번역 제공업체
AI Localization Automator는 각각 고유한 강점과 구성 옵션을 가진 5가지 다른 AI 제공업체를 지원합니다. 프로젝트의 요구 사항, 예산 및 품질 요구 사항에 가장 적합한 제공업체를 선택하세요.
Ollama (로컬 AI)
최적 용도: 개인정보 보호에 민감한 프로젝트, 오프라인 번역, 무제한 사용
Ollama는 AI 모델을 사용자의 컴퓨터에서 로컬로 실행하여 API 비용이나 인터넷 요구 사항 없이 완전한 개인정보 보호와 제어를 제공합니다.
인기 모델
- translategemma:12b (Gemma 3 기반의 전문화된 번역 모델)
- llama3.2 (권장 범용 모델)
- mistral (효율적인 대안)
- codellama (코드 인식 번역)
- 그 외 많은 커뮤니티 모델들
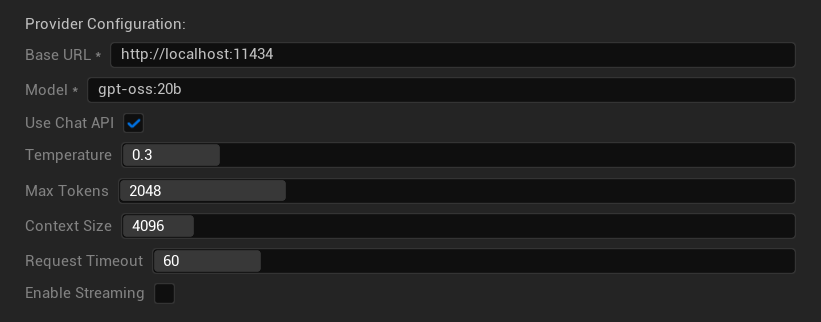
구성 옵션
- 기본 URL: 로컬 Ollama 서버 (기본값:
http://localhost:11434) - 모델: 로컬에 설치된 모델 이름 (필수)
- 채팅 API 사용: 더 나은 대화 처리를 위해 활성화
- Temperature: 0.0-2.0 (0.3 권장)
- 최대 토큰: 1-8,192 토큰
- 컨텍스트 크기: 512-32,768 토큰
- 요청 시간 초과: 10-300초 (로컬 모델은 더 느릴 수 있음)
- 스트리밍 활성화: 실시간 응답 처리를 위해
강점
- ✅ 완전한 개인정보 보호 (데이터가 사용자의 컴퓨터를 떠나지 않음)
- ✅ API 비용이나 사용 제한 없음
- ✅ 오프라인 작동
- ✅ 모델 매개변수에 대한 완전한 제어
- ✅ 다양한 커뮤니티 모델
- ✅ 벤더 종속성 없음
고려 사항
- 💻 로컬 설정과 충분한 성능의 하드웨어 필요
- ⚡ 일반적으로 클라우드 제공업체보다 느림
- 🔧 더 많은 기술적 설정 필요
- 📊 번역 품질은 모델에 따라 크게 달라짐 (일부는 클라우드 제공업체를 능가할 수 있음)
- 💾 모델 저장을 위한 대용량 저장 공간 필요
Ollama 설정하기
- Ollama 설치: ollama.ai에서 다운로드하여 시스템에 설치
- 모델 다운로드:
ollama pull translategemma:12b를 사용하여 선택한 모델 다운로드 - 서버 시작: Ollama는 자동으로 실행되거나,
ollama serve로 시작 - 플러그인 구성: 플러그인 설정에서 기본 URL과 모델 이름 설정
- 연결 테스트: 구성을 적용할 때 플러그인이 연결성을 확인함
OpenAI
최적 용도: 전반적으로 가장 높은 번역 품질, 광범위한 모델 선택
OpenAI는 최신 GPT 모델, 추론 모델 및 웹 검색 지원 모델을 포함한 Chat Completions API를 통해 업계를 선도하는 언어 모델을 제공합니다.
