デモプロジェクト
Runtime MetaHuman Lip Sync をすぐに使い始められるよう、すぐに使えるデモプロジェクトが2つ用意されています。どちらも Unreal Engine 5.6+ で構築され、Blueprintのみで動作し、Windows、Mac、Linux、iOS、Android、および Android ベースのプラットフォーム(Meta Quest を含む)でクロスプラットフォーム対応しています。
利用可能なデモプロジェクト
- AI会話型NPC / インタラクティブアバター
- 基本的なリップシンクデモ
音声認識、AIチャットボット(LLM)、テキスト読み上げ、オーディオ再生とリアルタイムのリップシンクを組み合わせた、完全なAI会話アバターワークフローです。これらすべてが単一のプロジェクト内で連携して動作します。ゲーム、インタラクティブキオスク、バーチャルプロダクション、ミュージアムインスタレーション、デジタルアシスタント、トレーニングシミュレーションなど、幅広いユースケースに適しています。
パイプライン概要
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
LLMがストリーミングモードに設定されている場合、応答全体を待つのではなく、出力が文ごとに分割され、各文が完了するたびにTTSに送信されるため、レイテンシーが最小限に抑えられます。
動画
クイックプレビュー(約30秒)
デモの動作を簡単に紹介します。
完全なチュートリアル
セットアップ、設定、そして会話パイプライン全体を網羅した詳細なチュートリアルです。
ダウンロード
必須プラグインとオプションプラグイン
デモプロジェクトはモジュール式です。使用したいプロバイダーのプラグインのみが必要です。
| プラグイン | 目的 | 必須ですか? |
|---|---|---|
| Runtime MetaHuman Lip Sync | リップシンクアニメーション | 常に |
| Runtime Audio Importer | 音声キャプチャと処理 | 常に |
| Runtime Speech Recognizer | オフライン音声認識(whisper.cpp) | 常に |
| Runtime AI Chatbot Integrator | 外部LLM(OpenAI、Claude、DeepSeek、Gemini、Grok、Ollama)および/または外部TTS(OpenAI、ElevenLabs) | 🔶 オプション |
