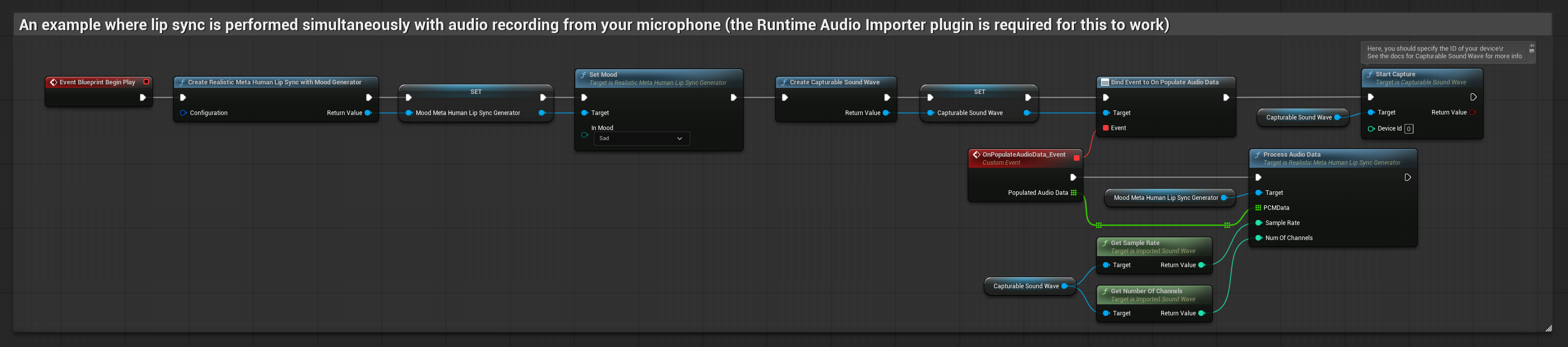
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。

- 通常
- ストリーミング
このアプローチは、ローカルTTSを使用してテキストから音声を合成し、リップシンクを実行します。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime Text To Speechを使用してテキストから音声を生成する
- Runtime Audio Importerを使用して合成されたオーディオをインポートする
- インポートしたサウンドウェーブを再生する前に、その
OnGeneratePCMDataデリゲートにバインドする - バインドされた関数内で、Runtime Viseme Generatorの
ProcessAudioDataを呼び出す
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。