사용 가능한 모델
GPT-5 패밀리 (주력 모델)
- gpt-5, gpt-5-mini, gpt-5-nano
- gpt-5.1, gpt-5.2, gpt-5.3-chat-latest
- gpt-5.4, gpt-5.4-mini, gpt-5.4-nano
GPT-4.1 패밀리 (고성능)
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
GPT-4o 패밀리 (멀티모달)
- gpt-4o, gpt-4o-mini, chatgpt-4o-latest
O-시리즈 (추론 모델 — temperature/top_p 지원 안 함)
- o1, o1-pro, o3, o3-mini, o4-mini
웹 검색 모델 (Temperature/top_p 지원 안 함)
- gpt-5-search-api, gpt-4o-search-preview, gpt-4o-mini-search-preview
레거시 / 프리뷰
- gpt-4.5-preview, gpt-4, gpt-4-32k, gpt-4-turbo, gpt-3.5-turbo, gpt-3.5-turbo-16k

구성 옵션
- API 키: 사용자의 OpenAI API 키 (필수)
- 기본 URL: API 엔드포인트 (기본값:
https://api.openai.com/v1/chat/completions) - 모델: 위에 나열된 사용 가능한 모델 중 선택
- Temperature 사용: temperature 매개변수 켜기/끄기 (o-시리즈 추론 및 웹 검색 모델의 경우 자동으로 무시됨)
- Temperature: 0.0–2.0 (번역 일관성을 위해 0.3 권장)
- Top P: 0.0–1.0 nucleus 샘플링 매개변수 (o-시리즈 추론 및 웹 검색 모델의 경우 무시됨)
- 최대 완료 토큰: 1–128,000 토큰 (출력 및 추론 토큰 모두 포함)
- 요청 시간 초과: 5–300초
강점
- ✅ 일관되게 높은 품질의 번역
- ✅ 뛰어난 컨텍스트 이해
- ✅ 강력한 형식 보존
- ✅ 광범위한 언어 지원
- ✅ 안정적인 API 가동 시간
고려 사항
- 💰 요청당 더 높은 비용
- 🌐 인터넷 연결 필요
- ⏱️ 등급에 따른 사용 제한
Anthropic Claude
최적 용도: 미묘한 뉘앙스의 번역, 창의적인 콘텐츠, 안전 중심 애플리케이션
Claude 모델은 컨텍스트와 뉘앙스 이해에 탁월하여, 서사 중심 게임과 복잡한 현지화 시나리오에 이상적입니다.
사용 가능한 모델
Claude 4.6 패밀리 (최신)
- claude-opus-4-6, claude-sonnet-4-6
Claude 4.5 패밀리
- claude-haiku-4-5 (빠르고 효율적)
- claude-sonnet-4-5, claude-opus-4-5
Claude 4.x 패밀리
- claude-sonnet-4-0, claude-opus-4-1, claude-opus-4-0
Claude 3.x 패밀리 (레거시)
- claude-3-7-sonnet-latest, claude-3-5-haiku-latest, claude-3-opus-latest
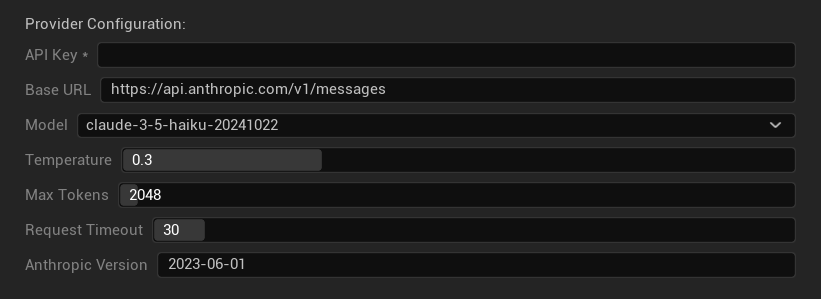
구성 옵션
- API 키: 사용자의 Anthropic API 키 (필수)
- 기본 URL: Claude API 엔드포인트
- 모델: Claude 모델 패밀리 중 선택
- Temperature: 0.0–1.0 (0.3 권장)
- Top K: Top-K 샘플링 매개변수 (0 = 설정 안 함)
- 최대 토큰: 1–64,000 토큰
- 요청 시간 초과: 5–300초
- Anthropic 버전: API 버전 헤더
강점
- ✅ 탁월한 컨텍스트 인식
- ✅ 창의적/서사적 콘텐츠에 적합
- ✅ 강력한 안전 기능
- ✅ 상세한 추론 능력 (3.7+ 모델에서 확장된 사고)
- ✅ 뛰어난 지시 따르기 능력
고려 사항
- 💰 프리미엄 가격 정책
- 🌐 인터넷 연결 필요
- 📏 모델별 토큰 제한 다양
DeepSeek
최적 용도: 비용 효율적인 번역, 높은 처리량, 예산에 민감한 프로젝트
DeepSeek은 다른 제공업체의 비용의 일부로 경쟁력 있는 번역 품질을 제공하여 대규모 현지화 프로젝트에 이상적입니다.
사용 가능한 모델
- deepseek-chat (범용, 권장)
- deepseek-reasoner (향상된 추론 능력)
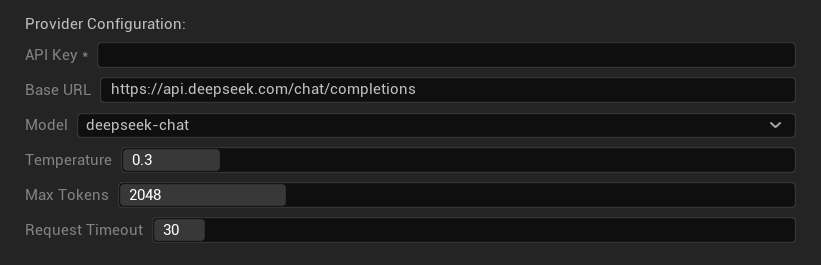
구성 옵션
- API 키: 사용자의 DeepSeek API 키 (필수)
- 기본 URL: DeepSeek API 엔드포인트
- 모델: 채팅 모델과 추론 모델 중 선택
- Temperature: 0.0-2.0 (0.3 권장)
- 최대 토큰: 1-8,192 토큰
- 요청 시간 초과: 5-300초
강점
- ✅ 매우 비용 효율적
- ✅ 좋은 번역 품질
- ✅ 빠른 응답 시간
- ✅ 간단한 구성
- ✅ 높은 요율 제한
고려 사항
- 📏 낮은 토큰 제한
- 🆕 새로운 제공업체 (검증된 실적이 적음)
- 🌐 인터넷 연결 필요
Google Gemini
최적 용도: 다국어 프로젝트, 비용 효율적인 번역, Google 생태계 통합
Gemini 모델은 향상된 추론을 위한 사고 모드와 같은 고유한 기능과 경쟁력 있는 가격으로 강력한 다국어 기능을 제공합니다.