| Runtime Local LLM | llama.cpp によるローカル LLM 推論(Llama、Mistral、Gemma など、GGUF モデル) | 🔶 オプション |
| Runtime Text To Speech | PiperとKokoroによるローカルTTS | 🔶 オプション |
上記の各プラグインは個別にオプションですが、デモを動作させるには少なくとも1つのLLMプロバイダーと少なくとも1つのTTSプロバイダーが必要です。自由に組み合わせてください(例:ローカルLLM + ElevenLabs TTS、またはOpenAI LLM + ローカルTTS)。
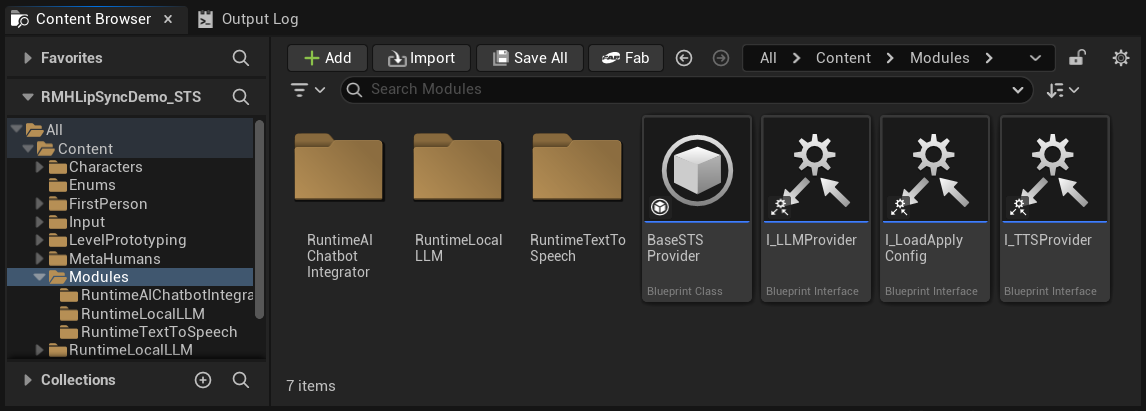
モジュラーアーキテクチャ
Content フォルダ内に Modules フォルダがあり、その中に 3 つのサブフォルダが含まれています。
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
オプションプラグインを1つ以上入手していない場合は、該当するフォルダを削除するだけで問題ありません。デモプロジェクトの基本アセット(ゲームインスタンス、ウィジェットなど)はこれらのモジュールを直接参照していないため、削除してもアセット参照エラーは発生しません。設定UIは、フォルダが存在しないプロバイダーを自動的に非表示にします。
このモジュール性はLLMとTTSプロバイダーにのみ適用されます。音声認識(Runtime Speech Recognizer)とリップシンク(Runtime MetaHuman Lip Sync)はベースデモプロジェクトの一部であり、常に必要です。
初回起動時、Unreal が不足しているオプションプラグインを無効にするかどうかを尋ねることがあります。はいをクリックしてください。対応する Content/Modules/ フォルダも削除したことを確認してください(上記参照)。
デモプロジェクトのレイアウト
以下に示すユーザーインターフェースは、すべてUMG(Unreal Motion Graphics)で構築されており、音声認識→LLM→TTS→リップシンクというパイプラインのデモンストレーションを目的としています。プロジェクトのビジュアルデザイン、操作方式、プラットフォーム(VR/AR、モバイル、コンソール、キオスクなど)に合わせて、自由にスタイルを変更したり置き換えたりできます。また、ユースケースで不要なウィジェットは、単に非表示にする(例:可視性をCollapsedやHiddenに設定する)ことも可能です。