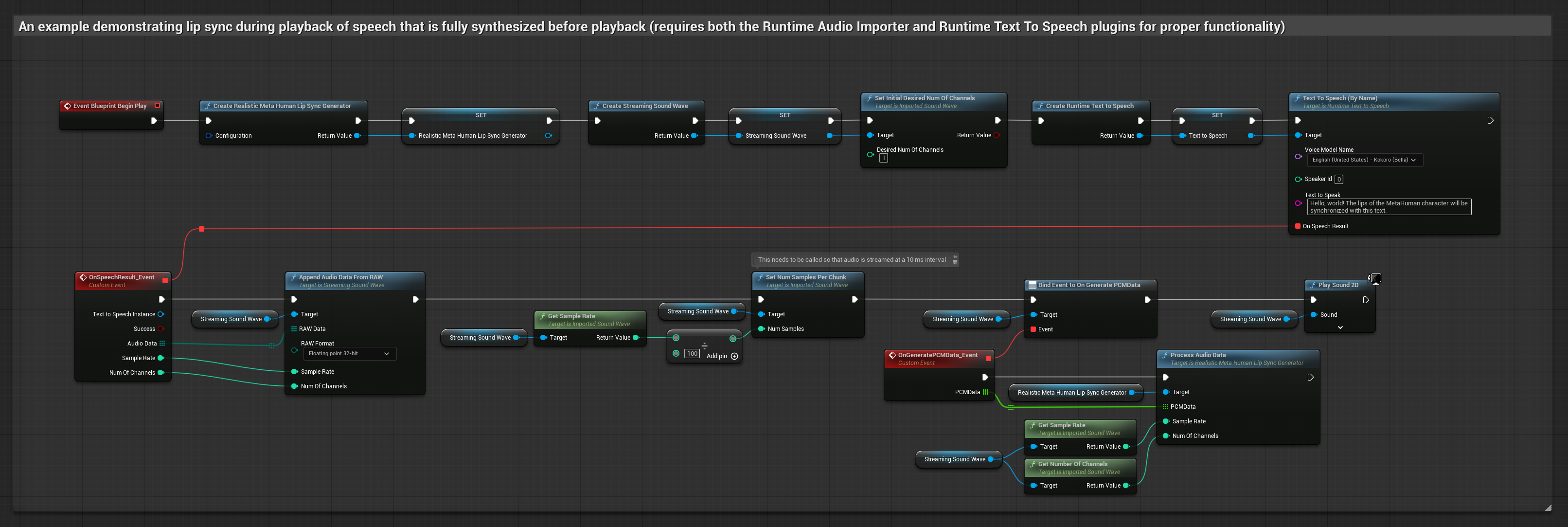
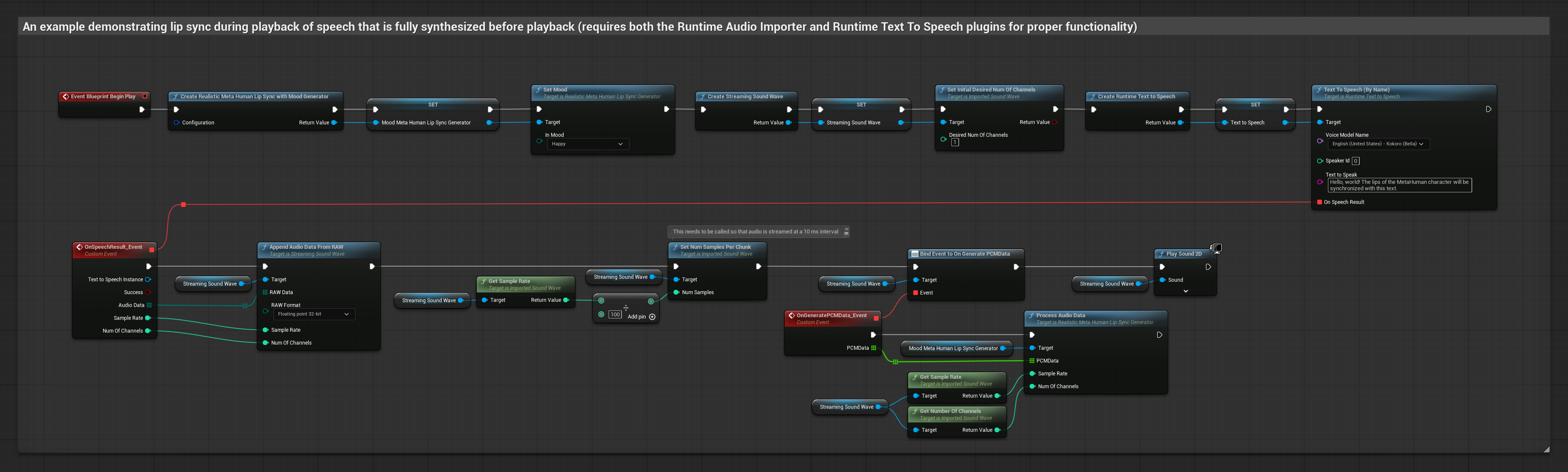
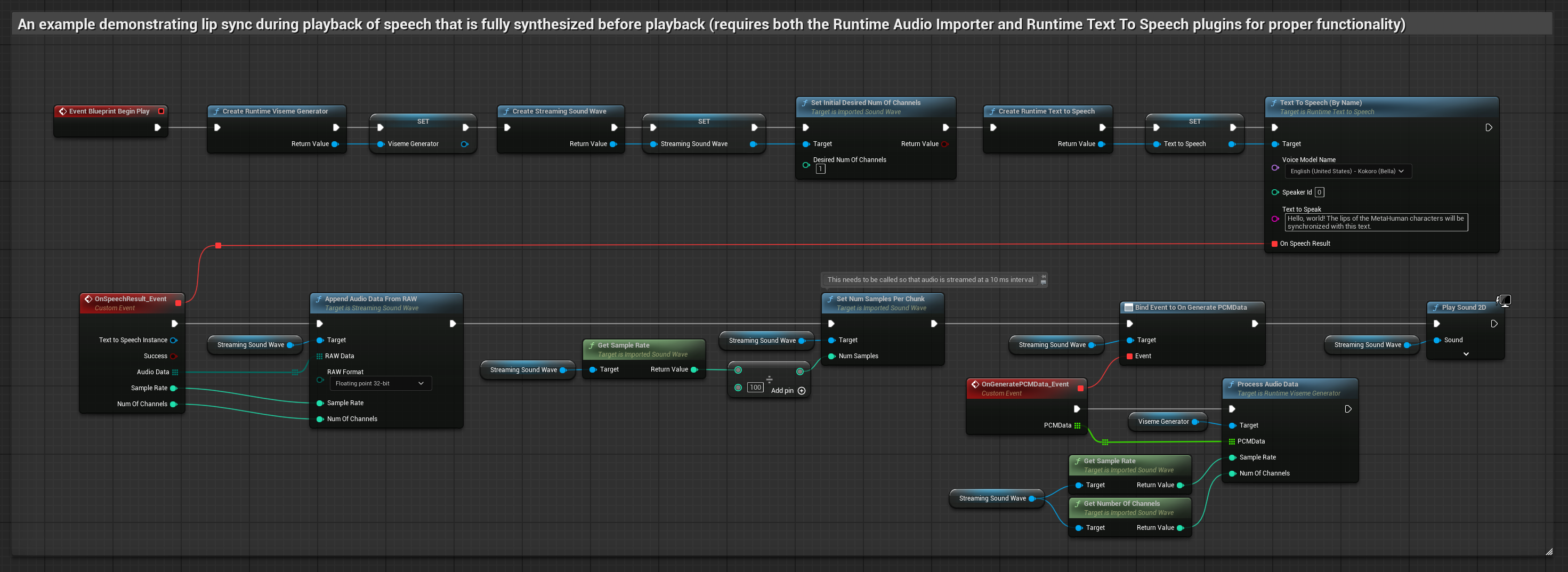
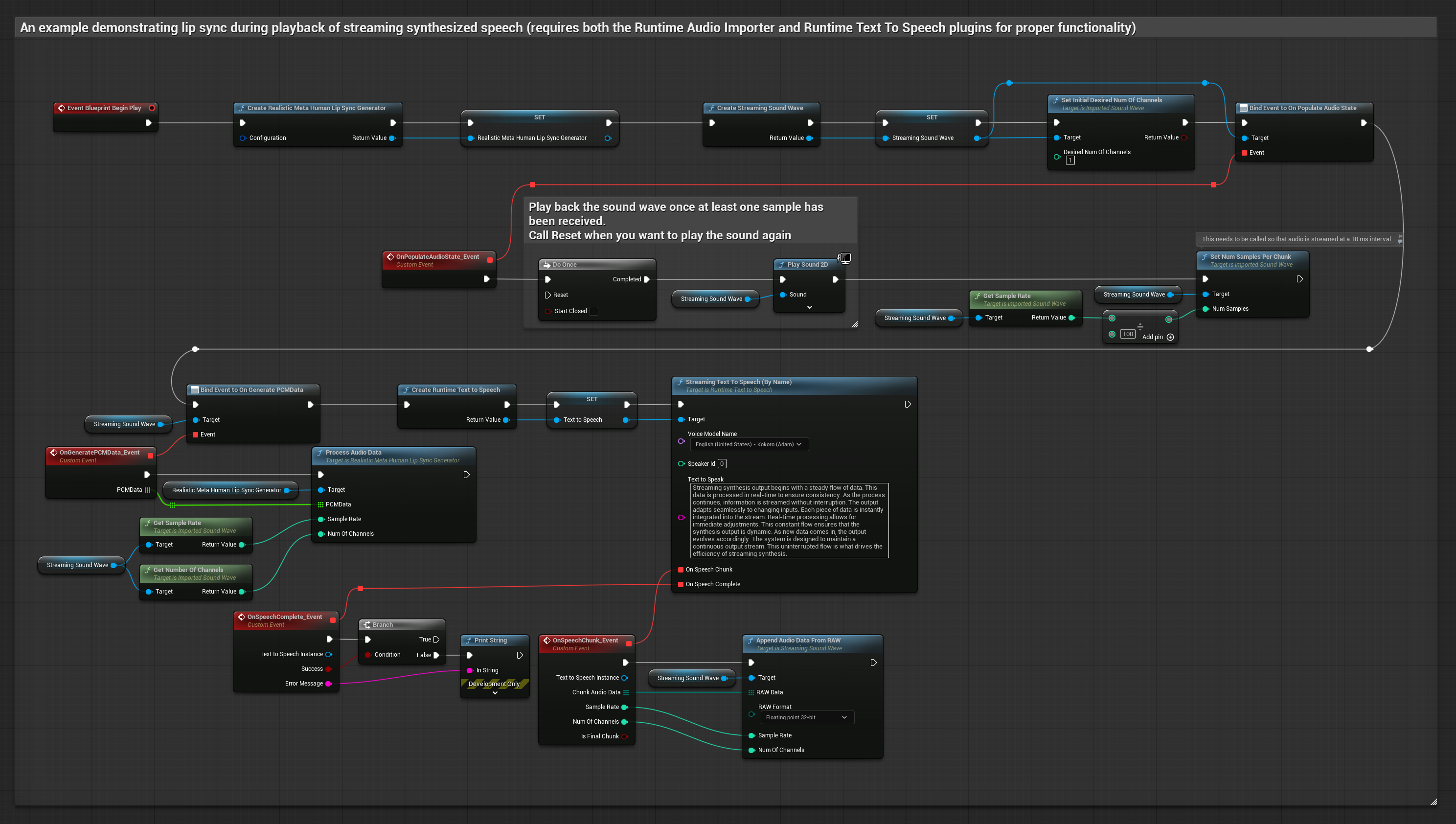
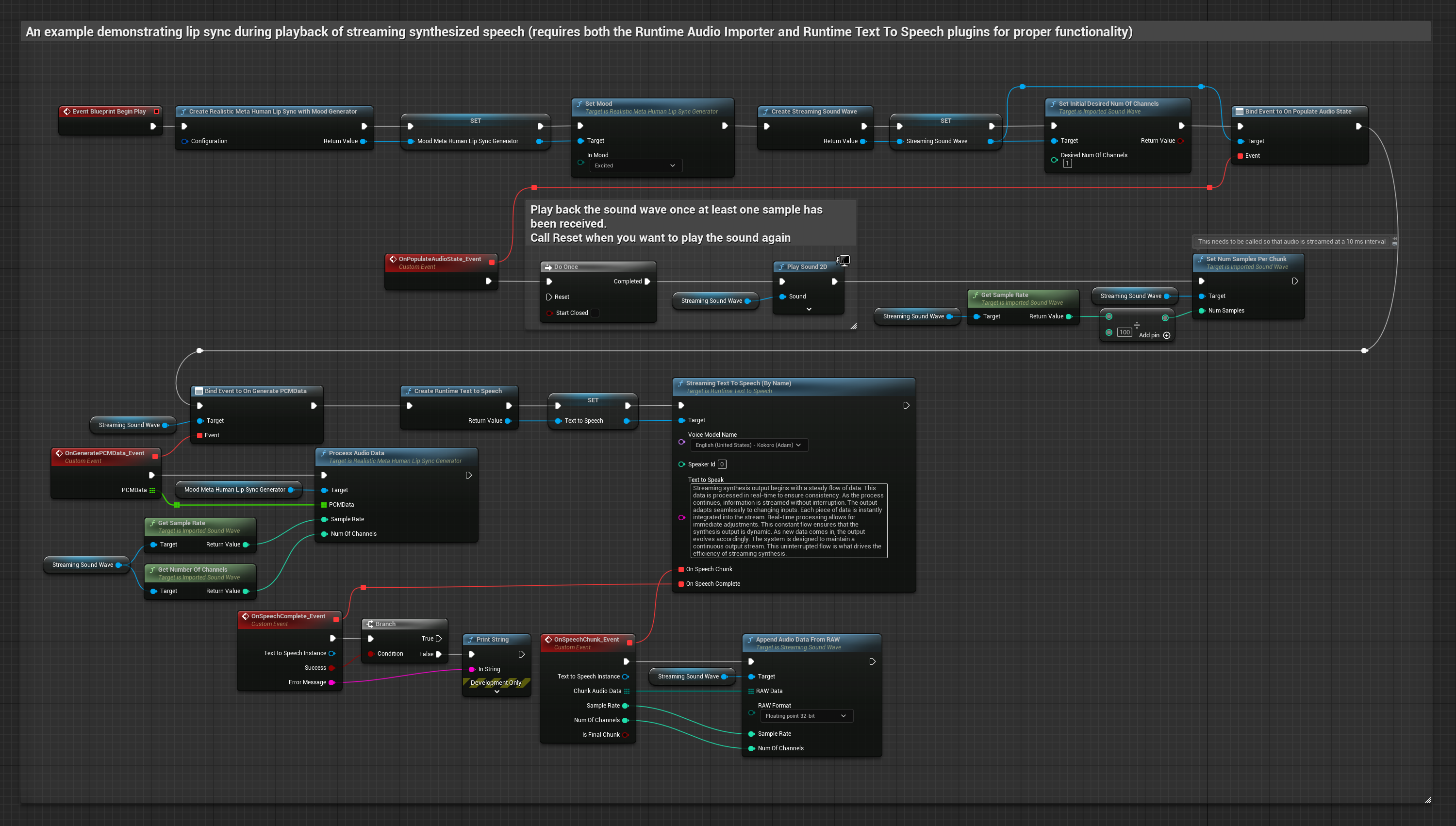
このアプローチでは、ストリーミング音声合成とリアルタイムのリップシンクを組み合わせています。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime Text To Speechを使用して、テキストからストリーミング音声を生成します
- Runtime Audio Importerを使用して、合成されたオーディオをインポートします
- ストリーミングサウンドウェーブを再生する前に、その
OnGeneratePCMDataデリゲートにバインドします - バインドされた関数内で、Runtime Viseme Generatorから