사용 가능한 모델
Gemini 3.x 패밀리 (프리뷰)
- gemini-3.1-pro-preview, gemini-3-pro-preview, gemini-3-flash-preview
Gemini 2.5 패밀리 (사고 지원 포함)
- gemini-2.5-pro (사고 기능 포함 주력 모델)
- gemini-2.5-flash (빠르고, 사고 지원 포함)
- gemini-2.5-flash-lite (경량 변형)
Gemini 2.0 패밀리
- gemini-2.0-flash, gemini-2.0-flash-lite
최신 별칭
- gemini-flash-latest, gemini-flash-lite-latest
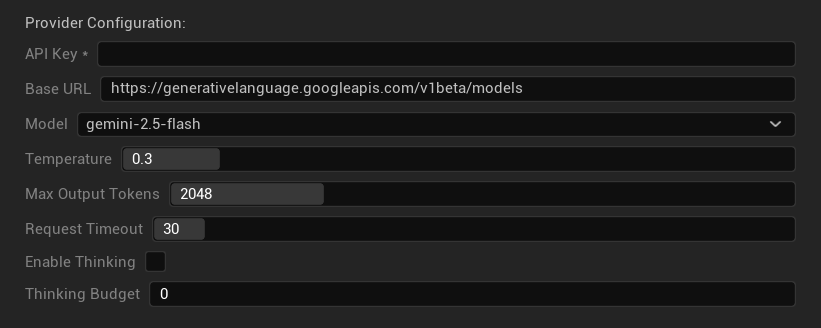
구성 옵션
- API 키: 사용자의 Google AI API 키 (필수)
- 기본 URL: Gemini API 엔드포인트
- 모델: Gemini 모델 패밀리 중 선택
- Temperature: 0.0–2.0 (0.3 권장)
- 최대 출력 토큰: 1–8,192 토큰
- 요청 시간 초과: 5–300초
- 사고 활성화: 2.5+ 모델에 대해 향상된 추론 활성화
- 사고 예산: 사고 토큰 할당 제어 (0 = 사고 없음)
강점
- ✅ 강력한 다국어 지원
- ✅ 경쟁력 있는 가격
- ✅ 고급 추론 (사고 모드)
- ✅ Google 생태계 통합
- ✅ 최신 모델에 대한 프리뷰 접근과 함께 정기적인 모델 업데이트
고려 사항
- 🧠 사고 모드는 토큰 사용량 증가
- 📏 모델별 가변적인 토큰 제한
- 🌐 인터넷 연결 필요
적합한 제공업체 선택하기
| 제공업체 | 최적 용도 | 품질 | 비용 | 설정 | 개인정보 보호 |
|---|---|---|---|---|---|
| Ollama | 개인정보 보호/오프라인 | 가변적* | 무료 | 고급 | 로컬 |
| OpenAI | 최고 품질 | ⭐⭐⭐⭐⭐ | 💰💰💰 | 쉬움 | 클라우드 |
| Claude | 창의적 콘텐츠 | ⭐⭐⭐⭐⭐ | 💰💰💰💰 | 쉬움 | 클라우드 |
| DeepSeek | 예산 프로젝트 | ⭐⭐⭐⭐ | 💰 | 쉬움 | 클라우드 |
| Gemini | 다국어 | ⭐⭐⭐⭐ | 💰 | 쉬움 | 클라우드 |
*Ollama의 품질은 사용된 로컬 모델에 따라 크게 달라짐 - 일부 최신 로컬 모델은 클라우드 제공업체와 동등하거나 능가할 수 있음.
제공업체 구성 팁
모든 클라우드 제공업체에 대해:
- API 키를 안전하게 저장하고 버전 관리 시스템에 커밋하지 마세요
- 일관된 번역을 위해 보수적인 temperature 설정(0.3)으로 시작하세요
- API 사용량과 비용을 모니터링하세요
- 대규모 번역 실행 전에 소규모 배치로 테스트하세요
Ollama에 대해:
- 충분한 RAM을 확보하세요 (더 큰 모델의 경우 8GB+ 권장)
- 더 나은 모델 로딩 성능을 위해 SSD 저장 장치 사용
- 더 빠른 추론을 위해 GPU 가속 고려
- 프로덕션 번역에 의존하기 전에 로컬에서 테스트하세요