| Area | 何がありますか |
|---|---|
| 中央揃え | メタヒューマンキャラクター。 |
| 左側 | 4つの設定ボタン(音声認識、AIチャットボット、テキスト読み上げ、アニメーション)については、以下で詳しく説明します。 |
| 中央下部 | 録音開始ボタン。これをクリックすると音声会話が始まります。マイクで音声をキャプチャし、文字起こしを行い、LLMに送信し、TTSで応答を合成し、リップシンクで再生します。完全にハンズフリーで動作します。 |
| 右中央 | 会話履歴ウィジェットは、あなたとAIの間の完全なやり取り(ユーザーとアシスタントの両方のメッセージ)を表示します。また、テキスト入力フィールドも含まれており、音声認識を使用せずに直接メッセージを入力できます。これは、テスト、アクセシビリティ、またはマイクが利用できない場合に便利です。 |
同じセッション内で両方の入力モードを自由に混在させることができます。メッセージを話したり、タイプしたりできます。
リップシンクがテストを続けるうちに(単なる固定遅延ではなく)音声からどんどん遅れていく場合は、以下のアニメーション設定の処理チャンクサイズを参照してください。
設定ボタン
左側の4つの設定ボタンは、パイプラインの各パート専用のパネルを開きます。
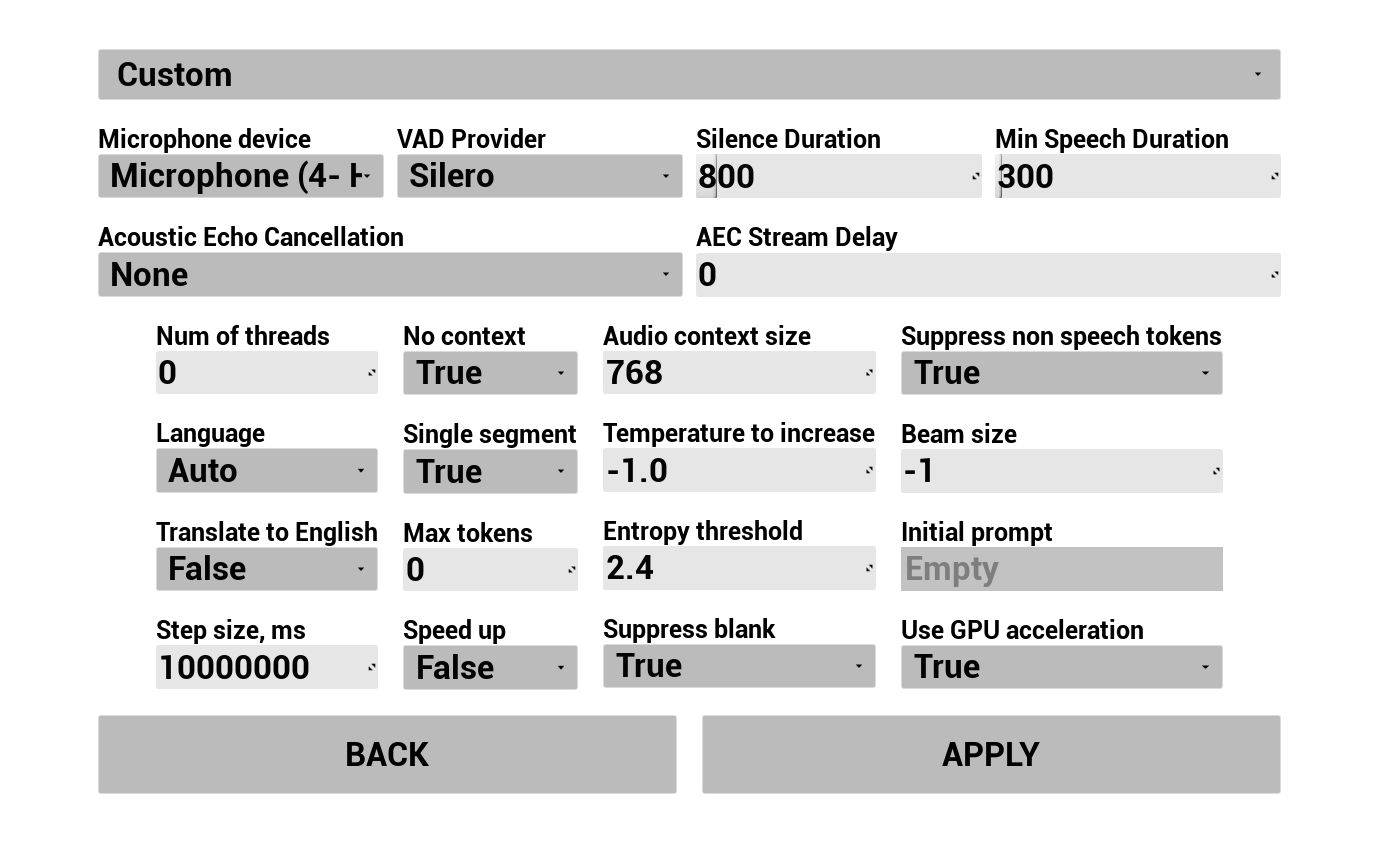
1. 音声認識を設定する
ユーザーの音声がどのようにキャプチャされ、文字起こしされるかを設定します。
- 言語を選択
- 音声認識パラメータを調整(Whisperモデル設定)
- AEC(音響エコーキャンセレーション)を設定
- VAD(音声アクティビティ検出)を設定
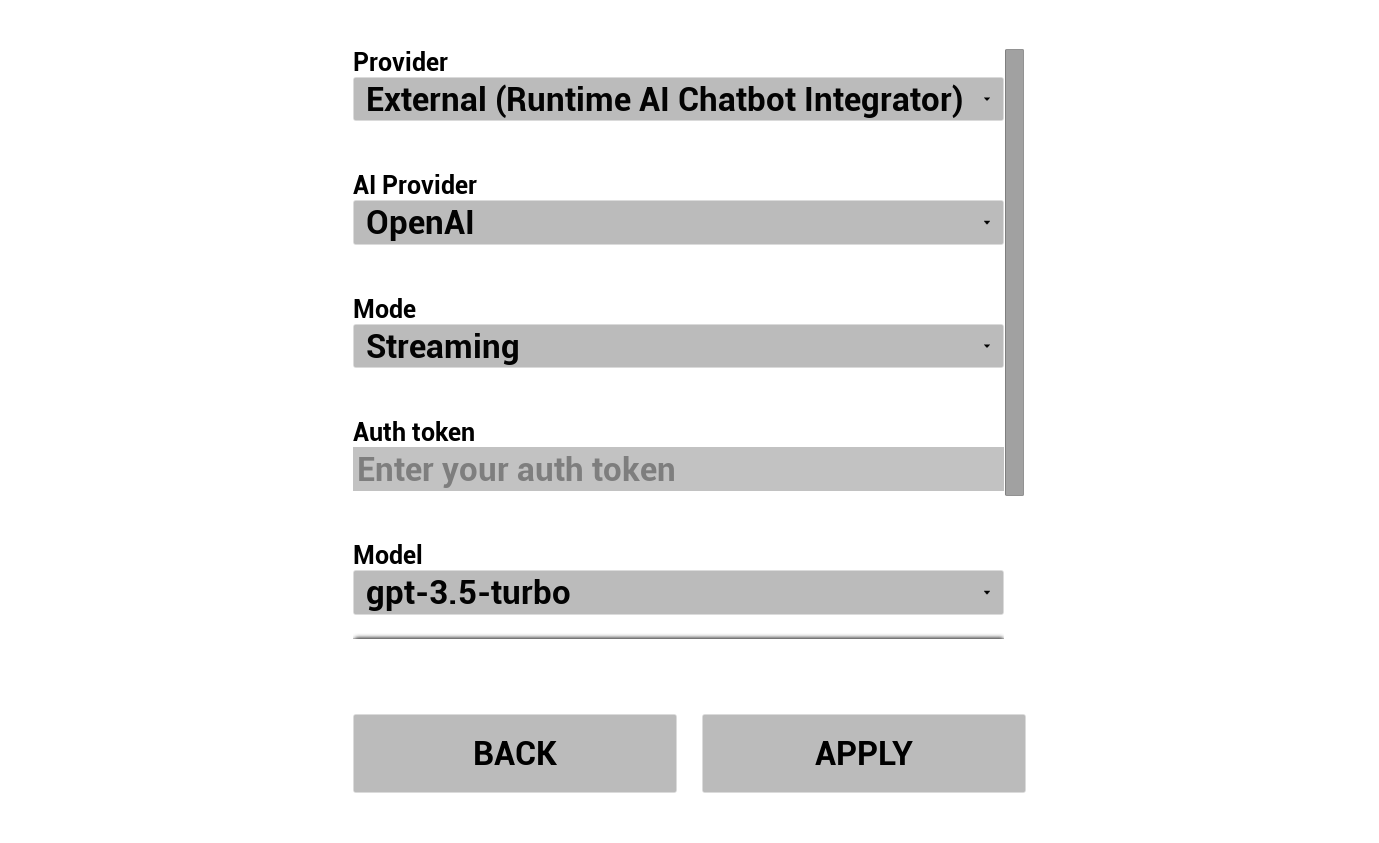
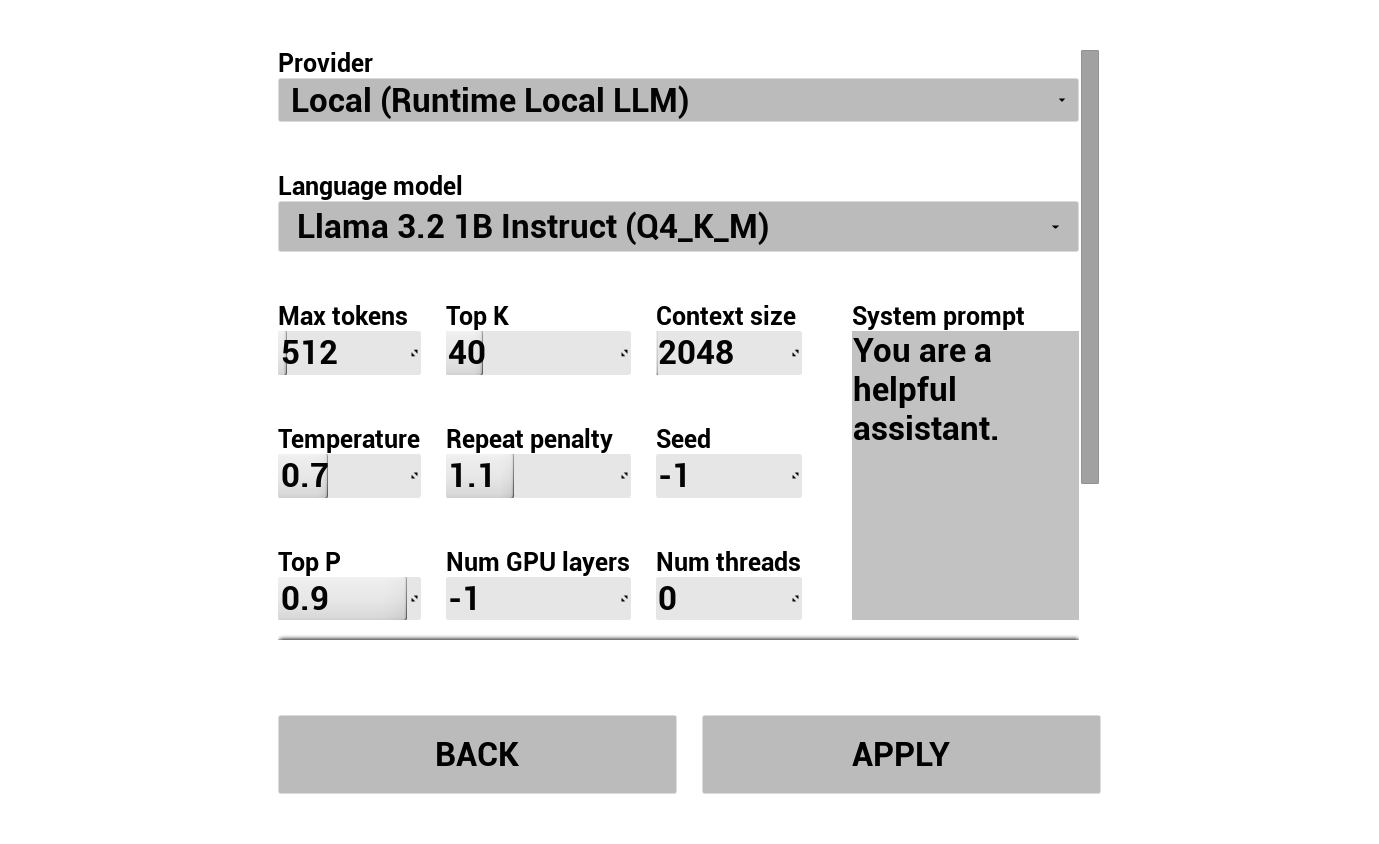
2. AIチャットボットを設定する
LLMプロバイダーを選択して設定してください。
- プロバイダーを選択(Runtime AI Chatbot Integrator または Runtime Local LLM)