ProcessAudioDataを呼び出します
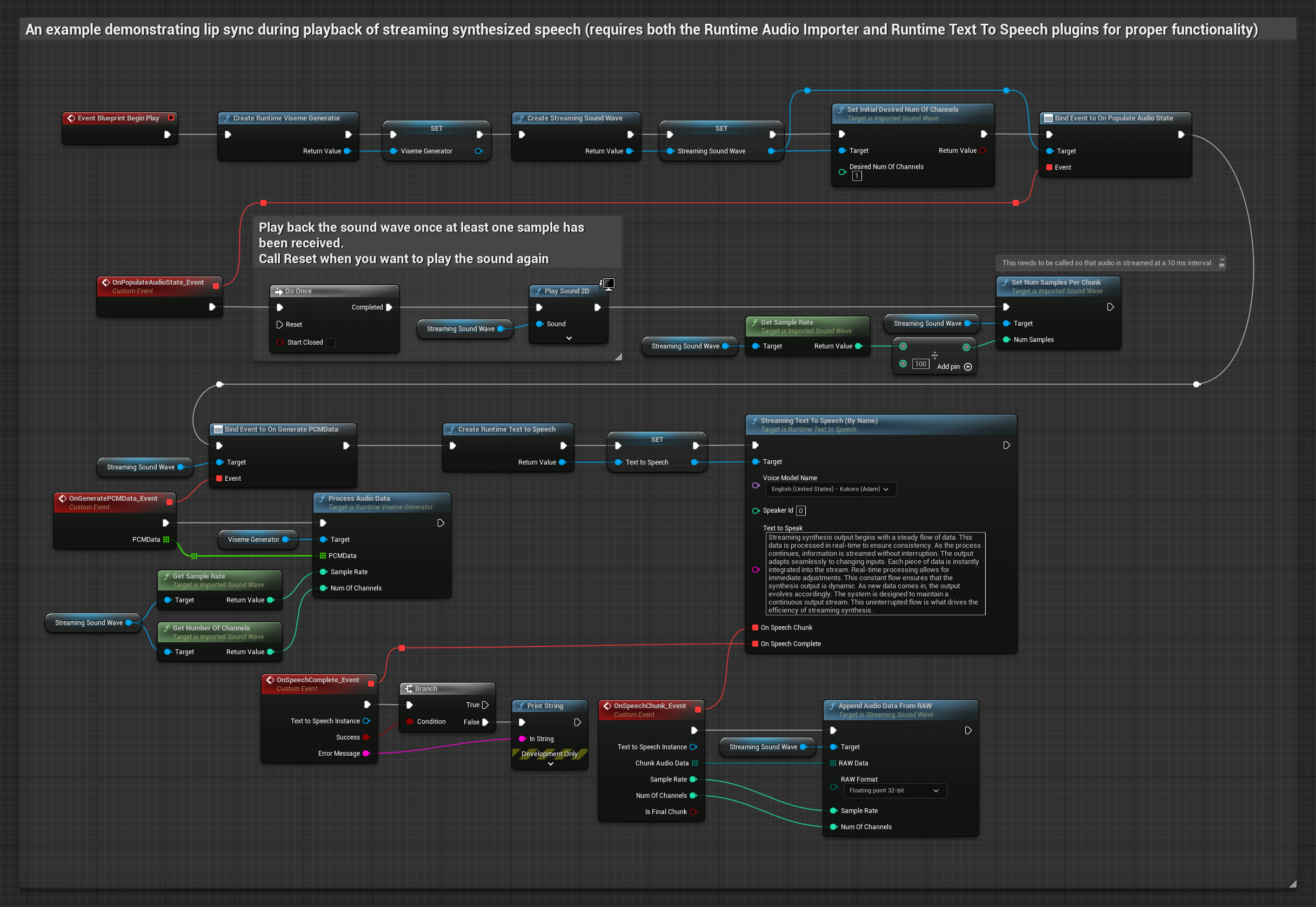
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。
- 通常
- ストリーミング
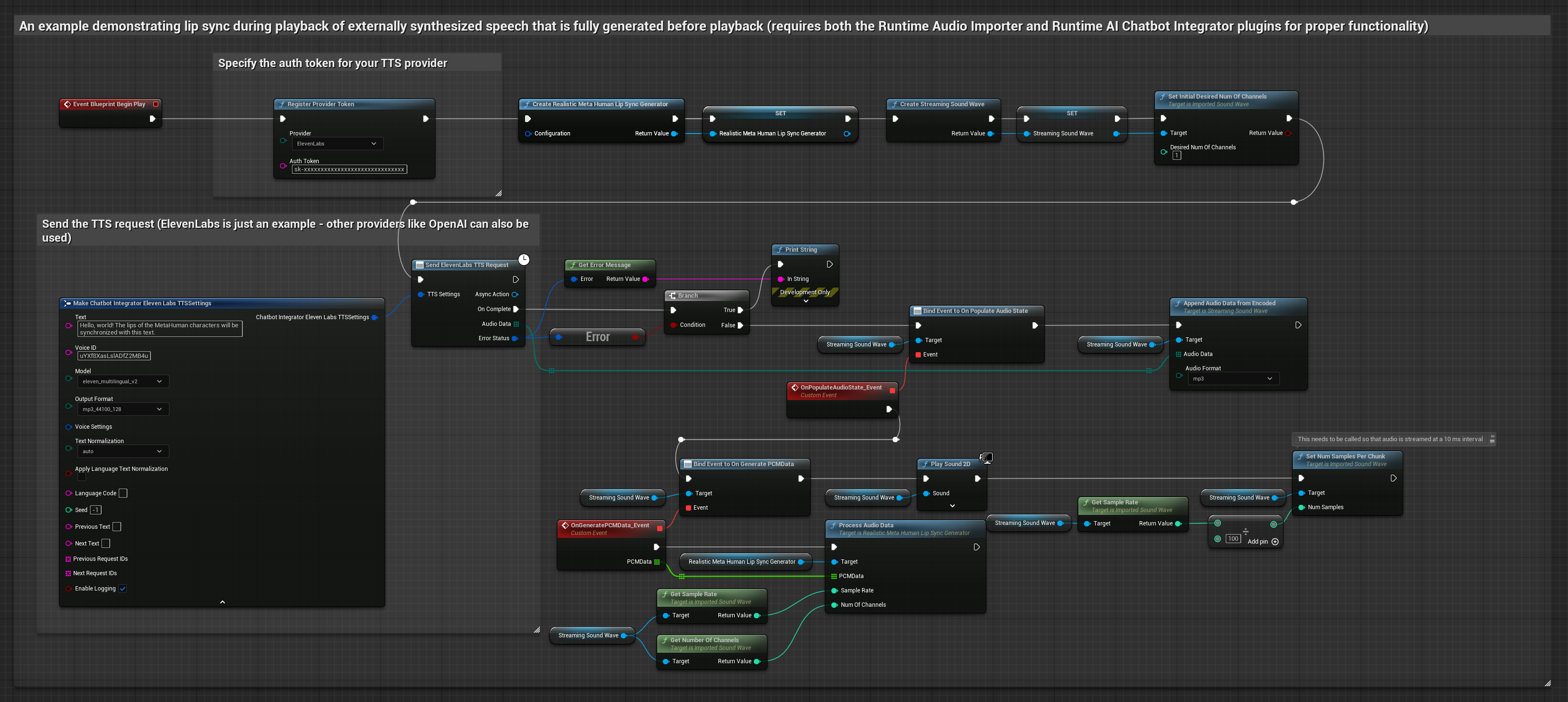
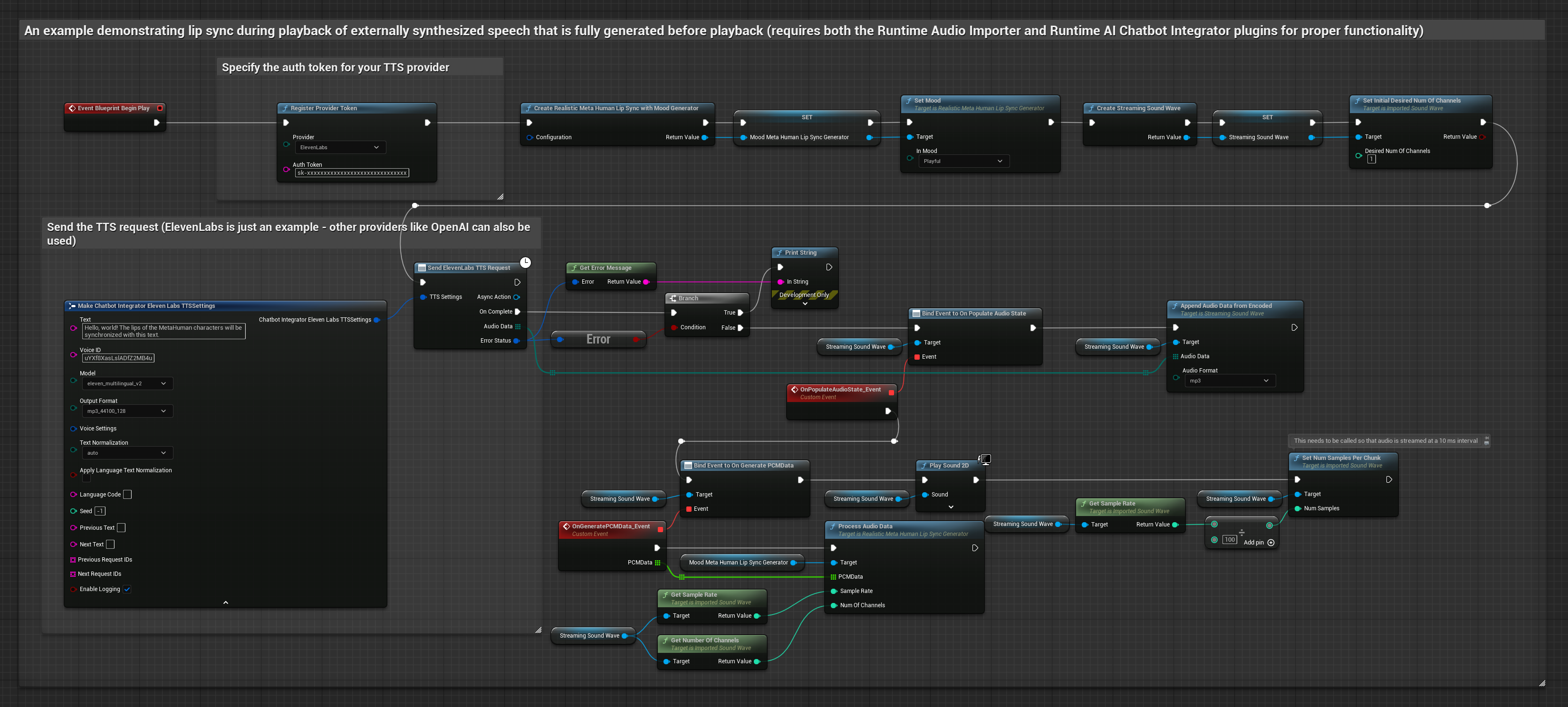
このアプローチでは、Runtime AI Chatbot Integrator プラグインを使用して、AIサービス(OpenAI または ElevenLabs)から合成音声を生成し、リップシンクを実行します。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime AI Chatbot Integratorを使用して、外部API(OpenAI、ElevenLabsなど)を介してテキストから音声を生成します
- Runtime Audio Importerを使用して、合成されたオーディオデータをインポートします
