추론 매개변수
LLM 추론 매개변수 구조는 모델이 텍스트를 로드하고 생성하는 방식을 제어합니다. 모델을 로드할 때 이러한 매개변수를 전달합니다. 이 페이지에서는 각 매개변수와 그 효과에 대해 설명합니다.
파라미터 참조
| 매개변수 | Type | 기본값 | 범위 | 설명 |
|---|---|---|---|---|
| 최대 토큰 | int32 | 512 | 1–8192 | 단일 응답에서 생성할 최대 토큰 수 |
| 온도 | float | 0.7 | 0.0–2.0 | 무작위성을 제어합니다. 0.0 = 결정론적. 값이 높을수록 더 창의적인 출력. |
| Top P | float | 0.9 | 0.0–1.0 | 핵 샘플링. 누적 확률이 이 값을 초과하는 토큰만 고려됩니다. |
| Top K | int32 | 40 | 0–200 | 상위 K개의 가장 확률 높은 토큰으로 선택을 제한합니다. 0 = 비활성화 |
| 반복 패널티 | float | 1.1 | 0.0–3.0 | 출력에 이미 나타난 토큰에 패널티를 부과합니다. 1.0 = 패널티 없음 |
| GPU 레이어 수 | int32 | -1 | -1–200 | 모델 레이어를 GPU로 오프로드할 수량입니다. -1 = 자동. 0 = CPU 전용 |
| 컨텍스트 크기 | int32 | 2048 | 128–131072 | 최대 컨텍스트 창 (토큰 기준). 값이 클수록 더 많은 메모리를 사용합니다. |
| 시스템 프롬프트 | FString | "당신은 유용한 도우미입니다." | — | 모델의 행동을 형성하는 시스템 지침 |
| 시드 | int32 | -1 | -1+ | 재현 가능한 출력을 위한 랜덤 시드. -1 = 랜덤 |
| 스레드 수 | int32 | 0 | 0–128 | 생성에 사용할 CPU 스레드 수입니다. 0 = 자동 |
사용법
- 블루프린트
- C++
추론 매개변수는 로드 및 비동기 노드에서 구조체 핀으로 나타납니다. 구조체를 분해하여 개별 값을 설정하세요.
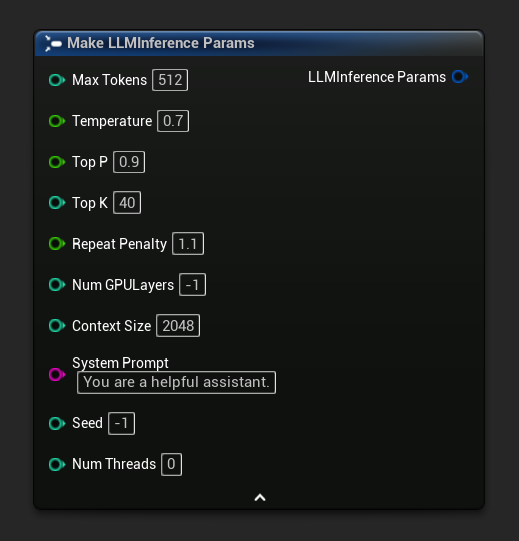
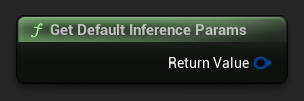
기본 매개변수 세트를 시작점으로 얻으려면 Get Default Inference Params를 사용하세요:
// Creative writing
FLLMInferenceParams CreativeParams;
CreativeParams.MaxTokens = 1024;
CreativeParams.Temperature = 1.2f;
CreativeParams.TopP = 0.95f;
CreativeParams.TopK = 80;
CreativeParams.RepeatPenalty = 1.2f;
CreativeParams.SystemPrompt = TEXT("You are a creative storyteller.");
// Factual / deterministic
FLLMInferenceParams FactualParams;
FactualParams.MaxTokens = 256;
FactualParams.Temperature = 0.1f;
FactualParams.TopP = 0.5f;
FactualParams.TopK = 10;
FactualParams.SystemPrompt = TEXT("Answer questions concisely and accurately.");
// Mobile-optimized
FLLMInferenceParams MobileParams;
MobileParams.MaxTokens = 128;
MobileParams.ContextSize = 1024;
MobileParams.NumGPULayers = 0;
MobileParams.NumThreads = 4;
MobileParams.SystemPrompt = TEXT("You are a helpful assistant. Keep responses brief.");
// Get defaults programmatically
FLLMInferenceParams DefaultParams = URuntimeLocalLLM::GetDefaultInferenceParams();
플랫폼 권장 사항
모바일 / VR (Android, iOS, Meta Quest)
- 컨텍스트 크기: 1024–2048
- GPU 레이어 수: 장치가 GPU 컴퓨팅 지원을 확인하지 않는 한 0 (CPU 전용)
- 최대 토큰 수: 반응형 상호작용을 위해 256 미만
- 스레드 수: 장치에 따라 2–4
데스크톱 (Windows, Mac, Linux)
- 컨텍스트 크기: 대부분의 대화에서 2048–8192
- GPU 레이어 수: -1 (자동)로 설정하여 GPU 가속을 사용 가능할 때 활용
- 스레드 수: 0 (자동)
- 최대 토큰 수: 긴 응답의 경우 512–2048
장기 대화
애플리케이션이 긴 세션 동안 대화를 유지하는 경우(NPC 대화, 지속형 어시스턴트, 롤플레이), 단순히 Context Size를 늘리는 대신 자동 요약과 함께 컨텍스트 크기를 설정하는 것을 고려하세요. 자동 요약이 활성화된 적당한 Context Size(2048–4096)는 지연 시간과 메모리 사용량을 안정적으로 유지하는 반면, 더 큰 컨텍스트 창은 모든 생성 작업을 점진적으로 느리게 만듭니다. 자동 컨텍스트 요약을 참조하세요.