- モードを選択:通常またはストリーミング(プロバイダー依存、ストリーミングでは文単位のTTS受け渡しが可能。パイプライン概要を参照)
- 外部プロバイダーの場合:認証トークン、モデル名など
- ローカルLLMの場合:GGUFモデルを選択し、コンテキストサイズやその他の推論パラメータを設定。また、デモから直接ランタイムで独自のGGUFモデルをダウンロード(例:URL経由)し、プロジェクトを再ビルドせずに即座に使用できます。
プロバイダーのコンボボックスには、Content/Modules/ にプラグインモジュールフォルダが存在するプロバイダーのみが表示されます。
3. テキスト読み上げを設定する
TTSプロバイダーを選択し、音声/モデルを設定してください:
- プロバイダーを選択(OpenAI/ElevenLabs用のRuntime AI Chatbot Integrator、またはローカルのPiper/Kokoro用のRuntime Text To Speech)
- モードを選択:通常またはストリーミング(オーディオが一度に返されるか、合成されながら返されるかを制御)
- 音声/モデルを選択
- プロバイダー固有のパラメータを調整

4. アニメーションを設定する
AIアバターのビジュアルをコントロール:
- 3つのプリダウンロード済みMetaHumanキャラクター(Aera、Ada、Orlando)から選択
- リップシンクモデル(StandardまたはRealistic)を選択
- リップシンクモデルタイプを選択 - Highly Optimized、Semi-Optimized、またはOriginal(モデルタイプを参照)
- 処理チャンクサイズを調整 - リップシンク推論の実行頻度を制御します(処理チャンクサイズを参照)
- CPU負荷が原因でリップシンクが時間とともに音声から遅れていく場合は、この値を480または640に増やしてください。
- 会話中にMetaHumanで再生する待機アニメーションを選択します。

エディタでデモを事前設定する
ソースバージョンを使用する場合、エディターでデフォルト値を事前に入力しておくことで、実行のたびに値を再入力する必要がなくなります。
| What | どこ |
|---|---|
| 一般設定(リップシンクモデル、アイドルアニメーション、キャラクタークラス、音声認識など) | Content/LipSyncSTSGameInstance |