- インポートしたサウンドウェーブを再生する前に、その
OnGeneratePCMDataデリゲートにバインドします - バインドされた関数内で、Runtime Viseme Generatorの
ProcessAudioDataを呼び出します
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。
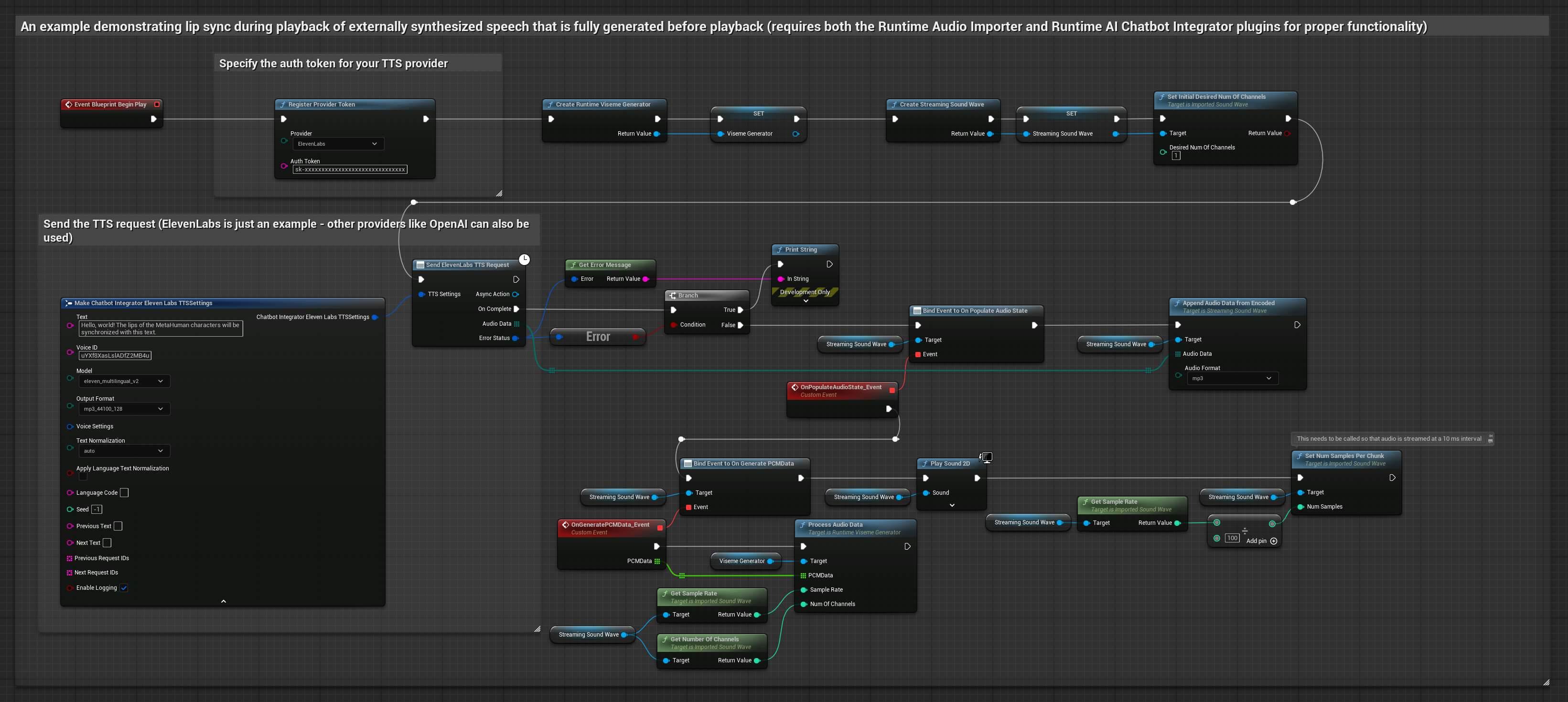
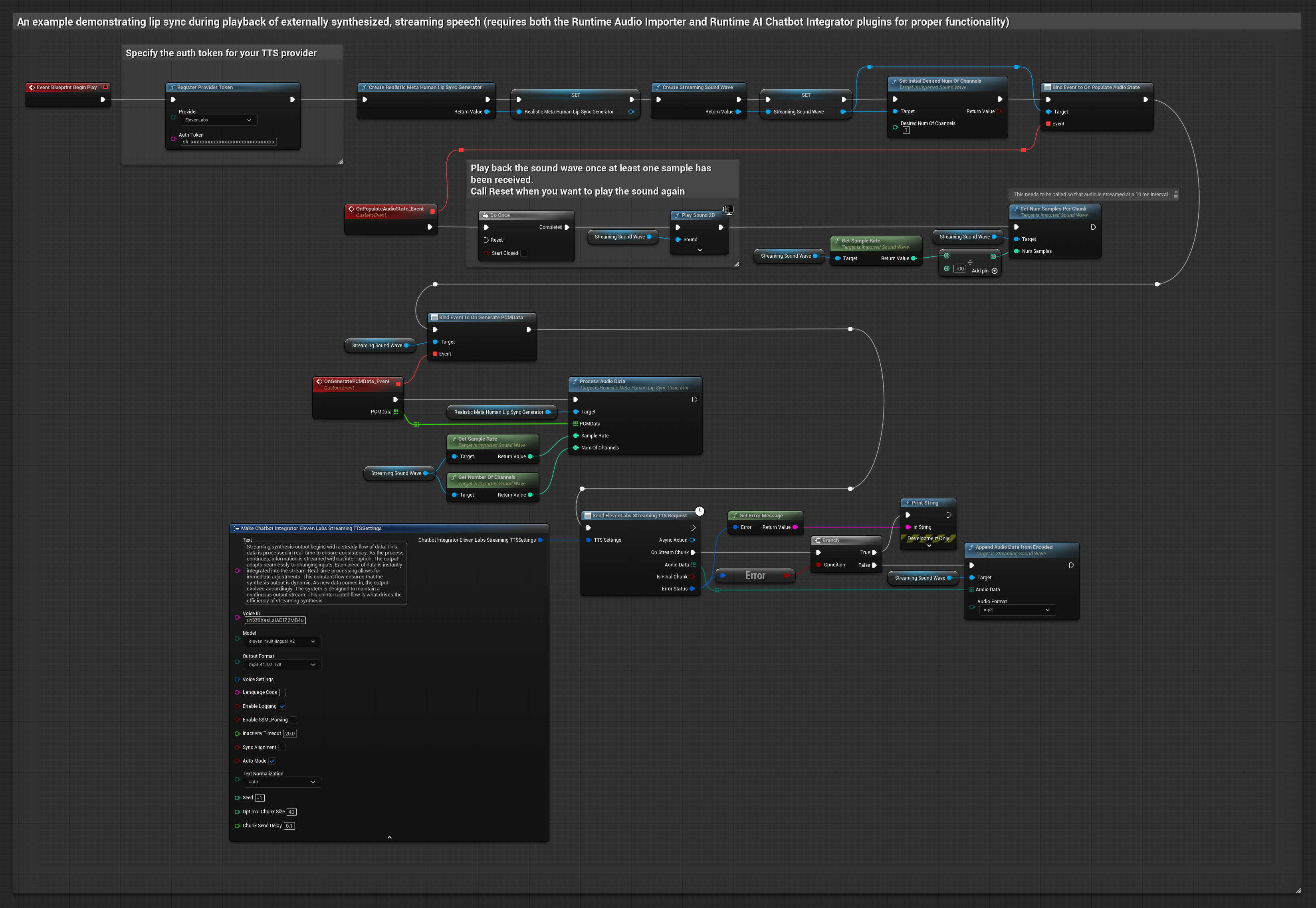
このアプローチでは、Runtime AI Chatbot Integrator プラグインを使用して、AIサービス(OpenAI または ElevenLabs)から合成ストリーミング音声を生成し、リップシンクを実行します。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime AI Chatbot Integratorを使用して、ストリーミングTTS API(ElevenLabs Streaming APIなど)に接続します
- Runtime Audio Importerを使用して、合成されたオーディオデータをインポートします
- ストリーミングサウンドウェーブを再生する前に、その
OnGeneratePCMDataデリゲートにバインドします - バインドされた関数内で、Runtime Viseme Generatorの
ProcessAudioDataを呼び出します
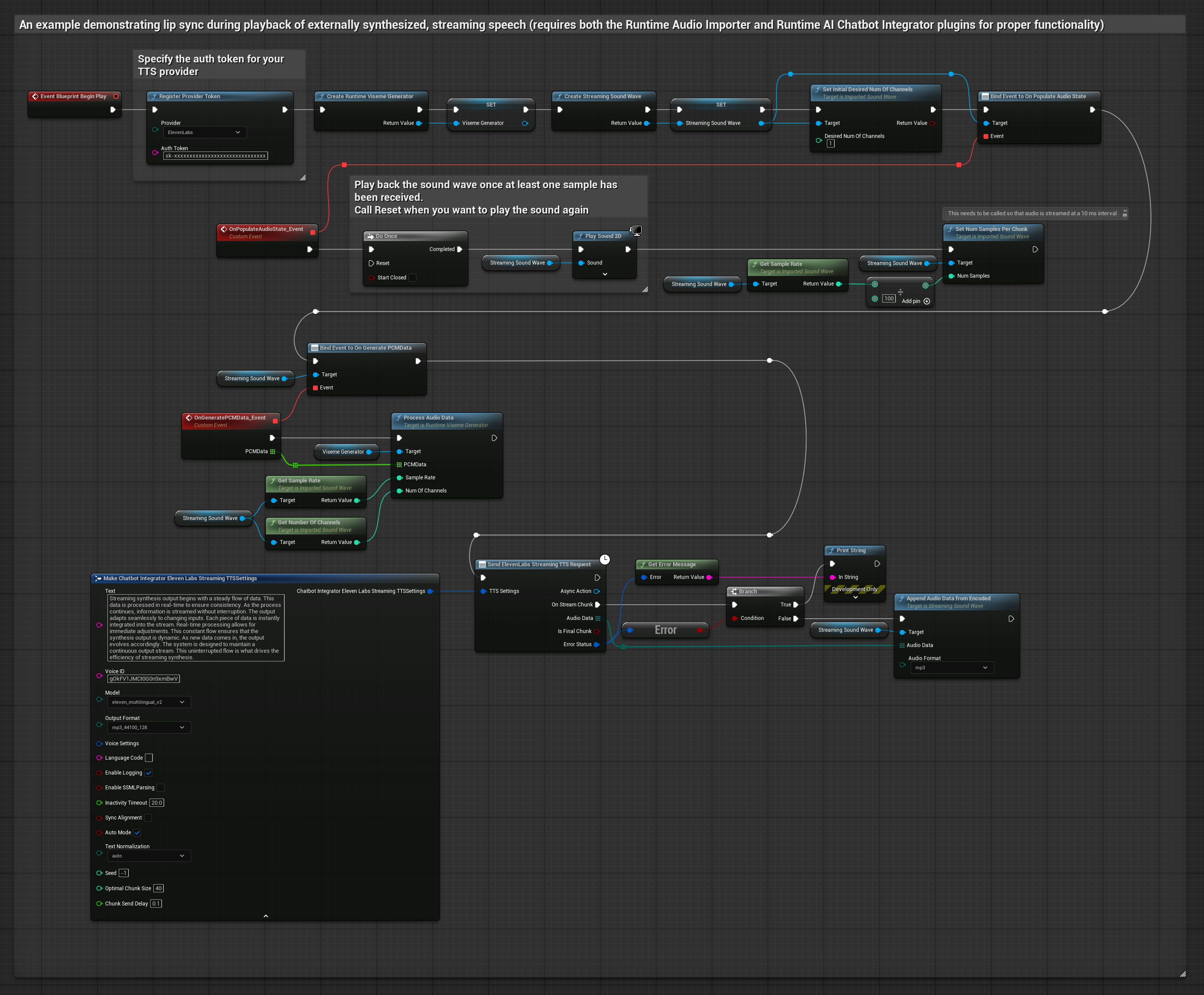
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。

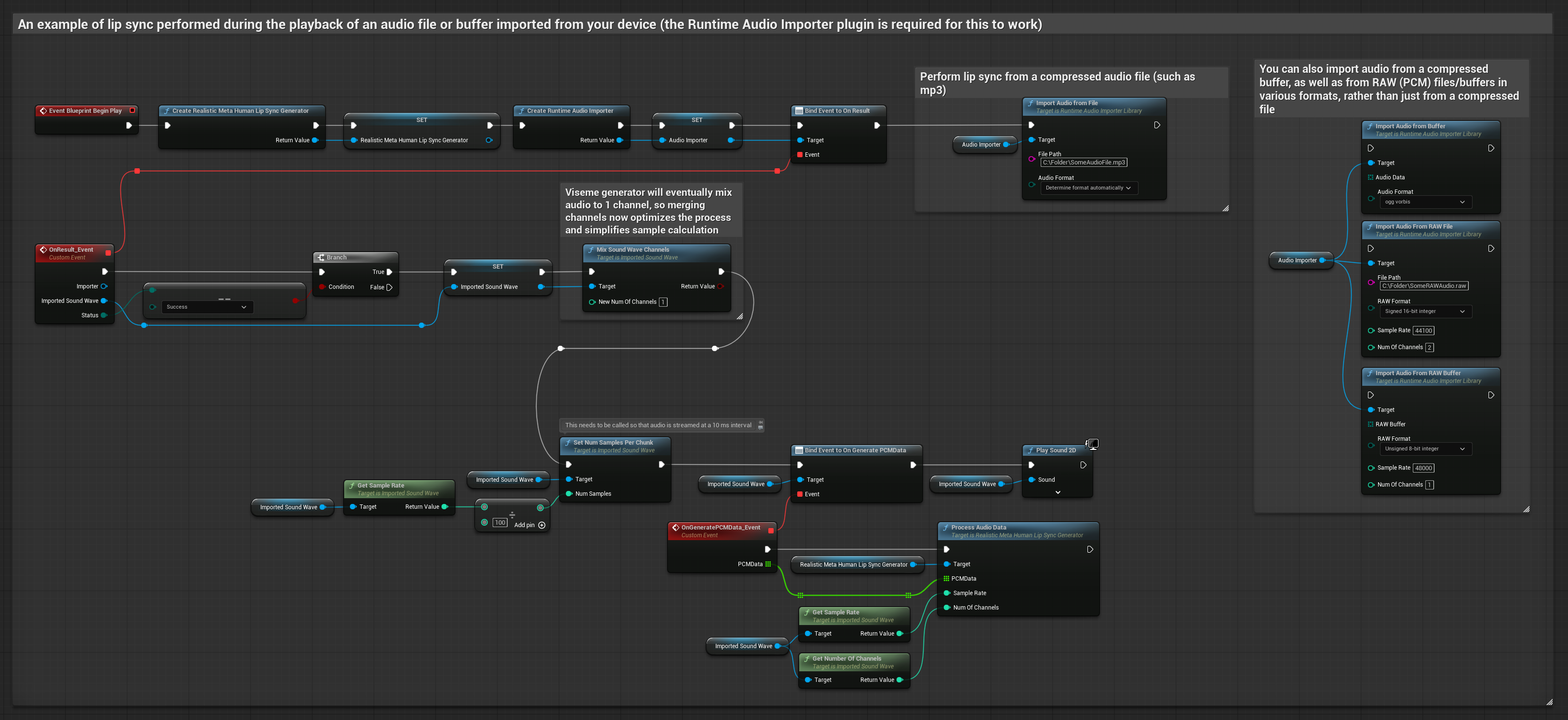
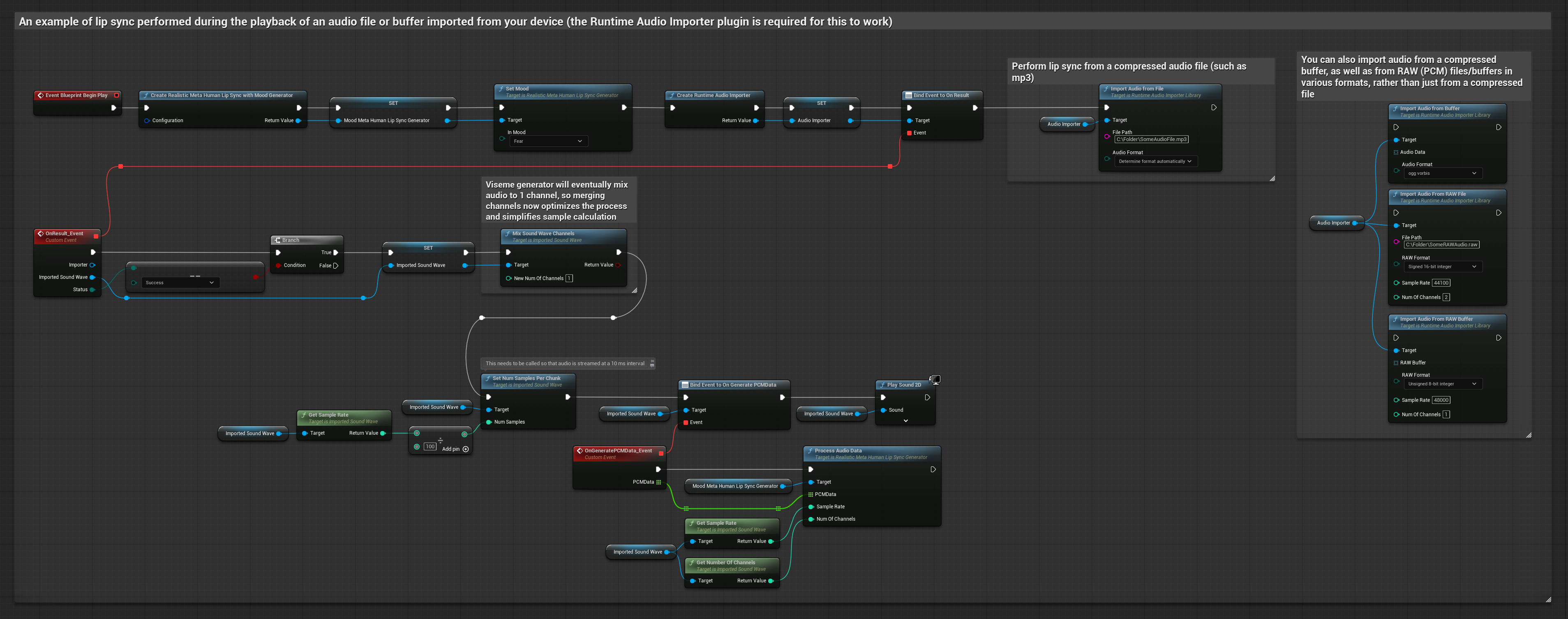
このアプローチでは、事前に録音されたオーディオファイルまたはオーディオバッファを使用してリップシンクを行います。