| 外部LLM / 外部TTS 設定(ランタイムAIチャットボットインテグレーター) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| Local LLM 設定 (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| ローカルTTS設定(ランタイムテキスト読み上げ) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
クロスプラットフォームに関する注意事項
デモで使用されるすべてのプラグインは Windows、Mac、Linux、iOS、Android、およびAndroidベースのプラットフォーム(Meta Questを含む)をサポートしているため、デモプロジェクトもこれらすべてで動作します。これにより、ゲームやデスクトップキオスクからモバイルアプリ、スタンドアロンVRヘッドセット、オンセットのバーチャルプロダクション環境まで、幅広い環境への展開に適しています。
性能の低いデバイス(モバイル、スタンドアロンVR)では、以下の対応を検討してください。
- 標準リップシンクモデルをRealisticの代わりに使用してください。モデル比較を参照
- 高度に最適化モデルタイプに切り替える
- 処理チャンクサイズを増やしてCPU負荷を軽減する
- より小さいLLM/TTSモデルを選択する
プラットフォーム固有の設定を参照して、Android、iOS、Mac、Linuxでの追加のセットアップ手順を確認してください。
Pixel Streaming サポート
Pixel Streaming でのデモのデプロイ(クリックして展開)
AI会話デモプロジェクトはPixel Streaming環境でも動作し、MetaHumanアバターをリモートクライアント(例:ウェブブラウザ)にストリーミングしながら、クライアント側からユーザーのマイク音声をキャプチャできます。デモに必要な変更は1つだけです。
1. Runtime Audio Importer用のPixel Streaming拡張機能をインストールする
Runtime Audio Importerプラグインは、Pixel Streamingクライアントからオーディオをキャプチャできる無料の拡張プラグインを提供します。使用しているPixel Streamingインフラストラクチャのバージョンに応じて、以下のいずれかをインストールしてください。