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- Runtime Audio Importerを使用して、ディスクまたはメモリからオーディオファイルをインポートします
- インポートしたサウンドウェーブを再生する前に、その
OnGeneratePCMDataデリゲートにバインドします - バインドされた関数内で、Runtime Viseme Generatorの
ProcessAudioDataを呼び出します - インポートしたサウンドウェーブを再生し、リップシンクアニメーションを観察します
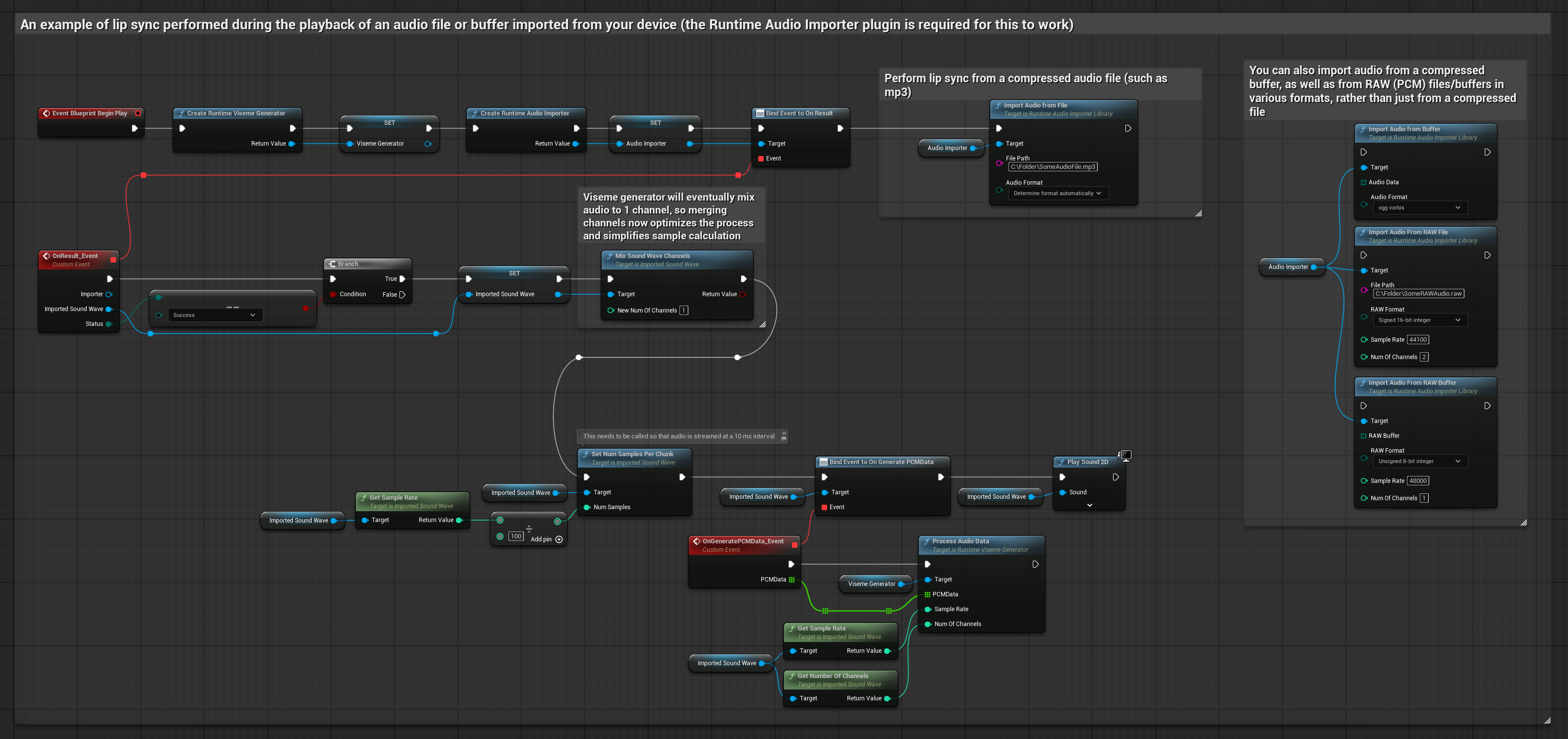
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。
バッファからオーディオデータをストリーミングするには、以下が必要です:
- 標準モデル
- リアリスティックモデル
- ムード対応リアリスティックモデル
- ストリーミングソースから取得可能な浮動小数点PCM形式のオーディオデータ(浮動小数点サンプルの配列)(またはRuntime Audio Importerを使用してより多くのフォーマットをサポート)
- サンプルレートとチャンネル数
- オーディオチャンクが利用可能になるたびに、これらのパラメータを指定してRuntime Viseme Generatorの
ProcessAudioDataを呼び出す
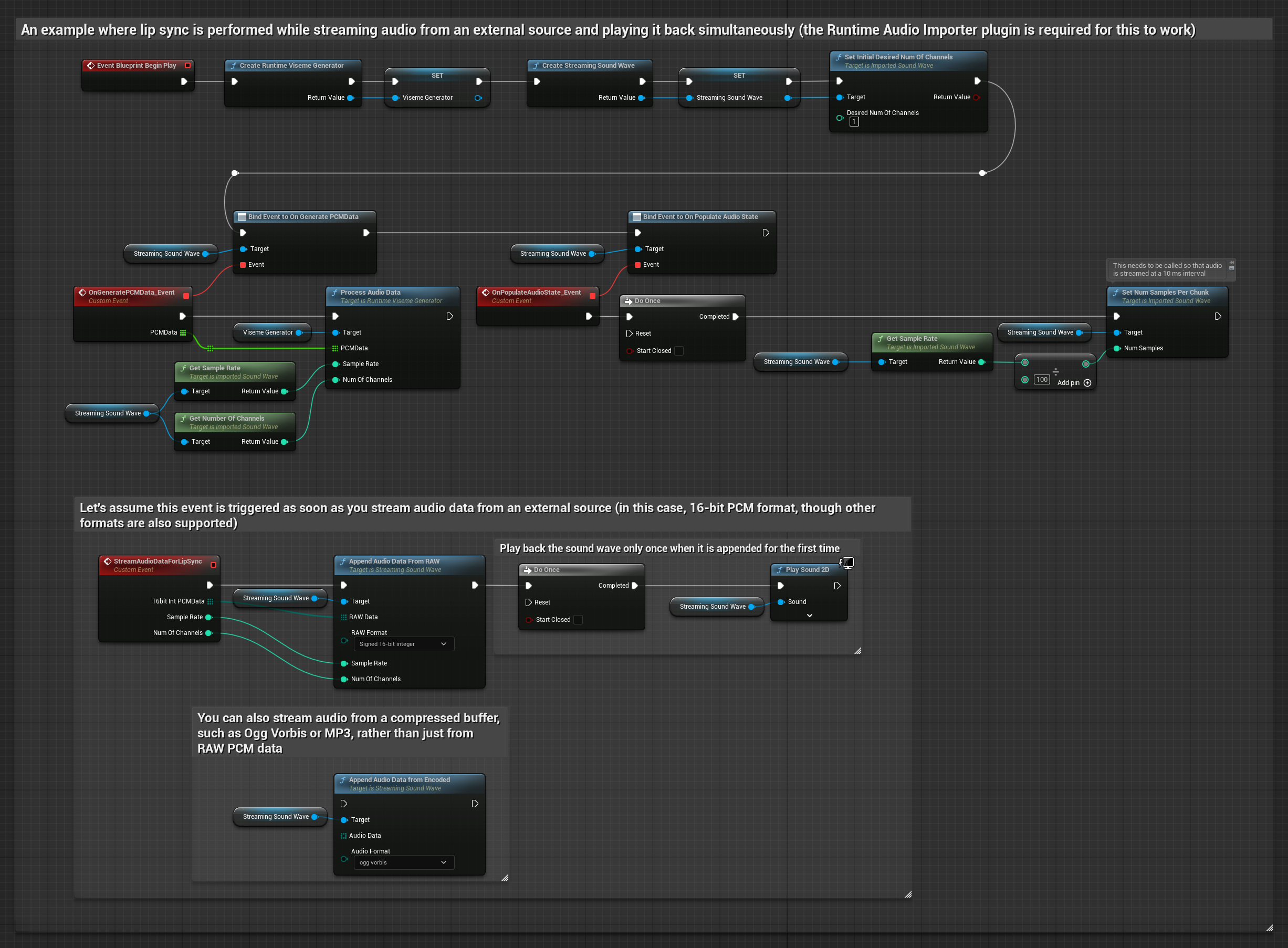
リアリスティックモデルは、スタンダードモデルと同じオーディオ処理ワークフローを使用しますが、VisemeGeneratorの代わりにRealisticLipSyncGenerator変数を使用します。
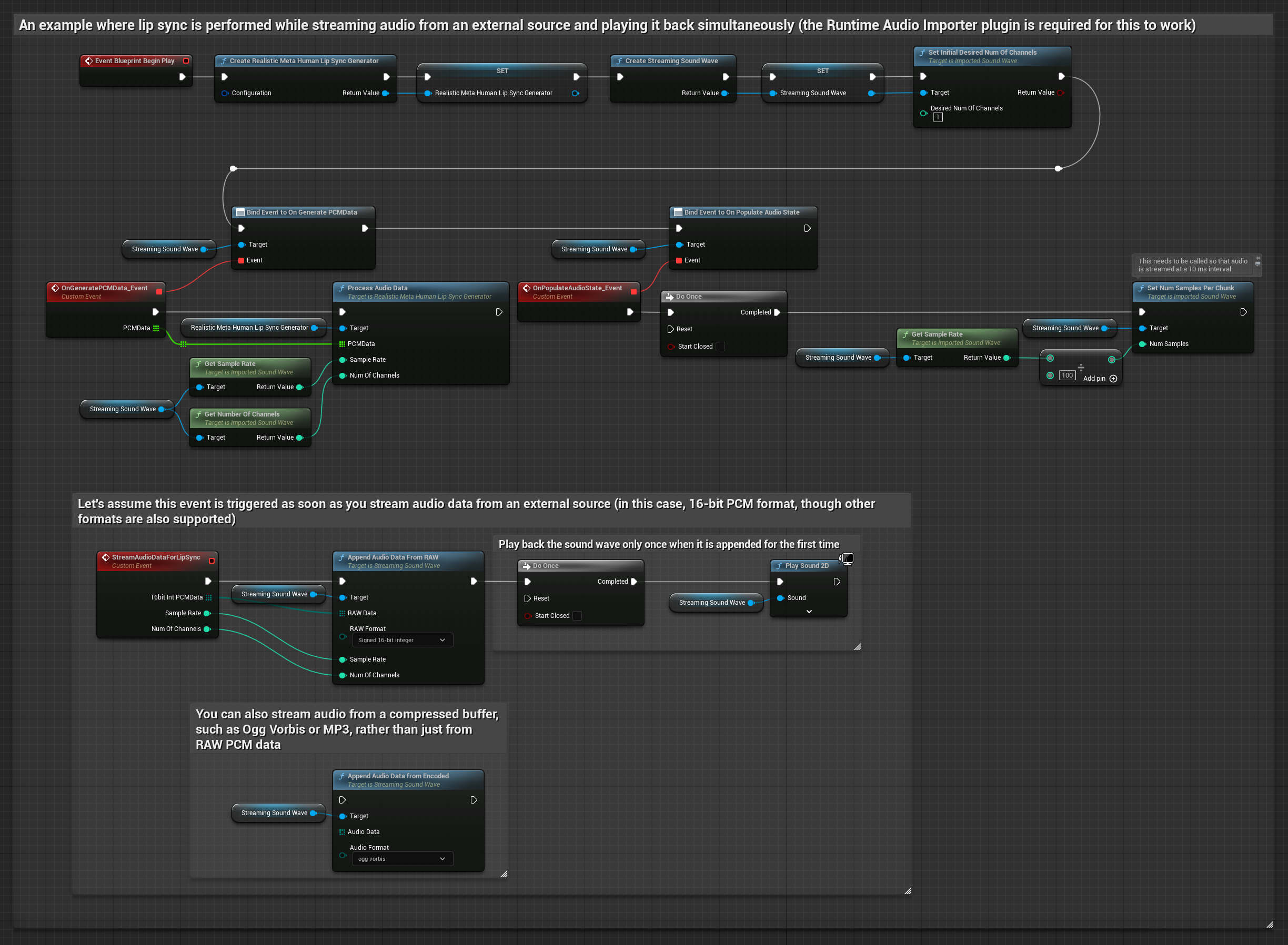
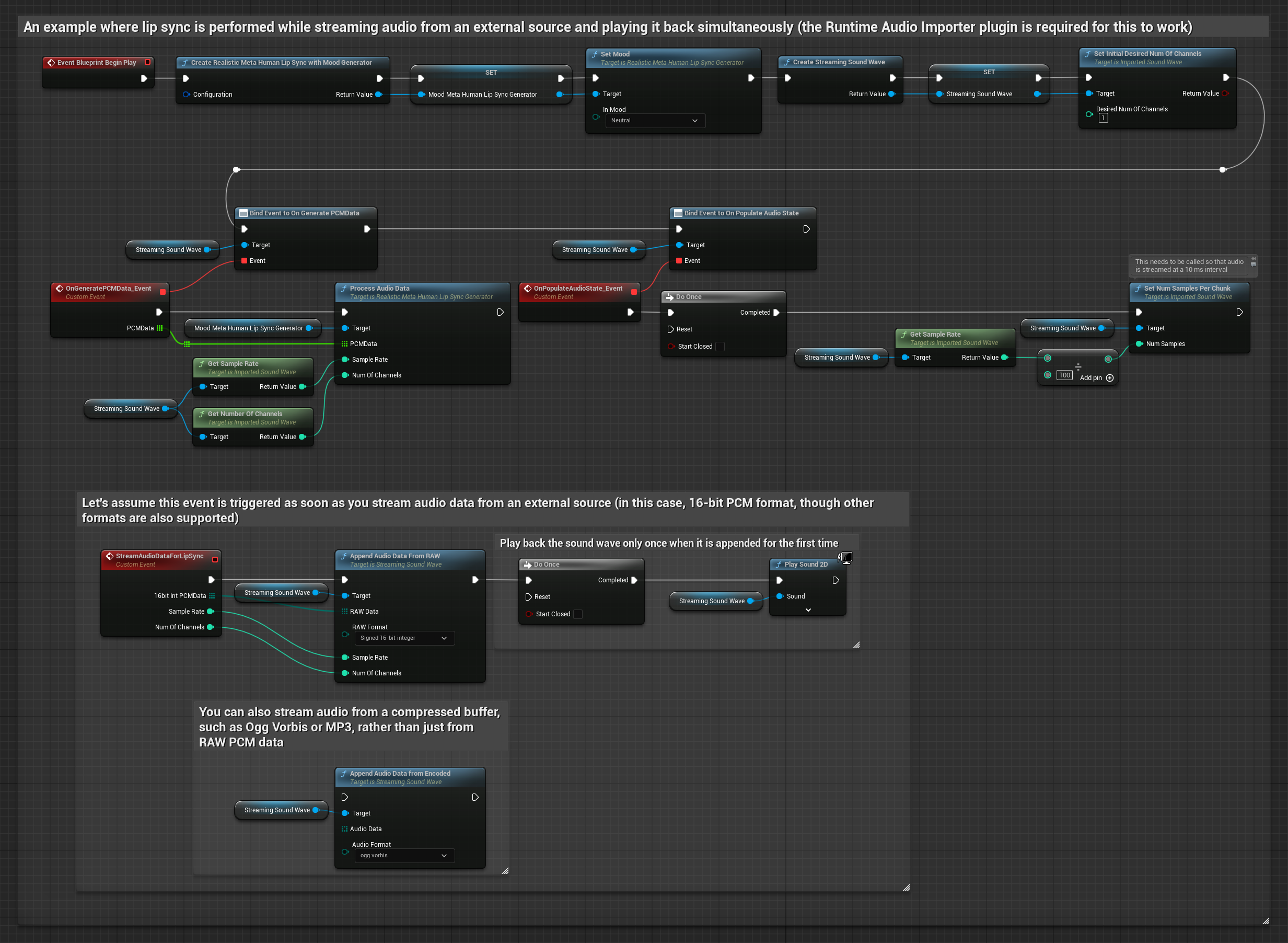
注意: ストリーミングオーディオソースを使用する場合は、歪んだ再生を避けるために、オーディオ再生のタイミングを適切に管理してください。詳細については、ストリーミングサウンドウェーブのドキュメントを参照してください。
処理パフォーマンスのヒント
-
チャンクサイズ:
ProcessingChunkSize設定オプション を増やす(例:320、480、640サンプル)ことで、品質や応答性への影響を最小限に抑えつつ、レイテンシを顕著に改善できます。 -
モデルタイプ: リアリスティックモデルを使用する場合、高度に最適化されたモデルタイプ(デフォルトで選択)に切り替えるとパフォーマンスが向上します。元のモデルは、特にノイズの多いオーディオにおいて、わずかに品質が優れる場合があることに注意してください。
-
バッファ管理: ムード対応モデルは、オーディオを320サンプルのフレーム(16kHzで20ms)で処理します。最適なパフォーマンスを得るために、オーディオ入力のタイミングをこれに合わせてください。
-
ジェネレーターの再作成: Realisticモデルで確実に動作させるには、非アクティブ期間後に新しいオーディオデータを入力するたびにジェネレーターを再作成してください。説明については、トラブルシューティングのジェネレーターの再作成を参照してください。
次のステップ
オーディオ処理の設定が完了したら、以下のことを行いたい場合があります。