- Pixel Streaming 拡張機能(元の Pixel Streaming プラグイン用)、または
- Pixel Streaming 2 拡張機能(新しい Pixel Streaming 2 プラグイン用)
ダウンロードリンクとインストール手順はこちらでご確認いただけます: Pixel Streaming Audio Capture - 拡張プラグインのインストール。
2. LipSyncSTSGameInstance 内のキャプチャ可能なサウンドウェーブノードを交換します。
拡張プラグインをインストールした後:
- コンテンツブラウザで
/All/Gameに移動し、LipSyncSTSGameInstanceアセットを開きます。 - イベントグラフに切り替えます。
- Event Init を見つけ、実行フローを辿って
Create Capturable Sound Wave→Set Capturable Sound Waveのノードペアを見つけます。 Create Capturable Sound Wave呼び出しを、ターゲットとする Pixel Streaming インフラストラクチャのバージョンに応じて、Create Pixel Streaming Capturable Sound WaveまたはCreate Pixel Streaming 2 Capturable Sound Waveに置き換えます。- その出力を同じ
Set Capturable Sound Waveノードに接続します。
この後、プロジェクトはPixel Streamingにデプロイする準備が整います。音声認識、LLM、TTS、リップシンクはすべて以前と同様に機能しますが、オーディオはローカルマイクではなくリモートクライアントからキャプチャされます。
独自のキャラクターを持ち込む
デモプロジェクトには、3つのサンプルMetaHumanキャラクター(Aera、Ada、Orlando)が付属していますが、独自のMetaHumanをインポートしてデモで使用することもできます。
📺 ビデオチュートリアル: デモプロジェクトにカスタムメタヒューマンキャラクターを追加する
Runtime MetaHuman Lip Syncプラグイン自体は、MetaHuman以外にも多くのキャラクターシステムをサポートしています(ARKitベースのキャラクター、Daz Genesis 8/9、Reallusion CC3/CC4、Mixamo、ReadyPlayerMeなど - カスタムキャラクター設定ガイドを参照)。ゲームのNPC、バーチャルプレゼンター、キオスクの案内役、バーチャルプロダクション用のデジタルヒューマンなど、どのようなキャラクターパイプラインにもこのプラグインは適応します。
よりシンプルなデモプロジェクトで、完全なAI会話ワークフローは含まず、リップシンク機能そのものに焦点を当てています。さまざまな音声ソースでリップシンクの動作を確認したい場合に適しています。
注目の動画
ダウンロード
含まれるもの
このデモでは、基本的なリップシンクのワークフローを紹介します。
- マイク入力 - ライブ音声からのリアルタイムリップシンク
- オーディオファイル再生 - インポートしたオーディオファイルからのリップシンク
- テキスト読み上げ - 合成音声によって駆動されるリップシンク
必須プラグインとオプションプラグイン
| プラグイン | 目的 | 必須ですか? |
|---|---|---|
| Runtime MetaHuman Lip Sync | リップシンクアニメーション | ✅ 必須 |
| Runtime Audio Importer | 音声のインポートとキャプチャ | ✅ 必須 |
| Runtime Text To Speech | TTSデモシーン用のローカルTTS | 🔶 オプション |
| Runtime AI Chatbot Integrator | 外部TTSプロバイダー(OpenAI、ElevenLabs) | 🔶 オプション |
標準リップシンクモデルに関する注意事項
Standard Model(Realisticではなく)をいずれかのデモプロジェクトで使用する予定がある場合は、Standard Lip Sync Extensionプラグインをインストールする必要があります。インストール手順については、Standard Model Extensionをご参照ください。
ヘルプが必要ですか?
デモプロジェクトのセットアップや実行中に問題が発生した場合は、お気軽にお問い合わせください。
カスタム開発のご依頼(例:デモに独自のロジックを追加する、特定のプラットフォームやキャラクターパイプラインに適応させるなど)は、[email protected] までお問い合わせください。